数据库系统 第54节 数据库优化器
数据库优化器是数据库管理系统(DBMS)中的一个关键组件,它的作用是分析用户的查询请求,并生成一个高效的执行计划。这个执行计划定义了如何访问数据和执行操作,以最小化查询的执行时间和资源消耗。以下是数据库优化器的主要组成部分和它们的功能:
代价估计 (Cost Estimation)
代价估计是指优化器评估不同查询执行计划所需的资源和时间的过程。优化器会尝试预测每个可能的执行计划的成本,包括:
- I/O成本:读取或写入数据所需的磁盘操作次数。
- CPU成本:执行查询所需的处理时间,如排序、连接和计算表达式。
- 内存使用:执行查询所需的内存量,如用于排序或哈希操作的内存。
伪代码示例:
class ExecutionPlan {// 执行计划的属性,如表扫描、索引使用等
}class Cost {double io_cost; // I/O成本double cpu_cost; // CPU成本double memory_cost; // 内存成本
}Cost estimate_cost(ExecutionPlan plan) {Cost cost = new Cost();// 根据执行计划计算I/O、CPU和内存成本cost.io_cost = calculate_io_cost(plan);cost.cpu_cost = calculate_cpu_cost(plan);cost.memory_cost = calculate_memory_cost(plan);return cost;
}
访问路径选择 (Access Path Selection)
访问路径选择是优化器决定如何访问数据的过程。这包括选择使用全表扫描、索引扫描、索引连接等策略。优化器会考虑以下因素:
- 数据分布:数据在表或索引中的分布情况。
- 索引选择:是否存在合适的索引可以加速查询。
- 选择性:查询条件的筛选效果,即查询条件能够减少多少数据量。
伪代码示例:
class AccessPath {String type; // 如 "全表扫描"、"索引扫描" 等// 其他属性,如使用的索引、表等
}List<AccessPath> generate_access_paths(Query query) {List<AccessPath> paths = new ArrayList<>();// 生成可能的访问路径paths.add(new AccessPath("全表扫描"));// 检查是否存在可用的索引if (query.can_use_index()) {paths.add(new AccessPath("索引扫描"));}return paths;
}
统计信息的使用
数据库优化器通常会利用统计信息来帮助做出更好的决策。这些统计信息包括:
- 表的行数:表中数据的总量。
- 列的分布:列值的分布情况,如唯一值的数量。
- 索引的选择性:索引列的唯一值比例。
伪代码示例:
class Statistics {long row_count; // 表的行数Map<String, Long> column_cardinalities; // 列的唯一值数量Map<String, Double> index_selectivities; // 索引的选择性
}Statistics get_statistics(Table table) {Statistics stats = new Statistics();// 填充统计信息stats.row_count = table.get_row_count();stats.column_cardinalities = table.get_column_cardinalities();stats.index_selectivities = table.get_index_selectivities();return stats;
}
执行计划的生成和选择
优化器会生成多个可能的执行计划,并根据代价估计选择成本最低的计划。
伪代码示例:
ExecutionPlan generate_execution_plans(Query query) {List<AccessPath> paths = generate_access_paths(query);List<ExecutionPlan> plans = new ArrayList<>();for (AccessPath path : paths) {// 根据访问路径生成执行计划plans.add(create_execution_plan(path));}// 选择成本最低的执行计划return plans.stream().min(Comparator.comparing(estimate_cost)).orElseThrow(() -> new IllegalStateException("No plan found"));
}
优化器的挑战
数据库优化器面临的挑战包括:
- 复杂性:随着查询复杂性的增加,可能的执行计划数量呈指数级增长。
- 统计信息的准确性:统计信息的准确性直接影响代价估计的准确性。
- 动态数据:数据的动态变化可能会影响执行计划的有效性。
数据库优化器是一个复杂且动态的系统,它需要不断地适应数据的变化和查询的需求。在实际的数据库系统中,如MySQL、PostgreSQL、Oracle等,优化器的实现会包含更多的细节和高级特性,如查询重写、子查询展开、并行执行等。
为了进一步说明数据库优化器的工作原理,我们可以扩展之前的伪代码示例,以展示如何生成和选择执行计划,以及如何利用统计信息来辅助决策。以下是一些更详细的伪代码示例,这些示例将帮助我们理解优化器在实际数据库系统中可能的实现方式。
统计信息的收集和使用
在实际的数据库系统中,统计信息的收集是一个持续的过程,通常由数据库的维护任务(如ANALYZE)来完成。
class TableStatistics {long rowCount;Map<String, Histogram> columnStatistics;
}class Histogram {List<Bucket> buckets;
}class Bucket {Object lowerBound;Object upperBound;long frequency;
}void collect_statistics(Table table) {TableStatistics stats = new TableStatistics();stats.rowCount = table.rowCount();for (Column column : table.columns()) {Histogram histogram = calculate_histogram(column);stats.columnStatistics.put(column.name(), histogram);}table.setStatistics(stats);
}Histogram calculate_histogram(Column column) {// 实际的统计信息收集可能会涉及复杂的算法和大量的数据处理// 这里只是一个简化的示例Histogram histogram = new Histogram();// 填充直方图桶return histogram;
}
执行计划的生成
在生成执行计划时,优化器会考虑多种可能的访问路径,并为每种路径生成一个执行计划。
class ExecutionPlan {String planDetails;Cost cost;
}ExecutionPlan create_execution_plan(AccessPath accessPath, TableStatistics stats) {ExecutionPlan plan = new ExecutionPlan();plan.planDetails = "Plan using " + accessPath.type;plan.cost = estimate_cost(accessPath, stats);return plan;
}Cost estimate_cost(AccessPath accessPath, TableStatistics stats) {Cost cost = new Cost();// 基于访问路径和统计信息来估计成本if (accessPath.type.equals("索引扫描")) {cost.io_cost = calculate_index_scan_cost(accessPath.index, stats);cost.cpu_cost = 0; // 假设索引扫描不需要CPU计算} else if (accessPath.type.equals("全表扫描")) {cost.io_cost = calculate_full_table_scan_cost(stats.rowCount);cost.cpu_cost = calculate_cpu_cost_for_scan(stats.rowCount);}cost.memory_cost = estimate_memory_usage(accessPath, stats);return cost;
}double calculate_index_scan_cost(Index index, TableStatistics stats) {// 根据索引的选择性和数据分布来估计成本return stats.rowCount * 0.1; // 假设的计算
}double calculate_full_table_scan_cost(long rowCount) {// 估计全表扫描的成本return rowCount * 0.05; // 假设的计算
}double calculate_cpu_cost_for_scan(long rowCount) {// 估计CPU计算的成本return rowCount * 0.01; // 假设的计算
}double estimate_memory_usage(AccessPath accessPath, TableStatistics stats) {// 估计执行计划的内存使用return 100; // 假设的固定值
}
执行计划的选择
优化器会根据估计的成本来选择最佳的执行计划。
ExecutionPlan choose_best_plan(List<ExecutionPlan> plans) {return plans.stream().min(Comparator.comparing(plan -> plan.cost.io_cost + plan.cost.cpu_cost + plan.cost.memory_cost)).orElseThrow(() -> new IllegalStateException("No plan found"));
}
优化器的高级特性
在实际的数据库系统中,优化器可能还会考虑以下高级特性:
- 查询重写:优化器可能会改变查询的表达方式,以提高效率,例如将子查询转换为连接操作。
- 并行执行:优化器可能会将查询分解为多个可以并行执行的部分。
- 查询缓存:优化器可能会利用查询缓存来避免重复执行相同的查询。
这些高级特性的实现会进一步增加优化器的复杂性,但同时也能显著提高数据库系统的性能。
请注意,上述伪代码是为了说明优化器的工作原理而设计的,实际的数据库优化器实现会更加复杂,并且会涉及到大量的细节和特定场景的优化。
为了进一步深入探讨数据库优化器的高级特性,我们可以继续扩展之前的示例,包括查询重写、并行执行和查询缓存的实现。这些特性可以帮助数据库系统更高效地处理复杂的查询,并提高整体性能。
查询重写 (Query Rewriting)
查询重写是优化器用来改进查询性能的一种技术,它通过改变查询的逻辑结构来减少资源消耗。例如,将子查询转换为连接操作,或者将复杂的连接操作分解为多个简单的步骤。
伪代码示例:
class Query {String originalQuery;String rewrittenQuery;
}Query rewrite_query(Query query) {Query rewrittenQuery = new Query();rewrittenQuery.originalQuery = query.originalQuery;// 检查是否存在子查询if (contains_subquery(query.originalQuery)) {rewrittenQuery.rewrittenQuery = convert_subquery_to_join(query.originalQuery);} else {rewrittenQuery.rewrittenQuery = query.originalQuery;}return rewrittenQuery;
}boolean contains_subquery(String query) {// 检查查询中是否包含子查询// 这里只是一个简化的示例return query.contains("SELECT ... FROM ... WHERE ... IN (SELECT ...)");
}String convert_subquery_to_join(String query) {// 将子查询转换为连接操作// 这里只是一个简化的示例return query.replaceAll("IN \\(SELECT (.+?)\\)", "INNER JOIN ($1)");
}
并行执行 (Parallel Execution)
并行执行是优化器用来加速查询执行的一种技术,它通过将查询分解为多个可以并行处理的部分来提高性能。
伪代码示例:
class ParallelExecutionPlan {List<ExecutionPlan> parallelPlans;
}ParallelExecutionPlan create_parallel_execution_plan(Query query) {ParallelExecutionPlan parallelPlan = new ParallelExecutionPlan();List<ExecutionPlan> plans = generate_execution_plans(query);// 选择可以并行执行的计划for (ExecutionPlan plan : plans) {if (can_parallelize(plan)) {parallelPlan.parallelPlans.add(plan);}}return parallelPlan;
}boolean can_parallelize(ExecutionPlan plan) {// 检查执行计划是否可以并行化// 这里只是一个简化的示例return plan.planDetails.contains("全表扫描") || plan.planDetails.contains("索引扫描");
}
查询缓存 (Query Caching)
查询缓存是优化器用来提高重复查询性能的一种技术,它通过缓存查询结果来避免重复执行相同的查询。
伪代码示例:
class QueryCache {Map<String, Result> cache;QueryCache() {cache = new HashMap<>();}Result get_result(String query) {// 从缓存中获取结果return cache.get(query);}void put_result(String query, Result result) {// 将结果添加到缓存cache.put(query, result);}
}Result execute_query_with_caching(Query query, QueryCache cache) {Result result = cache.get_result(query.originalQuery);if (result == null) {result = execute_query(query);cache.put_result(query.originalQuery, result);}return result;
}Result execute_query(Query query) {// 执行查询并返回结果// 这里只是一个简化的示例return new Result(); // 假设的结果对象
}
优化器的监控和自适应
除了上述特性,数据库优化器还可以包括监控和自适应特性,以动态调整其行为以适应当前的数据库负载和数据分布。
伪代码示例:
class OptimizerStatistics {long totalQueries;long cachedHits;long rewriteSuccesses;void record_query_execution(Result result) {totalQueries++;if (result.isCached()) {cachedHits++;}}void record_query_rewrite(Query query) {if (query.rewrittenQuery != null) {rewriteSuccesses++;}}
}OptimizerStatistics optimizerStats = new OptimizerStatistics();void monitor_optimizer_performance() {// 定期检查优化器统计信息if (optimizerStats.totalQueries > 1000) {// 根据统计信息调整优化器策略adjust_optimizer_strategy();}
}void adjust_optimizer_strategy() {// 根据监控结果调整优化器策略// 这里只是一个简化的示例
}
通过这些高级特性和监控机制,数据库优化器能够更智能地处理各种查询,从而提高数据库系统的整体性能和响应能力。实际的数据库系统,如Oracle、SQL Server、MySQL等,都有自己独特的优化器实现,包括复杂的统计信息收集、查询重写规则、并行执行策略和查询缓存机制。
相关文章:

数据库系统 第54节 数据库优化器
数据库优化器是数据库管理系统(DBMS)中的一个关键组件,它的作用是分析用户的查询请求,并生成一个高效的执行计划。这个执行计划定义了如何访问数据和执行操作,以最小化查询的执行时间和资源消耗。以下是数据库优化器的…...

微服务杂谈
几个概念 还是第一次听说Spring Cloud Alibaba ,真是孤陋寡闻了,以前只知道 SpringCloud 是为了搭建微服务的,spring boot 则是快速创建一个项目,也可以是一个微服务 。那么SpringCloud 和 Spring boot 有什么区别呢?S…...

【Pandas操作2】groupby函数、pivot_table函数、数据运算(map和apply)、重复值清洗、异常值清洗、缺失值处理
1 数据清洗 #### 概述数据清洗是指对原始数据进行处理和转换,以去除无效、重复、缺失或错误的数据,使数据符合分析的要求。#### 作用和意义- 提高数据质量:- 通过数据清洗,数据质量得到提升,减少错误分析和错误决策。…...

如何分辨IP地址是否能够正常使用
在互联网的日常使用中,无论是进行网络测试、网站访问、数据抓取还是远程访问,一个正常工作的IP地址都是必不可少的。然而,由于各种原因,IP地址可能无法正常使用,如被封禁、网络连接问题或配置错误等。本文将详细介绍如…...

Sqoop 数据迁移
Sqoop 数据迁移 一、Sqoop 概述二、Sqoop 优势三、Sqoop 的架构与工作机制四、Sqoop Import 流程五、Sqoop Export 流程六、Sqoop 安装部署6.1 下载解压6.2 修改 Sqoop 配置文件6.3 配置 Sqoop 环境变量6.4 添加 MySQL 驱动包6.5 测试运行 Sqoop6.5.1 查看Sqoop命令语法6.5.2 测…...

【数据结构】排序算法系列——希尔排序(附源码+图解)
希尔排序 算法思想 希尔排序(Shell Sort)是一种改进的插入排序算法,希尔排序的创造者Donald Shell想出了这个极具创造力的改进。其时间复杂度取决于步长序列(gap)的选择。我们在插入排序中,会发现是对整体…...

c++(继承、模板进阶)
一、模板进阶 1、非类型模板参数 模板参数分类类型形参与非类型形参。 类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。 非类型形参,就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中…...

【机器学习】从零开始理解深度学习——揭开神经网络的神秘面纱
1. 引言 随着技术的飞速发展,人工智能(AI)已从学术研究的实验室走向现实应用的舞台,成为推动现代社会变革的核心动力之一。而在这一进程中,深度学习(Deep Learning)因其在大规模数据处理和复杂问题求解中的卓越表现,迅速崛起为人工智能的最前沿技术。深度学习的核心是…...
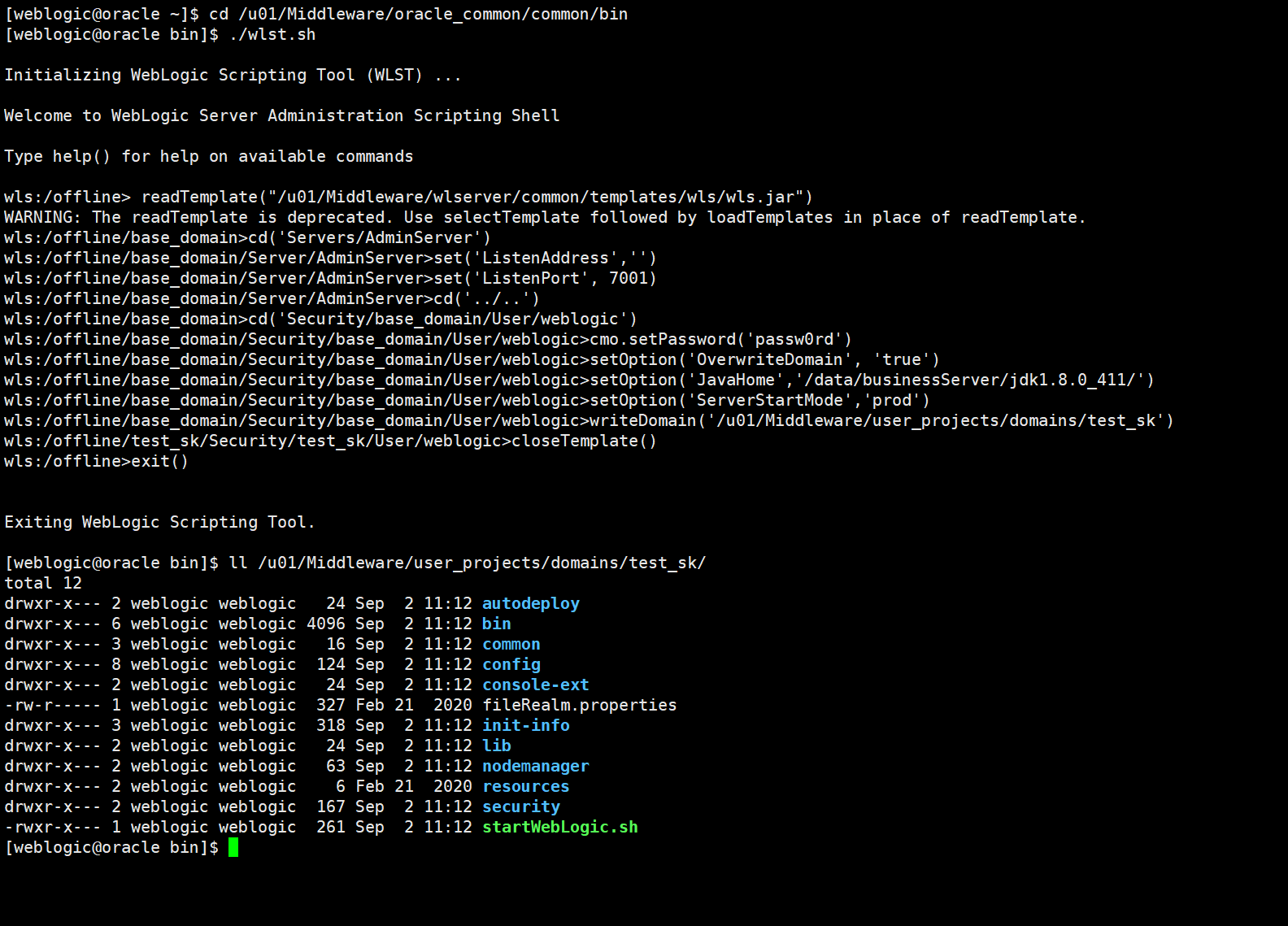
WebLogic 笔记汇总
WebLogic 笔记汇总 一、weblogic安装 1、创建用户和用户组 groupadd weblogicuseradd -g weblogic weblogic # 添加用户,并用-g参数来制定 web用户组passwd weblogic # passwd命令修改密码# 在文件末尾增加以下内容 cat >>/etc/security/limits.conf<<EOF web…...

leetcode:2710. 移除字符串中的尾随零(python3解法)
难度:简单 给你一个用字符串表示的正整数 num ,请你以字符串形式返回不含尾随零的整数 num 。 示例 1: 输入:num "51230100" 输出:"512301" 解释:整数 "51230100" 有 2 个尾…...

Python GUI入门详解-学习篇
一、简介 GUI就是图形用户界面的意思,在Python中使用PyQt可以快速搭建自己的应用,自己的程序看上去就会更加高大上。 有时候使用 python 做自动化运维操作,开发一个简单的应用程序非常方便。程序写好,每次都要通过命令行运行 pyt…...

QT5实现https的post请求(QNetworkAccessManager、QNetworkRequest和QNetworkReply)
QT5实现https的post请求 前言一、一定要有sslErrors处理1、问题经过2、代码示例 二、要利用抓包工具1、问题经过2、wireshark的使用3、利用wireshark查看服务器地址4、利用wireshark查看自己构建的请求报文 三、返回数据只能读一次1、问题描述2、部分代码 总结 前言 QNetworkA…...

vscode 使用git bash,路径分隔符缺少问题
window使用bash --login -i 使用bash时候,在系统自带的terminal里面进入,测试conda可以正常输出,但是在vscode里面输入conda发现有问题 bash: C:\Users\marswennaconda3\Scripts: No such file or directory实际路径应该要为 C:\Users\mars…...
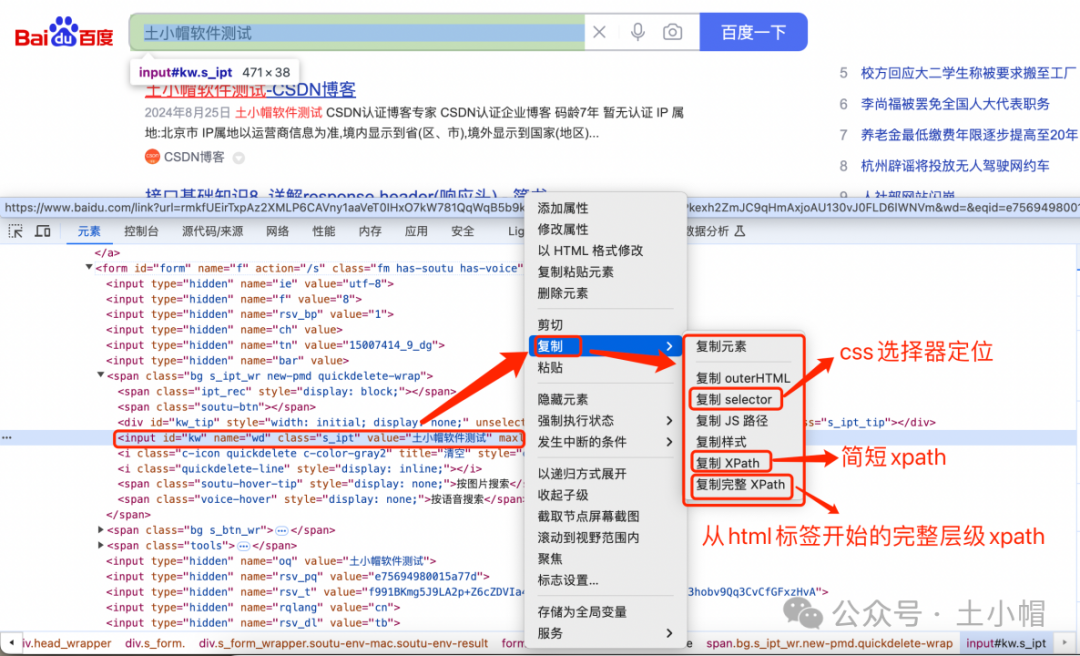
F12抓包10:UI自动化 - Elements(元素)定位页面元素
课程大纲 1、前端基础 1.1 元素 元素是构成HTML文档的基本组成部分之一,定义了文档的结构和内容,比如段落、标题、链接等。 元素大致分为3种:基本结构、自闭合元素(self-closing element)、嵌套元素。 1、基本结构&…...

android 删除系统原有的debug.keystore,系统运行的时候,重新生成新的debug.keystore,来完成App的运行。
1、先上一个图:这个是keystore无效的原因 之前在安装这个旧版本android studio的时候呢,安装过一版最新的android studio,然后通过模拟器跑过测试的demo。 2、运行旧的项目到模拟器的时候,就报错了: Execution failed…...

SQL入门题
作者SQL入门小白,此栏仅是记录一些解题过程 1、题目 用户访问表users,记录了用户id(usr_id)和访问日期(log_date),求出连续3天以上访问的用户id。 2、解答过程 2.1数据准备 通过navicat创建数据…...

Python实战:实战练习案例汇总
Python实战:实战练习案例汇总 **Python世界系列****Python实践系列****Python语音处理系列** 本文逆序更新,汇总实践练习案例。 Python世界系列 Python世界:力扣题43大数相乘算法实践Python世界:求解满足某完全平方关系的整数实…...

zabbix之钉钉告警
钉钉告警设置 我们可以将同一个运維组的人员加入到同一个钉钉工作群中,当有异常出现后,Zabbix 将告警信息发送到钉钉的群里面,此时,群内所有的运维人员都能在第一时间看到这则告警详细。 Zabbix 监控系统默认没有开箱即用…...

《OpenCV计算机视觉》—— 对图片进行旋转的两种方法
文章目录 一、用numpy库中的方法对图片进行旋转二、用OpenCV库中的方法对图片进行旋转 一、用numpy库中的方法对图片进行旋转 numpy库中的 np.rot90 函数方法可以对图片进行旋转 代码实现如下: import cv2 import numpy as np# 读取图片 img cv2.imread(wechat.jp…...
)
Python 错误 ValueError 解析,实际错误实例详解 (一)
文章目录 前言Python 中错误 ValueError: No JSON object Could Be Decoded在 Python 中解码 JSON 对象将 JSON 字符串解码为 Python 对象将 Python 对象编码为 JSON 字符串Python 中错误 ValueError: Unsupported Pickle Protocol: 3Python 中的 Pickling 和 UnpicklingPython…...

职场新人不会写自我介绍?3分钟AI生成直接拿面试
刚步入职场的新人,写简历是不是最怕碰到“自我评价”或“自我介绍”这一栏?盯着空白屏幕憋了一下午,最后只能干巴巴地敲下“性格开朗、吃苦耐劳、具有团队合作精神”这种假大空的话。好不容易搞定简历投递出去,结果总是石沉大海&a…...

安装离线版mysql,全网最详细
CentOS7 离线安装 MySQL 5.7 完整版(一次装好、配置齐全、开机自启、远程访问、字符集、防火墙、环境变量、日志、权限全部搞定,零返工)适配你的服务器:CentOS Linux release 7.6.1810 x86_64,Java1.8 已就绪ÿ…...

STR912评估板UART0通信故障排查与解决方案
1. MCBSTR9评估板UART0通信故障排查指南最近在调试STR912芯片的串口通信时,发现一个硬件设计上的"坑"值得分享。使用Keil MCBSTR9评估板V2版本时,UART0(COM1)接口竟然无法正常工作!经过一番排查,…...

phpenv故障排除终极指南:解决PHP版本管理中的10大常见问题
phpenv故障排除终极指南:解决PHP版本管理中的10大常见问题 【免费下载链接】phpenv Simple PHP version management 项目地址: https://gitcode.com/gh_mirrors/ph/phpenv phpenv是一款简单而强大的PHP版本管理工具,专为PHP开发者设计,…...

超导量子处理器校准技术:频率分配与门优化
1. 超导量子处理器校准技术概述超导量子处理器校准是量子计算硬件实现中的关键环节,其核心目标是通过系统化的参数优化和误差抑制,确保量子比特能够可靠地执行高保真度的量子门操作。在Zuchongzhi 3.1处理器的研发过程中,我们成功集成了105个…...

构建金融级 AI Agent:Claude for Financial Services 架构解析
一、 金融 AI 的核心挑战:通用 LLM 的局限性 在金融实战中,通用大模型(如 Claude 3.5, GPT-4)直接上岗会面临三大障碍: 幻觉风险:在财务建模中,极小的数值偏差即可导致估值错误。数据孤岛&#…...

NotebookLM脑机接口部署避坑指南:TensorRT加速失效、电极位移漂移补偿、低信噪比场景下的9种fallback策略
更多请点击: https://codechina.net 第一章:NotebookLM脑机接口研究 NotebookLM 是 Google 推出的基于用户自有文档进行深度理解与推理的 AI 助手,虽其官方定位并非直接面向脑机接口(BCI)领域,但其底层架构…...

Layerdivider:3分钟搞定PSD分层,AI智能分层工具让设计效率提升500%
Layerdivider:3分钟搞定PSD分层,AI智能分层工具让设计效率提升500% 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾经面对…...

别再给Claude送钱了!7个硬核技巧让Token消耗爆降80%,我亲测有效
文章目录前言1. 杀鸡不用牛刀:根据任务复杂度切换模型,别用导弹打蚊子2. 把CLAUDE.md当“项目宪法”,别当“信息垃圾场”3. 把脏活累活交给Subagent,但别滥用4. 精准打击!明确指定文件和行号,别让Claude大海…...

写论文缺参考文献?教你一招最快的反向查文献
写文献综述、毕业论文、科研报告时,你是不是也常遇到这些难题:观点明明写得很清楚,却找不到权威文献支撑;文献综述凑不够篇幅,论据来源不充分;逐篇翻数据库筛选文献太耗时,引文格式排版还总出错…...