大模型RAG实战|构建知识库:文档和网页的加载、转换、索引与存储
我们要开发一个生产级的系统,还需要对LlamaIndex的各个组件和技术进行深度的理解、运用和调优。本系列将会聚焦在如何让系统实用上,包括:知识库的管理,检索和查询效果的提升,使用本地化部署的模型等主题。我将会讲解相关的组件和技术,辅以代码示例。最终这些文章中的代码将形成一套实用系统。
过去一年,大模型的发展突飞猛进。月之暗面的Kimi爆火,Llama3开源发布,大模型各项能力提升之大有目共睹。
对于大模型检索增强生成(RAG)系统来说,我们越来越认识到,其核心不在于模型的能力,而是在于如何更好地构建和使用知识库,提升检索的效能。
1
知识库的三类数据
无论是企业还是个人,我们构建知识库,自然希望高质量的数据越多越好。这些数据主要分为三类。
- 文件:电脑上为数众多的文件资料,包括方案、文稿、产品资料等,通常为PDF、DOCX、PPT等格式
- 网页:收集的网页信息,比如我们在微信上打开和阅读的公众号文章。如果觉得这些文章有用,会收藏起来
- 数据库:保存在各种数据库中的文本信息,比如企业内部的信息系统,会记录用户提出的问题与相应的解决方案
对于个人用户,建立个人知识库,主要是电脑上的文件资料和收藏的网页信息。而对于企业来说,接入和利用已有信息系统的数据库中的文本数据,也非常关键。
LlamaIndex是一个专门针对构建RAG系统开发的开源数据框架,对于以上三类数据的处理,都提供了很好的支持。
2
数据处理的四个步骤
无论是哪一类数据,LlamaIndex处理数据的过程,都分为四步:
1)加载数据(Load)
LlamaIndex提供了众多数据接入组件(Data Connector),可以加载文件、网页、数据库,并提取其中的文本,形成文档(Document)。未来还将能提取图片、音频等非结构化数据。
最常用的是SimpleDirectoryReader,用来读取文件系统指定目录中的PDF、DOCX、JPG等文件。

我们在LlamaHub上,可以找到数百个数据接入组件,用来加载各种来源与格式的数据,比如电子书epub格式文件的接入组件。
2) 转换数据(Transform)
类似传统的ETL,转换数据是对文本数据的清洗和加工。通常,输入是文档(Document),输出是节点(Node)。
数据处理的过程,主要是将文本分割为文本块(Chunk),并通过嵌入模型,对文本块进行嵌入(Embedding)。同时,可提取元数据(Metadata),例如原文件的文件名和路径。
这里有两个重要的参数,chunk_size和chunk_overlap,分别是文本块分割的大小,和相互之间重叠的大小。我们需要调整这些参数,从而达到最好的检索效果。
3)建立索引(Index)
索引是一种数据结构,以便于通过大语言模型(LLM)来查询生成的节点。
最常使用的是向量存储索引(Vector Store Index),这种方式把每个节点(Node)的文本,逐一创建向量嵌入(vector embeddings),可以理解是文本语义的一种数字编码。
不同于传统的关键词匹配,通过向量检索,比如余弦相似度,我们可以找到语义相近的文本,尽管在文字上有可能截然不同。
4)存储数据(Store)
默认情况下,以上操作生成的数据都保存在内存中。要避免每次重来,我们需要将这些数据进行持久化处理。
LlamaIndex 提供了内置的persisit()方法,将索引数据持久化保存在磁盘文件中。更常见的做法是通过索引存储器(Index Store),将索引保存在向量数据库中,如Chroma、LanceDB等。
知识库的管理,不仅要保存索引数据,也要保存所有文档(Document)及其提取的节点(Node)。
LLamaIndex提供了文档存储器(Document Store),把这些文本数据保存在MongoDB、Redis等NoSQL数据库中,这样我们可以对每一个节点进行增删改查。
3
代码实现示例
下面结合代码,介绍构建知识库的过程。
我们将使用LlamaIndex来加载和转换文档和网页数据,建立向量索引,并把索引保存在Chroma,把文档和节点保存在MongoDB。
示例1:加载本地文件
对于在本地文件系统中的文件,LlamaIndex提供了非常简便的方法来读取:SimpleDirectoryReader。
我们只需要将已有的文件,放在指定的目录下,比如./data,通过这个方法就可以全部加载该目录下的所有文件,包括子目录中的文件。
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader(input_dir="./data", recursive=True).load_data()
print(f"Loaded {len(documents)} Files")
如果,我们在知识库中上传了新的文件,还可以指定加载这个文件,而非读取整个目录。
SimpleDirectoryReader(input_files=["path/to/file1", "path/to/file2"])
文件加载后,LlamaIndex会逐一提取其中的文本信息,形成文档(Document)。通常一个文件对应一个文档。
示例2:加载网页信息
LlamaIndex读取和加载网页信息也很简单。这里,我们用到另一个工具SimpleWebPageReader。
给出一组网页的URL,我们使用这个工具可以提取网页中的文字信息,并分别加载到文档(Document)中。

代码中我给出的网页,是我写的《大卫说流程》系列文章。你可以改为任何你想读取的网页。未来,你可以针对这些网页内容来向大模型提问。
使用这个工具,我们需要安装llama-index-readers-web和html2text组件。为了行文简洁,未来不再说明。你可以在运行代码时根据提示,安装所需的Python库和组件。
示例3:分割数据成块
接下来,我们通过文本分割器(Text Splitter)将加载的文档(Document)分割为多个节点(Node)。
LlamaIndex使用的默认文本分割器是SentenceSplitter。我们可以设定文本块的大小是256,重叠的大小是50。文本块越小,那么节点的数量就越多。
from llama_index.core.node_parser import SentenceSplitter
nodes = SentenceSplitter(chunk_size=256, chunk_overlap=50).get_nodes_from_documents(documents)
print(f"Load {len(nodes)} Nodes")
之前我介绍过文本分割器Spacy,对中文支持更好。我们可以通过Langchain引入和使用。

示例4:数据转换管道与知识库去重
上一步给出的数据转换方法,其实并不实用。问题在于没有对文档进行管理。我们重复运行时,将会重复加载,导致知识库内重复的内容越来越多。
为了解决这个问题,我们可以使用LlamaIndex提供的数据采集管道(Ingestion Pipeline)的功能,默认的策略为更新插入(upserts),实现对文档进行去重处理。

示例5:索引与存储的配置
在上面的数据采集管道的代码示例中,我们配置了用来生成向量索引的嵌入模型(embed_model),以及采用Chroma作为向量库,MongoDB作为文档库,对数据进行持久化存储。
嵌入模型的配置如下。这里我们通过之前介绍过的HugginFace的命令行工具,将BAAI的bge-small-zh-v1.5嵌入模型下载到本地,放在“localmodels”目录下。
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="./localmodels/bge-small-zh-v1.5")
然后配置向量库,Chroma将把数据存储在我们指定的“storage”目录下。
import chromadb
from llama_index.vector_stores.chroma import ChromaVectorStore
db = chromadb.PersistentClient(path="./storage")
chroma_collection = db.get_or_create_collection("think")
chroma_vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
我们可以使用Redis或MongoDB来存储处理后的文档、节点及相关信息,包括文档库(docstore)和索引信息库(index_store)。
作为示例,我们选用在本机上安装的MongoDB。

示例6:构建知识库
现在,我们可以将此前的数据采集管道生成的文档和节点,载入到文档知识库中(docstore)。
storage_context.docstore.add_documents(nodes)
print(f"Load {len(storage_context.docstore.docs)} documents into docstore")这步完成后,我们在MongoDB中,可以找到一个名为“db_docstore”的数据库,里面有三张表,分别是:
- docstore/data
- docstore/metadata
- docstore/ref_doc_info
我们可以通过MongoDB,来查询相关的文档和节点,元数据以及节点之间的关系信息。
未来,当你有更多的文件和网页需要放入知识库中,只需要遵循以上的步骤加载和处理。
示例7:实现RAG问答
完成知识库的构建之后,我们可以设定使用本地的LLM,比如通过Ollama下载使用Gemma 2B模型。
然后,加载索引,生成查询引擎(Query Engine),你就可以针对知识库中的内容进行提问了。

以上,主要介绍了使用LlamaIndex构建知识库的过程。
未来,我们可以结合Streamlit、Flask等前端框架,进一步开发成一个完善的知识库管理系统,以便对知识内容进行持续的增加与更新,并支持灵活的配置文本分割的各项参数和选择嵌入模型。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
相关文章:
大模型RAG实战|构建知识库:文档和网页的加载、转换、索引与存储
我们要开发一个生产级的系统,还需要对LlamaIndex的各个组件和技术进行深度的理解、运用和调优。本系列将会聚焦在如何让系统实用上,包括:知识库的管理,检索和查询效果的提升,使用本地化部署的模型等主题。我将会讲解相…...

江协科技stm32————11-5 硬件SPI读写W25Q64
一、开启时钟,开启SPI和GPIO的时钟 二、初始化GPIO口,其中SCK和MOSI是由硬件外设控制的输出信号,配置为复用推挽输出 MISO是硬件外设的输入信号,配置为上拉输入,SS是软件控制的输出信号,配置为通用推挽输出…...

网络编程day04(UDP、Linux IO 模型)
目录 【1】UDP 1》通信流程 2》函数接口 1> recvfrom 2> sendto 3》代码展示 1> 服务器代码 2> 客户端代码 【2】Linux IO 模型 场景假设一 1》阻塞式IO:最常见、效率低、不耗费CPU 2》 非阻塞 IO:轮询、耗费CPU,可以处…...

【android10】【binder】【2.servicemanager启动——全源码分析】
系列文章目录 可跳转到下面链接查看下表所有内容https://blog.csdn.net/handsomethefirst/article/details/138226266?spm1001.2014.3001.5501文章浏览阅读2次。系列文章大全https://blog.csdn.net/handsomethefirst/article/details/138226266?spm1001.2014.3001.5501 目录 …...

Java实现简易计算器功能(idea)
目的:写一个计算器,要求实现加减乘除功能,并且能够循环接收新的数据,通过用户交互实现。 思路: (1)写4个方法:加减乘除 (2)利用循环switch进行用户交互 &…...

Parsec问题解决方案
Parsec目前就是被墙了,有解决方案但治标不治本,如果想稳定串流建议是更换稳定的串流软件,以下是一些解决方案 方案一:在%appdata%/Parsec/config.txt中,添加代理 app_proxy_address 127.0.0.1 app_proxy_scheme http…...

Swift 创建扩展(Extension)
类别(Category) 和 扩展(Extension) 的 用法很多. 常用的 扩展(Extension) 有分离代码和封装模块的功能,例如登陆页面有注册功能,有登陆功能,有找回密码功能,都写在一个页面就太冗余了,可以考虑使用 扩展(Extension) 登陆页面的方法来分离代码 本文介绍Swift 如何创建扩展(Ex…...
)
九月五日(k8s配置)
一、安装环境 环境准备:(有阿里云) k8s-master 192.168.1.11 k8s-node1 192.168.1.22 k8s-node2 192.168.1.33 二、前期准备 在k8s-master主机 [rootk8s-master ~]# vim /etc/hosts …...

某极验4.0 -消消乐验证
⚠️前言⚠️ 本文仅用于学术交流。 学习探讨逆向知识,欢迎私信共享学习心得。 如有侵权,联系博主删除。 请勿商用,否则后果自负。 网址 aHR0cHM6Ly93d3cyLmdlZXRlc3QuY29tL2FkYXB0aXZlLWNhcHRjaGE 1. 浅聊一下 验证码样式 验证成功 - …...

洛谷 P10798 「CZOI-R1」消除威胁
题目来源于:洛谷 题目本质:贪心,st表,单调栈 解题思路:由于昨天联练习了平衡树,我就用平衡树STL打了个暴力,超时得了30分 这是暴力代码: #include<bits/stdc.h> using name…...
)
Pow(x, n)
题目 实现 pow(x, n) ,即计算 x 的 n 次幂函数(即,xn)。 示例 1: 输入:x 2.00000, n 10 输出:1024.00000示例 2: 输入:x 2.10000, n 3 输出:9.26100示…...
一文带你学会使用滑动窗口
🔥个人主页:guoguoqiang. 🔥专栏:leetcode刷题 209.长度最小的子数组 求最短长度之和等于目标值。 方法一: 暴力枚举(会超时) 从头开始遍历直到之和等于target然后更新结果。这…...

如何从0到1本地搭建whisper语音识别模型
文章目录 环境准备1. 系统要求2. 安装依赖项1:安装 Python 和虚拟环境2:安装 Whisper3:下载 Whisper 模型4:进行语音识别5:提高效率和精度6:开发和集成Whisper 是 OpenAI 发布的一个强大的语音识别模型,它可以将语音转换为文本,支持多语言输入,并且可以处理各种音频类…...

PyTorch 创建数据集
图片数据和标签数据准备 1.本文所用图片数据在同级文件夹中 ,文件路径为train/’ 2.标签数据在同级文件,文件路径为train.csv 3。将标签数据提取 train_csvpd.read_csv(train.csv)创建继承类 第一步,首先创建数据类对象 此时可以想象为单个数据单元的…...

[Java]SpringBoot登录认证流程详解
登录认证 登录接口 1.查看原型 2.查看接口 3.思路分析 登录核心就是根据用户名和密码查询用户信息,存在则登录成功, 不存在则登录失败 4.Controller Slf4j RestController public class LoginController {Autowiredprivate EmpService empService;/*** 登录的方法** param …...

【Day08】
目录 MySQL-多表查询-概述 MySQL-多表查询-内连接 MySQL-多表查询-外连接 MySQL-多表查询-[标量、列]子查询 MySQL-多表查询-[行、表]子查询 MySQL-多表查询-案例 MySQL-事务-介绍与操作 MySQL-事务-四大特性 MySQL-索引-介绍 MySQL-索引-结构 MySQL-索引-操作语法 …...

mongodb在Java中条件分组聚合查询并且分页(时间戳,按日期分组,年月日...)
废话不多说,先看效果图: SQL查询结果示例: 多种查询结果示例: 原SQL: db.getCollection("hbdd_order").aggregate([{// 把时间戳格式化$addFields: {orderDate: {"$dateToString": {"for…...
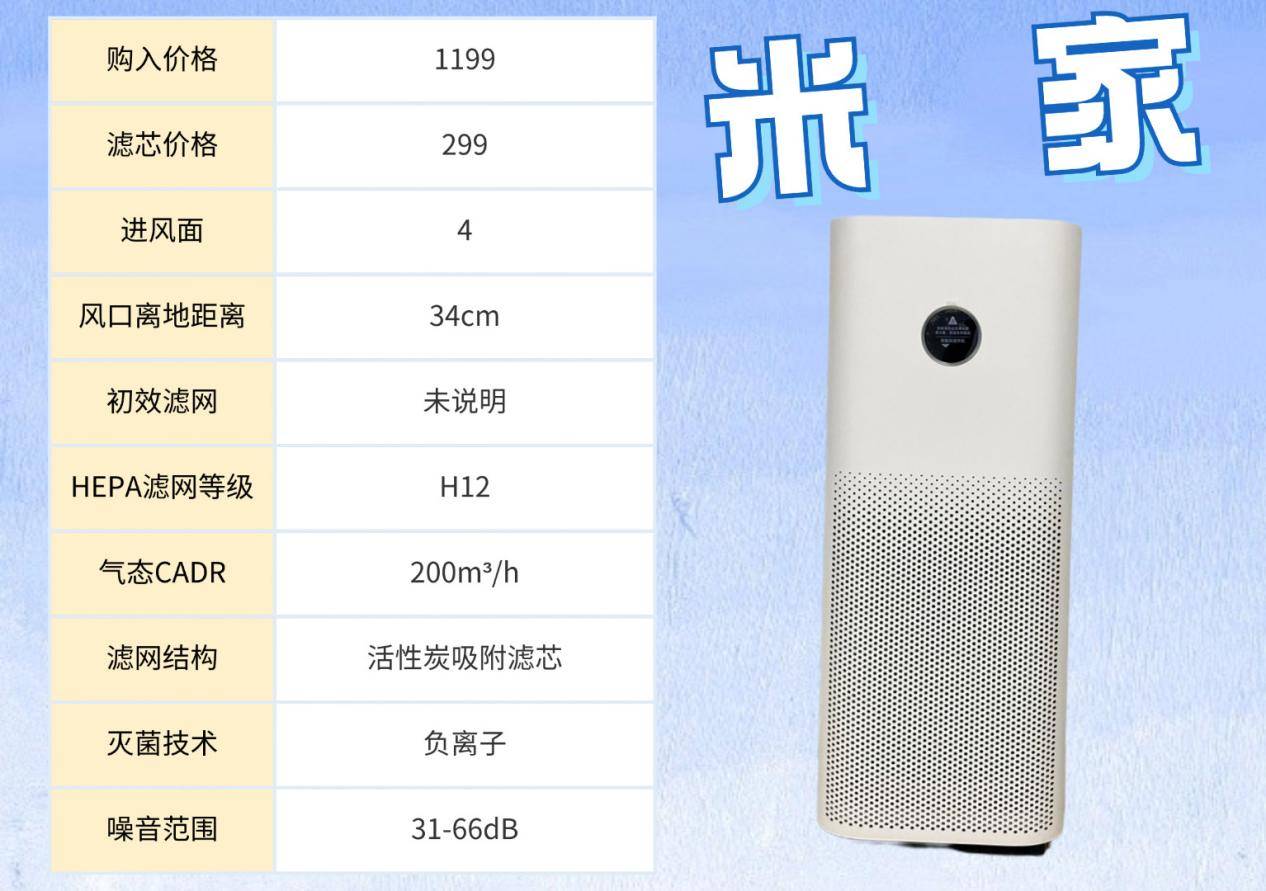
怎么样处理浮毛快捷又高效?霍尼韦尔、希喂、米家宠物空气净化器实测对比
掉毛多?掉毛快?猫毛满天飞对身体有危害吗?多猫家庭经验分享篇: 一个很有趣的现象,很多人在养猫、养狗后耐心都变得更好了。养狗每天得遛,养猫出门前得除毛,日复一日的重复磨练了极好的耐心。我家…...

什么是WebGL技术?有什么特点?应用领域有哪些?
WebGL(Web Graphics Library)技术是一种在Web浏览器中渲染交互式3D和2D图形的JavaScript API。以下是对WebGL技术的详细解析: 一、定义与起源 定义: WebGL全称Web Graphics Library,即网络图形库,它允许…...

500W逆变器(一)
EG8015_24V_500W 这款逆变器是基于 EG8015 SPWM 专用芯片而设计的方案。其额定的输出功率为 500 瓦, 最大输出功率为 600 瓦,输出电压为 220V10%,输出频率为 50Hz0.1Hz,额定输出电流为 2.3 安培。 穿越机降落的时候不要垂直降落,要…...

HS2-HF Patch终极指南:一键解锁完整汉化与去码体验
HS2-HF Patch终极指南:一键解锁完整汉化与去码体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为《Honey Select 2》的语言障碍和功能限制而…...

电玩城新政解读:价格趋势与消费避坑指南
行业现状:一场新规带来的市场洗牌最近,不少玩家发现,常去的那家电玩城变了——以前一块钱两个币,现在一块钱一个币,机器游戏规则也悄悄调整了。这背后,是2024年以来多地密集出台电玩城管理新规带来的连锁反…...

HsMod深度解析:基于BepInEx的炉石传说全方位模改进阶指南
HsMod深度解析:基于BepInEx的炉石传说全方位模改进阶指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod 你是否厌倦了炉石传说中繁琐的动画等待?是否渴望更高效的游…...

STM32MP1 M4核心定时器中断实战:从原理到1ms精准时基实现
1. 项目概述:深入STM32MP1的M4核心定时器世界在嵌入式开发中,定时器(Timer)堪称是系统的“心跳”和“节拍器”,其重要性不言而喻。对于STM32MP1这款集成了双核Cortex-A7和单核Cortex-M4的异构处理器,其M4核…...

【AI面试八股文 Vol.3.5:推理幻觉规模定律】CoT、幻觉与 Scaling Law:为什么模型会推理,也会一本正经胡说
摘要:这篇会把 CoT、幻觉和 Scaling Law 放到同一条工程主线上:CoT 不是教模型思考,而是触发模型把隐式路径显式写出来;幻觉不是单一 bug,而是训练知识边界、解码策略和指令跟随压力叠加后的结果;Scaling L…...

2025年AI数字人行业现状:全国超99万家企业涌入,真正能落地的不到一成
当生成式AI的浪潮席卷各行各业,AI数字人成为最先跑出商业化落地速度的细分赛道。然而,在全国超99万家相关企业蜂拥而入的热闹背后,一个残酷的现实正在显现:绝大多数所谓的"AI数字人"不过是披着科技外衣的"会动的照…...

3分钟快速上手Vin象棋:基于YOLOv5的智能中国象棋连线工具终极指南
3分钟快速上手Vin象棋:基于YOLOv5的智能中国象棋连线工具终极指南 【免费下载链接】VinXiangQi Xiangqi syncing tool based on Yolov5 / 基于Yolov5的中国象棋连线工具 项目地址: https://gitcode.com/gh_mirrors/vi/VinXiangQi 你是否厌倦了手动记录棋局的…...

2025年终极指南:PlayIntegrityFix让你的Root设备完美通过Google认证
2025年终极指南:PlayIntegrityFix让你的Root设备完美通过Google认证 【免费下载链接】PlayIntegrityFix Fix Play Integrity (and SafetyNet) verdicts. 项目地址: https://gitcode.com/GitHub_Trending/pl/PlayIntegrityFix 还在为Root后的Android设备无法正…...

3步掌握Sabaki围棋软件:从新手到高手的完整指南
3步掌握Sabaki围棋软件:从新手到高手的完整指南 【免费下载链接】Sabaki An elegant Go board and SGF editor for a more civilized age. 项目地址: https://gitcode.com/gh_mirrors/sa/Sabaki 在围棋的智慧世界里,一款优秀的软件能让您的学习和…...

企业内训系统集成Taotoken实现多模型AI助教与可控的交互成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内训系统集成Taotoken实现多模型AI助教与可控的交互成本 对于现代企业而言,构建一个高效、智能的内训系统是提升员…...