深度学习基础案例4--运用动态学习率构建CNN卷积神经网络实现的运动鞋识别(测试集的准确率84%)
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
前言
- 前几天一直很忙,一直在数学建模中,没有来得及更新,接下来将恢复正常
- 这一次的案例很有意思:在学习动态调整学习率的时候,本来想着记录训练过程中的训练集中损失率最低的学习率,记录下来了发现是:0.001(是初始值),然后用0.001去训练,发现出现了过拟合,哈哈哈哈哈。
目标
- 学习动态调整学习率
- 使测试集的准确率达到84%
结果
- 达到了84%
1、数据预处理
数据文件夹说明(data): 分为训练集和测试集,每个文件夹里面都含有不同品牌的运动鞋分类,分类单独一个文件
1、导入库
import torch
import torch.nn as nn
import torchvision
import numpy as np
import os, PIL, pathlib device = ('cuda' if torch.cuda.is_available() else 'cup')
device
输出:
'cuda'
2、数据导入与展示
# 查看数据数据文件夹内容
data_dir = './data/train/'
data_dir = pathlib.Path(data_dir)# 获取该文件夹内内容
data_path = data_dir.glob('*') # 获取绝对路径
classNames = [str(path).split('\\')[2] for path in data_path]
classNames
输出:
['adidas', 'nike']
# 数据展示
import matplotlib.pyplot as plt
from PIL import Image# 获取文件名称
data_path_name = './data/train/nike/'
data_path_list = [f for f in os.listdir(data_path_name) if f.endswith(('jpg', 'png'))]# 创建画板
fig, axes = plt.subplots(2, 8, figsize=(16, 6)) # fig:画板,ases子图# 展示
for ax, img_file in zip(axes.flat, data_path_list):path_name = os.path.join(data_path_name, img_file)img = Image.open(path_name)ax.imshow(img)ax.axis('off')plt.show()

3、数据处理
# 将所有的数据图片统一格式
from torchvision import transforms, datasets train_path = './data/train/'
test_path = './data/test/'# 定义训练集、测试集图片标准
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 统一图片大小transforms.ToTensor(), # 统一规格transforms.Normalize( # 数据标准化mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225] )
])test_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225] )
])# 数据处理
train_data = datasets.ImageFolder(root=train_path, transform=train_transforms)
test_data = datasets.ImageFolder(root=test_path, transform=test_transforms)
4、加载与划分动态数据
batch_size = 32train_dl = torch.utils.data.DataLoader(train_data,batch_size=batch_size,shuffle=True,num_workers=1)test_dl = torch.utils.data.DataLoader(test_data,batch_size=batch_size,shuffle=True,num_workers=1)
# 展示图像参数
for param, data in train_dl:print("image(N, C, H, W): ", param.shape)print("data: ", data)break
image(N, C, H, W): torch.Size([32, 3, 224, 224])
data: tensor([0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0,0, 1, 1, 0, 1, 0, 0, 0])
2、构建CNN神经网络
卷积:--> 12*220*220 --> 12*216*216
池化:--> 12*108*108
卷积: --> 24*104*104 --> 24*100*100
池化:--> 24*50*50 --> 25*50*2
import torch.nn.functional as F class Net_work(nn.Module):def __init__(self):super(Net_work, self).__init__() # 父类信息构建self.conv1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, padding=0),nn.BatchNorm2d(12), # 第一个参数:特征数量nn.ReLU())self.conv2 = nn.Sequential(nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, padding=0),nn.BatchNorm2d(12),nn.ReLU())self.pool1 = nn.Sequential(nn.MaxPool2d(2, 2))self.conv3 = nn.Sequential(nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, padding=0),nn.BatchNorm2d(24),nn.ReLU())self.conv4 = nn.Sequential(nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, padding=0),nn.BatchNorm2d(24),nn.ReLU())self.pool2 = nn.Sequential(nn.MaxPool2d(2, 2))self.dropout = nn.Sequential(nn.Dropout(0.2))self.fc = nn.Sequential(nn.Linear(24*50*50, len(classNames)))def forward(self, x):batch_size = x.size(0) # 每一次训练的批次大小,N,C,H,Wx = self.conv1(x) # 卷积-->NB-->激活x = self.conv2(x) # 卷积-->NB-->激活x = self.pool1(x) # 池化x = self.conv3(x) # 卷积-->NB-->激活x = self.conv4(x) # 卷积-->NB-->激活x = self.pool2(x) # 池化x = x.view(batch_size, -1) # -1,代表自动展示,将24*50*50展开x = self.fc(x)return x
# 将网络结构导入GPU
model = Net_work().to(device)
model
输出:
Net_work((conv1): Sequential((0): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU())(conv2): Sequential((0): Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1))(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU())(pool1): Sequential((0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(conv3): Sequential((0): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU())(conv4): Sequential((0): Conv2d(24, 24, kernel_size=(5, 5), stride=(1, 1))(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU())(pool2): Sequential((0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(dropout): Sequential((0): Dropout(p=0.2, inplace=False))(fc): Sequential((0): Linear(in_features=60000, out_features=2, bias=True))
)
3、模型的训练准备
1、设置超参数
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
# 初始化学习率
lr = 1e-4
# 创建梯度下降法
optimizer = torch.optim.SGD(model.parameters(), lr=lr)2、创建训练函数
def train(dataloader, model, loss_fn, optimizer):# 总大小size = len(dataloader.dataset)# 批次大小batch_size = len(dataloader)# 准确率和损失trian_acc, train_loss = 0, 0# 训练for X, y in dataloader:X, y = X.to(device), y.to(device)# 模型训练与误差评分pred = model(X)loss = loss_fn(pred, y)# 梯度清零optimizer.zero_grad() # 梯度上更新# 方向传播loss.backward()# 梯度更新optimizer.step()# 记录损失和准确率train_loss += loss.item()trian_acc += (pred.argmax(1) == y).type(torch.float64).sum().item()# 计算损失和准确率trian_acc /= sizetrain_loss /= batch_sizereturn trian_acc, train_loss
3、创建测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)batch_size = len(dataloader)test_acc, test_loss = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_loss += loss.item()test_acc += (pred.argmax(1) == y).type(torch.float64).sum().item()test_acc /= size test_loss /= batch_sizereturn test_acc, test_loss
4、动态调整学习率
def adjust_learning_rate(optimizer, epoch, start_lr):# 调整规则:每 2 次都衰减到原来的 0.92lr = start_lr * (0.95 ** (epoch // 2))for param_group in optimizer.param_groups:param_group['lr'] = lr
4、正式训练
train_acc = []
train_loss = []
test_acc = []
test_loss = []# 定义训练次数
epoches = 40for epoch in range(epoches):# 动态调整学习率adjust_learning_rate(optimizer, epoches, lr)# 训练model.train()epoch_trian_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)# 测试model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)# 记录train_acc.append(epoch_trian_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')print(template.format(epoch+1, epoch_trian_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
Epoch: 1, Train_acc:52.0%, Train_loss:0.736, Test_acc:52.6%, Test_loss:0.695
Epoch: 2, Train_acc:59.2%, Train_loss:0.685, Test_acc:61.8%, Test_loss:0.672
Epoch: 3, Train_acc:65.1%, Train_loss:0.644, Test_acc:72.4%, Test_loss:0.593
Epoch: 4, Train_acc:66.7%, Train_loss:0.616, Test_acc:65.8%, Test_loss:0.571
Epoch: 5, Train_acc:69.3%, Train_loss:0.602, Test_acc:68.4%, Test_loss:0.555
Epoch: 6, Train_acc:69.7%, Train_loss:0.580, Test_acc:69.7%, Test_loss:0.525
Epoch: 7, Train_acc:73.3%, Train_loss:0.559, Test_acc:77.6%, Test_loss:0.530
Epoch: 8, Train_acc:75.9%, Train_loss:0.544, Test_acc:71.1%, Test_loss:0.513
Epoch: 9, Train_acc:75.7%, Train_loss:0.531, Test_acc:75.0%, Test_loss:0.495
Epoch:10, Train_acc:78.7%, Train_loss:0.517, Test_acc:81.6%, Test_loss:0.508
Epoch:11, Train_acc:78.9%, Train_loss:0.499, Test_acc:78.9%, Test_loss:0.503
Epoch:12, Train_acc:81.3%, Train_loss:0.486, Test_acc:77.6%, Test_loss:0.482
Epoch:13, Train_acc:80.5%, Train_loss:0.480, Test_acc:76.3%, Test_loss:0.476
Epoch:14, Train_acc:83.3%, Train_loss:0.468, Test_acc:81.6%, Test_loss:0.497
Epoch:15, Train_acc:81.7%, Train_loss:0.459, Test_acc:81.6%, Test_loss:0.518
Epoch:16, Train_acc:83.9%, Train_loss:0.461, Test_acc:77.6%, Test_loss:0.465
Epoch:17, Train_acc:85.9%, Train_loss:0.443, Test_acc:78.9%, Test_loss:0.497
Epoch:18, Train_acc:84.9%, Train_loss:0.430, Test_acc:78.9%, Test_loss:0.485
Epoch:19, Train_acc:85.9%, Train_loss:0.428, Test_acc:78.9%, Test_loss:0.504
Epoch:20, Train_acc:86.5%, Train_loss:0.418, Test_acc:82.9%, Test_loss:0.446
Epoch:21, Train_acc:87.5%, Train_loss:0.406, Test_acc:82.9%, Test_loss:0.464
Epoch:22, Train_acc:87.5%, Train_loss:0.403, Test_acc:78.9%, Test_loss:0.486
Epoch:23, Train_acc:87.6%, Train_loss:0.393, Test_acc:81.6%, Test_loss:0.443
Epoch:24, Train_acc:88.6%, Train_loss:0.391, Test_acc:84.2%, Test_loss:0.435
Epoch:25, Train_acc:89.8%, Train_loss:0.374, Test_acc:78.9%, Test_loss:0.421
Epoch:26, Train_acc:89.8%, Train_loss:0.371, Test_acc:81.6%, Test_loss:0.444
Epoch:27, Train_acc:90.2%, Train_loss:0.372, Test_acc:82.9%, Test_loss:0.435
Epoch:28, Train_acc:90.8%, Train_loss:0.360, Test_acc:80.3%, Test_loss:0.431
Epoch:29, Train_acc:89.8%, Train_loss:0.356, Test_acc:80.3%, Test_loss:0.423
Epoch:30, Train_acc:91.8%, Train_loss:0.346, Test_acc:78.9%, Test_loss:0.447
Epoch:31, Train_acc:91.2%, Train_loss:0.343, Test_acc:84.2%, Test_loss:0.420
Epoch:32, Train_acc:92.4%, Train_loss:0.338, Test_acc:82.9%, Test_loss:0.455
Epoch:33, Train_acc:92.8%, Train_loss:0.333, Test_acc:80.3%, Test_loss:0.469
Epoch:34, Train_acc:92.4%, Train_loss:0.326, Test_acc:80.3%, Test_loss:0.432
Epoch:35, Train_acc:93.0%, Train_loss:0.321, Test_acc:82.9%, Test_loss:0.429
Epoch:36, Train_acc:92.4%, Train_loss:0.323, Test_acc:77.6%, Test_loss:0.459
Epoch:37, Train_acc:93.8%, Train_loss:0.312, Test_acc:84.2%, Test_loss:0.458
Epoch:38, Train_acc:94.0%, Train_loss:0.312, Test_acc:84.2%, Test_loss:0.437
Epoch:39, Train_acc:94.8%, Train_loss:0.306, Test_acc:81.6%, Test_loss:0.434
Epoch:40, Train_acc:93.6%, Train_loss:0.304, Test_acc:84.2%, Test_loss:0.421
5、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epoch_length = range(epoches)plt.figure(figsize=(12, 3))plt.subplot(1, 2, 1)
plt.plot(epoch_length, train_acc, label='Train Accuaray')
plt.plot(epoch_length, test_acc, label='Test Accuaray')
plt.legend(loc='lower right')
plt.title('Accurary')plt.subplot(1, 2, 2)
plt.plot(epoch_length, train_loss, label='Train Loss')
plt.plot(epoch_length, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Loss')plt.show()

模型评价
-
准确率:
- 训练集稳定逐步上升
- 测试集不太稳定,但是总体趋向上升
-
损失率:
- 训练集和测试集总体趋于下降
- 训练和测试的差距后面,大于0.1,继续训练可能会出现过拟合的现象
6、预测
from PIL import Image# 获取类型
classes = list(train_data.class_to_idx)# 需要参数:路径、模型、类别
def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB') # 以GRB颜色打开# 展示plt.imshow(test_img)test_img = transform(test_img) # 统一规格# 压缩img = test_img.to(device).unsqueeze(0) # 去掉第一个 1# 预测model.eval()output = model(img)_, pred = torch.max(output, 1)pred_class = classes[pred]print(f'预测结果是: {pred_class}')# 预测
predict_one_image("./data/test/adidas/10.jpg", model, train_transforms, classes)
预测结果是: adidas

7、模型保存
path = './model.pth'
torch.save(model.state_dict(), path) # 保存模型状态model.load_state_dict(torch.load(path, map_location=device)) # 报错模型参数
输出:
<All keys matched successfully>
8、总结
准确率和损失率:
-
理想:测试集损失率底,且测试集准确率高
-
过拟合:训练集准确率高,而测试集准确率比较低,比如在这个案例中,如果学习率直接设置固定值,会发现到后面的时候,准确率上升,甚至达到了98%,但是测试集准确率却一直在78%徘徊,故如训练次数多的时候,训练集准确度一般会一直上升(有梯度下降法优化),但是测试集可能会在后一个地方一直徘徊,甚至出现下降的现象,从而出现过拟合的现象
相关文章:
深度学习基础案例4--运用动态学习率构建CNN卷积神经网络实现的运动鞋识别(测试集的准确率84%)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 前几天一直很忙,一直在数学建模中,没有来得及更新,接下来将恢复正常这一次的案例很有意思:在学习动态调整…...
tekton pipeline workspaces
tekton pipeline workspace是一种为执行中的管道及其任务提供可用的共享卷的方法。 在pipeline中定义worksapce作为共享卷传递给相关的task。在tekton中定义workspace的用途有以下几点: 存储输入和/或输出在task之间共享数据secret认证的挂载点ConfigMap中保存的配置的挂载点…...

[git操作] git创建仓库上传github报错
操作流程如下 使用 git init使用 git remote add origin 项目ssh链接git add . 报错如下 Bus error (core dumped)然后执行任何别的操作都会报错: fatal: Unable to create path .. /.git/index.lock: File exists.Another git process seems to be running in …...

飞牛fnOS安装KDE桌面
飞牛fnOS安装KDE桌面 这段时间新出的nas系统飞牛os真不错,基于debian的可折腾性又高了不少,今天就来给这个系统装个桌面,插上显示器也能当个电脑自己进自己的管理界面,播放下视频,上上网啥的。 文章目录 飞牛fnOS安装…...

运维Tips | 如何安全的移除系统中旧的Linux内核?
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] 如何安全的删除系统中旧的 Linux 内核? 描述:如果更新了 Linux 操作系统,那么你会注意到,每次升级 Linux 内核后,GRUB 菜单都会添加一个新的引导条…...
基于JAVA+SpringBoot+Vue的工程教育认证的计算机课程管理平台
基于JAVASpringBootVue的工程教育认证的计算机课程管理平台 前言 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN[新星计划]导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末附源码下载链接…...

软件质量保障:故障演练介绍
目录 背景:架构变化带来的问题 什么是故障演练 为什么需要故障演练 故障演练场景有哪些 不同演练类型和目标 如何对工具进行评估 功能评测项 告警评测项 观测指标评测项 总结 背景:架构变化带来的问题 随着架构越来越复杂、应用越来越多样&…...

Vue3可编辑表格插件
插件亮点: 通过可自定义单元格内容。可控的状态控制,例如只读、禁止编辑行等配置。可控的状态交互,例如框选单元格、框选行等配置。可控的推拽顺序,例如拖拽行、推拽列。方便的单元格数据验证配置。方便的快捷右键菜单,…...

RedisTemplate操作Redis
文章目录 1. String 命令1.1 添加缓存1.2 设置过期时间(单独设置)1.3 获取缓存值1.4 删除key1.5 顺序递增1.6 顺序递减1.7 常用的 2. Hash命令2.1 添加缓存2.2 设置过期时间(单独设置)2.3 添加一个Map集合2.4 提取所有的小key2.5 提取所有的value值2.6 根据key提取value值2.7 获…...

Web安全:SQL注入实战测试.(扫描 + 测试)
Web安全:SQL注入实战测试. SQL注入就是 有些恶意用户在提交查询请求的过程中 将SQL语句插入到请求内容中,同时程序的本身对用户输入的内容过于相信,没有对用户插入的SQL语句进行任何的过滤,从而直接被SQL语句直接被服务端执行&am…...
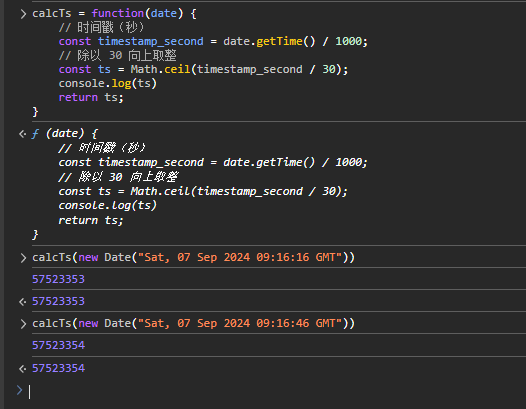
猜测、实现 B 站在看人数
猜测、实现 B 站在看人数 猜测找到接口参数总结 实现 猜测 找到接口 浏览器打开一个 B 站视频,比如 《黑神话:悟空》最终预告 | 8月20日,重走西游_黑神话悟空 (bilibili.com) ,打开 F12 开发者工具,经过观察…...

网络编程(UDP)
UDP编程 UDP:全双工通信、面向无连接、不可靠 UDP(User Datagram Protocol)用户数据报协议,是不可靠的无连接的协议。在数据发送前,因为不需要进行连接,所以可以进行高效率的数据传输。 适用场景 发送小尺寸…...

CENet及多模态情感计算实战(论文复现)
CENet及多模态情感计算实战(论文复现) 本文所涉及所有资源均在传知代码平台可获取 文章目录 CENet及多模态情感计算实战(论文复现)概述研究背景主要贡献论文思路主要内容和网络架构数据集介绍性能对比复现过程(重要&am…...
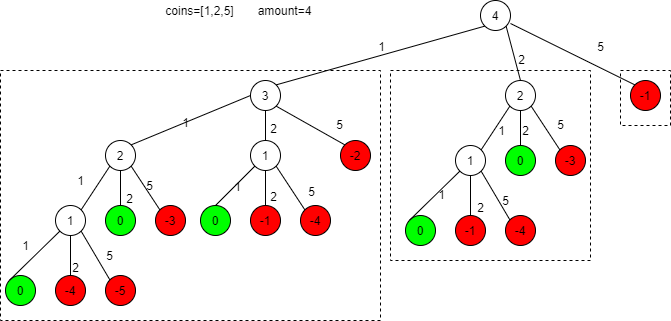
备战秋招60天算法挑战,Day34
题目链接: https://leetcode.cn/problems/coin-change/ 视频题解: https://www.bilibili.com/video/BV1qsvDeHEkg/ LeetCode 322.零钱兑换 题目描述 给你一个整数数组coins,表示不同面额的硬币;以及一个整数amount,表…...

vue实现评论滚动效果
vue插件实现滚动效果 一、安装组件 官网地址:https://chenxuan0000.github.io/vue-seamless-scroll/ 1、vue2安装 npm install vue-seamless-scroll --savevue3安装 npm install vue3-seamless-scroll --save二、组件引入 <template><div v-if"…...

iphone13 不升级IOS使用广电卡
iPhone13的信号📶,15系统刷高版本iPCC,本帖以后不再更新!!! 自从知道可以通过刷iPCC的方式改善信号(不更新iOS大版本的情况下),尝试了各种版本。 我自己用下来总结 - 移动联通48、49、50 &…...
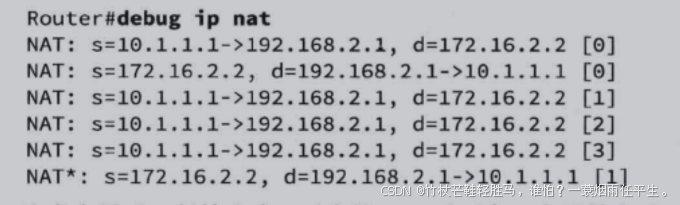
网络地址转换
文章目录 1. NAT使用环境2. NAT的优缺点3. NAT的三种类型4. NAT工作原理5. 配置示例6. 常用排错命令 1. NAT使用环境 需要连接到互联网,但主机没有全局唯一的IP地址;更换的ISP的要求对网络进行重新编址;需要合并两个使用相同编址方案的内联网…...

【python】 @property属性详解 and mysql的sqlalchemy的原生sql
【python】 property属性详解 一文搞懂python中常用的装饰器(classmethod、property、staticmethod、abstractmethod…) sqlalchemy的原生sql from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker# 数据库连接字符串 DATAB…...

西门子WinCC开发笔记(一):winCC西门子组态软件介绍、安装
文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/142060535 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、Op…...

如何在5个步骤中编写更好的ChatGPT提示
ChatGPT是一个风靡全球的生成式人工智能 (AI) 工具。虽然它有可能编造一些东西,但是通过精心设计提示,可以确保获得最佳结果。在这篇文章中,我们将探讨如何做到这一点。 在本文中,我将向你展示如何编写提示,激励驱动C…...

Navicat16/17 Mac版试用期终极重置指南:三种自动化方案实现无限免费使用
Navicat16/17 Mac版试用期终极重置指南:三种自动化方案实现无限免费使用 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_ma…...

树莓派4B部署YOLOv8保姆级避坑指南:从PyTorch版本选择到模型推理全流程
树莓派4B部署YOLOv8实战手册:从版本适配到高效推理的深度解析 引言 在嵌入式设备上部署现代计算机视觉模型,就像给一辆微型赛车装上F1引擎——潜力巨大但挑战重重。最近帮朋友在树莓派4B上部署YOLOv8时,我们花了三天时间才走出"依赖地狱…...

Windows与Linux跨系统数据传输:从SCP、Rsync到自动化脚本的完整指南
1. 项目概述:为什么我们需要跨系统传输数据?在混合IT环境成为常态的今天,一个典型的开发或运维场景是:你的主力工作机运行着Windows,而你的代码、应用或数据处理任务则部署在远端的Linux服务器上。无论是将本地的配置文…...
一套代码搞定 App/小程序/H5/PC,私域流量神器)
别再重复造轮子了!这个开源论坛小程序(Java+Uniapp)一套代码搞定 App/小程序/H5/PC,私域流量神器
你是否有过这些想法? 我想做个类似“知识星球”的圈子小程序,但外包报价动辄 5 万起…… 公司要做私域社区,需要同时支持微信小程序和 App,难道要养两个开发团队? 想靠“付费帖子 会员 打赏”变现,去哪…...

从VLP-16到国产激光雷达:拆解看机械旋转式LiDAR的技术传承与差异
从VLP-16到国产激光雷达:机械旋转式LiDAR的技术传承与创新 在自动驾驶技术快速发展的浪潮中,激光雷达(LiDAR)作为环境感知的核心传感器,其技术演进一直备受关注。VLP-16作为机械旋转式LiDAR的经典产品,不仅…...

hoverboard-firmware-hack-FOC终极兼容性指南:STM32F103RCT6与GD32F103RCT6深度对比
hoverboard-firmware-hack-FOC终极兼容性指南:STM32F103RCT6与GD32F103RCT6深度对比 【免费下载链接】hoverboard-firmware-hack-FOC With Field Oriented Control (FOC) 项目地址: https://gitcode.com/GitHub_Trending/ho/hoverboard-firmware-hack-FOC 想…...

什么是运算符
等一下...

Ubuntu 18.04环境下小米K30U内核编译实战与排错指南
1. 项目概述与核心价值最近在折腾一台小米K30U,想给它刷个自定义内核,体验一下超频或者优化调度。但网上的教程要么是针对新机型,要么就是环境配置说得不清不楚,特别是对于Ubuntu 18.04这个已经有点“年迈”但依然稳定的系统版本&…...

2026年,写给所有还在迷茫的技术人:你的坚持终将闪耀
站在2026年的节点回望,整个互联网行业的寒潮似乎还没完全退去,AI大模型重构业务逻辑的浪潮又拍在了每个技术人的岸边。尤其是对千万软件测试从业者来说,这种迷茫感来得更加具体:手工测试岗位不断被自动化脚本挤压,纯功…...

harmonyos-ai-skill:让 Cursor 按 ArkTS 规范写鸿蒙,不再瞎编 API
端侧 Kit、MCP 接线都写过之后,写代码的人仍会遇到:Cursor 生成「像 React 的 ArkTS」、编造不存在的 Kit 名。社区项目 harmonyos-ai-skill 用可安装知识包,把 API 11 / DevEco 6 约束塞进 AI 工具链。 1. 问题:通用大模型不懂你…...