Hive是什么?
Apache Hive 是一个基于 Hadoop 的数据仓库工具,用于在 Hadoop 分布式文件系统(HDFS)上管理和查询大规模结构化数据集。Hive 提供了一个类似 SQL 的查询语言,称为 HiveQL,通过这种语言可以在 HDFS 上执行 MapReduce 作业而无需编写复杂的代码。
Hive 的核心概念和特点
-
数据仓库工具:Hive 可以将结构化数据存储在 HDFS 上,用户可以通过 SQL 查询这些数据,主要用于大规模数据分析任务。
-
HiveQL(查询语言):Hive 的查询语言 HiveQL 类似于 SQL,但背后实际是将查询转换为 MapReduce、Tez 或 Spark 作业执行。
-
Schema on Read:Hive 不会强制要求在写入数据时进行数据的格式化或结构验证,而是在查询时根据定义的 schema 进行验证。
-
分区和分桶:Hive 支持通过分区和分桶来优化查询性能,特别是在处理大规模数据集时。
- 分区:可以将表中的数据按列(如日期、地区)划分成多个文件夹,从而加速特定查询。
- 分桶:可以进一步将分区数据划分为更小的子集,从而更好地平衡数据。
-
扩展性和兼容性:Hive 兼容 Hadoop 生态系统中的其他工具,比如 Tez 和 Spark,可以使用不同的执行引擎来提高性能。
Hive 架构
Hive 架构主要由以下几个组件组成:
-
Metastore:Hive 的元数据存储,用于保存数据库、表、分区等信息。Metastore 通常使用关系型数据库(如 MySQL、PostgreSQL)来存储这些元数据。
-
Driver:接收并解析用户的 HiveQL 查询,将其转换为执行计划,之后交由执行引擎(如 MapReduce、Tez 或 Spark)来执行。
-
Compiler:Hive 的查询编译器将 HiveQL 语句编译为有向无环图(DAG),并将其转化为执行作业。
-
Execution Engine:Hive 的执行引擎负责根据编译结果执行实际的查询。可以选择不同的执行引擎,比如 Hadoop 的 MapReduce、Apache Tez 或 Spark。
-
CLI/Thrift Server:Hive 提供了 CLI(命令行接口)和 Thrift Server,可以通过不同的方式与 Hive 进行交互。Thrift Server 允许其他程序使用 Hive 提供的 JDBC/ODBC 接口进行访问。
Hive 的使用
1. 创建数据库和表
-- 创建数据库
CREATE DATABASE IF NOT EXISTS mydb;-- 使用数据库
USE mydb;-- 创建表(例如存储用户信息)
CREATE TABLE IF NOT EXISTS users (id INT,name STRING,age INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
2. 加载数据
-- 从 HDFS 加载数据到表中
LOAD DATA INPATH '/user/hive/data/users.csv' INTO TABLE users;
3. 查询数据
-- 查询表中的所有数据
SELECT * FROM users;-- 基于条件查询
SELECT name, age FROM users WHERE age > 25;
4. 分区表
为了优化查询性能,可以创建分区表。分区表将数据按特定列(例如日期或地区)进行分割。
-- 创建一个按年份和月份分区的用户表
CREATE TABLE IF NOT EXISTS users_partitioned (id INT,name STRING,age INT
)
PARTITIONED BY (year INT, month INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;-- 加载分区数据
LOAD DATA INPATH '/user/hive/data/2023/01/users.csv' INTO TABLE users_partitioned PARTITION (year=2023, month=1);
5. Hive 分桶
分桶是进一步将数据划分为更小的子集,可以提升查询的均衡性和性能。
-- 创建带分桶的表
CREATE TABLE IF NOT EXISTS users_bucketed (id INT,name STRING,age INT
)
CLUSTERED BY (id) INTO 10 BUCKETS;
6. 管理 Hive 的元数据
Hive 的元数据存储在 Metastore 中,用户可以通过 Hive 的 DDL 语句管理元数据。
-- 查看所有数据库
SHOW DATABASES;-- 查看某个数据库中的表
SHOW TABLES IN mydb;-- 查看表的结构
DESCRIBE users;
Hive 的执行引擎
Hive 可以使用不同的执行引擎来执行查询。默认情况下,Hive 使用 Hadoop 的 MapReduce 引擎,但也支持 Apache Tez 和 Apache Spark 作为引擎。Tez 和 Spark 通常比 MapReduce 更快,适合实时或交互式查询。
- MapReduce:Hive 最早使用的执行引擎,适合大批量的离线处理任务。
- Tez:更高效的执行引擎,适合需要快速响应的大规模查询。
- Spark:兼具批处理和实时处理能力,能够显著提升查询性能。
Hive 的性能优化
-
分区和分桶:通过分区和分桶减少数据扫描量,优化查询性能。
-
MapJoin 优化:对于小表的 Join 操作,可以使用 MapJoin,减少 shuffle 的开销。
-
索引:Hive 支持表的索引,可以加快查询性能。
-
并行执行:Hive 可以配置并行执行多个查询操作,提升效率。
-
压缩:Hive 支持多种文件压缩格式,如 ORC、Parquet 等,既能减少存储空间,又能提高查询性能。
Hive 和传统数据库的比较
-
数据规模:Hive 专为处理超大规模数据而设计,适合数百 TB 甚至 PB 级别的数据分析,而传统数据库通常只能处理有限的数据规模。
-
Schema on Read:Hive 的 Schema on Read 模式允许在查询时解析数据结构,而传统数据库采用 Schema on Write,即在写入数据时需要先定义结构。
-
查询引擎:Hive 是基于分布式计算的,通过执行引擎(如 MapReduce、Tez、Spark)来处理分布式查询,而传统数据库采用集中式查询处理。
Hive 的应用场景
- 批量数据分析:Hive 适用于大规模数据的批量分析和 ETL 操作。
- 数据仓库解决方案:Hive 可以作为大数据平台上的数据仓库,处理海量数据并提供查询服务。
- 报表生成:Hive 可以用来生成定期的业务报表,尤其适合处理大数据报表。
总结
Apache Hive 是一个强大的数据仓库工具,特别适用于处理和分析大规模结构化数据。通过 HiveQL,用户可以使用类似 SQL 的语言与海量数据进行交互,而不需要深入理解 Hadoop 的底层工作机制。
相关文章:

Hive是什么?
Apache Hive 是一个基于 Hadoop 的数据仓库工具,用于在 Hadoop 分布式文件系统(HDFS)上管理和查询大规模结构化数据集。Hive 提供了一个类似 SQL 的查询语言,称为 HiveQL,通过这种语言可以在 HDFS 上执行 MapReduce 作…...

计算机网络:http协议
计算机网络:http协议 一、本文内容与前置知识点1. 本文内容2. 前置知识点 二、HTTP协议工作简介1. 特点2. 传输时间分析3. http报文结构 三、HTTP版本迭代1. HTTP1.0和HTTP1.1主要区别2. HTTP1.1和HTTP2主要区别3. HTTPS与HTTP的主要区别 四、参考文献 一、本文内容…...

【stata】自写命令分享dynamic_est,一键生成dynamic effect
1. 命令简介 dynamic_est 是一个用于可视化动态效应(dynamic effect)的工具。它特别适用于事件研究(event study)或双重差分(Difference-in-Differences, DID)分析。通过一句命令即可展示动态效应…...

文心一言 VS 讯飞星火 VS chatgpt (342)-- 算法导论23.2 1题
一、对于同一个输入图,Kruskal算法返回的最小生成树可以不同。这种不同来源于对边进行排序时,对权重相同的边进行的不同处理。证明:对于图G的每棵最小生成树T,都存在一种办法来对G的边进行排序,使得Kruskal算法所返回的…...

部署若依Spring boot项目
nohup和& nohup命令解释 nohup命令:nohup 是 no hang up 的缩写,就是不挂断的意思,但没有后台运行,终端不能标准输入。 nohup :不挂断的运行,注意并没有后台运行的功能,就是指,用nohup运行命令可以使命令永久的执行下去,和用户终端没有关系,注意了nohup没有后台…...

oc打包:权限弹窗无法正常弹出
在遇到编写了权限无法弹出弹窗时,需要查看是不是调用时机不对,这里直接教万能改法。 将权限获取方法编写在applicationDidBecomeActive 进入前台的生命周期接口中,如下: if (@available(iOS 14, *)) {NSLog<...

深入理解RxJava:响应式编程的现代方式
在当今的软件开发世界中,异步编程和事件驱动的架构变得越来越重要。RxJava,作为响应式编程(Reactive Programming)的一个流行库,为Java和Android开发者提供了一种强大的方式来处理异步任务和事件流。本文将深入探讨RxJ…...
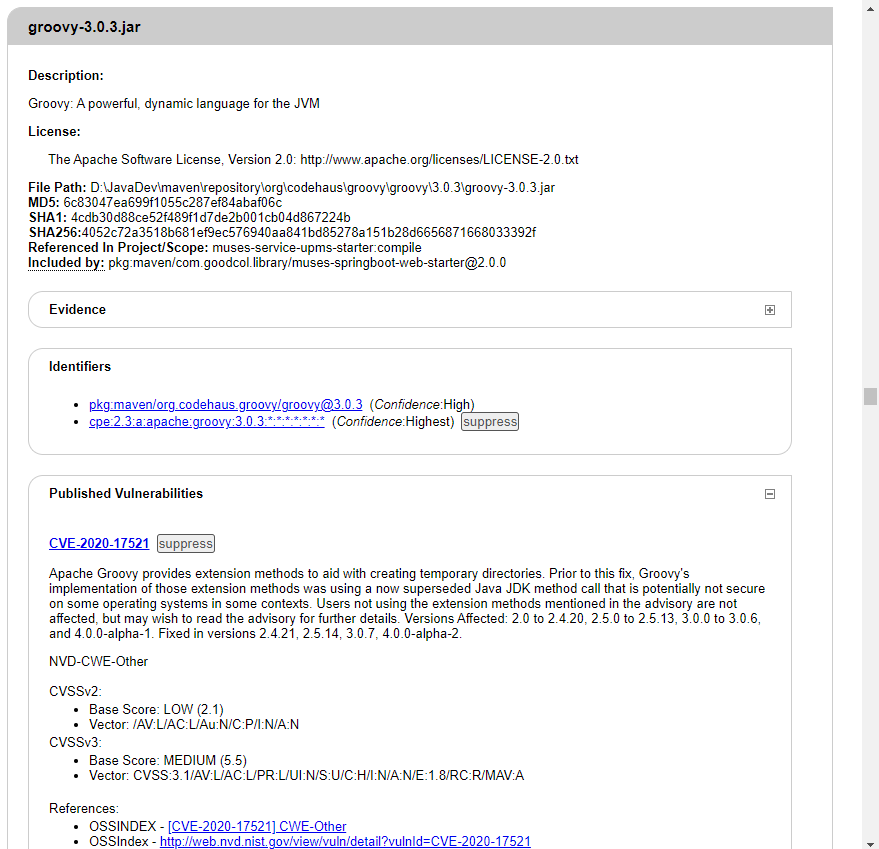
Maven 依赖漏洞扫描检查插件 dependency-check-maven 的使用
前言 在现代软件开发中,开源库的使用愈加普遍,然而这些开源库中的漏洞往往会成为潜在的安全风险。如何及时的发现依赖的第三方库是否存在漏洞,就变成很重要了。 本文向大家推荐一款可以进行依赖包漏洞检查的 maven 插件 dependency-check-m…...

2. 下载rknn-toolkit2项目
官网链接: https://github.com/airockchip/rknn-toolkit2 安装好git:[[1. Git的安装]] 下载项目: git clone https://github.com/airockchip/rknn-toolkit2.git或者直接去github下载压缩文件,解压即可。...

xhr、ajax、axois、fetch的区别
一、XMLHttpRequest (XHR)、AJAX、Axios 和 Fetch API 都是用于在不重新加载整个页面的情况下与服务器进行通信的技术和库。它们在处理超时、终止请求、进度反馈等机制上有一些显著的差异。以下是它们的详细比较: 1. XMLHttpRequest (XHR) XMLHttpRequest 是一种浏…...

【HuggingFace Transformers】OpenAIGPTModel源码解析
OpenAIGPTModel源码解析 1. GPT 介绍2. OpenAIGPTModel类 源码解析 说到ChatGPT,大家可能都使用过吧。2022年,ChatGPT的推出引发了广泛的关注和讨论。这款对话生成模型不仅具备了强大的语言理解和生成能力,还能进行非常自然的对话,…...

macOS安装Java和Maven
安装Java Java Downloads | Oracle 官网下载默认说最新的Java22版本,注意这里我们要下载的是Java8,对应的JDK1.8 需要登陆Oracle,没有账号的可以百度下。账号:908344069qq.com 密码:Java_2024 Java8 jdk1.8配置环境变量 open -e ~/.bash_p…...

SpringBoot教程(安装篇) | Elasticsearch的安装
SpringBoot教程(安装篇) | Elasticsearch的安装 一、确定Elasticsearch版本二、下载elasticsearch(windows版本)官网下载如何解压配置 允许 别人跨域 访问自己启动运行 三、Es可视化工具安装(elasticsearch-head&#…...

前端登录鉴权——以若依Ruoyi前后端分离项目为例解读
权限模型 Ruoyi框架学习——权限管理_若依框架权限-CSDN博客 用户-角色-菜单(User-Role-Menu)模型是一种常用于权限管理的设计模式,用于实现系统中的用户权限控制。该模型主要包含以下几个要素: 用户(User)…...

【Tools】大模型中的自注意力机制
摇来摇去摇碎点点的金黄 伸手牵来一片梦的霞光 南方的小巷推开多情的门窗 年轻和我们歌唱 摇来摇去摇着温柔的阳光 轻轻托起一件梦的衣裳 古老的都市每天都改变模样 🎵 方芳《摇太阳》 自注意力机制(Self-Attention)是一…...

PhotoZoom Classic 9软件新功能特性及安装激活图文教程
PhotoZoom Classic 9这款软件能够对数码图片进行放大,而且放大后的图片没有任何的品质的损坏,没有锯齿,不会失真,如果您有兴趣的话可以试试哦! PhotoZoom Classic 9软件新功能特性 通过屡获殊荣的 S-Spline XL 插值…...

【数据结构】直接插入排序
目录 一、基本思想 二、动图演示 三、思路分析 四、代码实现 五、易错提醒 六、时间复杂度分析 一、基本思想 直接插入排序(Straight Insertion Sort)是一种简单直观的排序算法,其基本思想是: 把待排序的一个记录按其关键码…...

JavaScript 实现虚拟滚动技术
虚拟滚动 虚拟滚动(有时称为 虚拟列表、虚拟滚动条)是 JavaScript 中的一种技术,旨在优化大数据量的列表渲染,尤其是当有成千上万的数据项时,直接渲染整个列表会导致性能问题。虚拟列表通过只渲染用户视口中可见的那一…...

【重学 MySQL】十八、逻辑运算符的使用
【重学 MySQL】十八、逻辑运算符的使用 AND运算符OR运算符NOT运算符异或运算符使用 XOR 关键字使用 BIT_XOR() 函数注意事项 注意事项 在MySQL中,逻辑运算符是构建复杂查询语句的重要工具,它们用于处理布尔类型的数据,进行逻辑判断和组合条件…...

关于 QImage原始数据格式与cv::Mat原始数据进行手码数据转换 的解决方法
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/141996117 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV…...

机器学习预测器评估随机数生成器最小熵:原理、实现与对比分析
1. 项目概述:当机器学习遇上随机性评估在信息安全领域,随机数生成器的质量是基石。无论是生成加密密钥、初始化向量,还是为各类协议提供随机性,其输出的不可预测性直接决定了整个系统的安全强度。我们如何量化这种“不可预测性”&…...

Web渗透信息收集实战:从被动侦察到精准测绘
1. 这不是“黑客速成班”,而是Web渗透工程师的日常切片很多人点开“精通 Kali Linux Web 渗透测试”这个标题,第一反应是:又要教怎么黑进某个网站了?其实恰恰相反——我带过的二十多个渗透测试新人里,前两周最常犯的错…...

SVM与逻辑回归:从线性分类到核方法的原理、对比与实践指南
1. 项目概述:从线性分类到非线性世界的两把钥匙在机器学习的工具箱里,支持向量机(SVM)和逻辑回归(LR)是两把经久不衰的“瑞士军刀”。它们都源于线性模型,却通过不同的哲学路径,解决…...

如何免费解锁Wand专业版功能:Wand-Enhancer完整使用指南
如何免费解锁Wand专业版功能:Wand-Enhancer完整使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为Wand(原WeMod&…...

化学教学平台——数据可视化与电化学AI动画推演
化学教学平台——数据可视化与电化学AI动画推演 1 项目概述 本化学教学平台是一套完整的前端Web应用,旨在为化学教育工作者和学生提供两个核心功能模块:数据智能查询与化学性质可视化(基于ECharts和D3.js),以及反应模拟预判——基于电化学原理的AI动画推演(基于Three.j…...

将 Hermes Agent 工具链接入 Taotoken 的配置要点解析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将 Hermes Agent 工具链接入 Taotoken 的配置要点解析 Hermes Agent 是一款功能强大的 AI 智能体开发框架,支持通过自定…...

第39天:SQL详解之DQL
Python学习100天(从入门到精通系列文章) 文章目录 Python学习100天(从入门到精通系列文章) 前言 一、基本查询与投影 1.1 查询所有列 1.2 投影与别名 二、数据筛选(WHERE 子句) 2.1 等值与比较筛选 2.2 多条件组合(AND / OR) 2.3 范围查询(BETWEEN) 2.4 CASE 表达式与…...

ncmdumpGUI:三步解密网易云音乐NCM文件,实现音乐自由播放
ncmdumpGUI:三步解密网易云音乐NCM文件,实现音乐自由播放 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了心爱…...

Gemini深度研究模式性能跃迁实录:单次查询响应缩短68%,附12项可复用Prompt工程Checklist
更多请点击: https://kaifayun.com 第一章:Gemini深度研究模式性能跃迁实录 Gemini深度研究模式(Deep Research Mode)并非简单调用多轮API,而是通过动态规划推理路径、自适应检索增强与跨文档语义对齐三大机制&#x…...

如何用3个步骤建立完全私有的点对点文件同步网络?
如何用3个步骤建立完全私有的点对点文件同步网络? 【免费下载链接】syncthing-android Wrapper of syncthing for Android. 项目地址: https://gitcode.com/gh_mirrors/sy/syncthing-android 你是否曾因云端服务的隐私隐患而犹豫不决?是否厌倦了每…...