算法【洪水填充】
洪水填充是一种很简单的技巧,设置路径信息进行剪枝和统计,类似感染的过程。路径信息不撤销,来保证每一片的感染过程可以得到区分。看似是暴力递归过程,其实时间复杂度非常好,遍历次数和样本数量的规模一致。
下面通过一些题目来加深理解。
题目一
测试链接:https://leetcode.cn/problems/number-of-islands/
分析:洪水填充更可以看作是一个感染过程,将空间中符合条件的位置感染成我们需要的东西。这道题可以从是陆地的地方深度优先开始感染,将陆地感染成用以区分不再是陆地的信号。当遍历完整个空间后,我们就知道有多少个岛屿。代码如下。
class Solution {
public:int arr[5] = {0, 1, 0, -1, 0};void dfs(int i, int j, int row, int column, vector<vector<char>>& grid){if(i < 0 || i >= row || j < 0 || j >= column || grid[i][j] != '1'){return;}grid[i][j] = '0';for(int index = 0;index < 4;++index){dfs(i+arr[index], j+arr[index+1], row, column, grid);}}int numIslands(vector<vector<char>>& grid) {int row = grid.size();int column = grid[0].size();int ans = 0;for(int i = 0;i < row;++i){for(int j = 0;j < column;++j){if(grid[i][j] == '1'){++ans;dfs(i, j, row, column, grid);}}}return ans;}
};其中,arr数组是用于遍历一个位置的周围即上下左右;在numIslands方法中调用dfs方法时,岛屿数加1,相当于重新感染一个新岛屿。
题目二
测试链接:https://leetcode.cn/problems/surrounded-regions/
分析:这个题可以看出,如果一个O和矩阵的四周存在的O相连,则这个O不会被替换成X,那么我们可以对矩阵的四周,也就是上下左右四个边界的O,使用深度优先进行感染,将其设为一个用以区分的信号。最后将矩阵中所有没有被更新为信号的O,更新为X;将更新为信号的位置更新为O。代码如下。
class Solution {
public:int arr[5] = {0, 1, 0, -1, 0};void dfs(int i, int j, int row, int column, vector<vector<char>>& board){if(i < 0 || i >= row || j < 0 || j >= column || board[i][j] != 'O'){return;}board[i][j] = 'z';for(int index = 0;index < 4;++index){dfs(i+arr[index], j+arr[index+1], row, column, board);}}void solve(vector<vector<char>>& board) {int row = board.size();int column = board[0].size();for(int i = 0;i < column;++i){if(board[0][i] == 'O'){dfs(0, i, row, column, board);}}for(int i = 0;i < column;++i){if(board[row-1][i] == 'O'){dfs(row-1, i, row, column, board);}}for(int i = 0;i < row;++i){if(board[i][0] == 'O'){dfs(i, 0, row, column, board);}}for(int i = 0;i < row;++i){if(board[i][column-1] == 'O'){dfs(i, column-1, row, column, board);}}for(int i = 0;i < row;++i){for(int j = 0;j < column;++j){if(board[i][j] == 'O'){board[i][j] = 'X';}else if(board[i][j] == 'z'){board[i][j] = 'O';}}}}
};其中,信号为z,也就是说在最后更新时,O更新为X,z更新为O;最开始的4个for循环是对上下左右四个边界的O进行感染。
题目三
测试链接:https://leetcode.cn/problems/making-a-large-island/
分析:这道题涉及到岛屿的面积,所以在感染时,我们设置的信号应该是岛屿的编号。这样方便对不同编号的岛屿进行面积统计。在感染之后,我们得到了岛屿的数量,以及每个岛屿的面积。这时,遍历空间中那些不是岛屿的位置并进行判定。判定过程为对这些位置上下左右是否连接了岛屿,如果连接了,则加上这个岛屿的面积,注意不要重复计算岛屿面积,最后再加上这个位置的面积,也就是再加1。遍历空间中不是岛屿的位置,最终得到最大值。代码如下。
class Solution {
public:int area[125003] = {0};set<int> used;int arr[5] = {0, 1, 0, -1, 0};void dfs(int i, int j, int n, vector<vector<int>>& grid, int number){if(i < 0 || i >= n || j < 0 || j >= n || grid[i][j] != 1){return;}grid[i][j] = number;++area[number];for(int index = 0;index < 4;++index){dfs(i+arr[index], j+arr[index+1], n, grid, number);}}int largestIsland(vector<vector<int>>& grid) {int n = grid.size();int number = 2;int ans = 0;int temp_ans;for(int i = 0;i < n;++i){for(int j = 0;j < n;++j){if(grid[i][j] == 1){dfs(i, j, n, grid, number);++number;}}}for(int i = 2;i < number;++i){ans = ans > area[i] ? ans : area[i];}for(int i = 0;i < n;++i){for(int j = 0;j < n;++j){if(grid[i][j] == 0){temp_ans = 0;for(int index = 0;index < 4;++index){if(i+arr[index] >= 0 && i+arr[index] < n && j+arr[index+1] >= 0 && j+arr[index+1] < n &&grid[i+arr[index]][j+arr[index+1]] != 0 && used.count(grid[i+arr[index]][j+arr[index+1]]) == 0){temp_ans += area[grid[i+arr[index]][j+arr[index+1]]];used.insert(grid[i+arr[index]][j+arr[index+1]]);}}++temp_ans;ans = ans > temp_ans ? ans : temp_ans;used.clear();}}}return ans;}
};其中,used用来判断一个岛屿是否已经被加过;number是当前岛屿的编号,因为0和1已经被使用所以number从2开始;需要将ans的初始值设为最大岛屿值是因为有可能全部是陆地,也就是没有连接的机会,那么这时的最大值自然就是最大岛屿值。
题目四
测试链接:https://leetcode.cn/problems/bricks-falling-when-hit/
分析:这个题我们看到了稳定和掉落这两个状态,很容易想到使用并查集。使用并查集的思路是,在没有打落砖块的时候,使用并查集将稳定的砖块设为一个集合,不稳定的砖块设为一个集合。最开始顶部的砖块是稳定的,然后相邻砖块之间归为一个集合。设置一个是否稳定的数组,顶部砖块是稳定的设为true,其他设为false。在union方法合并的时候,更新代表元素的是否稳定数组。遍历完砖块后,查询有多少个砖块的集合的代表元素是稳定的,这时候得到没有打入炮弹时的稳定砖块数目。实际上这个数目应该是统计的砖块数目。然后每打落一个砖块,重新统计一次稳定的数目,然后用上一次稳定的数目减此次稳定的数目再减1,因为打落的砖块是消失不计入不稳定的数目,但是这个方法复杂度太高,会超时。所以使用洪水填充加时光倒流。我们需要得到每次炮弹掉落的砖块数目,那么可以在所有炮弹打落之后往回加,也就是从最后一个炮弹开始,每一个炮弹没打之后多了多少稳定的砖块。主要流程就是,首先,将所有炮弹打出去,也就是把炮弹的指向位置的网格值减1,然后将顶部的网格,也就是已经稳定的网格开始洪水填充现存的砖块,将网格值更新为2(什么都行主要要区分1),然后开始时光倒流,从最后一个炮弹往前遍历,把炮弹指向位置处加1,如果为0,则代表之前这个位置没有砖块,continue;如果大于0,则判定这个位置的上下左右是否有等于2的砖块,因为2代表了现在稳定的砖块,如果有,则从炮弹恢复的位置开始洪水填充将1更新为2,更新的数目减1则为这个炮弹对应掉落的砖块数目,减1是因为炮弹指向位置不计入掉落的砖块数目。代码如下。
class Solution {
public:int arr[5] = {0, 1, 0, -1, 0};int dfs(int i, int j, int row, int column, vector<vector<int>>& grid){if(i < 0 || i >= row || j < 0 || j >= column || grid[i][j] != 1){return 0;}int num = 1;grid[i][j] = 2;for(int index = 0;index < 4;++index){num += dfs(i+arr[index], j+arr[index+1], row, column, grid);}return num;}vector<int> hitBricks(vector<vector<int>>& grid, vector<vector<int>>& hits) {vector<int> ans;int row = grid.size();int column = grid[0].size();int length = hits.size();ans.assign(length, 0);for(int i = 0;i < length;++i){--grid[hits[i][0]][hits[i][1]];}for(int i = 0;i < column;++i){if(grid[0][i] == 1){dfs(0, i, row, column, grid);}}for(int i = length-1;i >= 0;--i){++grid[hits[i][0]][hits[i][1]];if(grid[hits[i][0]][hits[i][1]] == 0){continue;}if(hits[i][0] == 0){ans[i] = dfs(hits[i][0], hits[i][1], row, column, grid) - 1;}else if(hits[i][0] >= 0 && hits[i][0] < row && hits[i][1]+1 >= 0 && hits[i][1]+1 < column && grid[hits[i][0]][hits[i][1]+1] == 2){ans[i] = dfs(hits[i][0], hits[i][1], row, column, grid) - 1;}else if(hits[i][0] >= 0 && hits[i][0] < row && hits[i][1]-1 >= 0 && hits[i][1]-1 < column && grid[hits[i][0]][hits[i][1]-1] == 2){ans[i] = dfs(hits[i][0], hits[i][1], row, column, grid) - 1;}else if(hits[i][0]+1 >= 0 && hits[i][0]+1 < row && hits[i][1] >= 0 && hits[i][1] < column && grid[hits[i][0]+1][hits[i][1]] == 2){ans[i] = dfs(hits[i][0], hits[i][1], row, column, grid) - 1;}else if(hits[i][0]-1 >= 0 && hits[i][0]-1 < row && hits[i][1] >= 0 && hits[i][1] < column && grid[hits[i][0]-1][hits[i][1]] == 2){ans[i] = dfs(hits[i][0], hits[i][1], row, column, grid) - 1;}}return ans;}
};其中,在恢复炮弹指向位置时大于0的判定中,如果指向位置本身就是顶部位置,那么不管这个位置的上下左右是否有为2的位置,直接填充。
相关文章:

算法【洪水填充】
洪水填充是一种很简单的技巧,设置路径信息进行剪枝和统计,类似感染的过程。路径信息不撤销,来保证每一片的感染过程可以得到区分。看似是暴力递归过程,其实时间复杂度非常好,遍历次数和样本数量的规模一致。 下面通过…...

PostgreSQL的repmgr工具介绍
PostgreSQL的repmgr工具介绍 repmgr(Replication Manager)是一个专为 PostgreSQL 设计的开源工具,用于管理和监控 PostgreSQL 的流复制及实现高可用性。它提供了一组工具和实用程序,简化了 PostgreSQL 复制集群的配置、维护和故障…...
面试官:synchronized的锁升级过程是怎样的?
大家好,我是大明哥,一个专注「死磕 Java」系列创作的硬核程序员。 回答 在 JDK 1.6之前,synchronized 是一个重量级、效率比较低下的锁,但是在JDK 1.6后,JVM 为了提高锁的获取与释放效,,对 synchronized 进…...

Linux中的时间
1、date命令 参数作用参数作用参数作用%Y年xxxx%m月xx%d日xx%H小时(00~23)%M分钟(00~59)%S秒(00~59)%I小时(00~12)%t跳格[Tab键]%j今…...

用Boot写mybatis的增删改查
一、总览 项目结构: 图一 1、JavaBean文件 2、数据库操作 3、Java测试 4、SpringBoot启动类 5、SpringBoot数据库配置 二、配置数据库 在项目资源包中新建名为application.yml的文件,如图一。 建好文件我们就要开始写…...

电脑主机内存
在计算机的组成结构当中内存是非常重要的一部分,它用来存储程序和数据。对于计算机来说有了内存才能保证计算机的正常工作。 内部存储器就是我们所说的内存条,一般是用来即时存储数据。不做数据的长期保留。 外部存储器就是我们常说的固态或者硬盘。固态…...
文件操作与隐写
一、文件类型的识别 1、文件头完好情况: (1)file命令 使用file命令识别:识别出file.doc为jpg类型 (2)winhex 通过winhex工具查看文件头类型,根据文件头部内容去判断文件的类型 eg:JPG类型 &a…...

SQLException: No Suitable Driver Found - 完美解决方法详解
🚨 SQLException: No Suitable Driver Found - 完美解决方法详解 🚨 **🚨 SQLException: No Suitable Driver Found - 完美解决方法详解 🚨****摘要 📝****引言 🎯****正文 📚****1. 问题概述 ❗…...
pycharm破解教程
下载pycharm https://www.jetbrains.com/pycharm/download/other.html 破解网站 https://hardbin.com/ipfs/bafybeih65no5dklpqfe346wyeiak6wzemv5d7z2ya7nssdgwdz4xrmdu6i/ 点击下载破解程序 安装pycharm 自己选择安装路径 安装完成后运行破解程序 等到Done图标出现 选择Ac…...
如何使用 ef core 的 code first(fluent api)模式实现自定义类型转换器?
如何使用 ef core 的 code first 模式实现自定义类型转换器 前言 1. 项目结构2. 实现步骤2.1 定义转换器2.1.1 DateTime 转换器2.1.2 JsonDocument 转换器 2.2 创建实体类并配置数据结构类型2.3 定义 Utility 工具类2.4 配置 DbContext2.4.1 使用 EF Core 配置 DbContext 的两种…...

MapSet之相关概念
系列文章: 1. 先导片--Map&Set之二叉搜索树 2. Map&Set之相关概念 目录 1.搜索 1.1 概念和场景 1.2 模型 2.Map的使用 2.1 关于Map的说明 2.2 关于Map.Entry的说明 2.3 Map的常用方法说明 3.Set的说明 3.1关于Set说明 3.2 常见方法说明 1.搜…...

【大数据】浅谈Pyecharts:数据可视化的强大工具
文章目录 一、引言二、Pyecharts是什么三、Pyecharts的发展历程四、如何使用Pyecharts1. 安装Pyecharts2. 创建图表(1)导入Pyecharts模块:(2)创建图表实例:(3)添加数据:&…...
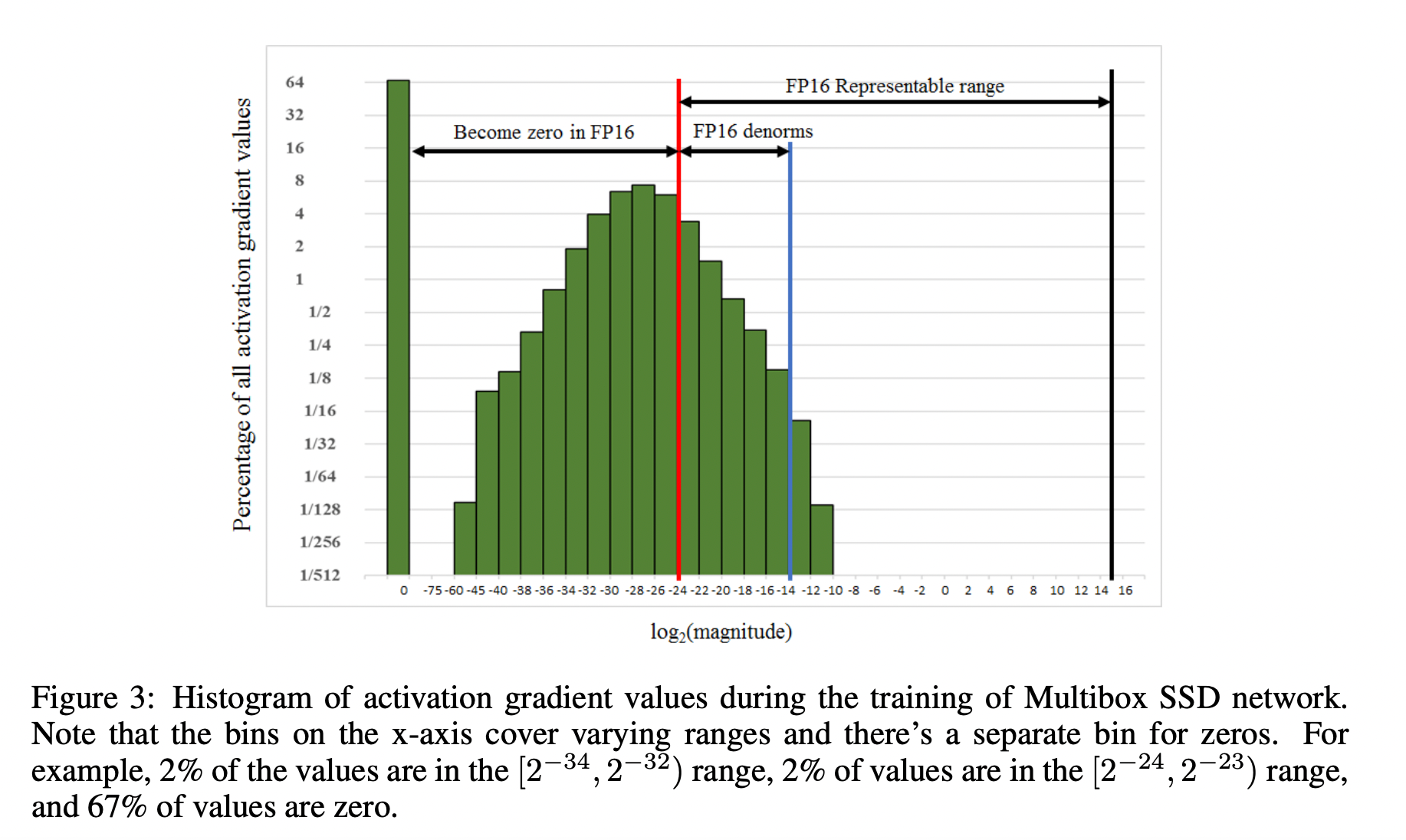
[深度学习][LLM]:浮点数怎么表示,什么是混合精度训练?
混合精度训练 混合精度训练1. 浮点表示法:[IEEE](https://zh.wikipedia.org/wiki/电气电子工程师协会)二进制浮点数算术标准(IEEE 754)1.1 浮点数剖析1.2 举例说明例子 1:例子 2: 1.3 浮点数比较1.4 浮点数的舍入 2. 混合精度训练2.1 为什么需…...

openssl双向认证自签名证书生成
编写配置文件openssl.cnf [ req ] distinguished_name req_distinguished_name req_extensions req_ext[ req_distinguished_name ] countryName Country Name (2 letter code) countryName_default US stateOrProvinceName State or Province Name…...

如何使用 Python 读取 Excel 文件:从零开始的超详细教程
“日出东海落西山 愁也一天 喜也一天 遇事不钻牛角尖” 文章目录 前言文章有误敬请斧正 不胜感恩!||Day03为什么要用 Python 读取 Excel 文件?准备工作:安装所需工具安装 Python安装 Pandas安装 openpyxl 使用 Pandas 读取 Excel 文件什么是 …...

仕考网:公务员笔试和面试哪个难?
公务员笔试和面试哪个难?二者之间考察的方向不同,难度也是不同的。 笔试部分因其广泛的知识点和有限的考试时间显得难度更高一些,在笔试环节中,考生需在有限的时间内应对各种问题,而且同时还要面对激烈的竞争,在众多…...
:时间优化)
C++知识点总结(55):时间优化
时间优化 一、调试方法1. 输出调试2. 构造样例 二、时间优化1. 前缀和1.1 概念1.2 例题Ⅰ 区间最多数码Ⅱ 双字母字符串Ⅲ Wandering...Ⅳ 数对数目 2. 排序例题选择排序过程 一、调试方法 1. 输出调试 cout 是一个强大的调试工具,可以帮助我们查看程序的状态和变…...
)
GitHub每日最火火火项目(9.7)
项目名称:polarsource / polar 项目介绍:polar 是一个开源的项目,它是 Lemon Squeezy 的替代方案,具有更优惠的价格。该项目旨在让开发者能够凭借自己的热情进行编码并获得报酬。通过使用 polar,开发者可以更轻松地实现…...

11Python的Pandas:可视化
Pandas本身并没有直接的可视化功能,但它与其他Python库(如Matplotlib和Seaborn)无缝集成,允许你快速创建各种图表和可视化。这里是一些使用Pandas数据进行可视化的常见方法: 1. 使用Matplotlib Pandas中的plot()方法…...

【周易哲学】生辰八字入门讲解(二)
😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本文讲解【周易哲学】生辰八字入门讲解,期待与你一同探索、学习、进步,一起卷起来叭! 目录 十神十神判断十神类象十神与五行案例 地支藏干藏…...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...
)
大佬推荐的网络安全学习路线(从基础到高级,超级详细)
大佬推荐的网络安全学习路线(从基础到高级,超级详细) 说起网络安全,你可能会担心它是一个过时的行业。有人说,网络安全快卷死了,你既要攻又要防,并且随着技术的发展,你还要不断地学…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

同步带装配工艺要点与损伤防控策略
一、引言在工业精密传动系统中,盖茨同步带凭借高精度、高效率、无滑差的优势,成为自动化设备、精密机床、输送产线的核心传动部件。多数企业在运维中,普遍将同步带异常磨损、断齿、断带等故障归咎于工况恶劣或产品质量问题,却忽略…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

真可用!美团数字人模型开源,MV、电商等统统拿下
美团开源的数字人视频生成框架 LongCat-Video-Avatar 刚刚更新到 1.5 版本。是真能用。这版更新把音频编码器换了,推理步数砍到8步,在770人、13240条主观评分的大规模评测里,雷达图面积全面领先。音频编码器换血,8步出图LongCat-V…...