秃姐学AI系列之:实战Kaggle比赛:图像分类(CIFAR-10)
目录
准备工作
整理数据集
将验证集从原始的训练集中拆分出来
整理测试集
使用函数
图像增广
读取数据集
定义模型
定义训练函数
训练和验证数据集
对测试集进行分类并提交结果
准备工作
首先导入竞赛需要的包和模块
import collections
import math
import os
import shutil # python用来操作文件很方便的一个包
import pandas as pd
import torch
import torchvision
from torch import nn
from d2l import torch as d2l使用d2l里面的一个小规模样本来代替完整的 CIFAR-10 数据集,包含前1000个训练图像和5个随机测试图像的数据集的小规模样本
d2l.DATA_HUB['cifar10_tiny'] = (d2l.DATA_URL + 'kaggle_cifar10_tiny.zip','2068874e4b9a9f0fb07ebe0ad2b29754449ccacd')# 如果使用完整的Kaggle竞赛的数据集,设置demo为False
demo = Trueif demo:data_dir = d2l.download_extract('cifar10_tiny')
else:data_dir = '../data/cifar-10/'整理数据集
我们需要整理数据集来训练和测试模型。
首先,我们用以下函数读取CSV文件中的标签,它返回一个字典,该字典将文件名中不带扩展名的部分映射到其标签。
def read_csv_labels(fname):"""读取fname来给标签字典返回一个文件名"""with open(fname, 'r') as f:# 跳过文件头行(列名)lines = f.readlines()[1:]tokens = [l.rstrip().split(',') for l in lines]return dict(((name, label) for name, label in tokens))labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
print('# 训练样本 :', len(labels))
print('# 类别 :', len(set(labels.values())))# 训练样本 : 1000
# 类别 : 10将验证集从原始的训练集中拆分出来
我们定义 reorg_train_valid 函数来将验证集从原始的训练集中拆分出来。
此函数中的参数 valid_ratio 是验证集中的样本数与原始训练集中的样本数之比。 更具体地说,令 n 等于样本最少的类别中的图像数量,而 r 是比率。验证集将为每个类别拆分出 max(⌊nr⌋,1) 张图像。
让我们以valid_ratio=0.1为例,由于原始的训练集有50000张图像,因此 train_valid_test/train 路径中将有45000张图像用于训练,而剩下5000张图像将作为路径 train_valid_test/valid 中的验证集。组织数据集后,同类别的图像将被放置在同一文件夹下。
def copyfile(filename, target_dir):"""将文件复制到目标目录"""os.makedirs(target_dir, exist_ok=True)shutil.copy(filename, target_dir)def reorg_train_valid(data_dir, labels, valid_ratio):"""将验证集从原始的训练集中拆分出来"""# 训练数据集中样本最少的类别中的样本数n = collections.Counter(labels.values()).most_common()[-1][1]# 验证集中每个类别的样本数n_valid_per_label = max(1, math.floor(n * valid_ratio))label_count = {}for train_file in os.listdir(os.path.join(data_dir, 'train')):label = labels[train_file.split('.')[0]]fname = os.path.join(data_dir, 'train', train_file)copyfile(fname, os.path.join(data_dir, 'train_valid_test','train_valid', label))if label not in label_count or label_count[label] < n_valid_per_label:copyfile(fname, os.path.join(data_dir, 'train_valid_test','valid', label))label_count[label] = label_count.get(label, 0) + 1else:copyfile(fname, os.path.join(data_dir, 'train_valid_test','train', label))return n_valid_per_label整理测试集
下面的reorg_test函数用来在预测期间整理测试集,以方便读取。
def reorg_test(data_dir):"""在预测期间整理测试集,以方便读取"""for test_file in os.listdir(os.path.join(data_dir, 'test')):copyfile(os.path.join(data_dir, 'test', test_file),os.path.join(data_dir, 'train_valid_test', 'test','unknown'))使用函数
最后,我们使用一个函数来调用前面定义的函数read_csv_labels、reorg_train_valid和reorg_test。
在这里,我们只将样本数据集的批量大小设置为32。 在实际训练和测试中,应该使用Kaggle竞赛的完整数据集,并将 batch_size设置为更大的整数,例如128。 我们将10%的训练样本作为调整超参数的验证集。
def reorg_cifar10_data(data_dir, valid_ratio):labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))reorg_train_valid(data_dir, labels, valid_ratio)reorg_test(data_dir)batch_size = 32 if demo else 128
valid_ratio = 0.1
reorg_cifar10_data(data_dir, valid_ratio)图像增广
使用图像增广来解决过拟合的问题。
例如在训练中,可以随机水平翻转图像;还可以对彩色图像的三个RGB通道执行标准化。 下面,列出了其中一些可以调整的操作。
transform_train = torchvision.transforms.Compose([# 在高度和宽度上将图像放大到40像素的正方形torchvision.transforms.Resize(40),# 随机裁剪出一个高度和宽度均为40像素的正方形图像,# 生成一个面积为原始图像面积0.64~1倍的小正方形,# 然后将其缩放为高度和宽度均为32像素的正方形torchvision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0),ratio=(1.0, 1.0)),torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor(),# 标准化图像的每个通道torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])])在测试期间,我们只对图像执行标准化,以消除评估结果中的随机性。
transform_test = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])])读取数据集
每个样本都包括一张图片和一个标签。
在训练期间,我们需要指定上面定义的所有图像增广操作。当验证集在超参数调整过程中用于模型评估时,不应引入图像增广的随机性。在最终预测之前,我们根据训练集和验证集组合而成的训练模型进行训练,以充分利用所有标记的数据。
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train_valid_test', folder),transform=transform_train) for folder in ['train', 'train_valid']]valid_ds, test_ds = [torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train_valid_test', folder),transform=transform_test) for folder in ['valid', 'test']]指定上面定义的所有图像增广操作
train_iter, train_valid_iter = [torch.utils.data.DataLoader(# shuffle要开随机梯度下降,drop_last:如果最后一组不满batch_size,true会丢掉最后一节dataset, batch_size, shuffle=True, drop_last=True)for dataset in (train_ds, train_valid_ds)]valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False,drop_last=True)test_iter = torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False,drop_last=False) # 但是test的不能丢定义模型
模型直接用了一个ResNet-18
def get_net():num_classes = 10net = d2l.resnet18(num_classes, 3)return netloss = nn.CrossEntropyLoss(reduction="none")定义训练函数
# lr_period,lr_decay:学习率下降的一种方法
# lr_period:每隔多少了epoch
# lr_decay:下降多少(0.5:减半)
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,lr_decay):trainer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9,weight_decay=wd)# 调整lr 把decay值*lrscheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)num_batches, timer = len(train_iter), d2l.Timer()legend = ['train loss', 'train acc']if valid_iter is not None:legend.append('valid acc')animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=legend)# 多GPU训练net = nn.DataParallel(net, device_ids=devices).to(devices[0])for epoch in range(num_epochs):net.train()metric = d2l.Accumulator(3)# 为了展示 画图用的 正常训练不需要for i, (features, labels) in enumerate(train_iter):timer.start()l, acc = d2l.train_batch_ch13(net, features, labels,loss, trainer, devices)metric.add(l, acc, labels.shape[0])timer.stop()if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[2], metric[1] / metric[2],None))if valid_iter is not None:valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter)animator.add(epoch + 1, (None, None, valid_acc))# 每个epoch之后更新一下lrscheduler.step()measures = (f'train loss {metric[0] / metric[2]:.3f}, 'f'train acc {metric[1] / metric[2]:.3f}')if valid_iter is not None:measures += f', valid acc {valid_acc:.3f}'print(measures + f'\n{metric[2] * num_epochs / timer.sum():.1f}'f' examples/sec on {str(devices)}')训练和验证数据集
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 2e-4, 5e-4
lr_period, lr_decay, net = 4, 0.9, get_net()
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,lr_decay)
对测试集进行分类并提交结果
在获得具有超参数的满意的模型后,我们使用所有标记的数据(包括验证集)来重新训练模型并对测试集进行分类。
net, preds = get_net(), []
# 使用完整的数据集训练模型
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period,lr_decay)for X, _ in test_iter:y_hat = net(X.to(devices[0]))# 占比最大的值取出来preds.extend(y_hat.argmax(dim=1).type(torch.int32).cpu().numpy())
sorted_ids = list(range(1, len(test_ds) + 1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id': sorted_ids, 'label': preds})
df['label'] = df['label'].apply(lambda x: train_valid_ds.classes[x])
# 存成一个csv
df.to_csv('submission.csv', index=False)相关文章:
秃姐学AI系列之:实战Kaggle比赛:图像分类(CIFAR-10)
目录 准备工作 整理数据集 将验证集从原始的训练集中拆分出来 整理测试集 使用函数 图像增广 读取数据集 定义模型 定义训练函数 训练和验证数据集 对测试集进行分类并提交结果 准备工作 首先导入竞赛需要的包和模块 import collections import math import os i…...

nginx: [error] invalid PID number ““ in “/run/nginx.pid“
出现这个报错的原因 : 空值:“/run/nginx.pid” 文件为空或者内容不是有效的PID数字 文件损坏:如果PID文件被意外修改,例如被其他程序覆盖了内容,可能会显示为无效。 路径错误:Nginx无法找到指定的PID文件…...

Java使用Apache POI向Word文档中填充数据
Java使用Apache POI向Word文档中填充数据 向一个包含占位符的Word文档中填充数据,并保存为新的文档。 准备工作 环境搭建 在项目中添加Apache POI依赖。在pom.xml中添加如下依赖: <dependencies><dependency><groupId>org.apache.po…...

Gitflow基础知识
0.理想状态 现状 听完后的理想状态 没使用过 git 知道 git 是什么,会用 git 基础流程命令 用过 git,但只通过图形化界面操作 脱离图形化界面操作,通过 git 命令操作 会 git 命令 掌握 gitflow 规范,合理使用 rebase 和解决…...

NLP基础及其代码-tokenizer
基础知识 NLP-分词器:SentencePiece【参考Chinese-LLaMA-Alpaca在通用中文语料上训练的20K中文词表并与原版LLaMA模型的32K词表进行合并的代码】_sentencepiece 中文训练-CSDN博客 【OpenLLM 008】大模型基础组件之分词器-万字长文全面解读LLM中的分词算法与分词器…...

OpenCV结构分析与形状描述符(8)点集凸包计算函数convexHull()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 查找一个点集的凸包。 函数 cv::convexHull 使用斯克拉斯基算法(Sklansky’s algorithm)来查找一个二维点集的凸包&#…...

灰光模块,彩光模块-介绍
1. 引用 知识分享系列一:5G基础知识-CSDN博客 5G前传的最新进展-CSDN博客 灰光和彩光_通信行业5G招标系列点评之二:一文读懂5G前传-光纤、灰光、彩光、CWDM、LWDM、MWDM...-CSDN博客 ADOP带你了解:CWDM、DWDM、MWDM、LWDM:快速…...

python-新冠病毒
题目描述 假设我们掌握了特定时间段内特定城市的新冠病毒感染病例的信息。在排名 i 的当天有 i 个案例,即: 第一天有一例感染第二天有两例感染第三天有三例感染以此类推...... 请计算 n 天内的感染总数和每天平均感染数。 输入 整数 n 表示天数&…...

2023年408真题计算机网络篇
https://zhuanlan.zhihu.com/p/6954228062023年网络规划设计师上午真题解析TCP流量计算_哔哩哔哩_bilibili 1 1在下图所示的分组交换网络中,主机H1和H2通过路由器互联,2段链路的数据传输速率为100 Mb/s、时延带宽积 (即单向传播时延带宽&am…...

分类学习器(Classification Learner App)MATLAB
在MATLAB中,分类学习器用于构建和评估分类模型。MATLAB提供了一些工具和功能,帮助你进行分类任务,例如分类学习器应用程序、统计和机器学习工具箱中的函数等。 数据集介绍 不同的人被要求在平板电脑上写字母"J"、“V"和&quo…...

DolphinDB 基准性能测试工具:金融模拟数据生成模块合集
测试 DolphinDB 数据库性能时,往往需要快速写入一些测试数据。为方便用户快速完成简单的基准性能测试,金融 Mock 数据生成模块覆盖了常用的金融数据集,满足用户生成模拟数据的需求。基于本模块生成的模拟数据不具有实际意义,建议仅…...

BUUCTF—[BJDCTF2020]The mystery of ip
题解 打开环境点击上面的flag可以看到这个IP页面。 抓个包看看有啥东西无,可以看到在返回包有IP。 看到IP就想到X-Forwarded-For这个玩意,我们用X-Forwarded-For随便添加个IP看看。可以看到返回的IP内容变成了123。 X-Forwarded-For:123 推测它会输出我…...

leecode100题-双指针-三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 答案中不可以包含重复的三元组。 示例 1: 输入…...

计算机毕业设计PySpark+Django考研分数线预测 考研院校推荐系统 考研推荐系统 考研爬虫 考研大数据 Hadoop 大数据毕设 机器学习 深度学习
《PySparkDjango考研分数线预测与推荐系统》开题报告 一、研究背景与意义 随着教育水平的提高和就业竞争的加剧,越来越多的学生选择继续深造,参加研究生入学考试(考研)。然而,考研信息繁杂,选择专业和院校…...

Go语言多态实践以及gin框架c.BindJSON序列化遇到的坑
遇到的问题 如果定义的接收结构体字段是interface{},在调用gin的 c.BindJSON 方法后会直接转为map, 导致无法断言为其他类型 场景 在创建工程请求中,根据工程类别的不同会有多种创建参数,比如 // A 类型需要编译 所以有这些字…...
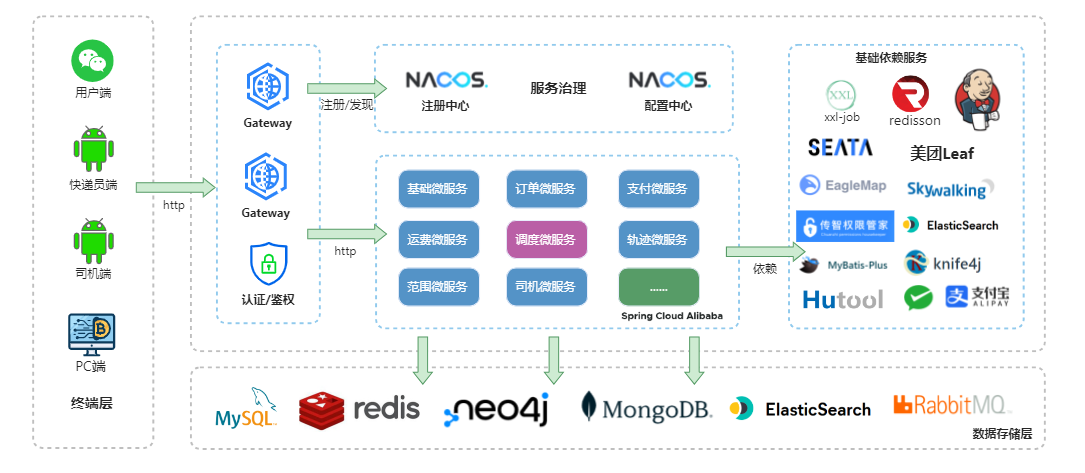
SpringCloud神领物流学习笔记:项目概述(一)
SpringCloud神领物流学习笔记:项目概述(一) 文章目录 SpringCloud神领物流学习笔记:项目概述(一)1、项目介绍2、基本业务流程3、系统架构4、技术架构 1、项目介绍 神领物流是一个基于微服务架构体系的【…...

RocketMQ异步报错:No route info of this topic
在SpringBoot中发送RocketMQ异步消息的时候报错了,提示org.apache.rocketmq.client.exception.MQClientException: No route info of this topic, testTopic1 这里给出具体的解决方案 一、Broker模块不支持自动创建topic,并且topic没有被手动创建过 R…...

Node.js学习记录(一)
目录 一、文件读取 readFile 二、写入文件 writeFile 三、动态路径 __dirname:表示当前文件所处的目录、path.join 四、获取路径文件名 path.basename 五、提取某文件中的css、JS、html 六、http 七、启动创建web服务器 服务器响应 八、将资源请求的 url 地…...

【AI】Pytorch_模型构建
建议点赞收藏关注!持续更新至pytorch大部分内容更完。 本文已达到10w字,故按模块拆开,详见目录导航。 整体框架如下 数据及预处理 模型及其构建 损失函数及优化器 本节目录 模型线性回归逻辑回归LeNetAlexNet 构建模块组织复杂网络初始化网络…...

FFmpeg源码:avcodec_descriptor_get函数分析
一、avcodec_descriptor_get函数的声明 avcodec_descriptor_get函数声明在FFmpeg源码(本文演示用的FFmpeg源码版本为7.0.1)的头文件libavcodec/codec_desc.h中: /*** return descriptor for given codec ID or NULL if no descriptor exist…...

用o1-preview构建端到端水质分类系统
1. 项目概述:用 o1-preview 构建端到端水质分类系统的真实复现手记 我做机器学习项目快十年了,从最早手动调参、写 Makefile 编译模型,到后来用 MLflow 跟踪实验、用 Flask 封装 API,再到如今用 Docker 打包上云——整个流程早已刻…...

扩散模型如何重塑建筑设计流程:从概念生成到性能优化的AI协作
1. 项目概述:当AI成为建筑师的“副驾驶”几年前,当我在设计院通宵达旦地对着屏幕调整一个曲面屋顶的参数时,我就在想,有没有一种工具,能让我把脑子里那个模糊的意象,瞬间变成可供推敲的视觉草稿?…...

从DEM到glTF:打造跨平台三维地形模型的完整工作流
1. 为什么需要从DEM到glTF的三维地形工作流 三维地形模型在游戏开发、虚拟现实、城市规划等领域有着广泛应用。传统的工作流程往往存在平台兼容性差、数据转换复杂等问题。glTF作为"3D界的JPEG",已经成为跨平台三维模型交换的事实标准。将数字高程模型&am…...

利用taotoken模型广场为ai应用快速进行模型选型与测试
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为AI应用快速进行模型选型与测试 在构建一个需要集成多种AI能力的应用时,开发者面临的首要挑战往…...

2026 AI大模型API加速网站推荐
在AI开发领域,一个现实问题始终困扰着开发者:如何接入模型厂商的官方API?在海外,注册、绑卡、调用这三个步骤就能轻松解决。然而,国内开发者面临着跨境网络波动、外币支付门槛、发票合规需求以及多厂商Key碎片化管理等…...

AI推广的核心原理是什么?
理解AI推广的原理,你才能知道该做什么、不该做什么,而不是盲目操作。一句话概括AI推广的核心原理:让AI在回答用户问题时,选择引用你的内容。就这么简单。但要做到这件事,你需要理解AI是怎么"选择"的。AI回答…...

对比直接使用厂商API,Taotoken在路由容灾上的体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API,Taotoken在路由容灾上的体验差异 1. 引言:服务稳定性的现实挑战 在将大模型能力集成…...

技术团队的“1对1沟通”:别等员工提离职了才聊真心话
在软件测试领域,我们习惯于用脚本验证系统的稳定性,用压测工具探测性能的边界,却常常忽略了对团队中最重要的“系统”——人——进行定期的健康检查。许多技术管理者,尤其是从资深测试工程师晋升上来的团队负责人,往往…...
)
专利技术复杂性地级市面板(2001-2025)
核心速览数据编号:2323时间跨度:2001–2025空间尺度:中国全部地级市数据格式:Excel 年度面板测算依据:Research Policy 2026 顶刊范式(Frigon)测算方法(可直接写论文)以I…...

Go语言AI Agent框架goclaw:模块化架构与技能系统实战
1. 项目概述:一个用Go语言构建的现代化AI Agent框架如果你正在寻找一个功能全面、架构清晰,并且能让你快速上手构建智能助理的Go语言框架,那么goclaw(狗爪)绝对值得你花时间研究。我最近在评估几个开源的AI Agent框架&…...