Kafka【十四】生产者发送消息时的消息分区策略
【1】分区策略
Kafka中Topic是对数据逻辑上的分类,而Partition才是数据真正存储的物理位置。所以在生产数据时,如果只是指定Topic的名称,其实Kafka是不知道将数据发送到哪一个Broker节点的。我们可以在构建数据传递Topic参数的同时,也可以指定数据存储的分区编号。

指定分区传递数据是没有任何问题的。Kafka会进行基本简单的校验,比如是否为空,是否小于0之类的。但是你的分区是否存在就无法判断了,所以需要从Kafka中获取集群元数据信息,此时会因为长时间获取不到元数据信息而出现超时异常。所以如果不能确定分区编号范围的情况,不指定分区还是一个不错的选择。
如果不指定分区,Kafka会根据集群元数据中的主题分区来通过算法来计算分区编号并设定:
(1) 如果指定了分区,直接使用
(2) 如果指定了自己的分区器,通过分区器计算分区编号,如果有效,直接使用
(3) 如果指定了数据Key,且使用Key选择分区的场合,采用murmur2非加密散列算法(类似于hash)计算数据Key序列化后的值的散列值,然后对主题分区数量模运算取余,最后的结果就是分区编号

(4) 如果未指定数据Key,或不使用Key选择分区,那么Kafka会采用优化后的粘性分区策略进行分区选择:
- 没有分区数据加载状态信息时,会从分区列表中随机选择一个分区。

- 如果存在分区数据加载状态信息时,
- 根据分区数据队列加载状态,通过随机数获取一个权重值。
- 根据这个权重值在队列加载状态中进行二分查找法,查找权重值的索引值。
- 将这个索引值加1就是当前设定的分区。
增加数据后,会根据当前粘性分区中生产的数据量进行判断,是不是需要切换其他的分区。判断标准就是大于等于批次大小(16K)的2倍,或大于一个批次大小(16K)且需要切换。如果满足条件,下一条数据就会放置到其他分区。
【2】分区器
在某些场合中,指定的数据我们是需要根据自身的业务逻辑发往指定的分区的。所以需要自己定义分区编号规则,而不是采用Kafka自动设置。Kafka早期版本中提供了两个分区器,不过在当前kafka版本中已经不推荐使用了。
自定义分区器
首先我们需要创建一个类,然后实现Kafka提供的分区类接口Partitioner,接下来重写方法。这里我们只关注partition方法即可,因为此方法的返回结果就是需要的分区编号。
/*** TODO 自定义分区器实现步骤:* 1. 实现Partitioner接口* 2. 重写方法* partition : 返回分区编号,从0开始* close* configure*/
public class KafkaPartitionerMock implements Partitioner {/*** 分区算法 - 根据业务自行定义即可* @param topic The topic name* @param key The key to partition on (or null if no key)* @param keyBytes The serialized key to partition on( or null if no key)* @param value The value to partition on or null* @param valueBytes The serialized value to partition on or null* @param cluster The current cluster metadata* @return 分区编号,从0开始*/@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {return 0;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
配置分区器
public class ProducerPartitionTest {public static void main(String[] args) {Map<String, Object> configMap = new HashMap<>();configMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configMap.put( ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());configMap.put( ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 这里配置自定义分区器configMap.put( ProducerConfig.PARTITIONER_CLASS_CONFIG, KafkaPartitionerMock.class.getName());KafkaProducer<String, String> producer = null;try {producer = new KafkaProducer<>(configMap);for ( int i = 0; i < 1; i++ ) {ProducerRecord<String, String> record = new ProducerRecord<String, String>("test", "key" + i, "value" + i);final Future<RecordMetadata> send = producer.send(record, new Callback() {public void onCompletion(RecordMetadata recordMetadata, Exception e) {if ( e != null ) {e.printStackTrace();} else {System.out.println("数据发送成功:" + record.key() + "," + record.value());}}});}} catch ( Exception e ) {e.printStackTrace();} finally {if ( producer != null ) {producer.close();}}}
}
相关文章:
Kafka【十四】生产者发送消息时的消息分区策略
【1】分区策略 Kafka中Topic是对数据逻辑上的分类,而Partition才是数据真正存储的物理位置。所以在生产数据时,如果只是指定Topic的名称,其实Kafka是不知道将数据发送到哪一个Broker节点的。我们可以在构建数据传递Topic参数的同时ÿ…...

SQL优化:执行计划详细分析
视频讲解:SQL优化:SQL执行计划详细分析_哔哩哔哩_bilibili 1.1 执行计划详解 id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1.1.1 ID 【概…...

Android Studio -> Android Studio 获取release模式和debug模式的APK
Android Studio上鼠标修改构建类型 Release版本 激活路径:More tool windows->Build Variants->Active Build Variant->releaseAPK路径:Project\app\build\intermediates\apk\app-release.apk Debug版本 激活路径:More tool w…...

基于 SpringBoot 的实习管理系统
专业团队,咨询送免费开题报告,大家可以来留言。 摘 要 随着信息化时代的到来,管理系统都趋向于智能化、系统化,实习管理也不例外,但目前国内仍都使用人工管理,市场规模越来越大,同时信息量也越…...

vmware workstation 17 linux版
链接: https://pan.baidu.com/s/1F3kpNEi_2GZW0FHUO-8p-g?pwd6666 提取码: 6666 1 先安装虚拟机 不管什么错误 先安装vmware workstation 17 2 编译 覆盖安装vmware-host-modules-workstation-17.5.1 只需这样就可以 # sudo apt install dkms build-essential bc iw…...

Windows环境本地部署Oracle 19c及卸载实操手册
前言: 一直在做其他测试,貌似都忘了Windows环境oracle 19c的部署,这是一个很早很早的安装记录了,放上来做个备录给到大家参考。 Oracle 19c:进一步增强了自动化功能,并提供了更好的性能和安全性。这个版本在自动化、性能和安全性方面进行了重大改进,以满足现代企业对数…...
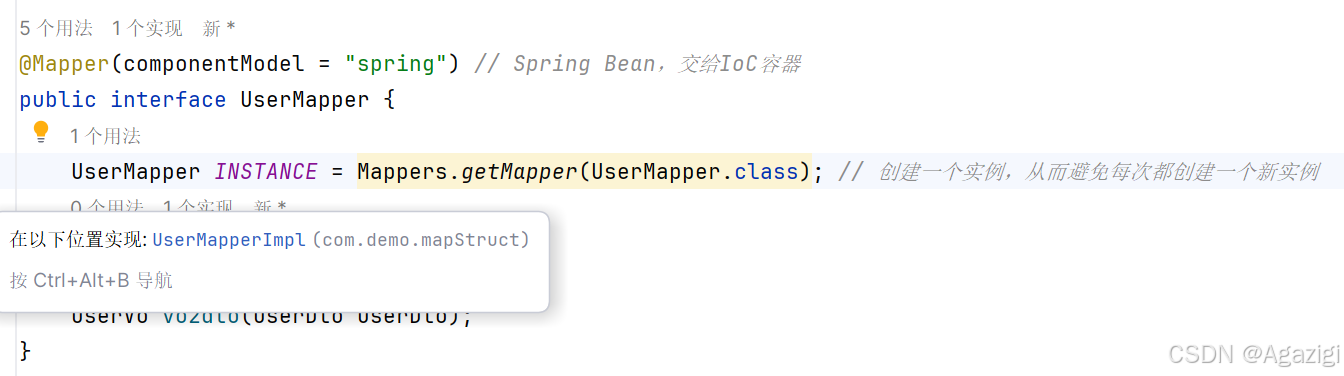
MapStruct介绍
一、MapStruct 1.1何为MapStruct 要说这个东西,其实和我们刚刚讲到的Lombok相类似。其是由我们的源代码加上MapStruct经过编译后得到.class文件,文件中自动补全了代码。那么补全了什么代码?实现了什么功能? MapStruct的产生&…...

35天学习小结
距离上次纪念日,已经过去了35天咯 算算也有5周了,在这一个月里,收获的也挺多,在这个过程中认识的大佬也是越来越多了hh 学到的东西,其实也没有很多,这个暑假多多少少还是有遗憾的~ 第一周 学习了一些有…...

【iOS】UIViewController的生命周期
UIViewController的生命周期 文章目录 UIViewController的生命周期前言UIViewController的一个结构UIViewController的函数的执行顺序运行代码viewWillAppear && viewDidAppear多个视图控制器跳转时的生命周期pushpresent 小结 前言 之前对于有关于UIViewControlller的…...
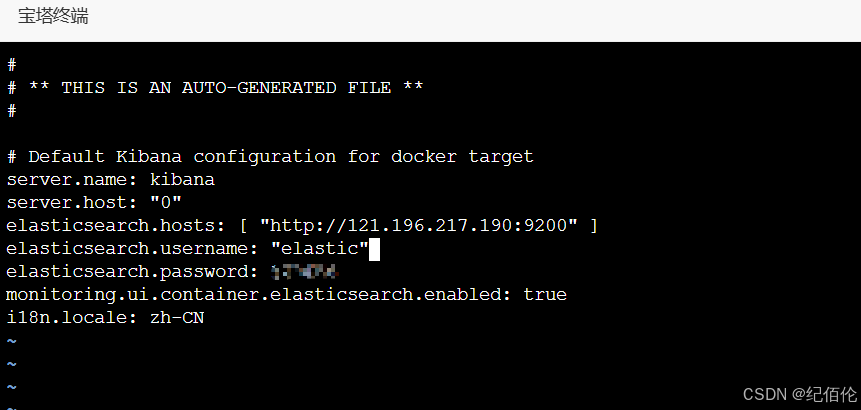
ELK在Linux服务器下使用docker快速部署(超详细)
ELK是什么? 首先说说什么是ELK ELK 是一个开源的日志管理和分析平台,由三个主要组件组成: Elasticsearch:一个分布式搜索和分析引擎,能够快速存储、搜索和分析大量数据。它是 ELK 堆栈的核心,负责数据的…...
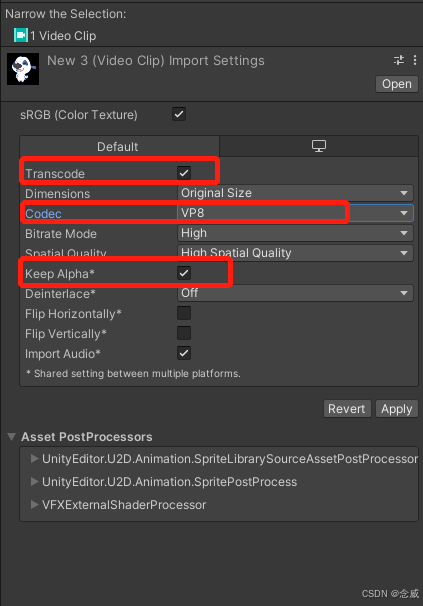
unity导入半透明webm + AE合成半透明视频
有些webm的文件导入unity后无法正常播报,踩坑好久才知道需要webm中的:VP8 标准 现在手上有几条mp4双通道的视频,当然unity中有插件是可以支持这种视频的,为了省事和代码洁癖,毅然决然要webm走到黑。 mp4导入AE合成半透…...

力扣: 四数相加II
文章目录 需求代码结尾 需求 给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 < i, j, k, l < n nums1[i] nums2[j] nums3[k] nums4[l] 0 示例 1: 输入…...

径向基函数神经网络RBFNN案例实操
简介 (来自ChatGPT的介绍,如有更正建议请指出) 径向基函数神经网络(Radial Basis Function Neural Network, RBFNN)是一种特殊的前馈神经网络,其结构和特点与其他常见的神经网络有所不同,主要表现在以下几个方面: 网络结构三层结构:RBF神经网络通常由三层组成:输入层…...

Java-数据结构-二叉树-习题(一) (✪ω✪)
文本目录: ❄️一、习题一(检查两颗树是否相同): ▶ 思路: ▶ 代码: ❄️二、习题二(另一棵树的子树): ▶ 思路: ▶ 代码: ❄️三、习题三(翻转二叉树): ▶ 思路: ▶ 代…...

js 时间戳转日期格式
timestampToDate(obj.project_time), import moment from “moment”; const timestampToDate (timestamp: any) > { const date new Date(timestamp * 1000); const newDate moment(date).format(“YYYY-MM-DD”); return newDate; // 使用Intl.DateTimeFormat进行格式…...

基于人工智能的自动驾驶系统项目教学指南
自动驾驶系统是人工智能的一个核心应用领域,涉及多个学科的交叉:从计算机视觉、深度学习、传感器融合到控制系统,自动驾驶项目可以提供高度的挑战性和实践意义。在这篇文章中,我们将构建一个基于深度学习的自动驾驶系统的简化版本…...
[Linux#49][UDP] 2w字详解 | socketaddr | 常用API | 实操:实现简易Udp传输
目录 套接字地址结构(sockaddr) 1.Socket API 2.sockaddr结构 3. sockaddr、sockaddr_in 和 sockaddr_un 的关系 sockaddr 结构体 sockaddr_in 结构体(IPv4 套接字地址) sockaddr_un 结构体(Unix域套接字地址&a…...

期权组合策略有什么风险?期权组合策略是什么?
今天期权懂带你了解期权组合策略有什么风险?期权组合策略是什么?期权组合策略是通过结合不同期权合约(如看涨期权和看跌期权),以及标的资产(如股票)来实现特定投资目标的策略。 期权组合策略市…...

从Zotero6到Zotero7的数据迁移尝试?(有错勿喷,多多指教!)
从Zotero6到Zotero7的数据迁移尝试 0 前言 之前在主机上一直用的Zotero6(实验室主机),最近发现在个人笔记本上看论文更频繁,尝试重新部署Zotero,才发现竟然更新了!所以这里简单记录一下数据迁移过程&…...
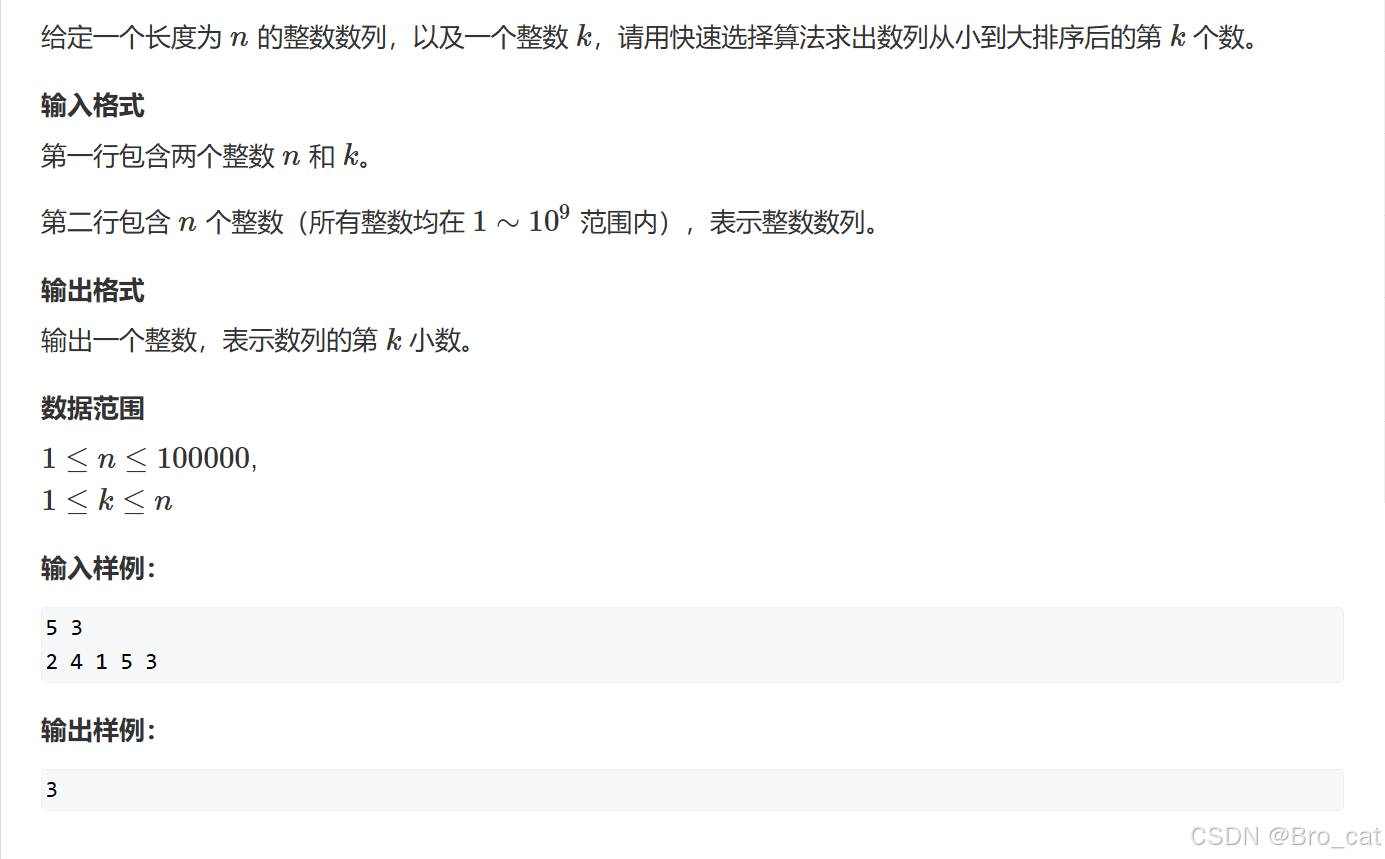
快速排序(分治思想)
什么是快速排序 快速排序(Quick Sort)是一种广泛使用的高效排序算法,由计算机科学家托尼霍尔在1960年提出。它采用分治法(Divide and Conquer)策略,将一个大数组分为两个小数组,然后递归地对这两…...
)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战(含ifconfig与DHCP详解)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战 当你第一次看到QNX Neutrino RTOS的Photon桌面时,那种兴奋感可能很快会被一个现实问题冲淡——这个看起来酷炫的系统怎么连上网?作为实时操作系统领域的标杆,QNX在车载系…...

Shell脚本加固实战:用shellguard提升脚本健壮性与安全性
1. 项目概述:一个为Shell脚本穿上“防弹衣”的守护者 在运维开发、自动化部署乃至日常的系统管理工作中,Shell脚本是我们最忠实、最高效的伙伴。从简单的日志清理到复杂的CI/CD流水线,Shell脚本无处不在。然而,脚本的安全性、健壮…...

Helm-Intellisense:VS Code智能补全插件,提升values.yaml编写效率
1. 项目概述:为什么我们需要一个Helm智能补全工具?如果你和我一样,日常工作中大量使用Helm来管理Kubernetes应用,那你一定对编写values.yaml文件时那种“盲人摸象”的感觉深有体会。面对一个动辄几十上百行配置的Helm Chart&#…...

用Git和Markdown构建个人知识库:Wandercode项目实践指南
1. 项目概述:从“漫游代码”到个人知识管理系统的蜕变最近在GitHub上看到一个挺有意思的项目,叫“Wandercode”,直译过来就是“漫游代码”。乍一看这个标题,可能会让人联想到某种代码生成器或者自动化脚本工具。但当我深入探究其仓…...

Nexus:RAG 时代终结?编译器 AI 知识层来了
最近 Pinecone 发布了一个新东西:**Nexus。**最早我是在抖音上看到的,说实话,这种标题挺吓人的,低劣但有效,我都忍不住要点进去: RAG 时代终结了。向量数据库不够用了。Agent 需要 Knowledge Engine。因为…...

开源项目仪表盘开发指南:基于React、Next.js与GitHub API的实践
1. 项目概述:一个为开源项目量身定制的现代化仪表盘 最近在折腾一个开源项目,想把它的状态、数据和一些关键指标更直观地展示出来,于是找到了 tugcantopaloglu/openclaw-dashboard 这个仓库。简单来说,这是一个专门为开源项目设…...
)
别再只盯着图片了!用3DCNN处理视频动作识别,从原理到代码实战(PyTorch版)
3DCNN实战:从视频动作识别到PyTorch代码实现 当监控摄像头捕捉到一场突如其来的争执,或是体育赛事中运动员的关键动作,传统图像识别技术往往力不从心。这些场景中的信息不仅存在于每一帧画面里,更隐藏在帧与帧之间的动态变化中——…...

FSearch终极指南:如何在Linux上实现秒级文件搜索
FSearch终极指南:如何在Linux上实现秒级文件搜索 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 还在为Linux系统中查找文件而烦恼吗?FSearch是…...
表面吸附模型的构建与可视化)
从DFT计算到论文插图:一条龙搞定Pt(111)表面吸附模型的构建与可视化
从DFT计算到论文插图:Pt(111)表面吸附模型的完整构建与可视化指南 在计算材料科学领域,构建精确的表面吸附模型是研究催化反应机理、表面化学过程的第一步。对于刚入门的研究者来说,如何快速构建一个符合物理实际的Pt(111)表面吸附模型&#…...
)
ESP32+LVGL8.3保姆级教程:搞定ST7789V屏幕和CST816T触摸(附完整代码)
ESP32LVGL8.3实战指南:ST7789V屏幕与CST816T触摸的深度适配 当一块240x280分辨率的ST7789V屏幕与CST816T触摸芯片组合遇到ESP32开发板,如何让LVGL8.3图形库完美驱动这套硬件?本文将带你从零开始,穿越配置迷宫,解决色彩…...