DoubletFinder去除双细胞分析学习
在单细胞RNA测序过程中,有时两个或多个细胞可能在制备过程中意外结合成一个单一的"假细胞",称为双峰细胞或双倍体。这些双峰细胞可能会扭曲数据分析和解释,因此,需要使用一些方法对它们进行识别和剔除。其中DoubletFinder是最常用的一个工具。
官方对DoubletFinder输入的对象和参数介绍

-
seu:这是一个完全处理过的 Seurat 对象,即已经完成了数据规范化(NormalizeData)、寻找变异基因(FindVariableGenes)、数据标准化(ScaleData)、主成分分析(RunPCA)和 t-SNE 分析(RunTSNE)。
-
PCs:指定用于分析的统计显著的主成分数量,例如 PCs = 1:10。
-
pN:定义生成的人工双倍体数量,以合并的真实-人工数据比例表示。默认设置为 25%,根据 McGinnis, Murrow 和 Gartner 在 2019 年的 Cell Systems 文章,DoubletFinder 的表现在很大程度上与 pN 参数无关。
-
pK:定义用于计算 pANN 的 PC 邻域大小,同样以合并的真实-人工数据比例表示。没有默认值,因为每个单细胞 RNA 测序数据集都应该调整 pK 值。最优的 pK 值应该使用下面描述的策略来估计。
-
nExp:定义用于做出最终双倍体/单倍体预测的 pANN 阈值。这个值最好从 10X 或 Drop-Seq 设备的细胞加载密度中估计,并根据同源双倍体的预估比例进行调整。
官网文档中对示例数据的要求和参数进行了解释。其中seu对象是建议提前进行处理的。PC值其实可以按照使用者降维聚类选择的值而定。pN就默认25%即可。pK和nExp有函数可以进行计算。
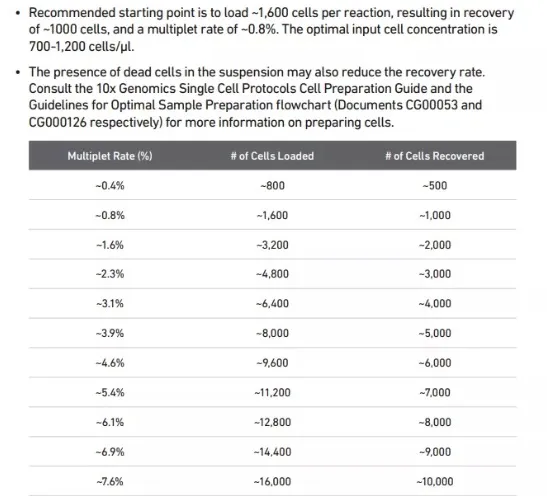
下面的表格是DoubletRate参数选择的参考文件(10X),在分析之前参照这个表格上边的细胞数选择DoubletRate值。
步骤流程
1、导入
scRNA是多样本已经合并完成并进行过标准流程后的数据集
rm(list=ls())
library(DoubletFinder)
library(BiocParallel)
library(qs)
library(Seurat)register(MulticoreParam(workers = 4, progressbar = TRUE))
scRNA <- qread("./sce.qs")
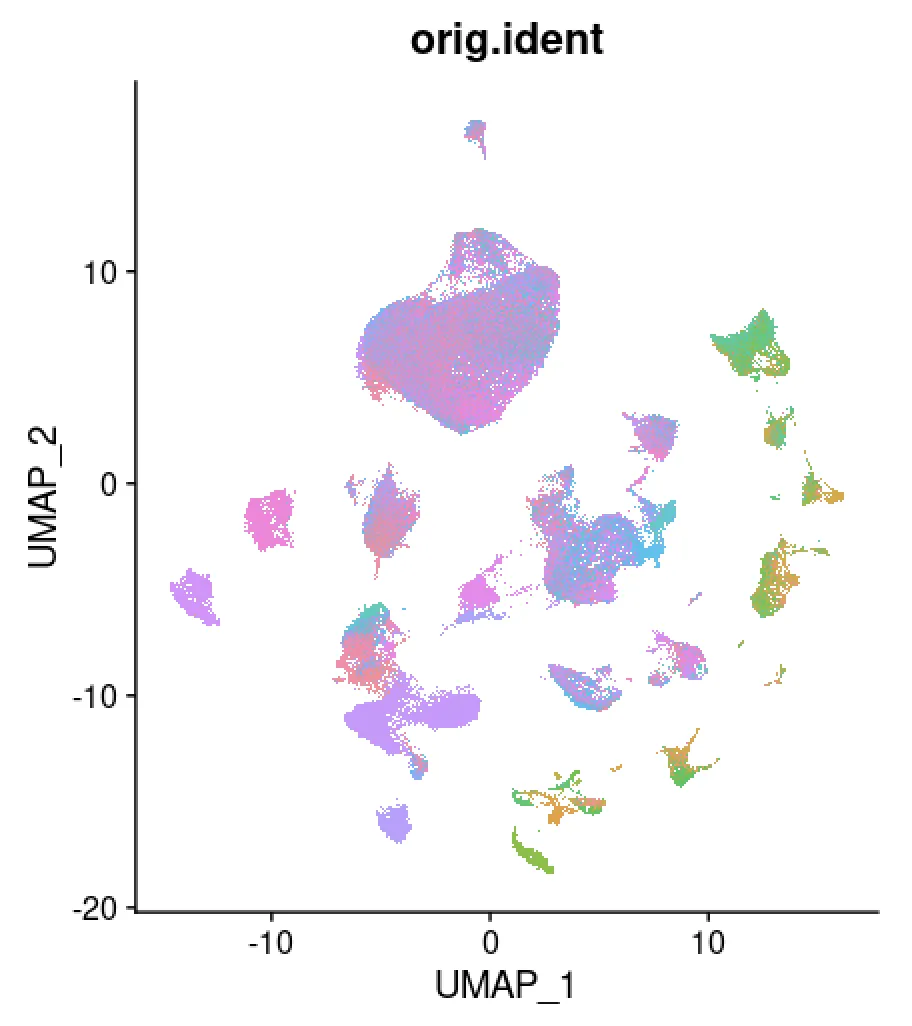
table(scRNA$orig.ident)# check一下
DimPlot(scRNA,pt.size = 0.8,group.by = "orig.ident",label = F)
2、DoubletFinder分析
一般是建议按照每个cluster进行分析,SCT参数是指SCTransform,如果是其他方式比如harmony之后的,可以考虑不选择T。
#单个分开,用来做DoubletFinder
sce_list <- SplitObject(scRNA, split.by = "orig.ident")pc.num <- 1:30
DoubletRate = 0.023 # 大约4800的细胞
# 找到pK
sweep.res <- paramSweep(sce_list[["C1"]], PCs = pc.num, sct = F) # sct也可以选择T
sweep.stats <- summarizeSweep(sweep.res, GT = FALSE)
bcmvn <- find.pK(sweep.stats)
pK_bcmvn <- bcmvn$pK[which.max(bcmvn$BCmetric)] %>% as.character() %>% as.numeric()# 计算homotypic doublets的比例和预期的doublet数目
homotypic.prop <- modelHomotypic(sce_list[["C1"]]$seurat_clusters) # 最好提供celltype
nExp_poi <- round(DoubletRate * ncol(sce_list[["C1"]]))
nExp_poi.adj <- round(nExp_poi * (1 - homotypic.prop))# 使用确定的参数鉴定doublets
sce_list[["C1"]] <- doubletFinder(sce_list[["C1"]], PCs = pc.num, pN = 0.25, pK = pK_bcmvn, nExp = nExp_poi.adj, reuse.pANN = F, sct = F) # 也可以选择T# 图片展示
DimPlot(sce_list[["C1"]], reduction = "umap", group.by = "DF.classifications_0.25_0.28_95")
对sce_list中的每一个样本都需要走一遍流程,之后再进行合并。
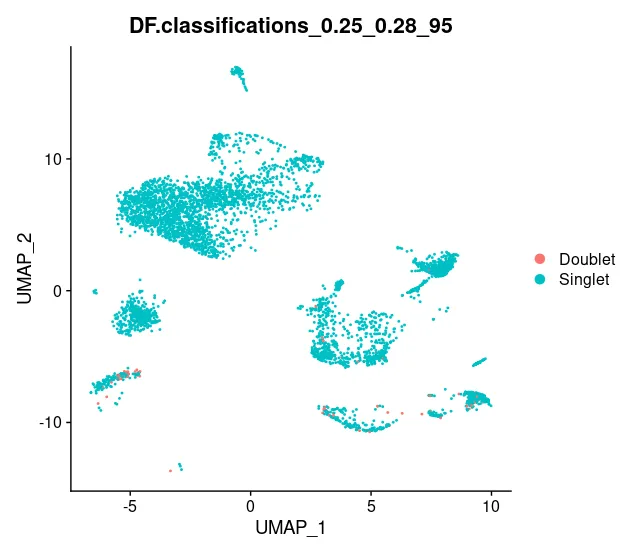
流程不复杂,C1名称需要按照自己数据修改,如果样本量多的话步骤会比较繁琐,使用者可考虑进行函数封装。
同时也有一些观点认为应谨慎处理双细胞,因为这些双细胞毕竟是人为定义的,那么是不是真的是双细胞其实也是要思考的,所以可以先进行双细胞的检测不删除,等后续观察细胞分群的情况以及功能富集等一些操作之后再做考虑。
参考资料:
1、DoubletFinder: https://github.com/chris-mcginnis-ucsf/DoubletFinder
2、单细胞天地:https://mp.weixin.qq.com/s/O0U8vlMIG9vUVE3FK08LJg
致谢:感谢曾老师以及生信技能树团队全体成员。
注:若对内容有疑惑或者有发现明确错误的朋友,请联系后台(欢迎交流)。更多内容可关注公众号:生信方舟
- END -
相关文章:
DoubletFinder去除双细胞分析学习
在单细胞RNA测序过程中,有时两个或多个细胞可能在制备过程中意外结合成一个单一的"假细胞",称为双峰细胞或双倍体。这些双峰细胞可能会扭曲数据分析和解释,因此,需要使用一些方法对它们进行识别和剔除。其中DoubletFind…...
)
软考高级第四版备考---第四十八天(项目基本要素-项目项目、项目集、项目组合和运营管理之间的关系)
一、概述: 项目集是一组相互关联且被协调管理的项目、子项目集和项目集活动,目的是为了获得分别管理无法获得的利益。项目集不是大项目,大项目是指规模、影响等特别大的项目; 项目组合是指为实现战略目标而组合在一起管理的项目、…...

系统架构设计师:信息系统基础知识
简简单单 Online zuozuo: 简简单单 Online zuozuo 简简单单 Online zuozuo 简简单单 Online zuozuo 简简单单 Online zuozuo :本心、输入输出、结果 简简单单 Online zuozuo : 文章目录 系统架构设计师:信息系统基础知识前言信息系统构成:信息系统功能:信息系统生命周期…...

微服务-nacos
nacos-注册中心 启动 服务注册到nacos...

快速上手 | 数据可观测性平台 Datavines 自定义SQL规则使用指南
摘要 本文主要介绍在 Datavines平台已有规则不能满足需求的情况下,如何通过自定义SQL规则来实现基于业务特性的数据质量检查。 规则介绍 自定义聚合SQL规则是 Datavines 平台中内置的一个灵活的规则,该规则允许用户通过编写SQL的方式来实现想要的数据质…...

MySQL零基础入门教程-6 查询去重、内外连接查询、子查询、分页查询DQL,基础+实战
教程来源:B站视频BV1Vy4y1z7EX 001-数据库概述_哔哩哔哩_bilibili 我听课收集整理的课程的完整笔记,供大家学习交流下载:夸克网盘分享 本文内容为完整笔记的第六篇 分组查询&DQL总结P41-P66 1、把查询结果去除重复记录 注意…...

Elastic:如何将数据转化为可操作的见解?
作者:来自 Elastic Elastic Platform Team 一切,从某种程度上说,每个人,都是数据。在我们这个数据驱动的世界里,我们的兴趣和互动被统计和分类,为组织提供如何创造更好的产品和更好的体验的见解。更不用说&…...

基于SSM和VUE的药品管理系统(含源码+sql+视频导入教程+文档)
👉文末查看项目功能视频演示获取源码sql脚本视频导入教程视频 1 、功能描述 基于SSM和VUE的药品管理系统2拥有两种角色 管理员:药品管理、出库管理、入库管理、销售员管理、报损管理等 销售员:登录注册、入库、出库、销售、报损等 1.1 背景…...

机器学习--神经网络
神经网络 计算 神经网络非常简单,举个例子就理解了(最后一层的那个写错了,应该是 a 1 ( 3 ) a^{(3)}_1 a1(3)): n o t a t i o n notation notation: a j ( i ) a^{(i)}_j aj(i) 表示第 i i i 层的…...

post请求中有[]报400异常
序言 在和前端同学联调的时候,发现只要post请求参数里面有[],就会报400的错误 可以看到日志中: The valid characters are defined in RFC 7230 and RFC 3986 解决办法: 参考了博客: spring boot 中解决post请求中有…...
ad22 如何在pcb 的keepout layout 上画线 然后裁出想要的黑色画布大小
选择下面的keepout layout,然后右键打开,然后按照这个图进行选择 然后看这个界面我收藏的第三个,就可以了...

SparkSQL SET和RESET
前言 我们在用代码写spark程序的时候,如果要设置一些配置参数,可以通过: SparkConf val conf = new SparkConf().setMaster("local[2]").setAppName("CountingSheep") val sc = new SparkContext(conf)spark-submit ./bin/spark-submit --name "M…...

java 中线程的等待和唤醒
java.lang.Object#wait() java.lang.Object#wait(long) java.lang.Object#wait(long, int) java.lang.Object#notify() java.lang.Object#notifyAll() 这几个方法属于Object,在使用 synchronized 实现同步的时候,需要使用当前监视器的以上方法ÿ…...

windows下自启springboot项目(jar+nginx)
1、将springboot项目打包为jar 2、新建文本文档 test.txt,并输入 java -jar D:\test\test.jar(修改为自己的jar包位置) 保存 然后修将后缀名改为 .bat 3、在同一目录再新建 文本文档test.txt,输入以下内容,&…...

解锁SAP数据的潜力:SNP Glue与SAP Datasphere的协同作用
在各种文章中,我们研究了客户如何利用SNP Glue与基于云的数据仓库和数据湖相结合,以充分利用其SAP数据。SNP Glue 通过高性能集成解决方案帮助客户解锁 SAP 数据孤岛。例如,可以使用SNP Glue先进的增量捕获(CDC)近乎实…...

Missing package to enable rendering OpenAI Gym in Colab
题意:“缺少用于在 Colab 中渲染 OpenAI Gym 的软件包。” 问题背景: Im attempting to render OpenAI Gym environments in Colab via a Mac using the StarAI code referenced in previous questions on this topic. However, it fails. The key erro…...

通过打包 Flash Attention 来提升 Hugging Face 训练效率
简单概述 现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个最近的 PR以及新的DataCollatorWithFlattening。 最近的 PRhttps://github.com/huggingface/transformers/pull/3…...

用hiredis连接redis
hiredis 什么是 Hiredis Hiredis 是一个用于与 Redis 服务器进行通信的 C 语言库。它提供了一组 API,方便开发者在各种应用场景中实现与 Redis 服务器的数据交互操作。 在服务器端的应用中,比如构建 Web 服务或者后端处理程序时,如果需要频…...

第G8周:ACGAN任务
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 本周任务: 根据GAN、CGAN、SGAN及它们的框架图,写出ACGAN代码。 框架图 从图中可以看到,ACGAN的前半部分类似于CGAN&#…...

nvm拉取安装node包时报错的解决办法
问题一:用nvm安装某个版本node包时,node正确安装了,但是对应的npm无法安装 原因:原系统中node.js没有卸载干净, 解决办法:先把原系统中node.js卸载干净。再安装nvm和node包 问题二:nvm无法拉取…...
—— 卷积运算的本质(三十八))
深度学习CNN(一)—— 卷积运算的本质(三十八)
1. 定位导航 🎉 第 9 章 CNN 大门正式开启! CNN 是深度学习历史上最具影响力的架构创新之一: 2012 AlexNet:ImageNet 革命,开启深度学习时代 2015 ResNet:突破"深度极限" 2020 Vision Transformer:CNN 的最大竞争对手出现 直到 2024 年:CNN 仍是图像处理、…...

别再手动改hosts了!用Docker Compose一键部署Authelia SSO,顺便搞定Traefik反向代理
一键部署Authelia SSO与Traefik反向代理的Docker Compose实战指南 在当今复杂的网络环境中,管理多个Web应用的认证流程往往成为开发者的痛点。手动配置hosts文件、逐个设置访问权限不仅耗时耗力,还容易出错。本文将介绍如何利用Docker Compose快速搭建Au…...

ThinkPHP8.x全面升级:现代化PHP开发新标杆
好的,我们来梳理一下 ThinkPHP 8.x 版本(通常指 8.0 及后续小版本)的主要特性和改进方向。相较于之前的版本(如 5.x),8.x 版本在架构、性能、规范性和安全性上都有显著提升:核心方向与重大变更&…...

【MYSQL】 mysql库和表的操作--详解
一.库的操作1.1 创建数据库创建数据库:create database db_name; -- 本质就是在 /var/lib/mysql 创建一个目录CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...] create_specification: [DEFAULT] CHARACTER SET chars…...

新手入门教程使用Python快速调用Taotoken提供的多模型API服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手入门教程使用Python快速调用Taotoken提供的多模型API服务 对于刚开始接触大模型API的开发者而言,直接对接不同厂商…...
)
告别点灯:用STM32+FPGA+FSMC做个数据吞吐测试仪(附Quartus与标准库工程)
STM32与FPGA联袂打造:高性能数据吞吐测试仪实战指南 在嵌入式系统开发中,总线通信性能往往是决定整体系统响应速度的关键瓶颈。对于硬件爱好者、电子工程师和学生群体而言,如何直观测量和优化总线传输效率,是一个既具挑战性又充满…...

AzurLaneLive2DExtract:碧蓝航线Live2D资源提取的完整指南
AzurLaneLive2DExtract:碧蓝航线Live2D资源提取的完整指南 【免费下载链接】AzurLaneLive2DExtract OBSOLETE - see readme / 碧蓝航线Live2D提取 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneLive2DExtract 想要从碧蓝航线游戏中提取精美的Live2D…...

百度季报图解:营收321亿 AI业务占比首次过半 DAA重塑AI价值标准
雷递网 雷建平 5月18日百度集团(纳斯达克:BIDU及香港联交所:9888(港元柜台)及89888(人民币柜台))今天公布其截至2026年3月31日止第一季度的未经审计财务业绩,财报显示&am…...

UVa 232 Crossword Answers
题目分析 本题是一个填字游戏(Crossword Puzzle\texttt{Crossword Puzzle}Crossword Puzzle)的题目。给定一个 rcr \times crc 的网格,其中白色格子包含字母,黑色格子用 *\texttt{*}* 表示。需要按照规则对白色格子进行编号&#…...

XNBCLI深度解析:掌握星露谷物语XNB文件解包打包的完全手册
XNBCLI深度解析:掌握星露谷物语XNB文件解包打包的完全手册 【免费下载链接】xnbcli A CLI tool for XNB packing/unpacking purpose built for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/xn/xnbcli 想要深度定制星露谷物语游戏体验…...