TinyWebSever源码逐行注释(五)_ http_conn.cpp
前言
项目源码地址
项目详细介绍
项目简介:
Linux下C++轻量级Web服务器,助力初学者快速实践网络编程,搭建属于自己的服务器.
- 使用 线程池 + 非阻塞socket + epoll(ET和LT均实现) + 事件处理(Reactor和模拟Proactor均实现) 的并发模型
- 使用状态机解析HTTP请求报文,支持解析GET和POST请求
- 访问服务器数据库实现web端用户注册、登录功能,可以请求服务器图片和视频文件
- 实现同步/异步日志系统,记录服务器运行状态
- 经Webbench压力测试可以实现上万的并发连接数据交换
http_conn.cpp利用一个主从状态机来处理客户端的htttp连接并生成相应的响应。主要内容如下:
根据状态转移,通过主从状态机封装了http连接类。其中,主状态机在内部调用从状态机,从状态机将处理状态和数据传给主状态机
- 客户端发出http连接请求
- 从状态机读取数据,更新自身状态和接收数据,传给主状态机
- 主状态机根据从状态机状态,更新自身状态,决定响应请求还是继续读取
原项目地址的注释较少不适合初学者,于是我将每行都加上了注释帮助大家更好的理解:
#include "http_conn.h"
#include <mysql/mysql.h>
#include <fstream>// 定义HTTP响应的一些状态信息,用于不同HTTP请求返回的状态码和描述
const char *ok_200_title = "OK";
const char *error_400_title = "Bad Request"; // 客户端请求有语法错误,服务器无法处理
const char *error_400_form = "Your request has bad syntax or is inherently impossible to satisfy.\n";
const char *error_403_title = "Forbidden"; // 客户端没有访问权限
const char *error_403_form = "You do not have permission to get file from this server.\n";
const char *error_404_title = "Not Found"; // 请求的资源不存在
const char *error_404_form = "The requested file was not found on this server.\n";
const char *error_500_title = "Internal Error"; // 服务器内部错误
const char *error_500_form = "There was an unusual problem serving the request file.\n";// 用于线程安全操作的锁
locker m_lock;// 存储用户名和密码的映射,用于验证登录和注册
map<string, string> users;// 初始化数据库结果,将数据库中的用户信息读取到内存中
void http_conn::initmysql_result(connection_pool *connPool)
{// 从连接池中取出一个MYSQL连接MYSQL *mysql = NULL;connectionRAII mysqlcon(&mysql, connPool);// 查询user表中的username和passwd字段,获取用户信息if (mysql_query(mysql, "SELECT username,passwd FROM user")){LOG_ERROR("SELECT error:%s\n", mysql_error(mysql));}// 获取查询结果MYSQL_RES *result = mysql_store_result(mysql);// 获取结果集中字段的数量int num_fields = mysql_num_fields(result);// 获取所有字段的信息MYSQL_FIELD *fields = mysql_fetch_fields(result);// 遍历结果集的每一行,将用户名和密码存入map中while (MYSQL_ROW row = mysql_fetch_row(result)){string temp1(row[0]); // 用户名string temp2(row[1]); // 密码users[temp1] = temp2; // 存入map}
}// 设置文件描述符为非阻塞模式
int setnonblocking(int fd)
{int old_option = fcntl(fd, F_GETFL); // 获取当前的文件描述符状态标志int new_option = old_option | O_NONBLOCK; // 添加非阻塞标志fcntl(fd, F_SETFL, new_option); // 设置新的文件描述符状态return old_option; // 返回旧的文件描述符状态
}// 向内核事件表注册读事件,并设置触发模式为ET或LT模式,同时选择是否启用EPOLLONESHOT模式
void addfd(int epollfd, int fd, bool one_shot, int TRIGMode)
{epoll_event event;event.data.fd = fd; // 绑定fdif (1 == TRIGMode) // ET模式下,添加EPOLLET标志event.events = EPOLLIN | EPOLLET | EPOLLRDHUP; // EPOLLRDHUP表示对端关闭连接elseevent.events = EPOLLIN | EPOLLRDHUP; // LT模式下if (one_shot) // 是否启用EPOLLONESHOT模式,防止同一个socket被多个线程处理event.events |= EPOLLONESHOT;epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); // 向epoll实例中注册事件setnonblocking(fd); // 设置非阻塞
}// 从内核事件表中删除文件描述符
void removefd(int epollfd, int fd)
{epoll_ctl(epollfd, EPOLL_CTL_DEL, fd, 0); // 删除指定文件描述符的事件close(fd); // 关闭文件描述符
}// 修改文件描述符上的注册事件,重置EPOLLONESHOT
void modfd(int epollfd, int fd, int ev, int TRIGMode)
{epoll_event event;event.data.fd = fd;if (1 == TRIGMode) // ET模式event.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP;else // LT模式event.events = ev | EPOLLONESHOT | EPOLLRDHUP;epoll_ctl(epollfd, EPOLL_CTL_MOD, fd, &event); // 修改事件
}int http_conn::m_user_count = 0; // 用户数量初始化为0
int http_conn::m_epollfd = -1; // epoll实例文件描述符初始化为-1// 关闭连接,减少用户计数
void http_conn::close_conn(bool real_close)
{if (real_close && (m_sockfd != -1)) // 只有当real_close为true并且socket存在时才关闭连接{printf("close %d\n", m_sockfd);removefd(m_epollfd, m_sockfd); // 从epoll中移除该文件描述符m_sockfd = -1; // 重置socket描述符m_user_count--; // 用户总量减1}
}// 初始化连接的相关信息
void http_conn::init(int sockfd, const sockaddr_in &addr, char *root, int TRIGMode,int close_log, string user, string passwd, string sqlname)
{m_sockfd = sockfd; // 保存传入的socket文件描述符m_address = addr; // 保存客户端的地址信息addfd(m_epollfd, sockfd, true, m_TRIGMode); // 注册epoll事件,并且启用EPOLLONESHOT模式m_user_count++; // 新增一个用户// 初始化一些相关参数,如网站根目录、触发模式、是否关闭日志等doc_root = root;m_TRIGMode = TRIGMode;m_close_log = close_log;strcpy(sql_user, user.c_str()); // 保存数据库用户名strcpy(sql_passwd, passwd.c_str()); // 保存数据库密码strcpy(sql_name, sqlname.c_str()); // 保存数据库名init(); // 调用init()函数初始化其他成员变量
}// 初始化连接的一些内部状态
void http_conn::init()
{mysql = NULL;bytes_to_send = 0;bytes_have_send = 0;m_check_state = CHECK_STATE_REQUESTLINE; // 初始状态为解析请求行m_linger = false;m_method = GET; // 默认请求方法为GETm_url = 0;m_version = 0;m_content_length = 0;m_host = 0;m_start_line = 0;m_checked_idx = 0;m_read_idx = 0;m_write_idx = 0;cgi = 0; // CGI标志初始化为0m_state = 0;timer_flag = 0;improv = 0;// 初始化读写缓冲区memset(m_read_buf, '\0', READ_BUFFER_SIZE);memset(m_write_buf, '\0', WRITE_BUFFER_SIZE);memset(m_real_file, '\0', FILENAME_LEN);
}// 从状态机,用于逐行解析读取到的数据
http_conn::LINE_STATUS http_conn::parse_line()
{char temp;// 遍历缓冲区,从m_checked_idx位置开始逐字符检查for (; m_checked_idx < m_read_idx; ++m_checked_idx){temp = m_read_buf[m_checked_idx];// 如果当前字符为回车符if (temp == '\r'){// 如果回车符是缓冲区最后一个字符,则表示还没有完整的一行,返回LINE_OPENif ((m_checked_idx + 1) == m_read_idx)return LINE_OPEN;// 如果回车符后面是换行符,说明读取到了一行完整的请求else if (m_read_buf[m_checked_idx + 1] == '\n'){m_read_buf[m_checked_idx++] = '\0'; // 将回车符替换为字符串结束符m_read_buf[m_checked_idx++] = '\0'; // 将换行符替换为字符串结束符return LINE_OK; // 返回LINE_OK,表示读取到了一行}return LINE_BAD; // 如果不是换行符,说明请求行格式错误}// 如果当前字符是换行符else if (temp == '\n'){// 检查前一个字符是否为回车符if (m_checked_idx > 1 && m_read_buf[m_checked_idx - 1] == '\r'){m_read_buf[m_checked_idx - 1] = '\0'; // 将回车符替换为字符串结束符m_read_buf[m_checked_idx++] = '\0'; // 将换行符替换为字符串结束符return LINE_OK;}return LINE_BAD; // 如果前一个字符不是回车符,则返回LINE_BAD}}return LINE_OPEN; // 如果没有遇到回车换行,表示行不完整,返回LINE_OPEN
}// 循环读取客户端数据,直到无数据可读或对方关闭连接
bool http_conn::read_once()
{if (m_read_idx >= READ_BUFFER_SIZE) // 如果读缓冲区已满,则返回false{return false;}int bytes_read = 0;// LT模式读取数据if (0 == m_TRIGMode){// 从socket中读取数据,存储到读缓冲区bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0);m_read_idx += bytes_read;if (bytes_read <= 0) // 如果读取到的数据为空或发生错误{return false;}return true;}// ET模式读取数据,需要循环读取,直到没有数据可读else{while (true){// 尝试读取数据bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0);if (bytes_read == -1) // 出现错误{// 如果错误是EAGAIN或者EWOULDBLOCK,表示数据已经全部读取完毕if (errno == EAGAIN || errno == EWOULDBLOCK)break;return false; // 否则,发生了其他错误}else if (bytes_read == 0) // 对方关闭了连接{return false;}m_read_idx += bytes_read; // 更新读索引}return true;}
}// 解析HTTP请求行,获取请求方法、目标URL及HTTP版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char *text)
{m_url = strpbrk(text, " \t"); // 查找请求行中的第一个空格或制表符,后面是URLif (!m_url){return BAD_REQUEST; // 如果没有找到空格或制表符,说明请求行格式错误}*m_url++ = '\0'; // 将空格或制表符替换为字符串结束符,分离出请求方法char *method = text; // 获取请求方法if (strcasecmp(method, "GET") == 0) // 比较请求方法是否为GETm_method = GET;else if (strcasecmp(method, "POST") == 0) // 比较请求方法是否为POST{m_method = POST;cgi = 1; // 如果是POST方法,开启CGI处理}elsereturn BAD_REQUEST; // 如果不是GET或POST,返回BAD_REQUESTm_url += strspn(m_url, " \t"); // 跳过URL前的空格或制表符m_version = strpbrk(m_url, " \t"); // 查找URL后的空格或制表符,后面是HTTP版本if (!m_version)return BAD_REQUEST; // 如果没有找到,返回BAD_REQUEST*m_version++ = '\0'; // 将空格或制表符替换为字符串结束符,分离出URLm_version += strspn(m_version, " \t"); // 跳过版本号前的空格或制表符if (strcasecmp(m_version, "HTTP/1.1") != 0) // 检查是否为HTTP/1.1return BAD_REQUEST;// 如果URL是以"http://"或"https://"开头,跳过协议部分if (strncasecmp(m_url, "http://", 7) == 0){m_url += 7;m_url = strchr(m_url, '/'); // 查找URL路径部分}if (strncasecmp(m_url, "https://", 8) == 0){m_url += 8;m_url = strchr(m_url, '/');}if (!m_url || m_url[0] != '/') // 如果URL无效或不以'/'开头,返回BAD_REQUESTreturn BAD_REQUEST;if (strlen(m_url) == 1) // 如果URL为"/",显示默认页面strcat(m_url, "judge.html");m_check_state = CHECK_STATE_HEADER; // 切换状态到解析请求头return NO_REQUEST;
}// 解析HTTP请求的头部信息
http_conn::HTTP_CODE http_conn::parse_headers(char *text)
{if (text[0] == '\0') // 如果当前头部信息为空,表示解析完毕{if (m_content_length != 0) // 如果有消息体,切换到解析消息体的状态{m_check_state = CHECK_STATE_CONTENT;return NO_REQUEST;}return GET_REQUEST; // 如果没有消息体,说明请求已完整,返回GET_REQUEST}// 解析Connection头部,判断是否为长连接else if (strncasecmp(text, "Connection:", 11) == 0){text += 11;text += strspn(text, " \t");if (strcasecmp(text, "keep-alive") == 0){m_linger = true; // 如果是keep-alive,保持长连接}}// 解析Content-Length头部,获取消息体的长度else if (strncasecmp(text, "Content-length:", 15) == 0){text += 15;text += strspn(text, " \t");m_content_length = atol(text); // 将字符串转换为长整型,表示消息体长度}// 解析Host头部,获取主机名else if (strncasecmp(text, "Host:", 5) == 0){text += 5;text += strspn(text, " \t");m_host = text; // 保存主机名}else{LOG_INFO("oop!unknow header: %s", text); // 记录未知的头部字段}return NO_REQUEST; // 继续解析其他头部
}// 解析HTTP请求的消息体
http_conn::HTTP_CODE http_conn::parse_content(char *text)
{if (m_read_idx >= (m_content_length + m_checked_idx)) // 检查是否完整读取了消息体{text[m_content_length] = '\0'; // 将消息体以\0结束m_string = text; // 将消息体存储起来,通常是POST请求的参数return GET_REQUEST; // 消息体解析完成,返回GET_REQUEST}return NO_REQUEST; // 消息体还未解析完整,继续读取
}// 主状态机处理入口,依次调用解析请求行、请求头、消息体的函数
http_conn::HTTP_CODE http_conn::process_read()
{LINE_STATUS line_status = LINE_OK; // 当前行的解析状态HTTP_CODE ret = NO_REQUEST; // HTTP请求的解析结果char *text = 0;// 循环解析HTTP请求,直到完整解析或遇到错误while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) || ((line_status = parse_line()) == LINE_OK)){text = get_line(); // 获取解析到的一行数据m_start_line = m_checked_idx; // 更新已解析的起始位置LOG_INFO("%s", text); // 记录解析到的内容switch (m_check_state) // 根据当前解析状态,处理不同部分{case CHECK_STATE_REQUESTLINE: // 解析请求行{ret = parse_request_line(text); // 调用parse_request_line()函数解析if (ret == BAD_REQUEST) // 如果解析失败,返回错误return BAD_REQUEST;break;}case CHECK_STATE_HEADER: // 解析请求头{ret = parse_headers(text); // 调用parse_headers()函数解析if (ret == BAD_REQUEST) // 如果解析失败,返回错误return BAD_REQUEST;else if (ret == GET_REQUEST) // 如果请求完整,执行do_request(){return do_request();}break;}case CHECK_STATE_CONTENT: // 解析消息体{ret = parse_content(text); // 调用parse_content()函数解析if (ret == GET_REQUEST) // 如果解析成功,执行do_request()return do_request();line_status = LINE_OPEN; // 如果消息体不完整,继续等待数据break;}default:return INTERNAL_ERROR; // 发生未知错误,返回服务器内部错误}}return NO_REQUEST; // 如果还未解析完成,返回NO_REQUEST
}// 处理HTTP请求,生成相应的响应
http_conn::HTTP_CODE http_conn::do_request()
{strcpy(m_real_file, doc_root); // 将网站根目录复制到m_real_file中int len = strlen(doc_root); // 获取根目录路径的长度const char *p = strrchr(m_url, '/'); // 查找请求的最后一个'/',区分不同的URL// 如果是POST请求,且URL是登录或注册请求if (cgi == 1 && (*(p + 1) == '2' || *(p + 1) == '3')){// 根据请求的类型判断是登录还是注册char flag = m_url[1];char *m_url_real = (char *)malloc(sizeof(char) * 200); // 动态分配内存strcpy(m_url_real, "/");strcat(m_url_real, m_url + 2); // 构造实际文件路径strncpy(m_real_file + len, m_url_real, FILENAME_LEN - len - 1); // 拼接完整路径free(m_url_real); // 释放动态内存// 解析POST请求的用户名和密码char name[100], password[100];int i;for (i = 5; m_string[i] != '&'; ++i)name[i - 5] = m_string[i]; // 提取用户名name[i - 5] = '\0';int j = 0;for (i = i + 10; m_string[i] != '\0'; ++i, ++j)password[j] = m_string[i]; // 提取密码password[j] = '\0';// 如果是注册请求if (*(p + 1) == '3'){// 检查数据库中是否存在同名用户char *sql_insert = (char *)malloc(sizeof(char) * 200);strcpy(sql_insert, "INSERT INTO user(username, passwd) VALUES(");strcat(sql_insert, "'");strcat(sql_insert, name);strcat(sql_insert, "', '");strcat(sql_insert, password);strcat(sql_insert, "')");if (users.find(name) == users.end()) // 如果用户不存在,插入新用户{m_lock.lock(); // 加锁,防止并发修改int res = mysql_query(mysql, sql_insert); // 执行插入语句users.insert(pair<string, string>(name, password)); // 更新内存中的用户表m_lock.unlock(); // 解锁if (!res)strcpy(m_url, "/log.html"); // 注册成功,跳转到登录页面elsestrcpy(m_url, "/registerError.html"); // 注册失败,跳转到错误页面}elsestrcpy(m_url, "/registerError.html"); // 用户已存在,返回错误页面}// 如果是登录请求else if (*(p + 1) == '2'){// 检查用户名和密码是否匹配if (users.find(name) != users.end() && users[name] == password)strcpy(m_url, "/welcome.html"); // 登录成功,跳转到欢迎页面elsestrcpy(m_url, "/logError.html"); // 登录失败,跳转到错误页面}}// 根据URL后缀处理不同的页面请求if (*(p + 1) == '0'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/register.html"); // 注册页面strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}else if (*(p + 1) == '1'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/log.html"); // 登录页面strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}else if (*(p + 1) == '5'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/picture.html"); // 图片页面strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}else if (*(p + 1) == '6'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/video.html"); // 视频页面strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}else if (*(p + 1) == '7'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/fans.html"); // 粉丝页面strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}elsestrncpy(m_real_file + len, m_url, FILENAME_LEN - len - 1); // 其他请求,拼接实际文件路径// 检查文件是否存在if (stat(m_real_file, &m_file_stat) < 0)return NO_RESOURCE; // 文件不存在,返回NO_RESOURCE// 检查文件是否有读取权限if (!(m_file_stat.st_mode & S_IROTH))return FORBIDDEN_REQUEST; // 没有权限,返回FORBIDDEN_REQUEST// 检查是否是目录if (S_ISDIR(m_file_stat.st_mode))return BAD_REQUEST; // 请求的是目录,返回BAD_REQUEST// 打开文件int fd = open(m_real_file, O_RDONLY);m_file_address = (char *)mmap(0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0); // 将文件映射到内存close(fd); // 关闭文件描述符return FILE_REQUEST; // 返回文件请求
}// 解除内存映射
void http_conn::unmap()
{if (m_file_address){munmap(m_file_address, m_file_stat.st_size); // 解除文件的内存映射m_file_address = 0; // 重置文件地址指针}
}// 向客户端写入HTTP响应
bool http_conn::write()
{int temp = 0;if (bytes_to_send == 0) // 如果要发送的字节为0,表示响应已经发送完毕{modfd(m_epollfd, m_sockfd, EPOLLIN); // 修改epoll事件为读事件,准备处理下一次请求init(); // 重新初始化连接return true;}// 循环发送响应数据,直到全部发送完成或遇到错误while (1){temp = writev(m_sockfd, m_iv, m_iv_count); // 使用writev函数将响应数据发送给客户端if (temp < 0) // 发送过程中遇到错误{// 如果错误是由于非阻塞写导致的缓冲区已满if (errno == EAGAIN){modfd(m_epollfd, m_sockfd, EPOLLOUT); // 重新注册写事件return true;}unmap(); // 如果遇到其他错误,取消文件映射return false;}bytes_have_send += temp; // 更新已经发送的字节数bytes_to_send -= temp; // 更新剩余需要发送的字节数// 如果已经发送完响应头部if (bytes_have_send >= m_iv[0].iov_len){m_iv[0].iov_len = 0; // 清空头部的iov结构体长度m_iv[1].iov_base = m_file_address + (bytes_have_send - m_write_idx); // 设置发送文件的起始地址m_iv[1].iov_len = bytes_to_send; // 更新剩余需要发送的文件长度}else{m_iv[0].iov_base = m_write_buf + bytes_have_send; // 更新响应头部的发送位置m_iv[0].iov_len -= temp; // 更新头部剩余需要发送的长度}if (bytes_to_send <= 0) // 如果所有数据都已发送完成{unmap(); // 取消文件映射modfd(m_epollfd, m_sockfd, EPOLLIN); // 重新注册读事件if (m_linger) // 如果是长连接{init(); // 重新初始化连接,等待处理新的请求return true;}else{return false; // 如果不是长连接,关闭连接}}}
}// 将HTTP响应生成并写入缓冲区
bool http_conn::add_response(const char *format, ...)
{if (m_write_idx >= WRITE_BUFFER_SIZE) // 如果写入的响应数据超出缓冲区大小,返回false{return false;}va_list arg_list;va_start(arg_list, format); // 开始可变参数处理int len = vsnprintf(m_write_buf + m_write_idx, WRITE_BUFFER_SIZE - 1 - m_write_idx, format, arg_list); // 格式化输出到缓冲区if (len >= (WRITE_BUFFER_SIZE - 1 - m_write_idx)) // 如果格式化后的数据超出缓冲区大小,返回false{va_end(arg_list);return false;}m_write_idx += len; // 更新缓冲区索引va_end(arg_list);LOG_INFO("request:%s", m_write_buf); // 记录生成的响应return true;
}// 向响应中添加状态行
bool http_conn::add_status_line(int status, const char *title)
{return add_response("%s %d %s\r\n", "HTTP/1.1", status, title); // 将状态行写入响应中
}// 向响应中添加头部信息
bool http_conn::add_headers(int content_len)
{add_content_length(content_len); // 添加Content-Length头部,指定响应内容长度add_linger(); // 添加Connection头部,指定是否保持连接add_blank_line(); // 添加空行,表示头部结束return true;
}// 向响应中添加Content-Length头部
bool http_conn::add_content_length(int content_len)
{return add_response("Content-Length:%d\r\n", content_len); // 写入Content-Length头部
}// 向响应中添加Connection头部
bool http_conn::add_linger()
{return add_response("Connection:%s\r\n", (m_linger == true) ? "keep-alive" : "close"); // 根据长连接状态写入Connection头部
}// 向响应中添加空行
bool http_conn::add_blank_line()
{return add_response("%s", "\r\n"); // 写入空行
}// 向响应中添加实际内容
bool http_conn::add_content(const char *content)
{return add_response("%s", content); // 将内容写入响应
}// 处理向客户端返回的完整响应
bool http_conn::process_write(HTTP_CODE ret)
{switch (ret){case INTERNAL_ERROR: // 内部错误时的响应{add_status_line(500, error_500_title); // 添加状态行,状态码500add_headers(strlen(error_500_form)); // 添加响应头if (!add_content(error_500_form)) // 添加错误内容return false;break;}case BAD_REQUEST: // 错误请求时的响应{add_status_line(400, error_400_title); // 添加状态行,状态码400add_headers(strlen(error_400_form)); // 添加响应头if (!add_content(error_400_form)) // 添加错误内容return false;break;}case NO_RESOURCE: // 资源不存在时的响应{add_status_line(404, error_404_title); // 添加状态行,状态码404add_headers(strlen(error_404_form)); // 添加响应头if (!add_content(error_404_form)) // 添加错误内容return false;break;}case FORBIDDEN_REQUEST: // 没有权限访问时的响应{add_status_line(403, error_403_title); // 添加状态行,状态码403add_headers(strlen(error_403_form)); // 添加响应头if (!add_content(error_403_form)) // 添加错误内容return false;break;}case FILE_REQUEST: // 正常的文件请求{add_status_line(200, ok_200_title); // 添加状态行,状态码200if (m_file_stat.st_size != 0) // 如果请求的文件不为空{add_headers(m_file_stat.st_size); // 添加响应头,指定内容长度为文件大小m_iv[0].iov_base = m_write_buf; // 设置第一块内存区域为响应头部m_iv[0].iov_len = m_write_idx;m_iv[1].iov_base = m_file_address; // 设置第二块内存区域为文件内容m_iv[1].iov_len = m_file_stat.st_size;m_iv_count = 2;bytes_to_send = m_write_idx + m_file_stat.st_size; // 更新需要发送的总字节数return true;}else{const char *ok_string = "<html><body></body></html>"; // 如果文件为空,返回一个简单的HTML页面add_headers(strlen(ok_string)); // 添加响应头if (!add_content(ok_string)) // 添加空页面的内容return false;}}default:return false;}m_iv[0].iov_base = m_write_buf; // 设置第一块内存区域为响应头部m_iv[0].iov_len = m_write_idx;m_iv_count = 1;bytes_to_send = m_write_idx; // 更新需要发送的字节数return true;
}// 主逻辑函数,负责处理HTTP请求并生成响应
void http_conn::process()
{HTTP_CODE read_ret = process_read(); // 调用process_read解析HTTP请求if (read_ret == NO_REQUEST) // 如果请求不完整,继续监听{modfd(m_epollfd, m_sockfd, EPOLLIN);return;}bool write_ret = process_write(read_ret); // 生成响应if (!write_ret){close_conn(); // 如果生成响应失败,关闭连接}modfd(m_epollfd, m_sockfd, EPOLLOUT); // 修改epoll事件为写事件,准备发送响应
}相关文章:
_ http_conn.cpp)
TinyWebSever源码逐行注释(五)_ http_conn.cpp
前言 项目源码地址 项目详细介绍 项目简介: Linux下C轻量级Web服务器,助力初学者快速实践网络编程,搭建属于自己的服务器. 使用 线程池 非阻塞socket epoll(ET和LT均实现) 事件处理(Reactor和模拟Proactor均实现) 的并发模型使用状态机…...

windows手工杀毒-寻找可疑进程之句柄
上篇回顾:windows手工杀毒-寻找可疑进程之内存-CSDN博客 上篇中我们介绍了如果通过进程的内存分析进程是否是可疑进程,主要是通过查看是否有可写可执行的内存页。也可以通过查看内存内容,看是否是可疑内容,不过这个可能需…...

java开发后端
1.BeanUtils.toBean 方法 它是一个常见的 Java 工具方法,用于将一个 JavaBean 对象转换为另一个 JavaBean 对象 FlowOrderDO flowOrder BeanUtils.toBean(createReqVO, FlowOrderDO.class); 这行代码使用了 BeanUtils.toBean 方法,它是一个常见的 Ja…...

Redis 的标准使用规范之数据类型使用规范
数据类型使用规范 提示:以下是本篇文章正文内容,可供参考 (1)、字符文本(STRING) 【建议】选型为简易文本类缓存 :比如普通的字符、文本、Json 结构 ,通常能起到加速读写和降低后端压力的作用。 【建议】…...

人工智能技术导论——基于产生式规则的机器推理
在引出本章的内容之前先介绍一个概念 知识 知识的概念 知识(Knowledge)是人们在改造客观世界的实践中形成的对客观事物(包括自然的和人造的)及其规律的认识,包括对事物的现象、本质、状态、关系、联系和运动等的认识…...

Apache Guacamole 安装及配置VNC远程桌面控制
文章目录 官网简介支持多种协议无插件浏览器访问配置和管理应用场景 Podman 部署 Apache Guacamole拉取 docker 镜像docker-compose.yml部署 PostgreSQL生成 initdb.sql 脚本部署 guacamole Guacamole 基本用法配置 VNC 连接 Mac 电脑开启自带的 VNC 服务 官网 https://guacam…...

在Linux中从视频流截取图片帧(ffmpeg )
Linux依赖说明: 说明: 使用到的 依赖包 1. ffmpegsudo apt update sudo apt-get install ffmpeg2. imagemagick (选装) (检测图像边缘信息推断清晰度,如果是简单截取但个图像帧>用不到<)sudo apt-get install imagemagick备注: 指令及相关参数说明核心指令: (作用: 执…...

使用脚手架来创建 express 项目
使用脚手架(scaffold)可以快速搭建Express应用程序的基本结构。Express自身提供了一个官方脚手架工具叫做express-generator,它可以帮助你快速地生成一个包含基本文件结构的Express项目。 安装Express Generator 首先,你需要全局…...

单片机常用的软件架构
参考 9种单片机常用的软件架构...
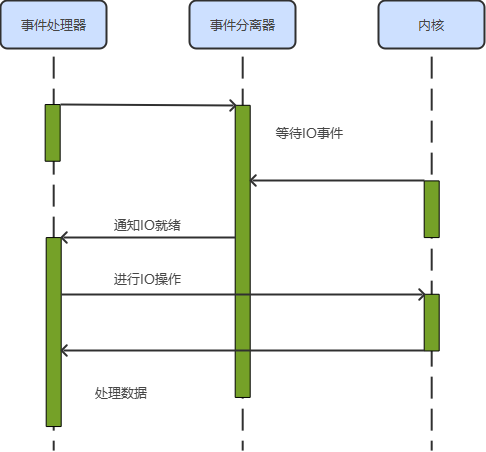
服务器模型 Reactor 和 Proactor
Proactor 具体流程如下: 处理器发起异步操作,并关注 IO 完成事件;事件分离器等待操作完成事件;分离器等待过程中,内核并行执行实际的 IO 操作,并将结果存储入用户自定义的缓冲区,最后通知事件分…...

使用 Grype 检查 .jar 包中的漏洞
在开发和部署 Java 应用时,确保依赖库和项目文件中的安全性至关重要。Grype 是一款强大的开源工具,用于扫描项目文件(如 .jar 包)中的已知漏洞。本篇博客将介绍如何手动安装 Grype 并使用它检测 .jar 包中的安全漏洞。 一、手动安…...

IDEA 常用插件推荐,美观又实用!
1、 TONGYl Lingma - Your Al Coding Assistant. Type less, Code more. 通义灵码,是一款基于通义大模型的智能编码辅助工具,提供行级/函数级实时续写、自然语言生成代码、单元测试生成、代码注释生成、代码解释、研发智能问答、异常报错排查等能力&…...

浮点数精度问题
为什么会产生精度问题? 我们带着这个问题去探寻浮点数二进制的存储原理 浮点数是怎么存在计算机中的? 浮点数在计算机中的表示通常遵循IEEE 754标准。其基本概念如下: 结构:浮点数由三部分组成: 符号位(…...

RK3576芯片在智能家居里中型智慧屏产品的应用方案分析
智能家居在近年来得到了快速发展,AI技术不断发展,人机交互十分成熟,各种家电也都迎来了智能化浪潮,智能家居为人们提供了优秀的产品体验,受到主流消费者的青睐,智能家居里的中型智慧屏产品也随之兴起。 瑞芯…...

什么是生成式 AI?
人工智能 (AI) 通过使用机器学习与环境交互并执行任务来模仿人类行为,而无需明确指示要输出的内容。 生成式 AI 描述 AI 中用于创建原创内容的一类功能。 人员通常与聊天应用程序中内置的生成式 AI 交互。 此类应用程序的一个常见示例是 Microsoft Copilot…...

计算机网络期末试题及答案
一、选择题(每空2分,共20分) 1、下列关于常用交换技术的描述不正确的是( )。 A、电路交换是面向连接可靠的,适合大量的、连续的数据传输。 B、分组交换采用存储转发方式,以较小的固定长度的分组作为数据传输单…...

MySQL中DML操作(一)
添加数据(INSERT) 1.选择插入 INSERT INTO 表名(列名1 , 列名2 , 列名3......) VALUES(值1 , 值2 , 值3......); 示例: 向departments表中添加一条数据,部门名称为market,工作地点ID为1。 insert into department…...

Django 模板继承
Django 模板继承的语法主要涉及两个关键标签:{% extends %} 和 {% block %}。 语法详解 {% extends %}: 用于指定当前模板继承自哪个父模板。语法:{% extends "父模板的路径" %} {% extends "base.html" %}{% block %}&…...

黑马点评17——多级缓存-Lua语法
文章目录 Lua语法初始Lua变量和循环条件控制、函数 变量和循环函数和条件控制 Lua语法 初始Lua https://www.lua.org/ 魔兽的一些插件就是用lua开发的。 centOs已经装好了lua,直接用~ 变量和循环 条件控制、函数 变量和循环 函数和条件控制...
如何在Linux 上运行 SciChart WPF图表控件?
SciChart – 一个跨平台图表库,可实现 Windows Presentation Foundation (WPF)、JavaScript 以及原生 iOS (Swift/Objective-C) 和 Android (Java/Kotlin),基于代号为 Visual Xccelerator 的专有 C 渲染引擎。这提供了 SciChart 众所周知的速度和性能&am…...

终极指南:如何用calendar.js轻松实现农历公历智能转换
终极指南:如何用calendar.js轻松实现农历公历智能转换 【免费下载链接】calendar.js 中国农历(阴阳历)和西元阳历即公历互转JavaScript库 项目地址: https://gitcode.com/gh_mirrors/ca/calendar.js 想要在你的Web应用中添加中国传统文…...

混合强化学习驱动的智能营销决策框架
1. 项目概述:当营销决策遇上“会思考的机器人” 你有没有遇到过这样的场景:市场部刚上线一套新用户分群模型,A/B测试跑了一周,结果发现高价值用户转化率不升反降;或者运营团队精心设计的优惠券发放策略,在季…...

RK3568播放RTSP摄像头实测:软解1080P直接CPU跑满,降到360P才流畅,硬解到底怎么搞?
RK3568 RTSP摄像头解码实战:从软解瓶颈到硬解优化全解析 最近在调试RK3568开发板的RTSP摄像头播放功能时,遇到了一个典型问题:1080P软解直接让CPU跑满,降到360P才能勉强流畅。这让我开始深入探索瑞芯微平台的硬解方案,…...

Monocle投票系统实现原理:构建高效的帖子排名算法
Monocle投票系统实现原理:构建高效的帖子排名算法 【免费下载链接】monocle Link and news sharing 项目地址: https://gitcode.com/gh_mirrors/mon/monocle Monocle是一个功能强大的链接和新闻聚合平台,其核心功能之一就是智能投票排名系统。这篇…...

eLabFTW电子实验室笔记本架构设计与Docker容器化部署指南
eLabFTW电子实验室笔记本架构设计与Docker容器化部署指南 【免费下载链接】elabftw :notebook: eLabFTW is the most popular open source electronic lab notebook for research labs. 项目地址: https://gitcode.com/gh_mirrors/el/elabftw eLabFTW作为开源电子实验室…...

抖音批量下载神器:免费开源工具解决你的视频保存难题
抖音批量下载神器:免费开源工具解决你的视频保存难题 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

如何在5分钟内掌握Windows上最强大的屏幕标注工具ppInk
如何在5分钟内掌握Windows上最强大的屏幕标注工具ppInk 【免费下载链接】ppInk Fork from Gink 项目地址: https://gitcode.com/gh_mirrors/pp/ppInk 你是否曾在演示、教学或远程协作中,需要在屏幕上快速标注重点,却发现工具要么太复杂࿰…...

PEMS交通数据分析实战:如何用Python从海量5分钟速度数据中挖掘拥堵规律?
PEMS交通数据分析实战:如何用Python从海量5分钟速度数据中挖掘拥堵规律? 在智能交通系统快速发展的今天,PEMS(Performance Measurement System)提供的5分钟级交通流数据已成为城市拥堵分析和路网优化的黄金标准。这些看…...

RTX251实时系统中NMI中断支持问题解析
1. RTX251调试中的NMI中断问题解析在嵌入式系统开发中,非屏蔽中断(NMI)作为一种高优先级的中断机制,通常用于处理系统关键错误和调试场景。然而,当使用Keil的RTX251实时操作系统与Temic 251系列芯片配合时,开发者可能会遇到NMI支持…...
LibreSprite:为什么这款开源像素动画软件能成为独立开发者的首选?
LibreSprite:为什么这款开源像素动画软件能成为独立开发者的首选? 【免费下载链接】LibreSprite Animated sprite editor & pixel art tool -- Fork of the last GPLv2 commit of Aseprite 项目地址: https://gitcode.com/gh_mirrors/li/LibreSpri…...