【LLM论文日更】| LLM2Vec揭秘大型语言模型的文本嵌入潜能
- 论文:https://arxiv.org/pdf/2404.05961
- 代码:https://github.com/McGill-NLP/llm2vec
- 机构:McGill University, Mila ServiceNow Research ,Facebook CIFAR AI Chair
- 领域:embedding model
- 发表:COLM 2024
研究背景
- 研究问题:这篇文章要解决的问题是如何将解码器仅的语言模型(LLMs)有效地转换为强大的文本编码器。尽管LLMs在大多数自然语言处理(NLP)任务中表现出色,但社区对其在文本嵌入任务中的应用进展缓慢。
- 研究难点:该问题的研究难点包括:解码器仅的LLMs的因果注意力机制限制了它们生成丰富上下文表示的能力;需要在不依赖昂贵适应或合成数据的情况下实现参数高效的转换。
- 相关工作:该问题的研究相关工作有:传统的预训练双向编码器或编码器-解码器模型(如BERT和T5),这些模型通常通过多步骤训练管道进行适应;最近的研究开始探索解码器仅的LLMs在文本嵌入任务中的应用
研究方法
这篇论文提出了LLM2Vec,一种简单的无监督方法,可以将任何解码器仅的LLM转换为通用文本编码器。具体来说,LLM2Vec包括三个简单步骤:
- 启用双向注意力:通过替换解码器仅的LLM的因果注意力掩码为一个全1矩阵,使每个令牌能够访问序列中的每个其他令牌,从而将其转换为双向LLM。
- 掩码下一个令牌预测(MNTP):使用MNTP训练目标,结合下一个令牌预测和掩码语言建模。给定一个输入序列,随机掩盖一部分输入令牌,然后训练模型根据过去和未来的上下文预测被掩盖的令牌。重要的是,在预测位置i的掩码令牌时,基于前一个位置的令牌表示计算损失。
- 无监督对比学习:通过SimCSE应用无监督对比学习,生成同一句子的两种不同表示,并训练模型最大化这两种表示之间的相似性,同时最小化与其他句子表示的相似性。

实验设计
- 模型选择:实验使用了三种不同的解码器仅的LLMs,参数从1.3B到8B不等:S-LLaMA-1.3B、LLaMA-2-7B和Mistral-7B。
- 训练数据:使用英文维基百科数据进行MNTP和无监督SimCSE步骤的训练。具体来说,使用Wikitext-103数据集进行MNTP步骤,使用Gao等人发布的维基百科句子子集进行无监督SimCSE步骤。
- 训练过程:
- MNTP训练:随机掩盖输入序列的一部分令牌,使用LoRA进行微调,掩码概率分别为20%(S-LLaMA-1.3B、LLaMA-2-7B和Meta-LLaMA-3-8B)和80%(Mistral-7B)。
- 无监督SimCSE训练:对同一输入序列应用两次模型,使用独立采样的dropout掩码,训练模型最大化两次表示之间的相似性。
监督训练流程:
监督训练是通过以下步骤完成的:
数据准备:
- 使用E5数据集的公共部分进行训练。E5数据集包含约150万个样本,涵盖多种NLP任务。
模型初始化:
- 使用LoRA进行微调,初始权重从SimCSE权重中继承。
- MNTP LoRA权重合并到基础模型中,可训练LoRA权重使用SimCSE权重初始化。
训练过程:
- 训练模型1000步,批量大小为512。
- 使用Adam优化器,学习率为2e-4,前300步采用线性学习率预热。
- 训练过程中使用bfloat16量化、Flash Attention 2和梯度检查点等技术优化GPU内存消耗。
评估:
- 在MTEB基准上进行评估,比较不同模型在公开数据集上的表现。
- 结果表明,LLM2Vec模型在仅使用公开数据训练的模型中达到了最新的最佳性能。
结果与分析
-
词级任务评估:在词级任务(如分块、命名实体识别和词性标注)上,LLM2Vec转换的模型显著优于仅编码器模型。例如,在分块任务中,S-LLaMA-1.3B模型的改进幅度为5%。
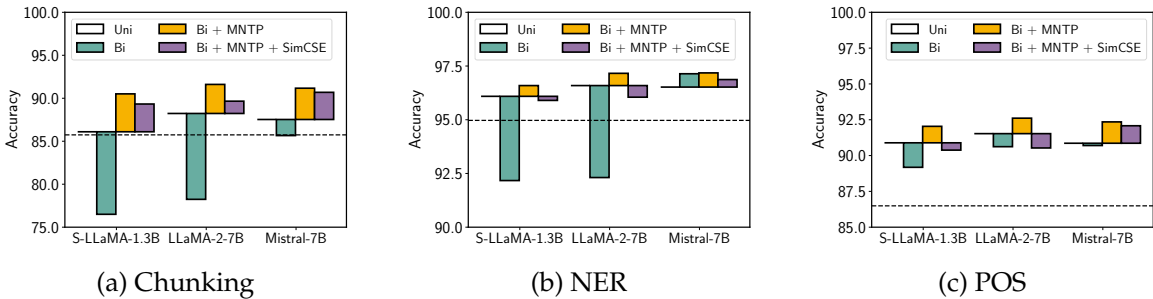
-
序列级任务评估:在Massive Text Embeddings Benchmark(MTEB)上,LLM2Vec转换的模型在无监督模型中达到了新的最佳性能,最佳模型的得分为56.8。结合监督对比学习后,Meta-LLaMA-3-8B模型在仅使用公开数据训练的模型中达到了最新的最佳性能。


3. 通过分析模型在不同层级的表示变化,发现Mistral-7B模型在无需任何训练的情况下就可以很好地处理双向注意力
优点与创新
- 提出了LLM2Vec方法:LLM2Vec提供了一种简单且无监督的方法,可以将任何解码器仅语言模型(Decoder-only LLM)转换为强大的文本编码器。
- 有效提升模型性能:通过在多个流行的解码器仅LLM上应用LLM2Vec,研究者在词级任务和序列级任务上均取得了显著的性能提升。
- 无需标签数据:LLM2Vec不需要任何标注数据,具有高度的数据和参数效率。
- 新的无监督状态:在MTEB基准测试中,LLM2Vec转换的模型在无监督模型中达到了新的最佳水平。
- 结合监督对比学习:当将LLM2Vec与监督对比学习结合时,研究者在仅使用公开可用数据进行训练的模型中达到了最新的最佳性能。
- 广泛的分析:提供了对LLM2Vec如何影响底层模型的深入分析,并揭示了Mistral-7B的一个有趣特性,即该模型可以在不进行任何微调的情况下处理双向注意力。
不足与反思
- 大尺寸解码器仅LLM的挑战:近年来,训练非常大的解码器仅LLM的趋势日益明显,这些模型的参数规模和输出嵌入维度都较大,导致训练和推理延迟增加,内存和计算需求更高。
- 预训练数据的污染:尽管研究中使用的是公开可用的数据集,但仍有可能存在来自LLaMA-2-7B和Mistral-7B模型预训练数据的污染风险。
- 扩展到其他语言:目前的研究仅使用了英语文本语料库和基准测试,未来工作需要将LLM2Vec方法扩展到其他语言。
相关文章:
【LLM论文日更】| LLM2Vec揭秘大型语言模型的文本嵌入潜能
论文:https://arxiv.org/pdf/2404.05961代码:https://github.com/McGill-NLP/llm2vec机构:McGill University, Mila ServiceNow Research ,Facebook CIFAR AI Chair领域:embedding model发表:COLM 2024 研…...

大模型微调有必要做吗?LoRa还是RAG?
我需要对大模型做微调吗? 想自定义大模型时,选择:微调还是RAG还是ICL? 需要对大模型做微调? 在人工智能的世界里,大型语言模型(LLM)已经成为了我们探索未知、解决问题的得力助手。…...

机器人外呼系统如何使用呢?
智能电话机器人作为人工智能进入电销行业的一个分类,目前已取得不错的成绩。智能电话机器人针对电销行业的痛点所作出了改善。 作为新兴的一种电销手段,很多企业对其充满好奇又望而却步。那么很多朋友都有想知道为什么现在很多人都用AI机器人拓客&#x…...

python-月份有几天
题目描述 小理现在有一份日历,但是这个日历很奇怪并不能告诉小理日期信息。小理现在有年和月,希望你能帮他计算出来这一年这个月有几天。 输入 输入共一行,两个整数,代表年和月,中间用空格隔开。 输出 一个整数&am…...

1017 Queueing at Bank
链接: 1017 Queueing at Bank - PAT (Advanced Level) Practice (pintia.cn) 题目大意: 有n个客户,k个窗口。已知每个客户的到达时间和需要的时长,如果有窗口就依次过去,如果没有窗口就在黄线外等候(黄线…...
DPDK 测试说明
文章目录 2.DPDK 测试说明2.1硬件pci加密设备绑定到igb_uio驱动IGB_UIO 主要负责什么内容 ? 2.2 test命令使用说明2.3 dpdk-test-crypto-perf命令使用说明2.4 使用testpmd测试网卡性能 2.DPDK 测试说明 2.1硬件pci加密设备绑定到igb_uio驱动 dpdk-stable/usertool…...

上传及接收pdf文件,使用pdfbox读取pdf文件内容
前端上传pdf文件 html <form class"layui-form"><div style"background-color: #ffffff" ><div style"padding: 30px"><div class"layui-form-item"><div class"layui-inline"><label c…...

第一个搭建SpringBoot项目(连接mysql)
首先新建项目找到Spring Initializr 我使用的URL是https://start.spring.io这里最低的JDK版本是17,而且当网速不好的时候可能会显示超时,这里可以选用阿里云的镜像https://start.aliyun.com可以更快一些但是里面还是有一些区别的 我们这里选择Java语言&a…...

docker部署rabbitMQ 单机版
获取rabbit镜像:我们选择带有“mangement”的版本(包含web管理页面); docker pull rabbitmq:management 创建并运行容器: docker run -d --name rabbitmq -p 5677:5672 -p 15677:15672 rabbitmq:management --name:…...

PDF 全文多语言 AI 摘要 API 数据接口
PDF 全文多语言 AI 摘要 API 数据接口 PDF / 文本摘要 AI 生成 PDF 文档摘要 AI 处理 / 智能摘要。 1. 产品功能 支持多语言摘要生成;支持 formdata 格式 PDF 文件流传参;快速处理大文件;基于 AI 模型,持续迭代优化;…...

《信息系统安全》课程实验指导
第1关:实验一:古典密码算法---代换技术 任务描述 本关任务:了解古典密码体制技术中的代换技术,并编程实现代换密码的加解密功能。 注意所有明文字符为26个小写字母,也就是说字母表为26个小写字母。 相关知识 为了完…...

Accelerated Soft Error Testing 介绍
加速软错误测试(Accelerated Soft Error Testing, ASET)是一种评估半导体器件或集成电路(ICs)在高辐射环境中发生软错误率(Soft Error Rate, SER)的方法。这种测试方法通过模拟或加速软错误的发生,以便在较短时间内评估器件的可靠性。软错误指的是那些不会对硬件本身造成…...

Redis缓存常用的读写策略
缓存常用的读写策略 缓存与DB的数据不一致问题,大多数都是指DB的数据已经修改,而缓存中的数据还是旧数据的情况。 旁路缓存模式 对于读操作:基本上所有模式都是先尝试从缓存中读,没有的话再去DB读取,然后写到缓存中…...
9月产品更新 | 超10项功能升级,快来看看你的需求上线了吗?
Smartbi用户可以在官网(PC端下载),更新后便可以使用相关功能,也可以在官网体验中心体验相关功能。 接下来,我们一起来看看都有哪些亮点功能更新吧。 ▎插件商城 Smartbi麦粉社区的应用市场新增了“插件”模块…...

ARP协议工作原理析解 (详细抓包分析过程)
目录 1. ARP 协议 2. 工作原理 3. ARP 协议报文格式 4. ARP 缓存的查看和修改 5. tcpdump 抓包分析 ARP 协议工作原理 5.1 搭建 2 台虚拟机 5.2 在主机 192.168.0.155 打开一个shell命令行开启抓包监听 5.3 在主机 192.168.0.155 打开另一个shell命令行 telnet 192.168.…...

axure动态面板
最近转管理岗了,作为项目负责人,需要常常与客户交流沟通,这时候画原型的能力就是不可或缺的本领之一了,关于axure可能很多it行业者都不是很陌生,简单的功能呢大家就自行去摸索,我们这次从动态面板开始讲起。…...
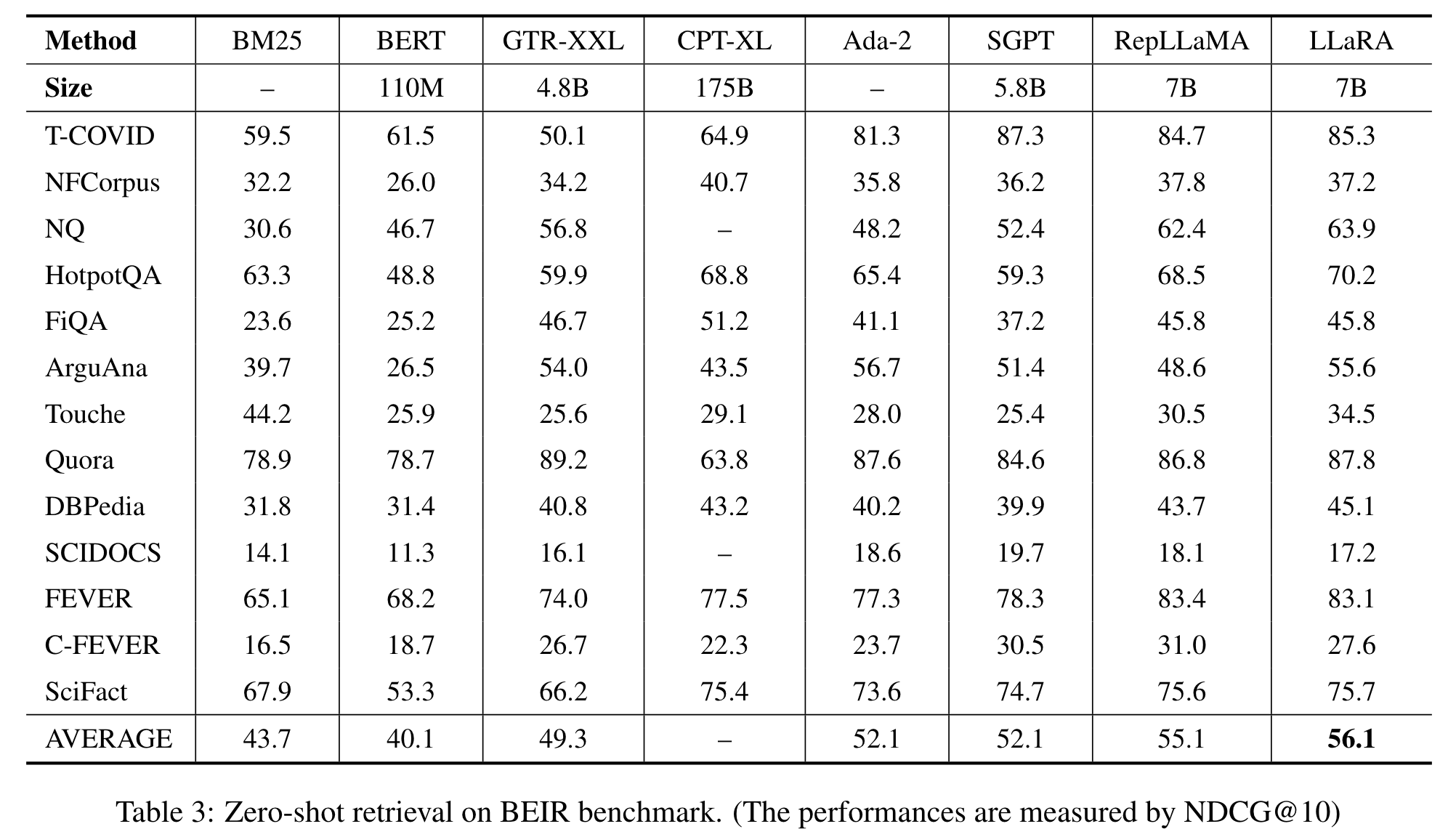
[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval
引言 今天带来北京智源研究院(BAAI)团队带来的一篇关于如何微调LLM变成密集检索器的论文笔记——Making Large Language Models A Better Foundation For Dense Retrieval。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们&quo…...

Linux平台屏幕|摄像头采集并实现RTMP推送两种技术方案探究
技术背景 随着国产化操作系统的推进,市场对国产化操作系统下的生态构建,需求越来越迫切,特别是音视频这块,今天我们讨论的是如何在linux平台实现屏幕|摄像头采集,并推送至RTMP服务。 我们知道,Linux平台&…...

梧桐数据库|中秋节活动·抽奖领取大闸蟹
有话说 众所周不知,我的工作就是做一个国产的数据库产品—中国移动梧桐数据库(简称WuTongDB)。 近期我们举办了一次小活动,来提升梧桐数据库的搜索量和知名度,欢迎大家来参加,免费抽奖领取大闸蟹哦~~~ 具…...

Python怎么发送邮件:基础步骤与详细教程?
Python怎么发送邮件带附件?怎么使用Python发送邮件? 无论是工作中的通知、报告,还是生活中的问候、邀请,电子邮件都扮演着不可或缺的角色。那么,Python怎么发送邮件呢?AokSend将详细介绍Python发送邮件的基…...

10M参数也能跑ARC与数独,Bengio团队押注「多轨迹推理」
10M 参数跑到数独 97%,GRAM 把递归推理改成多轨迹采样。 10M 参数,在大模型时代显得有些微不足道。 但 Yoshua Bengio 团队与 KAIST、Mila、NYU 研究人员提出的 GRAM,用这个量级的模型跑出了几组值得注意的结果。 在 Sudoku-Extreme 上准确率…...

3步彻底解决Windows更新后开始菜单重置难题:ExplorerPatcher深度解析与实战
3步彻底解决Windows更新后开始菜单重置难题:ExplorerPatcher深度解析与实战 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 每次Wi…...
:如何抢占方言AI语音红利窗口期?)
ElevenLabs江西话TTS上线倒计时(仅限首批200家本地企业内测):如何抢占方言AI语音红利窗口期?
更多请点击: https://codechina.net 第一章:ElevenLabs江西话语音技术正式发布与战略意义 ElevenLabs于2024年9月正式推出全球首个面向方言场景深度优化的语音合成模型——Jiangxi-Dialect TTS v1.0,首次实现对赣语昌靖片(以南昌…...

【Typescript】11-类抽象类与面向对象建模
类、抽象类与面向对象建模 TypeScript 不是一门纯粹的面向对象语言,但它对类系统的支持足够完整,足以覆盖很多工程场景。问题在于,很多人学到 class 之后,会误以为这就是组织 TypeScript 代码的默认方式。现实恰恰相反࿱…...

实力入选丨全知科技荣登嘶吼2026网络安全产业图谱
近日,嘶吼安全产业研究院正式发布《嘶吼2026网络安全产业图谱》。全知科技凭借在数据安全赛道的长期深耕积淀、持续技术创新能力与规模化行业落地实践,成功入选图谱数据安全核心板块,强势入围开发与应用安全、数据安全两大核心板块࿰…...

机器学习博士生存指南:问题定义、三维技术栈与认知带宽管理
1. 这不是“读博指南”,而是一份机器学习方向博士生的生存手记 我带过7届硕士、指导过4位博士,自己也从MIT CSAIL实验室的PhD candidate一路走到现在,在工业界和学术界都完整跑过ML方向的闭环——从ICML投稿被拒5次到最终以共同作者身份参与N…...

程序员想开 AI 会员:ChatGPT、Claude、Gemini 这些该怎么充值更省心?
最近很多程序员开 AI 会员,已经不是为了“尝鲜”了。更多时候是因为真的用得上:代码报错看半天,想让 AI 帮忙缩小排查范围。 接手老项目,想让 AI 先帮忙解释模块逻辑。 接口文档太长,想快速整理字段和调用方式。 READM…...

G-Helper终极指南:如何用免费开源工具彻底替代Armoury Crate
G-Helper终极指南:如何用免费开源工具彻底替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbo…...

15万个科技岗位消失的真相
周四早上7点43分,我的手机震动了一下,是一位同行的消息——另一位我认识了五年的数据团队负责人。他管理的团队规模是我的两倍,所在的公司你一定听说过。 消息只有四个字:“你的人安全吗?” 我立刻明白他的意思。Met…...

相控阵天线设计避坑指南:为什么低副瓣方案里,Chebyshev加权比单纯调相位更靠谱?
相控阵天线设计避坑指南:为什么低副瓣方案里,Chebyshev加权比单纯调相位更靠谱? 在相控阵天线设计中,低副瓣性能往往是工程师们追求的关键指标之一。副瓣过高不仅会浪费辐射能量,还可能造成信号干扰、目标识别困难等一…...