通过打包 Flash Attention 来提升 Hugging Face 训练效率
简单概述
现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个最近的 PR以及新的DataCollatorWithFlattening。
-
最近的 PRhttps://github.com/huggingface/transformers/pull/31629
-
DataCollatorWithFlatteninghttps://hf.co/docs/transformers/main/en/main_classes/data_collator#transformers.DataCollatorWithFlattening
它可以在保持收敛质量的同时,将训练吞吐量提高多达 2 倍。继续阅读以了解详细信息!
简介
在训练期间,对小批量输入进行填充是一种常见的整理输入数据的方法。然而,由于无关的填充 token ,这引入了效率低下的问题。不进行填充而是打包示例,并使用 token 位置信息,是一种更高效的选择。然而,之前打包的实现并没有在使用 Flash Attention 2 时考虑示例边界,导致出现不希望的跨示例注意力,这降低了质量和收敛性。
Hugging Face Transformers 现在通过一项新功能解决了这个问题,该功能在打包时保持对边界的意识,同时引入了一个新的数据整理器 DataCollatorWithFlattening 。
通过选择 DataCollatorWithFlattening ,Hugging Face Trainer 的用户现在可以无缝地将序列连接成一个单一的张量,同时在 Flash Attention 2 计算过程中考虑到序列边界。这是通过 flash_attn_varlen_func 实现的,它计算每个小批量的累积序列长度 ( cu_seqlens )。同样的功能也适用于 TRL 库中的 Hugging Face SFTTrainer 用户,通过在调用数据整理器 DataCollatorForCompletionOnlyLM 时设置一个新的标志 padding_free=True 来实现。
吞吐量提高多达 2 倍
我们使用带有新 DataCollatorWithFlattening 的此功能在训练过程中看到了显著的处理吞吐量提升。下图显示了在训练期间测量的吞吐量,单位为 token /秒。在这个例子中,吞吐量是在 8 个 A100-80 GPU 上对一个 epoch 内的 20K 个随机选自两个不同指令调整数据集 (FLAN 和 OrcaMath) 的样本的平均值。
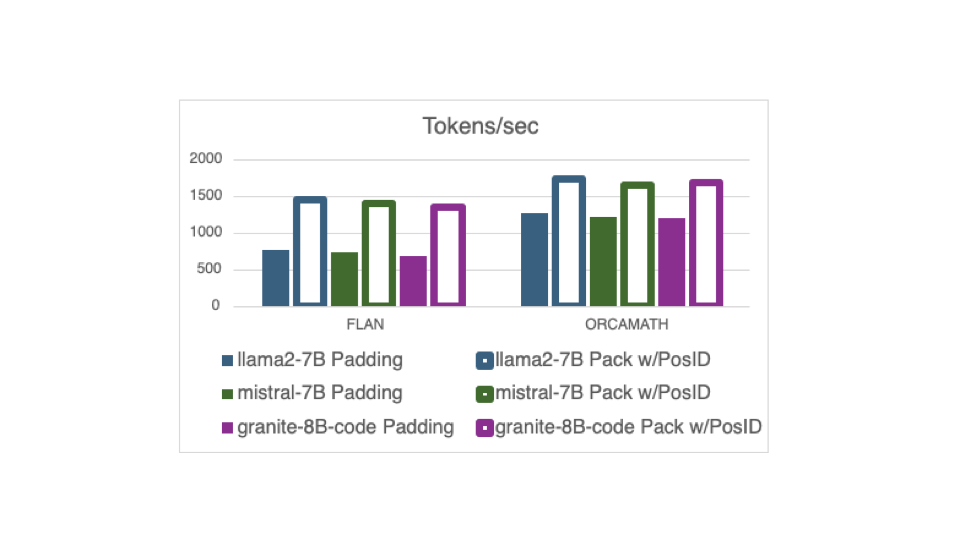
FLAN 数据集的平均序列较短,但序列长度差异较大,因此每个批次中的示例长度可能会有很大差异。这意味着填充的 FLAN 批次可能会因为未使用的填充 token 而产生显著的开销。在 FLAN 数据集上进行训练时,使用新的 DataCollatorWithFlattening 在提高吞吐量方面显示出显著的优势。我们在这里展示的模型中看到了 2 倍的吞吐量提升: llama2-7B、mistral-7B 和 granite-8B-code。
OrcaMath 数据集的示例较长,且示例长度差异较小。因此,从打包中获得的改进较低。我们的实验显示,在使用这种打包方式在 OrcaMath 数据集上训练时,这三个模型的吞吐量增加了 1.4 倍。
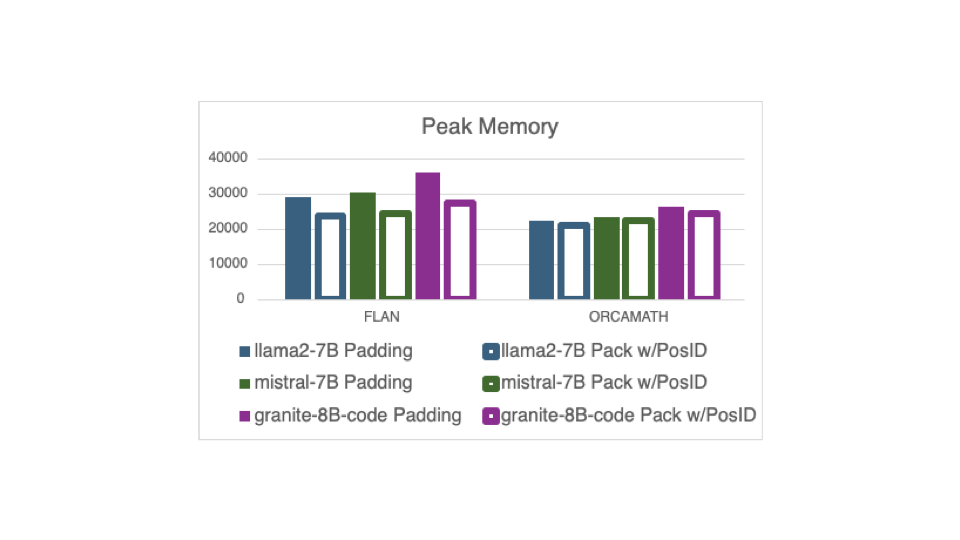
通过使用新的 DataCollatorWithFlattening 进行打包,内存使用也有所改善。下图显示了相同的三个模型在相同的两个数据集上训练时的峰值内存使用情况。在 FLAN 数据集上,峰值内存减少了 20%,这得益于打包的显著好处。
在 OrcaMath 数据集上,由于其示例长度更为均匀,峰值内存减少了 6%。
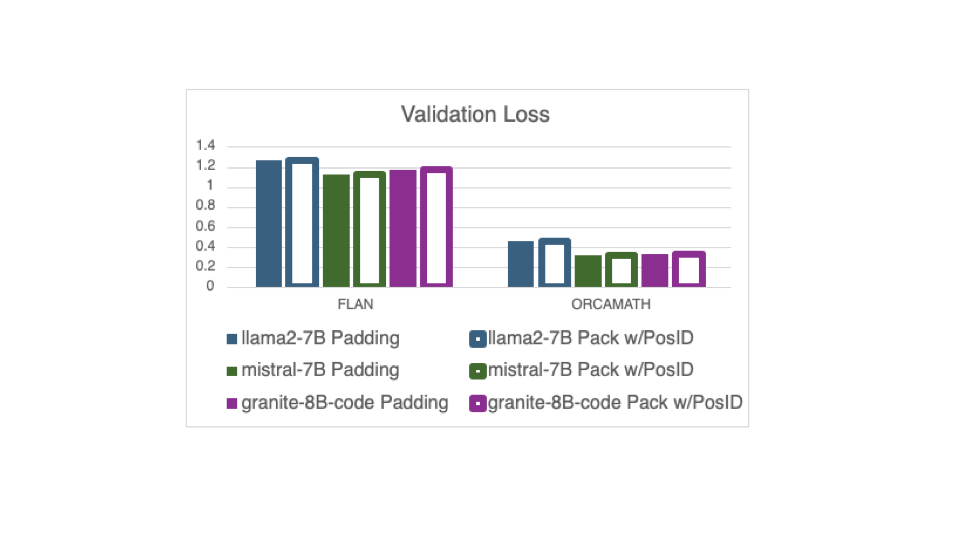
当打包示例减少了优化步骤的数量时,可能会损害训练的收敛性。然而,这个新功能保留了小批量,因此与使用填充示例相同的优化步骤数量。因此,对训练收敛性没有影响,正如我们在下一个图中看到的那样,该图显示了相同的三个模型在相同的两个数据集上训练时,无论是使用新的 DataCollatorWithFlattening 进行打包还是使用填充,模型的验证损失是相同的。
工作原理
考虑一个批处理数据,其中批量大小 (batchsize) 为 4,四个序列如下:

在将示例连接之后,无填充整理器返回每个示例的 input_ids 、 labels 和 position_ids 。因此,对于这批数据,整理器提供了以下内容:

所需的修改是轻量级的,仅限于向 Flash Attention 2 提供 position_ids 。
然而,这依赖于模型暴露 position_ids 。在撰写本文时,有 14 个模型暴露了它们,并且受该解决方案的支持。具体来说,Llama 2 和 3、Mistral、Mixtral、Granite、DBRX、Falcon、Gemma、OLMo、Phi 1、2 和 3、phi3、Qwen 2 和 2 MoE、StableLM 以及 StarCoder 2 都受该解决方案支持。
开始使用
利用 position_ids 进行打包的好处很容易实现。
如果你正在使用 Hugging Face Transformers 中的 Trainer ,只需两个步骤:
-
使用 Flash Attention 2 实例化模型
-
使用新的
DataCollatorWithFlattening
如果你正在使用 TRL 中的 Hugging Face SFTTrainer 配合 DataCollatorForCompletionOnlyLM ,那么所需的两个步骤是:
-
使用 Flash Attention 2 实例化模型
-
在调用
DataCollatorForCompletionOnlyLM时设置padding_free=True,如下所示:collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer, padding_free=True)
如何使用它
对于 Trainer 用户,下面的例子展示了如何使用这个新功能。
# 使用 DataCollatorWithFlattening 的示例import torch# 加载模型
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("instructlab/merlinite-7b-lab",torch_dtype=torch.bfloat16,attn_implementation="flash_attention_2"
)# 读取数据集
from datasets import load_dataset
train_dataset = load_dataset("json", data_files="path/to/my/dataset")["train"]# 使用 DataCollatorWithFlattening
from transformers import DataCollatorWithFlattening
data_collator = DataCollatorWithFlattening()# 训练
from transformers import TrainingArguments, Trainer
train_args = TrainingArguments(output_dir="/save/path")
trainer = Trainer(args=train_args,model=model,train_dataset=train_dataset,data_collator=data_collator
)
trainer.train()
对于 TRL 用户,下面的例子展示了如何在使用 SFTTrainer 时使用这个新功能。
# 使用 DataCollatorForCompletionOnlyLM SFTTrainer 示例import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer, DataCollatorForCompletionOnlyLMdataset = load_dataset("lucasmccabe-lmi/CodeAlpaca-20k", split="train")model = AutoModelForCausalLM.from_pretrained("instructlab/merlinite-7b-lab",torch_dtype=torch.bfloat16,attn_implementation="flash_attention_2")
tokenizer = AutoTokenizer.from_pretrained("instructlab/merlinite-7b-lab")
tokenizer.pad_token = tokenizer.eos_tokendef formatting_prompts_func(example):output_texts = []for i in range(len(example['instruction'])):text = f"### Question: {example['instruction'][i]}\n ### Answer: {example['output'][i]}"output_texts.append(text)return output_textsresponse_template = " ### Answer:"
response_template_ids = tokenizer.encode(response_template, add_special_tokens=False)[2:]
collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer, padding_free=True)trainer = SFTTrainer(model,train_dataset=dataset,args=SFTConfig(output_dir="./tmp",gradient_checkpointing=True,per_device_train_batch_size=8),formatting_func=formatting_prompts_func,data_collator=collator,
)trainer.train()
结论
得益于最近的 PR 和新推出的 DataCollatorWithFlattening ,现在打包指令调整示例 (而不是填充) 已与 Flash Attention 2 完全兼容。这种方法与使用 position_ids 的模型兼容。在训练期间可以观察到吞吐量和峰值内存使用的改善,而训练收敛性没有下降。实际的吞吐量和内存改善取决于模型以及训练数据中示例长度的分布。对于具有广泛示例长度变化的训练数据,使用 DataCollatorWithFlattening 相对于填充将获得最大的益处。TRL 库中的 SFTTrainer 用户可以通过在调用 DataCollatorForCompletionOnlyLM 时设置新的标志 padding_free=True 来使用同一功能。想要更详细的分析,请查看论文:https://hf.co/papers/2407.09105。
如何学习AI大模型?
?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

相关文章:
通过打包 Flash Attention 来提升 Hugging Face 训练效率
简单概述 现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个最近的 PR以及新的DataCollatorWithFlattening。 最近的 PRhttps://github.com/huggingface/transformers/pull/3…...

用hiredis连接redis
hiredis 什么是 Hiredis Hiredis 是一个用于与 Redis 服务器进行通信的 C 语言库。它提供了一组 API,方便开发者在各种应用场景中实现与 Redis 服务器的数据交互操作。 在服务器端的应用中,比如构建 Web 服务或者后端处理程序时,如果需要频…...

第G8周:ACGAN任务
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 本周任务: 根据GAN、CGAN、SGAN及它们的框架图,写出ACGAN代码。 框架图 从图中可以看到,ACGAN的前半部分类似于CGAN&#…...

nvm拉取安装node包时报错的解决办法
问题一:用nvm安装某个版本node包时,node正确安装了,但是对应的npm无法安装 原因:原系统中node.js没有卸载干净, 解决办法:先把原系统中node.js卸载干净。再安装nvm和node包 问题二:nvm无法拉取…...

PyTorch 和 TensorFlow
PyTorch 和 TensorFlow 是目前最流行的两个深度学习框架。它们各自有不同的特点和优势,适合不同的使用场景。以下是对这两个框架的详细比较和介绍。 1. PyTorch 简介 PyTorch 是由 Facebook AI Research (FAIR) 开发的开源深度学习框架,以其易用性和灵…...

数据库视图和索引
参考链接: 数据库的视图和索引的概念和区别_索引和视图的区别-CSDN博客 MySQL 数据库--索引(理论详解及实例演示)_数据库索引-CSDN博客 1.视图 视图是从一个或多个表中导出来的表,是一种不是一种真正存在的概念。这样…...

哈希表的底层实现(1)---C++版
目录 哈希表的基本原理 哈希表的优点 哈希表的缺点 应用场景 闭散列法 开散列法 开放定值法Open Addressing——线性探测的模拟实现 超大重点部分评析 链地址法Separate Chaining——哈希桶的模拟实现 哈希表(Hash Table)是一种数据结构&#x…...

如何使用PTK一键安装opengaussdb 5.0
1、关于PTK工具 MogDB数据库是云和恩墨基于openGauss开源数据库打造,安稳易用的企业级关系型数据库。 PTK是云和恩墨出品的一款工具,帮助用户更便捷地部署管理MogDB数据库。 1.1 使用场景 开发人员快速启动多个本地 MogDB 环境用户通过 PTK 快速安装…...

跟李沐学AI:长短期记忆网络LSTM
输入们、遗忘门和输出门 LSTM引入输入门、忘记门和输出门 输入门计算公式为:。 遗忘门计算公式为:。 输出门计算公式为:。 它们由三个具有sigmoid激活函数的全连接层处理, 以计算输入门、遗忘门和输出门的值。 因此,…...

【BIM模型数据】BIM模型的数据如何存储,BIM大模型数据云端存储,需要考虑哪些因素,BIM模型数据存储和获取
【BIM模型数据】BIM模型的数据如何存储,BIM大模型数据云端存储,需要考虑哪些因素,BIM模型数据存储和获取 BIM文件的结构化数据和非结构化数据的存储方式,需要根据数据的特性和使用需求来选择。以下是一些推荐的存储策略࿱…...

【LLM大模型】大模型架构:layer\_normalization
2.layer_normalization 1.Normalization 1.1 Batch Norm 为什么要进行BN呢? 在深度神经网络训练的过程中,通常以输入网络的每一个mini-batch进行训练,这样每个batch具有不同的分布,使模型训练起来特别困难。Internal Covariat…...

PON光模块的独特类型和特性
在当前互联网需求快速增长的背景下,PON光模块已成为实现光纤网络高速数据传输的重要组成部分。从住宅宽带到各种企业应用程序解决方案,PON光模块始终致力于实现高质量的数据传输与无缝通信。了解PON光模块的类型和特性对于深入理解现代网络基础设施至关重…...
架构与业务的一致性应用:实现企业战略目标和合规管理的全面指南
在当今快速变化的数字经济中,信息架构已成为企业实现其业务目标、优化运营效率和确保数据安全的关键工具。 一个成功的信息架构不仅要与企业的战略目标紧密对齐,还必须遵循日益严格的合规性要求,以保护敏感数据并满足法规规定。《信息架构&a…...

时尚穿搭想换就换,各种风格一键完美搭配!亲测在线虚拟试衣换装平台效果超赞!
随着科技的发展,时尚领域也迎来了新的革命。传统的试衣方式逐渐被现代科技所取代,虚拟试衣间的出现使得用户可以在舒适的家中轻松体验不同的服装风格。 先前给大家也介绍过一些虚拟试衣的技术,例如AnyFit或者OutfitAnyone等,今天…...
)
【C++】C++ 标准库string类介绍(超详细解析,小白必看系列)
C 标准库中的 std::string 类是一个非常强大的工具,用于处理和操作字符串。它属于 <string> 头文件,并提供了一套丰富的功能和方法。以下是 std::string 类的一些主要特性和常用操作: 1 string简介 字符串是表示字符序列的类 标准的字…...

若依RuoYi项目环境搭建教程(RuoYi-Vue + RuoYi-Vue3版本)
文章目录 一、开发脚手架选择二、RuoYi框架1、介绍2、版本发展3、为什么选择若依4、优缺点5、项目内置功能 三、后端项目部署1、拉取源码2、环境要求3、Maven构建4、MySQL相关(1)导入SQL脚本(2)配置信息 5、Redis相关(…...

Java 后端接口入参 - 联合前端VUE 使用AES完成入参出参加密解密
加密效果: 解密后的数据就是正常数据: 后端:使用的是spring-cloud框架,在gateway模块进行操作 <dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>30…...
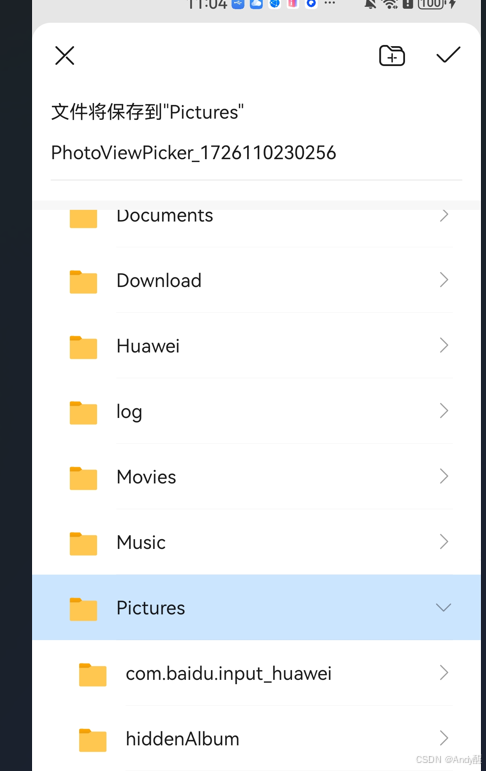
HarmonyOS开发之使用PhotoViewPicker(图库选择器)保存图片
一:效果图 二:添加依赖 import fs from ohos.file.fs;//文件管理 import picker from ohos.file.picker//选择器 三:下载,保存图片的实现 // 下载图片imgUrldownloadAndSaveImage(imgUrl: string) {http.createHttp().request(…...

跨境独立站支付收款常见问题排雷篇1.0丨出海笔记
最近小伙伴们在社群讨论挺多关于独立站支付问题的,鉴于不少朋友刚接触独立站,我整理了一些独立站支付相关的问题和解决方案,供大家参考,百度网上一堆媒体的那些软文大家就别看了,都是软广或者抄来抄去,让大…...

uni-app实现web-view和App之间的相互通信
双向实时 如果app端部署成网站,则web-view就是iframe,使用也可以双向通讯 https://uniapp.dcloud.net.cn/component/web-view.html APP端代码 index.vue: <template><web-viewid"m-webview":fullscreen"true":src"…...

别再只跑仿真了!用Vivado 2023.1给你的FPGA图像处理项目做个“硬件体检”
从仿真到硬件的跨越:FPGA图像处理项目实战验证指南 在实验室里看着仿真波形完美无缺,却在开发板上遭遇各种"灵异事件"——这可能是每个FPGA开发者都经历过的成长仪式。仿真环境就像飞行模拟器,能教会你基本操作,但真正的…...

基于Adafruit CRICKIT与3D打印的水面机器人DIY全攻略
1. 项目概述:打造你的第一艘智能水面机器人 如果你对机器人、水上航行或者水下摄影感兴趣,但又觉得从零开始设计电路和结构太复杂,那么这个项目就是为你准备的。今天,我想分享一个我最近完成的、非常有趣且实用的创客项目&#x…...

OpenSTA静态时序分析工具:从入门到精通的完整指南
OpenSTA静态时序分析工具:从入门到精通的完整指南 【免费下载链接】OpenSTA OpenSTA engine 项目地址: https://gitcode.com/gh_mirrors/op/OpenSTA OpenSTA静态时序分析工具是数字集成电路设计中不可或缺的开源时序验证解决方案。作为一款功能强大的门级静态…...

VK视频下载器:三步实现VKontakte视频永久保存的实用方案
VK视频下载器:三步实现VKontakte视频永久保存的实用方案 【免费下载链接】VK-Video-Downloader Скачивайте видео с сайта ВКонтакте в желаемом качестве 项目地址: https://gitcode.com/gh_mirrors/vk/VK-Video…...
)
别再为版本号头疼了!手把手教你搞定Windows上ChromeDriver与Chrome的版本匹配(附最新镜像源)
别再为版本号头疼了!手把手教你搞定Windows上ChromeDriver与Chrome的版本匹配 每次启动Selenium脚本时看到SessionNotCreatedException报错,就像在高速公路上突然爆胎——明明昨天还能正常运行的自动化测试,今天就因为Chrome自动更新而彻底罢…...
)
Labelme版本不兼容报错?手把手教你修改源码和JSON文件(附3.18.0与4.5.6对比)
Labelme版本兼容性实战:从源码修改到JSON批量处理的完整指南 当你正专注于一个重要的数据标注项目,突然遭遇"Error opening file lineColor"的红色报错框,整个团队的标注进度被迫停滞——这种场景对于使用Labelme进行图像标注的开发…...

Vivado时序约束实战:用Set_Case_Analysis给FPGA设计‘瘦身’,提升分析效率
Vivado时序约束实战:用Set_Case_Analysis给FPGA设计‘瘦身’,提升分析效率 当你在Vivado中面对一个包含数百个时钟域的中大型FPGA设计时,是否曾被长达数小时的时序分析运行时间和内存爆满的警告折磨得焦头烂额?我曾接手过一个图像…...
)
告别wx.startRecord!微信小程序录音功能保姆级教程(RecorderManager全解析)
微信小程序录音功能深度重构指南:从wx.startRecord到RecorderManager的完整迁移方案 在微信小程序开发生态中,音频处理能力一直是实现丰富交互体验的核心组件之一。随着技术架构的持续优化,微信团队对录音API进行了重大升级,用更现…...
构建企业级数据集成管道)
从零到一:基于Kettle(PDI)构建企业级数据集成管道
1. 企业级数据集成为何选择Kettle? 第一次接触Kettle(现在官方称为Pentaho Data Integration)是在2013年一个银行数据迁移项目上。当时客户需要将分散在20多个业务系统中的客户数据整合到新建的数据仓库,项目组评估了多个ETL工具后…...

搞懂USB2.0 Reset:从Hub发信号到设备握手的完整流程拆解
USB2.0 Reset全流程解析:从信号触发到高速模式切换的工程实践 当你的USB设备频繁掉线或枚举失败时,逻辑分析仪上那些跳变的波形到底在诉说什么?作为嵌入式开发者,我们常常需要像侦探一样解读这些电子信号背后的协议语言。本文将带…...