SimHash算法详解与应用
1. 简介
在当今信息爆炸的时代,如何有效地管理和处理海量的文本数据,尤其是去除重复内容,是一项重要的任务。SimHash 是一种巧妙的哈希算法,它不仅能快速生成文本的哈希值,还能在不同文本之间生成相似的哈希值,这使得它成为大规模文本去重和相似性检测的利器。本文将深入探讨SimHash的原理、计算步骤,并通过实际案例展示如何在大数据处理中利用SimHash实现高效的文本去重和相似性检测。
2. SimHash的原理
SimHash的核心思想是将文本的特征映射为一个固定长度的二进制哈希值,并且保证相似的文本生成相似的哈希值。为了达到这个目标,SimHash依赖于以下几个关键步骤:
- 文本预处理:对输入文本进行分词处理,去除停用词(如“的”、“是”等),并提取出具有代表性的关键词。
- 特征权重计算:为每个关键词分配一个权重,通常使用TF-IDF(词频-逆文档频率)算法来衡量关键词的重要性。
- 生成哈希向量:对每个关键词计算哈希值,并根据关键词的权重对哈希值的每一位进行加权处理。
- 叠加生成最终哈希值:将所有关键词的加权哈希值进行叠加,根据每个位的正负决定最终哈希值的位值。
通过上述过程,SimHash可以生成一个64位或128位的二进制哈希值,这个值不仅能代表文本内容,还能用于快速比较文本的相似性。
3. SimHash的计算步骤
为了更直观地理解SimHash的计算过程,我们可以通过以下Mermaid流程图来展示:
4. SimHash的应用场景
SimHash在实际应用中表现出色,尤其适合处理以下场景:
-
文本去重:在新闻聚合或网页爬虫系统中,经常会遇到内容重复的文章或页面。通过计算每篇文章的SimHash值,可以快速识别并删除重复的内容,极大地提高了数据处理的效率。
-
相似文档查找:在文档管理系统中,用户可能需要查找与某篇文档内容相似的其他文档。SimHash可以帮助快速定位这些相似文档,减少手动查找的时间。
-
网页去重:在搜索引擎中,SimHash可以用来去除内容相似的网页,确保用户获得多样化的搜索结果。这在优化搜索引擎的性能和用户体验方面起着重要作用。
5. SimHash的优缺点
优点
-
计算速度快:SimHash算法非常高效,可以快速生成文本的哈希值。这使得它特别适用于实时性要求高的应用场景,如搜索引擎和实时数据处理系统。
-
空间效率高:SimHash生成的哈希值通常较短,占用的存储空间小。因此,在需要处理大规模数据的系统中,SimHash是一个非常经济的选择。
缺点
-
精度问题:SimHash在某些情况下可能不够精确,特别是在处理特征词较少或权重相近的文本时。这可能导致不同文本生成相似的哈希值,从而降低去重或相似性检测的效果。
-
碰撞问题:尽管SimHash设计用于减少碰撞,但在大规模数据集上,仍然可能出现不同文本生成相同哈希值的情况。这可能会影响算法的准确性。
6. SimHash与其他相似性检测算法的比较
在选择文本相似性检测算法时,SimHash和MinHash是两种常见的选择。两者各有优劣,适用于不同的应用场景:
| 比较项 | SimHash | MinHash |
|---|---|---|
| 计算速度 | 快 | 较快 |
| 空间效率 | 高 | 较高 |
| 精度 | 适中 | 高 |
| 应用场景 | 文本去重、网页去重、相似性检测 | 文档相似性检测、集合相似性 |
-
SimHash:适合大规模文本去重和网页去重,尤其是在需要快速处理大规模数据时表现出色。
-
MinHash:在精度要求较高的场景中,如文档相似性检测,MinHash可能更为合适。
7. Golang代码示例
下面是一个使用Golang实现SimHash的代码示例,代码中包含中文注释,方便理解每个步骤的具体操作:
package mainimport ("crypto/md5""encoding/hex""fmt""strings"
)// 计算字符串的MD5哈希值
func md5Hash(s string) string {hash := md5.New()hash.Write([]byte(s))return hex.EncodeToString(hash.Sum(nil))
}// 计算文本的SimHash值
func computeSimhash(text string) uint64 {// 将文本按空格分割为词汇words := strings.Fields(text)hashBits := make([]int, 64) // 使用64位的SimHash// 遍历每个词汇for _, word := range words {// 计算词汇的MD5哈希值,并转换为64位的整数hashValue := md5Hash(word)hashInt, _ := hex.DecodeString(hashValue[:16])var hash64 uint64for _, b := range hashInt {hash64 = (hash64 << 8) | uint64(b)}// 对哈希值的每一位进行处理for i := 0; i < 64; i++ {bit := (hash64 >> i) & 1if bit == 1 {hashBits[i] += 1} else {hashBits[i] -= 1}}}// 生成最终的SimHash值var simhash uint64for i := 0; i < 64; i++ {if hashBits[i] > 0 {simhash |= (1 << i)}}return simhash
}func main() {// 示例文本1text1 := "这是一个用于计算SimHash的示例文本"// 示例文本2text2 := "这是一个不同的文本,用于SimHash计算"// 计算两个文本的SimHash值hash1 := computeSimhash(text1)hash2 := computeSimhash(text2)// 打印SimHash值fmt.Printf("文本1的SimHash值: %x\n", hash1)fmt.Printf("文本2的SimHash值: %x\n", hash2)// 比较两个文本的SimHash值,计算汉明距离hammingDistance := 0for i := 0; i < 64; i++ {if (hash1>>i)&1 != (hash2>>i)&1 {hammingDistance++}}fmt.Printf("两个文本的汉明距离: %d\n", hammingDistance)
}
代码说明:
-
MD5哈希函数:
md5Hash函数用于计算每个词汇的MD5哈希值,并将其转换为一个16字节的字符串。我们只使用前64位(8字节)来生成最终的SimHash值。这种做法简单而高效,适合在大规模文本处理中使用。 -
SimHash计算函数:
computeSimhash函数通过对每个词汇的哈希值进行加权叠加,生成64位的SimHash值。加权的方式很简单:如果某一位是1,则加1;如果是0,则减1。最终,生成的SimHash值由各个位的叠加结果决定,这保证了相似的文本产生相似的哈希值。 -
汉明距离计算:在
main函数中,计算两个文本的SimHash值并打印出来,同时计算两个SimHash值的汉明距离。汉明距离越小,表示两个文本越相似。通过这种方式,我们可以快速
判断两个文本的相似度。
示例输出:
运行此代码后,你可能会得到类似以下的输出结果:
文本1的SimHash值: 8bff35d6ec0a8f76
文本2的SimHash值: 8bff75d6ec1b8f76
两个文本的汉明距离: 4
在这个示例中,两个文本的汉明距离为4,表明它们是相似的文本。你可以根据需要调整代码和示例文本,进一步测试和扩展SimHash的应用。
8. 实战案例
假设你正在构建一个大型新闻聚合平台,每天需要处理数百万篇文章。为了确保用户看到多样化的内容,你需要去除那些内容重复或高度相似的文章。通过计算每篇文章的SimHash值,并将其与数据库中现有文章的SimHash值进行比较,你可以高效地识别并去除重复内容。这种方法不仅节省了存储空间,还提高了系统的响应速度,确保用户获得最佳体验。
9. 总结
SimHash是一种简单而高效的相似性检测算法,特别适合处理大规模数据集。在需要快速处理大量文本的场景中,如搜索引擎、新闻聚合平台和文档管理系统,SimHash凭借其计算速度快、空间效率高的特点,成为了一种不可或缺的工具。尽管SimHash在精度上可能不如一些其他算法,但它在实际应用中所表现出的高效性和实用性,使得它在很多场景中都有着广泛的应用前景。
10. 参考文献
- Charikar, M. S. (2002). Similarity Estimation Techniques from Rounding Algorithms. In Proceedings of the thirty-fourth annual ACM symposium on Theory of computing (STOC '02).
- Wikipedia - SimHash: https://en.wikipedia.org/wiki/SimHash
- “Introduction to Information Retrieval” by Manning, Raghavan, and Schütze.
相关文章:

SimHash算法详解与应用
1. 简介 在当今信息爆炸的时代,如何有效地管理和处理海量的文本数据,尤其是去除重复内容,是一项重要的任务。SimHash 是一种巧妙的哈希算法,它不仅能快速生成文本的哈希值,还能在不同文本之间生成相似的哈希值&#x…...

RasberryPi 3B树莓派基本配置
RaspberryPi 3B树莓派基本配置 文章目录 RaspberryPi 3B树莓派基本配置一、准备工作1.1 硬件准备:1.1.1 树莓派和电源适配器:1.1.2 USB转TTL模块:1.1.3 读卡器和TF卡: 1.2 软件准备:1.2.1 下载 Raspberry Pi OS&#x…...
Docker编译环境的使用(ubuntu)
目录 Ubuntu安装docker 重启docker 拉取镜像 进入docker安装软件 提交docker 添加用户到docker组 进入docker 添加build用户 停止容器 保存docker镜像 load镜像 删除容器 Ubuntu安装docker sudo apt install docker.io 国内可用的源 Welcome to nginx! (tence…...

认知杂谈53
今天分享 有人说的一段争议性的话 I I 1.自助者天助 首先呢,咱得好好琢磨琢磨“自助者天助”这句话。这话说起来好像有点高深莫测的感觉,其实啊,道理特别简单。 就是说要是你自己都不乐意努力,那老天爷也不会平白无故地来帮你…...

量子计算信息安全威胁与应对策略分析
作者简介 赖俊森 中国信息通信研究院技术与标准研究所光网络技术与应用研究部主任工程师,正高级工程师,主要研究方向为量子信息、量子通信、量子计算等。 赵文玉 中国信息通信研究院技术与标准研究所副所长,正高级工程师,主要…...
如何使用RMAN恢复数据库?)
Oracle(112)如何使用RMAN恢复数据库?
使用 RMAN(Recovery Manager)恢复 Oracle 数据库是确保数据在灾难情况下能够得到恢复的关键步骤。以下是详细的指导和代码示例,展示如何使用 RMAN 进行数据库恢复。 1. 准备工作 在开始恢复之前,需要确保以下几点: …...

I2C通信协议
简介 I2C(Inter IC Bus)是由Philips公司开发的一种通用数据总线,由两根通信线:SCL(Serial Clock)和SDA(Serial Data)组成。是一种同步、半双工带数据应答的通信协议,支持…...

使用Python实现智能信用评分系统
1. 项目简介 本教程将带你一步步实现一个智能信用评分系统。我们将使用Python和一些常用的深度学习库,如TensorFlow和Keras。最终,我们将实现一个可以预测信用评分的模型。2. 环境准备 首先,你需要安装以下库: TensorFlowKeraspandasnumpyscikit-learn你可以使用以下命令…...

RocketMQ之发送消息源码分析
RocketMQ之send()源码分析 一、代码序列图 二、关键步骤分析 1、向namesrv拉取队列信息 2、选择目标队列 3、向broker发送消息 三、代码学习 1、代码结构 (设计模式) 2、工具类和方法...
使用宝塔面板安装mrdoc
使用宝塔面板安装mrdoc 1、所需环境2、ubuntu系统安装3、宝塔面板安装4、NginxPHPMySQL安装5、python项目管理器安装6、 python版本安装7、mrdoc的部署7.1、下载项目源码7.2、新建python管理器项目 8、使用MySQL作为默认数据库8.1、安装mysqlclient插件8.2、配置数据库连接信息…...

C++操作符重载实例
C操作符重载实例,我们把坐标值CVector的加法进行重载,计算c3c1c2时,也就是计算x3x1x2,y3y1y2,以下是C代码: #include <iostream> using namespace std;class CVector{public:int x,y;CVector(){} ; …...

Linux高效进程控制的实战技巧
Linux高效进程控制的实战技巧 Linux是一种开源的Unix-like操作系统内核,由林纳斯托瓦兹(Linus Torvalds)于1991年首次发布。Linux以其稳定性、安全性和灵活性而著称,广泛应用于服务器、桌面、嵌入式系统等多个领域。在Linux系统编…...

使用条件变量实现线程同步:C++实战指南
使用条件变量实现线程同步:C实战指南 在多线程编程中,线程同步是确保程序正确性和稳定性的关键。条件变量(condition variable)是一种强大的同步原语,用于在线程之间进行协调,避免数据竞争和死锁。本文将详…...

Spark2.x 入门: KMeans 聚类算法
一 KMeans简介 KMeans 是一个迭代求解的聚类算法,其属于 划分(Partitioning) 型的聚类方法,即首先创建K个划分,然后迭代地将样本从一个划分转移到另一个划分来改善最终聚类的质量。 ML包下的KMeans方法位于org.apach…...

如何快速练习键盘盲打
盲打是指在不看键盘的情况下进行打字,这样可以显著提高打字速度和效率。以下是一些练习盲打的方法: 熟悉键盘布局:首先,你需要熟悉键盘上的字母和符号的位置。可以通过键盘图或者键盘贴纸来帮助记忆。 使用在线打字练习工具&…...

Flask中实现WebSocket需要什么组件
在Flask中实现WebSocket功能,通常不会直接使用Flask本身,因为Flask是一个轻量级的Web框架,主要设计用于处理HTTP请求。然而,你可以通过集成一些第三方库来在Flask应用中支持WebSocket。WebSocket是一种在单个TCP连接上进行全双工通…...

java8 Stream流详解
前言 Java 8引入了一种新的处理集合的方式——Stream API。它提供了一种高级迭代方式,支持函数式编程风格,使得集合操作更加简洁、清晰。本文将详细介绍Java 8 Stream API的核心概念、操作和使用技巧。 Stream API 简介 Stream API是Java 8中的一大亮…...
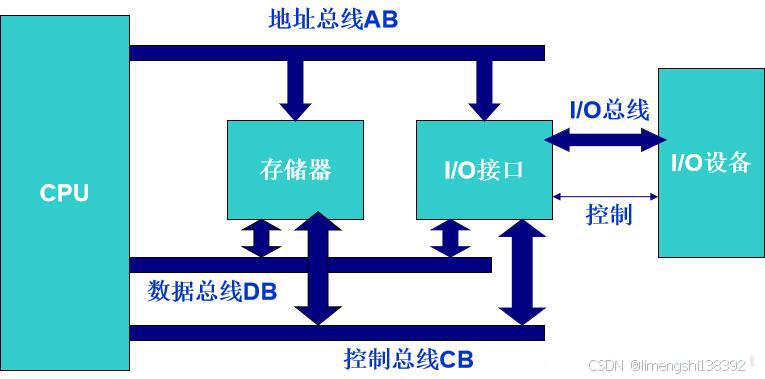
通信工程学习:什么是AB地址总线、DB数据总线、CD控制总线
AB地址总线、DB数据总线、CD控制总线 在计算机体系结构中,总线(Bus)是一种用于在计算机内部各个组件之间传输信息的物理通道。其中,AB地址总线、DB数据总线和CD控制总线是计算机总线系统中非常重要的三个组成部分,它们…...
(更新中……))
CP AUTOSAR标准之EthernetInterface(AUTOSAR_SWS_EthernetInterface)(更新中……)
1 简介和功能概述 该规范指定了AUTOSAR基础软件模块以太网接口的功能、API和配置。 在AUTOSAR分层软件架构[1]中,以太网接口属于ECU抽象层,或者更准确地说,属于通信硬件抽象。 这表明了以太网接口的主要任务: 为上层提供独立于硬件的以太网通信系统接口,该系统…...

Windows系统离线安装使用pm2 管理进程
目录 1. 安装 Node.js 和 npm 2. 创建一个项目目录 3. 初始化 npm 项目 4. 下载 pm2 及其所有依赖 5. 打包 pm2 及其依赖 6. 将打包文件传输到内网服务器 7. 在内网服务器上解压并安装 8. 使用 pm2 总结 在联网的机器上,使用 npm(Node.js 包管理…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验
艾尔登法环帧率解锁终极指南:告别卡顿,畅享丝滑游戏体验 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_m…...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

Python 3.7 + XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程
Python 3.7 XGBoost 多分类实战:从数据清洗到SHAP模型解释的保姆级教程在机器学习领域,XGBoost因其出色的性能和可解释性成为众多数据科学家的首选工具。本文将带您完整走过多分类任务的全流程,从原始数据到可解释的预测模型,每个…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

具身智能:面向新兴交叉学科建设的思考与建议 2026
这份由 CCF YOCSEF 长三角五地学术委员会 2026 年 5 月发布的白皮书,聚焦具身智能作为新兴交叉学科的建设,明确其并非 AI 与机器人学的简单拼接,而是围绕物理交互中的智能行为形成的新问题域,提出 “三大基本问题 一个应用需求”…...