【Pandas操作2】groupby函数、pivot_table函数、数据运算(map和apply)、重复值清洗、异常值清洗、缺失值处理
1 数据清洗
#### 概述数据清洗是指对原始数据进行处理和转换,以去除无效、重复、缺失或错误的数据,使数据符合分析的要求。#### 作用和意义- 提高数据质量:- 通过数据清洗,数据质量得到提升,减少错误分析和错误决策。
- 增加数据可用性:- 清洗后的数据更加规整和易于使用,提高数据的可用性和可读性。## 清洗维度- 缺失值处理:- 对于缺失的数据,可以删除包含缺失值的行或列或者填充缺失值。
- 重复值处理:- 识别和删除重复的数据行,避免重复数据对分析结果产生误导。
- 异常值处理:- 检测和处理异常值,决定是删除、替换或保留异常值。## 缺失值清洗##### 缺失值/空值的删除- 伪造缺失值数据
import pandas as pd
from pandas import DataFrame, Seriesdf = pd.read_csv('./data/none.csv', index_col=0)
df # NaN就是None空白

- 缺失值的检测和删除,相关方法:
- isnull():检测df中的每一个元素是否为空值,为空则给该元素返回True,否则返回False
- notnull():检测df中的每一个元素是否为非空值,为非空则给该元素返回True,否则返回False
- any():检测一行或一列布尔值中是否存在一个或多个True,有则返回True,否则返回False
- all():检测一行或一列布尔值中是否存全部为True,有则返回True,否则返回False
- dropna():将存在缺失值/空值的行或者列进行删除
# 检测哪些列中存在控制
df.isnull()

# 检测非空值
df.notnull()

# 可以判断哪些列存在控制
# axis=0表示针对列进行any操作
# axis=1表示针对行进行any操作
df.isnull().any(axis=0)

df.notnull().all(axis=0)

- dropna()进行空值检测和过滤
# 直接返回删除空值对应后的结果,不会直接改变原始数据
df.dropna()

- 计算df中每一列存在缺失值的个数和占比
for col in df.columns:# 满足该条件则表示第col列中存在空值if df[col].isnull().sum() > 0:# 求出该列空值的个数null_count = df[col].isnull().sum()# 求出该列中空值的占比: 空值的数量/列的总元素个数p = format(null_count / df[col].size, '.2%')print(col, null_count, p)

- 使用任意值填充空值
# 如果想应用于原始数据,就加上inplace=True
df.fillna(value=666)

- 使用近邻值填充空值
# 在竖直方向上,会用空值前面的值填充空值 ffill前值填充
df.fillna(axis=0, method='ffill').fillna(axis=0, method='bfill') # bfill后值填充

- 使用相关的统计值填充空值
# 可以空值列的均值、中位数、方差等统计指标对空值进行填充
for col in df.columns:if df[col].isnull().sum() > 0:# 计算出空值对应的均值mean_value = df[col].mean()df[col].fillna(value=mean_value, inplace=True)
df

注意:实现空值的清洗最好选择删除的方式,如果删除的成本比较高,再选择填充的方式。
2 重复值清洗
- 伪造重复行的数据源
df = pd.read_csv('data/repeat.csv', index_col=0)
df

- 使用duplicated()方法检测重复的行数据
df.duplicated().sum() # 2
- 使用drop_duplicates()方法检测且删除重复的行数据
df.drop_duplicates()

3 异常值清洗
异常值是分析师和数据科学家常用的术语,因为它需要密切注意,否则可能导致错误的估计。
简单来说,异常值是一个观察值,远远超出了样本中的整体模式。
异常值在统计学上的全称是疑似异常值,也称作离群点,异常值的分析也称作离群点分析。
异常值是指样本中出现的“极端值”,数据值看起来异常大或异常小,其分布明显偏离其余的观测值。
异常值分析是检验数据中是否存在不合常理的数据。
- 给定条件的异常数据处理
- 自定义一个1000行3列(A,B,C)取值范围为0-1的数据源,然后将C列中的值大于其两倍标准差的异常值进行清洗
data = pd.read_csv('./data/outlier.csv', index_col=0)
data

# C列的2倍标准差
twice_std = data['C'].std() * 2
twice_std
# 判定异常值, 即值大于2倍的标准差
ex = data['C'] > twice_std
ex # True表示异常值,False标志正常值

# 取出True对应的行数据 (异常值对应的行数据)
data.loc[ex]

# 提取异常值对应行数据的行索引
drop_index = data.loc[ex].index
drop_index

# 将异常值对应的行从数据表格中进行删除
data.drop(index=drop_index)

3 map映射
- 给Series中的一组数据提供另外一种表现形式,或者说给其绑定一组指定的标签或字符串。
- 创建一个df,两列分别是姓名和薪资,然后给其名字起对应的英文名,然后将英文的性别统一转换为中文的性别
dic = {'name': ['tom', 'jerry', 'alex', 'tom'],'salary': [10000, 20000, 15000, 21000],'gender': ['male', 'female', 'male', 'female']
}
df = pd.DataFrame(data=dic)
df

# 将性别使用中文来标志
sex_dic = {'male':'男','female':'女'
}# map可以根据gender这组数据中的每一个元素根据字典表示的关系进行映射
df['gender'] = df['gender'].map(sex_dic)
df

# 给每一个英文名起一个中文名
name_dic = {'tom': '张三','jerry': '李四','alex': '王五'
}
df['e_name'] = df['name'].map(name_dic)
df

4 数据运算
map函数对Series数据的运算处理(map作为Series的运算工具)
- 超过3000部分的钱缴纳50%的税,计算每个人的税后薪资
def after_sal(s): # 此处s参数表示每一个薪资的数据# 该函数的调用次数取决于salary列中元素的个数return s - (s - 3000) * 0.5df['after_sal'] = df['salary'].map(after_sal)
df

# 改为匿名函数
df['salary'].map(lambda s: s - (s - 3000) * 0.5)

dic = {'name': ['tom', 'jerry', 'alex', 'tom'],'salary': [10000, 20000, 15000, 21000],'gender': ['male', 'female', 'male', 'female'],'hire_date': ['2020-01-10', '2021-11-11', '2022-12-12','2023-01-19',]
}
df = pd.DataFrame(data=dic)
df

# 将每一个员工的入职日期 +2 年
# 将 'hire_date' 转换为日期格式并加上2年
df['hire_date'] = pd.to_datetime(df['hire_date'])
df['hire_date_now'] = df['hire_date'].map(lambda x: x + pd.DateOffset(years=2))
df

dic = {'name': ['tom', 'jerry', 'alex', 'tom'],'salary': [10000, 20000, 15000, 21000],'gender': ['male', 'female', 'male', 'female'],'hire_date': ['2020-01-10', '2021-11-11', '2022-12-12','2023-01-19',]
}
df = pd.DataFrame(data=dic)# 也可以使用函数
# 将每一个员工的入职日期 +2 年
def func(x):year, month, day = x.split('-')year = int(year) + 2return str(year)+'-'+month+'-'+day
df['hire_date'] = df['hire_date'].map(func)
df

提示:apply也可以像map一样充当运算工具,不过apply运算效率要远远高于map。
因此在数据量级较大的时候可以使用apply。
dic = {'name': ['tom', 'jerry', 'alex', 'tom'],'salary': [10000, 20000, 15000, 21000],'gender': ['male', 'female', 'male', 'female'],'hire_date': ['2020-01-10', '2021-11-11', '2022-12-12','2023-01-19',]
}
df = pd.DataFrame(data=dic)def func(x):year, month, day = x.split('-')year = int(year) + 2return str(year)+'-'+month+'-'+day
df['hire_date'] = df['hire_date'].apply(func)
df

5 数据分组
- 数据分类处理的核心:
- groupby()函数
- groups属性查看分组情况
import pandas as pd
import warningswarnings.filterwarnings('ignore')df = pd.DataFrame({'item':['Apple','Banana','0range','Banana','0range','Apple'],'price':[4, 3, 3, 2.5, 4, 2],'color':['red','yellow','yellow','green','green','green'],'weight':[12,20,50,30,20,44]
})
df

# 计算每种水果的平均价格
df.groupby(by='item').groups # groups查看分组的结果

mean_price = df.groupby(by='item')['price'].mean()
mean_price

# 将平均价格转为字典
dic = mean_price.to_dict()
dic

# 将水果的平均价格汇总到原始的数据中
df['mean_price'] = df['item'].map(dic)
df

# 计算不同颜色水果的最大重量
max_weight = df.groupby(by='color')['weight'].max()max_weight

dic = max_weight.to_dict()
df['color'].map(dic)

# 将不同水果的最大重量汇总到原始的数据中
df['max_weight'] = df['color'].map(dic)
df

# 计算每种水果最大价格和最低价格的差值
def func(x): # 参数x:一组水果的所有价格return x.max() - x.min()df.groupby(by='item')['price'].transform(func)

- agg实现对分组后的结果进行多种不同形式的聚合操作
# 求每种水果的最大和最小价格
df.groupby(by='item')['price'].agg(['max', 'min', 'mean', 'sum'])
6 透视表pivot_table函数
- 对不同字段不同形式的聚合操作
# 计算每种水果的平均价格
# 参数index:表示分组的条件
# 参数values:表示对哪些字段进行聚合操作
# 参数aggfunc:用户指定聚合形式
df.pivot_table(index='item', values='price', aggfunc='mean')

# 计算不同颜色水果的最大、最小和平均重量
df.pivot_table(index='color', aggfunc={'weight': 'max', 'weight': 'min', 'weight': 'mean',})

# 计算不同颜色水果的最大、最小和平均重量
df.pivot_table(index='color', values='weight', aggfunc=['max', 'min', 'mean'])

相关文章:
【Pandas操作2】groupby函数、pivot_table函数、数据运算(map和apply)、重复值清洗、异常值清洗、缺失值处理
1 数据清洗 #### 概述数据清洗是指对原始数据进行处理和转换,以去除无效、重复、缺失或错误的数据,使数据符合分析的要求。#### 作用和意义- 提高数据质量:- 通过数据清洗,数据质量得到提升,减少错误分析和错误决策。…...

如何分辨IP地址是否能够正常使用
在互联网的日常使用中,无论是进行网络测试、网站访问、数据抓取还是远程访问,一个正常工作的IP地址都是必不可少的。然而,由于各种原因,IP地址可能无法正常使用,如被封禁、网络连接问题或配置错误等。本文将详细介绍如…...

Sqoop 数据迁移
Sqoop 数据迁移 一、Sqoop 概述二、Sqoop 优势三、Sqoop 的架构与工作机制四、Sqoop Import 流程五、Sqoop Export 流程六、Sqoop 安装部署6.1 下载解压6.2 修改 Sqoop 配置文件6.3 配置 Sqoop 环境变量6.4 添加 MySQL 驱动包6.5 测试运行 Sqoop6.5.1 查看Sqoop命令语法6.5.2 测…...

【数据结构】排序算法系列——希尔排序(附源码+图解)
希尔排序 算法思想 希尔排序(Shell Sort)是一种改进的插入排序算法,希尔排序的创造者Donald Shell想出了这个极具创造力的改进。其时间复杂度取决于步长序列(gap)的选择。我们在插入排序中,会发现是对整体…...

c++(继承、模板进阶)
一、模板进阶 1、非类型模板参数 模板参数分类类型形参与非类型形参。 类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。 非类型形参,就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中…...

【机器学习】从零开始理解深度学习——揭开神经网络的神秘面纱
1. 引言 随着技术的飞速发展,人工智能(AI)已从学术研究的实验室走向现实应用的舞台,成为推动现代社会变革的核心动力之一。而在这一进程中,深度学习(Deep Learning)因其在大规模数据处理和复杂问题求解中的卓越表现,迅速崛起为人工智能的最前沿技术。深度学习的核心是…...
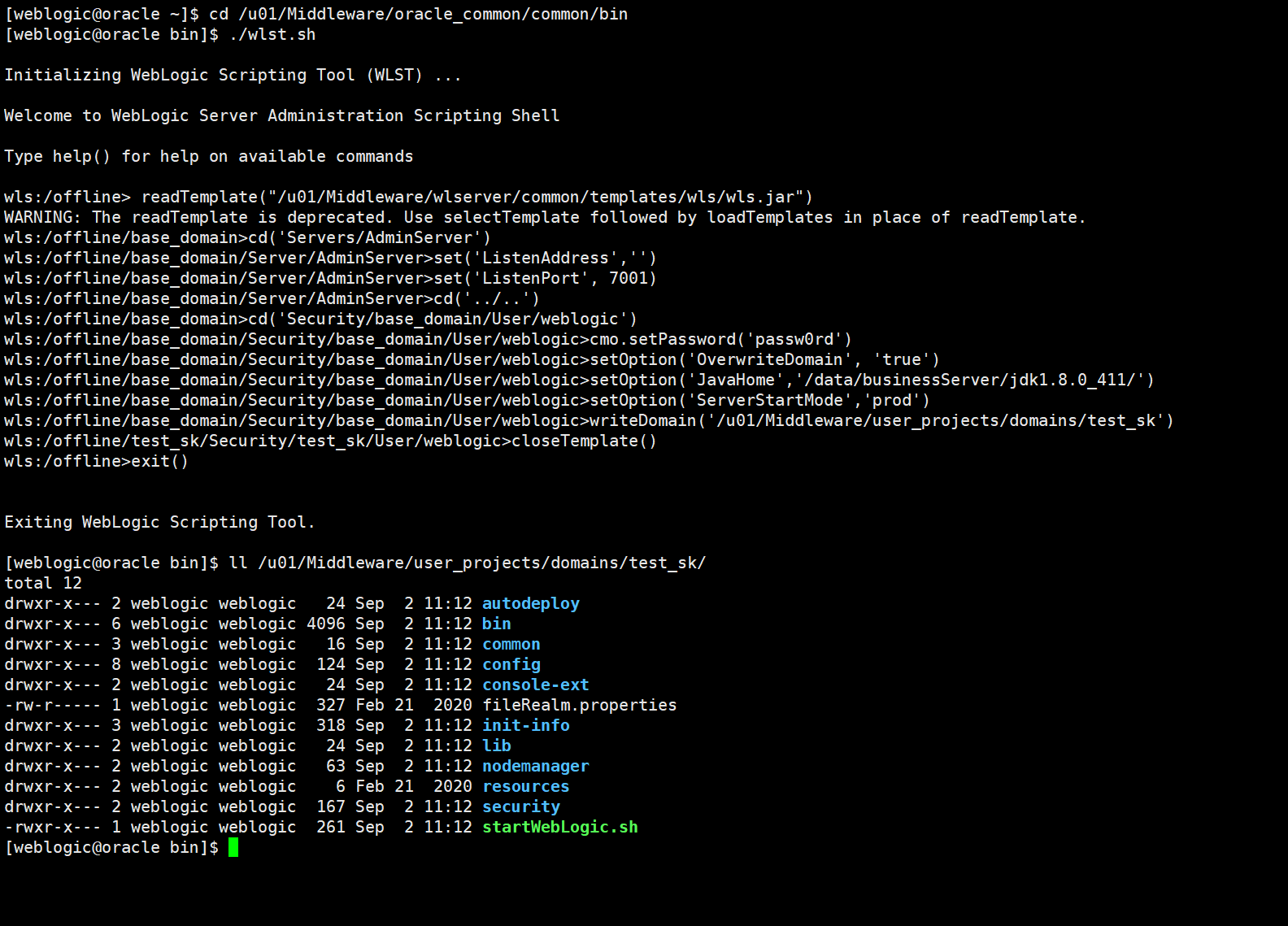
WebLogic 笔记汇总
WebLogic 笔记汇总 一、weblogic安装 1、创建用户和用户组 groupadd weblogicuseradd -g weblogic weblogic # 添加用户,并用-g参数来制定 web用户组passwd weblogic # passwd命令修改密码# 在文件末尾增加以下内容 cat >>/etc/security/limits.conf<<EOF web…...

leetcode:2710. 移除字符串中的尾随零(python3解法)
难度:简单 给你一个用字符串表示的正整数 num ,请你以字符串形式返回不含尾随零的整数 num 。 示例 1: 输入:num "51230100" 输出:"512301" 解释:整数 "51230100" 有 2 个尾…...

Python GUI入门详解-学习篇
一、简介 GUI就是图形用户界面的意思,在Python中使用PyQt可以快速搭建自己的应用,自己的程序看上去就会更加高大上。 有时候使用 python 做自动化运维操作,开发一个简单的应用程序非常方便。程序写好,每次都要通过命令行运行 pyt…...

QT5实现https的post请求(QNetworkAccessManager、QNetworkRequest和QNetworkReply)
QT5实现https的post请求 前言一、一定要有sslErrors处理1、问题经过2、代码示例 二、要利用抓包工具1、问题经过2、wireshark的使用3、利用wireshark查看服务器地址4、利用wireshark查看自己构建的请求报文 三、返回数据只能读一次1、问题描述2、部分代码 总结 前言 QNetworkA…...

vscode 使用git bash,路径分隔符缺少问题
window使用bash --login -i 使用bash时候,在系统自带的terminal里面进入,测试conda可以正常输出,但是在vscode里面输入conda发现有问题 bash: C:\Users\marswennaconda3\Scripts: No such file or directory实际路径应该要为 C:\Users\mars…...
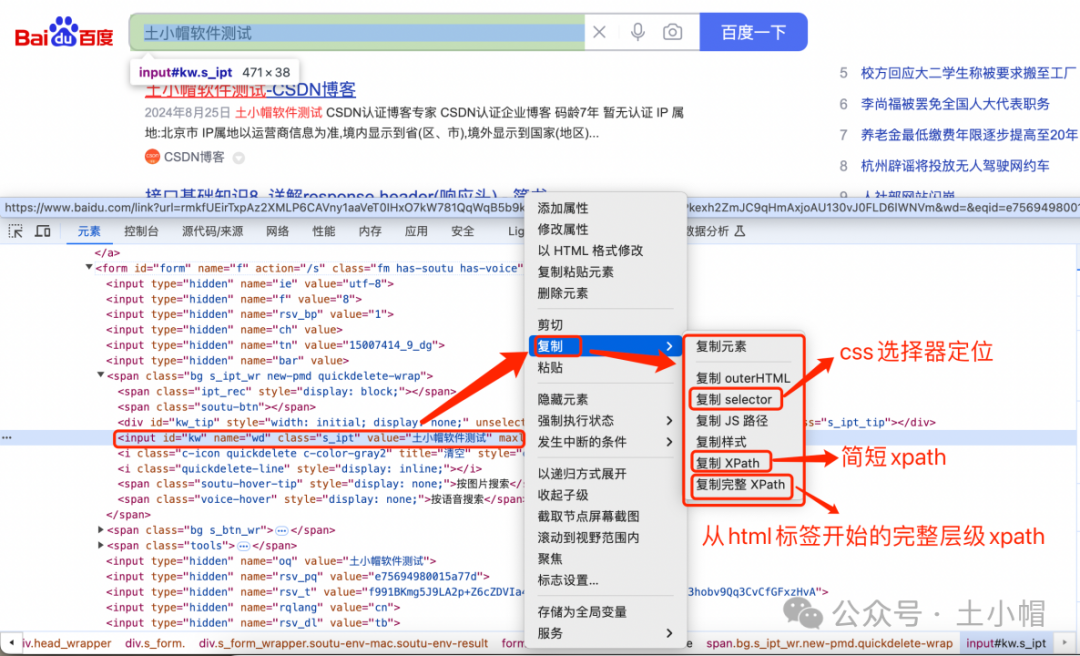
F12抓包10:UI自动化 - Elements(元素)定位页面元素
课程大纲 1、前端基础 1.1 元素 元素是构成HTML文档的基本组成部分之一,定义了文档的结构和内容,比如段落、标题、链接等。 元素大致分为3种:基本结构、自闭合元素(self-closing element)、嵌套元素。 1、基本结构&…...

android 删除系统原有的debug.keystore,系统运行的时候,重新生成新的debug.keystore,来完成App的运行。
1、先上一个图:这个是keystore无效的原因 之前在安装这个旧版本android studio的时候呢,安装过一版最新的android studio,然后通过模拟器跑过测试的demo。 2、运行旧的项目到模拟器的时候,就报错了: Execution failed…...

SQL入门题
作者SQL入门小白,此栏仅是记录一些解题过程 1、题目 用户访问表users,记录了用户id(usr_id)和访问日期(log_date),求出连续3天以上访问的用户id。 2、解答过程 2.1数据准备 通过navicat创建数据…...

Python实战:实战练习案例汇总
Python实战:实战练习案例汇总 **Python世界系列****Python实践系列****Python语音处理系列** 本文逆序更新,汇总实践练习案例。 Python世界系列 Python世界:力扣题43大数相乘算法实践Python世界:求解满足某完全平方关系的整数实…...

zabbix之钉钉告警
钉钉告警设置 我们可以将同一个运維组的人员加入到同一个钉钉工作群中,当有异常出现后,Zabbix 将告警信息发送到钉钉的群里面,此时,群内所有的运维人员都能在第一时间看到这则告警详细。 Zabbix 监控系统默认没有开箱即用…...

《OpenCV计算机视觉》—— 对图片进行旋转的两种方法
文章目录 一、用numpy库中的方法对图片进行旋转二、用OpenCV库中的方法对图片进行旋转 一、用numpy库中的方法对图片进行旋转 numpy库中的 np.rot90 函数方法可以对图片进行旋转 代码实现如下: import cv2 import numpy as np# 读取图片 img cv2.imread(wechat.jp…...
)
Python 错误 ValueError 解析,实际错误实例详解 (一)
文章目录 前言Python 中错误 ValueError: No JSON object Could Be Decoded在 Python 中解码 JSON 对象将 JSON 字符串解码为 Python 对象将 Python 对象编码为 JSON 字符串Python 中错误 ValueError: Unsupported Pickle Protocol: 3Python 中的 Pickling 和 UnpicklingPython…...

[java][git]上传本地代码及更新代码到GitHub教程
上传本地代码及更新代码到GitHub教程 上传本地代码 第一步:去github上创建自己的Repository,创建页面如下图所示: 红框为新建的仓库的https地址 第二步: echo "# Test" >> README.md 第三步:建立g…...

react antd table expandable defaultExpandAllRows 不生效问题
原因:defaultExpandAllRows只会在第一次渲染时触发 解决方案:渲染前判断table 的datasource 数据是否已准备好 {pageList.length > 0 ? (<TablerowSelection{rowSelection}columns{columns}dataSource{pageList}style{{ marginTop: 24 }}pagina…...

AI 挖洞新思路、深度解析两大间接提示词注入漏洞攻防思路,注入也能获得上万美金
0x01 简介 在移动 AI 领域,我已经很久没有关注过提示词注入漏洞了,在前两天关注到 Gemini 的漏洞之前,我对提示词注入的印象还停留在两年前,当时搞搞越狱,觉得这东西是纯内容安全,也只能等未来对能够进…...

NotebookLM概念关联分析全链路解析,从原始文本到可验证知识网络的6大断点与修复方案
更多请点击: https://intelliparadigm.com 第一章:NotebookLM概念关联分析全链路解析概览 NotebookLM 是 Google 推出的基于 LLM 的实验性研究辅助工具,其核心能力在于对用户上传的文档(PDF、TXT、网页等)进行语义理…...

销售跟进转任务,4个实操标准帮你高效交接无遗漏
不少销售朋友反馈,调岗、离职或带新人交接跟进任务时,常出现信息杂乱、关键内容遗漏的问题,要么仅提供大量聊天记录和录音,接手人难以快速找到重点,要么遗漏客户特殊要求、过往承诺,最终导致丢单、承担责任…...

CircuitFusion:多模态AI在集成电路设计中的革命性应用
1. 集成电路设计的多模态革命:CircuitFusion技术解析在AI芯片设计领域,一个令人头疼的现实是:随着芯片复杂度呈指数级增长,传统设计流程已难以应对。以7nm工艺节点为例,单个芯片可能包含数十亿个晶体管,设计…...

修一个Bug,引入另一个Bug:从Tomcat高危漏洞看中间件安全修复的困境
攻击者无需认证,仅需向集群通信端口发送构造数据,即可绕过加密校验并触发反序列化,实现远程代码执行。这个漏洞的特殊之处在于——它是官方修复上一个漏洞时“顺手”引入的。2026年5月,Apache Tomcat官方披露了一个高危漏洞CVE-20…...
)
告别单调按钮!用LVGL的imgbtn打造高颜值嵌入式UI(附9宫格切图技巧)
告别单调按钮!用LVGL的imgbtn打造高颜值嵌入式UI(附9宫格切图技巧) 在嵌入式设备开发中,用户界面的美观度往往被忽视,开发者更关注功能实现而非视觉体验。然而,随着智能家居、可穿戴设备和工业控制面板的普…...

欧美客户下最后通牒:2026年起没有Sedex,订单再多也出不了货!
各位外贸老板、工厂负责人注意了!2026年,全球供应链的ESG合规风暴已经进入下半场。如果你还在做纺织品、家具、电子、玩具出口,还没搞懂Sedex和SMETA新政,很可能随时被踢出欧美客户的供应商名录!没有这块“敲门砖”&am…...

从莎士比亚到鲁迅,NotebookLM辅助文学研究全流程,深度拆解7类文本生成陷阱与规避方案
更多请点击: https://codechina.net 第一章:NotebookLM在文学研究中的范式革命 传统文学研究长期依赖人工细读、索引比对与跨文本联想,耗时且易受主观经验局限。NotebookLM 以“源文档优先”(source-first)架构重构人…...

运维开发必备:5分钟搞定CentOS 7下ncurses库的安装与基础使用
运维开发必备:5分钟搞定CentOS 7下ncurses库的安装与基础使用 在服务器运维和自动化工具开发中,命令行界面(CLI)的高效交互能力往往决定了管理效率的上限。当我们需要在无GUI环境的Linux服务器上开发监控面板、配置向导或系统管理…...

AI测试-如何选择AI测试工具
在 AI 编程席卷开发圈的 2026 年,面对琳琅满目的工具,测试同学最常问的就是:Augment、Cursor、Trae、Claude Code、Codex 到底该怎么选? 这五款工具虽同为 AI 编程助手,但产品定位、技术路线和适用场景天差地别。本文…...