【附答案】C/C++ 最常见50道面试题
文章目录
- 面试题 1:深入探讨变量的声明与定义的区别
- 面试题 2:编写比较“零值”的`if`语句
- 面试题 3:深入理解`sizeof`与`strlen`的差异
- 面试题 4:解析C与C++中`static`关键字的不同用途
- 面试题 5:比较C语言的`malloc`与C++的`new`
- 面试题 6:实现一个“标准”的`MIN`宏
- 面试题 7:指针是否可以是`volatile`
- 面试题 8:探讨`a`和`&a`的区别
- 面试题 9:详述C/C++程序编译时的内存分配
- 面试题 10:区分`strcpy`、`sprintf`与`memcpy`
- 面试题 11:设置特定地址的整型变量值
- 面试题 12:面向对象的三大特征
- 面试题 13:探讨C++中的空类及其成员函数
- 面试题 14:拷贝构造函数与赋值运算符的深入分析
- 面试题 15:设计一个不允许继承的C++类
- 面试题 16:访问基类的私有虚函数
- 面试题 17:类成员函数的重写、重载和隐藏的区别
- 面试题 18:多态实现的原理
- 面试题 19:链表与数组的比较
- 面试题 20:单链表反序的实现
- 面试题 21:深入分析队列和栈的异同及其内存分配
- 面试题 22:实现队列功能的经典栈操作
- 面试题 23:计算二叉树的深度
- 面试题 24:直接插入排序的实现
- 面试题 25:冒泡排序的实现
- 面试题 26:深入探讨直接选择排序的实现及其不稳定性
- 面试题 27:堆排序的编程实现与分析
- 面试题 28:基数排序的编程实现与优化策略
- 面试题 29:对编程规范的深入理解
- 面试题 30:数据类型转换的正确性分析
- 面试题 31:逻辑运算符与位运算符的区别
- 面试题 32:C++引用与C语言指针的比较
- 面试题 33:探索二叉树中路径和的求解策略
- 面试题 34:编写一个安全的“MIN”宏
- 面试题 35:深入理解`typedef`和`define`的区别
- 面试题 36:探讨`const`关键字的多方面用途
- 面试题 37:分析`static`关键字的多重作用
- 面试题 38:解释`extern`关键字的作用
- 面试题 39:讨论流操作符重载返回引用的重要性
- 面试题 40:区分指针常量与常量指针
- 面试题 41:深入分析数组名与指针在C++中的差异
- 面试题 42:探讨避免“野指针”的最佳实践
- 面试题 43:常引用的应用及其重要性
- 面试题 44:实现字符串到整数的转换函数
- 面试题 45:`strcpy`、`sprintf`与`memcpy`的适用场景分析
- 面试题 46:编写一个C语言的死循环程序
- 面试题 47:位操作技巧
- 面试题 48:评论中断服务程序的编写
- 面试题 49:构造函数能否为虚函数
- 面试题 50:面向对象编程的理解
面试题 1:深入探讨变量的声明与定义的区别
在编程中,变量的声明指的是告知编译器变量的名称和类型,但不分配内存空间。声明可以多次,常见于头文件中,用于模块间的接口声明。使用extern关键字声明的变量,意味着其定义在别处,通常在另一个文件中。
相对地,定义则是创建一个具有存储空间的变量实例。定义只能有一次,通常在源文件中,确保为变量分配内存空间。例如,全局变量和局部变量的定义就是分配内存并初始化的过程。
面试题 2:编写比较“零值”的if语句
在JavaScript中,对基本数据类型与“零值”的比较可以通过以下if语句实现:
// 对于布尔型数据:
if (flag) {// A: 执行当flag为true时的操作
} else {// B: 执行当flag为false时的操作
}// 对于整数型数据:
if (0 !== flag) {// A: 执行当flag非零时的操作
} else {// B: 执行当flag为零时的操作
}// 对于指针型数据:
if (NULL === flag) {// A: 执行当flag为空指针时的操作
} else {// B: 执行当flag非空指针时的操作
}// 对于浮点型数据:
if ((flag >= -NORM) && (flag <= NORM)) {// A: 执行当flag在正常范围内时的操作
} else {// B: 执行当flag超出正常范围时的操作
}
注意,为避免潜在的赋值错误,应将“零值”置于比较操作的左侧。
面试题 3:深入理解sizeof与strlen的差异
sizeof是一个编译时确定的运算符,可以用于获取变量或类型在内存中占用的字节数。它在编译阶段就已确定,不依赖于运行时数据。
相对地,strlen是一个运行时确定的库函数,专门用于计算以空字符\0结尾的字符串的实际字符数。由于它需要遍历字符串,因此其结果仅在运行时才可知。
面试题 4:解析C与C++中static关键字的不同用途
在C语言中,static用于修饰局部静态变量(延长生命周期至程序结束)、外部静态变量(限制链接至其他文件)和静态函数(限制函数的作用域至定义它的文件内)。
在C++中,static除了上述功能外,还用于类中定义静态成员变量和静态成员函数。静态成员属于整个类,而非单个对象,常用于计数器或共享数据的存储。
面试题 5:比较C语言的malloc与C++的new
malloc和free是C标准库函数,用于动态内存的分配与释放。malloc分配内存但不初始化,free仅释放内存。
new和delete是C++操作符,用于对象的动态创建与销毁。new分配并初始化内存,delete释放内存并调用析构函数。new返回具体类型的指针,而malloc返回void指针。
面试题 6:实现一个“标准”的MIN宏
#define MIN(a, b) ((a) <= (b) ? (a) : (b))
使用时应注意宏的副作用,特别是在复杂的表达式中,可能会因宏展开导致意外行为。
面试题 7:指针是否可以是volatile
是的,指针可以是volatile,这表明指针指向的值可能会在程序的控制之外改变,如在中断服务程序中。
面试题 8:探讨a和&a的区别
#include <stdio.h>
int main() {int a[] = {1, 2, 3, 4, 5};int *ptr = (int *)(&a + 1);printf("%d, %d", *(a + 1), *(ptr - 1));return 0;
}
输出结果为2, 5。a作为数组名,代表数组首地址;&a取地址操作后,再强制类型转换为int*,指向数组之后的内存位置。
面试题 9:详述C/C++程序编译时的内存分配
C/C++程序内存分配包括:
- 静态存储区:存储全局变量、静态变量、常量。
- 栈区:存储函数局部变量、函数参数。
- 堆区:通过
malloc/new分配,由程序员管理。
面试题 10:区分strcpy、sprintf与memcpy
strcpy用于字符串复制。sprintf用于格式化输出到字符串。memcpy用于内存块复制,不仅限于字符串。
面试题 11:设置特定地址的整型变量值
int *ptr;
ptr = (int *)0x67a9;
*ptr = 0xaa66;
这个例子展示了如何通过强制类型转换将整型数据转换为指针,并设置其值。
面试题 12:面向对象的三大特征
- 封装性:数据和方法的保护。
- 继承性:代码重用和扩展。
- 多态性:接口的统一和实现的多样性。
面试题 13:探讨C++中的空类及其成员函数
在C++中,一个空类默认包含以下成员函数:
- 缺省构造函数:自动生成,用于创建类的新实例。
- 缺省拷贝构造函数:在对象之间进行浅拷贝。
- 缺省析构函数:在对象生命周期结束时自动调用。
- 缺省赋值运算符:用于对象间的赋值操作。
- 缺省取址运算符:允许获取对象的地址。
- 缺省取址运算符 const:常量版本的取址运算符,保证对象不会被修改。
值得注意的是,这些成员函数仅在实际使用时才会由编译器定义。此外,深入理解这些函数的默认行为对于优化类设计至关重要。
面试题 14:拷贝构造函数与赋值运算符的深入分析
拷贝构造函数和赋值运算符在类的操作中扮演着不同角色:
- 拷贝构造函数:用于生成新的类对象实例,不需要检查源对象与目标对象是否相同,因为它总是创建新实例。
- 赋值运算符:用于将一个对象的状态复制到另一个已经存在的对象。在赋值前,需要检查自赋值,并妥善处理内存释放等问题。
特别地,当类包含指针成员时,为了管理内存,避免内存泄漏,通常需要重写这两个函数,而不是依赖编译器提供的默认实现。
面试题 15:设计一个不允许继承的C++类
以下是一个使用模板和友元声明来阻止类继承的C++类示例:
template <typename T> class A {friend T; // 允许T访问私有成员
private:A() {}~A() {}
};class B : virtual public A<B> {
public:B() {}~B() {}
};class C : virtual public B {
public:C() {}~C() {}
};int main() {B b; // C c; // 这将导致编译错误return 0;
}
通过将构造函数和析构函数声明为私有,可以阻止类被继承。这种设计模式在需要控制类使用场景时非常有用。
面试题 16:访问基类的私有虚函数
以下程序展示了如何通过特定技巧调用基类的私有虚函数:
#include <iostream>
class A {
public:virtual void g() {std::cout << "A::g" << std::endl;}
private:virtual void f() {std::cout << "A::f" << std::endl;}
};class B : public A {
public:void g() {std::cout << "B::g" << std::endl;}virtual void h() {std::cout << "B::h" << std::endl;}
};typedef void (*Fun)();
void main() {B b;Fun pFun;for (int i = 0; i < 3; i++) {pFun = (Fun)*((int*)*((int*)&b) + i);pFun();}
}
输出结果为:
B::g
A::f
B::h
这个示例展示了虚函数表的工作原理和多态性的重要性。
面试题 17:类成员函数的重写、重载和隐藏的区别
- 重写:发生在派生类与基类之间,要求基类函数必须有
virtual修饰符,参数列表必须一致。 - 重载:发生在同一个类中,参数列表必须不同,与
virtual修饰符无关。 - 隐藏:发生在派生类与基类之间,参数列表可以相同也可以不同,但函数名必须相同。如果参数不同,即使基类函数有
virtual修饰,也会发生隐藏而非重写。
重载和覆盖是实现多态性的基础,但它们的技术实现和目的完全不同。
面试题 18:多态实现的原理
多态的实现依赖于虚函数表(vtable)和虚函数指针(vptr)。当类中存在虚函数时,编译器会为此类生成vtable,并在构造函数中将vptr指向相应的vtable。这样,通过this指针就可以访问到正确的vtable,实现动态绑定和多态。
面试题 19:链表与数组的比较
链表和数组在数据结构中有以下区别:
- 存储形式:数组使用连续内存空间,链表使用非连续的动态内存空间。
- 数据查找:数组支持快速查找,链表需要顺序检索。
- 数据插入或删除:链表支持快速的插入和删除操作,数组可能需要大量数据移动。
- 越界问题:链表没有越界问题,数组存在越界风险。
选择合适的数据结构取决于具体需求。
面试题 20:单链表反序的实现
单链表反序可以通过以下两种方法实现:
- 循环算法:
List reverse(List n) {if (!n) return n;List cur = n.next, pre = n, tmp;pre.next = null;while (cur != null) {tmp = cur;cur = cur.next;tmp.next = pre;pre = tmp;}return pre;
}
- 递归算法:
List* reverse(List* oldList, List* newHead = NULL) {if (oldList == NULL) return newHead;List* next = oldList->next;oldList->next = newHead;newHead = oldList;return (next == NULL) ? newHead : reverse(next, newHead);
}
循环算法直观易懂,递归算法则需要对循环算法有深刻理解。
面试题 21:深入分析队列和栈的异同及其内存分配
队列和栈作为两种基本的线性数据结构,在数据处理流程中扮演着重要角色。它们的主要区别在于数据的存取原则:队列遵循“先进先出”(FIFO)原则,而栈则采用“后进先出”(LIFO)原则。这种差异导致它们在实际应用场景中的使用方式也不尽相同。
在内存管理方面,需要区分程序内存中的“栈区”和“堆区”。栈区由编译器自动管理,用于存储函数调用时的局部变量和参数,其存取方式与数据结构中的栈相似。相对地,堆区的内存分配和释放通常由程序员控制,如果程序员不释放,可能需要等到程序结束时由操作系统回收。堆的内存分配方式与链表类似,但与数据结构中的“堆”不同。
面试题 22:实现队列功能的经典栈操作
通过两个栈实现队列功能是一种经典的数据结构应用。以下是使用C语言实现的示例代码,展示了如何通过两个栈进行队列操作:
// 节点结构体定义
typedef struct node {int data;struct node *next;
} node, *LinkStack;// 创建空栈
LinkStack CreateNULLStack(LinkStack *S) {*S = (LinkStack)malloc(sizeof(node));if (*S == NULL) {printf("Failed to malloc a new node.\n");return NULL;}(*S)->data = 0;(*S)->next = NULL;return *S;
}// 栈的插入函数
LinkStack Push(LinkStack *S, int data) {if (*S == NULL) {printf("No node in stack!\n");return *S;}LinkStack p = (LinkStack)malloc(sizeof(node));if (p == NULL) {printf("Failed to malloc a new node.\n");return *S;}p->data = data;p->next = (*S)->next;(*S)->next = p;return *S;
}// 出栈函数
node Pop(LinkStack *S) {node temp = {0, NULL};if (*S == NULL) {printf("No node in stack!\n");return temp;}LinkStack p = (*S)->next;node n = *p;(*S)->next = p->next;free(p);return n;
}// 双栈实现队列的入队函数
void StackToQueuePush(LinkStack *S, int data) {LinkStack S1 = NULL;CreateNULLStack(&S1);node n;while ((*S)->next != NULL) {n = Pop(S);Push(&S1, n.data);}Push(&S1, data);while (S1->next != NULL) {n = Pop(&S1);Push(S, n.data);}
}
这段代码展示了如何使用两个栈实现队列的基本操作,包括入队和出队。
面试题 23:计算二叉树的深度
二叉树的深度是衡量树结构复杂度的重要指标。以下是一个使用递归方法计算二叉树深度的示例代码:
// 定义二叉树节点结构
typedef struct BiTNode {int data;struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;// 计算二叉树的深度
int depth(BiTree T) {if (T == NULL) return 0;int d1 = depth(T->lchild);int d2 = depth(T->rchild);return (d1 > d2 ? d1 : d2) + 1;
}
这段代码通过递归调用自身来计算左右子树的深度,并返回较大的深度值加一。
面试题 24:直接插入排序的实现
直接插入排序是一种简单直观的排序算法,它通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。以下是直接插入排序的实现代码:
#include <iostream>
using namespace std;void InsertionSort(int ARRAY[], int length) {for (int i = 1; i < length; i++) {int key = ARRAY[i];int j = i - 1;while (j >= 0 && ARRAY[j] > key) {ARRAY[j + 1] = ARRAY[j];j--;}ARRAY[j + 1] = key;}
}int main() {int ARRAY[] = {0, 6, 3, 2, 7, 5, 4, 9, 1, 8};int length = sizeof(ARRAY) / sizeof(ARRAY[0]);InsertionSort(ARRAY, length);for (int i = 0; i < length; i++) {cout << ARRAY[i] << " ";}return 0;
}
这段代码展示了如何通过直接插入排序算法对数组进行排序。
面试题 25:冒泡排序的实现
冒泡排序是一种简单的排序算法,它重复地遍历待排序的序列,比较每对相邻元素,如果顺序错误就交换它们。以下是冒泡排序的实现代码:
#include <stdio.h>
#define LEN 10void BubbleSort(int ARRAY[], int len) {for (int i = 0; i < len - 1; i++) {for (int j = 0; j < len - i - 1; j++) {if (ARRAY[j] > ARRAY[j + 1]) {int temp = ARRAY[j];ARRAY[j] = ARRAY[j + 1];ARRAY[j + 1] = temp;}}}
}int main() {int ARRAY[] = {0, 6, 3, 2, 7, 5, 4, 9, 1, 8};BubbleSort(ARRAY, LEN);for (int i = 0; i < LEN; i++) {printf("%d ", ARRAY[i]);}return 0;
}
这段代码通过冒泡排序算法对数组进行排序,展示了冒泡排序的基本过程。
面试题 26:深入探讨直接选择排序的实现及其不稳定性
直接选择排序是一种简单直观的比较排序算法。它的工作原理是在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾。以下是直接选择排序的实现代码:
void selectionSort(int arr[], int n) {int i, j, min_idx, temp;for (i = 0; i < n-1; i++) {min_idx = i;for (j = i+1; j < n; j++)if (arr[j] < arr[min_idx])min_idx = j;temp = arr[min_idx];arr[min_idx] = arr[i];arr[i] = temp;}
}
直接选择排序的不稳定性主要体现在相同关键码的元素可能会因为排序而改变其原始顺序。虽然在简单整形数组排序中这通常不是问题,但在更复杂的数据结构中,这种不稳定性可能会导致问题。
面试题 27:堆排序的编程实现与分析
堆排序是一种基于比较的排序算法,它利用了二叉堆的数据结构来实现排序。以下是堆排序的实现代码:
void heapify(int arr[], int n, int i) {int largest = i; // Initialize largest as rootint left = 2 * i + 1; // left = 2*i + 1int right = 2 * i + 2; // right = 2*i + 2// If left child is larger than rootif (left < n && arr[left] > arr[largest])largest = left;// If right child is larger than largest so farif (right < n && arr[right] > arr[largest])largest = right;// If largest is not rootif (largest != i) {swap(&arr[i], &arr[largest]);// Recursively heapify the affected sub-treeheapify(arr, n, largest);}
}void heapSort(int arr[], int n) {// Build heap (rearrange array)for (int i = n / 2 - 1; i >= 0; i--)heapify(arr, n, i);// One by one extract an element from heapfor (int i = n - 1; i >= 0; i--) {swap(&arr[0], &arr[i]);heapify(arr, i, 0);}
}
堆排序虽然实现相对复杂,但它在最坏、平均和最好的情况下都能提供O(n log n)的时间复杂度,这使得它成为一种非常实用的排序算法。
面试题 28:基数排序的编程实现与优化策略
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。以下是基数排序的实现代码:
int getMax(int arr[], int n) {int mx = arr[0];for (int i = 1; i < n; i++)if (arr[i] > mx)mx = arr[i];return mx;
}void countSort(int arr[], int n, int exp) {int output[n]; // output arrayint i;int count[10] = {0};// Store count of occurrences in count[]for (i = 0; i < n; i++)count[(arr[i] / exp) % 10]++;// Change count[i] so that count[i] now contains the position of this digit in output[]for (i = 1; i < 10; i++)count[i] += count[i - 1];// Build the output arrayfor (i = n - 1; i >= 0; i--) {output[count[(arr[i] / exp) % 10] - 1] = arr[i];count[(arr[i] / exp) % 10]--;}// Copy the output array to arr[], so that arr[] now contains sorted numbersfor (i = 0; i < n; i++)arr[i] = output[i];
}void radixSort(int arr[], int n) {int m = getMax(arr, n);// Do counting sort for every digit. Note that instead of passing the digit number, exp is passed. exp is 10^i where i is the current digit numberfor (int exp = 1; m / exp > 0; exp *= 10)countSort(arr, n, exp);
}
基数排序在处理大量数据时非常有效,尤其是当数据范围很大时。通过适当的数据结构选择,可以进一步优化算法的复杂度。
面试题 29:对编程规范的深入理解
编程规范是确保代码质量、可读性和可维护性的关键。良好的编程规范应包括但不限于以下几点:
- 可行性:代码应能正确执行预定功能,避免逻辑错误。
- 可读性:代码应易于理解,适当使用注释和文档。
- 可移植性:代码应能在不同环境或平台上运行,减少平台依赖。
- 可测试性:代码应易于测试,方便进行单元测试和集成测试。
面试题 30:数据类型转换的正确性分析
在编程中,数据类型转换的正确性至关重要。例如,short i = 0; i = i + 1L; 中,第二句是正确的,因为1L表示长整型,这里涉及到从大类型到小类型的隐式转换,通常需要显示的强制类型转换以保证数据安全。
面试题 31:逻辑运算符与位运算符的区别
逻辑运算符(&&和||)和位运算符(&和|)的主要区别在于:
- 运算类型:逻辑运算符用于布尔逻辑判断,位运算符用于对操作数的位进行操作。
- 短路特性:逻辑运算符具有短路特性,即在确定结果后不再对其余操作数求值。
面试题 32:C++引用与C语言指针的比较
C++的引用和C语言的指针在本质上有以下区别:
- 初始化:引用必须在声明时初始化,而指针可以后期赋值。
- 可变性:引用一旦初始化后不可改变,指针可以随时指向其他对象。
- 空值:引用不能指向空值,指针可以指向
NULL。
这些区别使得引用在某些场景下比指针更安全,更易于管理。
面试题 33:探索二叉树中路径和的求解策略
在二叉树中找出和为特定值的所有路径是一个经典的算法问题,它要求我们从根节点开始,探索所有可能的路径,并检查它们的和是否与给定值相匹配。以下是使用C语言实现的代码示例,该代码展示了如何使用栈来存储当前路径,并递归地遍历树来寻找符合条件的路径:
#include <stdio.h>
#include <stdlib.h>typedef struct TreeNode {int val;struct TreeNode *left;struct TreeNode *right;
} TreeNode;typedef struct Path {TreeNode* tree;struct Path* next;
} Path;void initPath(Path** L) {*L = (Path*)malloc(sizeof(Path));(*L)->next = NULL;
}void pushPath(Path** H, TreeNode* T) {Path* p = *H;while (p->next != NULL) {p = p->next;}Path* newP = (Path*)malloc(sizeof(Path));newP->tree = T;newP->next = NULL;p->next = newP;
}void printPath(Path* L) {Path* p = L->next;while (p != NULL) {printf("%d ", p->tree->val);p = p->next;}printf("\n");
}int findPaths(TreeNode* T, int sum, Path* L) {if (T == NULL) return 0;pushPath(&L, T);if (T->val == sum && T->left == NULL && T->right == NULL) {printPath(L);popPath(&L);return 1;}if (findPaths(T->left, sum - T->val, L) || findPaths(T->right, sum - T->val, L)) {return 1;}popPath(&L);return 0;
}void popPath(Path** H) {Path* p = *H;Path* q = NULL;while (p->next != NULL) {q = p;p = p->next;free(q);}*H = NULL;
}int main() {// Example tree creation and usageTreeNode* root = (TreeNode*)malloc(sizeof(TreeNode));root->val = 3;root->left = (TreeNode*)malloc(sizeof(TreeNode));root->right = (TreeNode*)malloc(sizeof(TreeNode));root->left->val = 2;root->right->val = 6;root->left->left = (TreeNode*)malloc(sizeof(TreeNode));root->left->right = (TreeNode*)malloc(sizeof(TreeNode));root->right->left = (TreeNode*)malloc(sizeof(TreeNode));root->right->right = (TreeNode*)malloc(sizeof(TreeNode));root->left->left->val = 5;root->left->right->val = 4;Path* path = NULL;initPath(&path);int sum = 9;findPaths(root, sum, path);return 0;
}
这段代码展示了如何使用栈来存储当前路径,并递归地遍历树来寻找符合条件的路径。
面试题 34:编写一个安全的“MIN”宏
宏在C/C++编程中是一种方便的工具,但它们可能引入副作用,特别是当它们被用于复杂的表达式中时。以下是一个“MIN”宏的定义,它返回两个参数中的较小值,同时注意避免宏的常见陷阱:
#define MIN(a, b) ((a) <= (b) ? (a) : (b))
使用这个宏时,应确保不会在宏调用中产生意外的副作用,如在表达式中多次修改变量。
面试题 35:深入理解typedef和define的区别
typedef和define在C/C++中都用于定义别名,但它们在用法和执行时期上有显著差异:
typedef用于定义数据类型的别名,增强代码的可读性,并在编译时进行类型检查。define用于定义常量或宏,它在预处理阶段进行文本替换,不进行类型检查。
正确使用这些工具可以提高代码的可维护性和性能。
面试题 36:探讨const关键字的多方面用途
const关键字用于定义常量或只读数据,它在C/C++编程中有多种用途:
- 定义不可修改的变量或对象。
- 用于函数参数,确保函数内部不会修改参数值。
- 用于修饰成员函数,表明该函数不会修改对象的状态。
const的正确使用可以提高代码的安全性和可读性。
面试题 37:分析static关键字的多重作用
static关键字在C/C++中具有多种用途,包括定义静态变量、静态函数、静态数据成员和静态成员函数。它在不同的上下文中有不同的语义:
- 在函数内部,
static用于定义持久的局部变量。 - 在函数外部,
static用于定义全局变量,其作用域限定在定义它的文件内。 - 在类中,
static用于定义静态成员,这些成员不属于单个对象,而是属于类本身。
正确使用static可以控制变量的生命周期和可见性。
面试题 38:解释extern关键字的作用
extern关键字用于声明在其他文件中定义的全局变量或函数,它允许在当前文件中访问这些外部定义。这在大型项目中管理全局变量和函数时非常有用。
面试题 39:讨论流操作符重载返回引用的重要性
在C++中,流操作符>>和<<通常被重载为返回一个流引用。这样做的目的是允许链式调用,如cin >> a >> b;。返回流引用而不是流的副本可以避免不必要的对象创建和销毁,提高程序效率。
面试题 40:区分指针常量与常量指针
- 指针常量是指指针本身的值不可改变,即一旦指针被初始化后,不能再指向其他地址。
- 常量指针是指指针所指向的数据是不可修改的,但指针本身的值可以改变,指向其他地址。
理解这两者的区别对于正确使用指针和设计函数参数非常有用。
面试题 41:深入分析数组名与指针在C++中的差异
在C++中,数组名和指针虽然在某些情况下可以互换使用,但它们在本质上有显著的区别。数组名实际上代表数组的首地址,但它包含了数组的大小和类型信息,而指针变量则没有这些附加信息。以下代码示例展示了它们在sizeof和strlen操作中的差异:
#include <iostream>
#include <cstring>int main() {char str[13] = "Hello world!";char *pStr = "Hello world!";std::cout << "Size of str: " << sizeof(str) << std::endl; // 输出整个数组的大小std::cout << "Size of pStr: " << sizeof(pStr) << std::endl; // 输出指针变量的大小std::cout << "Length of str: " << strlen(str) << std::endl; // 输出字符串的实际长度std::cout << "Length of pStr: " << strlen(pStr) << std::endl; // 输出字符串的实际长度return 0;
}
输出结果:
Size of str: 13
Size of pStr: 8
Length of str: 12
Length of pStr: 12
注意,当数组名作为函数参数传递时,它会退化成指向数组首元素的指针,失去数组的大小和类型信息。
面试题 42:探讨避免“野指针”的最佳实践
“野指针”是指针使用中常见的问题,它可能导致不可预测的行为和程序崩溃。以下是避免“野指针”的策略:
- 初始化指针:声明指针时给予明确的初始值,通常是
NULL或具体的地址。 - 管理指针的生命周期:在使用完指针后,确保释放它指向的内存并将其设置为
NULL,避免悬挂指针。 - 限制指针的作用域:确保指针不会超出其应有的作用域,减少意外访问的风险。
面试题 43:常引用的应用及其重要性
常引用在C++中用于定义不允许修改的变量的别名,主要用于保护数据不被更改。它在函数参数中非常有用,可以确保函数不会改变传入的参数值。以下是常引用的一些使用场景:
- 保护不可变数据:确保数据在函数内部不被修改。
- 提高代码可读性:明确表明函数参数不应被修改。
面试题 44:实现字符串到整数的转换函数
字符串到整数的转换是常见的编程任务。以下是一个简单的实现,它将字符串转换为整数:
#include <iostream>
#include <cmath>int myAtoi(const char *str) {int num = 0;int sign = 1;const char *p = str;while (*p == ' ') p++; // 跳过空格if (*p == '+' || *p == '-') {sign = (*p == '-') ? -1 : 1;p++;}while (*p >= '0' && *p <= '9') {num = num * 10 + (*p - '0');p++;}return num * sign;
}int main() {std::cout << "Converted integer: " << myAtoi("-5486321") << std::endl;return 0;
}
面试题 45:strcpy、sprintf与memcpy的适用场景分析
这三个函数虽然都涉及数据复制,但它们的应用场景和效率有所不同:
strcpy:用于复制字符串,不涉及数据类型转换。sprintf:用于格式化输出,可以处理多种数据类型,但效率较低。memcpy:用于快速复制内存块,不关心数据类型,效率最高。
选择合适的函数可以提高程序的性能和可读性。
面试题 46:编写一个C语言的死循环程序
死循环是编程中常用的结构,尤其是在需要持续监控或处理任务时。以下是一个简单的死循环示例:
while (1) {// 持续执行的代码
}
面试题 47:位操作技巧
位操作是低级编程中的一个重要技巧,用于直接控制变量的特定位。以下是如何设置和清除变量的特定位:
#define BIT3 (1 << 3)static int a;// 设置 a 的 bit 3
void setBit3(void) {a |= BIT3;
}// 清除 a 的 bit 3
void clearBit3(void) {a &= ~BIT3;
}
这些操作确保了变量的其他位不受影响。
面试题 48:评论中断服务程序的编写
中断服务程序(ISR)是嵌入式系统中的重要组成部分,用于处理硬件中断。以下是一个中断服务程序的示例及其评论:
__interrupt double compute_area(double radius) {double area = M_PI * radius * radius;printf("Area = %f", area);return area;
}
评论:
- ISR不应返回值。
- ISR不应接受参数。
- 在ISR中进行浮点运算可能效率低下。
- 使用
printf可能导致性能问题。
面试题 49:构造函数能否为虚函数
构造函数不能是虚函数,因为它们在对象创建时被调用,而此时对象的类型尚未完全确定。析构函数可以是虚函数,以确保正确地清理资源。
面试题 50:面向对象编程的理解
面向对象编程是一种编程范式,它使用对象和类的概念来设计程序。这种方法提高了代码的可重用性和可维护性,使得程序更加模块化和易于理解。
相关文章:

【附答案】C/C++ 最常见50道面试题
文章目录 面试题 1:深入探讨变量的声明与定义的区别面试题 2:编写比较“零值”的if语句面试题 3:深入理解sizeof与strlen的差异面试题 4:解析C与C中static关键字的不同用途面试题 5:比较C语言的malloc与C的new面试题 6…...

C++音视频开发笔记目录
目录 🌕基础知识🌙详解FFmpeg🌙播放音视频时发生了什么? & 视频的编解码 & H264是什么? & MP4是什么? 🌕流媒体环境搭建🌙windows安装FFMpeg🌙docker一键部署…...

spring项目整合log4j2日志框架(含log4j无法打印出日志的情况,含解决办法)
Spring整合Log4j2的整体流程 Lo 1)导入log4j-core依赖 <!--导入日志框架--> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <ver…...

Linux网络:应用层协议http/https
认识URL URL是我们平时说的网址 eg:http常见的URL http://user:passwww.example.jp:80/dir/index.htm?uid1#ch1 注意: 服务器地址就是域名,相当于服务器ip地址 像http服务绑定80端口号,https服务绑定443端口。ssh服务端口绑定…...

transforemr网络理解
1.transformer网络中数据的流动过程: 2.transformer中残差的理解: 残差连接(Residual Connection) 的核心思想就是通过将输入与经过变化的输出相加,来最大限度地保留原始信息。 transforemr中注意力层网络和前馈神经…...

C++插件管理系统
插件加载目录结构 execute plug.exe plugify.dll plugify.pconfig res cpp-lang-module.pmodule example_plugin.pplugin bin cpp-lang-module.dll example_plugin.dll plugify.pconfig { "baseDir&…...

MyBatis 方法重载的陷阱及解决方案
在使用 MyBatis 进行开发时,尤其是使用注解模式(如 Select、Insert 等)时,开发者常常会遇到这样一个问题:为什么我的方法重载不能正常工作? 即使在 Java 中允许方法名相同但参数不同的重载,MyBa…...

STM32 ADC+DMA导致写FLASH失败
最近用STM32G070系列的ADCDMA采样时,遇到了一些小坑记录一下; 一、ADCDMA采样时进入死循环; 解决方法:ADC-dma死循环问题_stm32 adc dma死机-CSDN博客 将ADC的DMA中断调整为最高,且增大ADCHAL_ADC_Start_DMA(&ha…...

Python AttributeError: ‘dict_values’ object has no attribute ‘index’
Python AttributeError: ‘dict_values’ object has no attribute ‘index’ 在Python编程中,AttributeError 是一个常见的异常类型,通常发生在尝试访问对象没有的属性或方法时。今天,我们将深入探讨一个具体的 AttributeError:“…...
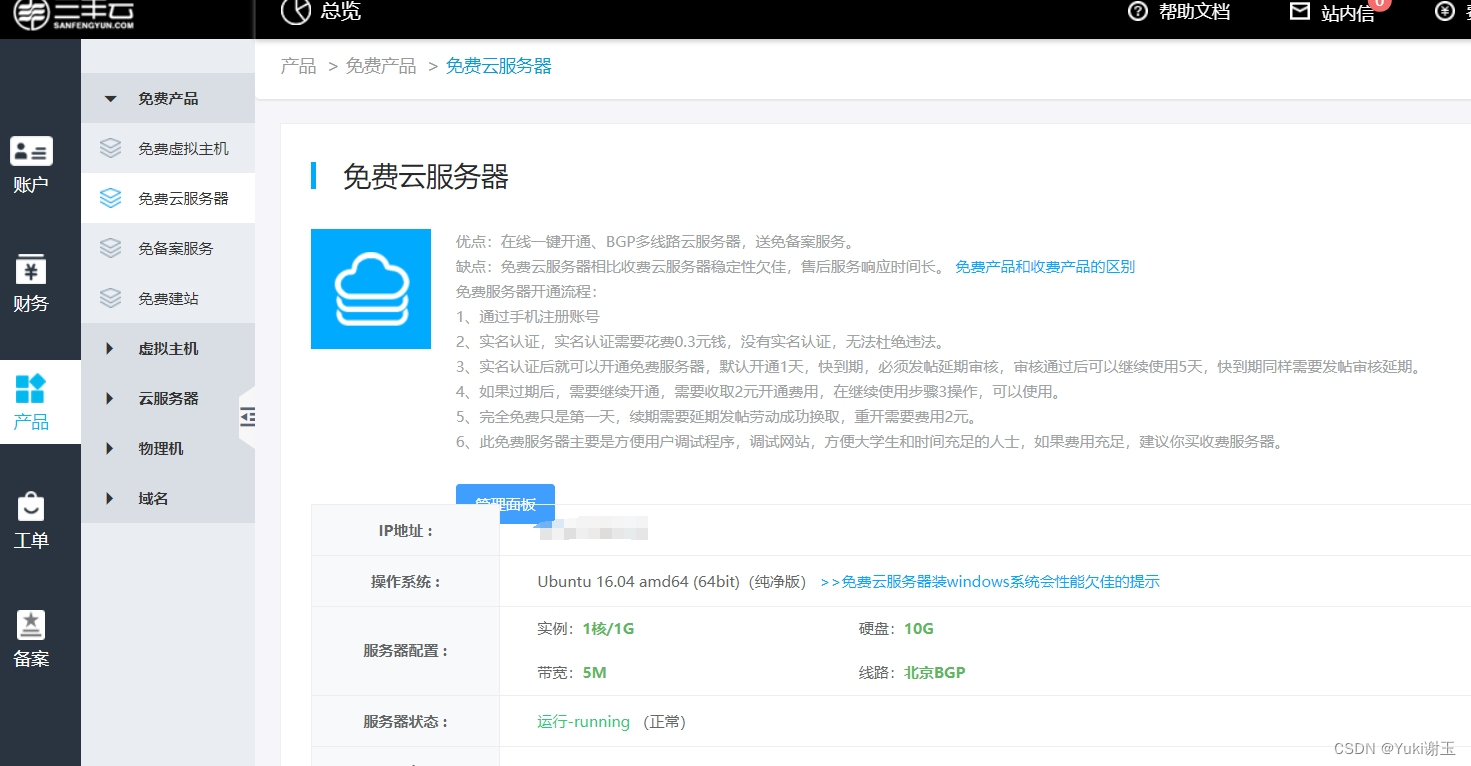
三丰云免费虚拟主机和免费云服务器评测
三丰云是一家提供免费虚拟主机和免费云服务器的知名服务提供商,深受用户好评。在这篇评测文章中,我们将对三丰云的免费虚拟主机和免费云服务器进行细致评测。 首先,我们来看看三丰云的免费虚拟主机服务。三丰云的免费虚拟主机提供稳定的服务器…...
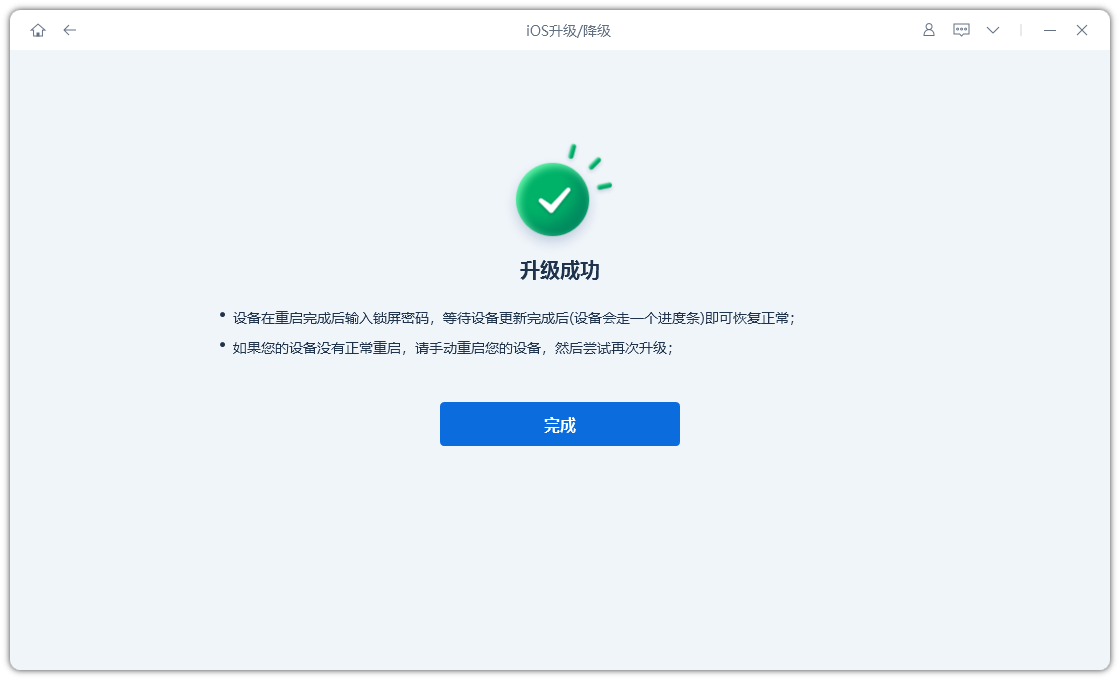
iOS18更新暂停卡住?iOS18升级失败解决办法分享
最近,苹果发布了iOS 18,许多用户都迫不及待更新更新系统体验新功能。然而,一些用户在网上反馈在iOS 18 更新在安装过程中会卡住或暂停,无法正常升级成功。 如果遇到“iOS 18更新暂停或卡住”问题,不用担心。在本文中&a…...

单片机软件工程师确认硬件
文章目录 简介流程确认能连接usb和调试器确认芯片信息确认芯片存储是否正常确认屏幕是否能点亮确认其他硬件 方式方法 简介 硬件工程师给出板子后,后面就是软件工程师的事儿了。 通常来说并不会很顺利。 流程 确认能连接usb和调试器 也是在“计算机管理”中 或者…...

乐鑫无线WiFi芯片模组,家电设备智能联网新体验,启明云端乐鑫代理商
在当今这个数字化飞速发展的时代,智能家居和物联网(IoT)设备已经成为我们生活中不可或缺的一部分。随着技术的进步,我们对于设备联网的需求也在不断提升。 智能家居、智能门锁、智能医疗设备等,这些设备通过联网实现了数据的实时传输和远程控…...

小米嵌入式面试题目RTOS面试题目 嵌入式面试题目
第一章-非RTOS bootloader工作流程 MCU启动流程 通信协议,SPI IIC MCU怎么选型,STM32F1和F4有什么区别 外部RAM和内部RAM区别,怎么分配 外部总线和内部总线区别 MCU上的固件,数据是怎么分配的 MCU启动流程 IAP是怎么升级的…...

Iceberg与SparkSQL写操作整合
前言 spark操作iceberg之前先要配置spark catalogs,详情参考Iceberg与Spark整合环境配置。 有些操作需要在spark3中开启iceberg sql扩展。 Iceberg使用Apache Spark的DataSourceV2 API来实现数据源和catalog。Spark DSv2是一个不断发展的API,在Spark版…...
MYSQL1
一、为什么学习数据库 1、岗位技能需求 2、现在的世界,得数据者得天下 3、存储数据的方法 4、程序,网站中,大量数据如何长久保存? 5、数据库是几乎软件体系中最核心的一个存在。 二、数据库相关概念 (一)数据库DB 数据库是将大量数据保存起来,通过计算机加…...

一文解答Swin Transformer + 代码【详解】
文章目录 1、Swin Transformer的介绍1.1 Swin Transformer解决图像问题的挑战1.2 Swin Transformer解决图像问题的方法 2、Swin Transformer的具体过程2.1 Patch Partition 和 Linear Embedding2.2 W-MSA、SW-MSA2.3 Swin Transformer代码解析2.3.1 代码解释 2.4 W-MSA和SW-MSA…...

Vue3:<Teleport>传送门组件的使用和注意事项
你好,我是沐爸,欢迎点赞、收藏、评论和关注。 Vue3 引入了一个新的内置组件 <Teleport>,它允许你将子组件树渲染到 DOM 中的另一个位置,而不是在父组件的模板中直接渲染。这对于需要跳出当前组件的 DOM 层级结构进行渲染的…...
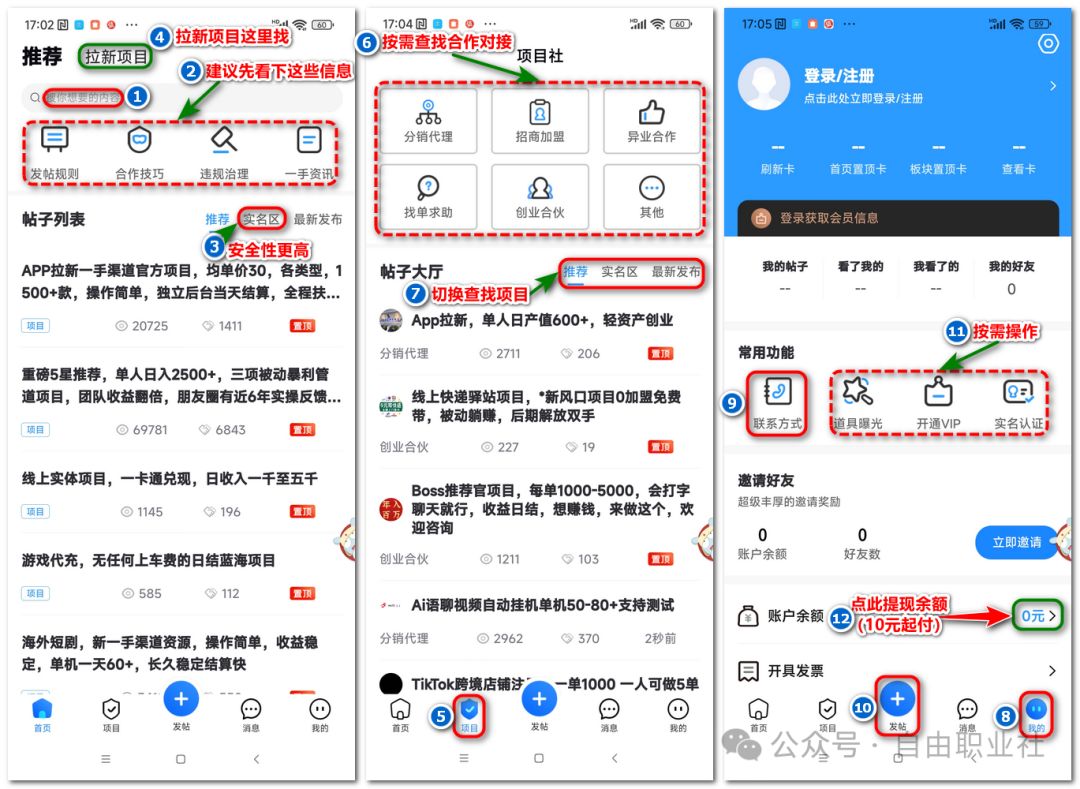
项目之家:又一家项目信息发布合作对接及一手接单平台
这几天“小三劝退师时薪700”的消息甚嚣尘上,只能说从某一侧面来看心理咨询师这个职业的前景还是可以的,有兴趣的朋友可以关注下。话说上一篇文章给大家介绍了U客直谈,今天趁热打铁再给大家分享一个地推拉新项目合作平台~项目之家:…...

02-java实习工作一个多月-经历分享
一、描述一下最近不写博客的原因 离我发java实习的工作的第一天的博客已经过去了一个多月了,本来还没入职的情况是打算每天工作都要写一份博客来记录一下的(最坏的情况也是每周至少总结一下的),其实这个第一天的博客都是在公司快…...

差分隐私矩阵机制与FFT优化:保护多轮迭代计算的高效方法
1. 差分隐私矩阵分解:从理论到工程实践在联邦学习、推荐系统这些需要频繁进行多轮迭代计算的场景里,我们常常面临一个核心矛盾:既要利用全体参与者的数据来训练一个高质量的全局模型,又要确保任何单个参与者的敏感信息不会在训练过…...
)
告别TeamViewer!在Ubuntu 22.04上安装向日葵远程控制的保姆级教程(附依赖问题解决)
在Ubuntu 22.04上无缝迁移至向日葵远程控制的完整指南当TeamViewer开始频繁弹出商业使用警告或连接不稳定时,许多Linux用户开始寻找更友好的替代方案。向日葵作为国产远程控制工具的后起之秀,不仅完全免费,还针对Linux环境做了深度优化。本文…...

兰亭妙微|UI设计外包中的UI图标设计核心技巧与设计师职业发展指南
在UI设计的视觉体系中,图标是传递信息的视觉语言,也是产品个性的关键载体。一枚富有设计感的图标,既能降低用户认知成本,又能让产品更具竞争力。北京兰亭妙微团队从工具选择、设计流程到个性表达,拆解UI图标创作的核心…...

歌词滚动姬:重新定义你的歌词制作体验,让每一句歌词都完美同步
歌词滚动姬:重新定义你的歌词制作体验,让每一句歌词都完美同步 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为制作LRC歌词而烦恼吗&a…...

软考中级嵌入式——第九章 数据结构与算法
1.数据结构与算法概念1.1数据结构数据结构概述:数据结构是计算机存储、组织数据的方式。简单来说,就是如何把现实中的数据(如数字、文字、图片)合理地整理好,放进计算机里,并定义好对这些数据可以做什么操作…...

5G FWA智能终端技术解析:从核心原理到部署实践
1. 项目背景与行业意义最近在圈子里看到一则消息,美格智能的5G FWA智能终端产品成功中标了中国联通的招标项目。这消息乍一看像是普通的商业新闻,但对于我们这些常年泡在通信和物联网领域的人来说,这背后其实藏着不少值得琢磨的门道。它不仅仅…...

【限时解密】Lindy自动化方案未公开的4层权限熔断机制:为什么92%的企业跳过这步就触发合规雷区?
更多请点击: https://kaifayun.com 第一章:Lindy人力资源自动化方案的合规性底层逻辑 Lindy人力资源自动化方案并非简单地将流程数字化,而是以全球主流劳动法规为约束边界,将合规性内化为系统架构的刚性层。其底层逻辑建立在“规…...

代数拓扑运算流程
文章目录0、背景一、标准计算流程:以单纯同调为例空间剖分,构建单纯复形生成各维度链群定义边界算子定义闭链群与边缘链群计算同调群并解读拓扑信息推导最终拓扑结论二、其他核心概念的典型计算逻辑0、背景 之前为了做一个东西学习TDA&…...

C51编译器内存空间警告解析与指针操作实践
1. 理解C51编译器中的内存空间警告 在Keil C51开发环境中,我们经常会遇到各种内存空间相关的警告和错误。其中"WARNING 259: POINTER: DIFFERENT MSPACE"是一个典型的指针操作问题,它揭示了8051架构下内存管理的特殊性。作为一名长期使用C51的…...

Windows 环境下 NVM 安装与 Node.js 版本管理完全指南
💡 为什么需要 NVM? 作为前端开发者,你是否遇到过这些困扰: 场景痛点新项目要求 Node 20,老项目依赖 Node 16频繁卸载重装,浪费时间团队协作时环境不一致代码在同事电脑上跑不通全局安装的依赖版本冲突升…...