基于机器学习的电商优惠券核销预测
1. 项目简介
随着移动互联网的快速发展,O2O(Online to Offline)模式已成为电商领域的一大亮点。优惠券作为一种有效的营销工具,被广泛应用于吸引新客户和激活老用户。然而,传统的随机投放方式往往效率低下,不仅对用户造成干扰,还可能损害品牌形象。因此,个性化优惠券投放成为提高营销效果的关键。本文将详细介绍如何利用机器学习技术进行电商优惠券使用预测,以实现优惠券的精准投放。
2. 数据准备
2.1 数据来源与收集
本研究使用的数据集包括线下和线上两个部分。线下数据集包含用户ID、商户ID、优惠券ID、折扣率、距离、领券日期和消费日期等信息。线上数据集则包含用户ID、商户ID、行为类型、优惠券ID、折扣率、领券日期和消费日期等信息。
2.2 数据预处理
数据预处理是机器学习中的关键步骤。首先,我们需要处理缺失值,例如将字符串类型的缺失值替换为np.nan。其次,对于异常值,如距离字段中的null值,我们将其替换为-1,并转换为整数类型。最后,我们需要对数据类型进行转换,确保所有数值字段都是正确的数据类型。
# 处理缺失值和异常值
t2.replace('null', -1, inplace=True)
t2.distance = t2.distance.astype('int')
t2.replace(-1, np.nan, inplace=True)3. 特征工程
特征工程是机器学习中提高模型性能的重要环节。我们从以下几个方面构建特征:
3.1 优惠券相关特征
- 优惠券类型(直接优惠为0,满减为1)
- 优惠券折率
- 满减优惠券的最低消费
- 历史出现次数
- 历史核销次数
- 历史核销率
- 历史核销时间率
- 领取优惠券是一周的第几天
- 领取优惠券是一月的第几天
- 历史上用户领取该优惠券次数
- 历史上用户消费该优惠券次数
- 历史上用户对该优惠券的核销率
def get_coupon_related_feature(dataset3, filename='coupon3_feature'):# 计算折扣率函数def calc_discount_rate(s):s = str(s)s = s.split(':')if len(s) == 1:return float(s[0])else:return 1.0 - float(s[1]) / float(s[0])# 提取满减优惠券中,满对应的金额def get_discount_man(s):s = str(s)s = s.split(':')if len(s) == 1:return 'null'else:return int(s[0])# 提取满减优惠券中,减对应的金额def get_discount_jian(s):s = str(s)s = s.split(':')if len(s) == 1:return 'null'else:return int(s[1])# 是不是满减卷def is_man_jian(s):s = str(s)s = s.split(':')if len(s) == 1:return 0else:return 1.0# 周几领取的优惠券dataset3['day_of_week'] = dataset3.date_received.astype('str').apply(lambda x: date(int(x[0:4]), int(x[4:6]), int(x[6:8])).weekday() + 1)# 每月的第几天领取的优惠券dataset3['day_of_month'] = dataset3.date_received.astype('str').apply(lambda x: int(x[6:8]))# 领取优惠券的时间与当月初距离多少天dataset3['days_distance'] = dataset3.date_received.astype('str').apply(lambda x: (date(int(x[0:4]), int(x[4:6]), int(x[6:8])) - date(2016, 6, 30)).days)# 满减优惠券中,满对应的金额dataset3['discount_man'] = dataset3.discount_rate.apply(get_discount_man)# 满减优惠券中,减对应的金额dataset3['discount_jian'] = dataset3.discount_rate.apply(get_discount_jian)# 优惠券是不是满减卷dataset3['is_man_jian'] = dataset3.discount_rate.apply(is_man_jian)# 优惠券的折扣率(满减卷进行折扣率转换)dataset3['discount_rate'] = dataset3.discount_rate.apply(calc_discount_rate)# 特定优惠券的总数量d = dataset3[['coupon_id']]d['coupon_count'] = 1d = d.groupby('coupon_id').agg('sum').reset_index()dataset3 = pd.merge(dataset3, d, on='coupon_id', how='left')dataset3.to_csv(os.path.join('features', filename + '.csv'), index=None)return dataset33.2 商户相关特征
- 商家优惠券被领取次数
- 商家优惠券被领取后不核销次数
- 商家优惠券被领取后核销次数
- 商家优惠券被领取后核销率
- 商家优惠券核销的平均/最小/最大消费折率
- 核销商家优惠券的不同用户数量,及其占领取不同的用户比重
- 商家优惠券平均每个用户核销多少张
- 商家被核销过的不同优惠券数量
- 商家被核销过的不同优惠券数量占所有领取过的不同优惠券数量的比重
- 商家平均每种优惠券核销多少张
- 商家被核销优惠券的平均时间率
- 商家被核销优惠券中的平均/最小/最大用户-商家距离
def get_merchant_related_feature(feature3, filename='merchant3_feature'):merchant3 = feature3[['merchant_id', 'coupon_id', 'distance', 'date_received', 'date']]# 提取不重复的商户集合t = merchant3[['merchant_id']]t.drop_duplicates(inplace=True)# 商户的总销售次数t1 = merchant3[merchant3.date != 'null'][['merchant_id']]t1['total_sales'] = 1t1 = t1.groupby('merchant_id').agg('sum').reset_index()# 商户被核销优惠券的销售次数t2 = merchant3[(merchant3.date != 'null') & (merchant3.coupon_id != 'null')][['merchant_id']]t2['sales_use_coupon'] = 1t2 = t2.groupby('merchant_id').agg('sum').reset_index()# 商户发行优惠券的总数t3 = merchant3[merchant3.coupon_id != 'null'][['merchant_id']]t3['total_coupon'] = 1t3 = t3.groupby('merchant_id').agg('sum').reset_index()# 商户被核销优惠券的用户-商户距离,转化为int数值类型t4 = merchant3[(merchant3.date != 'null') & (merchant3.coupon_id != 'null')][['merchant_id', 'distance']]t4.replace('null', -1, inplace=True)t4.distance = t4.distance.astype('int')t4.replace(-1, np.nan, inplace=True)# 商户被核销优惠券的最小用户-商户距离t5 = t4.groupby('merchant_id').agg('min').reset_index()t5.rename(columns={'distance': 'merchant_min_distance'}, inplace=True)# 商户被核销优惠券的最大用户-商户距离t6 = t4.groupby('merchant_id').agg('max').reset_index()t6.rename(columns={'distance': 'merchant_max_distance'}, inplace=True)# 商户被核销优惠券的平均用户-商户距离t7 = t4.groupby('merchant_id').agg('mean').reset_index()t7.rename(columns={'distance': 'merchant_mean_distance'}, inplace=True)# 商户被核销优惠券的用户-商户距离的中位数t8 = t4.groupby('merchant_id').agg('median').reset_index()t8.rename(columns={'distance': 'merchant_median_distance'}, inplace=True)# 合并上述特征merchant3_feature = pd.merge(t, t1, on='merchant_id', how='left')merchant3_feature = pd.merge(merchant3_feature, t2, on='merchant_id', how='left')merchant3_feature = pd.merge(merchant3_feature, t3, on='merchant_id', how='left')merchant3_feature = pd.merge(merchant3_feature, t5, on='merchant_id', how='left')merchant3_feature = pd.merge(merchant3_feature, t6, on='merchant_id', how='left')merchant3_feature = pd.merge(merchant3_feature, t7, on='merchant_id', how='left')merchant3_feature = pd.merge(merchant3_feature4. 数据集可视化分析
4.1 预测标签的类别分布

可以看出,标签为 1 的占比非常少,是一个类别极度不均衡的二分类问题。
4.2 特征相关性分析

4.3 商户的总销售次数分布情况

4.4 领取优惠券的时间与当月初距离天数分布

由于特征太多篇幅有限,此处只列出部分特征的分布可视化。
5. 训练集和验证集切分
由于比赛已结束,所以此处将手动切分出训练集、验证集、测试集,测试集用于不同模型的性能对比。
df_columns = dataset12_x.columns.values
print('===> feature count: {}'.format(len(df_columns)))X_train, X_valid, y_train, y_valid = train_test_split(dataset12_x, dataset12_y, test_size=0.1, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.1, random_state=42)
print('train: {}, valid: {}, test: {}'.format(X_train.shape[0], X_valid.shape[0], X_test.shape[0]))===> feature count: 53 train: 327856, valid: 40477, test: 36429
6. Xgboost 建模预测
Xgboost是一种高效的梯度提升框架,它可以用来解决分类、回归等多种机器学习任务。Xgboost通过集成多个弱学习器(通常是决策树),并优化损失函数来提高模型的准确性。
xgb_params = {'eta': 0.01,'min_child_weight': 20,'colsample_bytree': 0.5,'max_depth': 15,'subsample': 0.9,'lambda': 2.0,'eval_metric': 'auc','objective': 'binary:logistic','nthread': -1,'silent': 1,'booster': 'gbtree'
}pre_xgb_model = xgb.train(dict(xgb_params),dtrain,evals=watchlist,verbose_eval=50)交叉验证获取最佳迭代次数:
print('---> cv train to choose best_num_boost_round')
cv_result = xgb.cv(dict(xgb_params),dtrain,num_boost_round=5000,early_stopping_rounds=100,verbose_eval=100,show_stdv=False,)
best_num_boost_rounds = len(cv_result)
mean_train_logloss = cv_result.loc[best_num_boost_rounds-11 : best_num_boost_rounds-1, 'train-auc-mean'].mean()
mean_test_logloss = cv_result.loc[best_num_boost_rounds-11 : best_num_boost_rounds-1, 'test-auc-mean'].mean()
print('best_num_boost_rounds = {}'.format(best_num_boost_rounds))print('mean_train_auc = {:.7f} , mean_test_auc = {:.7f}\n'.format(mean_train_logloss, mean_test_logloss))[0] train-auc:0.87954 test-auc:0.87309 [100] train-auc:0.90277 test-auc:0.89217 [200] train-auc:0.90981 test-auc:0.89533 [300] train-auc:0.91590 test-auc:0.89786 [400] train-auc:0.92089 test-auc:0.89978 [500] train-auc:0.92522 test-auc:0.90138 [600] train-auc:0.92873 test-auc:0.90252 [700] train-auc:0.93169 test-auc:0.90334 [800] train-auc:0.93411 test-auc:0.90396 [900] train-auc:0.93610 test-auc:0.90444 [1000] train-auc:0.93786 test-auc:0.90482 [1100] train-auc:0.93937 test-auc:0.90512 [1200] train-auc:0.94078 test-auc:0.90540 [1300] train-auc:0.94218 test-auc:0.90564 [1400] train-auc:0.94347 test-auc:0.90583 [1500] train-auc:0.94468 test-auc:0.90595 [1600] train-auc:0.94578 test-auc:0.90607 [1700] train-auc:0.94686 test-auc:0.90616 [1800] train-auc:0.94787 test-auc:0.90626 [1900] train-auc:0.94886 test-auc:0.90632 [2000] train-auc:0.94986 test-auc:0.90636
6.1 特征重要程度分析

6.2 性能评估
# predict train
predict_train = xgb_model.predict(dtrain)
after_xgb_train_auc = evaluate_score(predict_train, y_train)# predict validate
predict_valid = xgb_model.predict(dvalid)
after_xgb_valid_auc = evaluate_score(predict_valid, y_valid)dtest = xgb.DMatrix(X_test, feature_names=df_columns)
predict_test = xgb_model.predict(dtest)
after_xgb_test_auc = evaluate_score(predict_test, y_test)print('训练集 auc = {:.7f} , 验证集 auc = {:.7f} , 测试集 auc = {:.7f}\n'.format(after_xgb_train_auc, after_xgb_valid_auc, after_xgb_test_auc))训练集 auc = 0.9042264 , 验证集 auc = 0.8958611 , 测试集 auc = 0.8960916
6.3 调参前后模型性能对比

可以看出,调参后,训练集、验证集和测试集的 AUC 都得到了不同程度的提升、
6.4 预测性能 ROC 曲线

7. 随机森林(RandomForest)建模预测
随机森林是一种集成学习方法,它通过构建多个决策树并将它们的预测结果进行汇总来提高整体模型的性能。随机森林在处理高维数据时表现出色,并且对于过拟合具有一定的抵抗力。
用RandomSearch+CV选取超参数:
# 建立一个分类器或者回归器
rf_clf = RandomForestClassifier()# 给定参数搜索范围:list or distribution
param_dist = {"n_estimators": [100, 500, 1000, 1500, 2000],"max_depth": [3, 5, 8, 12, 15],"max_features": [2, 5, 10,],"min_samples_split": [2, 4, 6, 8, 10, 12],"bootstrap": [True, False],"criterion": ["gini", "entropy"],
}n_iter_search = 20
random_search_cv = RandomizedSearchCV(rf_clf, param_distributions=param_dist, n_iter=n_iter_search, cv=5, n_jobs=-1, verbose=1)最佳参数训练 RF 模型:
rf_model = RandomForestClassifier(n_estimators=3000, criterion='gini', max_depth=12, min_samples_split=1000, min_samples_leaf=6, min_weight_fraction_leaf=0.0, max_features='sqrt', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, n_jobs=-1, random_state=42, verbose=1, warm_start=False, max_samples=None
)
训练集 auc = 0.6242629 , 验证集 auc = 0.6232508 , 测试集 auc = 0.6194697
8. Stochastic Gradient Descent(SGD算法)
SGD是一种优化算法,它通过随机选择样本来更新模型参数,从而减少计算量并加快收敛速度。SGD适用于大规模和在线机器学习任务。
同样的方法,测试 SGD 算法建模预测性能,此处省略。
9. 模型对比
import matplotlib.pyplot as plt
import numpy as npspecies = ['训练集', '验证集', '测试集']
penguin_means = {'Xgboost': (xgb_train_auc, xgb_valid_auc, xgb_test_auc),'RandomForest': (rf_train_auc, rf_valid_auc, rf_test_auc),'SGD': (sgd_train_auc, sgd_valid_auc, sgd_test_auc),
}
xgb_train_auc
x = np.arange(len(species))
width = 0.25
multiplier = 0plt.figure(figsize=(40, 20))
fig, ax = plt.subplots(layout='constrained', figsize=(30, 15))for attribute, measurement in penguin_means.items():offset = width * multiplierrects = ax.bar(x + offset, measurement, width, label=attribute)ax.bar_label(rects, padding=3, fontsize=26)multiplier += 1ax.set_ylabel('数据集', fontsize=26)
ax.set_title('不同模型的评测性能对比', fontsize=40)
ax.set_xticks(x + width, species, fontsize=26)
ax.legend(loc='upper left', fontsize=26)
ax.set_ylim(0, 1.5)plt.show()
我们比较了Xgboost、随机森林和SGD三种模型的性能。结果显示,Xgboost模型在训练集、验证集和测试集上的AUC值均高于其他两种模型。
10. 结论
通过对用户行为和优惠券使用情况的分析,我们构建了一个基于机器学习的优惠券使用预测模型。该模型能够有效地预测用户是否会核销他们收到的优惠券,从而帮助企业更精准地进行营销活动。未来的工作可以进一步优化特征选择、调整模型参数,或者尝试其他类型的机器学习算法以提升预测准确性。
相关文章:
基于机器学习的电商优惠券核销预测
1. 项目简介 随着移动互联网的快速发展,O2O(Online to Offline)模式已成为电商领域的一大亮点。优惠券作为一种有效的营销工具,被广泛应用于吸引新客户和激活老用户。然而,传统的随机投放方式往往效率低下,…...

PHP-FPM 远程代码执行漏洞(CVE-2019-11043)复现
启动环境 切换目录到vulhub/php/CVE-2019-11043下 查看端口 访问 安装漏洞利用工具 git clone https://github.com/neex/phuip-fpizdam.git 安装go语言 # 1、下载go,这里使用 go1.22.5 版本,可替换为最新版本 wget https://dl.google.com/go/go1.22.5.…...

Rust : 从事量化的生态现状与前景
Rust适不适合做量化工作? 一般地认为,目前大部分场景策略开发最佳是Python;策略交易和部署是C。但还是有人会问,Rust呢? 这个问题不太靠谱! 适不适合做一件事情,本身就是一件主观的事。即使是…...

Java项目——苍穹外卖(一)
Entity、DTO、VO Entity(实体) Entity 是表示数据库表的对象,通常对应数据库中的一行数据。它通常包含与数据库表对应的字段,并可能包含一些业务逻辑。 DTO(数据传输对象) 作用:DTO 是用于在…...

20240908 每日AI必读资讯
新AI编程工具爆火:手机2分钟创建一个APP! - AI初创公司Replit推出的智能体——Replit Agent。开发环境、编写代码、安装软件包、配置数据库、部署等等,统统自动化! - 操作方式也是极其简单,只需一个提出Prompt的动作…...

HNU-2023电路与电子学-实验3
写在前面: 本次实验是完成cpu设计的剩余部分,整体难度比上一次要小,细心完成就能顺利通过全部测评 一、实验目的 1.了解简易模型机的内部结构和工作原理。 2.分析模型机的功能,设计 8 重 3-1 多路复用器。 3.分析模型机的功能…...

html基础语法 看这一篇就够了!
HTML 一 概念 html:html 文件根标签 head:编写页面相关的属性 title:页面标题 body:页面内容展示信息 二 DOM 树: 所有的标签都是 html 的子标签 head 和 body 是兄弟标签,同一级别 head 和 title 为父子标签 1.第一个程序 <html><head>…...
【redis】redis的特性和主要应用场景
文章目录 redis 的特性在内存中存储数据可编程的扩展能力持久化集群高可用快 redis 的应用场景实时数据存储缓存消息队列 redis 的特性 redis 的一些特性(优点)成就了它 在内存中存储数据 In-memory data structures MySQL 主要是通过“表”的方式来…...

部署后端WebSocket服务到AWS云服务器
目录 1.创建AWS账户2.选择EC2实例3.配置EC2实例4.使用VSCode连接到EC2实例5.部署WebSocket服务6.配置域名和SSL(可选)7.监控和维护 1.创建AWS账户 如果你还没有AWS账户,你需要先在AWS官网注册一个。 2.选择EC2实例 登录到AWS管理控制台。搜…...

常见的集合
1、Collection 单列集合的根接口 遍历方法 Collection<String> c new ArrayList<>(); c.add("赵敏"); c.add("小昭"); c.add("素素"); c.add("灭绝"); System.out.println(c); //[赵敏, 小昭, 素素, 灭绝]//1、迭代器遍…...

Swift知识点---RxSwift学习
1. 什么是RxSwift RxSwift是Swift函数响应式编程的一个开源库,由Github的ReactiveX组织开发、维护 RxSwift的目的是:让数据/事件流 和 异步任务能够更方便的序列化处理,能够使用Swift进行响应式编程 RxSwift本质上还是观察者模式ÿ…...

驾驭不断发展的人工智能世界
从很多方面来看,历史似乎正在重演。许多企业正争相采用生成式人工智能 (Gen AI),就像它们争相采用云计算一样,原因也是一样的:效率、成本节约和竞争优势。 然而,与云一样,GenAI 仍是一项发展中的技术&…...
冒泡排序——基于Java的实现
简介 冒泡排序(Bubble Sort)是一种简单的排序算法,适用于小规模数据集。其基本思想是通过重复遍历待排序的数组,比较相邻的元素并交换它们的位置,以此将较大的元素逐步“冒泡”到数组的末尾。算法的名称源于其运行过程…...
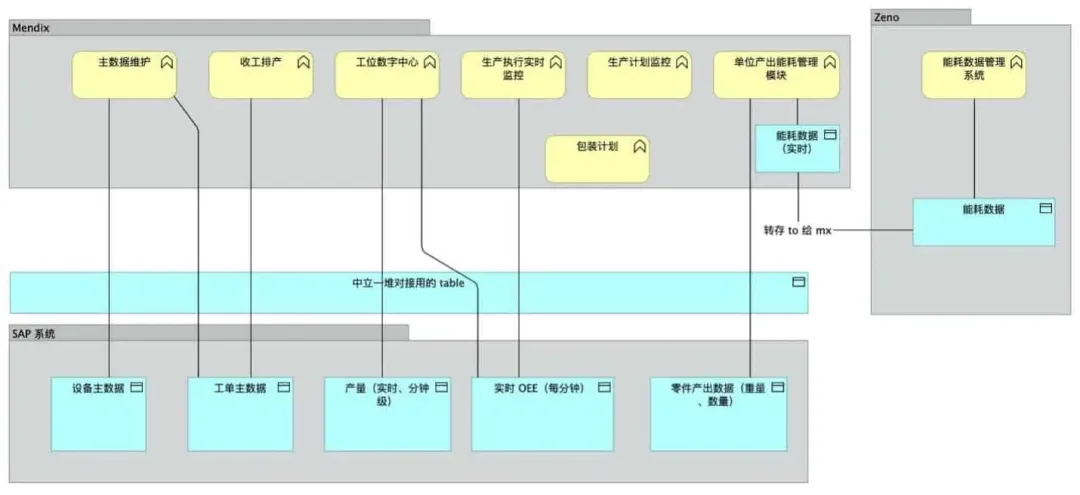
Mendix 创客访谈录|Mendix赋能汽车零部件行业:重塑架构,加速实践与数字化转型
在当前快速发展的技术时代,汽车行业正经历着前所未有的数字化转型。全球领先的汽车零配件制造商面临着如何利用最新的数字技术优化其制造车间管理的挑战。从设备主数据管理到生产执行工单管理,再到实时监控产量及能耗,需要一个灵活、快速且高…...

船舶机械设备5G智能工厂物联数字孪生平台,推进制造业数字化转型
船舶机械设备5G智能工厂物联数字孪生平台,推进制造业数字化转型。在当今数字化浪潮推动下,船舶制造业正经历着前所未有的变革。为了应对市场的快速变化,提升生产效率,降低成本,并增强国际竞争力,船舶机械设…...

什么是jsonp请求
JSONP(JSON with Padding)是一种解决跨域请求问题的技术。它允许网页从不同的域名请求数据,而不受同源策略的限制。JSONP 通过动态创建 script 标签来实现跨域请求,因为 script 标签不受同源策略的限制。 一、工作原理 客户端&a…...

【C++】STL容器详解【上】
目录 一、STL基本概念 二、STL的六大组件 三、string容器常用操作 3.1 string 容器的基本概念 3.2 string 容器常用操作 3.2.1 string 构造函数 3.2.2 string基本赋值操作 3.2.3 string存取字符操作 3.2.4 string拼接字符操作 3.2.5 string查找和替换 3.2.6 string比…...

助贷行业的三大严峻挑战:贷款中介公司转型债务重组业务
大家是否察觉到一种趋势?现如今,众多贷款辅助服务机构与专注于债务再构的公司之间形成了紧密的“联动”。有的选择将获取的贷款需求转介给债务重组方,有的则直接下场,动用自身资本参与债务重组业务。这一现象背后,究竟…...

力扣第42题 接雨水
前言 记录一下刷题历程 力扣第42题 接雨水 接雨水 原题目:给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出&…...

轻松录制每一刻:探索2024年免费高清录屏应用
你不会还在用一些社交工具来录屏吧?现在的市面上有不少免费录屏的软件了。别看如软件是免费的,它的功能比起社交工具的录屏功能来说全面的多。这次我就分享几款我用过的录屏工具。 1.福晰录屏大师 链接直达:https://www.foxitsoftware.cn/R…...
)
跟着 MDN 学CSS day_16:(深入掌握背景与边框的艺术)
在网页设计的视觉语言中,背景与边框是两个最基础也最强大的工具。它们就像舞台的幕布和画框,共同构建了元素的视觉边界与氛围。MDN的技能测试为我们提供了一个绝佳的实践机会,通过两个具体任务,将理论知识转化为实战能力。本文将深…...

如何利用LayerPlayer快速掌握iOS动画开发技巧
如何利用LayerPlayer快速掌握iOS动画开发技巧 【免费下载链接】LayerPlayer Layer Player explores the capabilities of Apples Core Animation API 项目地址: https://gitcode.com/gh_mirrors/la/LayerPlayer LayerPlayer是一款专注于探索Apple Core Animation API功能…...

告别‘薛定谔的网卡’:在Ubuntu 20.04上为RTL8168网卡手动编译驱动并配置开机自启的完整记录
深度解析:Ubuntu 20.04下RTL8168网卡驱动的编译与持久化加载实战当你盯着Ubuntu系统托盘上那个时隐时现的网络图标,或是反复插拔网线却依然无法获得稳定的有线连接时,可能正遭遇着经典的RTL8168网卡驱动问题。这个被开发者戏称为"薛定谔…...

Godot与AI深度协作:重构游戏开发工作流的5步实践
1. 这不是“调用API”——Godot与AI助手协作的本质是重构工作流很多人看到“Godot集成AI助手”,第一反应是:找个HTTP客户端发个请求,把提示词塞进去,等JSON返回,再parse一下显示在UI里。我试过三次——第一次用GDScrip…...

JMeter实战:从接口测试到性能基线的全链路压测指南
1. 这不是“点点点就能跑通”的测试,而是用JMeter撬动系统稳定性的杠杆很多人第一次打开JMeter,以为它就是个“高级版Postman”:填URL、选方法、点执行,看到Response里有JSON就松一口气——“接口通了,测试完了”。我带…...
)
别再折腾VMware Tools了!用FileZilla+SSH搞定Windows与Ubuntu虚拟机文件互传(保姆级教程)
告别VMware Tools烦恼:SSHFileZilla实现跨平台文件传输全攻略 每次在Windows和Ubuntu虚拟机之间传输文件时,VMware Tools总是给你带来各种麻烦?安装失败、兼容性问题、功能受限...这些问题我都经历过。今天我要分享的是一种更稳定、更通用的…...

Playwright MCP实战:AI驱动的网页自动修复与可验证调试
1. 这不是“让AI写网页”,而是让AI当你的前端搭档你有没有过这样的时刻:凌晨两点,线上一个按钮突然不响应,控制台报错指向一段被压缩过的JS,你一边翻Git历史一边怀疑人生;或者刚上线的表单在Safari里莫名错…...

图机器学习在农药生态毒性预测中的应用与挑战
1. 项目概述:当图机器学习遇见农药设计农药,这个听起来有些“硬核”的词汇,其实是我们现代农业的基石。从除草剂到杀虫剂,它们守护着全球的粮食安全。但硬币的另一面是,农药的生态毒性问题日益凸显,尤其是对…...

序数回归实战:从KNN阈值优化到神经网络模型全解析
1. 项目概述:当回归遇上“有序”世界在机器学习的工具箱里,回归和分类是两大基石。回归预测连续值,比如房价、温度;分类预测离散标签,比如猫、狗、汽车。但现实世界并非总是非黑即白,有一种特殊的数据类型常…...

Java NIO.2 异步基石:AsynchronousChannel 接口契约与并发安全深度剖析
前言:异步 I/O 的“宪法级”契约 在 Java NIO.2(AIO)的宏大架构中,AsynchronousChannel 是所有异步通道的根接口。它不定义任何具体的读写方法,也不关心网络拓扑或文件偏移——它只做一件事:确立异步 I/O 操…...