Linux基本功系列之sort命令实战

文章目录
- 前言
- 一. sort命令介绍
- 二. 语法格式及常用选项
- 三. 参考案例
- 3.1 按照文本默认排序
- 3.2 忽略相同的行
- 3.3 按数字大小进行排序
- 3.4 检查文件是否已经按照顺序排序
- 3.5 将第3列按照数字大小进行排序
- 3.6 将排序结果输出到文件
- 四. 探讨 -k的高级用法
- 总结
前言
大家好,又见面了,我是沐风晓月,本文是专栏【linux基本功-基础命令实战】的第43篇文章。
专栏地址:[linux基本功-基础命令专栏] , 此专栏是沐风晓月对Linux常用命令的汇总,希望能够加深自己的印象,以及帮助到其他的小伙伴😉😉。
如果文章有什么需要改进的地方还请大佬不吝赐教👏👏。
🏠个人主页:我是沐风晓月
🧑个人简介:大家好,我是沐风晓月,双一流院校计算机专业😉😉
💕 座右铭: 先努力成长自己,再帮助更多的人 ,一起加油进步🍺🍺🍺
💕欢迎大家:这里是CSDN,我总结知识的地方,喜欢的话请三连,有问题请私信😘
一. sort命令介绍
sort命令是一个排序命令,可以对文件进行排序,然后将排序结果标准输出。
sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
二. 语法格式及常用选项
依据惯例,我们还是先查看帮助,使用 sort --help
[root@mufenggrow ~]# sort --help
用法:sort [选项]... [文件]...或:sort [选项]... --files0-from=F
Write sorted concatenation of all FILE(s) to standard output.Mandatory arguments to long options are mandatory for short options too.
排序选项:-b, --ignore-leading-blanks 忽略前导的空白区域-d, --dictionary-order 只考虑空白区域和字母字符-f, --ignore-case 忽略字母大小写-g, --general-numeric-sort compare according to general numerical value-i, --ignore-nonprinting consider only printable characters-M, --month-sort compare (unknown) < 'JAN' < ... < 'DEC'-h, --human-numeric-sort 使用易读性数字(例如: 2K 1G)-n, --numeric-sort 根据字符串数值比较-R, --random-sort 根据随机hash 排序--random-source=文件 从指定文件中获得随机字节-r, --reverse 逆序输出排序结果--sort=WORD 按照WORD 指定的格式排序:一般数字-g,高可读性-h,月份-M,数字-n,随机-R,版本-V-V, --version-sort 在文本内进行自然版本排序其他选项:--batch-size=NMERGE 一次最多合并NMERGE 个输入;如果输入更多则使用临时文件-c, --check, --check=diagnose-first 检查输入是否已排序,若已有序则不进行操作-C, --check=quiet, --check=silent 类似-c,但不报告第一个无序行--compress-program=程序 使用指定程序压缩临时文件;使用该程序的-d 参数解压缩文件--debug 为用于排序的行添加注释,并将有可能有问题的用法输出到标准错误输出--files0-from=文件 从指定文件读取以NUL 终止的名称,如果该文件被指定为"-"则从标准输入读文件名-k, --key=KEYDEF sort via a key; KEYDEF gives location and type-m, --merge merge already sorted files; do not sort-o, --output=文件 将结果写入到文件而非标准输出-s, --stable 禁用last-resort 比较以稳定比较算法-S, --buffer-size=大小 指定主内存缓存大小-t, --field-separator=分隔符 使用指定的分隔符代替非空格到空格的转换-T, --temporary-directory=目录 使用指定目录而非$TMPDIR 或/tmp 作为临时目录,可用多个选项指定多个目录--parallel=N 将同时运行的排序数改变为N-u, --unique 配合-c,严格校验排序;不配合-c,则只输出一次排序结果-z, --zero-terminated 以0 字节而非新行作为行尾标志--help 显示此帮助信息并退出--version 显示版本信息并退出为了更直观一些,我们把常用的参数用表格来展示:
| 参数 | 描述 |
|---|---|
| GNU 参数说明 | |
| -c | 检查文件是否按照顺序进行排序 |
| -d | 排序时,处理英文字母,数字及空格字母外,忽略其他字符 |
| -f | 排序,将小写字母视为大写字母 |
| -M | 将前面的3个字母依照月份缩写进行排序 |
| -r | 以相反的顺序进行排序 |
| -n | 依照数值的大小进行排序- |
| -o | 排序后存入指定的文件 |
| -t | 指定一个用来区分键位置字符 |
| -k | 后面跟数字,指定按第几列进行排 |
有了具体的参数之后,我们再来看实战案例:
三. 参考案例
3.1 按照文本默认排序
此时,无需加任何参数,sort将文件/文本的每一行作为一个单位,相互比较.
比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
[root@mufenggrow ~]# sort /etc/passwd |head -5
abrt:x:173:173::/etc/abrt:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
avahi:x:70:70:Avahi mDNS/DNS-SD Stack:/var/run/avahi-daemon:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
chrony:x:993:988::/var/lib/chrony:/sbin/nologin从上面的代码可以看到: 按照首字符的ASCII码排序,
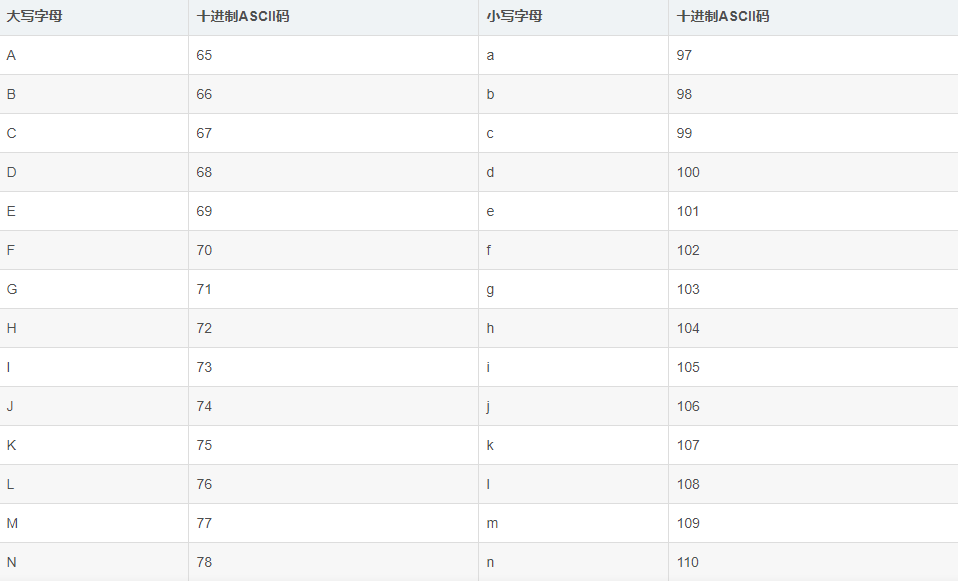
这里要理解什么是ASCII码:
在计算机中,所有的数据在存储和运算时都要使用二进制表示。而ASCII是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,它是现今最通用的单字节编码系统。
英文字母对应的ACSII码如下:
3.2 忽略相同的行
-u参数主要用来忽略相同的行
## 可以看到有相同的行
[root@mufeng-06 ~]# cat a.txt
tiger
deer
lion
elphant
monkey
bear
dog
pig
pig
## 使用-u参数后
[root@mufeng06 ~]# sort -u a.txt 删除重复的行,但是空行不会被删除bear
deer
dog
elphant
lion
monkey
pig
tiger
使用-u参数后,相同的行就没有了。
我们之前写过一个脚本统计在线的IP数有多少个,代码如下:
先写一个测试脚本:
[root@mufenggrow ~]# cat ping1.sh
#!/bin/bash
str="192.168.1."
for num in {1..10}
do
ip=${str}${num}
ping -c1 -w1 $ip &>/dev/nullif [ $? -eq 0 ];then
echo $ip >>/root/online.txtfi
done
# 统计在线IP的个数
online=`cat /root/online.txt|wc -l `
echo "在线ip总数为 $online"执行上面的脚本查看效果:
[root@mufenggrow ~]# ./ping1.sh
在线ip总数为 12
我们发现执行的结果为12个IP,这个结果是否准确? 我们查看文件内容:
[root@mufenggrow ~]# cat online.txt
192.168.1.1
192.168.1.2
192.168.1.4
192.168.1.10
192.168.1.1
192.168.1.2
192.168.1.4
192.168.1.10
192.168.1.1
192.168.1.2
192.168.1.4
192.168.1.10
通过查看文件,我们发现文件的内容为中有很多重复的IP,这时候我们就可以使用sort -u 参数:
[root@mufenggrow ~]# sort -u online.txt |wc -l
4
使用这个命令之后,是不是就感觉IP少了很多,去掉了重复的,结果就对了。
3.3 按数字大小进行排序
此处使用-n 参数
当你使用sort命令对数字进行排序,但是又不用-n参数的时候,就会发现是乱序的:
[root@mufenggrow ~]# cat a.txt
1
2
333
111
110
112
223
229
91
54
[root@mufenggrow ~]# sort a.txt
1
110
111
112
2
223
229
333
54
91是不是从排序里感觉112 反而不如2大了?
加上-n参数才是正常的,我们来看下代码:
[root@mufenggrow ~]# sort -n a.txt
1
2
54
91
110
111
112
223
229
333如果向对数字进行倒序排列,需要加-r 参数, 当然这里要对数字排序,所以-n还是少不了的。
[root@mufenggrow ~]# sort -nr a.txt
333
229
223
112
111
110
91
54
2
1
3.4 检查文件是否已经按照顺序排序
-c参数,可以检查文件是否按照顺序排序
[root@mufenggrow ~]# sort -c a.txt
sort:a.txt:4:无序: 111
可以看到无序,表示没有按照顺序排序,这里需要主要,当我们对一个文件排序后,虽然会再屏幕上显示,但并不会修改源文件。
3.5 将第3列按照数字大小进行排序
这里用到以下几个参数:
-n是按照数字大小排序
-r是以相反顺序
-k是指定需要排序的栏位
-t指定栏位分隔符为冒号
我们对/etc/passwd 以冒号为分隔符,把第三列进行大小排序
[root@mufenggrow ~]# sort -t: -nk 3 /etc/passwd |head -5
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
如果我们要将上面的排序变成从大到小排列:
[root@mufenggrow ~]# sort -t: -nrk 3 /etc/passwd |head -5
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
laoxin:x:1000:1000:laoxin:/home/laoxin:/bin/bash
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
colord:x:998:997:User for colord:/var/lib/colord:/sbin/nologin
libstoragemgmt:x:997:995:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin注意:
-t后面可以跟分隔符,如果分割符为: 比如容易操作,但如果分隔符为空格的时候,需要确认空格是否是规则的,比如有的是多个空格,有的是一个空格,就很难达到预期的效果
root@mufenggrow ~]# sort -t " " -k 3 b.txt
9 9 1 0
1 2 3 4
2 2 4 5
5 6 7 8
[root@mufenggrow ~]# cat c.txt
1 2 33 44
2 2 3 4
7 9 11 43 4 6 7[root@mufenggrow ~]# sort -t " " -k 4 c.txt1 2 33 44
2 2 3 4
3 4 6 7
7 9 11 4最后一个的排序按照第四列,就没成功,所以还是那句话,如果空格比较杂乱的时候,不建议使用空格进行排序,如果非要用空格,可以先做预处理。
3.6 将排序结果输出到文件
-o参数可以将结果输出到文件,比如我们把3.5的排序输出到a.txt中
root@mufenggrow ~]# sort -t: -nrk 3 /etc/passwd -o a.txt四. 探讨 -k的高级用法
案例一: 使用-u 参数去重的时候,希望参照第一个域进行去重
我们知道-u参数是去重,但是必须两行完全重复才可以,而有时候我们根据一部分来去重。
如果我们只用-u去重:
[root@mufenggrow ~]# sort -u d.txt
lisi: 34
mufeng: 100
mufeng:60
mufeng:99
wangwu: 66
zhangsan: 59
可以看到有三个mufeng
结合 -k试一下:
[root@mufenggrow ~]# sort -t: -u -k 1,1 d.txt lisi: 34
mufeng: 100
wangwu: 66
zhangsan: 59
[root@mufenggrow ~]# 可以看到mufeng下面的两个mufeng被去掉了。
这里的 -k 1,1 我们写作 -k start,end , 如果start 第一个域的第一个字符~end 最后一个域的最后一个字符,如果完全相同,仅保留第一次出现的行,后面出现的相同行都会被消除。
总结
sort命令在日常工作中,应用的比较广泛,一定要认真学习,记熟记牢常用参数。
💕💕💕 好啦,这就是今天要分享给大家的全部内容了,我们下期再见!✨ ✨ ✨
🍻🍻🍻如果你喜欢的话,就不要吝惜你的一键三连了~


相关文章:
Linux基本功系列之sort命令实战
文章目录前言一. sort命令介绍二. 语法格式及常用选项三. 参考案例3.1 按照文本默认排序3.2 忽略相同的行3.3 按数字大小进行排序3.4 检查文件是否已经按照顺序排序3.5 将第3列按照数字大小进行排序3.6 将排序结果输出到文件四. 探讨 -k的高级用法总结前言 大家好,…...
【笔记】移动端自动化:adb调试工具+appium+UIAutomatorViewer
学习源: https://www.bilibili.com/video/BV11p4y197HQ https://blog.csdn.net/weixin_47498728/category_11818905.html 一、移动端测试环境搭建 学习目标 1.能够搭建java 环境 2.能够搭建android 环境 (一)整体思路 我们的目标是Andr…...
面试复习题--性能检测原理
1、布局性能检测 Systrace,内存优化工具中也用到了 Systrace,这里关注 Systrace 中的 Frames 页面,正常情况下圆点为绿色,当出现黄色或者红色的圆点时,表现出现了丢帧。 Layout Inspector,是 AndroidStudio 自带工具…...

@LoadBalanced 和 @RefreshScope 同时使用,负载均衡失效分析
背景 最近引入了 Nacos Config 配置管理能力,说起来用法很简单,还是踩了三个坑。 Nacos Config 的 nacos 的帐号密码加密配置后,怎么解密而且在 NacosConfigBootstrapConfiguration 真正注入 Nacos Config 注入之前,而且不能触发…...

2023年个人计划
2023年个人计划 可能是最近太清闲,感觉生活很无聊,就胡乱做下新年的规划吧,扰乱下烦闷的心 1 二宝健健康康,活泼可爱 目前老婆已经怀孕5周左右了,二宝将在进行年中降生,希望老婆少受点罪,二宝…...

加拿大访问学者家属如何办理探亲签证?
由于大多数访问学者的访学期限都为一年,家人来访不仅可以缓解访学的寂寞生活,而且也是家人到加拿大体验国外风情的好机会。家属在国内申请赴加签证时,如果材料齐全,一般上午递交了申请,下午就可以拿到签证。以下是家人…...
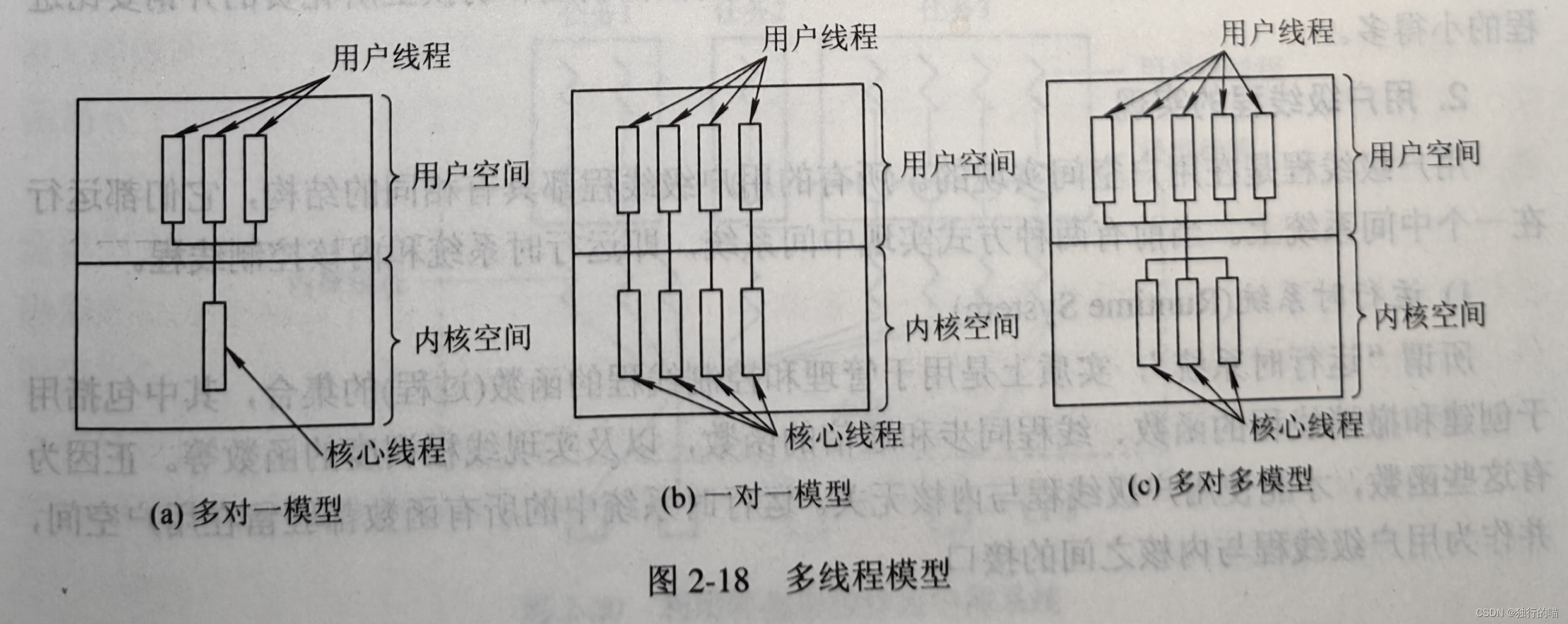
操作系统基础---多线程
文章目录操作系统基础---多线程1.为何引入线程程序并发的时空开销线程的设计思路线程的状态和线程控制块TCB2.线程与进程的比较3.线程的实现⭐1.内核支持线程KST2.用户级线程3.组合方式操作系统基础—多线程 1.为何引入线程 利用传统的进程概念和设计方法已经难以设计出适合于…...
等级考试试卷(六级)解析)
2022-12-10青少年软件编程(C语言)等级考试试卷(六级)解析
2022-12-10青少年软件编程(C语言)等级考试试卷(六级)解析T1、区间合并 给定 n 个闭区间 [ai; bi],其中i1,2,...,n。任意两个相邻或相交的闭区间可以合并为一个闭区间。例如,[1;2] 和 [2;3] 可以合并为 [1;3…...

太酷了,用Python实现一个动态条形图!
大家好,我是小F~说起动态条形图,小F之前推荐过两个Python库,比如「Bar Chart Race」、「Pandas_Alive」,都可以实现。今天就给大家再介绍一个新的Python库「pynimate」,一样可以制作动态条形图,…...
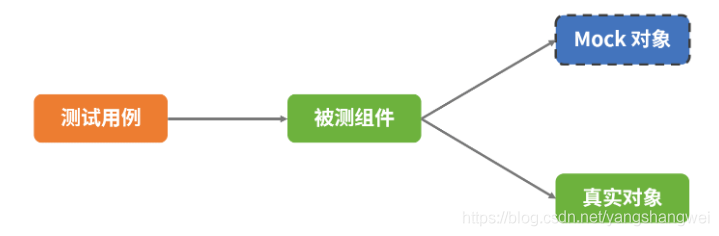
单元测试junit+mock
单元测试 是什么? 单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。至于“单元”的大小或范围,并没有一个明确的标准,“单元”可以是一个方法、类、功能模块或者子系统。 单元测试通…...
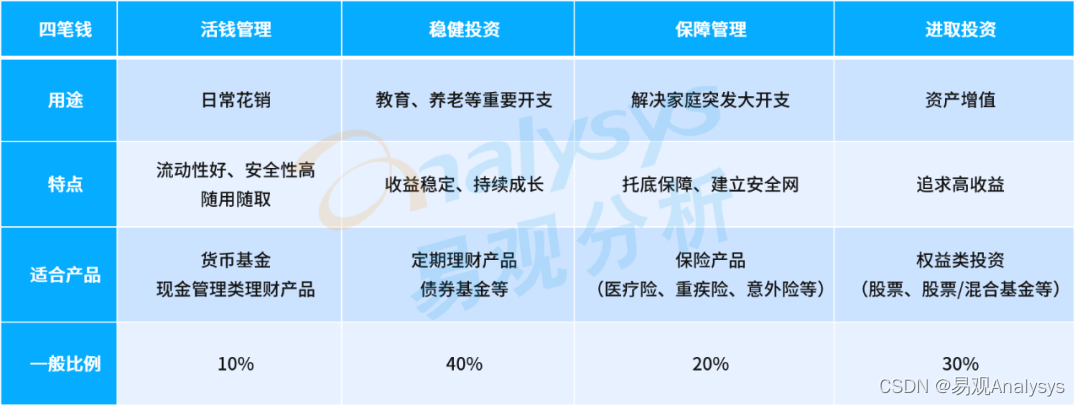
2022Q4手机银行新版本聚焦提升客群专属、财富开放平台、智能化能力,活跃用户规模6.91亿人
易观:2022年第4季度,手机银行APP迭代升级加快,手机银行作为零售银行服务及经营的主阵地,与零售银行业务发展的联系日益紧密。迭代升级一方面可以顺应零售银行发展战略及方向,对手机银行业务布局进行针对性调整优化&…...
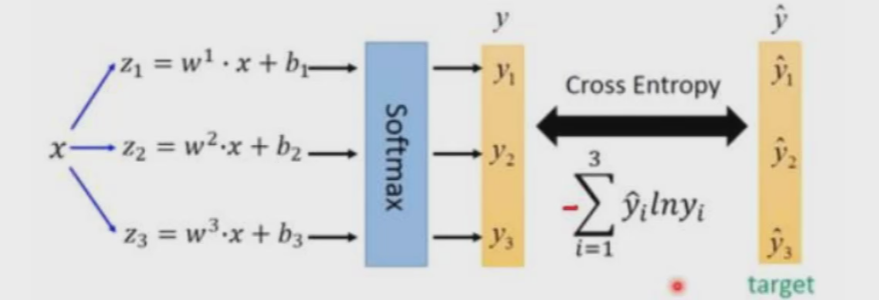
YOLO-V1~V3经典物体检测算法介绍
大名鼎鼎的YOLO物体检测算法如今已经出现了V8版本,我们先来了解一下它前几代版本都做了什么吧。本篇文章介绍v1-v3,后续会继续更新。一、节深度学习经典检测方法概述1.1 检测任务中阶段的意义我们所学的深度学习经典检测方法 ,有些是单阶段的…...
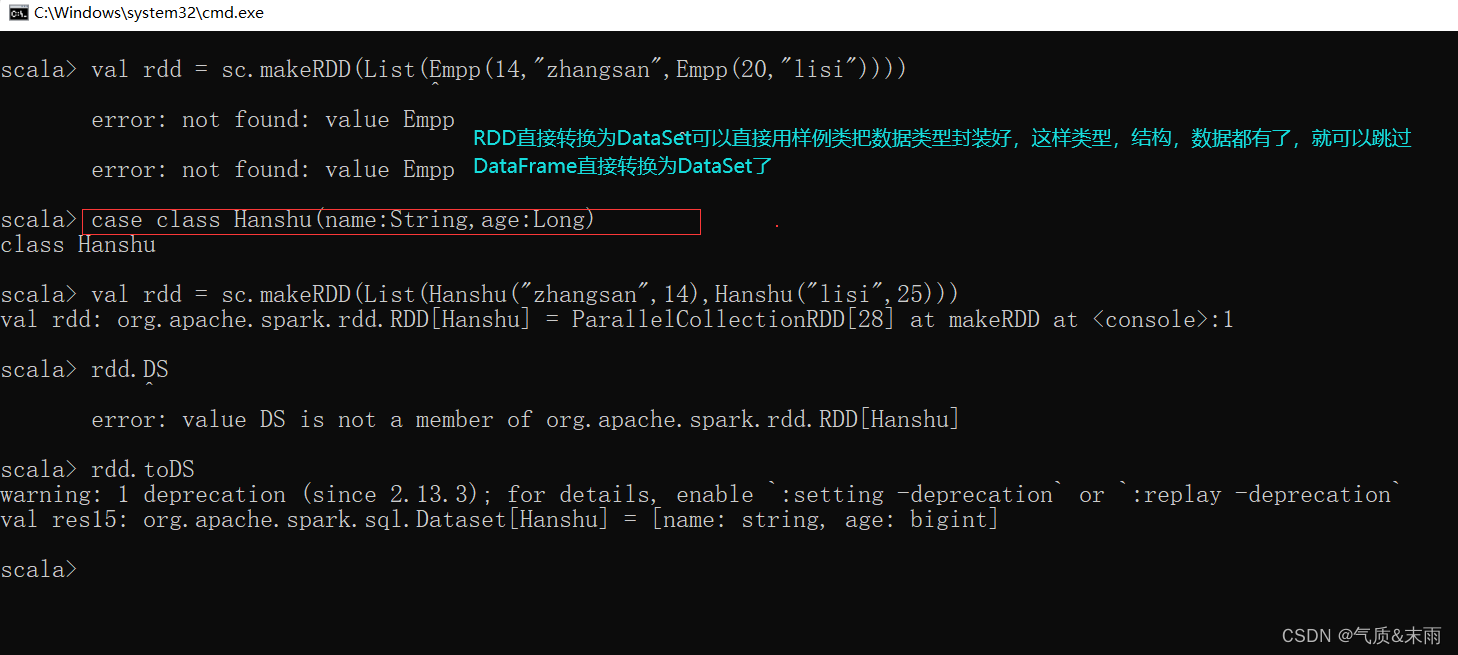
SparkSQL 核心编程
文章目录SparkSQL 核心编程1、新的起点2、SQL 语法1) 读取 json 文件创建 DataFrame2) 对 DataFrame 创建一个临时表3) 通过SQL语句实现查询全表3、DSL 语法1) 创建一个DataFrame2) 查看DataFrame的Schema信息3) 只查看"username"列数据4) 查看"username"列…...
Android核心开发【UI绘制流程解析+原理】
一、UI如何进行具体绘制 UI从数据加载到具体展现的过程: 进程间的启动协作: 二、如何加载到数据 应用从启动到onCreate的过程: Activity生产过程详解: 核心对象 绘制流程源码路径 1、Activity加载ViewRootImpl ActivityThread…...
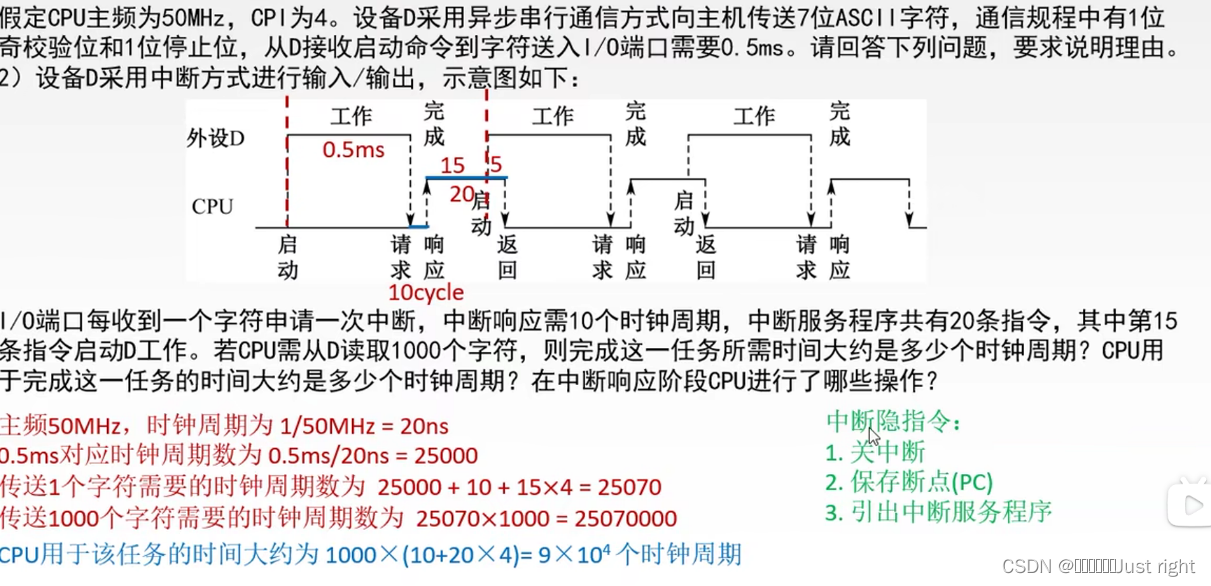
计算机组成原理第七章笔记记录
仅仅作为笔记记录,B站视频链接,若有错误请指出,谢谢 基本概念 演变过程 I/O系统基本组成 I/O软件 包括驱动程序、用户程序、管理程序、升级补丁等 下面的两种方式是用来实现CPU和I/O设备的信息交换的 I/O指令 CPU指令的一部分,由操作码,命令码,设备…...
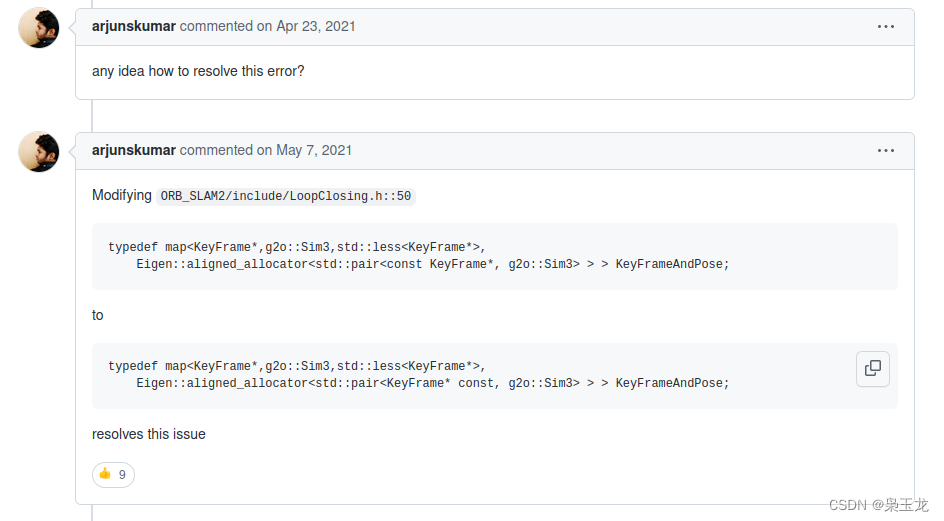
ORB-SLAM2编译、安装等问题汇总大全(Ubuntu20.04、eigen3、pangolin0.5、opencv3.4.10)
ORB-SLAM2编译、安装等问题汇总大全(Ubuntu20.04、eigen3、pangolin0.5、opencv3.4.10) 1:环境说明: 使用的Linux发行版本为Ubuntu 20.04 SLAM2下载地址为:git clone https://github.com/raulmur/ORB_SLAM2.git ORB_SLAM2 2&a…...

QuickBuck:一款专为安全研究人员设计的勒索软件模拟器
关于QuickBuck QuickBuck是一款基于Golang开发的勒索软件模拟工具,在该工具的帮助下,广大研究人员可以通过更简单的方法来判断反病毒保护方案是否能够有效地预防勒索软件的攻击。 功能介绍 该工具能够模拟下列勒索软件典型行为,其中包括&a…...

【八大数据排序法】堆积树排序法的图形理解和案例实现 | C++
第二十一章 堆积树排序法 目录 第二十一章 堆积树排序法 ●前言 ●认识排序 1.简要介绍 2.图形理解 3.算法分析 ●二、案例实现 1.案例一 ● 总结 前言 排序算法是我们在程序设计中经常见到和使用的一种算法,它主要是将一堆不规则的数据按照递增…...

低代码开发平台|生产管理-生产加工搭建指南
1、简介1.1、案例简介本文将介绍,如何搭建生产管理-生产加工。1.2、应用场景在主生产计划列表中下达加工后,在加工单列表可操作领料、质检。2、设置方法2.1、表单搭建1)新建表单【产品结构清单(BOM)】,字段…...
Python类型-语句-函数
文章目录类型动态类型:变量类型会随着程序的运行发生改变注释控制台控制台输入input()运算符算术关系逻辑赋值总结语句判断语句while循环for循环函数链式调用和嵌套调用递归关键字传参在C/java中,整数除以整数结果还是整数,并不会将小数部分舍弃…...

从服务器到手机:手把手教你修改游戏客户端IP,让私服在手机上跑起来
移动游戏私服客户端IP修改实战指南 当你在服务器上成功部署了游戏私服后,最令人沮丧的莫过于发现手机上的官方客户端无法连接到你的私人服务器。这个看似简单的"最后一公里"问题,往往成为许多私服搭建者的拦路虎。本文将彻底解决这个痛点&…...

知网AI率30%50%80%哪个最难降?比话降AI知网专精方案!
知网AI率30%50%80%哪个最难降?比话降AI知网专精方案! 很多硕博毕业生有个直觉:知网 AI 率 80% 比 30% 难降很多。这个直觉只对了一半。 真相是:难度不是看数字高低,是看「工具的技术路线对不对知网的算法」。一篇 80% …...

Python全栈实战:前后端分离开发核心要点
后端API搭建FastAPI与Flask是Python全栈开发的主流后端框架选择。两者均支持RESTful API开发,但适用场景不同:FastAPI代码示例(高性能方案):from fastapi import FastAPI app FastAPI()app.get("/items/{item_id…...

CDMA功率测量技术与Agilent 8960系统优化
1. CDMA功率测量技术背景与挑战在cdma2000移动通信系统中,精确的功率控制是实现高质量通信的核心技术之一。与GSM等采用固定功率等级的系统不同,CDMA要求移动台(MS)能够在80dB动态范围内精确调整发射功率。这种需求源于CDMA系统的自干扰特性——所有用户…...

2026最权威的十大AI辅助论文工具实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 要降低AIGC也就是人工智能生成内容的检测率,关键之处在于减少机器生成的痕迹,还要增加文本的…...

99%人开发Agent的致命误区!6大避坑指南助你从“调参怪”变“落地王”
本文揭示了开发Agent最常见的认知陷阱——将模型能力等同于系统能力,并提供了6大避坑指南:1. 掌握四层架构(Persona、CoT、Skill、MCP);2. 选择合适的执行模型(ReAct、Plan-and-Execute、Reflection&#x…...

Cesium三维地形剖切与开挖:从原理到可复用组件封装
1. 为什么需要地形剖切与开挖功能? 在三维地理信息系统中,地形剖切与开挖是最常用的分析功能之一。想象一下,你正在规划一条地下隧道,或者需要分析某处地质构造,这时候如果能把地表"切开"查看内部情况&#…...
)
保姆级教程:用Winbox给ROS配置一线多拨,实测200M宽带叠加效果(附避坑指南)
家庭网络优化实战:Winbox配置多拨提升宽带利用率 家里装了200M宽带,但下载大文件时总觉得速度没跑满?多人同时在线看4K视频就开始卡顿?其实通过简单的路由器配置,你完全有可能突破运营商单线限制,让宽带利用…...

HS2-HF Patch深度技术解析:专业级游戏MOD集成框架设计
HS2-HF Patch深度技术解析:专业级游戏MOD集成框架设计 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF Patch是一个针对HoneySelect2游戏的高…...

C++ 算法实战:从鸡兔同笼到多元方程求解的编程思维演进
1. 从鸡兔同笼开始理解算法思维 记得第一次接触鸡兔同笼问题时,我正啃着铅笔头对着数学作业发愁。题目说笼子里有35个头和94只脚,问鸡和兔各有多少只。这个看似简单的应用题,后来竟成了我算法思维的启蒙老师。 用C解决这个问题时,…...