数学建模笔记—— 主成分分析(PCA)
数学建模笔记—— 主成分分析
- 主成分分析
- 1. 基本原理
- 1.1 主成分分析方法
- 1.2 数据降维
- 1.3 主成分分析原理
- 1.4 主成分分析思想
- 2. PCA的计算步骤
- 3. 典型例题
- 4. 主成分分析说明
- 5. python代码实现
主成分分析
1. 基本原理
在实际问题研究中,多变量问题是经常会遇到的。变量太多,无疑会增加分析问题的难度与复杂性,而且在许多实际问题中,多个变量之间是具有一定的相关关系的。因此,人们会很自然地想到,能否在相关分析的基础上,用较少的新变量代替原来较多的旧变量,而且使这些较少的新变量尽可能多地保留原来变量所反映的信息?
一个简单的例子:
例如,某人要做一件上衣要测量很多尺寸,如身长、袖长、胸围、腰围、肩宽、肩厚等十几项指标,但某服装厂要生产一批新型服装绝不可能把尺寸的型号分得过多?
我们可以把多种指标中综合成几个少数的综合指标,做为分类的型号,将十几项指标综合成3项指标,一项是反映长度的指标,一项是反映胖瘦的指标,一项是反映特殊体型的指标。
1.1 主成分分析方法
在分析研究多变量的课题时,变量太多就会增加课题的复杂性。人们自然希望变量个数较少而得到的信息较多。在很多情形,变量之间是有一定的相关关系的,可以解释为这两个变量反映此课题的信息有一定的重叠。主成分分析是对于原先提出的所有变量,将重复的变量(关系紧密的变量)删去多余,建立尽可能少的新变量,使得这些新变量是两两不相关的,且这些新变量在反映课题的信息方面尽可能保持原有的信息。设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中可以取出几个较少的综合变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上用来降维的一种方法。
1.2 数据降维
降维是将高维度的数据(指标太多)保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。在实际的生产和应用中,降维在一定的信息损失范围内,可以为我们节省大量的时间和成本。降维也成为应用非常广泛的数据预处理方法。
降维优点:
- 使得数据集更易使用
- 除噪声
- 降低算法的计算开销
- 使得结果容易理解
1.3 主成分分析原理
PCA的主要目标是将特征维度变小,同时尽量减少信息损失。就是对一个样本矩阵,**一是换特征,**找一组新的特征来重新标识;**二是减少特征,**新特征的数目要远小于原特征的数目。
通过PCA将n维原始特征映射到k维(k<n)上,称这k维特征为主成分。需要强调的是,不是简单地从n维特征中去除其余n-k维特征,而是重新构造出全新的k维正交特征,且新生成的k维数据尽可能多地包含原来n维数据的信息。例如,使用PCA将20个相关的特征转化为5个无关的新特征,并且尽可能保留原始数据集的信息。
怎么找到新的维度呢?实质是数据间的方差够大,通俗地说,就是能够使数据到了新的维度基变换下,坐标点足够分散,数据间各有区分。
如图所示的左图中有5个离散点,降低维度,就是需要把点映射成一条线。将其映射到右图中黑色虚线上则样本变化最大,且坐标点更分散,这
条黑色虚线就是第一主成分的投影方向。
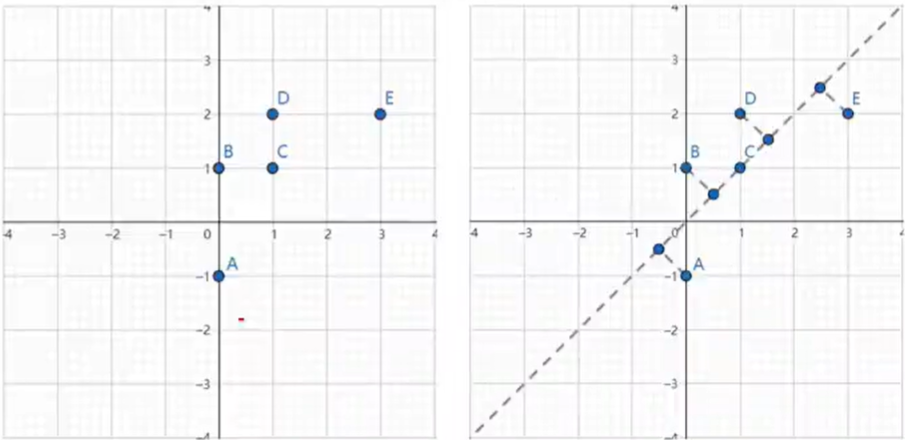
PCA是一种线性降维方法,即通过某个投影矩阵将高维空间中的原始样本点线性投影到低维空间,以达到降维的目的,线性投影就是通过矩阵变换的方式把数据映射到最合适的方向。
降维的几何意义可以理解为旋转坐标系,取前k个轴作为新特征。
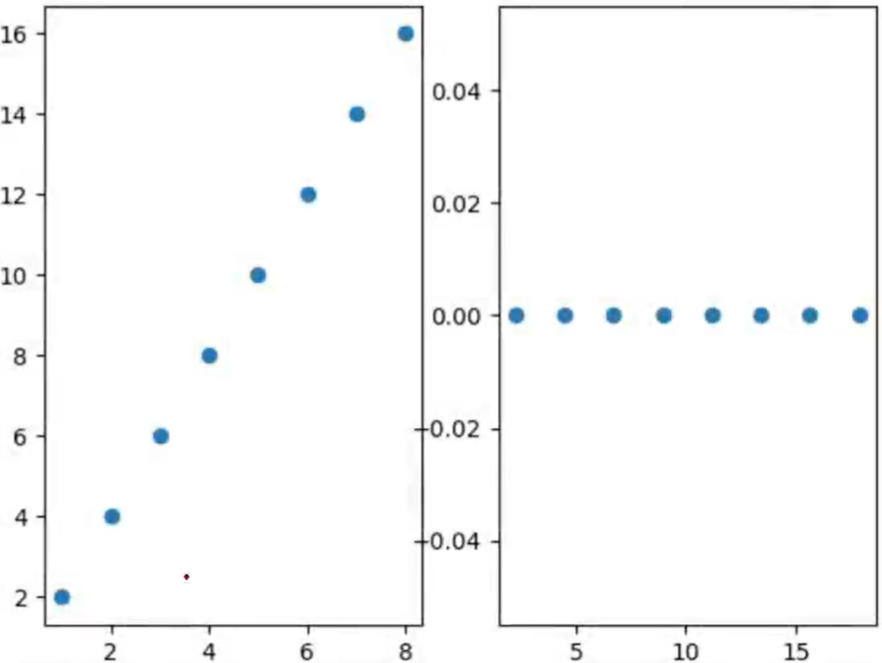
对于下图所示的情况,我们发现这些数据都几乎排列在一条直线上,并且在x轴方向和y轴方向的方差都比较大。但是如果把坐标轴旋转一定角度,使得这些数据在某个坐标轴的投影的方差比较大,便可以用新坐标系下方差较大的一个坐标轴坐标作为主成分。对于左图,数据为(1,2)、(2,4)…旋转坐标轴后,坐标为 ( 5 , 0 ) 、 ( 2 5 , 1 ) … … (\sqrt5,0)、\begin{pmatrix}2\sqrt5,1\end{pmatrix}\ldots\ldots (5,0)、(25,1)……这样主成分就是新坐标系下变量 x x x的数值 5 、 2 5 . . . . . . \sqrt{5}、2\sqrt{5}...... 5、25......
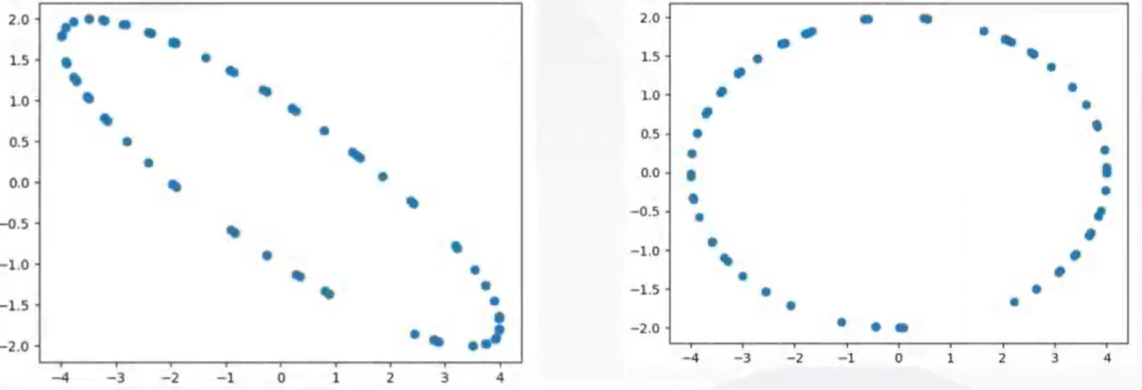
对于大多数情况,数据各个变量基本服从正态分布,所以变量为2的数据散点分布大致为一个椭圆,变量为3的散点分布大致为一个椭球,p个变量的数据大致分布在一个超椭圆。而通过旋转坐标系,使得超椭圆的长轴落在一个坐标轴上,其次超椭圆另一个轴也尽量落在坐标轴上。这样各个新的坐标轴上的坐标值便是相应的主成分。
例如,对于图示的数据,在x轴和y轴的方差都很大,所以可以旋转坐标系,使得椭圆两个轴尽量落在坐标轴上。这样,我们便以散点在新坐标系下的x坐标作为第一主成分(因为x方向方差最大),y轴的坐标为第二主成分。
主成分分析的理论推导较为复杂,需要借助投影寻踪,构造目标函数等方法来推导,在多元统计的相关书籍中都有详细讲解。但是其结论却是十分简洁。所以,如果只是需要实际应用,了解主成分分析的基本原理与实现方法便足够了。
降维的代数意义可以理解为:
m × n m\times n m×n阶的原始样本 X X X,与 n × k n\times k n×k阶矩阵 W W W做矩阵乘法运算 X × W X\times W X×W,即可得到 m × k m\times k m×k阶低维矩阵 Y Y Y,这里的 n × k n\times k n×k阶矩阵 W W W就是投影矩阵。
1.4 主成分分析思想
假设有 n n n个样本, p p p个指标,则可构成大小为 n × p n\times p n×p的样本矩阵 x : x: x:
x = [ x 11 x 12 ⋯ x 1 p x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋱ ⋮ x n 1 x n 2 ⋯ x n p ] = ( x 1 , x 2 , ⋯ , x p ) x=\begin{bmatrix}x_{11}&x_{12}&\cdots&x_{1p}\\x_{21}&x_{22}&\cdots&x_{2p}\\\vdots&\vdots&\ddots&\vdots\\x_{n1}&x_{n2}&\cdots&x_{np}\end{bmatrix}=\begin{pmatrix}x_1,x_2,\cdots,x_p\end{pmatrix} x= x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1px2p⋮xnp =(x1,x2,⋯,xp)
假设我们想找到新的一组变量 z 1 , z 2 , ⋅ ⋅ ⋅ , z m ( m ≤ p ) z_1,z_2,\cdotp\cdotp\cdotp,z_m(m\leq p) z1,z2,⋅⋅⋅,zm(m≤p),且它们满足:
{ z 1 = l 11 x 1 + l 12 x 2 + ⋯ + l 1 p x p z 2 = l 21 x 1 + l 22 x 2 + ⋯ + l 2 p x p ⋮ z m = l m 1 x 1 + l m 2 x 2 + ⋯ + l m p x p \begin{cases}z_1=l_{11}x_1+l_{12}x_2+\cdots+l_{1p}x_p\\z_2=l_{21}x_1+l_{22}x_2+\cdots+l_{2p}x_p\\\vdots\\z_m=l_{m1}x_1+l_{m2}x_2+\cdots+l_{mp}x_p\end{cases} ⎩ ⎨ ⎧z1=l11x1+l12x2+⋯+l1pxpz2=l21x1+l22x2+⋯+l2pxp⋮zm=lm1x1+lm2x2+⋯+lmpxp
系数 l i j l_{ij} lij的确定原则:
- z i z_i zi与 z j ( i ≠ j ; i , j = 1 , 2 , , m ) z_j(i\neq j;i,j=1,2,,m) zj(i=j;i,j=1,2,,m)相互无关
- z 1 z_1 z1是与 x 1 , x 2 , . . . , x p x_1,x_2,...,x_p x1,x2,...,xp 的一切线性组合中方差最大者
- z 2 z_2 z2与 z 1 z_1 z1不相关的 x 1 , x 2 , . . . , x p x_1,x_2,...,x_p x1,x2,...,xp 的一切线性组合中方差最大者
- 以此类推, z m z_m zm是与 z 1 , z 2 , . . . , z m − 1 z_1,z_2,...,z_{m-1} z1,z2,...,zm−1不相关的 x 1 , x 2 , . . . , x p x_1,x_2,...,x_p x1,x2,...,xp 的所有线性组合中方差最大者
- 新变量指标 z 1 , z 2 , . . . , z m z_1,z_2,...,z_m z1,z2,...,zm分别称为原变量指标 x 1 , x 2 , . . . , x p x_1,x_2,...,x_p x1,x2,...,xp的第一,第二,…,第m主成分
2. PCA的计算步骤
假设有 n n n个样本, p p p个指标,则可构成大小为 n × p n\times p n×p的样本矩阵 x : x: x:
x = [ x 11 x 12 ⋯ x 1 p x 21 x 22 ⋯ x 2 p ⋮ ⋮ ⋱ ⋮ x n 1 x n 2 ⋯ x n p ] = ( x 1 , x 2 , ⋯ , x p ) x=\begin{bmatrix}x_{11}&x_{12}&\cdots&x_{1p}\\x_{21}&x_{22}&\cdots&x_{2p}\\\vdots&\vdots&\ddots&\vdots\\x_{n1}&x_{n2}&\cdots&x_{np}\end{bmatrix}=\begin{pmatrix}x_1,x_2,\cdots,x_p\end{pmatrix} x= x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1px2p⋮xnp =(x1,x2,⋯,xp)
-
首先对其进行标准化处理
按列计算均值 x ‾ j = 1 n Σ i = 1 n x i j \overline x_j=\frac1n\Sigma_{i=1}^nx_{ij} xj=n1Σi=1nxij和标准差 S j = ∑ i = 1 n ( x i j − x j ‾ ) 2 n − 1 S_j= \sqrt {\frac {\sum _{i= 1}^n( x_{ij}- \overline {x_j}) ^2}{n- 1}} Sj=n−1∑i=1n(xij−xj)2 , 计算得标准化数据 X i j = x i j − x j ‾ s j X_{ij}=\frac{x_{ij}-\overline{x_j}}{s_j} Xij=sjxij−xj
原始样本矩阵经过标准化变为:
X = [ X 11 X 12 ⋯ X 1 p X 21 X 22 ⋯ X 2 p ⋮ ⋮ ⋱ ⋮ X n 1 X n 2 ⋯ X n p ] = ( X 1 , X 2 , ⋯ , X p ) \begin{aligned}&X=\begin{bmatrix}X_{11}&X_{12}&\cdots&X_{1p}\\X_{21}&X_{22}&\cdots&X_{2p}\\\vdots&\vdots&\ddots&\vdots\\X_{n1}&X_{n2}&\cdots&X_{np}\end{bmatrix}=\begin{pmatrix}X_1,X_2,\cdots,X_p\end{pmatrix}\end{aligned} X= X11X21⋮Xn1X12X22⋮Xn2⋯⋯⋱⋯X1pX2p⋮Xnp =(X1,X2,⋯,Xp) -
计算标准化样本的协方差矩阵/样本相关系数矩阵
R = [ r 11 r 12 ⋯ r 1 p r 21 r 22 ⋯ r 2 p ⋮ ⋮ ⋱ ⋮ r n 1 r n 2 ⋯ r n p ] 其中 r i j = 1 n − 1 ∑ k = 1 n ( X k i − X i ‾ ) ( X k j − X j ‾ ) \begin{aligned}&R=\begin{bmatrix}r_{11}&r_{12}&\cdots&r_{1p}\\r_{21}&r_{22}&\cdots&r_{2p}\\\vdots&\vdots&\ddots&\vdots\\r_{n1}&r_{n2}&\cdots&r_{np}\end{bmatrix}\\&\text{其中}\quad r_{ij}=\frac{1}{n-1}\sum_{k=1}^{n}\Big(X_{ki}-\overline{X_{i}}\Big)\Big(X_{kj}-\overline{X_{j}}\Big)\end{aligned} R= r11r21⋮rn1r12r22⋮rn2⋯⋯⋱⋯r1pr2p⋮rnp 其中rij=n−11k=1∑n(Xki−Xi)(Xkj−Xj) -
计算 R R R的特征值和特征向量
特征值: λ 1 ≥ λ 2 ≥ . . . ≥ λ p ≥ 0 特征向量: a 1 = [ a 11 a 21 ⋮ a p 1 ] , a 2 = [ a 12 a 22 ⋮ a p 2 ] , ⋯ , a p = [ a 1 p a 2 p ⋮ a p p ] \begin{aligned}&\text{特征值:}\quad\lambda_1\geq\lambda_2\geq...\geq\lambda_p\geq0\\&\text{特征向量:}\quad a_1=\begin{bmatrix}a_{11}\\a_{21}\\\vdots\\a_{p1}\end{bmatrix},a_2=\begin{bmatrix}a_{12}\\a_{22}\\\vdots\\a_{p2}\end{bmatrix},\cdots, a_p=\begin{bmatrix}a_{1p}\\a_{2p}\\\vdots\\a_{pp}\end{bmatrix}\end{aligned} 特征值:λ1≥λ2≥...≥λp≥0特征向量:a1= a11a21⋮ap1 ,a2= a12a22⋮ap2 ,⋯,ap= a1pa2p⋮app -
计算主成分贡献率以及累计贡献率
贡献率 α i λ i ∑ k = 1 p λ k ( i = 1 , 2 , . . . , p ) 累计贡献率 ∑ G ∑ k − 1 i λ k ∑ k = 1 p λ k ( i = 1 , 2 , . . . , p ) \text{贡献率}\alpha_i\frac{\lambda_i}{\sum_{k=1}^p\lambda_k}(i=1,2,...,p)\quad\text{累计贡献率}\sum G\frac{\sum_{k-1}^i\lambda_k}{\sum_{k=1}^p\lambda_k}(i=1,2,...,p) 贡献率αi∑k=1pλkλi(i=1,2,...,p)累计贡献率∑G∑k=1pλk∑k−1iλk(i=1,2,...,p) -
写出主成分
一般取累计贡献率超过80%的特征值所对应的第一、第二、…第 m ( m ≤ p ) m(m\le p) m(m≤p)个主成分。第 i i i个主成分:
F i = a 1 i X 1 + a 2 i X 2 + . . . + a p i X p ( i = 1 , 2 , . . . , m ) F_{i}=a_{1i}X_{1}+a_{2i}X_{2}+...+a_{pi}X_{p} (i=1 ,2 ,... ,m) Fi=a1iX1+a2iX2+...+apiXp(i=1,2,...,m) -
根据系数分析主成分代表的意义
对于某个主成分而言,指标前面的系数越大,代表该指标对于该主成分的影响越大。
-
利用主成分的结果进行后续的分析
- 主成分得分
- 聚类分析
- 回归分析
3. 典型例题
在制定服装标准的过程中,对128名成年男子的身材进行了测量,每人测得的指标中含有这样的六项:身高 ( x 1 ) (x_1) (x1)、坐高 ( x 2 ) (x_2) (x2)、胸围 ( x 3 ) (x_3) (x3)、手臂长 ( x 4 ) (x_4) (x4)、肋围 ( x 5 ) (x_5) (x5)、腰围 ( x 6 ) (x_6) (x6)。所得样本相关系数矩阵(对称矩阵)如下表:
x 1 x_{1} x1 x 2 x_{2} x2 x 3 x_{3} x3 x 4 x_{4} x4 x 5 x_{5} x5 x 6 x_{6} x6 x 1 x_1 x1 1 0.79 0.36 0.76 0.25 0.51 x 2 x_2 x2 0.79 1 0.31 0.55 0.17 0.35 x 3 x_3 x3 0.36 0.31 1 0.35 0.64 0.58 x 4 x_4 x4 0.76 0.55 0.35 1 0.16 0.38 x 5 x_5 x5 0.25 0.17 0.64 0.16 1 0.63 x 6 x_6 x6 0.51 0.35 0.58 0.38 0.63 1 注意:本题给我们的数据直接就是样本相关系数矩阵,一般来说,大家自己建模的时候,得到的是原始数据。
经过计算,相关系数矩阵的特征值、相应的特征向量以及贡献率列于下表:
| 特征向量 | a 1 a_{1} a1 | a 2 a_{2} a2 | a 3 a_{3} a3 | a 4 a_4 a4 | a 5 a_5 a5 | a 6 a_{6} a6 |
|---|---|---|---|---|---|---|
| x 1 : x_1: x1: 身高 | 0.469 | -0.365 | 0.092 | -0.122 | -0.080 | -0.786 |
| x 2 : x_2: x2: 坐高 | 0.404 | -0.397 | 0.613 | 0.326 | 0.027 | 0.443 |
| x 3 : x_3: x3: 胸围 | 0.394 | 0.397 | -0.279 | 0.656 | 0.405 | -0.125 |
| x 4 : x_4: x4: 手臂长 | 0.408 | -0.365 | -0.705 | -0.108 | -0.235 | 0.371 |
| x 5 : x_5: x5: 肋围 | 0.337 | 0.569 | 0.164 | -0.019 | -0.731 | 0.034 |
| x 6 : x_6: x6: 腰围 | 0.427 | 0.308 | 0.119 | -0.661 | 0.490 | 0.179 |
| 特征值 | 3.287 | 1.406 | 0.459 | 0.426 | 0.295 | 0.126 |
| 贡献率 | 0.548 | 0.234 | 0.077 | 0.071 | 0.049 | 0.021 |
| 累计贡献率 | 0.548 | 0.782 | 0.859 | 0.930 | 0.979 | 1.000 |
从表中可以看到前三个主成分的累计贡献率达85.9%,因此可以考虑只取三个主成分,他们能够很好地概括原始变量。
写出主成分并分析解释含义
F 1 = 0.469 X 1 + 0.404 X 2 + 0.394 X 3 + 0.408 X 4 + 0.339 X 5 + 0.427 X 6 F 2 = − 0.365 X 1 − 0.397 X 2 + 0.397 X 3 − 0.365 X 4 + 0.569 X 5 + 0.308 X 6 F 3 = 0.092 X 1 + 0.613 X 2 − 0.279 X 3 − 0.705 X 4 + 0.164 X 5 + 0.119 X 6 X i 均是标准化后的指标, x i : 身高、坐高、胸围、手臂长、肋围和腰围 F_{1}=0.469X_{1}+0.404X_{2}+0.394X_{3}+0.408X_{4}+0.339X_{5}+0.427X_{6}\\F_{2}=-0.365X_{1}\:-\:0.397X_{2}+0.397\:X_{3}\:-\:0.365X_{4}+0.569X_{5}+0.308X_{6}\\F_{3}=0.092X_{1}\:+0.613X_{2}\:-0.279X_{3}\:-0.705X_{4}\:+0.164X_{5}\:+0.119X_{6}\\ X_i均是标准化后的指标,x_i:身高、坐高、胸围、手臂长、肋围和腰围 F1=0.469X1+0.404X2+0.394X3+0.408X4+0.339X5+0.427X6F2=−0.365X1−0.397X2+0.397X3−0.365X4+0.569X5+0.308X6F3=0.092X1+0.613X2−0.279X3−0.705X4+0.164X5+0.119X6Xi均是标准化后的指标,xi:身高、坐高、胸围、手臂长、肋围和腰围
- 第一主成分 F 1 F_{1} F1对所有(标准化)原始变量都有近似相等的正载荷,故称第一主成分为**(身材)大小成分**
- 第二主成分 F 2 F_2 F2在 X 3 , X 5 , X 6 X_3,X_5,X_6 X3,X5,X6上有中等程度的正载荷,而在 X 1 , X 2 , X 4 X_1,X_2,X_4 X1,X2,X4上有中等程度的负载荷,称第二主成分为形状成分(或胖瘦成分)
- 第三主成分 F 3 F_3 F3在 X 2 X_2 X2上有大的正载荷,在 X 4 X_4 X4上有大的负载荷,而在其余变量上的载荷都较小,可称为第三主成分为臂长成分
- 当然,由于第三主成分贡献率不算高,实际意义也不太重要,因此我们可以考虑只取前两个。
4. 主成分分析说明
在主成分分析中,我们首先应保证所提取的前几个主成分的累计贡献率达到一个较高的水平,其次对这些被提取的主成分必须都能够给出符合实际背景和意义的解释。
主成分的解释其含义一般多少带有点模糊性,不像原始变量的含义那么清楚、确切,这是变量降维过程中不得不付出的代价。因此,提取的主成分个数m通常应明显小于原始变量个数p(除非p本身较小),否则维数降低的“利”可能抵不过主成分含义不如原始变量清楚的“弊”。
如果原始变量之间具有较高的相关性,则前面少数几个主成分的累计贡献率通常就能达到一个较高水平,也就是说,此时的累计贡献率通常较易得到满足。主成分分析的困难之处主要在于要能够给出主成分的较好解释,所提取的主成分中如有一个主成分解释不了,整个主成分分析也就失败了。主成分分析是变量降维的一种重要、常用的方法,简单的说,该方法要应用得成功,一是靠原
始变量的合理选取,二是靠“运气”。– 参考教材:《应用多元统计分析》王学民
5. python代码实现
数据data.csv内容如下:
年份,单产,种子费,化肥费,农药费,机械费,灌溉费
1990,1017.0,106.05,495.15,305.1,45.9,56.1
1991,1036.5,113.55,561.45,343.8,68.55,93.3
1992,792.0,104.55,584.85,414.0,73.2,104.55
1993,861.0,132.75,658.35,453.75,82.95,107.55
1994,901.5,174.3,904.05,625.05,114.0,152.1
1995,922.5,230.4,1248.75,834.45,143.85,176.4
1996,916.5,238.2,1361.55,720.75,165.15,194.25
1997,976.5,260.1,1337.4,727.65,201.9,291.75
1998,1024.5,270.6,1195.8,775.5,220.5,271.35
1999,1003.5,286.2,1171.8,610.95,195.0,284.55
2000,1069.5,282.9,1151.55,599.85,190.65,277.35
2001,1168.5,317.85,1105.8,553.8,211.05,290.1
2002,1228.5,319.65,1213.05,513.75,231.6,324.15
2003,1023.0,368.4,1274.1,567.45,239.85,331.8
2004,1144.5,466.2,1527.9,487.35,408.0,336.15
2005,1122.0,449.85,1703.25,555.15,402.3,358.8
2006,1276.5,537.0,1888.5,637.2,480.75,428.4
2007,1233.0,565.5,2009.85,715.65,562.05,456.9
源码如下:
import pandas as pd
import numpy as np# 在python中导入scipy库的linalg模块
# scipy是python中的一个科学计算库,linalg模块包含了线性代数的函数
from scipy import linalg# 读取csv文件的后五行
df = pd.read_csv('data.csv', usecols=[2, 3, 4, 5, 6])
# print(df)# df.to_numpy()是pandas对象中的一个方法,用于将DataFrame转换为NumPy数组
x = df.to_numpy()
# print(x)# 标准化数据
X = (x-np.mean(x, axis=0))/np.std(x, ddof=1, axis=0)# 计算协方差矩阵
R = np.cov(X.T)# 计算特征值和特征向量
eigvals, eigvecs = linalg.eigh(R)
# 将特征值数组按降序排列
eigvals = eigvals[::-1]
# 将特征向量数组按降序排列
eigvecs = eigvecs[:, ::-1]# 计算主成分贡献率和累积贡献率
contribution_rate = eigvals/sum(eigvals)
# np.cumsum()是numpy中的一个函数,用于计算数组的累积和
cumulative_contribution_rate = np.cumsum(contribution_rate)# 打印结果
print("特征值为:")
print(eigvals)
print("贡献率为:")
print(contribution_rate)
print("累积贡献率为:")
print(cumulative_contribution_rate)
print("与特征值对应的特征向量为:")
print(eigvecs)
输出结果:
特征值为:
[4.09453559 0.79266524 0.08165257 0.02069963 0.01044696]
贡献率为:
[0.81890712 0.15853305 0.01633051 0.00413993 0.00208939]
累积贡献率为:
[0.81890712 0.97744017 0.99377068 0.99791061 1. ]
与特征值对应的特征向量为:
[[-0.48104689 0.23837363 -0.01782683 -0.0038534 0.84346859][-0.48753322 -0.07920883 -0.33594594 -0.7565078 -0.26622096][-0.28138862 -0.92242424 -0.00452323 0.24430868 0.10122639][-0.47315152 0.26834026 -0.46128305 0.60577733 -0.35266544][-0.47733984 0.11845256 0.82098722 0.03206562 -0.28821424]]
相关文章:
数学建模笔记—— 主成分分析(PCA)
数学建模笔记—— 主成分分析 主成分分析1. 基本原理1.1 主成分分析方法1.2 数据降维1.3 主成分分析原理1.4 主成分分析思想 2. PCA的计算步骤3. 典型例题4. 主成分分析说明5. python代码实现 主成分分析 1. 基本原理 在实际问题研究中,多变量问题是经常会遇到的。变量太多,无…...

@vueup/vue-quill使用quill-better-table报moduleClass is not a constructor
quill官方中文文档:https://www.kancloud.cn/liuwave/quill/1434144 扩展表格的使用 注意:想要使用表格 quill的版本要是2.0以后 升级到这个版本后 其他一些插件就注册不了了。 安装: npm install quilllatest 版本需要大于2.0版本 npm…...

gpp.bat,g++编译C++源文件的批处理
今天编写一个gpp.bat文件,是专门编译C源文件的批处理,内容如下: g %1.cpp -o %1.exegpp.bat的文件路径:D:\YcjWork\CppTour\gpp.bat 使用方法,在CMD下运行(//两个斜杠后面的内容是注释): //运行gpp.bat&…...

JDBC:连接数据库
文章目录 报错 报错 Exception in thread “main” java.sql.SQLException: Can not issue SELECT via executeUpdate(). 最后这里输出的还是地址,就是要重写toString()方法,但是我现在还不知道怎么写 修改完的代码,但是数据库显示&#…...

【赵渝强老师】大数据主从架构的单点故障
大数据体系架构中的核心组件都是主从架构,即:存在一个主节点和多个从节点,从而组成一个分布式环境。下图为展示了大数据体系中主从架构的相关组件。 视频讲解如下: 大数据主从架构的单点故障 【赵渝强老师】大数据主从架构的…...

【AutoX.js】选择器 UiSelector
文章目录 原文:https://blog.c12th.cn/archives/37.html选择器 UiSelector笔记直接分析层次分析代码分析 最后 原文:https://blog.c12th.cn/archives/37.html 选择器 UiSelector 笔记 AutoX.js UiSelector 直接分析 用于简单、最直接的查找控件 开启悬…...

Elasticsearch数据写入过程
1. 写入请求 当一个写入请求(如 Index、Update 或 Delete 请求)通过REST API发送到Elasticsearch时,通常包含一个文档的内容,以及该文档的索引和ID。 2. 请求路由 协调节点:首先,请求会到达一个协调节点…...

FreeRTOS-基本介绍和移植STM32
FreeRTOS-基本介绍和STM32移植 一、裸机开发和操作系统开发介绍二、任务调度和任务状态介绍2.1 任务调度2.1.1 抢占式调度2.1.2 时间片调度 2.2 任务状态 三、FreeRTOS源码和移植STM323.1 FreeRTOS源码3.2 FreeRTOS移植STM323.2.1 代码移植3.2.2 时钟中断配置 一、裸机开发和操…...

在C++中,如何避免出现Bug?
C中的主要问题之一是存在大量行为未定义或对程序员来说意外的构造。我们在使用静态分析器检查各种项目时经常会遇到这些问题。但正如我们所知,最佳做法是在编译阶段尽早检测错误。让我们来看看现代C中的一些技术,这些技术不仅帮助编写简单明了的代码&…...

Linux 操作系统 进程(1)
什么是进程 想要了解什么是进程,或者说,为什么会有进程这个概念,我们就需要去了解现代计算机的设计框架(冯诺依曼体系): 计算机从设计之初就以执行程序为核心任务,也就是运算器从内存中读取,也只从内存中…...

clickhouse-v24.1-离线部署
部署版本 数据库版本:24.1.1.2048 jdk版本:jdk8 4个文件(三个ck的包): OpenJDK8U-jdk_x64_linux_hotspot_8u382b05.tar clickhouse-client-24.1.1.2048.x86_64.rpm clickhouse-common-static-24.1.1.2048.x86_64.…...

安卓13删除app 链接库警告弹窗Detected problems with app native
总纲 android13 rom 开发总纲说明 文章目录 1.前言2.问题分析3.代码修改彩蛋1.前言 有些客户的APP,打开首次会弹窗提示窗口, Detected problems with app native libraries (please consult log for detail):,需要删除这个窗口,避免挡住用户APP。而且这个提示有些app是以t…...

第四次北漂----挣个独立游戏的素材钱
第四次北漂,在智联招聘上,有个小公司主动和我联系。面试了下,决定入职了,osg/osgearth的。月薪两万一。 大跌眼镜的是,我入职后,第一天的工作内容就是接手他的工作,三天后他就离职了。 我之所以…...

漫谈设计模式 [12]:模板方法模式
引导性开场 菜鸟:老大,我最近在做一个项目,遇到了点麻烦。我们有很多相似的操作流程,但每个流程的细节又有些不同。我写了很多重复的代码,感觉很乱。你有啥好办法吗? 老鸟:嗯,听起…...

CSS学习10[重点]--浮动、浮动的效果以及内幕特性
CSS布局——浮动 前言一、普通流二、浮动三、什么是浮动?四、浮动的内幕特性总结 前言 CSS盒子布具的三种机制:普通流(标准流)、定位、浮动。 一、普通流 普通流:网页内元素自上而下,从左到右排序。 二、浮动 浮动…...
matlab基本语法
基本语法 变量命名规则 区分大小写长度不超过63位字母开头,可以有字母、下划线和数字组成,但不能使用标点应该简洁明了 命令行窗口 >>>clc 清楚命令窗口 >>> claer all 清理工作区内容 注释 %% 注释符 数据类型 1.数字 11 2…...

【Leetcode152】乘积最大子数组(动态规划)
文章目录 一、题目二、思路三、代码 一、题目 二、思路 (0)读懂题意:题目的“连续”是指位置的连续,而不是说数字的连续,这是个大坑。 (1)确定状态:定义两个状态来记录当前子数组的…...

STM32(十二):DMA直接存储器存取
DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设和存储器或者存储器和存储器之间的高速数据传输,无须CPU干预,节省了CPU的资源。(运行内存SRAM、程序存储器Flash、寄存器) 12个独立可配置的通道&…...
的“炒股”经历和感受)
关于我2020年7月至今(2024.9)的“炒股”经历和感受
声明:我远不是一个成熟的投资者(这个名词太大了,我那三瓜两枣似乎完全配不上投资者这三个字,或者“小小散”更加贴切)。本文不构成任何入(股)市的引导或者买卖股票的建议。 “炒股”这个词,相信绝大多数人看来都-是一个贬义词&…...

【Tools】Prompt Engineering简介
摇来摇去摇碎点点的金黄 伸手牵来一片梦的霞光 南方的小巷推开多情的门窗 年轻和我们歌唱 摇来摇去摇着温柔的阳光 轻轻托起一件梦的衣裳 古老的都市每天都改变模样 🎵 方芳《摇太阳》 大模型中的Prompt Engineering是指为了提高大模型在特定任…...

3个场景告诉你:为什么你需要PowerToys Text Extractor
3个场景告诉你:为什么你需要PowerToys Text Extractor 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_Trending/po/PowerToys…...
)
94、【Agent】【OpenCode】edit 工具提示词(参数内容)
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除 背景 上篇 blog 【Agent】【OpenCode】edit 工…...

【ChatGPT投资人邮件撰写黄金法则】:20年FA/VC顾问亲授——3类高回复率模板+5个致命话术雷区
更多请点击: https://codechina.net 第一章:ChatGPT投资人邮件撰写的核心认知与底层逻辑 投资人邮件不是信息的简单堆砌,而是认知对齐、信任构建与决策催化三重目标的高度凝练表达。其底层逻辑根植于风险投资行业的决策机制——LP关注资金效…...

对比直接使用官方API,通过Taotoken聚合调用的成本体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API,通过Taotoken聚合调用的成本体验 1. 从单一模型到聚合调用的成本视角 对于个人开发者或小型团队…...
)
告别命令行!在Ubuntu标题栏实时显示网速和CPU的保姆级教程(Indicator-Sysmonitor)
在Ubuntu标题栏打造个性化系统监控中心:Indicator-Sysmonitor终极指南每次打开终端查看系统资源占用是否让你感到繁琐?作为长期使用Ubuntu的开发者,我深刻理解高效监控系统状态的重要性。Indicator-Sysmonitor这款轻量级工具彻底改变了我的工…...

5分钟掌握DLSS Swapper:免费开源游戏性能优化神器
5分钟掌握DLSS Swapper:免费开源游戏性能优化神器 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为PC游戏玩家设计的免费开源工具,能够智能管理、下载和替换游戏中的DLSS、…...

【太阳能】基于matlab PEM电解模拟了24小时太阳能绿色氢电厂(每小时太阳能发电量、氢气产量、用水量、储罐动态以及每公斤H₂的成本【含Matlab源码 15561期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

【稻米计数】形态学稻米计数【含Matlab源码 15562期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab领域博客之家💞&…...

公平AI研究的组织协调困境:从技术理想走向工程实践
1. 公平AI研究的十字路口:当技术理想遭遇组织现实如果你最近几年关注过人工智能的新闻,大概率会看到这样的标题:“某招聘算法被曝歧视女性”、“某医疗AI系统对少数族裔诊断准确率显著偏低”。这些并非科幻小说的情节,而是算法偏见…...

OpenAI破解80年数学猜想:AI首次完成原创性科学突破
2026年5月21日,一个普通的工作日,数学界却迎来了一场地震。OpenAI的内部通用推理模型,独立证明了离散几何领域一个悬置近80年的核心猜想——而且不是证明了它成立,而是直接推翻了它。 目录 引言:一个简单到小学生都能理解的问题 Erdős单位距离猜想:80年的数学悬案 AI突破…...