LoRA: Low-Rank Adaptation Abstract
LoRA: Low-Rank Adaptation Abstract

LoRA 论文的摘要介绍了一种用于减少大规模预训练模型微调过程中可训练参数数量和内存需求的方法,例如拥有1750亿参数的GPT-3。LoRA 通过冻结模型权重并引入可训练的低秩分解矩阵,减少了10,000倍的可训练参数,并降低了3倍的GPU内存使用量,同时在性能上与完全微调持平,并且没有额外的推理延迟。更多信息请访问 LoRA GitHub。
LoRA GitHub。
LoRA(低秩适配)的主要优势
- 共享预训练模型:LoRA 通过冻结预训练模型,并高效替换低秩矩阵,实现任务间的切换。
- 提升效率:LoRA 仅需训练注入的小型低秩矩阵,减少高达三倍的硬件需求。
- 无推理延迟:通过将可训练的矩阵与冻结的权重融合,不会引入额外的推理延迟。
- 兼容性:LoRA 与诸如前缀微调的许多方法兼容,增加了应用中的灵活性。
术语和约定:
这一部分介绍了 LoRA 论文中使用的术语和约定,包括自注意力机制中的投影矩阵 W q W_q Wq, W k W_k Wk, W v W_v Wv, 和 W o W_o Wo,以及预训练权重矩阵 W 0 W_0 W0,和梯度更新 Δ W \Delta W ΔW。
完全微调过程:
在完全微调过程中,模型初始化为预训练的权重 Φ 0 \Phi_0 Φ0,并通过梯度下降反复更新为 Φ 0 + Δ Φ \Phi_0 + \Delta \Phi Φ0+ΔΦ,以最大化条件语言建模的目标函数:
max Φ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( P Φ ( y t ∣ x , y < t ) ) \max_{\Phi} \sum_{(x,y) \in \mathcal{Z}} \sum_{t=1}^{|y|} \log \left( P_{\Phi} (y_t | x, y_{<t}) \right) Φmax(x,y)∈Z∑t=1∑∣y∣log(PΦ(yt∣x,y<t))
其中一个主要缺点是,对于每个下游任务,必须学习一组不同的参数 Δ Φ \Delta \Phi ΔΦ,其维度等于 ∣ Φ 0 ∣ |\Phi_0| ∣Φ0∣。因此,如果预训练模型很大(例如 GPT-3 具有约 1750 亿参数),存储和部署多个独立的微调模型将非常具有挑战性,甚至不可行。
为了解决这一问题,本文采用了一种更加高效的参数化方法,任务特定的参数增量 Δ Φ = Δ Φ ( Θ ) \Delta \Phi = \Delta \Phi (\Theta) ΔΦ=ΔΦ(Θ) 被进一步编码为一个更小的参数集 Θ \Theta Θ,其维度 ∣ Θ ∣ ≪ ∣ Φ 0 ∣ |\Theta| \ll |\Phi_0| ∣Θ∣≪∣Φ0∣。优化 Δ Φ \Delta \Phi ΔΦ 的任务变为优化 Θ \Theta Θ:
max Θ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( p Φ 0 + Δ Φ ( Θ ) ( y t ∣ x , y < t ) ) \max_{\Theta} \sum_{(x,y) \in \mathcal{Z}} \sum_{t=1}^{|y|} \log \left( p_{\Phi_0 + \Delta \Phi (\Theta)} (y_t | x, y_{<t}) \right) Θmax(x,y)∈Z∑t=1∑∣y∣log(pΦ0+ΔΦ(Θ)(yt∣x,y<t))
在随后的部分中,我们提出了一种使用低秩表示来编码 Δ Φ \Delta \Phi ΔΦ,这既高效又节省内存。对于 GPT-3 这种 1750 亿参数的预训练模型,可训练的参数 Θ \Theta Θ 数量可以小至 Φ 0 \Phi_0 Φ0 的 0.01%。
低秩参数化更新矩阵
神经网络包含许多执行矩阵乘法的全连接层。这些层中的权重矩阵通常具有全秩。在适应特定任务时,Aghajanyan 等(2020)指出,预训练语言模型具有低“内在维度”,即便在投影到较小子空间时仍能有效学习。
基于此,我们假设权重的更新在适应过程中也具有低“内在秩”。对于预训练权重矩阵 W 0 ∈ R d × k W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k,我们通过低秩分解 W 0 + Δ W = W 0 + B A W_0 + \Delta W = W_0 + BA W0+ΔW=W0+BA 来约束其更新,其中 B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r 和 A ∈ R r × k A \in \mathbb{R}^{r \times k} A∈Rr×k,且秩 r ≪ min ( d , k ) r \ll \min(d, k) r≪min(d,k)。
在训练过程中, W 0 W_0 W0 被冻结且不接受梯度更新,而 A A A 和 B B B 包含可训练参数。注意, W 0 W_0 W0 和 Δ W = B A \Delta W = BA ΔW=BA 使用相同输入进行乘法运算,输出向量按坐标相加。对于 h = W 0 x h = W_0 x h=W0x,我们修改后的前向传递变为:
h = W 0 x + Δ W x = W 0 x + B A x h = W_0 x + \Delta W x = W_0 x + BA x h=W0x+ΔWx=W0x+BAx
我们在图 1 中展示了这种重新参数化方法。我们为 A A A 使用随机高斯初始化,并将 B B B 初始化为零,因此在训练开始时 Δ W = B A \Delta W = BA ΔW=BA 为零。然后我们通过 α r \frac{\alpha}{r} rα 缩放 Δ W x \Delta W x ΔWx,其中 α \alpha α 是与 r r r 成比例的常数。当使用 Adam 优化时,调节 α \alpha α 与调节学习率基本相同。因此,我们简单地将 α \alpha α 设置为我们尝试的第一个 r r r,且不进行微调。此缩放有助于减少在变化 r r r 时重新调节超参数的需要。
这种高效的低秩方法大大减少了参数数量,使得在保持性能的同时可以进行高效微调。
更广泛的微调
LoRA 引入了一种更广泛的微调方法,允许我们仅训练预训练参数的一部分,而不需要积累梯度更新以使权重矩阵在适应过程中达到全秩。通过设置 LoRA 秩 ( r ) 等于预训练权重矩阵的秩,我们可以大致恢复完整微调的表现能力。随着可训练参数的增加,LoRA 训练逐渐逼近原始模型的训练结果,而其他基于适配器的方法则趋向于一个无法处理长输入的简单 MLP。
无额外推理延迟
LoRA 在推理过程中没有额外的延迟。我们可以显式计算并存储 W = W 0 + B A W = W_0 + BA W=W0+BA,并像往常一样执行推理。当需要切换任务时,我们可以通过减去 B A BA BA 并添加不同的 B ′ A ′ B'A' B′A′ 来恢复 W 0 W_0 W0,这是一个高效的操作,几乎没有内存开销。这确保了在推理过程中,不会引入比微调模型更多的延迟。
应用于 Transformer 的 LoRA
原则上,我们可以将 LoRA 应用于神经网络中的任何权重矩阵子集,以减少可训练参数的数量。在 Transformer 架构中,自注意力模块中的四个权重矩阵 ( W_q ), ( W_k ), ( W_v ), ( W_o ) 以及 MLP 模块中的两个矩阵被视为维度为 ( d_{\text{model}} \times d_{\text{model}} ) 的单一矩阵,尽管输出维度通常会被切割成注意力头。我们将研究仅限于适配注意力权重,冻结 MLP 模块(因此它们不会在下游任务中被训练),以简化操作并提高参数效率。我们进一步研究了不同类型的注意力权重矩阵在 Transformer 中的适配效果,详见 [Section 7.1]。至于适配 MLP 层、LayerNorm 层以及偏差权重的实证研究,则留待未来工作。
实际的优势与限制
最显著的优势来自于减少了内存和存储的使用。对于使用 Adam 优化器训练的大型 Transformer,VRAM 使用量可以减少最多 ( \frac{2}{3} ),如果 ( r \ll d_{\text{model}} ),因为我们无需存储被冻结参数的优化器状态。在 GPT-3 175B 模型上,我们将训练期间的 VRAM 消耗从 1.2TB 降低到 350GB。对于 ( r = 4 ),并且仅适配查询和值投影矩阵,检查点大小减少了约 ( 10,000 \times ) (从 350GB 到 35MB)
。这使得我们可以使用显著更少的 GPU 进行训练,并避免 I/O 瓶颈。另一个好处是,我们可以通过仅交换 LoRA 权重而不是所有参数,在任务之间动态切换。这使得可以创建许多定制模型,这些模型可以在机器上即时进行切换,存储在 VRAM 中的预训练权重不会被影响。在 GPT-3 175B 的训练过程中,与全微调相比,LoRA 还观察到了 25% 的加速,因为我们不需要为大多数参数计算梯度。
LoRA 也有其局限性。例如,将输入批量化到不同的任务并非易事。如果在前向传递中选择将 ( A ) 和 ( B ) 吸收到 ( W ) 中以消除额外的推理延迟,这会有一定的限制。尽管可以选择不合并权重,并动态选择 LoRA 模块以在延迟不重要的场景中使用批量样本。

该表(表 4)展示了在三个任务上应用各种适应方法的 GPT-3 175B 的性能:WikiSQL、MultiNLI-matched(MNLI-m)和 SAMSum。主要度量指标是 WikiSQL 和 MNLI-m 上的验证准确率,以及 SAMSum 上的 Rouge-1/2/L 得分。
以下是结果的详细说明:
-
GPT-3 (FT)(完全微调)是基准方法。它对整个 175B 参数进行训练,并在 WikiSQL 上达到 73.8% 的准确率,在 MNLI-m 上达到 89.5%,在 SAMSum 上的 Rouge-1/2/L 得分为 52.0/28.0/44.5。
-
GPT-3 (BitFit) 仅训练了 14.2M 参数,在 MNLI-m 上表现相似(91.0%),但在 WikiSQL 上的准确率略低(71.3%)。Rouge 得分也比完全微调略低。
-
GPT-3 (PreEmbed) 和 GPT-3 (PreLayer) 代表基于预训练嵌入和层的方法。这些方法在 WikiSQL 和 MNLI-m 上的表现相对较差,尤其是 PreEmbed 模型,与 LoRA 和完全微调相比得分显著较低。
-
GPT-3 (Adapter) 方法相较于完全微调训练的参数较少。高秩适配器(AdapterH)在 WikiSQL 上达到 73.2% 的准确率,在 MNLI-m 上达到最高的 91.5% 准确率,并且在 SAMSum 上表现良好(53.2/29.0/45.1)。
-
GPT-3 (LoRA):LoRA(低秩适应)与其他方法相比表现特别出色。LoRA 仅训练了 4.7M 参数,在 WikiSQL 上达到接近完全微调的准确率(73.4%),在 MNLI-m(91.7%)和 SAMSum(53.8/29.8/45.9)上表现更好。对于 37.7M 参数的 LoRA 模型,WikiSQL 得分更高(74.0%)。
总结:
- LoRA 在大多数任务上都优于其他适应方法,甚至在某些任务上超过了完全微调的性能,同时训练的参数远远少于完全微调。
- LoRA 减少了大规模微调的需求,同时在测试任务上仍能达到较高的准确率和 Rouge 得分。
相关文章:
LoRA: Low-Rank Adaptation Abstract
LoRA: Low-Rank Adaptation Abstract LoRA 论文的摘要介绍了一种用于减少大规模预训练模型微调过程中可训练参数数量和内存需求的方法,例如拥有1750亿参数的GPT-3。LoRA 通过冻结模型权重并引入可训练的低秩分解矩阵,减少了10,000倍的可训练参数…...

正点原子阿尔法ARM开发板-IMX6ULL(二)——介绍情况以及汇编
文章目录 一、裸机开发(21个)二、嵌入式Linux驱动例程三、汇编3.1 处理器内部数据传输指令3.2 存储器访问指令3.3 压栈和出栈指令3.4 跳转指令3.5 算术运算指令3.6 逻辑运算指令 一、裸机开发(21个) 二、嵌入式Linux驱动例程 三、…...
(一))
Unreal Engine——AI生成高精度的虚拟人物和环境(虚拟世界构建、电影场景生成)(一)
一、Unreal Engine 介绍 Unreal Engine(虚幻引擎)是由Epic Games开发的强大3D游戏开发引擎,自1998年首次发布以来,已经历了多个版本的迭代。虚幻引擎主要用于制作高品质的3D游戏,但也广泛用于电影、建筑、仿真等其他领…...

Emlog程序屏蔽用户IP拉黑名单插件
插件介绍 在很多时候我们需要得到用户的真实IP地址,例如,日志记录,地理定位,将用户信息,网站数据分析等,其实获取IP地址很简单,感兴趣的可以参考一下。 今天给大家带来舍力写的emlog插件:屏蔽…...
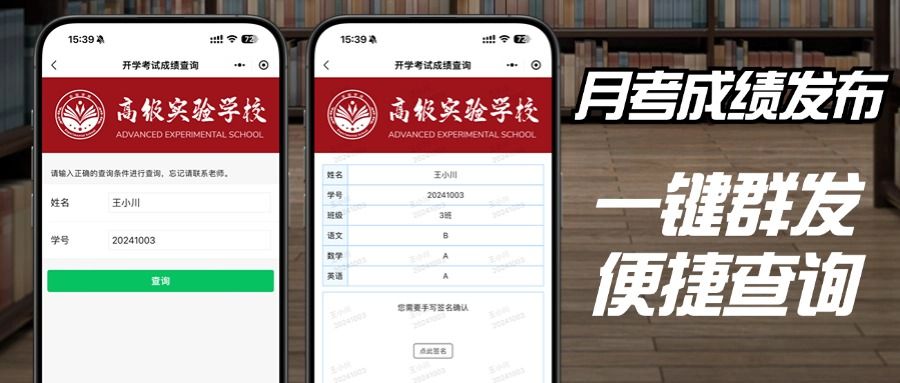
发送成绩的app或小程序推荐
老师们,新学期的第一次月考马上开始,是不是还在为如何高效、便捷地发布成绩而头疼呢?别担心,都2024年了,我们有更智能的方式来解决这个问题! 给大家安利一个超级实用的工具——易查分小程序。这个小程序简…...

51单片机-AT24C02(IIC总线介绍及其时序编写步骤)-第一节(下一节实战)
IIC开始通信(6大步) 我以前的文章也有对基本常用的通信协议讲解,如SPI UART IIC RS232 RS485 CAN的讲解,可前往主页查询,(2024.9.12,晚上20:53,将AT24C02存储芯片,掉电不…...

<<编码>> 第 11 章 逻辑门电路--或非门, 与非门, 缓冲器 示例电路
继电器或非门 info::操作说明 鼠标单击开关切换开合状态 闭合任意一个开关可使电路断开 primary::在线交互操作链接 https://cc.xiaogd.net/?startCircuitLinkhttps://book.xiaogd.net/code-hlchs-examples/assets/circuit/code-hlchs-ch11-19-nor-gate-by-relay.txt 或非门 i…...

股票api接口程序化报备,程序化交易监管对个人量化交易者有何影响
炒股自动化:申请官方API接口,散户也可以 python炒股自动化(0),申请券商API接口 python炒股自动化(1),量化交易接口区别 Python炒股自动化(2):获取…...

如何自己搭建一个网站?
今天的文章总结适合0基础,网站搭建的技巧和流程,哪怕你是小白,不会编程,也可以制作非常漂亮且实用的企业网站,如果想做个人博客更是不在话下。希望我的经验能帮助更多没有过多的经费、没有建站基础的朋友。用户跟着我的…...

虚拟化数据恢复—断电导致虚拟机目录项被破坏的数据恢复案例
虚拟化数据恢复环境: 某品牌服务器(部署VMware EXSI虚拟机)同品牌存储(存放虚拟机文件)。 虚拟化故障: 意外断电导致服务器上某台虚拟机无法正常启动。查看虚拟机配置文件发现这台故障虚拟机除了磁盘文件以…...

[机器学习]聚类算法
1 聚类算法简介 # 导包 from sklearn.datasets import make_blobs import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.metrics import calinski_harabasz_score # 构建数据 x,ymake_blobs(n_samples1000,n_features2,centers[[-1,-1],[0,0],[1…...

JVM面试真题总结(七)
文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 解释GC的引用计数算法及其局限性 引用计数算法是一种非常直观、简…...

深入理解CASAtomic原子操作类详解
1.CAS介绍 什么是 CAS CAS(Compare And Swap,比较与交换),是非阻塞同步的实现原理,它是CPU硬件层面的一种指令,从CPU层面能保证"比较与交换"两个操作的原子性。CAS指令操作包括三个参数&#x…...

C51单片机-单按键输入识别,键盘消抖
【实验目的】 独立按键的识别方法、键盘消抖等。 【实验现象】 每按一次独立键盘的S2键,与P1口相连的八个发光二极管中点亮的一个往下移动一位。 【实验说明】 关于按键去抖动的解释,我们在手动按键的时候,由于机械抖动或是其它一些非人为的因…...

基于CNN卷积神经网络迁移学习的图像识别实现
基于CNN卷积神经网络迁移学习的图像识别实现 基于CNN卷积神经网络迁移学习的图像识别实现写在前面一,原理介绍迁移学习的基本方法1.样本迁移(Instance based TL)2.特征迁移(Feature based TL)3.模型迁移(Pa…...

【iOS】push和present的区别
【iOS】push和present的区别 文章目录 【iOS】push和present的区别前言pushpop presentdismiss简单小demo来展示dismiss和presentdismiss多级 push和present的区别区别相同点 前言 在iOS开发中,我们经常性的会用到界面的一个切换的问题,这里我们需要理清…...

在Linux服务器上添加用户并设置自动登录
需要在Linux服务器上添加一个新用户,可以使用以下命令 # 这个命令会创建一个新的用户账户,默认情况下不会设置密码,不会在 /home 目录下为新用户创建home目录: # sudo useradd 用户名 # # 如果希望同时为新用户创建家目录&#…...

网站被爬,数据泄露,如何应对不断强化的安全危机?
近年来,众多传统零售商和互联网企业借助大数据、人工智能等先进技术手段,通过场景化设计、优化客户体验、融合线上线下渠道,推动了网络电商行业的消费方式变革,成为电商领域新的增长动力。 但值得注意的是,网络电商带来…...

为什么HTTPS会引入SSL/TLS协议
这时我面试遇到过的问题,整理了一下,希望对大家有帮助! 祝大家秋招顺利! 首先 SSL/TLS 协议通过使用数字证书来实现服务器身份认证, 当用户访问一个 HTTPS 网站时,浏览器会验证服务器的数字证书, 1.首先他对验证整证书是否在有效期 2.其次他会看证书中的服务器域名…...

Spring AOP,通知使用,spring事务管理,spring_web搭建
spring AOP AOP概述 AOP面向切面编程是对面向对象编程的延续(AOP (Aspect Orient Programming),直译过来就是 面向切面编程,AOP 是一种编程思想,是面向对象编程(OOP)的一种补充。) 面向切面编…...

柔性LED灯丝DIY:从电路原理到创意饰品制作全攻略
1. 项目概述:当生日遇上柔性LED灯丝给孩子的生日派对准备一份独一无二的、会发光的惊喜,是很多家长和手工爱好者的心愿。这次,我们不买现成的塑料灯牌,而是亲手做一个能戴在头上或挂在脖子上的“生日数字灯冠”。这个项目的核心&a…...

Windows平台QT BLE开发避坑指南:从环境搭建到稳定通信
1. Windows平台QT BLE开发环境搭建 在Windows平台上使用QT进行BLE开发,首先需要确保开发环境正确配置。我遇到过不少开发者因为环境问题卡在第一步,白白浪费好几天时间。这里分享几个关键点: 编译器选择是第一个坑。实测发现必须使用MSVC编译…...
Translumo:5分钟掌握Windows实时屏幕翻译终极指南
Translumo:5分钟掌握Windows实时屏幕翻译终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程
怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的旧Mac重新焕发活力吗…...

VectorDBBench:向量数据库性能基准测试工具详解与实战
1. 项目概述:向量数据库性能测试的“瑞士军刀”如果你正在评估或使用向量数据库,那么你一定遇到过这个灵魂拷问:“这么多产品,到底哪个最适合我的场景?”是选名声在外的老牌劲旅,还是选后起之秀的专精选手&…...

合宙Air153C看门狗芯片:嵌入式系统可靠性的硬件守护方案
1. 项目概述:一颗“小而美”的国产看门狗芯片最近在做一个低功耗的户外监测设备项目,主控用的就是合宙的Air系列MCU。在调试过程中,最让我头疼的就是系统偶尔的“死机”问题。设备部署在野外,不可能每次都跑过去手动重启。正当我琢…...

dotai:将AI大模型无缝集成到Shell终端的智能助手工具
1. 项目概述:当AI遇上你的终端如果你是一个重度命令行用户,每天在终端里敲击着ls、cd、git commit这些命令,有没有那么一瞬间,希望有个助手能帮你自动补全、解释命令,甚至直接帮你写出复杂的管道操作?dotai…...

LLM应用快速演示框架:从架构解析到智能体开发的实战指南
1. 项目概述:一个面向开发者的LLM应用快速演示框架最近在GitHub上闲逛,发现了一个名为wronai/llm-demo的项目,点进去一看,瞬间觉得眼前一亮。这可不是又一个简单的“Hello World”式的大语言模型调用示例,而是一个结构…...

Go语言SDK开发实战:为AI编程助手Cursor构建高效API客户端
1. 项目概述:一个为AI编程助手Cursor定制的Go语言SDK如果你和我一样,日常重度依赖Cursor这类AI编程助手来提升开发效率,同时又是个Go语言的忠实拥趸,那你肯定遇到过这样的场景:想用Go写个脚本,自动化处理一…...