NLP基础及其代码-tokenizer
基础知识
NLP-分词器:SentencePiece【参考Chinese-LLaMA-Alpaca在通用中文语料上训练的20K中文词表并与原版LLaMA模型的32K词表进行合并的代码】_sentencepiece 中文训练-CSDN博客
【OpenLLM 008】大模型基础组件之分词器-万字长文全面解读LLM中的分词算法与分词器(tokenization & tokenizers):BPE/WordPiece/ULM & beyond - 知乎 (zhihu.com)

BPE
Byte Pair Encoding
步骤:
1.语料库
2.确定词表大小
3.为每个单词添加分割符
4.从字母开始迭代合并出现频率高的字符串
"""
2024/9/9
bpe.py
wang_yi
"""
import re, collectionsdef get_vocab(filename):vocab = collections.defaultdict(int) # 对于 defaultdict(int) 创建的字典来说,任何不存在的键在访问时都会自动被赋值为 0with open(filename, 'r', encoding='utf-8') as fhand:for line in fhand:words = line.strip().split()for word in words:vocab[' '.join(list(word)) + ' </w>'] += 1return vocabdef get_stats(vocab):pairs = collections.defaultdict(int)for word, freq in vocab.items():symbols = word.split()for i in range(len(symbols)-1):pairs[symbols[i],symbols[i+1]] += freqreturn pairsdef merge_vocab(pair, v_in):v_out = {}bigram = re.escape(' '.join(pair)) # re.escape确保特殊字符被转义,以便在正则表达式中按照字面意义进行匹配p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)') # ?!负向前瞻断言,表示匹配位置前(<)或后面不是某种模式。\S: 表示任何非空白字符for word in v_in:w_out = p.sub(''.join(pair), word) # 替换结合字符对,保留原来字符串中的其他部分v_out[w_out] = v_in[word] # 将处理后的字符串 w_out 作为 v_out 字典的键,并将 v_in 字典中对应 word 的值赋给 v_out 字典中这个键return v_outdef get_tokens(vocab):tokens = collections.defaultdict(int)for word, freq in vocab.items():word_tokens = word.split()for token in word_tokens:tokens[token] += freqreturn tokens# vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}# Get free book from Gutenberg
# wget http://www.gutenberg.org/cache/epub/16457/pg16457.txt
vocab = get_vocab('pg16457.txt')print('==========')
print('Tokens Before BPE')
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')num_merges = 1000
for i in range(num_merges):pairs = get_stats(vocab)if not pairs:breakbest = max(pairs, key=pairs.get)vocab = merge_vocab(best, vocab)print('Iter: {}'.format(i))print('Best pair: {}'.format(best))tokens = get_tokens(vocab)print('Tokens: {}'.format(tokens))print('Number of tokens: {}'.format(len(tokens)))print('==========')
单词以</w>结尾



新分词
打印结果
Tokens Before BPE
Tokens: defaultdict(<class 'int'>, {'T': 1607, 'h': 26103, 'e': 59190, '</w>': 101849, 'P': 780, 'r': 29562, 'o': 35007, 'j': 858, 'c': 13900, 't': 44238, 'G': 300, 'u': 13723, 'n': 32498, 'b': 7426, 'g': 8752, 'B': 1162, 'k': 2732, 'f': 10463, 'A': 1379, 'l': 20619, 'd': 17581, 'M': 1204, 'i': 31414, 's': 28311, 'a': 36695, 'y': 8828, 'w': 8155, 'U': 178, 'S': 865, 'm': 9751, 'p': 8030, 'v': 4878, '.': 4061, 'Y': 250, ',': 8065, '-': 1063, 'L': 426, 'I': 1428, ':': 201, 'J': 78, 'V': 102, 'E': 895, 'R': 369, '6': 73, '2': 160, '0': 402, '5': 124, '[': 32, '#': 1, '1': 291, '4': 99, '7': 60, ']': 32, 'D': 322, 'C': 862, 'K': 41, 'O': 510, '/': 31, '*': 22, 'F': 419, 'H': 688, 'N': 793, '"': 4064, '!': 1214, 'W': 576, '3': 104, "'": 1236, 'Q': 33, 'X': 49, 'Z': 10, '?': 651, '8': 73, '9': 36, '_': 1426, 'à': 3, 'x': 937, 'z': 364, '°': 41, 'q': 575, ';': 561, '(': 53, ')': 53, '{': 23, '}': 16, 'è': 2, 'é': 14, '+': 2, '=': 3, 'ö': 2, 'ê': 5, 'â': 1, 'ô': 1, 'Æ': 3, 'æ': 2, '—': 2, '™': 57, '“': 11, '”': 11, '•': 4, '%': 1, '‘': 1, '’': 6, '$': 2})
Number of tokens: 103
==========
Iter: 0
Best pair: ('e', '</w>')
Tokens: defaultdict(<class 'int'>, {'T': 1607, 'h': 26103, 'e</w>': 17758, 'P': 780, 'r': 29562, 'o': 35007, 'j': 858, 'e': 41432, 'c': 13900, 't': 44238, '</w>': 84091, 'G': 300, 'u': 13723, 'n': 32498, 'b': 7426, 'g': 8752, 'B': 1162, 'k': 2732, 'f': 10463, 'A': 1379, 'l': 20619, 'd': 17581, 'M': 1204, 'i': 31414, 's': 28311, 'a': 36695, 'y': 8828, 'w': 8155, 'U': 178, 'S': 865, 'm': 9751, 'p': 8030, 'v': 4878, '.': 4061, 'Y': 250, ',': 8065, '-': 1063, 'L': 426, 'I': 1428, ':': 201, 'J': 78, 'V': 102, 'E': 895, 'R': 369, '6': 73, '2': 160, '0': 402, '5': 124, '[': 32, '#': 1, '1': 291, '4': 99, '7': 60, ']': 32, 'D': 322, 'C': 862, 'K': 41, 'O': 510, '/': 31, '*': 22, 'F': 419, 'H': 688, 'N': 793, '"': 4064, '!': 1214, 'W': 576, '3': 104, "'": 1236, 'Q': 33, 'X': 49, 'Z': 10, '?': 651, '8': 73, '9': 36, '_': 1426, 'à': 3, 'x': 937, 'z': 364, '°': 41, 'q': 575, ';': 561, '(': 53, ')': 53, '{': 23, '}': 16, 'è': 2, 'é': 14, '+': 2, '=': 3, 'ö': 2, 'ê': 5, 'â': 1, 'ô': 1, 'Æ': 3, 'æ': 2, '—': 2, '™': 57, '“': 11, '”': 11, '•': 4, '%': 1, '‘': 1, '’': 6, '$': 2})
Number of tokens: 104
==========
Iter: 1
Best pair: ('t', 'h')
Tokens: defaultdict(<class 'int'>, {'T': 1607, 'h': 12062, 'e</w>': 17758, 'P': 780, 'r': 29562, 'o': 35007, 'j': 858, 'e': 41432, 'c': 13900, 't': 30197, '</w>': 84091, 'G': 300, 'u': 13723, 'n': 32498, 'b': 7426, 'g': 8752, 'B': 1162, 'k': 2732, 'f': 10463, 'A': 1379, 'l': 20619, 'd': 17581, 'th': 14041, 'M': 1204, 'i': 31414, 's': 28311, 'a': 36695, 'y': 8828, 'w': 8155, 'U': 178, 'S': 865, 'm': 9751, 'p': 8030, 'v': 4878, '.': 4061, 'Y': 250, ',': 8065, '-': 1063, 'L': 426, 'I': 1428, ':': 201, 'J': 78, 'V': 102, 'E': 895, 'R': 369, '6': 73, '2': 160, '0': 402, '5': 124, '[': 32, '#': 1, '1': 291, '4': 99, '7': 60, ']': 32, 'D': 322, 'C': 862, 'K': 41, 'O': 510, '/': 31, '*': 22, 'F': 419, 'H': 688, 'N': 793, '"': 4064, '!': 1214, 'W': 576, '3': 104, "'": 1236, 'Q': 33, 'X': 49, 'Z': 10, '?': 651, '8': 73, '9': 36, '_': 1426, 'à': 3, 'x': 937, 'z': 364, '°': 41, 'q': 575, ';': 561, '(': 53, ')': 53, '{': 23, '}': 16, 'è': 2, 'é': 14, '+': 2, '=': 3, 'ö': 2, 'ê': 5, 'â': 1, 'ô': 1, 'Æ': 3, 'æ': 2, '—': 2, '™': 57, '“': 11, '”': 11, '•': 4, '%': 1, '‘': 1, '’': 6, '$': 2})
Number of tokens: 105
==========
Iter: 2
Best pair: ('t', '</w>')
Tokens: defaultdict(<class 'int'>, {'T': 1607, 'h': 12062, 'e</w>': 17758, 'P': 780, 'r': 29562, 'o': 35007, 'j': 858, 'e': 41432, 'c': 13900, 't</w>': 9280, 'G': 300, 'u': 13723, 't': 20917, 'n': 32498, 'b': 7426, 'g': 8752, '</w>': 74811, 'B': 1162, 'k': 2732, 'f': 10463, 'A': 1379, 'l': 20619, 'd': 17581, 'th': 14041, 'M': 1204, 'i': 31414, 's': 28311, 'a': 36695, 'y': 8828, 'w': 8155, 'U': 178, 'S': 865, 'm': 9751, 'p': 8030, 'v': 4878, '.': 4061, 'Y': 250, ',': 8065, '-': 1063, 'L': 426, 'I': 1428, ':': 201, 'J': 78, 'V': 102, 'E': 895, 'R': 369, '6': 73, '2': 160, '0': 402, '5': 124, '[': 32, '#': 1, '1': 291, '4': 99, '7': 60, ']': 32, 'D': 322, 'C': 862, 'K': 41, 'O': 510, '/': 31, '*': 22, 'F': 419, 'H': 688, 'N': 793, '"': 4064, '!': 1214, 'W': 576, '3': 104, "'": 1236, 'Q': 33, 'X': 49, 'Z': 10, '?': 651, '8': 73, '9': 36, '_': 1426, 'à': 3, 'x': 937, 'z': 364, '°': 41, 'q': 575, ';': 561, '(': 53, ')': 53, '{': 23, '}': 16, 'è': 2, 'é': 14, '+': 2, '=': 3, 'ö': 2, 'ê': 5, 'â': 1, 'ô': 1, 'Æ': 3, 'æ': 2, '—': 2, '™': 57, '“': 11, '”': 11, '•': 4, '%': 1, '‘': 1, '’': 6, '$': 2})
Number of tokens: 106
==========可以保存生成的分词,根据分词列表对输入的文本进行分词
"""
2024/9/9
bpe_code.py
wang_yi
"""
import re, collectionsdef get_vocab(filename):vocab = collections.defaultdict(int)with open(filename, 'r', encoding='utf-8') as fhand:for line in fhand:words = line.strip().split()for word in words:vocab[' '.join(list(word)) + ' </w>'] += 1return vocabdef get_stats(vocab):pairs = collections.defaultdict(int)for word, freq in vocab.items():symbols = word.split()for i in range(len(symbols) - 1):pairs[symbols[i], symbols[i + 1]] += freqreturn pairsdef merge_vocab(pair, v_in):v_out = {}bigram = re.escape(' '.join(pair))p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')for word in v_in:w_out = p.sub(''.join(pair), word)v_out[w_out] = v_in[word]return v_outdef get_tokens_from_vocab(vocab):tokens_frequencies = collections.defaultdict(int)vocab_tokenization = {}for word, freq in vocab.items():word_tokens = word.split()for token in word_tokens:tokens_frequencies[token] += freqvocab_tokenization[''.join(word_tokens)] = word_tokensreturn tokens_frequencies, vocab_tokenizationdef measure_token_length(token):if token[-4:] == '</w>':return len(token[:-4]) + 1else:return len(token)def tokenize_word(string, sorted_tokens, unknown_token='</u>'):if string == '':return []if sorted_tokens == []:return [unknown_token]string_tokens = []for i in range(len(sorted_tokens)):token = sorted_tokens[i]token_reg = re.escape(token.replace('.', '[.]'))matched_positions = [(m.start(0), m.end(0)) for m in re.finditer(token_reg, string)]if len(matched_positions) == 0:continuesubstring_end_positions = [matched_position[0] for matched_position in matched_positions]substring_start_position = 0for substring_end_position in substring_end_positions:substring = string[substring_start_position:substring_end_position]string_tokens += tokenize_word(string=substring, sorted_tokens=sorted_tokens[i + 1:],unknown_token=unknown_token)string_tokens += [token]substring_start_position = substring_end_position + len(token)remaining_substring = string[substring_start_position:]string_tokens += tokenize_word(string=remaining_substring, sorted_tokens=sorted_tokens[i + 1:],unknown_token=unknown_token)breakreturn string_tokens# vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}vocab = get_vocab('pg16457.txt')print('==========')
print('Tokens Before BPE')
tokens_frequencies, vocab_tokenization = get_tokens_from_vocab(vocab)
print('All tokens: {}'.format(tokens_frequencies.keys()))
print('Number of tokens: {}'.format(len(tokens_frequencies.keys())))
print('==========')num_merges = 100
for i in range(num_merges):pairs = get_stats(vocab)if not pairs:breakbest = max(pairs, key=pairs.get)vocab = merge_vocab(best, vocab)print('Iter: {}'.format(i))print('Best pair: {}'.format(best))tokens_frequencies, vocab_tokenization = get_tokens_from_vocab(vocab)print('All tokens: {}'.format(tokens_frequencies.keys()))print('Number of tokens: {}'.format(len(tokens_frequencies.keys())))print('==========')# Let's check how tokenization will be for a known word
word_given_known = 'mountains</w>'
word_given_unknown = 'Ilikeeatingapples!</w>'sorted_tokens_tuple = sorted(tokens_frequencies.items(), key=lambda item: (measure_token_length(item[0]), item[1]),reverse=True) # 根据 measure_token_length(item[0]) 排序,如果长度相同,则按 item[1](值)排序。reverse=True 降序排序
sorted_tokens = [token for (token, freq) in sorted_tokens_tuple]print(sorted_tokens)word_given = word_given_knownprint('Tokenizing word: {}...'.format(word_given))
if word_given in vocab_tokenization:print('Tokenization of the known word:')print(vocab_tokenization[word_given])print('Tokenization treating the known word as unknown:')print(tokenize_word(string=word_given, sorted_tokens=sorted_tokens, unknown_token='</u>'))
else:print('Tokenizating of the unknown word:')print(tokenize_word(string=word_given, sorted_tokens=sorted_tokens, unknown_token='</u>'))word_given = word_given_unknownprint('Tokenizing word: {}...'.format(word_given))
if word_given in vocab_tokenization:print('Tokenization of the known word:')print(vocab_tokenization[word_given])print('Tokenization treating the known word as unknown:')print(tokenize_word(string=word_given, sorted_tokens=sorted_tokens, unknown_token='</u>'))
else:print('Tokenizating of the unknown word:')print(tokenize_word(string=word_given, sorted_tokens=sorted_tokens, unknown_token='</u>'))字节对编码 - 毛雷日志 (leimao.github.io)
彻底搞懂BPE(Byte Pair Encode)原理(附代码实现)_bpe实现-CSDN博客
问题:
一个词可能存在多种拆分方式,对于算法来说,难以评估使用那个拆分方式比较合理,可以组合的列表中的优先级无法确定,通常会直接取第一个。如:
encode一个句子"linear algebra", 那么存在的划分方法有以下几种:
linear = li + near 或者 li + n + ea + r
algebra = al + ge + bra 或者 al + g + e + bra
在这个具体的case中,每个单词都有两种拆分方法, 那么整个句子就有4中拆分方法。
解决方式——>在merge的时候考虑merge前后的影响到底有多大
wordpiece
WordPiece基于概率生成新的subword而不是最高频字节对。
WordPiece和BPE的区别就在每次merge的过程中, BPE是通过合并最高频次的字节对,WordPiece选择能够提升语言模型概率最大的相邻子词加入词表
假设句子S=(t1,t2,...,tn),是由n个子词组成,ti表示子词,且假设各个子词之间是独立存在的,则句子S的语言模型似然值等价与所有子词概率的乘积:
把相邻位置的x和y两个子词进行合并,合并后产生的子词为z,此时句子S似然值的变化可表示为
![]()
选择让似然概率最大的值,具体的计算使用合并后的概率值,除以合并前的概率值,举个例子, 在考虑将"e"和"s"合并的时候除了会考虑"es"的概率值,还会考虑"e"和"s"的概率值。或者说,"es"的合并是通过考虑合并带来的价值。
步骤:
1.语料库
2.确定词表大小
3.为每个单词添加分割符
4.从字母开始迭代合并前后概率变化最大的字符串
在编码时从头开始查找最长的子词
"""
2024/9/10
wordpiece.py
wang_yi
"""
corpus = ["This is the Hugging Face course.","This chapter is about tokenization.","This section shows several tokenizer algorithms.","Hopefully, you will be able to understand how they are trained and generate tokens.",
]
from transformers import AutoTokenizer
from collections import defaultdict
# 在進行預標記化時計算語料庫中每個單詞的頻率:
tokenizer = AutoTokenizer.from_pretrained(r"G:\llm_model\bert-base-chinese")word_freqs = defaultdict(int)
for text in corpus:words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)new_words = [word for word, offset in words_with_offsets]for word in new_words:word_freqs[word] += 1print(word_freqs)
# 字母表是由單詞的所有第一個字母組成的唯一集合,以及出現在前綴為 ## 的其他字母:
alphabet = []
for word in word_freqs.keys():if word[0] not in alphabet:alphabet.append(word[0])for letter in word[1:]:if f"##{letter}" not in alphabet:alphabet.append(f"##{letter}")alphabet.sort()
# alphabet
print(alphabet)
# 在該詞彙表的開頭添加了模型使用的特殊標記。在使用 BERT 的情況下,它是列表 ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]:
vocab = ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"] + alphabet.copy()
# 需要拆分每個單詞, 所有不是第一個字母的字母都以 ## 為前綴:
splits = {word: [c if i == 0 else f"##{c}" for i, c in enumerate(word)]for word in word_freqs.keys()
}# 計算每對的分數
def compute_pair_scores(splits):letter_freqs = defaultdict(int)pair_freqs = defaultdict(int)for word, freq in word_freqs.items():split = splits[word]if len(split) == 1:letter_freqs[split[0]] += freqcontinuefor i in range(len(split) - 1):pair = (split[i], split[i + 1])letter_freqs[split[i]] += freqpair_freqs[pair] += freqletter_freqs[split[-1]] += freqscores = {pair: freq / (letter_freqs[pair[0]] * letter_freqs[pair[1]])for pair, freq in pair_freqs.items()}return scorespair_scores = compute_pair_scores(splits)
for i, key in enumerate(pair_scores.keys()):print(f"{key}: {pair_scores[key]}")if i >= 5:breakbest_pair = ""
max_score = None
for pair, score in pair_scores.items():if max_score is None or max_score < score:best_pair = pairmax_score = scoreprint(best_pair, max_score)
# 第一個要學習的合併是 ('a', '##b') -> 'ab', 並且我們添加 'ab' 到詞彙表中:
vocab.append("ab")def merge_pair(a, b, splits):for word in word_freqs:split = splits[word]if len(split) == 1:continuei = 0while i < len(split) - 1:if split[i] == a and split[i + 1] == b:merge = a + b[2:] if b.startswith("##") else a + bsplit = split[:i] + [merge] + split[i + 2:]else:i += 1splits[word] = splitreturn splitssplits = merge_pair("a", "##b", splits)
print(splits["about"])vocab_size = 70
while len(vocab) < vocab_size:scores = compute_pair_scores(splits)best_pair, max_score = "", Nonefor pair, score in scores.items():if max_score is None or max_score < score:best_pair = pairmax_score = scoresplits = merge_pair(*best_pair, splits)new_token = (best_pair[0] + best_pair[1][2:]if best_pair[1].startswith("##")else best_pair[0] + best_pair[1])vocab.append(new_token)
print(vocab)def encode_word(word):tokens = []while len(word) > 0:i = len(word)while i > 0 and word[:i] not in vocab:i -= 1if i == 0:return ["[UNK]"]tokens.append(word[:i])word = word[i:]if len(word) > 0:word = f"##{word}"return tokensprint(encode_word("Hugging"))
print(encode_word("HOgging"))def tokenize(text):pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)pre_tokenized_text = [word for word, offset in pre_tokenize_result]encoded_words = [encode_word(word) for word in pre_tokenized_text]return sum(encoded_words, [])tokenize("This is the Hugging Face course!")

标准化和预标记化 - Hugging Face NLP Course
运行结果:
defaultdict(<class 'int'>, {'This': 3, 'is': 2, 'the': 1, 'Hugging': 1, 'Face': 1, 'course': 1, '.': 4, 'chapter': 1, 'about': 1, 'tokenization': 1, 'section': 1, 'shows': 1, 'several': 1, 'tokenizer': 1, 'algorithms': 1, 'Hopefully': 1, ',': 1, 'you': 1, 'will': 1, 'be': 1, 'able': 1, 'to': 1, 'understand': 1, 'how': 1, 'they': 1, 'are': 1, 'trained': 1, 'and': 1, 'generate': 1, 'tokens': 1})
['##a', '##b', '##c', '##d', '##e', '##f', '##g', '##h', '##i', '##k', '##l', '##m', '##n', '##o', '##p', '##r', '##s', '##t', '##u', '##v', '##w', '##y', '##z', ',', '.', 'F', 'H', 'T', 'a', 'b', 'c', 'g', 'h', 'i', 's', 't', 'u', 'w', 'y']
('T', '##h'): 0.125
('##h', '##i'): 0.03409090909090909
('##i', '##s'): 0.02727272727272727
('i', '##s'): 0.1
('t', '##h'): 0.03571428571428571
('##h', '##e'): 0.011904761904761904
('a', '##b') 0.2
['ab', '##o', '##u', '##t']
['[PAD]', '[UNK]', '[CLS]', '[SEP]', '[MASK]', '##a', '##b', '##c', '##d', '##e', '##f', '##g', '##h', '##i', '##k', '##l', '##m', '##n', '##o', '##p', '##r', '##s', '##t', '##u', '##v', '##w', '##y', '##z', ',', '.', 'F', 'H', 'T', 'a', 'b', 'c', 'g', 'h', 'i', 's', 't', 'u', 'w', 'y', 'ab', '##fu', 'Fa', 'Fac', '##ct', '##ful', '##full', '##fully', 'Th', '##hm', '##thm', 'Hu', 'Hug', 'Hugg', 'ch', 'cha', 'chap', 'chapt', 'sh', 'th', 'is', '##thms', '##za', '##zat', '##ut', '##ta']
['Hugg', '##i', '##n', '##g']
['[UNK]']
['Th', '##i', '##s', 'is', 'th', '##e', 'Hugg', '##i', '##n', '##g', 'Fac', '##e', 'c', '##o', '##u', '##r', '##s', '##e', '[UNK]']单词中首字母不变,中间分词以##连接
Unigram Language Model(ULM)

与 BPE 和 WordPiece 相比,Unigram 在另一个方向上工作:它从一个较大的词汇表开始,然后从中删除标记,直到达到所需的词汇表大小。请注意,从不删除基本字符,以确保可以标记任何单词。
在训练的每一步,Unigram 算法都会在给定当前词汇的情况下计算语料库的损失。然后,遍历词汇表中的每个分词,分别计算如果删除该分词,整体损失会增加多少。寻找损失增加最少的分词,这些分词对语料库的整体损失影响较小,因此从某种意义上说,它们“不太需要”并且是移除的最佳候选者。
步骤:
1.建立一个足够大的词表。
2.求当前词表每个分词在语料上的概率。
3.根据词表,计算对语料最优分割下的loss。
4.遍历删除分词,计算删除该分词后对语料最优分割下的loss。
5.根据删除某分词后增加的损失进行排序,按要求比例丢弃对损失无影响或影响较小的分词。单字符不能被丢弃,这是为了避免OOV情况。
6.重复步骤2到5,直到词表大小减少到设定范围。
举个例子:
语料库:![]()
所有分词:
所有子词的出现次数:
给定分词的概率是它在原始语料库中的频率(我们找到它的次数),除以词汇表中所有分词的所有频率的总和(以确保概率总和为 1)。例如, "ug" 在 "hug" 、 "pug" 以及 "hugs" 中,所以它在我们的语料库中的频率为 20。所有频率之和为210, 并且子词 "ug" 出现的概率是 20/210
"pug" 的标记化 ["p", "u", "g"] 的概率为:
标记化 ["pu", "g"] 的概率为:
将一个单词分成尽可能少的分词拥有更高的概率
整体损失函数为
其中num(x)为当前单词在语料中出现的次数,p(x)为当前单词按某种分词方式分词的概率。
对于下面的分词方式:
![]()

所以损失是:
对每种分词方式计算去掉该分词后,最优分割方式下整体损失的变化
如将hug分词去掉,

按照hu g分割为最优分割
计算整体loss的变化值=hugs单词个数*(- (-log(0.071428)) + (-log(0.006802))) = 23.5

将_作为单词开头
相关文章:
NLP基础及其代码-tokenizer
基础知识 NLP-分词器:SentencePiece【参考Chinese-LLaMA-Alpaca在通用中文语料上训练的20K中文词表并与原版LLaMA模型的32K词表进行合并的代码】_sentencepiece 中文训练-CSDN博客 【OpenLLM 008】大模型基础组件之分词器-万字长文全面解读LLM中的分词算法与分词器…...

OpenCV结构分析与形状描述符(8)点集凸包计算函数convexHull()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 查找一个点集的凸包。 函数 cv::convexHull 使用斯克拉斯基算法(Sklansky’s algorithm)来查找一个二维点集的凸包&#…...

灰光模块,彩光模块-介绍
1. 引用 知识分享系列一:5G基础知识-CSDN博客 5G前传的最新进展-CSDN博客 灰光和彩光_通信行业5G招标系列点评之二:一文读懂5G前传-光纤、灰光、彩光、CWDM、LWDM、MWDM...-CSDN博客 ADOP带你了解:CWDM、DWDM、MWDM、LWDM:快速…...

python-新冠病毒
题目描述 假设我们掌握了特定时间段内特定城市的新冠病毒感染病例的信息。在排名 i 的当天有 i 个案例,即: 第一天有一例感染第二天有两例感染第三天有三例感染以此类推...... 请计算 n 天内的感染总数和每天平均感染数。 输入 整数 n 表示天数&…...

2023年408真题计算机网络篇
https://zhuanlan.zhihu.com/p/6954228062023年网络规划设计师上午真题解析TCP流量计算_哔哩哔哩_bilibili 1 1在下图所示的分组交换网络中,主机H1和H2通过路由器互联,2段链路的数据传输速率为100 Mb/s、时延带宽积 (即单向传播时延带宽&am…...

分类学习器(Classification Learner App)MATLAB
在MATLAB中,分类学习器用于构建和评估分类模型。MATLAB提供了一些工具和功能,帮助你进行分类任务,例如分类学习器应用程序、统计和机器学习工具箱中的函数等。 数据集介绍 不同的人被要求在平板电脑上写字母"J"、“V"和&quo…...

DolphinDB 基准性能测试工具:金融模拟数据生成模块合集
测试 DolphinDB 数据库性能时,往往需要快速写入一些测试数据。为方便用户快速完成简单的基准性能测试,金融 Mock 数据生成模块覆盖了常用的金融数据集,满足用户生成模拟数据的需求。基于本模块生成的模拟数据不具有实际意义,建议仅…...

BUUCTF—[BJDCTF2020]The mystery of ip
题解 打开环境点击上面的flag可以看到这个IP页面。 抓个包看看有啥东西无,可以看到在返回包有IP。 看到IP就想到X-Forwarded-For这个玩意,我们用X-Forwarded-For随便添加个IP看看。可以看到返回的IP内容变成了123。 X-Forwarded-For:123 推测它会输出我…...

leecode100题-双指针-三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 答案中不可以包含重复的三元组。 示例 1: 输入…...

计算机毕业设计PySpark+Django考研分数线预测 考研院校推荐系统 考研推荐系统 考研爬虫 考研大数据 Hadoop 大数据毕设 机器学习 深度学习
《PySparkDjango考研分数线预测与推荐系统》开题报告 一、研究背景与意义 随着教育水平的提高和就业竞争的加剧,越来越多的学生选择继续深造,参加研究生入学考试(考研)。然而,考研信息繁杂,选择专业和院校…...

Go语言多态实践以及gin框架c.BindJSON序列化遇到的坑
遇到的问题 如果定义的接收结构体字段是interface{},在调用gin的 c.BindJSON 方法后会直接转为map, 导致无法断言为其他类型 场景 在创建工程请求中,根据工程类别的不同会有多种创建参数,比如 // A 类型需要编译 所以有这些字…...
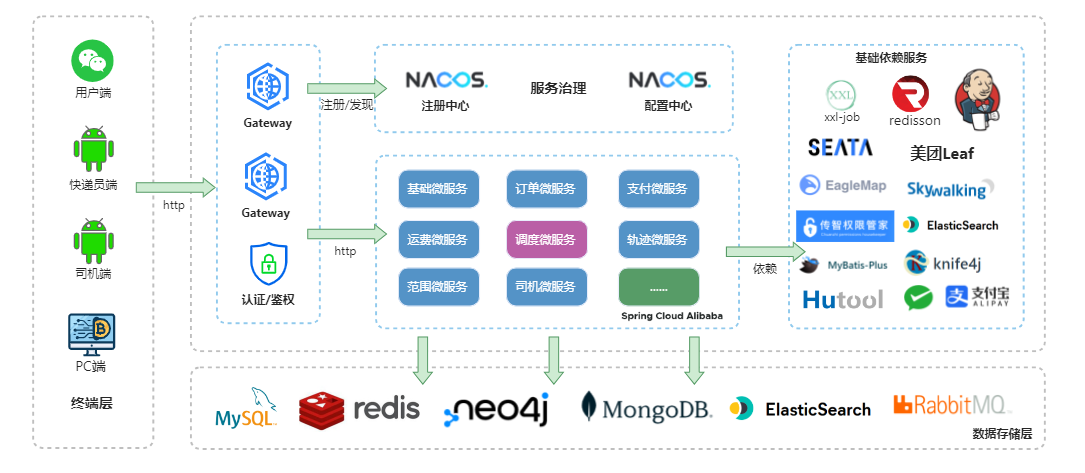
SpringCloud神领物流学习笔记:项目概述(一)
SpringCloud神领物流学习笔记:项目概述(一) 文章目录 SpringCloud神领物流学习笔记:项目概述(一)1、项目介绍2、基本业务流程3、系统架构4、技术架构 1、项目介绍 神领物流是一个基于微服务架构体系的【…...

RocketMQ异步报错:No route info of this topic
在SpringBoot中发送RocketMQ异步消息的时候报错了,提示org.apache.rocketmq.client.exception.MQClientException: No route info of this topic, testTopic1 这里给出具体的解决方案 一、Broker模块不支持自动创建topic,并且topic没有被手动创建过 R…...

Node.js学习记录(一)
目录 一、文件读取 readFile 二、写入文件 writeFile 三、动态路径 __dirname:表示当前文件所处的目录、path.join 四、获取路径文件名 path.basename 五、提取某文件中的css、JS、html 六、http 七、启动创建web服务器 服务器响应 八、将资源请求的 url 地…...

【AI】Pytorch_模型构建
建议点赞收藏关注!持续更新至pytorch大部分内容更完。 本文已达到10w字,故按模块拆开,详见目录导航。 整体框架如下 数据及预处理 模型及其构建 损失函数及优化器 本节目录 模型线性回归逻辑回归LeNetAlexNet 构建模块组织复杂网络初始化网络…...

FFmpeg源码:avcodec_descriptor_get函数分析
一、avcodec_descriptor_get函数的声明 avcodec_descriptor_get函数声明在FFmpeg源码(本文演示用的FFmpeg源码版本为7.0.1)的头文件libavcodec/codec_desc.h中: /*** return descriptor for given codec ID or NULL if no descriptor exist…...

为数据仓库构建Zero-ETL无缝集成数据分析方案(下篇)
对于从事数据分析的小伙伴们来说,最头疼的莫过于数据处理的阶段。在我们将数据源的原始数据导入数据仓储进行分析之前,我们通常需要进行ETL流程对数据格式进行统一转换,这个流程需要分配专业数据工程师基于业务情况完成,整个过程十…...

ElMessageBox消息确认框组件在使用时如何设置第三个或多个自定义按钮
ElMessageBox自带两个按钮一个确认一个取消,当还想使用该组件还想再加个功能组件时,就需要自定义个按钮加到组件里 第二种方法可以通过编写自定义弹窗来完成,个人觉得代码量增多过于繁琐,当然也可以实现 先定义方法负责获取dom父节点,创建新的子元素加…...

javaWeb【day04】--(MavenSpringBootWeb入门)
01. Maven课程介绍 1.1 课程安排 学习完前端Web开发技术后,我们即将开始学习后端Web开发技术。做为一名Java开发工程师,后端Web开发技术是我们学习的重点。 1.2 初识Maven 1.2.1 什么是Maven Maven是Apache旗下的一个开源项目,是一款用于…...
[Linux]:文件(下)
✨✨ 欢迎大家来到贝蒂大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:Linux学习 贝蒂的主页:Betty’s blog 1. 重定向原理 在明确了文件描述符的概念及其分配规则后,我们就可…...

旧设备重生:如何让经典iOS设备突破系统限制重获新生?
旧设备重生:如何让经典iOS设备突破系统限制重获新生? 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to downgrade/restore, save SHSH blobs, and jailbreak legacy iOS devices 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...

go logrus和zap各有什么优缺点
Go 生态中两个最流行的结构化日志库对比:Logrus vs Zap 对比 特性 Logrus Zap 性能 较慢(反射-based) 极快(零分配、结构化) API 风格 链式调用,类似 Python logging 显式字段࿰…...

开源OCR工具Umi-OCR:本地化部署与高效识别实践指南
开源OCR工具Umi-OCR:本地化部署与高效识别实践指南 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com/GitHub_…...

探索Demucs音频分离:当音乐遇见人工智能的魔法分解术
探索Demucs音频分离:当音乐遇见人工智能的魔法分解术 【免费下载链接】demucs Code for the paper Hybrid Spectrogram and Waveform Source Separation 项目地址: https://gitcode.com/gh_mirrors/de/demucs 想象一下,你正沉浸在一首复杂的交响乐…...

MinerU-Diffusion:文档OCR解码提速3.2倍新方案
MinerU-Diffusion:文档OCR解码提速3.2倍新方案 【免费下载链接】MinerU-Diffusion-V1-0320-2.5B 项目地址: https://ai.gitcode.com/OpenDataLab/MinerU-Diffusion-V1-0320-2.5B 导语 MinerU-Diffusion框架通过将文档OCR重构为逆渲染问题,采用并…...

Noi:整合多 AI 服务的新利器能否突出重围?
Noi:一站式 AI 服务整合新体验Noi 是一款图形用户界面(GUI)应用程序,它的核心亮点在于将所有 AI 服务整合到一处。用户通过单一用户界面(UI)就能访问 ChatGPT、Claude、Gemini、Perplexity 等多个服务&…...

快速集成A2A Agent
面我们提到可以将MCP服务也封装为一个Tool(AIFunction)让Agent调用,这里A2A Agent也是一样的道理。 这样做的好处是:让MAF中的Agent像调用本地函数一样调用远程A2A Agent 或 MCP Server。 下面的代码展示了在MAF中将A2A Card转换…...

MWGA 双线编译技术方案:一份代码,双端生成
核心技术原理MWGA 的双线编译基于模块化架构与跨平台编译引擎,实现「一份代码,双向生成」。代码分层: 将代码划分为核心业务逻辑层与端侧 UI 适配层。核心层包含数据模型、算法、权限校验等通用功能,纯 C# 编写且不依赖端侧 API&a…...

XUnity.AutoTranslator:打破Unity游戏语言壁垒的开源解决方案
XUnity.AutoTranslator:打破Unity游戏语言壁垒的开源解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 当你面对一款内容精彩但语言不通的Unity游戏时,是否曾因语言障碍而错…...

如何用OBS Multi RTMP插件实现一键多平台直播:终极免费解决方案
如何用OBS Multi RTMP插件实现一键多平台直播:终极免费解决方案 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 你是否曾经梦想过在YouTube、Twitch和Bilibili等平台上同时直…...