NLP-transformer学习:(6)dataset 加载与调用
NLP-transformer学习:(6)dataset 加载与调用

平常其实也经常进行trainning等等,但是觉得还是觉得要补补基础,所以静下心,搞搞基础联系
本章节基于 NLP-transformer学习:(5)讲解了如何做一个简单的训练和模型迁移,这里实践一个长用的dataset
文章目录
- NLP-transformer学习:(6)dataset 加载与调用
- @[TOC](文章目录)
- 1 什么是datasets
- 2 datasets 实战
- 2.1 基础操作
- 2.2 加载某一任务或某一部分
- 2.3 数据划分
- 2.4 数据选取和过滤
- 2.4 数据映射
- 2.5 数据保存与加载
文章目录
- NLP-transformer学习:(6)dataset 加载与调用
- @[TOC](文章目录)
- 1 什么是datasets
- 2 datasets 实战
- 2.1 基础操作
- 2.2 加载某一任务或某一部分
- 2.3 数据划分
- 2.4 数据选取和过滤
- 2.4 数据映射
- 2.5 数据保存与加载
提示:以下是本篇文章正文内容,下面案例可供参考
1 什么是datasets
地址:https://huggingface.co/datasets

datasets言而简之就是加载数据集用的
使用之前需要:
pip install datasets
有些特殊的库需要
pip install datasets[vision]
pip install datasets[audio]
2 datasets 实战
2.1 基础操作
加载代码如下:
# if the py name is datasets, the import action will first use the current file
# not the datasets installed by pip
# for example you may meet the error: will be "NameError: name 'load_dataset' is not defined"from datasets import *if __name__ == "__main__":# add a datasetdata_set = load_dataset("madao33/new-title-chinese")print(data_set)print("------------------------------")print("train[0]:")print(data_set["train"][0])print("------------------------------")print("train[:2]:")print(data_set["train"][:2])print("------------------------------")print("train[\"tile\"][:5]:")print(data_set["train"]["title"][:5])print("------------------------------")这里注意的是,使用的python 文件名不能是“datasets”即重名,不然会首先找当前文件,然后报错:
NameError: name ‘load_dataset’ is not defined
当改为非datasets 名字后就可以看到数据加载
可以看到这个数据集中只有训练和验证数据集。

然后我们使用一些切片用法可以看到期望结果:

2.2 加载某一任务或某一部分
(1)加载某个任务
datasets 部分数据中不是只有数据还包含了很多任务
对于super_gule,这个datasets 是一个 任务的集合,如果我们要添加某一任务

我们可以这样做,代码如下:
# if the py name is datasets, the import action will first use the current file
# not the datasets installed by pip
# for example you may meet the error: will be "NameError: name 'load_dataset' is not defined"from datasets import *if __name__ == "__main__":# add specific taskboolq_dataset = load_dataset("super_glue", "boolq",trust_remote_code=True)print(boolq_dataset)

注意这里有个小细节,如果写成自动化代码时,可以加加上信任主机,这样就不用再敲入一个y

(2)加载某个部分(也叫某个划分)
load_dataset 支持加载某个部分,并且对某个部分进行切片,且切片还可以用%描述,但不能用小数描述
# if the py name is datasets, the import action will first use the current file
# not the datasets installed by pip
# for example you may meet the error: will be "NameError: name 'load_dataset' is not defined"from datasets import *if __name__ == "__main__":## add a dataset#data_set = load_dataset("madao33/new-title-chinese")#print(data_set)## add specific task#boolq_dataset = load_dataset("super_glue", "boolq",trust_remote_code=True)#print(boolq_dataset)dataset = load_dataset("madao33/new-title-chinese", split="train")print("train:") print(dataset)dataset = load_dataset("madao33/new-title-chinese", split="train[10:100]")print("train 10:100:") print(dataset)dataset = load_dataset("madao33/new-title-chinese", split="train[10%:50%]")print("train 10%:100%:") print(dataset)dataset = load_dataset("madao33/new-title-chinese", split=["train[:40%]", "train[40%:]"])print("train 40% and 60%:") print(dataset)
运行结果:

2.3 数据划分
这个dataset 自带了个调整比例的 函数:train_test_split
# if the py name is datasets, the import action will first use the current file
# not the datasets installed by pip
# for example you may meet the error: will be "NameError: name 'load_dataset' is not defined"from datasets import *if __name__ == "__main__":datasets = load_dataset("madao33/new-title-chinese")print("origin train datasets:")print(datasets["train"])print("-----------------")print("make train set as test 0.1:")dataset = datasets["train"]print(dataset.train_test_split(test_size=0.1))print("-----------------")print("stratify:")boolq_dataset = load_dataset("super_glue", "boolq",trust_remote_code=True)dataset = boolq_dataset["train"]print(dataset.train_test_split(test_size=0.1, stratify_by_column="label"))# 分类数据集可以按照比例划分print("-----------------")
运行结果:
这里 test_size = 0.1 指,将训练数据的 0.1 用作test,即585 = 5850 × 0.1
stratify: 这样可以均衡数据

2.4 数据选取和过滤
from datasets import *if __name__ == "__main__":datasets = load_dataset("madao33/new-title-chinese")# 选取filter_res = datasets["train"].select([0, 1])print("select:")print(filter_res["title"][:5])# 过滤filter_dataset = datasets["train"].filter(lambda example: "中国" in example["title"])print("filter:")print(filter_dataset["title"][:5])
结果:

2.4 数据映射
数据映射,就是我们写一个函数,然后对数据集中的每个数据都做这样的处理
(1)将个每个数据处理下,这里举例家了前缀
代码:
from datasets import load_datasetdef add_prefix(example):example["title"] = 'Prefix: ' + example["title"]return exampleif __name__ == "__main__":datasets = load_dataset("madao33/new-title-chinese")prefix_dataset = datasets.map(add_prefix)print(prefix_dataset["train"][:10]["title"])
运行结果:
可以看到和期望一样,将每个title 加了个”prefix“

(2)将每个数据做tokenizer
from datasets import *
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
def preprocess_function(example, tokenizer = tokenizer):model_inputs = tokenizer(example["content"], max_length = 512, truncation = True)labels = tokenizer(example["title"], max_length=32, truncation=True)# label就是title编码的结果model_inputs["labels"] = labels["input_ids"]return model_inputsif __name__ == "__main__":processed_datasets = datasets.map(preprocess_function)print("train:")print(processed_datasets["train"][:5])print("validation:")print(processed_datasets["validation"][:5])结果可以看到,数据已经和前几章讲的类似,变成了token。
运行结果:




2.5 数据保存与加载
from datasets import *
from transformers import AutoTokenizerif __name__ == "__main__":datasets = load_dataset("madao33/new-title-chinese")processed_datasets = datasets.map(preprocess_function)print("from web:") print(processed_datasets["validation"][:2])processed_datasets = datasets.map(preprocess_function)processed_datasets.save_to_disk("./processed_data")processed_datasets = load_from_disk("./processed_data")print("from local:") print(processed_datasets["validation"][:2])
结果:


相关文章:
NLP-transformer学习:(6)dataset 加载与调用
NLP-transformer学习:(6)dataset 加载与调用 平常其实也经常进行trainning等等,但是觉得还是觉得要补补基础,所以静下心,搞搞基础联系 本章节基于 NLP-transformer学习:(5࿰…...

数据库系统 第43节 数据库复制
数据库复制是一种重要的技术,用于在多个数据库系统之间同步数据。这在分布式系统中尤其重要,因为它可以提高数据的可用性、可扩展性和容错性。以下是几种常见的数据库复制类型: 主从复制 (Master-Slave Replication): 在这种模式下࿰…...
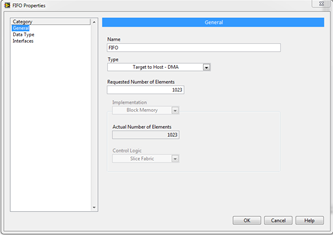
LabVIEW FIFO详解
在LabVIEW的FPGA开发中,FIFO(先入先出队列)是常用的数据传输机制。通过配置FIFO的属性,工程师可以在FPGA和主机之间,或不同FPGA VIs之间进行高效的数据传输。根据具体需求,FIFO有多种类型与实现方式&#x…...

如何验证VMWare WorkStation的安装?
如何验证VMWare WorkStation的安装? 右击"网络",点击 打开"网络和Internet设置",点击更改适配器选项,如果出现VMNet1和VMNet8,则说明安装成功。...

论文阅读:AutoDIR Automatic All-in-One Image Restoration with Latent Diffusion
论文阅读:AutoDIR: Automatic All-in-One Image Restoration with Latent Diffusion 这是 ECCV 2024 的一篇文章,利用扩散模型实现图像恢复的任务。 Abstract 这篇文章提出了一个创新的 all-in-one 的图像恢复框架,融合了隐扩散技术&#x…...

C++ | Leetcode C++题解之第392题判断子序列
题目: 题解: class Solution { public:bool isSubsequence(string s, string t) {int n s.size(), m t.size();vector<vector<int> > f(m 1, vector<int>(26, 0));for (int i 0; i < 26; i) {f[m][i] m;}for (int i m - 1; …...

操作系统概述(三、虚拟化)
系列文章目录 文章目录 系列文章目录前言十一、操作系统上的进程1. 从系统启动到第一个进程系统调用:fork(), 创建进程execv()PATH环境变量销毁进程 十二、进程的地址空间**查看进程的地址空间**进程地址空间管理进程地址空间隔离 十三、系统调用和 shell十四、C标准…...

基于ARM芯片与OpenCV的工业分拣机器人项目设计与实现流程详解
一、项目概述 项目目标和用途 本项目旨在设计和实现一套工业分拣机器人系统,能够高效、准确地对不同类型的物品进行自动分拣。该系统广泛应用于物流、仓储和制造业,能够显著提高工作效率,降低人工成本。 技术栈关键词 ARM芯片 步进电机控…...

UNITY UI简易反向遮罩
附带示例资源文件:https://download.csdn.net/download/qq_55895529/89726994?spm1001.2014.3001.5503 大致效果: 实现思路:通过ui shader的模板测试功能实现 通过让想要被突出显示的物体优先渲染并写入模板值,而后再让黑色遮罩渲染并判断模板值进行渲…...
)
牛客周赛59(A,B,C,D,E二维循环移位,F范德蒙德卷积)
比赛链接 官方讲解 很幸运参加了内测,不过牛客这消息推送天天发广告搞得我差点错过内测消息,差点进小黑屋,好在开赛前一天看到了。 这场不难,ABC都很签到,D是个大讨论,纯屎,E是需要对循环移位…...

C语言中的隐型计算
隐型计算(Implicit Computation)是C语言中一个不易察觉的特性,它发生在类型转换和操作顺序不明确的场合。隐型计算可能导致数据溢出、精度丢失或者不正确的结果。 例如,当你在一个int类型和unsigned类型混合的表达式中使用时&…...

ffmpeg面向对象-待定
1.常用对象 rtsp拉流第一步都是avformat_open_input,其入参可以看下怎么用: AVFormatContext *fmt_ctx NULL; result avformat_open_input(&fmt_ctx, input_filename, NULL, NULL);其中fmt_ctx 如何分配内存的?如下 int avformat_ope…...
面试题及参考答案)
大厂嵌入式数字信号处理器(DSP)面试题及参考答案
什么是模拟信号处理和数字信号处理(DSP)在嵌入式系统中的应用? 模拟信号处理是对连续变化的模拟信号进行操作和处理。在嵌入式系统中,模拟信号处理的应用包括传感器信号的调理,例如温度传感器、压力传感器等输出的模拟信号通常比较微弱且可能受到噪声干扰,需要通过放大器…...

GC-分代收集器
GC收集器介绍 十款GC收集器 上图中共有十款GC收集器,它们可以根据回收时的属性分为分代和分区两种类型: 分代收集器:Serial、ParNew、Parallel Scavenge、CMS、Serial Old(MSC)、Parallel Old 分区收集器ÿ…...

C++从入门到起飞之——priority_queue(优先级队列) 全方位剖析!
🌈个人主页:秋风起,再归来~🔥系列专栏:C从入门到起飞 🔖克心守己,律己则安 目录 1、priority_queue的介绍 2、priority_queue的使用 3、priority_queue的模拟实现 3.1、仿函数的介…...

[数据集][目标检测]西红柿缺陷检测数据集VOC+YOLO格式17318张3类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):17318 标注数量(xml文件个数):17318 标注数量(txt文件个数):17318 标…...

【小沐学OpenGL】Ubuntu环境下glut的安装和使用
文章目录 1、简介1.1 OpenGL简介1.2 glut简介1.3 freeglut 2、glut安装2.1 命令安装glut2.2 源码安装glut 3、glut测试3.1 测试1,版本打印3.2 测试2,绘制三角形3.3 测试3,VBO绘制三角形 结语 1、简介 1.1 OpenGL简介 OpenGL作为图形界的工业…...

ROS 发行版 jazzy 加载urdf 渲染到 RVIZ2
新版启动urdf需要两个包分别为urdf_tutorial、urdf_launch 配置package.xml <exec_depend>rviz_common</exec_depend> <exec_depend>rviz_default_plugins</exec_depend> <exec_depend>rviz2</exec_depend> <exec_depend>robot…...

SpringBoot中利用EasyExcel+aop实现一个通用Excel导出功能
一、结果展示 主要功能:可以根据前端传递的参数,导出指定列、指定行 1.1 案例一 前端页面 传递参数 {"excelName": "导出用户信息1725738666946","sheetName": "导出用户信息","fieldList": [{&q…...
)
排序链表(归并排序)
148. 排序链表 - 力扣(LeetCode) 以O(nlogn)时间复杂度, O(1)空间复杂度 排序链表 涉及知识点: 找到链表的中间节点 2095. 删除链表的中间节点 - 力扣(LeetCode)合并有序链表 21. 合并两个有序链…...

Unity InputField组件保姆级配置指南:从登录框到聊天框,一次搞定所有输入场景
Unity InputField组件实战配置指南:从登录验证到聊天系统的深度优化在游戏开发中,用户输入交互是连接玩家与游戏世界的重要桥梁。Unity的InputField组件作为最常用的输入控件之一,其配置灵活性直接影响用户体验的流畅度。本文将深入探讨如何针…...

3D光学流技术在机器人动作生成中的应用与优化
1. 3D光学流技术解析与机器人动作生成3D光学流技术是计算机视觉领域的重要突破,它通过分析物体在三维空间中的连续运动轨迹,为机器人动作规划提供了前所未有的精确度。传统2D光学流仅能捕捉平面运动信息,而3D光学流则能完整重建物体在XYZ三个…...

ChatGPT生成图表总“丑”?3步精准调优Prompt+4类D3.js/Plotly适配模板,即刻提升专业度
更多请点击: https://intelliparadigm.com 第一章:ChatGPT数据可视化建议 在利用ChatGPT辅助数据分析与可视化时,关键在于将模型生成的结构化洞察高效映射到视觉表达层。ChatGPT本身不直接渲染图表,但可精准生成符合主流库&#…...

AI Agent Harness多租户数据隔离
AI Agent Harness多租户数据隔离:构建企业级智能协作平台的安全基石 1. 引入与连接:从一场云端智能客服泄露事故谈起 核心概念: AI Agent(智能代理):具备自主感知、推理决策、行动执行能力的软件实体,可代表个人/组织完成特定任务,是当前大模型应用落地的核心载体 AI …...

3分钟掌握novel-downloader:打造你的永久小说图书馆终极指南
3分钟掌握novel-downloader:打造你的永久小说图书馆终极指南 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 你是否曾经因为小说网站突然关闭、章节被删除或VIP内容无法离…...

【ChatGPT故事化表达黄金法则】:20年AI内容专家亲授3步叙事框架,让提示词转化率提升300%
更多请点击: https://intelliparadigm.com 第一章:ChatGPT故事化表达的底层认知革命 传统人机交互长期受限于指令式范式——用户需精确编码意图,系统则机械匹配关键词或规则。ChatGPT 的突破性不在于参数规模,而在于其将语言建模…...

利用Taotoken模型广场为不同业务场景选择性价比最优的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同业务场景选择性价比最优的大模型 在将大模型能力集成到实际业务的过程中,开发者常常面临一…...

2026年度最新主流AI写作辅助软件综合排行
本次测评结合综合运行性能、学术场景匹配度、用户实际口碑与功能完备程度,对2026年市面上热门AI论文辅助工具开展综合排序,依照综合推荐分值由高至低排列,同时逐一介绍每款工具的核心优势、特色亮点以及适合的使用场景。第一梯队:…...

Node.js 项目如何集成 Taotoken 实现稳定的大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 项目如何集成 Taotoken 实现稳定的大模型调用 对于 Node.js 后端服务开发者而言,在项目中引入大模型能力正变得…...

实测Taotoken聚合接口在高峰时段的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken聚合接口在高峰时段的延迟与稳定性表现 作为开发者,在将大模型能力集成到生产环境时,服务的稳…...