ELK在Linux服务器下使用docker快速部署(超详细)
ELK是什么?
首先说说什么是ELK
ELK 是一个开源的日志管理和分析平台,由三个主要组件组成:
- Elasticsearch:一个分布式搜索和分析引擎,能够快速存储、搜索和分析大量数据。它是 ELK 堆栈的核心,负责数据的索引和查询。
- Logstash:一个数据处理管道,可以从多种来源收集数据,进行处理和转换,然后将数据发送到 Elasticsearch。Logstash 支持多种输入、过滤和输出插件,使其非常灵活。
- Kibana:一个数据可视化工具,允许用户通过图形界面查看和分析存储在 Elasticsearch 中的数据。用户可以创建仪表板、图表和其他可视化效果,以便更好地理解数据。
ELK 堆栈通常用于日志管理、监控和数据分析,广泛应用于 IT 运维、安全分析和业务智能等领域。通过 ELK,用户可以实时收集、分析和可视化数据,从而快速发现和解决问题。
用白话说:L用来将写的日志文件传输到E中,E可以理解为一个高性能的数据库,支持存储数据和查询,K用来将E中的数据用可视化页面展示出来。
这三个工具都是单独存在的,只是经常将它们组合在称为ELK,所以说如果有其他的工具可以代替其中一个,即可以代替使用,比如说ELK中的L,它功能很多,但是占用内存太多了,轻量级的filebeat就可以适用大多数情况,其简化了部署和配置过程,还通过SSL/TLS支持确保了数据传输的安全性,减少了对系统资源的占用。通过filebeat可以收集多种不同格式的数据,并转换成es可以分辨的格式(如json)存入es中指定的索引中,之后就可以用过kibana查看es中收到的数据。
E中的索引:是一个逻辑命名空间,包含一组相关的文档,类似于传统关系型数据库中的数据库。
ES中的文档:是 Elasticsearch 中存储的基本数据单元,表示一条记录或一项数据,类似于数据库中的一行。
字段(Field):文档由若干字段组成,每个字段有一个字段名和字段值,字段值可以是多种类型,如字符串、数字、日期等。
具体实现
前言
以下步骤是用的aliyun的linux服务器,只要你用的是linux服务器就大差不差都能使用ip地址为:121.196.217.190
在代码中如果有使用到ip地址的请记得把 ip 地址替换!
还有如果用的是服务器的话,记得要把端口开放,不然外部浏览器是进不去容器使用的端口,这里要用到的端口是9200、9300、5601,还有防火墙问题朋友请自行解决。
安装的时候最好统一版本,否则会出现很多问题,我这里使用的版本都是7.12.1版本,拉取镜像的时候统一加上该版本号。
Docker 搭建ELK之前最好熟悉docker的相关指令:比如容器卷使用 docker run -d -v myvolume:/data myimage、强制删除容器: docker rm -f 容器id、创建网络: docker network create elk、进入容器docker exec -it es /bin/bash等等。
在后面的步骤中我也会简短的介绍这些命令的作用,还是看不懂的可以无脑复制粘贴,或者去gpt再详细搜一下命令的作用。
为了方便所有容器的挂载,先创建如下目录 /usr/local/elk,再执行mkdir /usr/local/elk/{elasticsearch,kibana} 创建2个对应的目录,所以以下操作如无特别说明,均在 /usr/local/elk下执行。
为了容器间的通信,需要先用 docker 创建一个网络:
docker network create --subnet=192.168.0.0/16 elk
至于为什么网络用的是192.168.0.0/16 朋友们可以自己去搜一下。略:其实没什么特殊要求,你想的话也可以改,
一、Docker 安装 ElasticSearch
1、拉取镜像
docker pull elasticsearch:7.12.1
2、检查是否拉取成功 运行后看到自己的镜像排列其中即拉取成功
docker images
3、运行容器,并将容器内部的配置文件复制一份到容器外。
# 运行 elasticsearch
docker run -d --name es --net elk -P -e "discovery.type=single-node" elasticsearch:7.12.1
docker run:Docker CLI 的命令,用于创建并启动一个新的容器。-d:表示以 detached 模式运行容器,即在后台运行。--name es:为容器指定一个名称,这里名称为es。--net elk:指定容器要加入的网络,这里使用的是名为elk的网络。-P:将容器的端口映射到宿主机的随机端口上。这使得可以从宿主机访问容器的端口。-e "discovery.type=single-node":设置环境变量discovery.type为single-node。这是 Elasticsearch 的配置,表示以单节点模式运行,不需要集群模式的发现过程。elasticsearch:7.12.1:指定要使用的镜像名称和标签,这里使用的是elasticsearch镜像的7.12.1版本。
# 进入容器查看配置文件路径
docker exec -it es /bin/bash
cd config
docker exec:Docker CLI 的命令,用于在运行中的容器内执行命令。-it:这两个参数组合在一起,-i表示交互式(interactive),-t表示分配一个伪终端(pseudo-TTY)。它们使得你可以与容器内运行的命令进行交互。es:指定要执行命令的容器的名称或 ID。在这个例子中,容器名称是es。/bin/bash:这是要在容器内执行的命令,即启动 Bash shell。
4、容器化配置
在 config 中使用ls命令可以看到 elasticsearch.yml 配置文件,再执行 pwd 命令可以看到当前目录为: /usr/share/elasticsearch/config,后用命令exit退出容器,开始执行文件的拷贝:
# 将容器内的配置文件拷贝到 /usr/local/elk/elasticsearch/ 中
docker cp es:/usr/share/elasticsearch/config/elasticsearch.yml elasticsearch/# 修改文件权限
chmod 666 elasticsearch/elasticsearch.yml# 在elasticsearch 目录下再创建data目录,同时修改权限
mkdir elasticsearch/data
chmod -R 777 elasticsearch/data
这里进行修改文件权限只是为了在进行挂载后,在外部修改配置文件,容器内部的配置文件也会更改。
5、重新运行容器并挂载刚才创建的文件
# 先删除旧的容器
docker rm -f es# 运行新的容器
docker run -d --name es \
--net elk \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
--privileged=true \
-v $PWD/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v $PWD/elasticsearch/data/:/usr/share/elasticsearch/data \
elasticsearch:7.12.1
-v $PWD/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml:
- 将宿主机当前目录下的
elasticsearch/elasticsearch.yml文件挂载到容器的 Elasticsearch 配置目录中,用于自定义 Elasticsearch 配置。
-v $PWD/elasticsearch/data/:/usr/share/elasticsearch/data:
- 将宿主机当前目录下的
elasticsearch/data/目录挂载到容器的 Elasticsearch 数据目录中,用于持久化存储 Elasticsearch 数据。
此时使用 docker ps 即可查看已经运行的容器有哪些,此时使用curl 121.196.217.190:9200 或者直接去浏览器输入121.196.217.190:9200查看elasticsearch有没有启动成功,下面就是成功的样子。

到此为止容器elasticsearch安装完成,之后因为data已经挂载了,在data下可以查看容器内的数据。在宿主机修改也会同步到容器内部。
6、es认证
进入到vi elasticsearch/elasticsearch.yml 进行操作添加配置进入vim操作后,摁下 i进入插入模式将以下内容添加进去。
http.cors.enabled: true
http.cors.allow-origin: "*"xpack.security.enabled: true
xpack.security.audit.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true
添加好使用命令esc + : + wq!后摁下enter就修改配置好了,可以使用cat elasticsearch/elasticsearch.yml 进行查看。
之后重启es 使用命令docker restart es
此时进入到es容器中docker exec -it es /bin/bash 进入到bin文件夹中cd bin
运行以下命令
./elasticsearch-setup-passwords interactive
之后就可以让你输入密码了,建议都输入成一样的,比如abcdef,
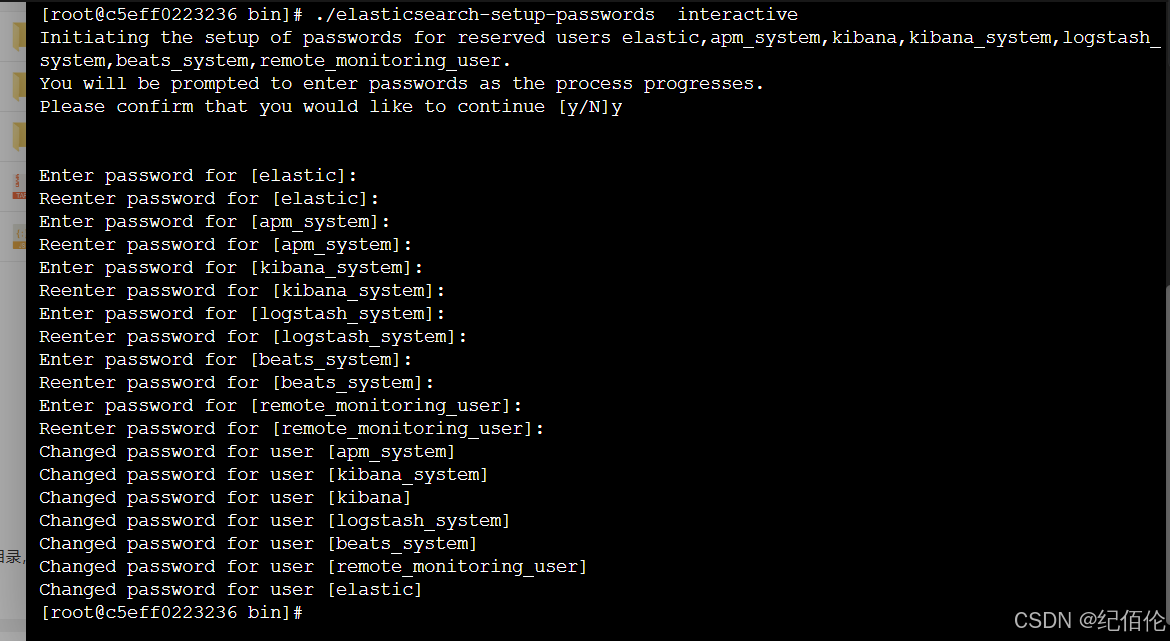
之后可以换个浏览器(怕当前浏览器有缓存)再输入121.196.217.190:9200 发现有弹窗让你输入账号密码,说明es认证成功了,
账号默认是elastic 密码就是刚才自己输入的那个

二、Docker 安装 Kibana
1、拉取镜像
docker pull kibana:7.12.1
2、检查是否拉取成功 运行后看到自己的镜像排列其中即拉取成功
docker images
3、启动
# 启动 kibana 容器并连接同一网络elk
docker run -d --name kibana --net elk -P -e "ELASTICSEARCH_HOSTS=http://es:9200" -e "I18N_LOCALE=zh-CN" kibana:7.12.1
-e “ELASTICSEARCH_HOSTS=http://es:9200” 表示连接刚才启动的 elasticsearch 容器,因为在同一网络(elk)中,地址可直接填 容器名+端口,即 es:9200, 也可以填 http://121.196.217.190:9200,即 http://ip:端口
4、拷贝文件
docker cp kibana:/usr/share/kibana/config/kibana.yml kibana/chmod 666 kibana/kibana.yml
之后打开配置文件修改内容
修改es的地址为自己的ip,添加账号密码和添加i18n.locale: zh-CN将kibana改为汉化版本。
注意:账号密码都要用“”包围 比如“elastic"/“abcdef”
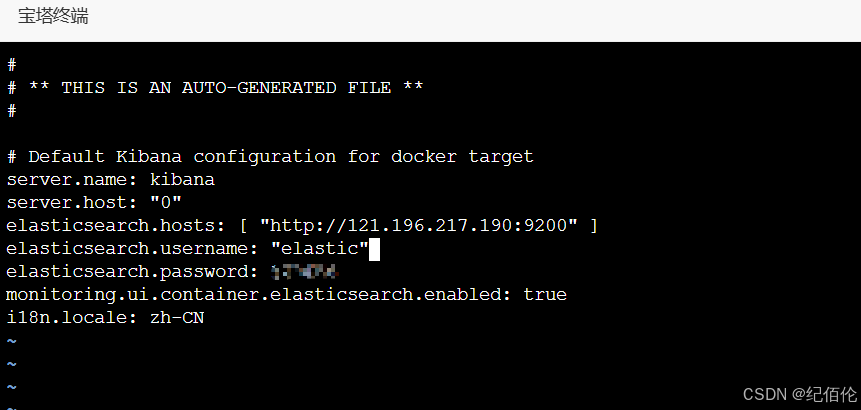
这样有了配置文件,在启动容器时就不用通过 -e 指定环境变量了。
5、重新开个容器
#删除原来未挂载的容器
docker rm -f kibana# 启动容器并挂载
docker run -d --name kibana \
-p 5601:5601 \
-v $PWD/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml \
--net elk \
--privileged=true \
kibana:7.12.1
等待两秒后浏览器输入看是否成功http://121.196.217.190:5601 打开 kibana 控制台,就能看到可视化页面了,如果失败了可以使用: docker logs kibana 查看容器日志看是否运行有误等。
至此:ELK中的EK已经完成!
最后就看L了,这里就直接配置一个filebeat
三、配置filebeat
filebeat不用docker下载了,可以直接使用wget下载
# 进入elk文件夹后
# 下载
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.8.1-linux-x86_64.tar.gz
# 解压文件
tar -zxvf filebeat-8.8.1-linux-x86_64.tar.gz
# 重命名
mv filebeat-8.8.1-linux-x86_64 filebeat
elk在宝塔中的简单部署和使用_宝塔 elasticsearch-CSDN博客
可以先看看这个博主的后半段。
相关文章:
ELK在Linux服务器下使用docker快速部署(超详细)
ELK是什么? 首先说说什么是ELK ELK 是一个开源的日志管理和分析平台,由三个主要组件组成: Elasticsearch:一个分布式搜索和分析引擎,能够快速存储、搜索和分析大量数据。它是 ELK 堆栈的核心,负责数据的…...
unity导入半透明webm + AE合成半透明视频
有些webm的文件导入unity后无法正常播报,踩坑好久才知道需要webm中的:VP8 标准 现在手上有几条mp4双通道的视频,当然unity中有插件是可以支持这种视频的,为了省事和代码洁癖,毅然决然要webm走到黑。 mp4导入AE合成半透…...

力扣: 四数相加II
文章目录 需求代码结尾 需求 给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 < i, j, k, l < n nums1[i] nums2[j] nums3[k] nums4[l] 0 示例 1: 输入…...

径向基函数神经网络RBFNN案例实操
简介 (来自ChatGPT的介绍,如有更正建议请指出) 径向基函数神经网络(Radial Basis Function Neural Network, RBFNN)是一种特殊的前馈神经网络,其结构和特点与其他常见的神经网络有所不同,主要表现在以下几个方面: 网络结构三层结构:RBF神经网络通常由三层组成:输入层…...

Java-数据结构-二叉树-习题(一) (✪ω✪)
文本目录: ❄️一、习题一(检查两颗树是否相同): ▶ 思路: ▶ 代码: ❄️二、习题二(另一棵树的子树): ▶ 思路: ▶ 代码: ❄️三、习题三(翻转二叉树): ▶ 思路: ▶ 代…...

js 时间戳转日期格式
timestampToDate(obj.project_time), import moment from “moment”; const timestampToDate (timestamp: any) > { const date new Date(timestamp * 1000); const newDate moment(date).format(“YYYY-MM-DD”); return newDate; // 使用Intl.DateTimeFormat进行格式…...

基于人工智能的自动驾驶系统项目教学指南
自动驾驶系统是人工智能的一个核心应用领域,涉及多个学科的交叉:从计算机视觉、深度学习、传感器融合到控制系统,自动驾驶项目可以提供高度的挑战性和实践意义。在这篇文章中,我们将构建一个基于深度学习的自动驾驶系统的简化版本…...
[Linux#49][UDP] 2w字详解 | socketaddr | 常用API | 实操:实现简易Udp传输
目录 套接字地址结构(sockaddr) 1.Socket API 2.sockaddr结构 3. sockaddr、sockaddr_in 和 sockaddr_un 的关系 sockaddr 结构体 sockaddr_in 结构体(IPv4 套接字地址) sockaddr_un 结构体(Unix域套接字地址&a…...

期权组合策略有什么风险?期权组合策略是什么?
今天期权懂带你了解期权组合策略有什么风险?期权组合策略是什么?期权组合策略是通过结合不同期权合约(如看涨期权和看跌期权),以及标的资产(如股票)来实现特定投资目标的策略。 期权组合策略市…...

从Zotero6到Zotero7的数据迁移尝试?(有错勿喷,多多指教!)
从Zotero6到Zotero7的数据迁移尝试 0 前言 之前在主机上一直用的Zotero6(实验室主机),最近发现在个人笔记本上看论文更频繁,尝试重新部署Zotero,才发现竟然更新了!所以这里简单记录一下数据迁移过程&…...
快速排序(分治思想)
什么是快速排序 快速排序(Quick Sort)是一种广泛使用的高效排序算法,由计算机科学家托尼霍尔在1960年提出。它采用分治法(Divide and Conquer)策略,将一个大数组分为两个小数组,然后递归地对这两…...

JAVA相关知识
JAVA基础知识 说一下对象创建的过程? 类加载检查:当Java虚拟机(JVM)遇到一个类的new指令时,它首先检查这个类是否已经被加载、链接和初始化。如果没有,JVM会通过类加载器(ClassLoaderÿ…...

详解TCP的三次握手
TCP(三次握手)是指在建立一个可靠的传输控制协议 (TCP) 连接时,客户端和服务器之间的三步交互过程。这个过程的主要目的是确保连接是可靠的、双方的发送与接收能力是正常的,并且可以开始数据传输。下面是对每个步骤的详细解释&…...
Java面试篇基础部分-Java创建线程详解
导语 多线程的方式能够在操作系统的多核配置上更好的利用服务器的多个CPU的资源,这样的操作可以使得程序运行起来更加高效。Java中多线程机制提供了在一个进程内并发去执行多个线程,并且每个线程都并行的去执行属于线程处理的自己的任务,这样可以提高程序的执行效率,让…...
Ubuntu 20.04/22.04无法连接网络(网络图标丢失、找不到网卡)的解决方案
问题复述: Ubuntu 20.04无法连接到网络,网络连接图标丢失,网络设置中无网络设置选项。 解决方案 对于Ubuntu 20.04而言:逐条执行 sudo service network-manager stopsudo rm /var/lib/NetworkManager/NetworkManager.statesudo…...
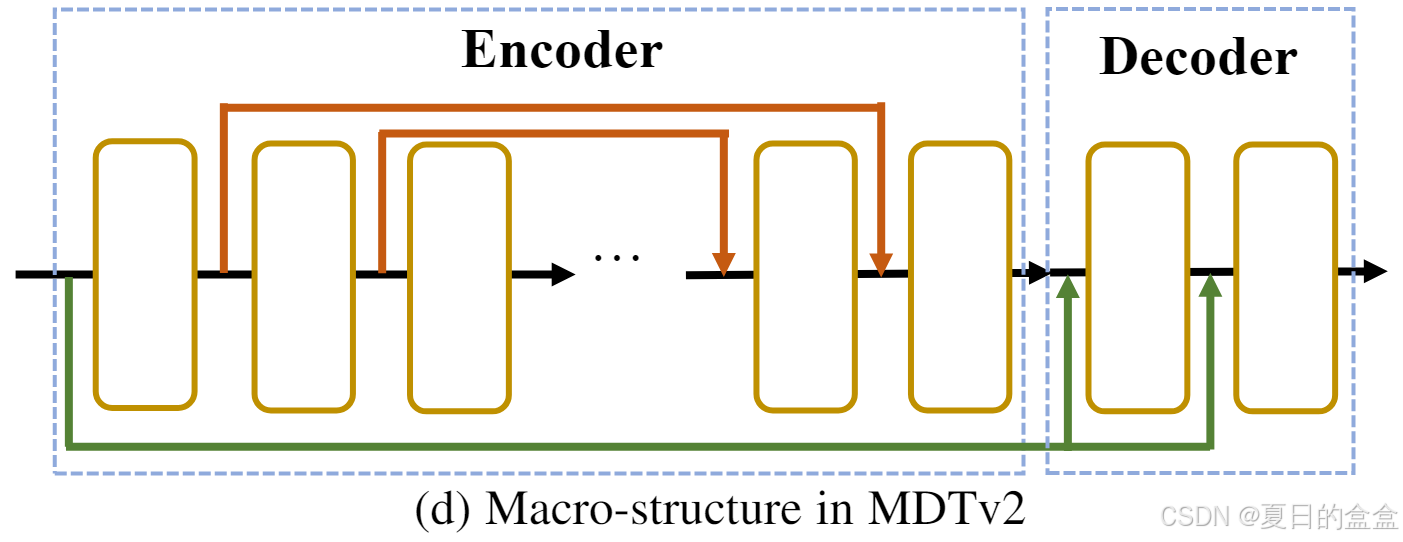
《MDTv2- Masked Diffusion Transformer is a Strong Image Synthesizer》
论文摘要 论文提出了一种名为**Masked Diffusion Transformer (MDT)**的新模型,旨在增强扩散概率模型(DPMs)在图像合成中的上下文推理能力。通过引入掩码潜在建模方案,MDT能够显著提升DPMs在图像中对象部分之间关系的学习能力&am…...

算法 - 二分查找
算法 - 二分查找 今天继续八股文学习,看一下比较常规的几个算法 二分查找是一个基于分治策略的搜索方法,简单的理解就是每次都缩小一轮搜索范围,从中间search一次,直到搜索到结果或者为空为止。 基本思路(设一个有序的…...

Python知识点:如何使用Python进行图像批处理
在Python中进行图像批处理可以使用多种库,如 Pillow、OpenCV 和 imageio。这些库可以用来执行各种图像处理任务,如调整大小、裁剪、旋转、滤镜应用等。以下是使用这些库进行图像批处理的示例。 使用 Pillow 进行图像批处理 Pillow 是一个功能强大的图像…...

数据结构实验1
实验题1:求1到n的连续整数和 题目描述 编写一个程序,对于给定的正整数n,求12…十n,采用逐个累加与(n1)/2(高斯法)两种解法。对于相同的n,给出这两种解法的求和结果和求解时间,并用相关数据进行测试。 运行代码 //实验题1:求1到n的连续整数和 #includ…...

使用Postman+JMeter进行简单的接口测试
以前每次学习接口测试都是百度,查看相关人员的实战经验,没有结合自己公司项目接口真正具体情况。 这里简单分享一下公司项目Web平台的一个查询接口,我会使用2种工具Postman和JMeter如何对同一个接口做调试。 准备工作 首先,登录公…...

猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧
猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&#…...

基于Sovereign-MCP-Servers构建私有AI工具链:从协议原理到Docker化部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给Claude、Cursor这类工具加上“联网”和“执行”能力时,绕不开一个概念:MCP(Model Context Protocol)。简单说,MCP就是一套标准协议,它能让…...
)
用STM32+LoRa+阿里云IoT Studio,我DIY了一个低成本畜牧电子围栏(附完整代码)
基于STM32与LoRa的智能畜牧围栏系统开发实战 在广袤的牧区,牲畜走失一直是困扰牧民的核心问题。传统物理围栏不仅成本高昂,在草原这类开放地形中实施难度也很大。本文将详细介绍如何利用STM32微控制器、LoRa远距离通信模块和阿里云IoT Studio平台&#x…...

【Midjourney图像生成黑科技】:树胶重铬酸盐工艺原理、复刻难点与AI艺术胶片质感还原全流程指南
更多请点击: https://intelliparadigm.com 第一章:树胶重铬酸盐工艺的历史溯源与数字时代复兴意义 树胶重铬酸盐工艺(Gum Bichromate Process)诞生于19世纪中叶,是人类最早实现光敏图像复制的化学摄影术之一。其核心原…...
)
多语种出海必备,ElevenLabs菲律宾文语音质量实测对比:Wavenet vs. Instant Voice vs. Custom Model(附MOS评分表)
更多请点击: https://intelliparadigm.com 第一章:多语种出海语音技术演进与菲律宾语本地化挑战 随着全球数字服务加速出海,语音交互系统正从单语种向多语种、低资源语言深度拓展。菲律宾语(Filipino/Tagalog)作为东…...

Pro Trinket:Arduino UNO的紧凑型替代方案与双模编程实战
1. Pro Trinket:当Arduino遇上“口袋工程学”如果你和我一样,在创客圈子里摸爬滚打多年,肯定经历过这样的场景:一个基于Arduino UNO的酷炫原型在面包板上运行得风生水起,但当你试图把它塞进一个精致的3D打印外壳&#…...

DeepMind Lab:强化学习研究的3D视觉仿真平台搭建与实战指南
1. 项目概述:一个被低估的强化学习研究“健身房”如果你在深度强化学习(Deep Reinforcement Learning, DRL)这个圈子里待过一段时间,或者正试图入门,那么你大概率听说过OpenAI的Gym、Unity的ML-Agents,甚至…...

大语言模型长上下文建模:从注意力优化到Mamba架构的工程实践
1. 项目概述:为什么长上下文建模是LLM的“圣杯”?如果你在过去一年里深度使用过任何主流的大语言模型,无论是ChatGPT、Claude还是开源的Llama、Qwen,一个共同的痛点一定让你印象深刻:“它好像不记得我们之前聊了什么”…...

多机驱动振动系统同步控制理论【附模型】
✨ 长期致力于振动机械、自同步、控制同步、GA-BP PID、定速比研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)GA-BP神经网络PID控制器设计及其参数自…...

子高斯随机变量与深度学习异常检测原理
1. 子高斯随机变量基础解析子高斯随机变量是概率论中一类具有特殊尾部性质的分布。简单来说,一个随机变量X如果满足存在常数σ>0,使得对于所有λ∈R都有E[exp(λX)] ≤ exp(λσ/2),那么我们就称X是σ-子高斯的。这类分布的关键特征是它们…...