【2024】Math-Shepherd:无需人工注释即可逐步验证和强化法学硕士。
搜索词:
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
P Wang, L Li, Z Shao, R Xu, D Dai, Y Li, D Chen, Y Wu, Z Sui
Proceedings of the 62nd Annual Meeting of the Association for …, 2024•aclanthology.org
摘要
本文提出了一种创新的面向过程的数学过程奖励模型 Math-shepherd,该模型为数学问题解决的每个步骤分配奖励分数。Math-shepherd 的训练是使用自动构建的过程监督数据实现的,打破了现有工作中严重依赖人工注释的瓶颈。我们在两种场景中探索了 Math-shepherd 的有效性:1)验证: Math-shepherd 用于对大型语言模型 (LLM) 生成的多个输出进行重新排序;2)强化学习 (RL):Math-shepherd 用于强化 LLM。借助 Math-shepherd,一系列开源 LLM 表现出色。例如,使用 Math-shepherd 进行过程强化学习显著增强了 Mistral-7B(在 GSM8K 上从 77.9% → 84.1% 提高,在 MATH 上从 28.6% → 33.0%)。经过 Math-shepherd 的验证,在两个基准测试中的准确率可以进一步提高到 89.1% 和 43.5%。我们相信,自动过程监督对于 LLM 的未来发展具有巨大的潜力。
1.总结
该论文的主要内容是提出了一种名为 MATH - SHEPHERD 的面向过程的数学过程奖励模型,用于评估和改进大语言模型(LLMs)在数学推理任务中的表现,具体内容包括:
- 研究背景:
- 大语言模型在复杂的多步数学推理问题中面临挑战,验证方法可提高 LLMs 输出的准确性和一致性,其中过程奖励模型(PRM)能提供精确反馈,但训练数据获取成本高。
- 相关工作:
- 改善和引发 LLMs 数学推理能力的方法包括预训练、微调、提示等。
- 数学推理验证的两类模型为结果奖励模型(ORM)和过程奖励模型(PRM),PRM 优于 ORM,但依赖昂贵的人工标注数据集。
- 【
数学推理验证的两类主要模型为结果奖励模型(ORM)和过程奖励模型(PRM),它们的定义和特点如下:
- 结果奖励模型(ORM):
- 定义:给定一个数学问题和其解决方案,ORM 会根据整个生成序列分配一个实数值来表明该解决方案是否正确。
- 训练方式:通常使用交叉熵损失进行训练,即通过采样一些候选解决方案,并根据其答案是否正确来自动构建训练集。虽然可能会将一些通过错误推理得到正确答案的假阳性解决方案误分级,但对训练一个好的 ORM 仍然有效。
- 过程奖励模型(PRM):
- 定义:PRM 会对解决方案的每一个推理步骤进行评分,它能够更精确地反馈问题,通过识别错误出现的具体位置,为强化学习和自动校正提供有价值的信号。
- 训练方式:通常使用类似于以下的损失函数进行训练:,其中是第步推理的标准答案,是 PRM 分配给第步的 sigmoid 分数,是推理步骤的数量。此外,PRM 的训练也可以被看作是一个三分类问题,但本文将其视为二分类。
-
这两种模型在数学推理验证中具有不同的作用和优势。ORM 相对简单,根据整体结果进行判断;而 PRM 能够提供更详细的反馈,更符合人类评估推理问题的方式,当推理过程中的任何步骤出现错误时,最终结果更有可能不正确。然而,PRM 的训练数据收集较为困难,以往依赖人工标注,成本高昂,这限制了其发展和应用。
】
- 【
- 方法:
- 任务表述:在验证和强化学习场景中评估奖励模型的性能。
- 奖励模型:ORM 根据整个生成序列分配置信分数,PRM 为推理步骤分配分数。
- 自动过程标注:定义推理步骤的质量为推断正确答案的潜力,通过 “完成器” 和估计来自动构建 PRM 的训练数据集。
- 排名验证:使用 PRM 的最小分数表示解决方案的最终分数,并探索与自一致性的结合。
- 强化学习:采用逐步的近端策略优化(PPO)来训练 LLMs。
- 实验:
- 数据集:使用 GSM8K 和 MATH 两个数学推理数据集进行实验。
- 参数设置:基于一系列大语言模型进行实验,设置了训练参数和超参数。
- 基线和指标:在验证场景中与自一致性和 ORM 进行比较,在强化学习场景中与 ORM 和 RFT 进行比较,使用准确率作为评估指标。
- 主要结果:
- MATH - SHEPHERD 作为验证器优于自一致性和 ORM,在更具挑战性的数据集上优势更明显。
- MATH - SHEPHERD 作为奖励模型在强化学习中能显著提高模型性能。
- RL 和验证相结合具有互补性,能进一步提高模型性能。
- 分析:
- 自动过程标注质量较高,LLM 完成器的能力对数据质量重要,更强的基础模型和优质训练数据能提升标注质量。
- PRM 数据效率更高,具有更高的潜力上限。
- PRM 在分布外评估中表现优于 ORM,奖励模型能推广到其他领域。
- 结论:
- MATH - SHEPHERD 使用自动构建的过程监督数据进行训练,无需人工标注,实验证明了该方法在验证和强化学习场景中的有效性。
- 局限性:
- 完成过程的计算成本高,但仍低于人工标注成本,未来可通过高效推理技术缓解。
- 自动过程标注存在噪声,PRM 与人类标注的 PRM800K 数据集存在差距,未来可进行更全面的比较并结合人工标注。
2.分析
解决的问题:
解决大型语言模型(LLMs)在复杂多步数学推理问题中表现不佳的问题,通过引入一种新的处理器导向的数学过程奖励模型 MATH - SHEPHERD,来提高 LLMs 在数学推理任务中的性能。
面临的挑战:
- 训练过程奖励模型(PRM)需要高质量的标注数据,但收集这些数据通常依赖人工标注,成本高昂,阻碍了 PRM 的发展和实际应用。
- 现有 LLMs 在处理复杂数学推理问题时存在不足,需要有效的方法来改进和验证其推理结果。
创新点:
- 自动过程标注框架:提出了一个自动过程标注框架,灵感来自蒙特卡洛树搜索,通过定义推理步骤的质量为其推导正确答案的潜力,利用微调的 LLM 解码从某一步开始的多个后续推理路径,并根据解码的最终答案与标准答案的匹配情况自动收集逐步的监督信息,从而无需人工标注来构建 PRM 的训练数据。
- 验证和强化学习的应用:在验证场景中,MATH - SHEPHERD 用于对 LLMs 生成的多个输出进行重新排序;在强化学习场景中,MATH - SHEPHERD 用于通过逐步的 PPO 来强化 LLMs。
- 实验结果的先进性:通过在广泛使用的数学基准测试集(GSM8K 和 MATH)上的实验,以及对一系列从 7B 到 70B 的 LLMs 的测试,证明了 MATH - SHEPHERD 的有效性,并且在某些情况下取得了超越现有开源模型的性能结果。
方法:该论文提出的方法主要包括以下几个部分:
- 任务定义:
- 验证:给定一个问题,从生成器中采样 N 个候选解决方案,使用奖励模型对这些候选进行评分,选择最高分的解决方案作为最终答案,以提高 LLMs 解决数学问题的成功率。
- 强化学习:使用自动构建的 PRM 通过逐步的 RL 来监督 LLMs,评估 LLMs 贪婪解码输出的准确性,以训练出更高性能的 LLMs。
- 奖励模型:
- ORM:给定数学问题和其解决方案,ORM 会分配一个实数值来表明是否正确,通常使用交叉熵损失进行训练,通过自动构建训练集的方式为问题采样一些候选解决方案,并根据答案正确性进行标注。
- PRM:PRM 会对的每一个推理步骤分配一个分数,通常使用类似的损失函数进行训练,其中和分别是第步推理的标准答案和 PRM 分配的分数,是推理步骤的数量。
- 自动过程标注:
- 定义:受蒙特卡洛树搜索启发,将推理步骤的质量定义为其推导正确答案的潜力,这源于推理过程的主要目标是帮助人类或智能体得出合理的结果。
- 解决方案:
- Completion:使用 “completer” 从给定推理步骤完成后续个推理过程,并根据所有解码答案的正确性来估计该步骤的潜力。【正确的越多,越有潜力、推理质量越高】
- Estimation:使用硬估计(HE)和软估计(SE)两种方法来估计步骤的质量。HE 假设只要推理步骤能得出正确答案,则该步骤是好的;SE 则将步骤的质量视为得出正确答案的频率。
-
在该论文中,硬估计(Hard Estimation,HE)和软估计(Soft Estimation,SE)是用于估计推理步骤质量的两种方法,具体如下:
-
这两种估计方法用于在自动过程标注中为推理步骤分配质量标签,从而为训练过程奖励模型(PRM)提供数据。
-
【咱们用一个学生做数学题的例子来解释论文中的硬估计(HE)和软估计(SE)。
硬估计(HE):
假设一个学生在做一道复杂的数学题,解题过程有很多步骤。在硬估计中,如果一个步骤能够直接导向正确答案,那么这个步骤就被认为是好的。
比如这道数学题是求一个图形的面积。学生先尝试了一种方法计算边长,这个计算边长的步骤如果最终能让他得出正确的图形面积答案,那这个计算边长的步骤就被硬估计认为是好的,标记为 1;如果这个步骤不能让他得出正确答案,那就认为这个步骤不好,标记为 0。
软估计(SE):
还是这个学生做数学题。软估计不是那么绝对地判断一个步骤的好坏。它看的是一个步骤在多次尝试中导向正确答案的频率。
比如说这个学生用同样的方法做了很多道类似的求图形面积的题目。他每次都经过计算边长这个步骤,然后看在所有这些题目中,通过这个计算边长的步骤最终正确得出图形面积答案的次数占总次数的比例。如果做了 10 道题,有 6 道题通过这个计算边长的步骤最后得出了正确答案,那么这个计算边长步骤的软估计质量就是 0.6。】
-
【也可以用一个简单的医学诊断的例子来解释软估计(SE)和硬估计(HE)。可以理解为充要条件与充分不必要条件,但是这个充分不必要的程度,可以用一个概率来衡量。
硬估计(HE):
想象你是一位医生,正在诊断一个病人是否患有某种严重的疾病。在硬估计中,判断标准非常明确。如果某个检查结果或者症状能够确凿地表明病人患有这种疾病,我们就说这个检查结果或者症状是 “好的”(对应于推理步骤是好的)。
例如,对于某种特定的疾病,只有当血液检测中出现了某个特定的生物标志物时,我们才确定病人患有这个疾病。如果这个生物标志物出现了,我们就认为当前考虑的这个血液检测这个步骤是好的,标记为 1;如果没有这个生物标志物,我们就认为这个步骤不好,标记为 0。
软估计(SE):
还是这位医生在诊断病人。软估计就不像硬估计那么绝对。它考虑的是一个步骤得出正确诊断的频率。
比如,我们有很多个病人,都做了同样的一项身体检查。我们统计一下,在这些病人中,这个身体检查结果正确地指向了我们关注的疾病的次数。如果有一半的病人通过这个检查结果正确地被诊断出患有疾病,那么这个检查步骤的软估计质量就是 0.5。
总的来说,硬估计是一种非黑即白的判断方式,而软估计则更像是一种基于概率或者频率的相对判断方式。
】
-
- 排名验证:
- 使用 PRM 对解决方案进行排名时,使用所有步骤中的最低分数来代表该解决方案的最终分数。
- 探索了自一致性和奖励模型的组合,根据最终答案对解决方案进行分组并计算每组的总分,最终预测答案基于候选解决方案的总分和奖励模型的评分。
- 强化学习:
- 采用逐步的近端策略优化(PPO)进行强化学习,与传统的 ORM 在响应结束时提供奖励不同,PRM 在每个推理步骤结束时提供奖励。
- 【近端策略优化(Proximal Policy Optimization,PPO)是一种用于优化策略的强化学习算法。
-
一、基本原理
在强化学习中,智能体通过与环境交互来学习最优策略,以最大化累积奖励。PPO 的核心思想是在每次更新策略时,尽量使新策略与旧策略之间的差异保持在一个较小的范围内,从而实现更稳定的学习过程。
具体来说,PPO 通过优化一个目标函数来更新策略。这个目标函数通常由两部分组成:策略的预期回报和一个约束项,用于限制新策略与旧策略之间的差异。
二、算法流程
- 初始化策略网络和价值网络。
- 智能体与环境交互,收集经验数据(状态、动作、奖励等)。
- 使用收集到的经验数据计算策略的优势函数,即当前动作相对于平均动作的优势。
- 根据优势函数和经验数据,计算目标函数。
- 使用优化算法(如随机梯度下降)更新策略网络和价值网络的参数,以最大化目标函数。
- 重复步骤 2 至 5,直到满足停止条件。
-
三、优势
- 稳定性高:通过限制策略更新的幅度,PPO 可以避免策略在更新过程中出现剧烈波动,从而提高学习的稳定性。
- 样本效率高:PPO 能够有效地利用收集到的经验数据,减少对大量样本的需求,从而提高学习效率。
- 通用性强:PPO 可以应用于各种不同的强化学习任务,包括连续动作空间和离散动作空间的问题。
-
四、应用场景
- 机器人控制:可以用于训练机器人执行各种任务,如行走、抓取物体等。
- 游戏开发:在游戏中训练智能体以实现更高的游戏水平。
- 自动驾驶:优化自动驾驶汽车的决策策略,提高行驶安全性和效率。
- 金融交易:学习最优的交易策略,以实现最大化收益。】
-
- 【近端策略优化(Proximal Policy Optimization,PPO)是一种用于优化策略的强化学习算法。
- 采用逐步的近端策略优化(PPO)进行强化学习,与传统的 ORM 在响应结束时提供奖励不同,PRM 在每个推理步骤结束时提供奖励。

通过以上方法,该论文旨在解决训练 PRM 数据收集困难的问题,提高 LLMs 在数学推理任务中的性能。
图 1:以前的自动结果注释和我们的自动过程注释的比较。 (a):自动结果注释根据答案的正确性为整个解决方案 S 分配标签; (b) 自动过程注释使用“完成器”来完成中间步骤(该图中的 s1)的 N 个推理过程(该图中的 N=3),随后使用硬估计(HE)和软估计(SE)根据所有解码的答案来注释此步骤。

实验过程:该论文的实验过程主要包括以下步骤:
- 数据集选择:
- 使用两个广泛使用的数学推理数据集 GSM8K 和 MATH。
- 对于 GSM8K 数据集,在验证和强化学习场景中均使用整个测试集。
- 对于 MATH 数据集,在验证场景中由于计算成本原因,使用子集 MATH500(与 Lightman 等人在 2023 年测试集中使用的相同),该子集包含 500 个代表性问题,且子集评估与全量评估产生相似的结果。
- 为了评估不同的验证方法,为每个测试问题生成 256 个候选解决方案,并报告 3 组采样结果的平均准确率。
- 在强化学习场景中,使用整个测试集来评估模型性能。
- 使用 MetaMATH 来训练 LLMs。
-
重要组件。
-
生成器:
- 生成器的作用是为数学问题生成候选解决方案。在实验中,通过从生成器中采样多个候选解决方案,来为后续的验证和强化学习提供数据基础。
- 例如,在训练 ORM 和 PRM 的训练数据集中,会从生成器中为每个问题采样一定数量的候选解决方案,然后对这些解决方案进行标注和评估。
-
完成器:
- 完成器的主要功能是用于自动过程标注。具体来说,给定一个数学问题的中间推理步骤,完成器会从这个步骤开始解码多个后续的推理过程。
- 然后,根据这些解码的最终答案与标准答案的匹配情况,使用硬估计(HE)和软估计(SE)来标注这个中间步骤的质量。
- 例如,为了量化和估计一个给定推理步骤推导出正确答案的潜力,会使用 “完成器” 来从该步骤完成 N 个后续推理过程,并根据所有解码答案的正确性来估计该步骤的潜力。
-
奖励模型:
一、数据准备
- 利用生成器和完成器自动构建训练数据集:
- 生成器为数学问题生成候选解决方案。从生成器中为每个问题采样一定数量(如 15 个)的解决方案。
- 完成器从给定推理步骤开始解码多个后续推理过程。使用完成器从每个推理步骤完成后续多个推理过程,并根据所有解码答案与标准答案的匹配情况,通过硬估计(HE)和软估计(SE)为过程奖励模型(PRM)自动构建训练数据集。
- 二、模型训练
-
对于结果奖励模型(ORM):
- ORM 通常使用交叉熵损失进行训练。根据整个生成序列分配置信分数,即给定数学问题和其解决方案,ORM 会分配一个实数值来表明该解决方案是否正确。
- 例如,公式为,其中是解决方案的黄金答案(如果正确,,否则),是 ORM 分配给的 sigmoid 分数。
-
对于过程奖励模型(PRM):
- PRM 对解决方案的每一个推理步骤进行评分。使用类似于的损失函数进行训练,其中是第步推理的标准答案,是 PRM 分配给第步的 sigmoid 分数,是推理步骤的数量。
- 在训练 PRM 时,为了方便,可以使用硬估计版本训练,通过选择两个特殊标记来表示 “有潜力” 和 “无潜力” 标签,从而无需任何特定的模型调整。可以使用一个 epoch 进行训练,学习率设置为 1e - 6。
-
三、模型选择与调整
-
选择基础模型进行训练:
- 对于验证场景,选择较大规模的语言模型作为基础模型来训练奖励模型。例如,选择 LLaMA2 - 70B 和 LLemma34B 作为 GSM8K 和 MATH 的基础模型来训练奖励模型。
- 对于强化学习场景,选择合适的模型作为基础模型来训练奖励模型,并用于监督生成器。比如选择 Mistral - 7B 作为基础模型来训练奖励模型,并用于监督 LLama2 - 7B 和 Mistral - 7B 生成器。
-
参数调整与优化:
- 根据不同的模型和任务,调整学习率、Kullback - Leibler 系数等参数。例如,在强化学习中,LLaMA2 - 7B 和 Mistral - 7B 的学习率分别为 4e - 7 和 1e - 7,Kullback - Leibler 系数设置为 0.04,使用余弦学习率调度器,最小学习率设置为 1e - 8。
-
通过以上步骤,可以获得适用于数学推理任务的奖励模型,用于验证和强化学习场景,以提高大型语言模型在数学推理问题中的性能。
- 利用生成器和完成器自动构建训练数据集:
-
- 参数设置:
- 基于一系列大型语言模型进行实验,包括 LLaMA2 7B/13B/70B、LLemma 7B/34B、Mistral - 7B 和 DeepSeek - 67B。
- 在 MetaMATH 上训练生成器和完成器 3 个 epoch。
- Mistral - 7B 的学习率为 5e - 6,其他模型的学习率分别为:7B/13B 模型为 2e - 5,34B 模型为 1e - 5,67B/70B 模型为 6e - 6。
- 为构建 ORM 和 PRM 的训练数据集,在 GSM8K 和 MATH 训练集上训练 7B 和 13B 模型 1 个 epoch,然后从每个模型中为每个问题采样 15 个解决方案,消除重复解决方案并对每个步骤进行标注。
- 使用 LLemma - 7B 作为完成器,解码数 N = 8,从而为 GSM8K 获得约 170k 个解决方案,为 MATH 获得约 270k 个解决方案。
- 对于验证,选择 LLaMA2 - 70B 和 LLemma34B 作为 GSM8K 和 MATH 的基础模型来训练奖励模型。
- 对于强化学习,选择 Mistral - 7B 作为基础模型来训练奖励模型,并用于监督 LLama2 - 7B 和 Mistral - 7B 生成器。
- 奖励模型训练 1 个 epoch,学习率为 1e - 6,使用硬估计版本训练 PRM(便于利用标准语言建模管道,通过选择两个特殊标记来表示 “有潜力” 和 “无潜力” 标签,无需特定模型调整)。
- 在强化学习中,LLaMA2 - 7B 和 Mistral - 7B 的学习率分别为 4e - 7 和 1e - 7,Kullback - Leibler 系数设置为 0.04,使用余弦学习率调度器,最小学习率设置为 1e - 8。
- 使用 HAI - LLM 来训练所有模型,最大序列长度为 512。
- 基线和指标设置:
- 在验证场景中,将奖励模型的性能与自我一致性(多数投票)和结果奖励模型进行比较,使用最佳 N 解决方案的准确率作为评估指标,对于 PRM,使用所有步骤中的最低分数来代表解决方案的最终分数。
- 在强化场景中,将逐步监督与 ORM 提供的结果监督以及拒绝采样微调(RFT)进行比较,为 RFT 在 MetaMATH 中为每个问题采样 8 个响应,使用 LLMs 贪婪解码输出的准确率来评估性能。
- 指标:这篇论文主要用到了以下指标:
- 验证场景中的指标:
- 最佳 N 解决方案的准确率:在验证场景中,给定测试集中的一个问题,从生成器中采样 N 个候选解决方案,使用奖励模型对这些候选进行评分,选择最高分的解决方案作为最终答案。最佳 N 解决方案的准确率即指在这种选择方式下,最终答案正确的比例。该指标用于评估奖励模型在验证场景中选择正确答案的能力,从而衡量模型在提高 LLMs 解决数学问题成功率方面的表现。

- 验证场景中的指标:
-
-
-
- PRM 的最终分数表示:对于 PRM,使用所有步骤中的最低分数来代表一个解决方案的最终分数。这是因为 PRM 评估的是推理过程的每一步,如果任何步骤出现错误,都可能影响最终结果的正确性,所以使用最低分数可以更严格地评估解决方案的质量。
- 强化学习场景中的指标:
- LLMs 贪婪解码输出的准确率:在强化学习场景中,使用自动构建的 PRM 通过逐步的 RL 来监督 LLMs。LLMs 贪婪解码输出的准确率即指 LLMs 在贪婪解码(即每次选择当前认为最优的动作)情况下输出的结果正确的比例。该指标用于评估强化学习过程中 LLMs 的性能提升情况,以及 PRM 作为奖励模型在训练更高性能 LLMs 方面的有效性。
-
- 具体实验内容:
- MATH - SHEPHERD 作为验证器的实验:比较 MATH - SHEPHERD 与自我一致性和 ORM 在 GSM8K 和 MATH 数据集上的性能,观察不同模型在不同验证策略下的准确率表现。
- MATH - SHEPHERD 作为强化学习奖励模型的实验:评估带有过程监督的强化学习对两个监督微调模型性能的提升效果,对比 RFT 和 Outcome RL 与 Process RL 的性能差异。
- MATH - SHEPHERD 作为奖励模型和验证器结合的实验:分析 RL 和验证结合时的互补性,比较不同模型在不同组合策略下的性能表现。
- 自动过程标注质量的评估实验:通过手动标注 160 个步骤并使用不同完成器进行推断来探索自动 PRM 数据集的质量,观察硬估计(HE)和软估计(SE)的准确性以及与人类标注的差异,还研究了不同完成器和训练数据对数据质量的影响。
- 数据数量影响的分析实验:利用不同数量的训练数据深入分析 PRM 和 ORM 的性能,观察它们在数据效率和潜在上限方面的表现。
- 分布外性能的评估实验:在匈牙利国家期末考试上进行分布外评估,比较 LLemma - 34B - ORM 和 LLemma - 34B - PRM 与原始 LLemma - 34B 的性能,展示奖励模型在其他领域的泛化能力和 PRM 的优越性。
实验结论:
- MATH - SHEPHERD 作为验证器:
- 在 GSM8K 和 MATH 两个数据集上,MATH - SHEPHERD 始终优于自我一致性和 ORM,例如 DeepSeek - 67B 在 GSM8K 和 MATH 上的准确率分别达到 93.3% 和 48.1%。
- 与 GSM8K 相比,PRM 在更具挑战性的 MATH 数据集上比 ORM 具有更大的优势,这与之前的研究结果一致。
- 在 GSM8K 中,当与自我一致性结合时,性能会下降,而在 MATH 中,性能会提高。这表明如果奖励模型对于某个任务足够强大,将其与自我一致性结合可能会损害验证性能。
- MATH - SHEPHERD 作为强化学习的奖励模型:
- 带有过程监督的强化学习显著提高了两个监督微调模型的性能,例如 Mistral7B 在 GSM8K 和 MATH 数据集上的准确率分别达到 84.1% 和 33.0%。
- RFT 只略微提高了模型性能,可能是因为 MetaMATH 已经进行了一些类似 RFT 的数据增强策略。
- 结果强化学习(Outcome RL)也能增强模型性能,但不如 MATH - SHEPHERD 与过程强化学习(Process RL)结合的效果好,展示了该方法的潜力。
- MATH - SHEPHERD 作为奖励模型和验证器的结合:
- RL 和验证是互补的,例如在 MATH 中,使用过程强化学习的 Mistral7B 比使用自我一致性作为验证器的监督微调 Mistral - 7B 准确率高出 7.2%,性能差距甚至比贪婪解码结果的差距更大,达到 4.4%。
- 经过强化学习后,仅使用奖励模型的常规验证方法不如自我一致性,可能是因为初始奖励模型不足以监督强化学习后的模型。这些结果展示了迭代强化学习的潜力。
- 自动过程标注的质量:
- 使用 LLaMA2 - 70B 作为完成器,当 N 等于 4 时,硬估计(HE)的准确率达到 86%,表明自动构建的数据集具有较高质量,但随着 N 的增加,构建数据集的准确性会下降,可能是因为 N 较大时会导致更多的假阳性。
- 软估计(SE)的标签与人类标注的分布相比,随着 N 的增加,逐渐接近标准分布,但训练出的验证器在使用 SE 或 HE 训练时性能没有显著差异,可能是因为 HE 已经提供了较高质量的标注。
- 还研究了其他自动过程标注方法,如使用自然语言推理(NLI)模型和字符串匹配规则的方法,结果表明本文的标注策略优于这些方法。
- LLM 完成器的能力对数据质量有重要影响,更大的完成器能生成更高质量的数据集,高质量的训练集也能使模型作为完成器更有效。
- 数据数量的影响:
- PRM 在数据效率方面表现更优,当使用较小的训练数据集(如 10k 实例)时,PRM 比 ORM 的准确率高出约 4%,并且 PRM 似乎具有更高的潜在上限,这突出了 PRM 在验证方面的有效性。
- 分布外性能:
- 在匈牙利国家期末考试的分布外评估中,LLemma - 34B - ORM 和 LLemma - 34B - PRM 都优于原始的 LLemma - 34B,表明奖励模型可以推广到其他领域,并且 PRM 比 ORM 高出 9 分,进一步展示了 PRM 的优越性。
综上所述,该论文提出的 MATH - SHEPHERD 在验证和强化学习场景中都表现出了良好的性能,自动过程标注框架能够有效地构建高质量的训练数据集,为提高 LLMs 的数学推理能力提供了一种有效的方法。
3.思考
1.这种软硬分数的方法可以用于医疗、推理等类似领域
2.基于过程的评分能让模型偏好学习获得更好的效果,但是这个方法很看完成器完成推理的能力与偏好模型打分的能力。这两个能力能体现,看标注数据的结果是否好批判,例如这里是标准的一个数字,每一步都可以计算一个数字,就会更容易确定损失进行训练,比较结果是否正确。而医疗或其它领域需要思考有没有更好的方法,衡量输出结果的正确性,包含整体正确性,和推理每一步的正确性。
相关文章:
【2024】Math-Shepherd:无需人工注释即可逐步验证和强化法学硕士。
搜索词: Math-shepherd: Verify and reinforce llms step-by-step without human annotations P Wang, L Li, Z Shao, R Xu, D Dai, Y Li, D Chen, Y Wu, Z Sui Proceedings of the 62nd Annual Meeting of the Association for …, 2024•aclanthology.org 摘要…...
[苍穹外卖]-08微信支付详解
地址簿管理 分析需求: 查询地址列表/新增地址/修改地址/删除地址/设置默认地址/查询默认地址 接口设计 新增地址接口 查询用户所有的地址接口 查询默认地址接口 根据id修改地址接口 根据id删除地址接口 根据id查询地址接口 设置默认地址接口 数据库设计: 收货地址簿(address_…...

教你五句在酒桌上和领导说的话语
1、今天很荣幸能和领导一起吃饭,我敬领导一杯希望领导工作顺利身体健康!生意兴隆!2、我敬领导一杯感谢领导平时对我的关照先干为敬!3、谢谢领导这次给我这个机会我一定会好好把握的请领导放心我一定会好好工作绝对不辜负领导对我的期望4.领导能来这里我们感到非常骄…...

景联文科技:专业图像采集服务,助力智能图像分析
景联文科技是专业数据服务公司,致力于为人工智能企业提供从数据采集、清洗到标注的全流程解决方案。协助客户解决AI开发过程中数据处理环节的关键问题,助力企业实现智能化转型。 1.多样化的图像采集服务 景联文科技提供多样化的图像采集服务,…...

QT QTcpSocket作为客户端
前言 QTcpSocket是Qt提供的关于TCP网络通信的类。QTcpSocket是一个异步的类,能够非阻塞式发送和接收数据。QTcpSocket内部封装了网络通信相关细节,对外提供便利的接口去帮助开发人员实现简历连接、断开连接、数据收发。 主要内容 基本使用方式 项目文…...

【系统架构设计师-2023年】综合知识-答案及详解
更多内容请见: 备考系统架构设计师-核心总结索引 文章目录 【第1~2题】【第3题】【第4~5题】【第6题】【第7题】【第8题】【第9题】【第10~11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第21~22题】【第23题】【第24~…...

树莓派3B点灯(1)-- 四种方法
先做个简单一丢丢的吧。。。正好最近工作也要用这个。这次直接给够四种方法,给好给满。分别是Python点,用户空间配置GPIO点,设备树配置内核Leds驱动点,自己写驱动点。 用的板子是树莓派3B,GPIO 26口,蓝光L…...

Android解析XML格式数据
文章目录 Android解析XML格式数据搭建Web服务器Pull解析方式SAX解析方式 Android解析XML格式数据 通常情况下,每个需要访问网络的应用程序都会有一个自己的服务器,我们可以向服务器提交数据,也可以从服务器上获取数据。不过这个时候就出现了…...

数学建模笔记—— 灰色关联分析[GRA]
数学建模笔记—— 灰色关联分析[GRA] 灰色关联分析(GRA)1. 相关概念1.1 灰色系统1.2 什么是关联分析?1.3 灰色关联分析 2. 关联分析步骤3. 典型例题3.1 关联分析例题3.2 灰色关联综合评价 4. python代码实现4.1 关联分析4.2 灰色关联综合评价 灰色关联分析(GRA) 1.…...

ICM20948 DMP代码详解(13)
接前一篇文章:ICM20948 DMP代码详解(12) 上一回完成了对inv_icm20948_set_chip_to_body_axis_quaternion函数第2步即inv_rotation_to_quaternion函数的解析。回到inv_icm20948_set_chip_to_body_axis_quaternion中来,继续往下进行…...

【论软件需求获取方法及其应用】
摘要 2023 年 3 月,我所在的公司承接了某油企智慧加油站平台的建设工作。该项目旨在帮助加油站提升运营效率、降低运营成本和提高销售额。我在该项目中担任系统架构设计师,负责整个项目的架构设计工作。 本文以该项目为例,详细论述软件需求获…...

使用ESP8266和OLED屏幕实现一个小型电脑性能监控
前言 最近大扫除,发现自己还有几个ESP8266MCU和一个0.96寸的oled小屏幕。又想起最近一直想要买一个屏幕作为性能监控,随机开始自己diy。 硬件: ESP8266 MUColed小屏幕杜邦线可以传输数据的数据线 环境 Windows系统Qt6Arduino Arduino 库…...
Nexpose v6.6.266 for Linux Windows - 漏洞扫描
Nexpose v6.6.266 for Linux & Windows - 漏洞扫描 Rapid7 Vulnerability Management, release Aug 21, 2024 请访问原文链接:https://sysin.org/blog/nexpose-6/,查看最新版。原创作品,转载请保留出处。 作者主页:sysin.o…...

ess6新特性
1、let、const 块级作用域声明变量和常量 2、箭头函数 不能构建函数 不能new 没.prototype属性 没有this指向 this指向是根据上下文的 往上层查找 没有arguments(参数) 3、模板字符串 ${} 字符串中嵌入表达式 4、解构赋值 5、Promise 处理异步操作的标准机制 6、for of 遍历…...

C语言蓝桥杯:语言基础
竞赛常用库函数 最值查询 min_element和max_element在vector(迭代器的使用) nth_element函数的使用 例题lanqiao OJ 497成绩分析 第一种用min_element和max_element函数的写法 第二种用min和max的写法 二分查找 二分查找只能对数组操作 binary_search函数,用于查找…...

axure之变量
一、设置我们的第一个变量 1、点击axure上方设置一个全局变量a 3 2、加入按钮、文本框元件点击按钮文档框展示变量值。 交互选择【单击时】【设置文本】再点击函数。 点击插入变量和函数直接选择刚刚定义的全局变量,也可以直接手动写入函数(注意写入格式。) 这…...

vue缓存用法
Store 临时缓存 特点:需要定义,有初始值、响应式、全局使用、刷新重置 Pinia官方文档 https://pinia.vuejs.org 创建 store 缓存 示例代码 import {defineStore} from pinia import {store} from //storeexport const useMyStore defineStore({// 定义…...

栈入门,括号匹配问题
利用栈这道题应该很轻松可以解决,下面给出常用的代码: public static boolean isValid(String s) {// 创建一个栈来保存左括号Stack<Character> stack new Stack<>();// 遍历字符串中的每个字符for (char c : s.toCharArray()) {// 如果是…...

Vue入门学习笔记-表单
可以使用v-model 指令在表单控件元素上创建双向数据绑定。 引言: Vue采用了MVVM(Model-View-ViewModel)架构模式,通过指令可以快速实现数据和视图的双向绑定 修改视图层时,模型层也会改变;修改模型层&#…...
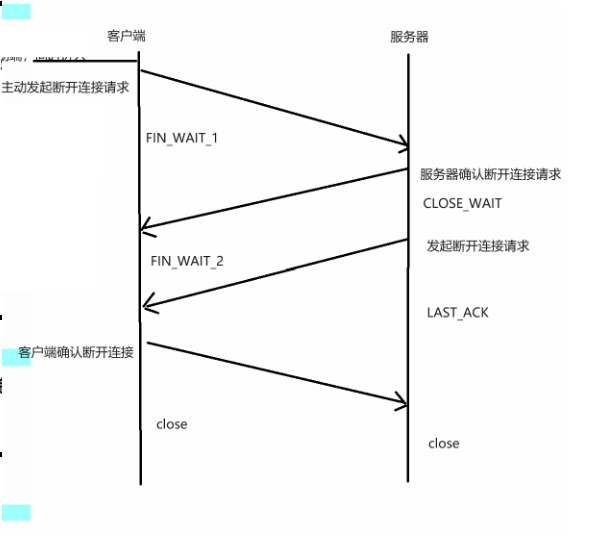
TCP通信三次握手、四次挥手
目录 前言 一、三次握手 TCP三次握手的详细过程 二、四次挥手 四次挥手的详细过程 前言 前面我说到了,UDP通信的实现,但我们经常说UDP通信不可靠,是因为他只会接收和发送,并不会去验证对方收到没有,那么我们说TCP通…...

Python窗口美化终极指南:5分钟打造Windows 11风格界面
Python窗口美化终极指南:5分钟打造Windows 11风格界面 【免费下载链接】py-window-styles Customize your python UI window with awesome pre-built windows 11 themes. 项目地址: https://gitcode.com/gh_mirrors/py/py-window-styles 还在为Python应用程序…...
)
游戏开发团队必须立即升级的语音合成栈:Llama-3-TTS开源模型实测对比(RTX 4090 vs. Snapdragon 8 Gen3)
更多请点击: https://codechina.net 第一章:AI语音合成在游戏开发中的应用 AI语音合成(Text-to-Speech, TTS)正深刻重塑游戏叙事、角色交互与本地化工作流。相比传统预录语音,实时TTS可动态生成符合上下文语境、情绪状…...

如何无限期使用Cursor AI编程助手:完整免费方案指南
如何无限期使用Cursor AI编程助手:完整免费方案指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...

FRED案例:矩形微透镜阵列
介绍小透镜阵列可应用在很多方面,其中包含光束均匀化。本文演示了一个用于在探测器上创建均匀的非相干照度的成像微透镜阵列的设计。输入光束具有高斯轮廓,半宽度等于微透镜阵列大小,并且显示了其功率轮廓被微透镜阵列消除掉。系统输出简单示…...

BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐
BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_…...
的简化与加速:从一次深夜调试说起)
【RT-DETR实战】060、解码器(Decoder)的简化与加速:从一次深夜调试说起
昨晚实验室的服务器又跑满了,监控告警提示显存溢出。跑到机房一看,又是RT-DETR在推理时卡在了解码器阶段。盯着屏幕上缓慢增长的处理进度条,我突然意识到——这个解码器,该动刀了。 问题出在哪 RT-DETR原本的解码器设计得很“学院派”,六层Transformer解码层堆叠,每层都…...

Moonlight安卓端自定义虚拟按键完全指南:从导入到高级配置
Moonlight安卓端自定义虚拟按键完全指南:从导入到高级配置 【免费下载链接】moonlight-android Moonlight安卓端 阿西西修改版 项目地址: https://gitcode.com/gh_mirrors/moo/moonlight-android 想要在手机或平板上畅玩PC游戏?🎮 Moo…...

终极魔兽争霸3兼容性修复指南:5分钟让经典游戏在现代电脑上重生
终极魔兽争霸3兼容性修复指南:5分钟让经典游戏在现代电脑上重生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代Win…...

3步掌握智慧树自动学习:解放双手的课程自动化神器
3步掌握智慧树自动学习:解放双手的课程自动化神器 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台繁琐的视频学习而烦恼吗?智慧…...

AI写论文必备指南!4款AI论文生成工具,让论文写作事半功倍!
写期刊论文是不是让你感到特别困难? 面对大量的文献、繁琐的格式要求,以及不断的修改,许多学术工作者都感到效率低下。别担心,接下来我们将介绍4款实测的AI论文写作工具,它们能够帮助你轻松生成论文。从文献检索、论文…...