Java8特性:分组、提取字段、去重、过滤、差集、交集
总结下自己使用过的特性
- 将对象集合根据某个字段分组
//根据id分组
Map<String, List<Bean>> newMap = successCf.stream().collect(Collectors.groupingBy(b -> b.getId().trim()));
- 获取对象集合里面的某个字段的集合
List<Bean> list = new ArrayList<>();
List<String> strList = list.stream().map(Bean::getId).collect(Collectors.toList());
- 將集合字段转换成字符串
List<Long> longList = new ArrayList<>();
String s = longList.stream().map(Object :: toString).collect(Collectors.joining(","));
- 提取字段去重distinct
List<String> strList = list.stream().map(Bean::getId).distinct().collect(Collectors.toList());
- 提取字段去重set
Set<String> idSet = list.stream().map(Bean :: getId).collect(Collectors.toSet());
- 过滤filter
Map<String, Integer> map = new HashMap<>();
//先分组
Map<String, List<Bean>> maps = list.stream().collect(Collectors.groupingBy(Bean::getname));
//循环获取到大小
houseIdMaps.forEach((s, names) -> {//房屋地址对应的条数map.put(s, names.size());
});
//过滤
//过滤重复的数据 >1
Map<String, Integer> mapRepeat = map.entrySet().stream().filter(entry -> entry.getValue() > 1).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
//过滤未重复的数据 =1
Map<String, Integer> mapNoRepeat = map.entrySet().stream().filter(entry -> entry.getValue() == 1).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
- 过滤filter,equals
List<Bean> list1 = list.stream().filter(a -> a.getId().equals("1")).collect(Collectors.toList());
- 差集(基于java8新特性) 适用于大数据量
/*** 差集(基于java8新特性) 适用于大数据量* 求List1中有的但是List2中没有的元素*/public static List<String> subList(List<String> list1, List<String> list2) {Map<String, String> tempMap = list2.parallelStream().collect(Collectors.toMap(Function.identity(), Function.identity(), (oldData, newData) -> newData));return list1.parallelStream().filter(str-> !tempMap.containsKey(str)).collect(Collectors.toList());}
- 交集(基于java8新特性) 适用于大数据量
/*** 交集(基于java8新特性) 适用于大数据量* 求List1和List2中都有的元素*/public static List<String> intersectList(List<String> list1, List<String> list2){Map<String, String> tempMap = list2.parallelStream().collect(Collectors.toMap(Function.identity(), Function.identity(), (oldData, newData) -> newData));return list1.parallelStream().filter(str-> tempMap.containsKey(str)).collect(Collectors.toList());}
相关文章:

Java8特性:分组、提取字段、去重、过滤、差集、交集
总结下自己使用过的特性 将对象集合根据某个字段分组 //根据id分组 Map<String, List<Bean>> newMap successCf.stream().collect(Collectors.groupingBy(b -> b.getId().trim()));获取对象集合里面的某个字段的集合 List<Bean> list new ArrayList&l…...

Maven快速上手使用指南的笔记
Maven Mini Guides Configuring for Reproducible Builds 使用Maven实现重复构建。 检查当前使用的插件的版本。 mvn artifact:check-buildplan修改pom.xml,增加如下配置,显式指定project.build.outputTimestamp的取值: <properties>…...

MySQL面试题大全和详解,含SQL例子
若有不理解,可以问一下这几个免费的AI网站 https://ai-to.cn/chathttp://m6z.cn/6arKdNhttp://m6z.cn/6b1quhhttp://m6z.cn/6wVAQGhttp://m6z.cn/63vlPw 下面是一些常见的 MySQL 面试题及其解答,包含 SQL 示例。 1. 什么是 MySQL? 答&…...

java-redis-雪崩
Redis 雪崩问题 Redis雪崩 是指在 Redis 缓存系统中,当大量缓存同时失效时,所有请求直接打到数据库,导致数据库瞬间压力激增,甚至崩溃的现象。雪崩问题通常出现在高并发的系统中,因为缓存的失效导致后端数据库承受不了…...

如何在mac上玩使命召唤手游?苹果电脑好玩的第一人称射击游戏推荐
《使命召唤4:现代战争》(Call of Duty 4: Modern Warfare)是由Infinity Ward开发并于2007年发行的第一人称射击游戏。该游戏是《使命召唤》系列的第四部作品,是一款非常受欢迎的游戏之一,《使命召唤4:现代战…...

SimHash算法详解与应用
1. 简介 在当今信息爆炸的时代,如何有效地管理和处理海量的文本数据,尤其是去除重复内容,是一项重要的任务。SimHash 是一种巧妙的哈希算法,它不仅能快速生成文本的哈希值,还能在不同文本之间生成相似的哈希值&#x…...

RasberryPi 3B树莓派基本配置
RaspberryPi 3B树莓派基本配置 文章目录 RaspberryPi 3B树莓派基本配置一、准备工作1.1 硬件准备:1.1.1 树莓派和电源适配器:1.1.2 USB转TTL模块:1.1.3 读卡器和TF卡: 1.2 软件准备:1.2.1 下载 Raspberry Pi OS&#x…...
Docker编译环境的使用(ubuntu)
目录 Ubuntu安装docker 重启docker 拉取镜像 进入docker安装软件 提交docker 添加用户到docker组 进入docker 添加build用户 停止容器 保存docker镜像 load镜像 删除容器 Ubuntu安装docker sudo apt install docker.io 国内可用的源 Welcome to nginx! (tence…...

认知杂谈53
今天分享 有人说的一段争议性的话 I I 1.自助者天助 首先呢,咱得好好琢磨琢磨“自助者天助”这句话。这话说起来好像有点高深莫测的感觉,其实啊,道理特别简单。 就是说要是你自己都不乐意努力,那老天爷也不会平白无故地来帮你…...

量子计算信息安全威胁与应对策略分析
作者简介 赖俊森 中国信息通信研究院技术与标准研究所光网络技术与应用研究部主任工程师,正高级工程师,主要研究方向为量子信息、量子通信、量子计算等。 赵文玉 中国信息通信研究院技术与标准研究所副所长,正高级工程师,主要…...
如何使用RMAN恢复数据库?)
Oracle(112)如何使用RMAN恢复数据库?
使用 RMAN(Recovery Manager)恢复 Oracle 数据库是确保数据在灾难情况下能够得到恢复的关键步骤。以下是详细的指导和代码示例,展示如何使用 RMAN 进行数据库恢复。 1. 准备工作 在开始恢复之前,需要确保以下几点: …...

I2C通信协议
简介 I2C(Inter IC Bus)是由Philips公司开发的一种通用数据总线,由两根通信线:SCL(Serial Clock)和SDA(Serial Data)组成。是一种同步、半双工带数据应答的通信协议,支持…...

使用Python实现智能信用评分系统
1. 项目简介 本教程将带你一步步实现一个智能信用评分系统。我们将使用Python和一些常用的深度学习库,如TensorFlow和Keras。最终,我们将实现一个可以预测信用评分的模型。2. 环境准备 首先,你需要安装以下库: TensorFlowKeraspandasnumpyscikit-learn你可以使用以下命令…...

RocketMQ之发送消息源码分析
RocketMQ之send()源码分析 一、代码序列图 二、关键步骤分析 1、向namesrv拉取队列信息 2、选择目标队列 3、向broker发送消息 三、代码学习 1、代码结构 (设计模式) 2、工具类和方法...
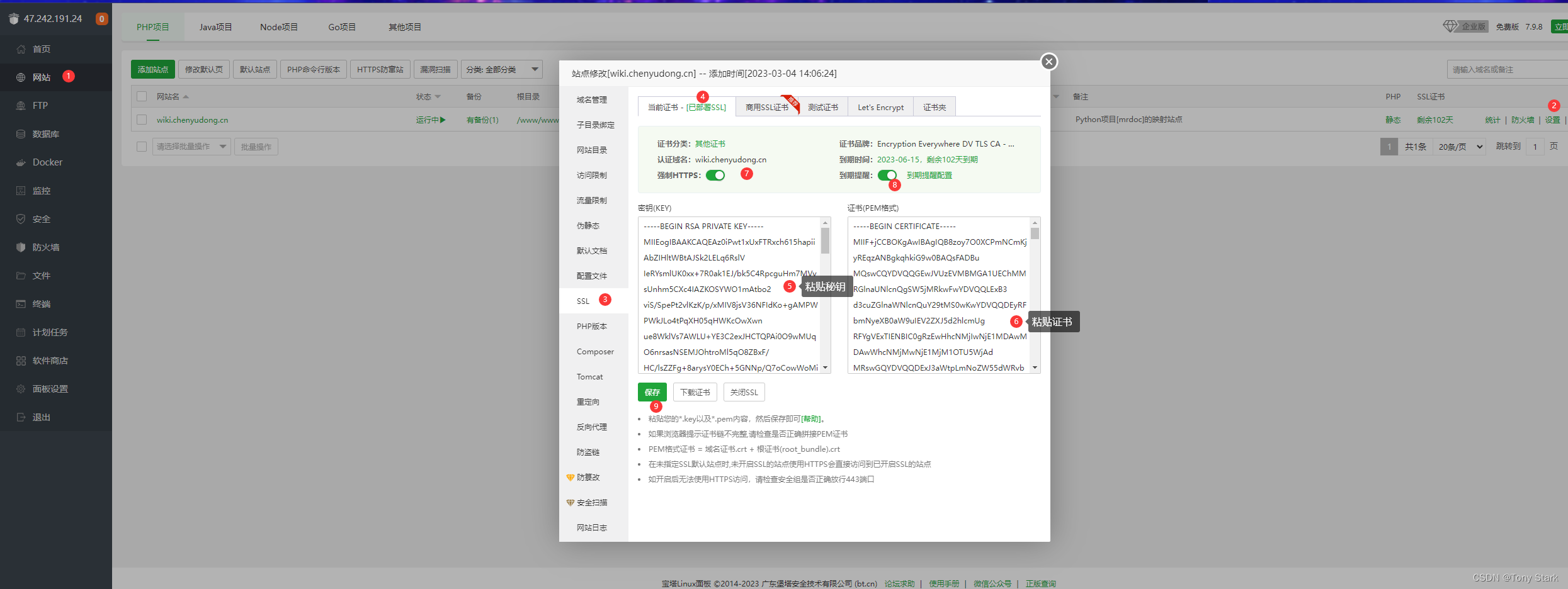
使用宝塔面板安装mrdoc
使用宝塔面板安装mrdoc 1、所需环境2、ubuntu系统安装3、宝塔面板安装4、NginxPHPMySQL安装5、python项目管理器安装6、 python版本安装7、mrdoc的部署7.1、下载项目源码7.2、新建python管理器项目 8、使用MySQL作为默认数据库8.1、安装mysqlclient插件8.2、配置数据库连接信息…...

C++操作符重载实例
C操作符重载实例,我们把坐标值CVector的加法进行重载,计算c3c1c2时,也就是计算x3x1x2,y3y1y2,以下是C代码: #include <iostream> using namespace std;class CVector{public:int x,y;CVector(){} ; …...

Linux高效进程控制的实战技巧
Linux高效进程控制的实战技巧 Linux是一种开源的Unix-like操作系统内核,由林纳斯托瓦兹(Linus Torvalds)于1991年首次发布。Linux以其稳定性、安全性和灵活性而著称,广泛应用于服务器、桌面、嵌入式系统等多个领域。在Linux系统编…...

使用条件变量实现线程同步:C++实战指南
使用条件变量实现线程同步:C实战指南 在多线程编程中,线程同步是确保程序正确性和稳定性的关键。条件变量(condition variable)是一种强大的同步原语,用于在线程之间进行协调,避免数据竞争和死锁。本文将详…...

Spark2.x 入门: KMeans 聚类算法
一 KMeans简介 KMeans 是一个迭代求解的聚类算法,其属于 划分(Partitioning) 型的聚类方法,即首先创建K个划分,然后迭代地将样本从一个划分转移到另一个划分来改善最终聚类的质量。 ML包下的KMeans方法位于org.apach…...

如何快速练习键盘盲打
盲打是指在不看键盘的情况下进行打字,这样可以显著提高打字速度和效率。以下是一些练习盲打的方法: 熟悉键盘布局:首先,你需要熟悉键盘上的字母和符号的位置。可以通过键盘图或者键盘贴纸来帮助记忆。 使用在线打字练习工具&…...

WarcraftHelper解决方案:魔兽争霸3跨系统优化指南
WarcraftHelper解决方案:魔兽争霸3跨系统优化指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸3作为经典的即时战略游戏&#…...

Ostrakon-VL像素终端实操:自定义扫描任务清单配置方法
Ostrakon-VL像素终端实操:自定义扫描任务清单配置方法 1. 像素特工终端介绍 Ostrakon-VL像素终端是一款专为零售与餐饮场景设计的智能扫描工具,采用独特的8-bit像素风格界面,将复杂的图像识别任务转化为直观有趣的"特工任务"。基…...

千问3.5-9B模型切换指南:OpenClaw多模型动态调用
千问3.5-9B模型切换指南:OpenClaw多模型动态调用 1. 为什么需要多模型动态调用 上周我尝试用OpenClaw自动整理电脑里积压的300多份PDF文档时,遇到了一个有趣的现象:处理简单文件重命名任务时,轻量级模型响应飞快;但遇…...

Wan2.2-I2V-A14B环境配置避坑指南:解决C盘空间不足与依赖冲突
Wan2.2-I2V-A14B环境配置避坑指南:解决C盘空间不足与依赖冲突 1. 引言 最近在Windows系统上配置Wan2.2-I2V-A14B环境时,我发现很多朋友都遇到了相同的问题:C盘空间莫名其妙被占满、各种依赖包冲突报错、CUDA版本不匹配等等。作为一个踩过所…...

OpenClaw+Qwen3-14b_int4_awq:3种降低token消耗的实战技巧
OpenClawQwen3-14b_int4_awq:3种降低token消耗的实战技巧 1. 为什么我们需要关注token消耗 第一次看到OpenClaw的token账单时,我差点从椅子上跳起来。一个简单的文件整理任务竟然消耗了接近5000个token,这还只是测试环境下的单次运行。当我…...

OpenClaw自动化视频处理:Qwen2.5-VL-7B分析关键帧生成视频摘要
OpenClaw自动化视频处理:Qwen2.5-VL-7B分析关键帧生成视频摘要 1. 为什么需要自动化视频摘要 作为一个经常需要处理大量视频素材的自媒体创作者,我长期被一个痛点困扰:如何快速了解长视频的核心内容。传统方法要么是手动拖动进度条随机查看…...

MySQL从节点上的服务崩了后如何做主从读写分离?
背景 我们的项目采用了读写分离的方案:查询和更新的业务走主库,统计相关的功能走从库,从而减少主库的压力。原理如下图所示: 读写分离的方案 如果从库崩了,实在无法访问了,就会把所有请求打到主库上。原理…...

根据给定文本内容,适合的标题可以是:“‘三泵排水电气控制系统及组态设计的梯形图、接线图原理图”...
自动排水控制设计3泵排水三泵排水电气控制系统排水组态 我们主要的后发送的产品有,带解释的梯形图接线图原理图图纸,io分配,组态画面每逢暴雨天,物业师傅盯着排水泵的手机都要刷出火星子——生怕哪台泵罢工,地下室直…...

精益生产线功能拆解:如何利用精益生产线解决多品种小批量生产难题
在当前的制造业环境中,订单碎片化已成为常态,精益生产线不再是一个可选的优化项,而是企业生存的必修课。面对多品种、小批量的市场需求,传统的大批量流水线往往显得笨重不堪,频繁换型导致的停机、在制品积压造成的资金…...
,仅开放72小时)
【限时解禁】Cuvil编译器v0.9.3内部架构设计图(含Python动态类型静态化映射表),仅开放72小时
第一章:Cuvil 编译器在 Python AI 推理中的应用Cuvil 是一款面向 AI 工作负载的轻量级领域专用编译器,专为优化 Python 生态中基于 PyTorch 和 ONNX 的模型推理而设计。它通过静态图重写、算子融合与硬件感知调度,在不修改用户代码的前提下&a…...