(深度学习快速入门)第五章第一节2:GAN经典案例之MNIST手写数字生成
- 获取pdf:密码7281
文章目录
- 一:数据集介绍
- 二:GAN简介
- (1)简介
- (2)损失函数
- 三:代码编写
- (1)参数及数据预处理
- (2)生成器与判别器模型
- (3)优化器和损失函数
- (4)训练
- 三:效果查看
- (1)tensorboard
- (2)生成图片效果
一:数据集介绍
MNIST数据集:MNIST是个手写数字图片集,每张图片都做了归一化处理,大小是28x28,并且是灰度图像,所以每张图像格式为1x28x28
- 数据集下载地址
包括如下四个文件

含义如下
| 类别 | 文件名 | 描述 |
|---|---|---|
| 训练集图片 | train-images-idx3-ubyte.gz(9.9M) | 包含60000个样本 |
| 训练集标签 | train-labels-idx1-ubyte.gz(29KB) | 包含60000个标签 |
| 测试集图片 | t10k-images-idx3-ubyte.gz(1.6M) | 包含10000个样本 |
| 测试集标签 | t10k-labels-idx1-ubyte.gz(5KB) | 包含10000个样本 |
当然torchvision.datasets中也内置了这个数据集,可以通过如下代码从网络上下载
train_data = dataset.MNIST(root='./mnist/',train=True,transform=transforms.ToTensor(),download=True)
test_data = dataset.MNIST(root='./mnist/',train=False,transform=transforms.ToTensor(),download=False)
root:表示数据集待存放的目录train:如果为true将会使用训练集的数据集(training.pt),如果为false将会使用测试集数据集(test.pt)download:如果为true将会从网络上下载并放入root中,如果数据集已下载则不会再次下载transform:接受PIL图片并返回转换后的图片,常用的就是转换为tensor(这里便会调用torchvision.transform)
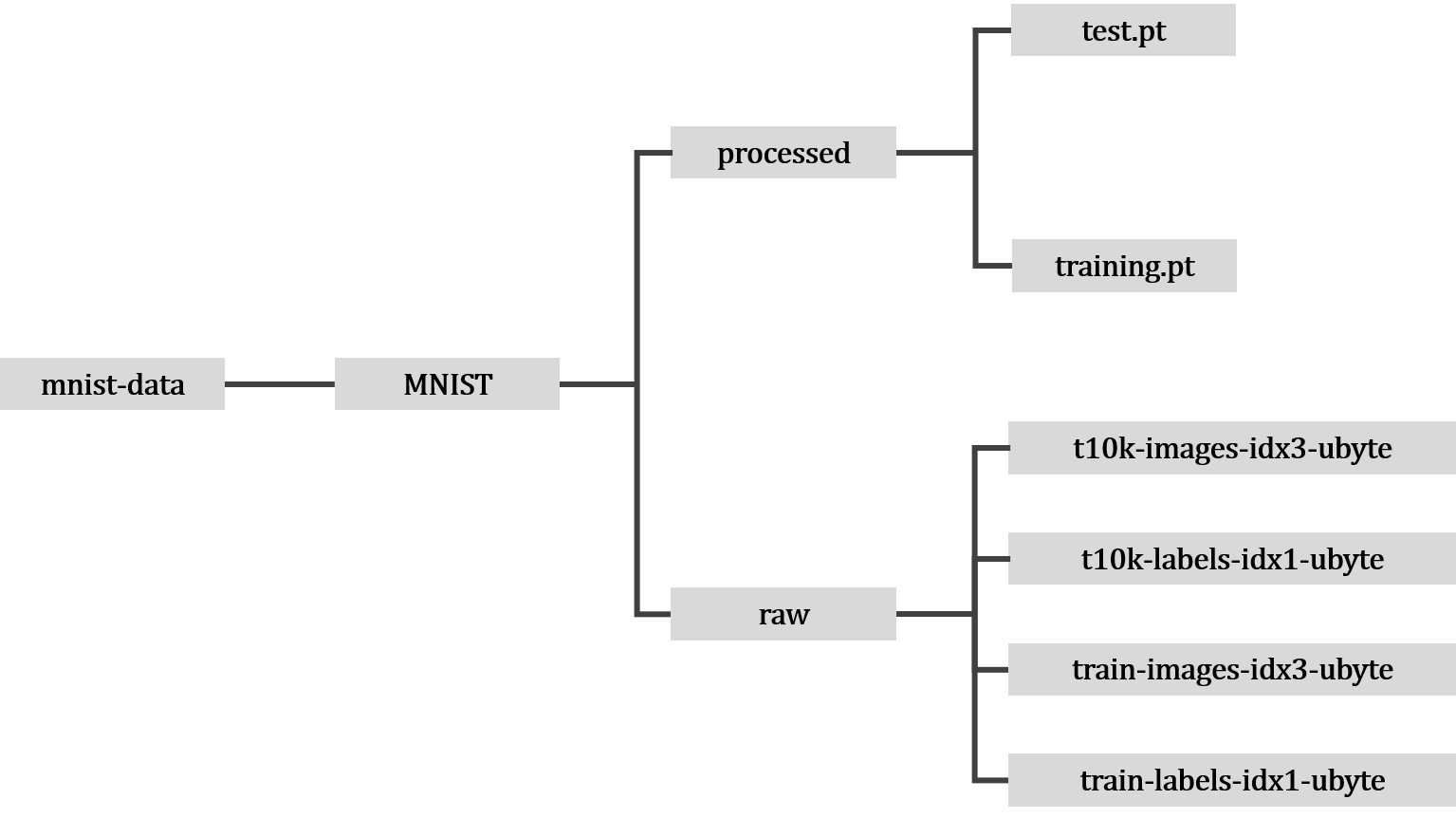
数据集加载成功后,文件布局如下
二:GAN简介
(1)简介
GAN(Generative Adversial Nets,生成式对抗网络):这是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型有两个模型:生成模型(Generative Model)和辨别模型(Discriminative Model)的互相博弈学习产生相当好的输出。实际使用时一般会选择DNN作为G和D
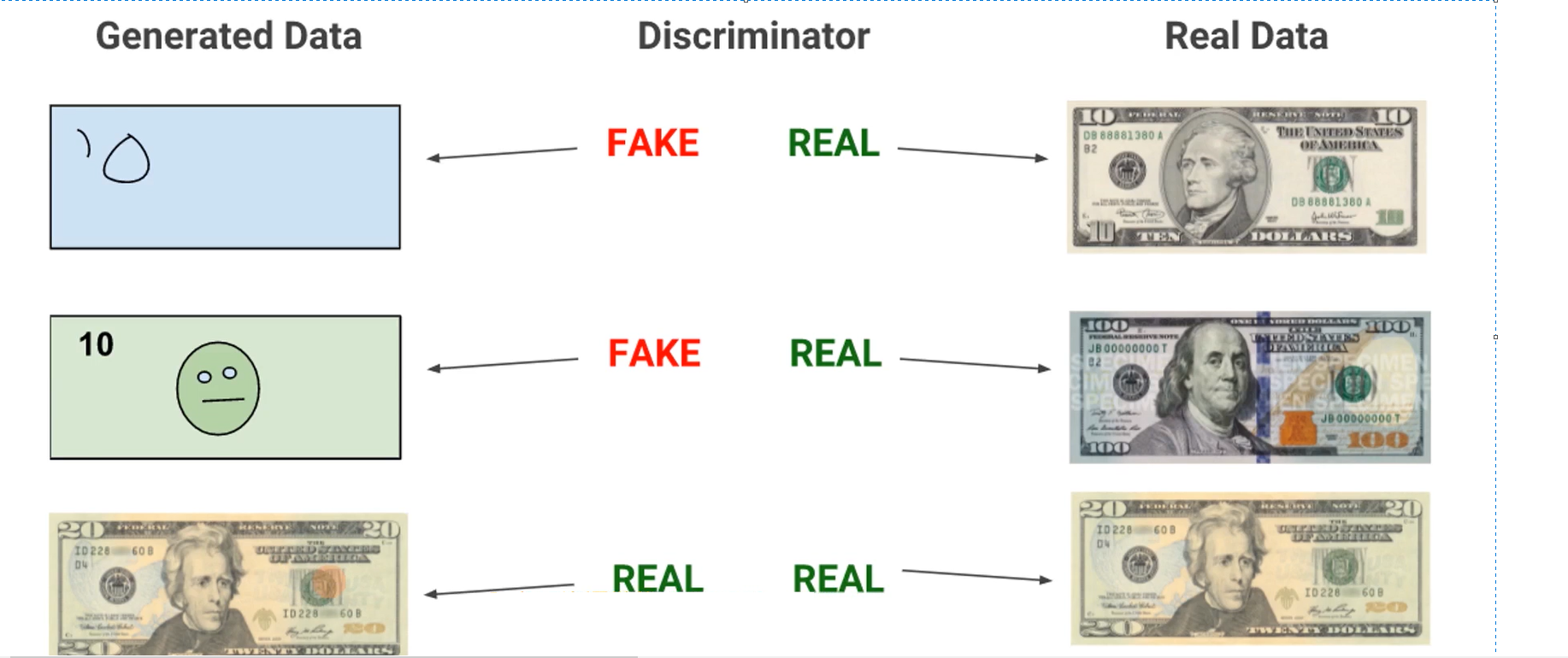
如下图,以论文中所述的制作假钞的例子为例进行说明
- 生成模型G的目的是尽量能够生成足以以假乱真的假钞去欺骗判别模型D,让它以为这是真钞
- 判别模型D的目的是尽量能够鉴别出生成模型G生成的假钞是假的
(2)损失函数
GAN损失函数如下

其中参数含义如下
- xxx:真实的数据样本
- zzz:噪声,从随机分布采集的样本
- GGG:生成模型
- DDD:判别模型
- G(z)G(z)G(z):输入噪声生成一条样本
- D(x)D(x)D(x):判别真实样本是否来自真实数据(如果是则为1,如果不是则为0)
- D(G(z))D(G(z))D(G(z)):判别生成样本是否来自真实数据(如果是则为1,如果不是则为0)
该损失函数整体分为两个部分
第一部分:给定GGG找到使VVV最大化的DDD,因为使VVV最大化的DDD会使判别器效果最好
- 对于①:判别器的输入为真实数据xxx,Ex∼pdata[logD(x)]E_{x}\sim p_{data}[logD(x)]Ex∼pdata[logD(x)]值越大表示判别器认为输入xxx为真实数据的概率越大,也即表示判别器的能力越强,所以这一项输出越大对判别器越有利
- 对于②:判别器的输入伪造数据G(z)G(z)G(z),此时D(G(z))D(G(z))D(G(z))越小那么就表示判别器将此伪造数据鉴别为真实数据的概率也越小,也即表示判别器的能力越强。注意此时第二项是log(1−D(G(z)))log(1-D(G(z)))log(1−D(G(z)))的期望Ex∼pdata[log(1−D(G(z)))]E_{x}\sim p_{data}[log(1-D(G(z)))]Ex∼pdata[log(1−D(G(z)))]。所以当判别器能力越强时,D(G(z))D(G(z))D(G(z))越小同时Ex∼pdata[log(1−D(G(z)))]E_{x}\sim p_{data}[log(1-D(G(z)))]Ex∼pdata[log(1−D(G(z)))]也就越大
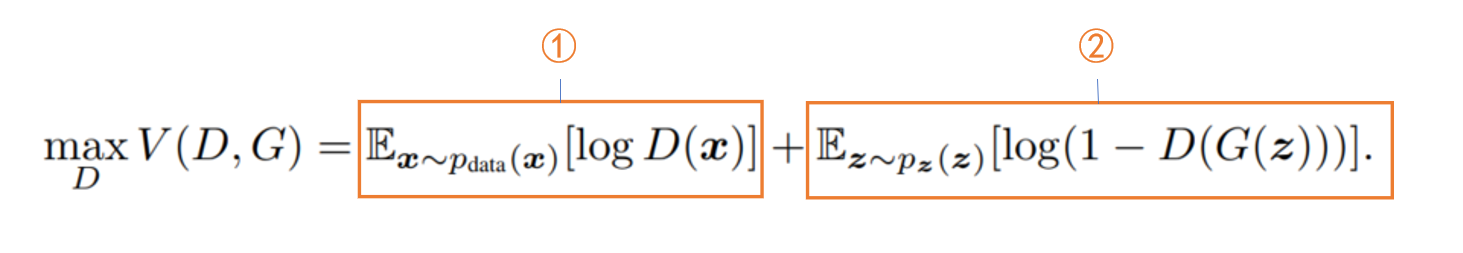
第二部分:给定DDD找到使VVV最小化的GGG,因为使VVV最小化的GGG会使生成器效果最好
- 对于①:由于固定了DDD,而这一部分只和DDD有关,因此这一部分是常量,所以可以舍去
- 对于②:判别器的输入伪造数据G(z)G(z)G(z),与上面不同的是,我们期望生成器的效果要好,尽可能骗过辨别器,所以D(G(z))D(G(z))D(G(z))要尽可能大(D(G(z))D(G(z))D(G(z))越大表示辨别器鉴定此数据为真实数据的概率越大),Ex∼pdata[log(1−D(G(z)))]E_{x}\sim p_{data}[log(1-D(G(z)))]Ex∼pdata[log(1−D(G(z)))]也就越小
三:代码编写
(1)参数及数据预处理
# 设备
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':print("GPU上运行")
else:print("CPU上运行")
# 图片格式
img_size = [1, 28, 28]# batchsize
batchsize = 64# latent_dim
latent_dim = 100# 数据集及变化
data_transforms = transforms.Compose([transforms.Resize(28),transforms.ToTensor(),transforms.Normalize([0.5], [0.5])]
)
dataset = torchvision.datasets.MNIST(root='~/autodl-tmp/dataset', train=True, download=False, transform=data_transforms)
(2)生成器与判别器模型
# 生成器模型
"""
根据输入生成图像
"""class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()def block(in_feat, out_feat, normalize=True):layers = [nn.Linear(in_feat, out_feat)]if normalize:layers.append(nn.BatchNorm1d(out_feat, 0.8))layers.append(nn.LeakyReLU(0.2, inplace=True))return layersself.model = nn.Sequential(*block(latent_dim, 128, normalize=False),*block(128, 256),*block(256, 512),*block(512, 1024),nn.Linear(1024, np.prod(img_size, dtype=np.int32)),nn.Tanh())def forward(self, x):# [batchsize, latent_dim]output = self.model(x)image = output.reshape(x.shape[0], *img_size)return image# 判别器模型
"""
判别图像真假
"""
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear( np.prod(img_size, dtype=np.int32), 512),nn.ReLU(inplace=True),nn.Linear(512, 256),nn.ReLU(inplace=True),nn.Linear(256, 128),nn.ReLU(inplace=True),nn.Linear(128, 1),nn.ReLU(inplace=True),nn.Sigmoid(),)def forward(self, x):# [batch_size, 1, 28, 28]x = x.reshape(x.shape[0], -1)output = self.model(x)return output(3)优化器和损失函数
# 优化器和损失函数
generator = Generator()
generator = generator.to(device)
discriminator = Discriminator()
discriminator = discriminator.to(device)g_optimizer = torch.optim.Adam(generator.parameters(), lr=0.0001)
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=0.0001)
loss_func = nn.BCELoss()
(4)训练
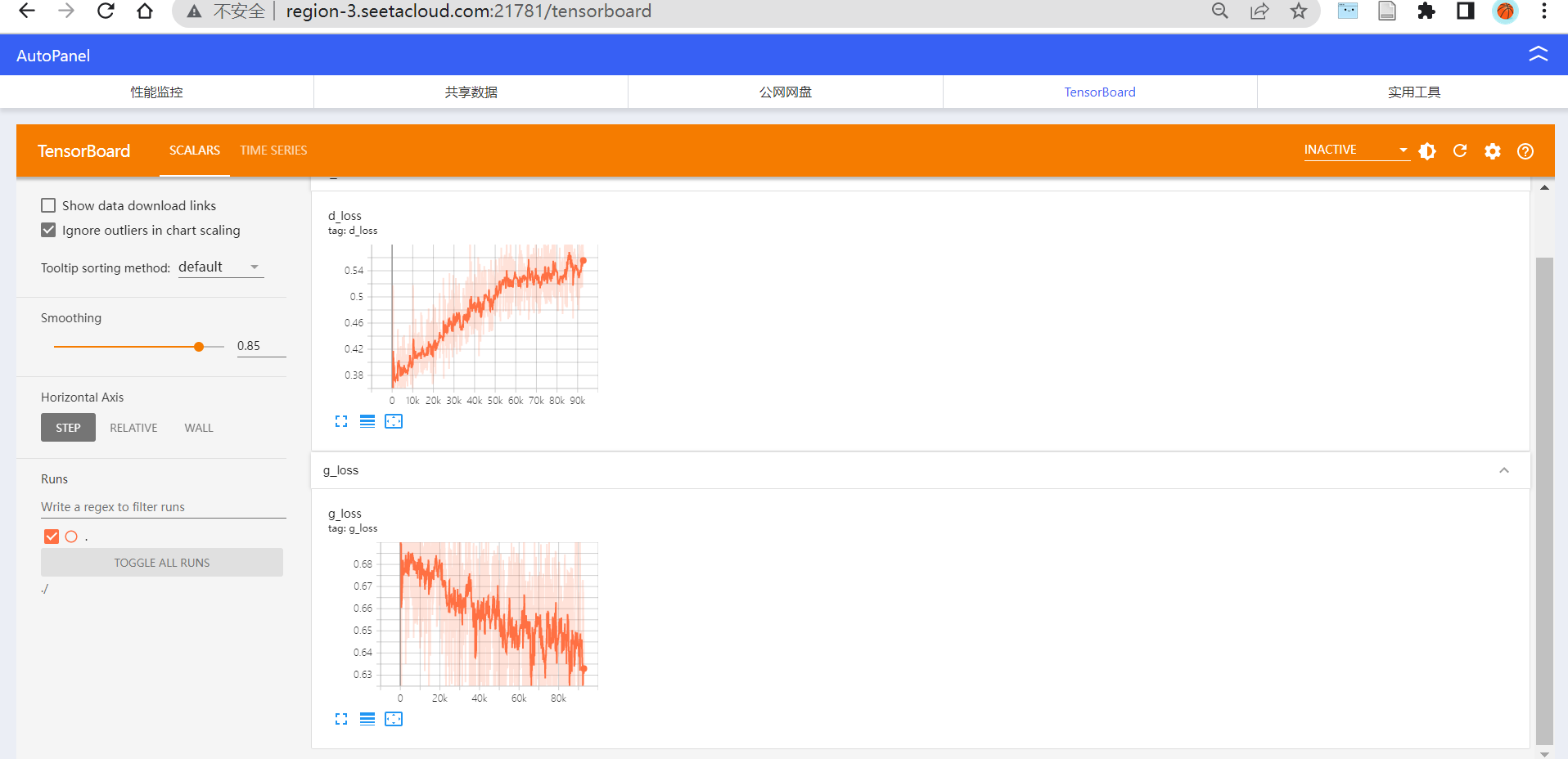
def train():step = 0dataloader = DataLoader(dataset=dataset, batch_size=batchsize, shuffle=True, drop_last=True, num_workers=8)for epoch in range(1, 100):print("-----------当前epoch:{}-----------".format(epoch))for i, batch in enumerate(dataloader):print("-----------当前batch:{}/{}-----------".format(i, (len(dataloader))))# 拿到真实图片X, _ = batchX = X.to(device)# 采用标准正态分布得到的batchsize × latent_dim的向量z = torch.randn(batchsize, latent_dim)z = z.to(device)# 送入生成器生成假图片pred_X = generator(z)g_optimizer.zero_grad()"""生成器损失:让生成的图像与通过辨别器与torch.ones(batchsize, 1)越接近越好"""g_loss = loss_func(discriminator(pred_X), torch.ones(batchsize, 1).to(device))g_loss.backward()g_optimizer.step()d_optimizer.zero_grad()"""辨别器损失:一方面让真实图片通过辨别器与torch.ones(batchsize, 1)越接近越好另一方面让生成图片通过辨别器与torch.zeros(batchsize, 0)越接近越好"""d_loss = 0.5 * (loss_func(discriminator(X), torch.ones(batchsize, 1).to(device)) + loss_func(discriminator(pred_X.detach()), torch.zeros(batchsize, 1).to(device)))d_loss.backward()d_optimizer.step()print("生成器损失{}".format(g_loss), "辨别器损失{}".format(d_loss))logger.add_scalar('g_loss', g_loss, step)logger.add_scalar('d_loss', d_loss, step)step = step+1if step % 1000 == 0:save_image(pred_X.data[:25], "./image_save/image_{}.png".format(step), nrow=5)
三:效果查看
(1)tensorboard
(2)生成图片效果
每1000个step保存一次照片,最后生成了92张图片,每张图片由每个batch的前25张图片构成
1000-step

5000-step

10000-step

20000-step

30000-step

50000-step

70000-step

80000-step

90000-step

920000-step(final)

相关文章:
(深度学习快速入门)第五章第一节2:GAN经典案例之MNIST手写数字生成
获取pdf:密码7281 文章目录一:数据集介绍二:GAN简介(1)简介(2)损失函数三:代码编写(1)参数及数据预处理(2)生成器与判别器模型&#x…...
雁过留痕,竟是病毒的痕迹?
凌恩生物全新升级宏病毒组分析流程;聚焦DNA,RNA病毒组研究热点;高灵敏度检测vOTUs;多软件整合,精准鉴定病毒序列;直击地化循环关键环节,助力宏病毒组科研成功!期刊:Micro…...

Linux基本功系列之sort命令实战
文章目录前言一. sort命令介绍二. 语法格式及常用选项三. 参考案例3.1 按照文本默认排序3.2 忽略相同的行3.3 按数字大小进行排序3.4 检查文件是否已经按照顺序排序3.5 将第3列按照数字大小进行排序3.6 将排序结果输出到文件四. 探讨 -k的高级用法总结前言 大家好,…...
【笔记】移动端自动化:adb调试工具+appium+UIAutomatorViewer
学习源: https://www.bilibili.com/video/BV11p4y197HQ https://blog.csdn.net/weixin_47498728/category_11818905.html 一、移动端测试环境搭建 学习目标 1.能够搭建java 环境 2.能够搭建android 环境 (一)整体思路 我们的目标是Andr…...
面试复习题--性能检测原理
1、布局性能检测 Systrace,内存优化工具中也用到了 Systrace,这里关注 Systrace 中的 Frames 页面,正常情况下圆点为绿色,当出现黄色或者红色的圆点时,表现出现了丢帧。 Layout Inspector,是 AndroidStudio 自带工具…...

@LoadBalanced 和 @RefreshScope 同时使用,负载均衡失效分析
背景 最近引入了 Nacos Config 配置管理能力,说起来用法很简单,还是踩了三个坑。 Nacos Config 的 nacos 的帐号密码加密配置后,怎么解密而且在 NacosConfigBootstrapConfiguration 真正注入 Nacos Config 注入之前,而且不能触发…...

2023年个人计划
2023年个人计划 可能是最近太清闲,感觉生活很无聊,就胡乱做下新年的规划吧,扰乱下烦闷的心 1 二宝健健康康,活泼可爱 目前老婆已经怀孕5周左右了,二宝将在进行年中降生,希望老婆少受点罪,二宝…...

加拿大访问学者家属如何办理探亲签证?
由于大多数访问学者的访学期限都为一年,家人来访不仅可以缓解访学的寂寞生活,而且也是家人到加拿大体验国外风情的好机会。家属在国内申请赴加签证时,如果材料齐全,一般上午递交了申请,下午就可以拿到签证。以下是家人…...
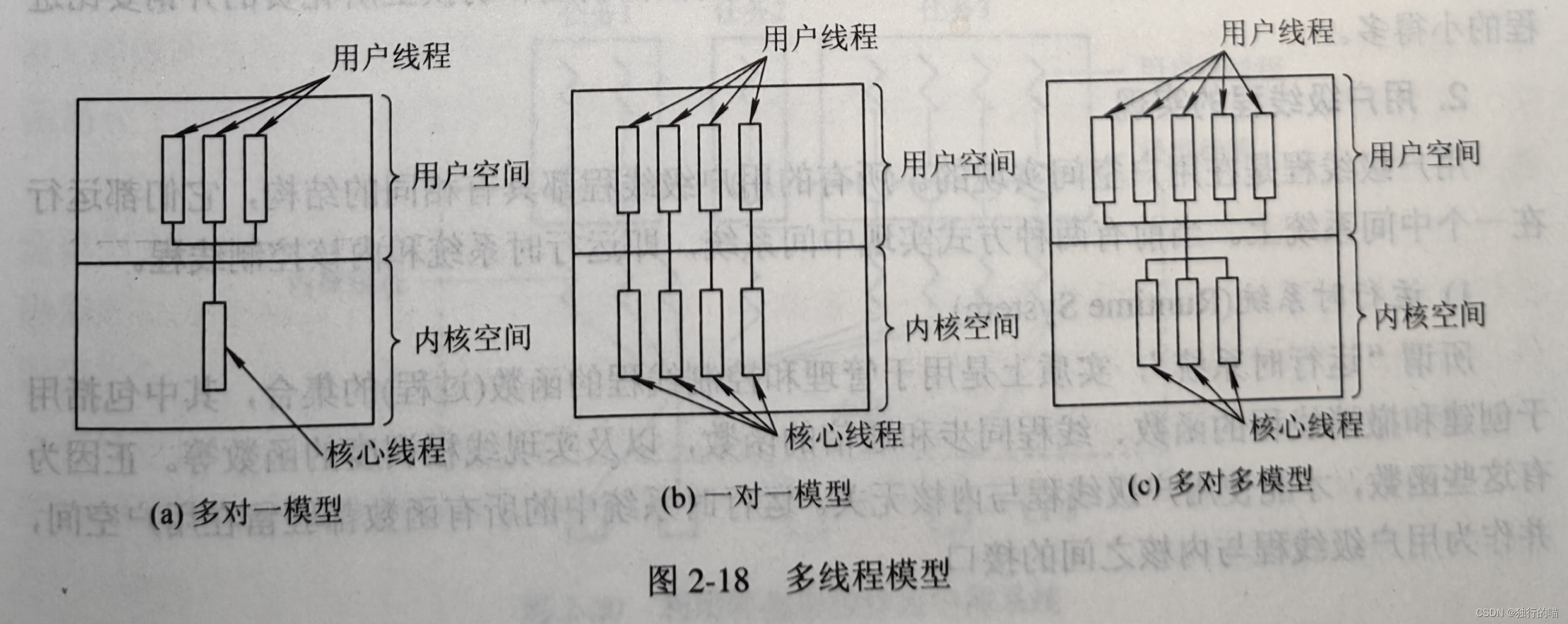
操作系统基础---多线程
文章目录操作系统基础---多线程1.为何引入线程程序并发的时空开销线程的设计思路线程的状态和线程控制块TCB2.线程与进程的比较3.线程的实现⭐1.内核支持线程KST2.用户级线程3.组合方式操作系统基础—多线程 1.为何引入线程 利用传统的进程概念和设计方法已经难以设计出适合于…...
等级考试试卷(六级)解析)
2022-12-10青少年软件编程(C语言)等级考试试卷(六级)解析
2022-12-10青少年软件编程(C语言)等级考试试卷(六级)解析T1、区间合并 给定 n 个闭区间 [ai; bi],其中i1,2,...,n。任意两个相邻或相交的闭区间可以合并为一个闭区间。例如,[1;2] 和 [2;3] 可以合并为 [1;3…...

太酷了,用Python实现一个动态条形图!
大家好,我是小F~说起动态条形图,小F之前推荐过两个Python库,比如「Bar Chart Race」、「Pandas_Alive」,都可以实现。今天就给大家再介绍一个新的Python库「pynimate」,一样可以制作动态条形图,…...
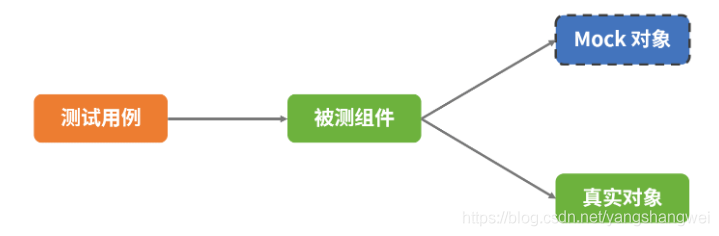
单元测试junit+mock
单元测试 是什么? 单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。至于“单元”的大小或范围,并没有一个明确的标准,“单元”可以是一个方法、类、功能模块或者子系统。 单元测试通…...
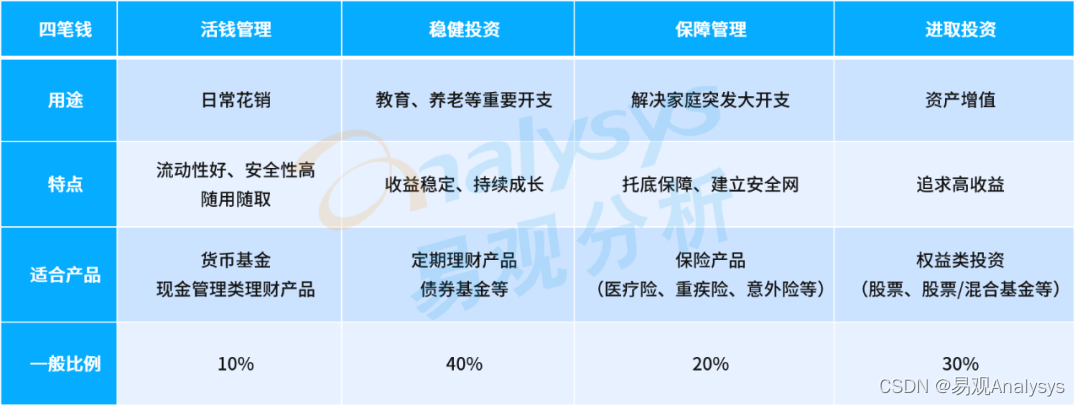
2022Q4手机银行新版本聚焦提升客群专属、财富开放平台、智能化能力,活跃用户规模6.91亿人
易观:2022年第4季度,手机银行APP迭代升级加快,手机银行作为零售银行服务及经营的主阵地,与零售银行业务发展的联系日益紧密。迭代升级一方面可以顺应零售银行发展战略及方向,对手机银行业务布局进行针对性调整优化&…...
YOLO-V1~V3经典物体检测算法介绍
大名鼎鼎的YOLO物体检测算法如今已经出现了V8版本,我们先来了解一下它前几代版本都做了什么吧。本篇文章介绍v1-v3,后续会继续更新。一、节深度学习经典检测方法概述1.1 检测任务中阶段的意义我们所学的深度学习经典检测方法 ,有些是单阶段的…...
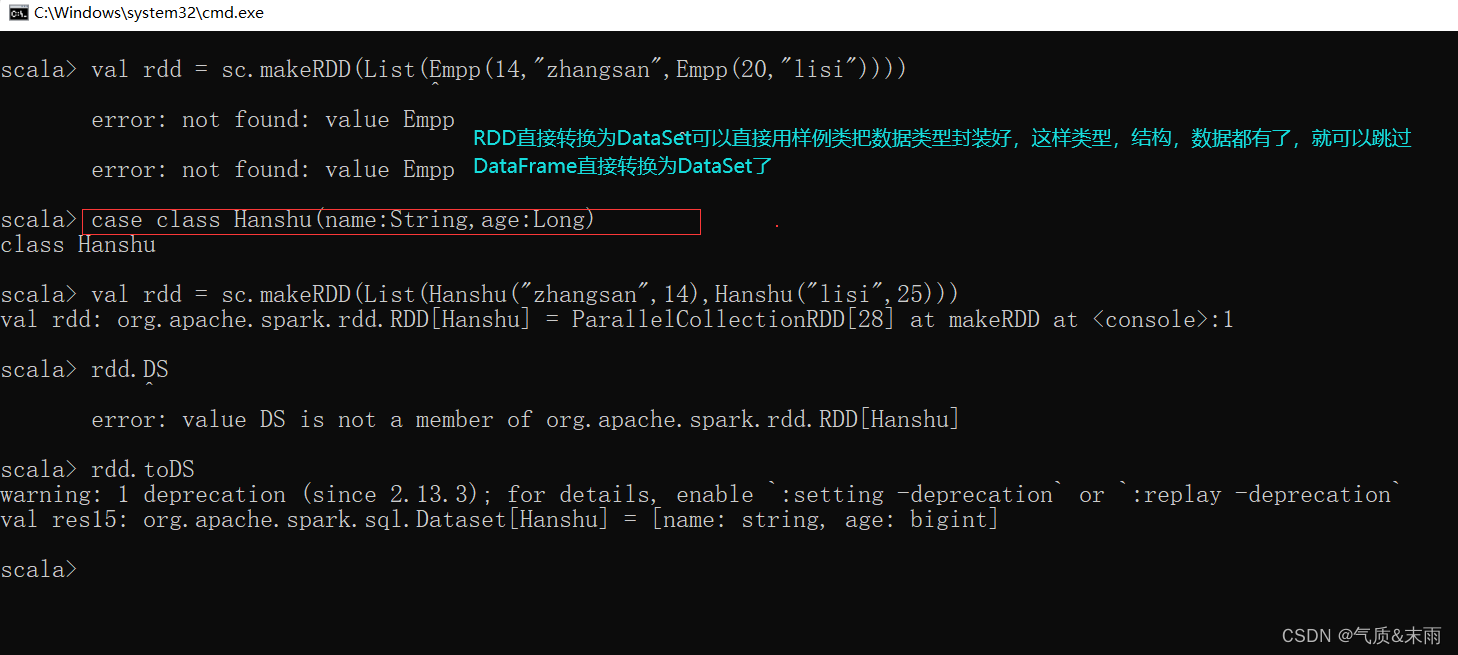
SparkSQL 核心编程
文章目录SparkSQL 核心编程1、新的起点2、SQL 语法1) 读取 json 文件创建 DataFrame2) 对 DataFrame 创建一个临时表3) 通过SQL语句实现查询全表3、DSL 语法1) 创建一个DataFrame2) 查看DataFrame的Schema信息3) 只查看"username"列数据4) 查看"username"列…...
Android核心开发【UI绘制流程解析+原理】
一、UI如何进行具体绘制 UI从数据加载到具体展现的过程: 进程间的启动协作: 二、如何加载到数据 应用从启动到onCreate的过程: Activity生产过程详解: 核心对象 绘制流程源码路径 1、Activity加载ViewRootImpl ActivityThread…...
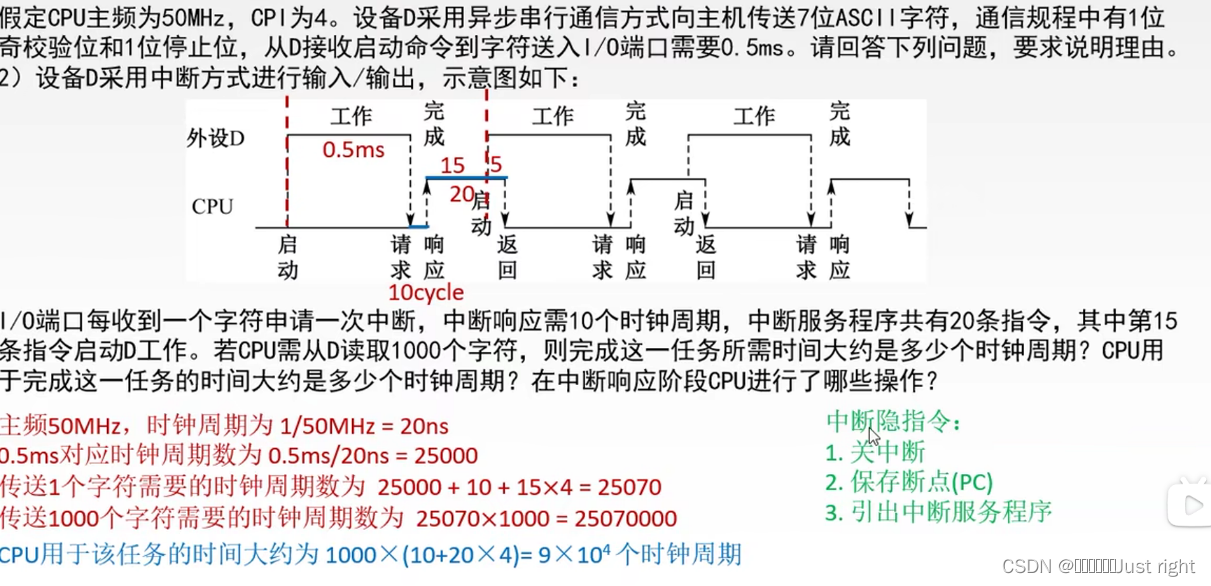
计算机组成原理第七章笔记记录
仅仅作为笔记记录,B站视频链接,若有错误请指出,谢谢 基本概念 演变过程 I/O系统基本组成 I/O软件 包括驱动程序、用户程序、管理程序、升级补丁等 下面的两种方式是用来实现CPU和I/O设备的信息交换的 I/O指令 CPU指令的一部分,由操作码,命令码,设备…...
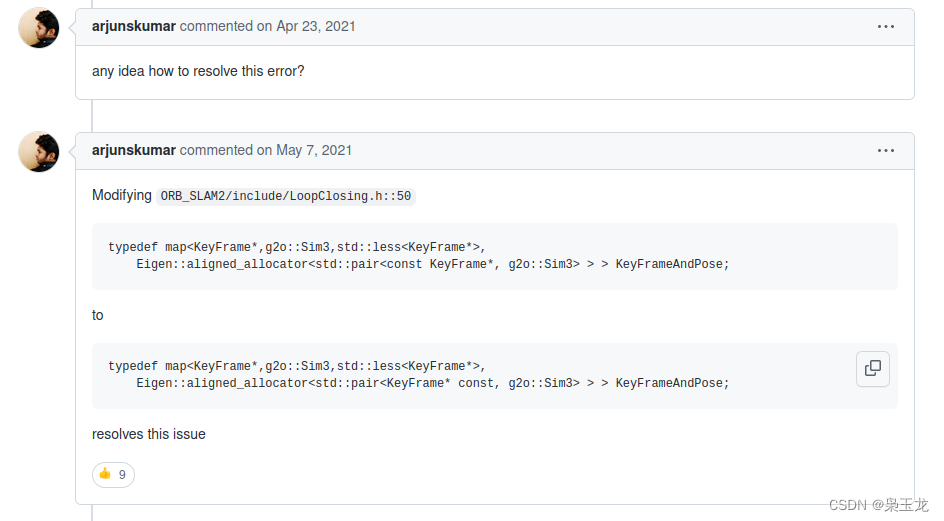
ORB-SLAM2编译、安装等问题汇总大全(Ubuntu20.04、eigen3、pangolin0.5、opencv3.4.10)
ORB-SLAM2编译、安装等问题汇总大全(Ubuntu20.04、eigen3、pangolin0.5、opencv3.4.10) 1:环境说明: 使用的Linux发行版本为Ubuntu 20.04 SLAM2下载地址为:git clone https://github.com/raulmur/ORB_SLAM2.git ORB_SLAM2 2&a…...

QuickBuck:一款专为安全研究人员设计的勒索软件模拟器
关于QuickBuck QuickBuck是一款基于Golang开发的勒索软件模拟工具,在该工具的帮助下,广大研究人员可以通过更简单的方法来判断反病毒保护方案是否能够有效地预防勒索软件的攻击。 功能介绍 该工具能够模拟下列勒索软件典型行为,其中包括&a…...

【八大数据排序法】堆积树排序法的图形理解和案例实现 | C++
第二十一章 堆积树排序法 目录 第二十一章 堆积树排序法 ●前言 ●认识排序 1.简要介绍 2.图形理解 3.算法分析 ●二、案例实现 1.案例一 ● 总结 前言 排序算法是我们在程序设计中经常见到和使用的一种算法,它主要是将一堆不规则的数据按照递增…...

DES算法C++实现踩坑实录:S盒置换与比特操作的那些坑
DES算法C实现中的五大典型陷阱与解决方案 在实现DES算法的过程中,许多开发者都会遇到一些看似简单却容易导致加密结果错误的细节问题。本文将聚焦于实际编码中最常见的五个"坑点",通过具体案例分析和解决方案,帮助开发者快速定位和…...

Agentfiles:统一管理AI编码助手技能文件的Obsidian插件
1. 项目概述:一个为AI编码助手打造的“技能管理中心” 如果你和我一样,同时在使用Claude Code、Cursor、Windsurf这些新一代的AI编码助手,那你一定也面临过同样的困扰:每个工具都有自己的一套“技能”(Skills…...

Linux终端美化:cmatrix屏保的安装与个性化配置指南
1. 初识cmatrix:从黑客帝国到你的终端 第一次看到cmatrix运行效果时,我正窝在咖啡馆调试服务器。黑色背景上不断下落的绿色字符,瞬间让我想起《黑客帝国》里尼奥看到的数字雨。这个诞生于2002年的开源项目,最初只是开发者Chris Al…...
)
集合进阶(Collection)
一、集合概述和分类1.1 集合的分类如下图所示:一类是单列集合元素是一个一个的,另一类是双列集合元素是一对一对的。 主要学习Collection单列集合。Collection是单列集合的根接口,也称之为顶层接口,Collection接口下面又有两个子接…...

Go+SQLite构建极简自托管笔记共享平台:从原理到部署实战
1. 项目概述:一个极简、自托管的笔记共享平台最近在折腾个人知识管理工具时,我一直在寻找一个能让我快速分享单篇笔记或代码片段,同时又不想依赖第三方云服务的方案。市面上的Pastebin类工具很多,但要么功能臃肿,要么隐…...
)
Xilinx MIG核读写DDR3时,这个时序细节没处理好,数据就全乱了(附Vivado 2020.1调试实录)
Xilinx MIG核DDR3读写时序陷阱:命令与数据通道异步处理实战解析 当你在Vivado中完成MIG核配置,看着DDR3初始化校准成功的指示灯亮起时,可能不会想到真正的挑战才刚刚开始。我曾在多个高速数据采集项目中,反复栽在同一个坑里——命…...

JS 侦探社:如何精准判断一个对象是不是数组?
🕵️♂️ JS 侦探社:如何精准判断一个对象是不是数组? 🤔 为什么判断数组这么难? 在 JavaScript 中,数组本质上也是一种对象。 console.log(typeof []); // "object" console.log(typeof {}…...

如何用dnGrep进行代码搜索:程序员必备的10个搜索模式
如何用dnGrep进行代码搜索:程序员必备的10个搜索模式 【免费下载链接】dnGrep Graphical GREP tool for Windows 项目地址: https://gitcode.com/gh_mirrors/dn/dnGrep dnGrep是一款强大的Windows图形化GREP搜索工具,专为开发者和技术用户设计。这…...

MyBatis 二级缓存脏读真实原因
很多同学熟悉 MyBatis 一级缓存、二级缓存基础用法,但多表联查、跨Mapper更新场景下的缓存脏读漏洞,90%的人都会踩坑。 本文结合完整实战案例,用大白话拆解:脏读如何产生、一级缓存二级缓存双重隐患、Namespace隔离缺陷࿰…...

不止是支付码:用vue-qr在后台管理系统生成带品牌Logo的物料二维码
企业级二维码生成方案:基于Vue-QR的后台管理系统深度整合 在数字化营销与产品管理的浪潮中,二维码已成为连接线上线下场景的关键纽带。对于企业级后台管理系统而言,快速生成带有品牌标识的定制化二维码,不仅能提升用户信任度&…...