论文复现--基于LeNet网络结构的数字识别
前言
- 一直就听说学习深度学习无非就是看论文,然后复现,不断循环,这段时间也看了好几篇论文(虽然都是简单的),但是对于我一个人自学,复现成功,我感觉还是挺开心的
- 本人初学看论文的思路:聚焦网络结构与其实验的效果
- LeNet虽然简单,很老了,但是毕竟经典,对于初学的的我来说,我感觉还是很有必要学习的,可以积累CNN网络结构模型
- 注意:minist数据集可以直接下载,不用自己找,详情请看导入数据
- 本来今天打算更新C从C++的变化基础的,但是由于种种原因,就先更新这篇吧
论文(知网可查询):基于LeNet-5的手写数字识别的改进方法
网络结构(LeNet):
-
卷积层:两层
-
池化层:两层
-
卷积层参数:
- 第一层:维度变化(1->6),步伐:1,卷积核:5 * 5
- 第二层:维度变化(6->16),步伐:1,卷积核:5 * 5
-
池化层:
- 两层都是:卷积核:2 * 2,步伐:2
-
全连接层:3层
- 16 * 5 * 5 --> 120 --> 84 --> 10
-
网络结构图如下(论文截图):

结果
- 轮次10,有点大了,可以降低
- 相比第一课,发现在训练集的损失率、测试集的损失率、训练集的准确率都有提升,详情情况结果可视化
1、前期准备
1、设置GPU
import torch # 用于张量计算和自动求导
import torch.nn as nn # 构建神经网络和损失函数
import matplotlib.pyplot as plt # 绘图
import torchvision # 专门处理视觉的库# 设置GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
print(torch.__version__)
print(torchvision.__version__)
cuda
2.4.0
0.19.0
2、导入数据
# 将所有的数据图片统一格式, 论文大小为:32 * 32
from torchvision import transforms, datasets transforms = transforms.Compose([transforms.Resize([32, 32]), # 统一图片大小transforms.ToTensor(), # 统一规格transforms.Normalize(mean=[0.1307], std=[0.3081]) # MNIST的均值和方差
])
# download设置为True,可以自动下载图片
train_ds = torchvision.datasets.MNIST('data', train=True, transform=transforms, download=False)test_ds = torchvision.datasets.MNIST('data', train=True, transform=transforms, download=False)
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds, batch_size=batch_size, shuffle=True)test_dl = torch.utils.data.DataLoader(test_ds, batch_size=batch_size, shuffle=True)
# 取一个批次查看数据格式
# 数据的shape为:[batch_size, channel, heigh, weight]
# batch_size是自己设定的,channel,height,weight分别是图片的通道数,高度,宽度
imgs, labels = next(iter(train_dl))
imgs.shape
结果:
torch.Size([32, 1, 32, 32])
3、数据可视化
import numpy as np# 指定图片的大小,图像的大小为20宽,5高
plt.figure(figsize=(20,5))
for i, imgs in enumerate(imgs[:20]):# 维度缩减npimg = np.squeeze(imgs.numpy())# 将整个figure分层2行10列,绘制第i+1个子图plt.subplot(2, 10, i + 1)plt.imshow(npimg, cmap=plt.cm.binary)plt.axis('off')

2、构建简单的CNN网络
import torch.nn.functional as Fnum_classes = 10 # 图片的类别数class Model(nn.Module):def __init__(self):super().__init__()# 特征提取网络设置self.conv1 = nn.Conv2d(1, 6, kernel_size=5) self.pool1 = nn.MaxPool2d(2) self.conv2 = nn.Conv2d(6, 16, kernel_size=5) self.pool2 = nn.MaxPool2d(2) # 分类网络设置self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, num_classes)# 前向传播def forward(self, x):x = F.relu(self.conv1(x))x = self.pool1(x)x = F.relu(self.conv2(x))x = self.pool2(x)x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x
加载并且打印模型
from torchinfo import summary# 将模型转移到GPU中
model = Model().to(device)summary(model)
=================================================================
Layer (type:depth-idx) Param #
=================================================================
Model --
├─Conv2d: 1-1 156
├─MaxPool2d: 1-2 --
├─Conv2d: 1-3 2,416
├─MaxPool2d: 1-4 --
├─Linear: 1-5 48,120
├─Linear: 1-6 10,164
├─Linear: 1-7 850
=================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0
=================================================================
for X, y in train_dl:print(X.shape) # 检查输入数据的形状break # 只打印第一个批次的数据形状
torch.Size([32, 1, 32, 32])
3、模型训练
1、设置超参数
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-2 # 学习率
opt = torch.optim.SGD(model.parameters(), lr = learn_rate)
2、编写训练函数
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集大小一共60000张图片num_batchs = len(dataloader) # 批次数目,1875 (60000/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device) # 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值的差距# 反向传播optimizer.zero_grad() # gred属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动跟新# 记录acc和losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchsreturn train_acc, train_loss3、编写测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,313(10000/32 = 321.5,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时候,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss4、正式训练
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Eopch: {:2d}, Train_acc: {:.1f}%, Train_loss: {:.3f}, Test_acc: {:.1f}%, test_loss: {:.3f}')print(template.format(epoch+1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc, epoch_test_loss))print('Done')
Eopch: 1, Train_acc: 75.9%, Train_loss: 0.739, Test_acc: 1.0%, test_loss: 0.144
Eopch: 2, Train_acc: 96.4%, Train_loss: 0.117, Test_acc: 1.0%, test_loss: 0.079
Eopch: 3, Train_acc: 97.6%, Train_loss: 0.080, Test_acc: 1.0%, test_loss: 0.073
Eopch: 4, Train_acc: 98.0%, Train_loss: 0.063, Test_acc: 1.0%, test_loss: 0.056
Eopch: 5, Train_acc: 98.4%, Train_loss: 0.053, Test_acc: 1.0%, test_loss: 0.048
Eopch: 6, Train_acc: 98.5%, Train_loss: 0.047, Test_acc: 1.0%, test_loss: 0.041
Eopch: 7, Train_acc: 98.7%, Train_loss: 0.042, Test_acc: 1.0%, test_loss: 0.035
Eopch: 8, Train_acc: 98.8%, Train_loss: 0.037, Test_acc: 1.0%, test_loss: 0.029
Eopch: 9, Train_acc: 99.0%, Train_loss: 0.033, Test_acc: 1.0%, test_loss: 0.029
Eopch: 10, Train_acc: 99.0%, Train_loss: 0.030, Test_acc: 1.0%, test_loss: 0.023
Done
4、结果可视化
import matplotlib.pyplot as plt
import warnings
# 忽略警告
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Train Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

相关文章:
论文复现--基于LeNet网络结构的数字识别
前言 一直就听说学习深度学习无非就是看论文,然后复现,不断循环,这段时间也看了好几篇论文(虽然都是简单的),但是对于我一个人自学,复现成功,我感觉还是挺开心的 本人初学看论文的思路:聚焦网络…...

Vue3 响应式工具函数isRef()、unref()、isReactive()、isReadonly()、isProxy()
isRef() isRef():检查某个值是否为 ref。 isRef函数接收一个参数,即要判断的值。如果该参数是由ref创建的响应式对象,则返回true;否则,返回false。 import { ref, isRef } from vue const normalValue 这是一个普通…...

数据结构之简单选择排序介绍与举例
简单选择排序 简单选择排序是一种排序算法,其基本思想是:通过n-i次关键字间的比较,从n-i1个记录中选出关键字最小的记录,并和第i个记录交换之。 举例: 给定数组 [64, 25, 12, 22, 11],进行简单选择排序。…...

九、Redis 的实际使用与Redis的设计
一、多级缓存架构 在线上系统中,一定不会单纯的只部署一个Redis集群,而是使用Redis结合其他的多级缓存应用进行架构。 使用多级缓存架构的优点就是可以使不同类型的数据分布在不同的应用中,比如redis的热点key可以存储到nginx本地缓存、服务…...
乔拓云模板助力,微信小程序快速上线无需愁备案
想要快速打造并上线自己的微信小程序吗?乔拓云平台是您的不二之选!无需担心复杂的备案流程,乔拓云提供免费服务,远程协助您轻松完成微信小程序的备案工作。 只需简单几步,您的小程序就能闪亮登场:首先&…...

Android命令行查看CPU频率和温度
在 Android 设备上,你可以通过命令行工具 adb 来查看 CPU 温度和 CPU 频率,并确定是否有降频情况。以下是具体步骤: 1. 查看 CPU 频率 你可以使用以下命令来查看 CPU 各个核心的当前频率: adb shell cat /sys/devices/system/c…...

力扣: 翻转字符串里的单词
文章目录 需求分析代码结尾 需求 给你一个字符串 s ,请你反转字符串中 单词 的顺序。 单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。 返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。 注意:输入字符…...

Wophp靶场寻找漏洞练习
1.命令执行漏洞 打开网站划到最下,此处的输入框存在任意命令执行漏洞 输入命令whoami 2.SQL注入 搜索框存在SQL注入,类型为整数型 最终结果可以找到管理员账户和密码 3.任意文件上传漏洞 在进入管理员后台后,上传木马文件 访问该文件&…...

国内智能运维厂商月度动态 202408
作为市场人员,虽然也添加了各类行业媒体、同行厂商的关注,但被同事问起业内动向时,常常也是记忆模糊、拍破脑袋也说不完整一件事。 所以找机会翻看了一下各大厂商的公号,先做个简单的8月汇总。 格式暂时是这样的: 整…...

C++ 左值与右值浅谈
左值与右值 序言概念左值和右值的划分理解右值引用常量左值引用与右值引用 移动语义引用折叠完美转发 参考资料 序言 虽然平常都算是了解左值,右值的用法,但是好记性不如烂笔头,记下来供大家评鉴,有错改错,有善赞善&a…...

oracle 如何查死锁
在Oracle中查看死锁通常涉及查询数据字典视图和动态性能视图。以下是一个基本的查询示例,用于检测和显示最近的死锁: SELECT dd.inst_id, dd.name, o.object_id, o.object_type, s.sid, s.serial#, s.username, p.spid, s.program,d.xidusn,d.xidslot,d…...

如何编写ChatGPT提示词
为ChatGPT编写有效的提示需要实施几个关键策略,以使文本到文本生成 AI 工具产生所需的输出。您可以使用 ChatGPT 提示(也称为 ChatGPT 命令)来增强您的工作或提高您在各个行业的表现。例如,营销人员可以提示 ChatGPT 为社交媒体帖…...

java项目之基于Spring Boot智能无人仓库管理源码(springboot+vue)
项目简介 智能无人仓库管理实现了以下功能: 基于Spring Boot智能无人仓库管理的主要使用者分为: 管理员的功能有:员工信息的查询管理,可以删除员工信息、修改员工信息、新增员工信息 💕💕作者:…...

大厂前端常见的笔试题目
https://zhuanlan.zhihu.com/p/488383397前端面试手写题目总结-CSDN博客 大厂前端面试中常见的手写代码题目涵盖了多个方面,包括但不限于算法、数据结构、JavaScript 基础知识、DOM 操作、异步编程等。以下是一些常见的手写代码题目及其简要说明: 1. 排…...
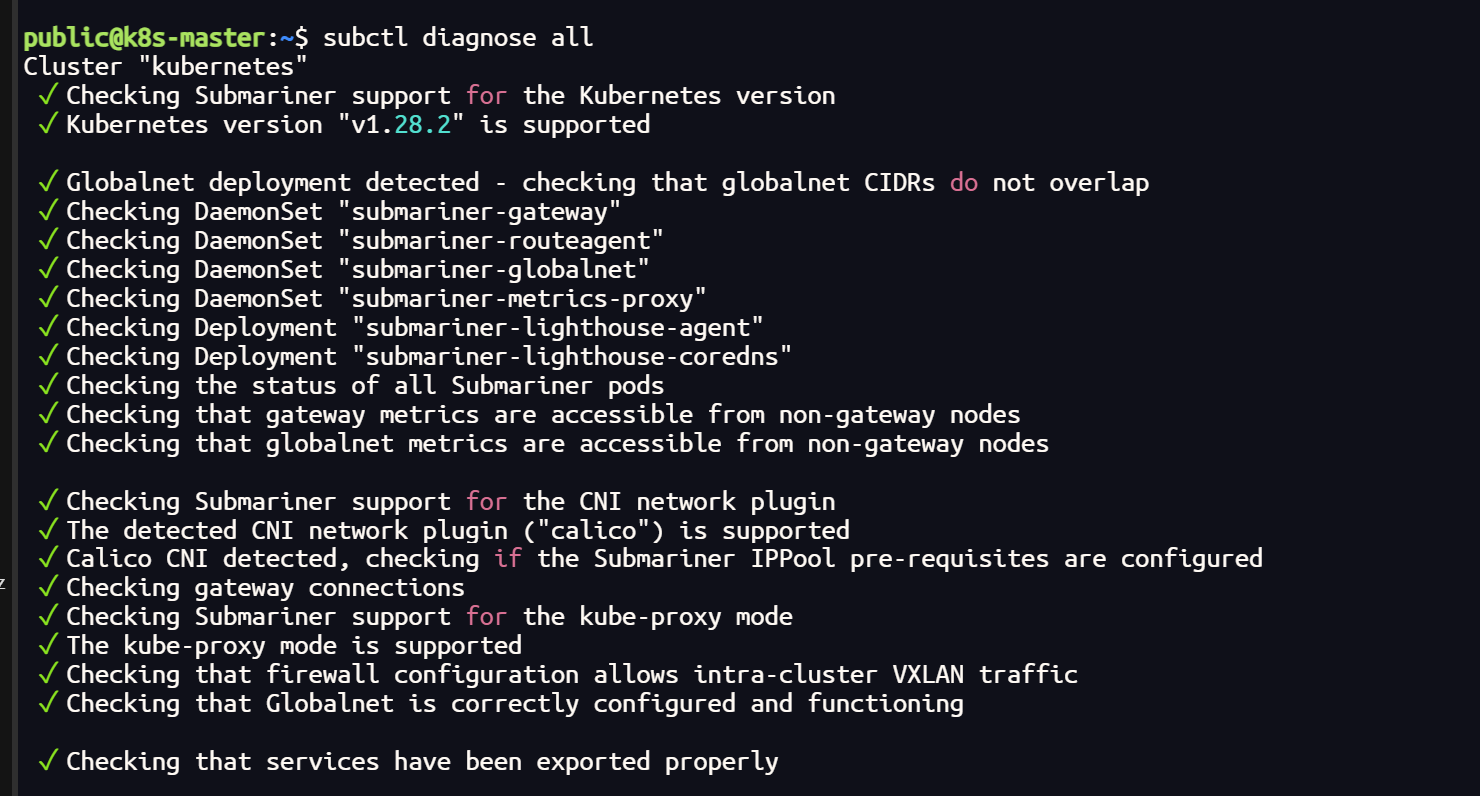
网络插件 Cilium 更换 Calico
网络插件 Cilium 更换 Calico 集群使用 submariner ,通过网络检测发现 Cilium 插件可能兼容性不太好 subctl diagnose allCilium 彻底卸载 helm uninstall cilium -n kube-system# 检查集群中的所有 CNI 插件(集群的每个节点都需要删除) s…...

SpringSecurity原理解析(二):认证流程
1、SpringSecurity认证流程包含哪几个子流程? 1)账号验证 2)密码验证 3)记住我—>Cookie记录 4)登录成功—>页面跳转 2、UsernamePasswordAuthenticationFilter 在SpringSecurity中处理认证逻辑是在UsernamePas…...
数据中台 | 数据资源管理平台介绍
01 产品概述 数据资源的盘查、集成、存储、组织、共享等全方位管理能力,无论对于企业的数字化转型,还是对企业数据资产的开发、运营、交易及入表,都具有极为关键的作用。今天,小兵就来为大家介绍我们自研数据智能平台中的核心产品…...
智慧环保平台建设方案
智慧环保平台建设方案摘要 政策导向与建设背景 背景:全国生态环境保护大会提出坚决打好污染防治攻坚战,推动生态文明建设,目标是在2035年实现生态环境质量根本好转。构建生态文明体系,包括生态文化、生态经济、目标责任、生态文明…...

SpringMVC映射请求;SpringMVC返回值类型;SpringMVC参数绑定;
一,SpringMVC映射请求 SpringMVC 使用 RequestMapping 注解为控制器指定可以处理哪些URL请求 1.1RequestMapping修饰类 注解RequestMapping修饰类,提供初步的请求映射信息,相对于WEB应用的跟目录。 注: 如果在类名前࿰…...

【第28章】Spring Cloud之Sentinel注解支持
文章目录 前言一、注解埋点支持二、SentinelResource 注解三、实战1. 准备2. 纯资源定义3. 添加资源配置 四、熔断(fallback)1. 业务代码1.1 Controller1.2 Service1.3 ServiceImpl 2. 熔断配置3. 熔断测试 总结 前言 上一章我们已经完成了对Sentinel的适配工作,这…...

COLMAP实战:跳过特征提取,直接用已知位姿完成三角测量与稠密重建
COLMAP高效重建实战:基于已知位姿的三角测量与稠密重建加速方案 三维重建技术正在机器人导航、AR/VR内容生成等领域快速普及,但传统流程中特征提取与匹配环节往往消耗超过70%的计算时间。当相机位姿已通过SLAM或其他传感器获取时,如何跳过这些…...

开源Claude本地部署指南:从模型选型到性能调优实战
1. 项目概述:当开源精神遇上AI推理最近在折腾本地部署大语言模型的朋友,估计都绕不开一个名字:Claude。作为Anthropic家的明星产品,Claude系列模型以其出色的推理能力、对指令的精准理解和强大的安全性,在开发者圈子里…...

终极指南:如何利用Play Integrity API构建专业级Android安全检测工具
终极指南:如何利用Play Integrity API构建专业级Android安全检测工具 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-checker…...

LLM应用开发资源导航:从Awesome List到实战项目构建
1. 项目概述:当“Awesome”遇见LLM应用如果你最近在GitHub上逛过,或者对大型语言模型(LLM)的应用开发感兴趣,那么“Shubhamsaboo/awesome-llm-apps”这个仓库大概率已经躺在你的浏览器书签或者GitHub星标列表里了。它不…...
气体传感器阵列与数据采集(附完整 C 语言驱动))
【嵌入式 AI 实战第 9 期】环境感知(一)气体传感器阵列与数据采集(附完整 C 语言驱动)
一、前言在物联网与人工智能快速发展的今天,环境感知能力已成为智能设备的核心功能之一。气体传感器作为环境感知的 "嗅觉器官",广泛应用于智能家居、工业安全、农业生产、医疗诊断等领域。传统的单一气体传感器只能检测特定类型的气体&#x…...

Adafruit IO物联网平台:从零构建环境监测与报警系统
1. 项目概述:为什么你需要一个像Adafruit IO这样的物联网平台?如果你玩过Arduino、树莓派或者任何单片机,肯定遇到过这样的场景:费了老大劲写代码让传感器读出数据,结果这些数据要么在串口监视器里一闪而过,…...

STM32F4的CAN总线配置避坑指南:从原理图到500Kbps通信的完整流程
STM32F4的CAN总线配置避坑指南:从原理图到500Kbps通信的完整流程 CAN总线作为工业控制领域的经典通信协议,在STM32F4系列开发中却常因硬件设计盲区和软件配置细节导致通信失败。本文将带您穿越从原理图设计到稳定实现500Kbps通信的全流程,重点…...

终极思维导图互操作指南:让markmap在不同工具间自由流转
终极思维导图互操作指南:让markmap在不同工具间自由流转 【免费下载链接】markmap Build mindmaps with plain text 项目地址: https://gitcode.com/gh_mirrors/ma/markmap 你是否曾因思维导图格式不兼容而抓狂?😫 辛辛苦苦在某个工具…...

ElevenLabs动画配音语音交付危机预警,紧急修复唇动不同步、语速断层、多语言混读错位的6大实时响应方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs动画配音语音交付危机的本质溯源 当动画制作团队依赖 ElevenLabs API 实时生成角色语音时,突然出现的 429 Too Many Requests 响应、TTS 音频静音片段、以及语音情感断层现象&…...

立创泰山派RK3566开发环境实战:从交叉编译到高效文件传输
1. 立创泰山派RK3566开发环境搭建全攻略 第一次拿到立创泰山派RK3566开发板时,我和大多数嵌入式开发者一样兴奋又忐忑。这款基于Rockchip RK3566处理器的开发板性能强劲,但配套资料相对分散,特别是对于从其他平台(比如我熟悉的IMX…...