小阿轩yx-Kubernertes日志收集
小阿轩yx-Kubernertes日志收集
前言
- 在 Kubernetes 集群中如何通过不同的技术栈收集容器的日志,包括程序直接输出到控制台日志、自定义文件日志等
有哪些日志需要收集
- 日志收集与分析很重要,为了更加方便的处理异常
简单总结一些比较重要的需要收集日志
- 服务器系统日志
- Kubernetes 组件日志
- 应用程序日志
除了这些日志外,可能还存在其它很多需要采集的日志,比如网关日志、服务之间调用链日志
日志采集工具有哪些
ELK 和 EFK
传统的架构中
- 比较成熟且流行的日志收集平台是 ELK(Elasticsearch+Logstash+Kibana),其中 Logstash 负责采集日志,并输出给 Elasticsearch,之后用 Kibana 进行展示。
- 几乎所有的服务都可以进行容器化
- ELK 技术栈同样可以部署到 Kubernetes 集群中,也可以进行相关的日志收集
但是由于 Logstash 比较消耗系统资源,并且配置稍微有点复杂,因此 Kubernetes 官方提出了 EFK(Elasticsearch+Fluentd+Kibana)的解决方案
相对于 ELK 中的 Logstash
- Fluentd 采用一锅端的形式,可以直接将某些日志文件中的内容存储至 Elasticsearch,然后通过 Kibana进行展示。
Fluentd 缺陷
- 它只能收集控制台日志(程序直接输出到控制台的日志),不能收集非控制台的日志,所以很难满足生产环境的需求
- 因为大部分情况下,没有遵循云原生理念开发的程序,往往会输出很多日志文件,这些容器内的日志无法采集
- 除非在每个 Pod 内添加一个 sidecar,将日志文件的内容进行 tail -f 转换成控制台日志,但这也是非常麻烦的。
另一个问题
- 大部分公司内都有很成熟的 ELK 平台,如果再搭建一个 EFK 平台,属于重复,当然用来存储日志的 Elasticsearch 集群不建议搭建在 Kubernetes 集群中,因为会非常浪费 Kubernetes 集群的资源,所以大部分情况下通过 Fluentd 采集日志输出到外部的 Elasticsearch 集群中。
总结
- Fluentd 功能有限,Logstash 太重,所以需要一个中和的工具进行日志的收集工作,此时就可以采用一个轻量化的收集工具:Filebeat。
Filebeat
早期的 ELK 架构中
- 日志收集均以 Logstash 为主,Logstash 负责收集和解析日志,对内存、CPU、IO 资源的消耗比较高,但是 Filebeat 所占系统的 CPU 和内存几乎可以忽略不计。
由于 Filebeat 本身是比较轻量级的日志采集工具,因此 Filebeat 经常被用于以 Sidecar 的形式配置在 Pod 中,用来采集容器内冲虚输出的自定义日志文件。
- Filebeat 同样可以采用 DaemonSet 的形式部署在 Kubernetes 集群中,用于采集系统日志和程序控制台输出的日志。
- Fluentd 和 Logstash 可以将采集的日志输出到 Elasticsearch 集群,Filebeat 同样可以将日志直接存储到 Elasticsearch 中,但是为了更好的分析日志或者减轻 Elasticsearch 的压力,一般都是将日志先输出到 Kafka,再由 Logstash 进行简单的处理,最后输出到 Elasticsearch 中。
新贵 Loki
- 上述讲的无论是 ELK、EFK 还是 Filebeat,都需要用到Elasticsearch 来存储数据
Elasticsearch
- 本身就像一座大山,维护难度和资源使用都是偏高的。
对于很多公司而言,热别是创新公司,可能并不想大费周章的去搭建一个 ELK、EFK或者其他重量级的日志平台,刚开始的人力投入可能是大于收益的,所以就需要一个更轻量级的日志收集平台。
一个基于 Kubernetes 平台的原生日志收集平台 Loki stack 应运而生,解决了上述的问题和难点,一经推出,就受到了用户的青睐。
Loki
- 是 Grafana Labs 开源的一个日志聚合系统。
优势
- 支持水平扩展、高可用、多租户的
Loki 的架构图

Loki 主要包含的组件
- Loki:主服务器,负责日志的存储和査询,参考了prometheus 服务发现机制,将标签添加到日志流,而不是想其他平台一样进行全文索引。
- Promtail:负责收集日志并将其发送给 Loki,主要用于发现采集目标以及添加对应 Labe1,最终发送给 Loki。
- Grafana:用来展示或查询相关日志,可以在页面査询指定标签 Pod 的日志。
和其他工具相比
- 虽然 Loki 不如其他技术栈功能灵活,但是 Loki 不对日志进行全文索引,仅索引相关日志的元数据,所以 Loki 操作起来更简单、更省成本。
- 而且 Loki 是基于 Kubernetes 进行设计的,可以很方便的部署在 Kubernetes 上,并且对集群的 Pod 进行日志采集,采集时会将 Kubernetes 集群中的一些元数据自动添加到日志中,让技术人员可以根据命名空间、标签字段进行日志的过滤,可以很快的定位到相关日志。
对于平台的选择,没有最好,只有最合适
- 比如公司内已经有了很成熟的 ELK平台,那么我们可以直接采用 Fluentd 或 Filebeat,然后将 Kubernetes 的日志输出到已存在的 Elasticsearch集群中即可。
- 如果公司并没有成熟的平台支持,又不想耗费很大的精力和成本去建立一个庞大的系统,那么 Loki stack 将会是一个很好的选择。
使用 EFK 收集控制台日志
- 首先我们使用 EFK 收集 Kubernetes 集群中的日志
- 本实验是在 Kubernetes 集群中启动一个 Elasticsearch 集群,如果企业已经有了 Elasticsearch 集群,可以直接将日志输出到已有的Elasticsearch集群中。
首先将 images-elk 镜像文件通过 Xftp 上传至 master、node01、node02(101、102、103)

将 efk-7.10.2 文件单独上传至 master(101)

这一步开启会话同步
进入镜像文件三个节点同时导入镜像
主机一
[root@k8s-master ~]# cd images/
[root@k8s-master images]# bash imp_docker_img.sh主机二
[root@k8s-node01 ~]# cd images/
[root@k8s-node01 images]# bash imp_docker_img.sh主机三
[root@k8s-node02 ~]# cd images/
[root@k8s-node02 images]# bash imp_docker_img.sh取消会话同步
部署 Elasticsearch+Fluentd+Kibana
下载需要的部署文档
https://github.com/dotbalo/k8s.git
- get clone
- 本案例已经下载好,可以直接使用
进入 ELK 目录
[root@k8s-master ~]# cd efk-7.10.2/创建 EFK 所用的命名空间
[root@k8s-master efk-7.10.2]# kubectl create -f create-logging-namespace.yaml
namespace/logging created创建 Elasticsearch 群集(已有该平台可以不创建)
[root@k8s-master efk-7.10.2]# kubectl create -f es-service.yaml
service/elasticsearch-logging created- 为 es 集群创建服务,以便为Fluentd 提供数据传入的端口
获取 SVC 状态信息
[root@k8s-master efk-7.10.2]# kubectl get svc -n logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-logging ClusterIP None <none> 9200/TCP,9300/TCP 20s- 9200 端口:用于所有通过 HTTP 协议进行的 API 调用。包括搜索、聚合、监控、以及其他任何使用HTTP 协议的请求。所有的客户端库都会使用该端口与 Elasticsearch 进行交互。
- 9300 端口:是一个自定义的二进制协议,用于集群中各节点之间的通信。用于诸如集群变更、主节点选举、节点加入/离开、分片分配等事项。
将文件创建出来
[root@k8s-master efk-7.10.2]# kubectl create -f es-statefulset.yaml
serviceaccount/elasticsearch-logging created
clusterrole,rbac.authorization.k8s.io/elasticsearch-logging created
clusterrolebinding.rbac.authorization.k8s.io/elasticsearch-logging created
statefulset.apps/elasticsearch-logging created- 创建 es 集群
获取 pod 的状态
[root@k8s-master efk-7.10.2]# kubectl get pod -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-0 1/1 Running 0 5m21s 创建 Kibana(已有该平台可以不创建)
[root@k8s-master efk-7.10.2]# kubectl create -f kibana-deployment.yaml -f kibana-service.yaml
deployment.apps/kibana-logging created
service/kibana-logging created 修改 Fluentd 的部署文件
- 由于在 Kubernetes 集群中,可能不需要对所有的机器都采集日志,因此可以更改 Fluentd 的部署文件。
添加一个 NodeSelector,只部署至需要采集日志的主机即可。
[root@k8s-master efk-7.10.2]# grep "nodeSelector" fluentd-es-ds.yaml -A 3
nodeSelector:fluentd: "true"volumes:- name: varlog为需要采集日志的服务器设置标签
[root@k8s-master efk-7.10.2]# kubectl label node k8s-node01 fluentd=true
node/k8s-node01 labeled
[root@k8s-master efk-7.10.2]# kubectl label node k8s-node02 fluentd=true
node/k8s-node02 labeled
[root@k8s-master efk-7.10.2]# kubectl label node k8s-master fluentd=true获取 node 节点的标签信息
[root@k8s-master efk-7.10.2]# kubectl get node -l fluentd=true --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-master Ready <none> 8d v1.23.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,fluentd=true,kubernetes.io/arch=amd64,kubernetes,io/hostname=k8s-master01,kubernetes,io/os=linux,node.kubernetes.io/node=
k8s-node01 Ready <none> 8d v1.23.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,fluentd=true,kubernetes.io/arch=amd64,kubernetes,io/hostname=k8s-master01,kubernetes,io/os=linux,node.kubernetes.io/node=
k8s-node02 Ready <none> 8d v1.23.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,fluentd=true,kubernetes.io/arch=amd64,kubernetes,io/hostname=k8s-master01,kubernetes,io/os=linux,node.kubernetes.io/node=创建 Fluentd
[root@k8s-master efk-7.10.2]# kubectl create -f fluentd-es-ds.yaml -f fluentd-es-configmap.yaml
serviceaccount/fluentd-es created
clusterrole.rbac.authorization.k8s,io/fluentd-es created
clusterrolebinding.rbac.authorization.k8s,io/fluentd-es createddaemonset.apps/fluentd-es-v3.1.1 created
configmap/fluentd-es-config-v0.2.1 created fluentd 的 ConfigMap 有一个字段需要注意,在 fluentd-es-configmap.yaml 文件的最后有一个output.conf:
host elasticsearch-logging
port 9200此处的配置将收集到得数据输出到指定的 Elasticsearch 集群中,由于创建 Elasticsearch 集群时会自动创建一个名为 elasticsearch-logging 的 Service,因此默认 Fluentd 会将数据输出到前面创建的 Elasticsearch 集群中。
如果企业已经存在一个成熟的 ELK 平台,可以创建一个同名的 Service 指向该集群,然后就能输出到现有的 Elasticsearch 集群中。
例如
apiVersion: v1
kind: Service
metadata:name: elasticsearch-loggingnamespace: logging
spec:type: ExternalNameexternalName: www.es.com- externalName: www.es.com:指向了外部 es 主机的地址或域名
<match **>
...host elasticsearch-loggingport 9200logstash format true
...</match>- host elasticsearch-logging:指定 fluentd 获取的日志要发往的主机
- port 9200:目标es 主机的端口号
- logstash_format true:指定是否使用常规的 index 命名格式,(1ogstash-%.%m.%d),默认为 false
Kibana 的使用
确认创建的 Pod 已经成功启动
[root@k8s-master efk-7.10.2]# kubectl get pod -n logging
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-0 1/1 Running 0 34m
fluentd-es-v3.1.1-7pm5p 1/1 Running 0 92s
fluentd-es-v3.1.1-wddc9 1/1 Running 0 15m
kibana-logging-7df48fb7b4-frfj6 1/1 Running 0 33m查看 kibana 暴露的端口
[root@k8s-master efk-7.10.2]# kubectl get svc -n logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-logging ClusterIP None <none> 9200/TCP,9300/TCP 35m
kibana-logging NodePort 10.104.162.209 <none> 5601:32734/TCP 34m访问 kibana
- 使用任意一个部署了 kube-proxy 服务的节点的 IP+32734 端口即可访问 kibana。
https://192.168.10.101:32734/kibana
创建一个 Pod 进行日志采集
编写 nginx 部署文件
[root@k8s-master efk-7.10.2]# cat nginx-service.yaml
apiVersion: v1
kind: Service
metadata:name: mynginxnamespace: defaultlabels:app: mynginx
spec:type: LoadBalancerports:- port: 80targetPort: httpprotocol: TCPname: httpselector:app: mynginx
---
apiVersion: apps/v1
kind: Deployment
metadata:name: mynginx-deploymentnamespace: defaultlabels:app: mynginx
spec:replicas: 2selector:matchLabels:app: mynginxtemplate:metadata:labels:app: mynginxspec:containers:- name: mynginximage: nginx:1.15.2ports:- name: httpcontainerPort: 80protocol: TCP部署该 Dployment
[root@k8s-master efk-7.10.2]# kubectl create -f nginx-service.yaml查看 pod 状态
[root@k8s-master efk-7.10.2]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mynginx-deployment-86655474f9-74whc 1/1 Running 0 34m
mynginx-deployment-86655474f9-zc5xh 1/1 Running 0 92s查看暴露的端口
[root@k8s-master efk-7.10.2]# kubectl get svc -n default
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13d
mynginx LoadBalancer 10.109.192.36 <none> 80:32019/TCP 12m客户端访问测试
[root@k8s-master efk-7.10.2]# curl 192.168.10.101:32019到 kibana 上查看

使用 Filebeat 收集自定义文件日志
基于云原生 12 要素开发的程序,一般会将日志直接输出到控制台,并非是指定一个文件存储日志,这一点和传统架构还是有区别的。
公司内的程序并非都是基于云原生要素开发
- 一些年代已久的程序,这类程序如果部署至 Kubernetes 集群中,就需要考虑如何将输出至本地文件的日志采集到 Elasticsearch。
之前了解到 Filebeat 是一个非常轻量级的日志收集工具,可以将其和应用程序部署至一个 Pod中,通过 Volume 进行日志文件的共享,之后 Filebeat 就可以采集里面的数据,并推送到日志平台。
本案例为了减轻 Elasticsearch 的压力
- 引入 Kafka 消息队列来缓存日志数据,之后通过Logstash 简单处理一下日志,最后再输出到 Elasticsearch 集群。
- 这种架构在生产环境中也是常用的架构,因为日志数量可能比较多,同时也需要对其进行加工。
- 当然 Fluentd 也可以将日志输出到 Kafka。
安装 helm 客户端(如果已有此工具,可跳过此步骤)
下载安装包
https://get.helm.sh/helm-v3.6.2-linux-amd64.atr.gzhttp://https://get.helm.sh/helm-v3.6.2-linux-amd64.atr.gz
解压
[root@k8s-master ~]# tar zxvf helm-v3.9.4-linux-amd64.tar.gz查看版本
[root@k8s-master ~]# helm version
version.BuildInfo{Version:"v3.6.2",
GitCommit:"ee407bdf364942bcb8e8c665f82e15aa28009b71",GitTreestate:"clean",
GoVersion:"go1.16.5"}创建 Kafka 和 Logstash
进入 filebeat 目录
[root@k8s-master ~]# cd elk-7.10.2/filebeat/查看 zookeeper 状态
[root@k8s-master filebeat]# kubectl get pod -n logging -l app.kubernetes.io/name=zookeeper- -l:指定标签
- 等一会,部署好显示状态为 Running
部署 kafka
[root@k8s-master filebeat]# helm install kafka kafka/ -n logging查看 kafka 状态
[root@k8s-master filebeat]# kubectl get pod -n logging -l app.kubernetes.io/component=kafka- 等一会,部署好显示状态为 Running
创建 logstash 服务
[root@k8s-master filebeat]# kubectl create -f logstash-service.yaml -f logstash-cm.yaml -f logstash.yaml -n logging注入 Filebeat Sidecar
创建一个模拟程序
[root@k8s-master filebeat]# kubectl create -f filebeat-cm.yaml -f app-filebeat.yaml -n logging查看 pod 状态
[root@k8s-master filebeat]# kubectl get pod -n logging
[root@k8s-master filebeat]# kubectl get svc -n logging
[root@k8s-master filebeat]# kubectl get svc- 这个 mynginx 的 svc 是创建在了 default 的命名空间的。
查看日志中的内容
[root@k8s-master filebeat]# kubectl exec app-ddf4b6db9-thtbs -n logging -- tail /opt/date.log最后返回主目录删除 EFK
[root@k8s-master ~]# rm -rf images-efk/- 最后删除整个 EFK 目录文件,不要影响后面的 Loki 实验
Loki
安装 Loki Stack(如果已安装,忽略此步骤)
首先将 images-loki 镜像文件通过 Xftp 上传至 master、node01、node02(101、102、103)

将 loki 文件单独上传至 master(101)

解压
[root@k8s-master ~]# tar zxvf helm-v3.9.4-linux-amd64.tar.gz将文件拷贝到指定目录下
[root@k8s-master ~]# cp linux-amd64/helm /usr/bin添加安装源
[root@k8s-master ~]# helm repo add grafana下载 loki-stack(如已有离线包,忽略此步骤)
https://grafana.github.io/helm-charts
[root@k8s-master ~]# helm repo update
grafana" has been added to your repositories
Hang tight while we grab the latest from your chart repositories......Successfully got an update from the "grafana" chart repository其他安装源
helm repo add loki https://grafana.github.io/loki/charts && helm repo update
查看列表
[root@k8s-master ~]# helm repo list查看版本信息
[root@k8s-master ~]# helm search repo loki-stack
NAME CHART VERSION APP VERSION DESCRIPTION
grafana/loki-stack2.8.3 v2.6.1 loki: like Prometheus,but for logs.拉取
[root@k8s-master ~]# helm pull grafana/loki-stack --version 2.8.3创建 Loki 命名空间
[root@k8s-master ~]# kubectl create ns loki
namespace/loki created解压 Loki 源码包
[root@k8s-master ~]# tar zxvf loki-stack-2.8.3.tgz创建 Loki Stack
[root@k8s-master ~]# helm upgrade --install loki loki-stack --set grafana.enabled=true --set grafana.service.type=NodePOrt -n loki
Release "loki" does not exist. Installing it now.
W0903 18:20:24.050253
36913 warnings.go:70]policy/v1betal PodsecurityPolicy is deprecated in v1.21+,unavailable in v1.25+W0903 18:20:24.05224336913 warnings.go:70]policy/v1beta1 PodsecurityPolicy isdeprecated in v1.21+,unavailable in v1.25+36913 warnings.go:70]policy/v1betal PodsecurityPolicy isW0903 18:20:24.055204deprecated in v1.21+,unavailable in v1.25+
W0903 18:20:24.14278636913 warnings.go:70]policy/v1beta1 PodsecurityPolicy isdeprecated in v1.21+,unavailable in v1.25+
W0903 18:20:24.14297636913 warnings.go:70]policy/v1betal PodsecurityPolicy isdeprecated in v1.21+,unavailable in v1.25+
36913 warnings.go:70]policy/v1beta1 PodsecurityPolicy isW0903 18:20:24.143197deprecated in v1.21+,unavailable in v1.25+NAME: loki
LAST DEPLOYED:Sat sep 3 18:20:23 2022NAMESPACE: loki
STATUS:deployed
REVISION:1
NOTES :
The Loki stack has been deployed to your cluster. Loki can now be added as a datasourcein Grafana.
See http://docs.grafana.org/features/datasources/loki/ for more detail.查看 Pod 状态
[root@k8s-master ~]# kubectl get pod -n loki
NAME READY STATUS RESTARTS AGE
loki-0 1/1 Running 0 2m12s
loki-grafana-64977c65f6-f26jk 1/1 Running 0 34m
loki-promtail-6bv2f 1/1 Running 0 92s
loki-promtail-xhlfc 1/1 Running 0 2m12s
loki-promtail-zscq9 1/1 Running 0 2m12s查看暴露的端口
[root@k8s-master efk-7.10.2]# kubectl get svc -n loki
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
loki ClusterIP 10.111.100.11 <none> 3100/TCP 2m40s
loki-grafana LoadBalancer 10.96.88.143 <none> 80:32734/TCP 2m40s
loki-headless ClusterIP None <none> 3100/TCP 2m40s
loki-memberlist ClusterIP None <none> 7946/TCP 2m40s查看 grafana 的密码
[root@k8s-master ~]# kubectl get secret loki-grafana --namespace loki -o jsonpath="{.data.admin-password}" | base64 --decode;echo
AfA2tYlsaPdy6hk1DB0xYfB7YZLf0501JsGtwcBV修改密码
[root@k8s-master ~]# kubectl exec -it loki-grafana-595d45d694-htg29 -n loki -c grafana grafana-cli admin reset-admin-password admin- 账号为:admin
登录
- https://192.168.10.101:32734
创建一个 Pod 进行日志采集
(还是前面的 pod)
编写 nginx 部署文件
[root@k8s-master ~]# cat nginx-service.yaml
apiVersion: v1
kind: Service
metadata:name: mynginxnamespace: defaultlabels:app: mynginx
spec:type: LoadBalancerports:- port: 80targetPort: httpprotocol: TCPname: httpselector:app: mynginx
---
apiVersion: apps/v1
kind: Deployment
metadata:name: mynginx-deploymentnamespace: defaultlabels:app: mynginx
spec:replicas: 2selector:matchLabels:app: mynginxtemplate:metadata:labels:app: mynginxspec:containers:- name: mynginximage: nginx:1.15.2ports:- name: httpcontainerPort: 80protocol: TCP部署该 Dployment
[root@k8s-master ~]# kubectl create -f nginx-service.yaml查看 pod 状态
[root@k8s-master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mynginx-deployment-86655474f9-74whc 1/1 Running 0 2m12s
mynginx-deployment-86655474f9-zc5xh 1/1 Running 0 2m12s查看暴露的端口
[root@k8s-master ~]# kubectl get svc -n default
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13d
mynginx LoadBalancer 10.109.192.36 <pending> 80:32019/TCP 12m客户端访问测试
[root@k8s-master ~]# curl 192.168.10.101:32019在 Loki 中查看此 Pod 的日志
{namespace="default",pod="mynginx-deployment-668d5454cb-lldng"}
{namespace="kube-system"}
{namespace="kube-system",pod="calico-node-gwtqw"}小阿轩yx-Kubernertes日志收集
相关文章:
小阿轩yx-Kubernertes日志收集
小阿轩yx-Kubernertes日志收集 前言 在 Kubernetes 集群中如何通过不同的技术栈收集容器的日志,包括程序直接输出到控制台日志、自定义文件日志等 有哪些日志需要收集 日志收集与分析很重要,为了更加方便的处理异常 简单总结一些比较重要的需要收集…...

0to1使用Redis实现“登录验证”次数限制
1 引言 系统为了避免密码遭到暴力破解,通常情况下需要在登录时,限制用户验证账号密码的次数,当达到一定的验证次数后,在一段时间内锁定该账号,不再验证。本章将用几行代码实现该功能,完整代码链接在文章最…...

ARM----时钟
时钟频率可以是由晶振提供的,我们需要高频率,但是外部接高的晶振会不稳定,所有使用PLL(锁相环)来放大频率。接下来就让我们学习用外部晶振提供的频率来配置时钟频率。 一.时钟源的选择 在这里我们选择外部晶振作为时钟…...

NISP 一级 —— 考证笔记合集
该笔记为导航目录,在接下来一段事件内,我会每天发布我关于考取该证书的相关笔记。 当更新完成后,此条注释会被删除。 第一章 信息安全概述 1.1 信息与信息安全1.2 信息安全威胁1.3 信息安全发展阶段与形式1.4 信息安全保障1.5 信息系统安全保…...

C++三位状态比较排序
数组相同元素个数及按序 void 交换3个数升(int& A, int& B, int& C, bool& k) {int J 0;if (B > A&&A > C)J C, C B, B A, A J, k true;//231else if (C > A&&A > B)J A, A B, B J, k true;//213else if (A > B&a…...

麒麟系统安装GPU驱动
1.nvidia 1.1显卡驱动 本机显卡型号:nvidia rtx 3090 1.1.1下载驱动 打开 https://www.nvidia.cn/geforce/drivers/ 也可以直接使用下面这个地址下载 https://www.nvidia.com/download/driverResults.aspx/205464/en-us/ 1.1.3安装驱动 右击,为run文件添加可…...

IDEA 安装lombok插件不兼容的问题及解决方法
解决:IDEA 安装lombok插件不兼容问题,plugin xxxx is incompatible 一、去官网下载最新的2024版本 地址传送通道: lombok插件官网地址https://plugins.jetbrains.com/plugin/6317-lombok/versions/stable 二、修改参数的配置 在压缩包路径…...

聊聊说话的习惯
1 在日常生活中,每个人都有固定的说话习惯。心理学研究表明,通过一个人的说话习惯,也可以分析出他的性格特点。对于每一个人来讲,说话习惯已经融为他们生活中的一部分。在社交活动中,一些不良的说话习惯很可能会给他们带来麻烦。…...

当水泵遇上物联网:智能水务新时代的浪漫交响
在当代科技的宏伟乐章中,物联网(IoT)技术宛如一位技艺高超的指挥家,引领着各行各业迈向智能化的新纪元。当这股创新浪潮涌向古老的水务行业时,一场前所未有的“智能水务”革命便悄然上演,而水泵——这一传统…...

【Canvas与钟表】干支表盘
【成图】 【代码】 <!DOCTYPE html> <html lang"utf-8"> <meta http-equiv"Content-Type" content"text/html; charsetutf-8"/> <head><title>387.干支表盘</title><style type"text/css">…...

分布式项目中使用雪花算法提前获取对象主键ID
hello,大家好,我是灰小猿! 在做分布式项目开发进行数据表结构设计时,有时候为了提高查询性能,在进行数据库表设计时,会使用自增ID来代替UUID作为数据的主键ID,但是这样就会有一个问题ÿ…...

小程序多个set-cookie无法处理
1、情景: 项目中遇到一个问题,客户的服务器上了华为云的防火墙,导致小程序请求头中携带了3个set- cookie(有两个是华为云给自动加的),而小程序端不知道用哪个来 处理,结果选了个错误的进行处理…...

Mybatis【分页插件,缓存,一级缓存,二级缓存,常见缓存面试题】
文章目录 MyBatis缓存分页延迟加载和立即加载什么是立即加载?什么是延迟加载?延迟加载/懒加载的配置 缓存什么是缓存?缓存的术语什么是MyBatis 缓存?缓存的适用性缓存的分类一级缓存引入案例一级缓存的配置一级缓存的工作流程一级…...

【Qt开发】QT6.5.3安装方法(使用国内源)亲测可行!!!
目录 🌕下载在线安装包🌕 把安装包放到系统盘🌕开始安装🌕参考文章 🌕下载在线安装包 https://mirrors.nju.edu.cn/qt/official_releases/online_installers/ 🌕 把安装包放到系统盘 我的系统盘是G盘&…...
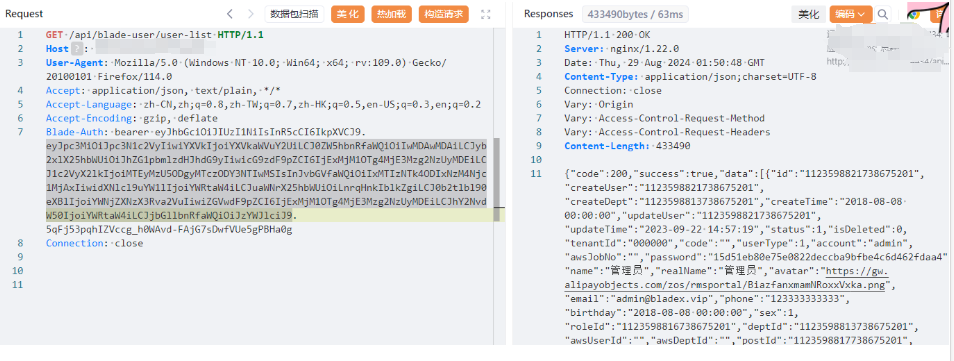
springblade-JWT认证缺陷漏洞CVE-2021-44910
漏洞成因 SpringBlade前端通过webpack打包发布的,可以从其中找到app.js获取大量接口 然后直接访问接口:api/blade-log/api/list 直接搜索“请求未授权”,定位到认证文件:springblade/gateway/filter/AuthFilter.java 后面的代码…...

Chapter 12 Vue CLI脚手架组件化开发
欢迎大家订阅【Vue2Vue3】入门到实践 专栏,开启你的 Vue 学习之旅! 文章目录 前言一、项目目录结构二、组件化开发1. 组件化2. Vue 组件的基本结构3. 依赖包less & less-loader 前言 组件化开发是Vue.js的核心理念之一,Vue CLI为开发者提…...
Ubuntu: 配置OpenCV环境
从从Ubuntu系统安装opencv_ubuntu安装opencv-CSDN博客文章浏览阅读2.3k次,点赞4次,收藏14次。开源计算机视觉(OpenCV)是一个主要针对实时计算机视觉的编程函数库。OpenCV的应用领域包括:2D和3D功能工具包、运动估计、面部识别系统、手势识别、人机交互、…...
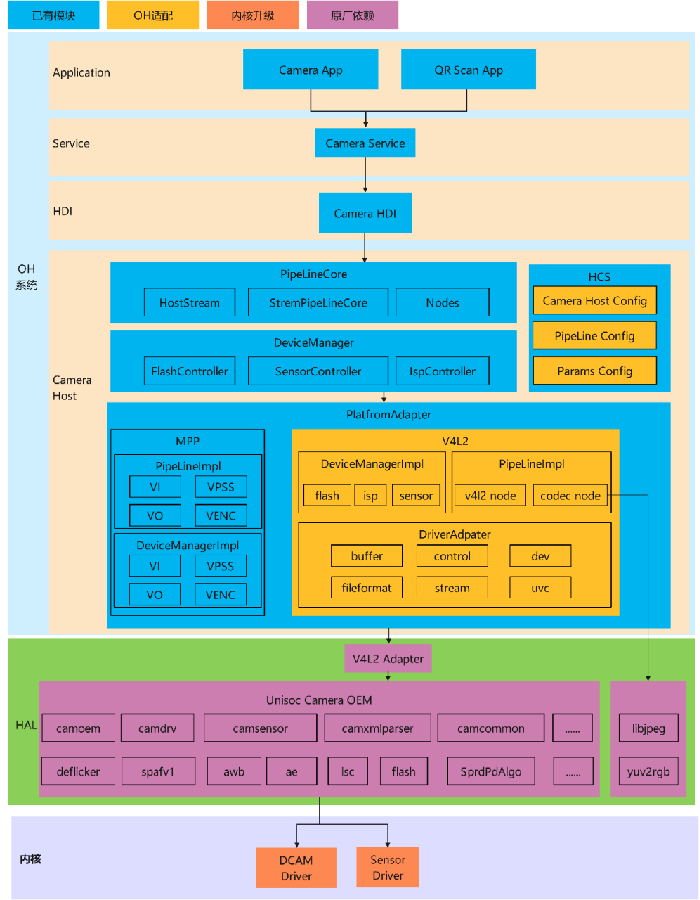
芯片解决方案--SL8541e-OpenHarmony适配方案
摘要 本文描述8541E芯片适配OpenHarmony的整体方案。 本文描述的整体方案,不止适用于8541e,也适用于该芯片厂家的其他芯片,如7863、7885,少部分子系统会略有差异。 整体方案架构 整体方案架构如下图,遵循OpenHarmo…...

Spring Boot之数据访问集成入门
Spring Boot中的数据访问和集成支持功能是其核心功能之一,通过提供大量的自动配置和依赖管理,极大地简化了数据访问层的开发。Spring Boot支持多种数据库,包括关系型数据库(如MySQL、Oracle等)和非关系型数据库&#x…...

Learn ComputeShader 09 Night version lenses
这次将要制作一个类似夜视仪的效果 第一步就是要降低图像的分辨率, 这只需要将id.xy除上一个数字然后再乘上这个数字 可以根据下图理解,很明显通过这个操作在多个像素显示了相同的颜色,并且很多像素颜色被丢失了,自然就会有降低分…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程
FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux FCEUX是一款功能强大的开源NES模拟器,让你在现代电脑上完美重温经典红白机游戏。无论…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

Android 11开发避坑:为什么你的App获取的Wifi MAC地址总是变?手把手教你配置固定MAC
Android 11开发实战:彻底解决Wifi MAC地址随机化问题最近在开发一个设备管理系统时,遇到了一个棘手的问题:我们的App在Android 11设备上获取的Wifi MAC地址每次都不一样,导致基于MAC地址的设备识别功能完全失效。经过一周的深入研…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...