Python 基本库用法:数学建模
文章目录
- 前言
- 数据预处理——sklearn.preprocessing
- 数据标准化
- 数据归一化
- 另一种数据预处理
- 数据二值化
- 异常值处理
- numpy 相关用法
- 跳过 nan 值的方法——nansum和nanmean
- 展开多维数组(变成类似list列表的形状)
- 重复一个数组——np.tile
- 分组聚集——pandas.DataFrame.groupby()
- 如何使用
- 直接使用聚集函数
- Agg
- 直接解析分组结果
- 参数说明——by
- 传入属性列列表
- 传入字典 dict
- 表格合并——pandas.merge()
- 数据库关系型表格 → 二维表——pandas.DataFrame.pivot()
- 序列极值的获取——scipy.signal.argrelextrema
前言
使用 Python 进行数学建模时,需要进行各种各样的数据预处理。因此熟练掌握 Python 的一些库可以帮助我们更好的进行数学建模。
数据预处理——sklearn.preprocessing
数据标准化
数据标准化的目的是,通过线性缩放,使得一组数据的均值变成 0 0 0,方差变成 1 1 1。使用scale方法:
from sklearn import preprocessing
import numpy as npdata = np.array([[1.,1.,4.,5.],[1.,4.,1.,9.],[1.,9.,8.,1.]])
# 默认按列标准化(axis = 0),如需按行标准化需要指定 axis = 1
print(preprocessing.scale(data))# 结果如下,原本方差为 0 的数据,标准化后方差仍然是 0(因为无法变成1)
#[[ 0. -1.1111678 -0.11624764 0. ]
# [ 0. -0.20203051 -1.16247639 1.22474487]
# [ 0. 1.31319831 1.27872403 -1.22474487]]
我们知道标准化的实质是减去均值、除以标准差。StandarScalar可以用一组数据的均值、方差去标准化另一组数据。比如:
from sklearn import preprocessing
import numpy as npdata = np.array([[1.,1.,4.,5.],[1.,4.,1.,9.],[1.,9.,8.,1.]])
scaler = preprocessing.StandardScaler().fit(data)
new_data = np.array([[9.,2.,3.,4.]])# 用 data 的均值、标准差去标准化 new_data
print(scaler.transform(new_data))
# 结果为 [[ 8. -0.80812204 -0.46499055 -0.30618622]]
数据归一化
数据归一化指的是,通过线性缩放,使得一组数据的最小值为 0 0 0,最大值为 1 1 1。**实质是全体减去最小值,然后除以减法过后的最大值。**可以使用MinMaxScaler类:
from sklearn import preprocessing
import numpy as npdata = np.array([[1.,1.,4.,5.],[1.,4.,1.,9.],[1.,9.,8.,1.]])
# 创建 scaler
scaler = preprocessing.MinMaxScaler()print(scaler.fit_transform(data))
# 结果是
#[[0. 0. 0.42857143 0.5 ]
# [0. 0.375 0. 1. ]
# [0. 1. 1. 0. ]]# 同样可以用 data 的缩放方式来归一化 new_data
new_data = np.array([[1,0,3,7]])
print(scaler.transform(new_data))
# 结果为 [[ 0. -0.125 0.28571429 0.75 ]]
另一种数据预处理
还有一种数据预处理是,对初始数据 { x 1 , x 2 , ⋯ , x n } \{x_1,x_2,\cdots,x_n\} {x1,x2,⋯,xn} 都除以 max 1 ≤ i ≤ n ∣ x i ∣ \max\limits_{1\leq i\leq n}|x_i| 1≤i≤nmax∣xi∣,使得所有数据都落在 [ − 1 , 1 ] [-1,1] [−1,1] 范围内。MaxAbsScaler类可以完成这种预处理,其用法和前面的MinMaxScaler类似。这个方法对那些已经中心化均值为 0 0 0 或者稀疏的数据有意义。
数据二值化
数据二值化设置一个阈值threshold,小于等于它的变成 0 0 0,大于它的变成 1 1 1。
from sklearn import preprocessing
import numpy as npdata = np.array([[1.,1.,4.,5.],[1.,4.,1.,9.],[1.,9.,8.,1.]])
# Binarizer 无参数默认 threshold = 0
print(preprocessing.Binarizer(threshold = 1).transform(data))
# 结果为
#[[0. 0. 1. 1.]
# [0. 1. 0. 1.]
# [0. 1. 1. 0.]]
参考文献:预处理数据的方法总结(使用sklearn-preprocessing)_from sklearn import preprocessing-CSDN博客
异常值处理
四分位法清除异常值:首先计算出序列的第一四分位数、第三四分位数 Q 1 , Q 3 Q_1,Q_3 Q1,Q3,然后计算四分位数间距 I Q R = Q 3 − Q 1 \mathit{IQR}=Q_3-Q_1 IQR=Q3−Q1。认为可接受的数据范围是 [ Q 1 − 1.5 I Q R , Q 3 + 1.5 I Q R ] [{{Q}_{1}}-1.5\mathit{IQR},{{Q}_{3}}+1.5\mathit{IQR}] [Q1−1.5IQR,Q3+1.5IQR]。如下图:

图源来自图片水印所示博客。
import pandas as pd# 直接把数据从这里输入进来
data = pd.Series([1,1,4,5,1,4,1,9,1,9,8,1,0])Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
# 根据条件筛选和删除异常值,输出的 data 就是处理后的结果
data = data[~((data < (Q1 - 1.5 * IQR)) | (data > (Q3 + 1.5 * IQR)))]
numpy 相关用法
跳过 nan 值的方法——nansum和nanmean
import numpy as nparr = np.array([1, 2, 3, 4, np.nan])
print(arr.sum(),arr.mean()) # nan nan
print(np.nansum(arr),np.nanmean(arr)) # 10.0 2.5,相当于删除所有 nan 值再操作
展开多维数组(变成类似list列表的形状)
import numpy as nparr = np.array(range(16)).reshape(4,-1)print(arr)
"""
[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11][12 13 14 15]]
"""
# 下面三种方法任选其一即可
print(arr.ravel())
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
print(arr.flatten())
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
print(arr.reshape(-1))
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
重复一个数组——np.tile
import numpy as np# 只描述对于 2 维数组的情况,其他详情见参考文献data = np.array([[1,1,4],[5,1,4]])# 只传一个参数 x,那么行方向重复 x 次
print(np.tile(data,3))
"""
[[1 1 4 1 1 4 1 1 4][5 1 4 5 1 4 5 1 4]]
"""# 传一个含有两个参数的元组 (x,y),那么列方向重复 x 次,行方向重复 y 次
print(np.tile(data,(2,4)))
"""
[[1 1 4 1 1 4 1 1 4 1 1 4][5 1 4 5 1 4 5 1 4 5 1 4][1 1 4 1 1 4 1 1 4 1 1 4][5 1 4 5 1 4 5 1 4 5 1 4]]
"""
参考文献:numpy.tile()_np.tile-CSDN博客
分组聚集——pandas.DataFrame.groupby()
对于一个表格进行类似 MySQL 聚集函数的处理,该方法的参数及默认值:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True,sort=True, group_keys=True, squeeze=False, observed=False, dropna=True)
如何使用
直接使用聚集函数
方法得到的是一个对象,对于该对象可以使用聚集函数。比如下面的例子:
import pandas as pddf = pd.DataFrame({'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': ['X', 'X', 'Y', 'Y']
})# 聚集函数——均值mean(),还可以是最大值max(),最小值min(),
# 求和sum(),求积prod(),计数count(),标准差std(),各种统计数据describe()等。
print(df.groupby('C').mean()) # 即参数 by = 'C'
# 结果如下所示
# A B
# C
# X 1.5 5.5
# Y 3.5 7.5print(df.groupby('C').rank())
# 结果如下所示
# A B
# 0 1.0 1.0
# 1 2.0 2.0
# 2 1.0 1.0
# 3 2.0 2.0
Agg
agg 在基于相同的分组情况下,可以对不同列分别使用不同的聚集函数,如:
import pandas as pddf = pd.DataFrame({'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': ['X', 'X', 'Y', 'Y']
})# 对 'A' 列分组求最小值,对 'B' 列分组求最大值
print(df.groupby('C').agg({'A':'min','B':'max'}))# 结果如下所示
# A B
# C
# X 1 6
# Y 3 8
也可以传入自定义函数,比如上面的'B':'max'也可以等价地改为'B':lambda x : max(x),其中参数x是由 agg 分组形成的元组。
直接解析分组结果
有时候希望根据分组结果,一组显示一张表格。直接打印 groupby 后的对象是不行的:
import pandas as pddf = pd.DataFrame({'name': ['香蕉', '菠菜', '糯米', '糙米', '丝瓜', '冬瓜', '柑橘', '苹果', '橄榄油'],'category': ['水果', '蔬菜', '米面', '米面', '蔬菜', '蔬菜', '水果', '水果', '粮油'],'price': [3.5, 6, 2.8, 9, 3, 2.5, 3.2, 8, 18],'count': [2, 1, 3, 6, 4, 8, 5, 3, 2]
})print(df.groupby('category'))
# 结果只是类名 + 内存地址
# <pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000025D2D49B6D8>
但是我们可以按照下面的方式遍历,其中循环变量name为str类型,group为DataFrame类型:
import pandas as pddf = pd.DataFrame({'name': ['香蕉', '菠菜', '糯米', '糙米', '丝瓜', '冬瓜', '柑橘', '苹果', '橄榄油'],'category': ['水果', '蔬菜', '米面', '米面', '蔬菜', '蔬菜', '水果', '水果', '粮油'],'price': [3.5, 6, 2.8, 9, 3, 2.5, 3.2, 8, 18],'count': [2, 1, 3, 6, 4, 8, 5, 3, 2]
})
result = df.groupby('category')for name, group in result:print(f'group name: {name}')print('-' * 30)print(group)print('=' * 30, '\n')
"""
group name: 水果
------------------------------name category price count
0 香蕉 水果 3.5 2
6 柑橘 水果 3.2 5
7 苹果 水果 8.0 3
==============================
group name: 米面
------------------------------name category price count
2 糯米 米面 2.8 3
3 糙米 米面 9.0 6
==============================
group name: 粮油
------------------------------name category price count
8 橄榄油 粮油 18.0 2
==============================
group name: 蔬菜
------------------------------name category price count
1 菠菜 蔬菜 6.0 1
4 丝瓜 蔬菜 3.0 4
5 冬瓜 蔬菜 2.5 8
==============================
"""
参数说明——by
上面使用都是by = 'C'等传入某一个属性列的方式。
传入属性列列表
如果要按照多个属性列分组,可以传入属性列列表如下所示:
import pandas as pddf = pd.DataFrame({'x':[1,1,1,1,2,2,2,2],'y':[3,3,4,4,3,3,4,4],'value':[1,1,4,5,1,4,1,9]
})
# 按照 (x,y) 分组并求取最大值
print(df.groupby(['x','y']).max())
"""
结果是:value
x y
1 3 14 5
2 3 44 9
"""
groupby 接收多个属性,会将这些属性全部变成索引。之后可以接上reset_index操作,传入参数level,可以将第level列索引变成属性。
传入字典 dict
要求字典是int到str的映射。这种情况下,将不会按照df中原有的列进行分组,而是根据字典的内容,将原来df中的某一行映射到字典对应的类中。例如:
import pandas as pddf = pd.DataFrame({'name': ['香蕉', '菠菜', '糯米', '糙米', '丝瓜', '冬瓜', '柑橘', '苹果', '橄榄油'],'category': ['水果', '蔬菜', '米面', '米面', '蔬菜', '蔬菜', '水果', '水果', '粮油'],'price': [3.5, 6, 2.8, 9, 3, 2.5, 3.2, 8, 18],'count': [2, 1, 3, 6, 4, 8, 5, 3, 2]
})# 下面这 5 行是为了自动化地得到字典:
# {0: '蔬菜水果', 1: '蔬菜水果', 2: '米面粮油', 3: '米面粮油', 4: '蔬菜水果',
# 5: '蔬菜水果', 6: '蔬菜水果', 7: '蔬菜水果', 8: '米面粮油'}
category_dict = {'水果': '蔬菜水果', '蔬菜': '蔬菜水果', '米面': '米面粮油', '粮油': '米面粮油'}
the_map = {}
for i in range(len(df.index)):the_map[i] = category_dict[df.iloc[i]['category']]
grouped = df.groupby(the_map)# 按照 the_map 进行分组,那么原 df 中第 0,1,4,5,6,7 行被归为“蔬菜水果”,
# 第 2,3,8 行被归为“米面粮油”
result = df.groupby(the_map)# 按照不同类别进行打印
for name, group in result:print(f'group name: {name}')print('-' * 30)print(group)print('=' * 30, '\n')
"""
结果为:
group name: 米面粮油
------------------------------name category price count
2 糯米 米面 2.8 3
3 糙米 米面 9.0 6
8 橄榄油 粮油 18.0 2
============================== group name: 蔬菜水果
------------------------------name category price count
0 香蕉 水果 3.5 2
1 菠菜 蔬菜 6.0 1
4 丝瓜 蔬菜 3.0 4
5 冬瓜 蔬菜 2.5 8
6 柑橘 水果 3.2 5
7 苹果 水果 8.0 3
==============================
"""
参考文献:深入理解 Pandas 中的 groupby 函数_observed=false-CSDN博客
表格合并——pandas.merge()
这个merge和 MySQL 的 join 是有几分相似的。该方法的参数和默认值:
DataFrame.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=True,suffixes=('_x', '_y'), copy=True, indicator=False,validate=None)
- 其中
how还可以是left,right,outer,对应 MySQL 中的左、右、外连接;MySQL 中连接产生的 null 在 Python 中变成 nan。 on可以指定链接的时候参照那些属性列。默认情况下on = None,即自然连接。- (不常用)
indicator参数在最终合并形成的表格中加入一个_merge列,值域为{left_only,both,right_only},描述每一条结果是如何连接形成的。例子如下:
import pandas as pddf1 = pd.DataFrame({'col1': [0, 1], 'col_left':['a', 'b']})
df2 = pd.DataFrame({'col1': [1, 2, 2],'col_right':[2, 2, 2]})
print(pd.merge(df1, df2, on='col1', how='outer', indicator=True))
"""
结果如下所示:col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
"""
参考文献:【python】详解pandas库的pd.merge函数-CSDN博客
数据库关系型表格 → 二维表——pandas.DataFrame.pivot()
标题的意思是这样的:已有一个关系型数据库,可以指定两个索引(行索引、列索引)以及对应的值索引,转化为一个二维表格。如下图所示。
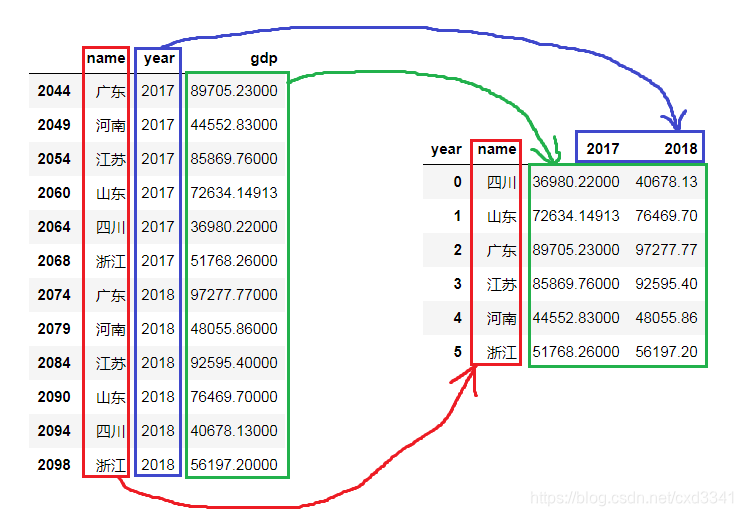
如果图片左边的 DataFrame 是变量 data,通过下面的语句实现到右边表格的转换:
data.pivot('name','year','gdp')
函数原型是:
DataFrame.pivot(index=None, columns=None, values=None)
右边二维表行列索引的生成机制是 index 和 columns 的笛卡尔积。笛卡尔积集合中可能有不存在的 (index, columns) 组合,经过pivot处理变成 nan,如:
import pandas as pd
data = pd.DataFrame({'name':['原神','原神','星铁','星铁','星铁'],'year':[2022,2023,2022,2023,2024],'income':[11,21,31,41,51]
})
print(data,'\n','-' * 24)
print(data.pivot('name','year','income'))
"""name year income
0 原神 2022 11
1 原神 2023 21
2 星铁 2022 31
3 星铁 2023 41
4 星铁 2024 51 ------------------------
year 2022 2023 2024
name
原神 11.0 21.0 NaN
星铁 31.0 41.0 51.0
"""
不能存在相同的 (index, columns) 组合:
import pandas as pd
data = pd.DataFrame({'name':['原神','原神'],'year':[2022,2022],'income':[11,21]
})
print(data.pivot('name','year','income'))
# ValueError: Index contains duplicate entries, cannot reshape
参考文献:Python dataframe.pivot()用法解析_dataframe pivot-CSDN博客
序列极值的获取——scipy.signal.argrelextrema
已知一个序列,可以用这个库方便地求极大值和极小值。代码示例如下:
from scipy.signal import argrelextrema
import numpy as np
# y 是待求序列
y = np.array([1,9,6,8,2,5,8,3,2,7,3,2,7,5])# np.greater_equal 表示求极大值,order = 1 表示和左边、右边的 1 个数字对比(是极大值的定义)
peak_index = argrelextrema(y,np.greater_equal,order=1)print(peak_index)
"""
结果: (array([ 1, 3, 6, 9, 12], dtype=int64),)
peak_index[0] 给出了极大值点的数组
"""
上面使用np.greater_equal求极大值点,同样地我们可以使用np.less_equal求极小值点。甚至可以自定义函数,将上面代码第 7 行改为:
peak_index = argrelextrema(y,lambda a,b: a - b > 3,order=1)
这将返回比左、右两边元素都大 3 3 3 的所有元素(此例中只有y[9])的索引(此例为9)。
参考文献:数据分析——scipy.signal.argrelextrema求数组中的极大值和极小值-CSDN博客
相关文章:
Python 基本库用法:数学建模
文章目录 前言数据预处理——sklearn.preprocessing数据标准化数据归一化另一种数据预处理数据二值化异常值处理 numpy 相关用法跳过 nan 值的方法——nansum和nanmean展开多维数组(变成类似list列表的形状)重复一个数组——np.tile 分组聚集——pandas.…...

Android Greendao的数据库复制到设备指定位置
方法如下: private void export() {// 确保您已经请求并获得了WRITE_EXTERNAL_STORAGE权限// 获取要储存的设备路径String picturesDirPath Environment.getExternalStoragePublicDirectory(Environment.DIRECTORY_PICTURES).getAbsolutePath();// 在公共目录下创建…...
Ajax 揭秘:异步 Web 交互的艺术
Ajax 揭秘:异步 Web 交互的艺术 一 . Ajax 的概述1.1 什么是 Ajax ?1.2 同步和异步的区别1.3 Ajax 的应用场景1.3.1 注册表单的用户名异步校验1.3.2 内容自动补全 二 . Ajax 的交互模型和传统交互模型的区别三 . Ajax 异步请求 axios3.1 axios 介绍3.1.1 使用步骤3…...

TitleBar:打造高效Android标题栏的新选择
在Android应用开发中,标题栏是用户界面的重要组成部分。一个好的标题栏不仅能够提升应用的专业感,还能增强用户体验。然而,传统的标题栏实现方式往往存在代码冗余、样式不统一、性能开销大等问题。今天,我们将介绍一个名为TitleBa…...

Lua协同程序Coroutine
Lua 协同程序(Coroutine) 定义 Lua 协同程序(Coroutine)与线程类似:拥有独立的堆栈、局部变量、指令指针,同时又与其它协同程序共享全局变量和其它大部分东西。 协同程序可以理解为一种特殊的线程,可以暂停和恢复其执行,从而允…...

【vue+帆软】帆软升级,从版本9升级到版本11,记录升级过程
帆软要升级,记录下过程 1、帆软官网地址必不可少,戳这里,跳转帆软官网 点击前端开发指南 点击JS API 跳转过来就是版本11 一直往下翻,在最底部有个2.2 在Web中使用,圈起来的就是要引入到index.html中的脚本 在项…...

linux从0到1 基础完整知识
1. Linux系统概述 Linux是一种开源操作系统,与Windows或macOS等操作系统不同,Linux允许用户自由地查看、修改和分发其源代码。以下是Linux系统的一些显著的优势。 稳定性和可靠性: 内核以其稳定性而闻名,能够持续运行数月甚至数…...

“人大金仓”正式更名为“电科金仓”; TDSQL-C支持回收站/并行DDL等功能; BigQuery支持直接查询AlloyDB
重要更新 1. “人大金仓”正式更名为“电科金仓”,完整名称“中电科金仓(北京)科技股份有限公司”,突出金仓是中国电子科技集团有限公司在基础软件领域产品( [1] ) 。据悉人大金仓在上半年营收入为9056万元,净利润约21…...

大模型微调 - 用PEFT来配置和应用 LoRA 微调
大模型微调 - 用PEFT来配置和应用 LoRA 微调 flyfish PEFT(Parameter-Efficient Fine-Tuning)是一种参数高效微调库,旨在减少微调大型预训练模型时需要更新的参数量,而不影响最终模型的性能。它支持几种不同的微调方法ÿ…...
Ubuntu构建只读文件系统
本文介绍Ubuntu构建只读文件系统。 嵌入式系统使用过程中,有时会涉及到非法关机(比如直接关机,或意外断电),这可能造成文件系统损坏,为了提高系统的可靠性,通常将根文件系统设置为只读…...

【黑金系】金融UI/UX体验设计师面试作品集 Figma源文件分享
在数字金融时代,UI/UX体验设计师扮演着至关重要的角色。他们不仅塑造着产品的界面,更引领着用户的使用体验。我们的面试作品集,正是这样一部展现金融UI/UX设计魅力的宝典。 这套作品集汇聚了众多经典案例,每一处设计都经过精心雕…...

Golang | Leetcode Golang题解之第392题判断子序列
题目: 题解: func isSubsequence(s string, t string) bool {n, m : len(s), len(t)f : make([][26]int, m 1)for i : 0; i < 26; i {f[m][i] m}for i : m - 1; i > 0; i-- {for j : 0; j < 26; j {if t[i] byte(j a) {f[i][j] i} else {…...

Liunx常用指令
1. 文件和目录管理 ls 用法:ls [选项] [文件/目录]示例:ls -l(以长列表格式显示),ls -a(显示所有文件,包括隐藏文件)。 cd 用法:cd [目录]示例:cd ..…...
如何使用清楚以及代替方法)
CSS基础:浮动(float)如何使用清楚以及代替方法
浮动元素在 CSS 中主要通过 float 属性来控制,影响元素的排列方式。浮动用于创建流式布局,常用于实现图文混排、布局列等效果。以下是浮动元素的相关属性和使用方法: 1. 基本浮动属性 float: 控制元素的浮动方向,可以设置为 left…...

margin重叠该怎么解决?
在CSS中,当两个或多个垂直相邻的块级元素(如<div>)的margin相遇时,它们不会叠加成两个margin的和,而是会取两个margin中的较大值,这种现象被称为“margin重叠”(margin collapsing&#x…...

Linux学习笔记(黑马程序员,前四章节)
第一章 快照 虚拟机快照: 通俗来说,在学习阶段我们无法避免的可能损坏Linux操作系统,如果损坏的话,重新安装一个Linux操作系统就会十分麻烦。VMware虚拟机支持为虚拟机制作快照。通过快照将当前虚拟机的状态保存下来,…...

tekton pipeline resources
PipelineResource 代表着一系列的资源,主要承担作为 Task 的输入或者输出的作用。它有以下几种类型: git:代表一个 git 仓库,包含了需要被构建的源代码。将 git 资源作为 Task 的 Input,会自动 clone 此 git 仓库。pu…...

使用Python实现多个PDF文件的合并
使用Python可以很方便地实现多个PDF文件的合并。我们可以使用PyPDF2库来完成这个任务。以下是一个实现PDF合并的Python脚本: import os from PyPDF2 import PdfMergerdef merge_pdfs(input_dir, output_filename):# 创建一个PdfMerger对象merger PdfMerger()# 获取…...

微擎忘记后台登录用户名和密码怎么办?解决方法
微擎忘记后台登录名和登录密码是很常见的,服务器百科网fwqbk.com告诉你找回后台登录用户名和密码的方法: 一:找回微擎后台用户名 (如果只是忘记了后台登录密码,请忽略此步骤,跳转到第二步) 通…...

blender我的对称模型好像中点被我不小心移动了 我现在如果雕刻 两边修改的地方不是对称的 我该怎么办
blender我的对称模型好像中点被我不小心移动了 我现在如果雕刻 两边修改的地方不是对称的 我该怎么办 首先请调整好模型确保左右前后对其相应的xyz轴 之后CtrlA应用变换 确保这些都归0且模型和xyz轴对应 如果在Blender中模型的中点(对称轴)不小心被移动了…...

逆向工程ChatGPT:开源社区如何解构大语言模型黑盒
1. 项目概述:当开源精神“撞上”闭源巨兽最近在GitHub上闲逛,发现一个叫Zai-Kun/reverse-engineered-chatgpt的项目热度不低。光看名字就挺有意思的,“逆向工程ChatGPT”。这可不是什么破解软件或者绕过付费墙的小把戏,它背后代表…...

ESP32驱动LCD1602:从I2C协议到动态数据展示
1. ESP32与LCD1602的完美组合 如果你正在寻找一种简单可靠的方式在物联网项目中显示实时数据,ESP32搭配LCD1602液晶屏绝对是个不错的选择。我最近在一个智能温室项目中就用了这套方案,用来实时显示温度和湿度数据,效果非常稳定。LCD1602虽然看…...
)
电赛小白也能搞定的二维云台:用K210+舵机实现色块追踪(附完整代码)
电赛入门实战:K210舵机构建高响应色块追踪云台 第一次参加电子设计竞赛时,面对复杂的视觉控制项目总有种无从下手的感觉。直到发现用K210开发板配合普通舵机就能搭建出反应灵敏的二维云台系统,整个过程就像拼乐高一样充满乐趣。本文将带你从零…...

【效率革命】PolyWindow插件:从多边形到精美窗户的3dMax一键生成秘籍
1. 为什么你需要PolyWindow插件? 如果你经常用3dMax做建筑可视化或室内设计,肯定遇到过这样的烦恼:项目里需要做几十个风格各异的窗户,每个都要手动建模、分格、赋材质,光是想到这个工作量就让人头皮发麻。我去年接的一…...

如何用applera1n免费绕过iOS激活锁:完整指南与操作教程
如何用applera1n免费绕过iOS激活锁:完整指南与操作教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否购买了一部二手iPhone或iPad,却发现设备被原主人的Apple ID锁定&a…...

Nestia:基于TypeScript编译时分析的NestJS端到端类型安全实践
1. 项目概述:当NestJS遇上TypeScript的极致类型安全如果你正在用NestJS开发后端API,并且对TypeScript的类型安全有近乎偏执的追求,那么你很可能已经听说过,或者正在寻找一个能让你“写一次,安全两次”的工具。我说的“…...

从零构建专属大语言模型:Self-LLM开源项目全流程实践指南
1. 项目概述与核心价值最近在开源社区里,一个名为datawhalechina/self-llm的项目引起了我的注意。乍一看,这像是一个关于大语言模型(LLM)的仓库,但“self”这个前缀又让人浮想联翩。经过一段时间的深入研究和实践&…...

gnamiblast-skill:基于技能化与管道化的智能文本处理工具解析
1. 项目概述与核心价值最近在GitHub上闲逛,又发现了一个挺有意思的项目,叫gabrivardqc123/gnamiblast-skill。光看这个名字,可能有点摸不着头脑,gnamiblast听起来像是个自造词,skill又指向了某种技能或功能。作为一名常…...

【最新v2.7.1 版本安装包】OpenClaw 小白入门必看,零基础无需命令零代码保姆级教学
OpenClaw v2.7.1 一键安装部署教程|可视化傻瓜式搭建 ✨适配系统:Windows10/11 64 位 ✨当前版本:v2.7.1 版本(虾壳云版) ✨安装包大小:58.7MB 【点击下载最新安装包】https://xiake.yun/api/download/…...

详解C++作用域与生命周期
Pascal之父Nicklaus Wirth曾经提出一个公式,展示出了程序的本质:程序算法数据结构。后人又给出一个公式与之遥相呼应:软件程序文档。这两个公式可以简洁明了的为我们展示程序和软件的组成。程序的运行过程可以理解为算法对数据的加工过程&…...