〖open-mmlab: MMDetection〗解析文件:configs/_base_/schedules
详细解析三个训练调度文件:schedule_1x.py、schedule_2x.py、schedule_20e.py
在深度学习模型训练过程中,训练调度(Training Schedule)是至关重要的,它决定了模型训练过程中学习率(Learning Rate, LR)的变化以及训练的总轮数(Epochs)。本文将详细解析三个训练调度文件:schedule_1x.py、schedule_2x.py和schedule_20e.py,这三个文件分别对应不同的训练时长和策略。
区别
这三个文件的主要区别在于训练的总轮数(max_epochs)和学习率调度策略(param_scheduler)中的milestones参数。max_epochs决定了训练的总轮数,而milestones参数则定义了在哪些epoch时学习率会进行衰减。
schedule_1x.py:训练总轮数为12轮,学习率在第8轮和第11轮时衰减。schedule_2x.py:训练总轮数为24轮,学习率在第16轮和第22轮时衰减。schedule_20e.py:训练总轮数为20轮,学习率在第16轮和第19轮时衰减。
schedule_1x.py 解析
# training schedule for 1x
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=12, val_interval=1)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')# learning rate
param_scheduler = [dict(type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),dict(type='MultiStepLR',begin=0,end=12,by_epoch=True,milestones=[8, 11],gamma=0.1)
]# optimizer
optim_wrapper = dict(type='OptimWrapper',optimizer=dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001))# Default setting for scaling LR automatically
# - `enable` means enable scaling LR automatically
# or not by default.
# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
auto_scale_lr = dict(enable=False, base_batch_size=16)
训练配置(train_cfg)
type:'EpochBasedTrainLoop',表示训练循环是基于epoch的。max_epochs:12,训练的总轮数为12轮。val_interval:1,表示每1轮进行一次验证。
验证和测试配置(val_cfg 和 test_cfg)
- 两者都设置为默认的循环配置。
学习率调度(param_scheduler)
- 首先使用
LinearLR,从0开始线性增加到start_factor=0.001,直到end=500迭代。 - 然后使用
MultiStepLR,在第8轮和第11轮时,学习率乘以gamma=0.1进行衰减。
优化器配置(optim_wrapper)
- 使用
SGD作为优化器,初始学习率为0.02,动量为0.9,权重衰减为0.0001。
自动缩放学习率(auto_scale_lr)
enable:False,表示不自动缩放学习率。base_batch_size:16,基础批量大小。
schedule_2x.py 解析
# training schedule for 2x
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=24, val_interval=1)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')# learning rate
param_scheduler = [dict(type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),dict(type='MultiStepLR',begin=0,end=24,by_epoch=True,milestones=[16, 22],gamma=0.1)
]# optimizer
optim_wrapper = dict(type='OptimWrapper',optimizer=dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001))# Default setting for scaling LR automatically
# - `enable` means enable scaling LR automatically
# or not by default.
# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
auto_scale_lr = dict(enable=False, base_batch_size=16)
训练配置(train_cfg)
max_epochs:24,训练的总轮数为24轮。
学习率调度(param_scheduler)
- 使用
MultiStepLR,在第16轮和第22轮时,学习率乘以gamma=0.1进行衰减。
schedule_20e.py 解析
# training schedule for 20e
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=20, val_interval=1)
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')# learning rate
param_scheduler = [dict(type='LinearLR', start_factor=0.001, by_epoch=False, begin=0, end=500),dict(type='MultiStepLR',begin=0,end=20,by_epoch=True,milestones=[16, 19],gamma=0.1)
]# optimizer
optim_wrapper = dict(type='OptimWrapper',optimizer=dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001))# Default setting for scaling LR automatically
# - `enable` means enable scaling LR automatically
# or not by default.
# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
auto_scale_lr = dict(enable=False, base_batch_size=16)
训练配置(train_cfg)
max_epochs:20,训练的总轮数为20轮。
学习率调度(param_scheduler)
- 使用
MultiStepLR,在第16轮和第19轮时,学习率乘以gamma=0.1进行衰减。
总结
这三个训练调度文件主要区别在于训练的总轮数和学习率衰减的时机。通过调整这些参数,可以控制模型的训练过程,以达到更好的训练效果。在实际应用中,根据模型的复杂度和训练数据的量,可以灵活选择或调整这些参数。
相关文章:

〖open-mmlab: MMDetection〗解析文件:configs/_base_/schedules
详细解析三个训练调度文件:schedule_1x.py、schedule_2x.py、schedule_20e.py 在深度学习模型训练过程中,训练调度(Training Schedule)是至关重要的,它决定了模型训练过程中学习率(Learning Rate, LR&…...

Android之Handler是如何保证延迟发送的
目录 核心组件延迟发送消息的工作原理具体步骤1. 创建 Handler:2.发送延迟消息3.消息入队列4.消息出队和处理: 关键点总结 在 Android 中,Handler 是用于在不同线程之间传递和处理消息的工具。它可以用于定时任务、延迟执行任务等。Handler 如何保证延迟发送消息的核…...

定位信标、基站、标签,定位信标是什么
定位信标、基站、标签,定位信标是什么 今天给各位分享定位信标、基站、标签的知识,其中也会对定位信标是什么进行解释,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧! 怎样做人员定位啊? 〖…...

2024国赛数学建模B题完整分析参考论文38页(含模型和可运行代码)
2024 高教社杯全国大学生数学建模完整分析参考论文 B 题 生产过程中的决策问题 目录 摘要 一、问题重述 二、问题分析 三、 模型假设 四、 模型建立与求解 4.1问题1 4.1.1问题1思路分析 4.1.2问题1模型建立 4.1.3问题1样例代码(仅供参考) 4.…...

Hive是什么?
Apache Hive 是一个基于 Hadoop 的数据仓库工具,用于在 Hadoop 分布式文件系统(HDFS)上管理和查询大规模结构化数据集。Hive 提供了一个类似 SQL 的查询语言,称为 HiveQL,通过这种语言可以在 HDFS 上执行 MapReduce 作…...

计算机网络:http协议
计算机网络:http协议 一、本文内容与前置知识点1. 本文内容2. 前置知识点 二、HTTP协议工作简介1. 特点2. 传输时间分析3. http报文结构 三、HTTP版本迭代1. HTTP1.0和HTTP1.1主要区别2. HTTP1.1和HTTP2主要区别3. HTTPS与HTTP的主要区别 四、参考文献 一、本文内容…...

【stata】自写命令分享dynamic_est,一键生成dynamic effect
1. 命令简介 dynamic_est 是一个用于可视化动态效应(dynamic effect)的工具。它特别适用于事件研究(event study)或双重差分(Difference-in-Differences, DID)分析。通过一句命令即可展示动态效应…...

文心一言 VS 讯飞星火 VS chatgpt (342)-- 算法导论23.2 1题
一、对于同一个输入图,Kruskal算法返回的最小生成树可以不同。这种不同来源于对边进行排序时,对权重相同的边进行的不同处理。证明:对于图G的每棵最小生成树T,都存在一种办法来对G的边进行排序,使得Kruskal算法所返回的…...

部署若依Spring boot项目
nohup和& nohup命令解释 nohup命令:nohup 是 no hang up 的缩写,就是不挂断的意思,但没有后台运行,终端不能标准输入。 nohup :不挂断的运行,注意并没有后台运行的功能,就是指,用nohup运行命令可以使命令永久的执行下去,和用户终端没有关系,注意了nohup没有后台…...

oc打包:权限弹窗无法正常弹出
在遇到编写了权限无法弹出弹窗时,需要查看是不是调用时机不对,这里直接教万能改法。 将权限获取方法编写在applicationDidBecomeActive 进入前台的生命周期接口中,如下: if (@available(iOS 14, *)) {NSLog<...

深入理解RxJava:响应式编程的现代方式
在当今的软件开发世界中,异步编程和事件驱动的架构变得越来越重要。RxJava,作为响应式编程(Reactive Programming)的一个流行库,为Java和Android开发者提供了一种强大的方式来处理异步任务和事件流。本文将深入探讨RxJ…...
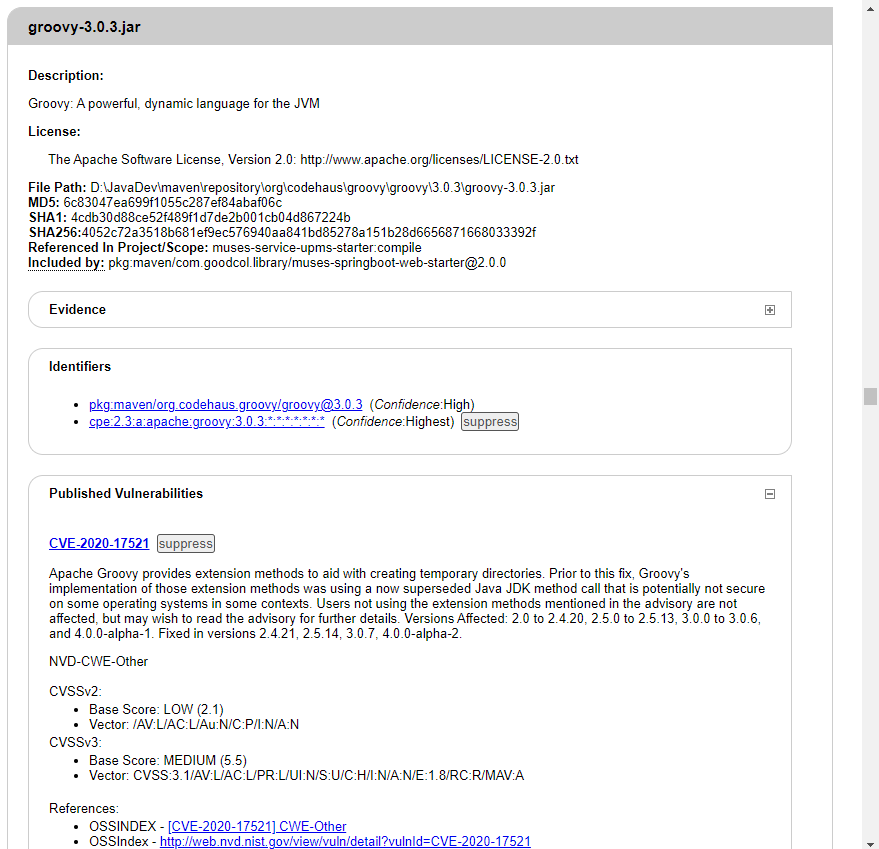
Maven 依赖漏洞扫描检查插件 dependency-check-maven 的使用
前言 在现代软件开发中,开源库的使用愈加普遍,然而这些开源库中的漏洞往往会成为潜在的安全风险。如何及时的发现依赖的第三方库是否存在漏洞,就变成很重要了。 本文向大家推荐一款可以进行依赖包漏洞检查的 maven 插件 dependency-check-m…...

2. 下载rknn-toolkit2项目
官网链接: https://github.com/airockchip/rknn-toolkit2 安装好git:[[1. Git的安装]] 下载项目: git clone https://github.com/airockchip/rknn-toolkit2.git或者直接去github下载压缩文件,解压即可。...

xhr、ajax、axois、fetch的区别
一、XMLHttpRequest (XHR)、AJAX、Axios 和 Fetch API 都是用于在不重新加载整个页面的情况下与服务器进行通信的技术和库。它们在处理超时、终止请求、进度反馈等机制上有一些显著的差异。以下是它们的详细比较: 1. XMLHttpRequest (XHR) XMLHttpRequest 是一种浏…...

【HuggingFace Transformers】OpenAIGPTModel源码解析
OpenAIGPTModel源码解析 1. GPT 介绍2. OpenAIGPTModel类 源码解析 说到ChatGPT,大家可能都使用过吧。2022年,ChatGPT的推出引发了广泛的关注和讨论。这款对话生成模型不仅具备了强大的语言理解和生成能力,还能进行非常自然的对话,…...

macOS安装Java和Maven
安装Java Java Downloads | Oracle 官网下载默认说最新的Java22版本,注意这里我们要下载的是Java8,对应的JDK1.8 需要登陆Oracle,没有账号的可以百度下。账号:908344069qq.com 密码:Java_2024 Java8 jdk1.8配置环境变量 open -e ~/.bash_p…...

SpringBoot教程(安装篇) | Elasticsearch的安装
SpringBoot教程(安装篇) | Elasticsearch的安装 一、确定Elasticsearch版本二、下载elasticsearch(windows版本)官网下载如何解压配置 允许 别人跨域 访问自己启动运行 三、Es可视化工具安装(elasticsearch-head&#…...

前端登录鉴权——以若依Ruoyi前后端分离项目为例解读
权限模型 Ruoyi框架学习——权限管理_若依框架权限-CSDN博客 用户-角色-菜单(User-Role-Menu)模型是一种常用于权限管理的设计模式,用于实现系统中的用户权限控制。该模型主要包含以下几个要素: 用户(User)…...

【Tools】大模型中的自注意力机制
摇来摇去摇碎点点的金黄 伸手牵来一片梦的霞光 南方的小巷推开多情的门窗 年轻和我们歌唱 摇来摇去摇着温柔的阳光 轻轻托起一件梦的衣裳 古老的都市每天都改变模样 🎵 方芳《摇太阳》 自注意力机制(Self-Attention)是一…...

PhotoZoom Classic 9软件新功能特性及安装激活图文教程
PhotoZoom Classic 9这款软件能够对数码图片进行放大,而且放大后的图片没有任何的品质的损坏,没有锯齿,不会失真,如果您有兴趣的话可以试试哦! PhotoZoom Classic 9软件新功能特性 通过屡获殊荣的 S-Spline XL 插值…...

MySQL JSON 类型操作:从入门到不踩坑
开场白 MySQL 5.7 加了 JSON 类型之后,很多人觉得终于可以在关系型数据库里存 JSON 了,不用再拆表了。但说实话,我一开始用 JSON 类型的时候也没少踩坑——查询语法记不住、索引不会建、JSON 路径表达式写错……后来用多了才发现,…...

2026校招人才整体素质洞察
导读:这份《2026 校招人才素质洞察报告》由前程无忧发布,围绕 AI 时代校招变局,依托 800 万 测评数据,系统剖析应届毕业生的素质特征,提出人才筛选新坐标,为企业校招提供战略方向与实操参考。关注公众号&a…...
)
ssm网上订餐系统(10089)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

对比直接使用官方API,通过Taotoken聚合调用的成本体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API,通过Taotoken聚合调用的成本体验 1. 从单一模型到聚合调用的成本视角 对于个人开发者或小型团队…...

B站视频转换终极指南:5步实现m4s到MP4的无损快速转换
B站视频转换终极指南:5步实现m4s到MP4的无损快速转换 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾在B站缓存了珍贵的视频…...

【DeepSeek缓存策略设计权威指南】:20年架构师亲授5大核心原则与3类典型场景落地实践
更多请点击: https://intelliparadigm.com 第一章:DeepSeek缓存策略设计的演进脉络与核心挑战 DeepSeek系列模型在推理服务中对缓存机制提出了严苛要求:既要应对长上下文带来的KV缓存爆炸式增长,又要兼顾多用户并发、动态批处理与…...

企业内统一AI开发环境借助TaotokenCLI工具一键配置
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一AI开发环境借助Taotoken CLI工具一键配置 在中大型企业的技术团队中,为所有开发者提供统一、标准化的AI服务…...

独立开发者如何利用 Taotoken 的 Token Plan 降低项目长期成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 的 Token Plan 降低项目长期成本 对于独立开发者而言,项目的长期维护成本是必须精打细算…...

ComfyUI-VideoHelperSuite视频工作流完整指南:从图像序列到专业视频的5个关键步骤
ComfyUI-VideoHelperSuite视频工作流完整指南:从图像序列到专业视频的5个关键步骤 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite ComfyUI-VideoHelpe…...

软件可维护性评估工具对比:从代码行数到AI模型,谁更懂开发者?
1. 项目概述:为什么我们需要重新审视可维护性评估?在软件开发的日常里,我们总在和时间赛跑。新功能要上线,Bug要修复,架构要优化,而代码库就在这日复一日的迭代中悄然生长。直到某一天,你发现修…...