Pytorch构建自己的数据集
1.Pytorch内置的Dataset
Pytorch中内置了许多数据集,我们可以从torchvision库中进行导入。比如,我们可以导入Fashion-MNIST数据集
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plttraining_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor()
)test_data = datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor()
)
但如果torchvision库中没有该数据集,我们需要自己构建一个。
其中一个方法就是把构建好的数据集使用torch.utils.data.TensorDataset()封装以下,然后再传入torch.utils.data.DataLoader
trainloader = torch.utils.data.DataLoader(training_data, batch_size=32, shuffle=True)
testloader = torch.utils.data.DataLoader(test_data, batch_size=32, shuffle=False)
但是如果自己写一个类的话会高达上一些,嘻嘻。下面看看如何自己构建一个Dataset Class。
2.Build Custom Dataset
构建一个Custom Dataset需要继承``三个函数__init__, __len__, 和 __getitem__。
__init__: 对类进行初始化__len__: 使该类可以返回dataset样本数量__getitem__: 给定一个idx,从数据集中导入并返回一个样本
下面我们来看看该如何构建Custom Dataset:
import os
import pandas as pd
from torchvision.io import read_imageclass CustomImageDataset(Dataset):def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file) # load labelself.img_dir = img_dirself.transform = transform # transformationself.target_transform = target_transformdef __len__(self):return len(self.img_labels) # 返回sample的个数def __getitem__(self, idx):img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])image = read_image(img_path) # load idx-th imagelabel = self.img_labels.iloc[idx, 1] # load idx-th labelif self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, label
注意:同时,__len__控制着产生样本的总个数。例如,如果总共有20个样本,我们希望20个样本全都放入dataloader中,则:
def __len(self):return 20
但如果我们只希望有20个样本中的15个放入到dataloader中,则:
def __len(self):return 15
但值得注意的是,return返回的数不能大于样本的总个数,即要小于等于20。并且,当返回的数小于总样本个数的时候,是取索引的前几个数,最后的几个数不会被放入dataloader中。比如return 15,是将data[:15]个数放入dataloader,而后5个数要舍去。可以用如下代码验证:
>>> data = np.arange(15).reshape(5,3)
>>> print(data)
array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11],[12, 13, 14]])
>>> class Data(Dataset):
... def __init__(self, data) -> None:
... super(Data, self).__init__()
... self.data = data
... def __len__(self):
... return 4
... def __getitem__(self, index):
... out = self.data[index]
... return torch.from_numpy(out)
>>> loader = DataLoader(Data(data), batch_size=4, shuffle=True)
>>> for i, x in enumerate(loader):
... print(i, x)0 tensor([[ 3, 4, 5],[ 9, 10, 11],[ 0, 1, 2],[ 6, 7, 8]])
可以发现,无论如何都不会输出[12, 13, 14]。
Reference:
Pytorch official tutorial
Writing custom datasets dataloaders and transforms
相关文章:

Pytorch构建自己的数据集
1.Pytorch内置的Dataset Pytorch中内置了许多数据集,我们可以从torchvision库中进行导入。比如,我们可以导入Fashion-MNIST数据集 import torch from torch.utils.data import Dataset from torchvision import datasets from torchvision.transforms …...
)
信息论小课堂:纠错码(海明码在信息传输编码时,通过巧妙的信道编码保证有了错误能够自动纠错。)
文章目录 引言I 纠错1.1 信息纠错的前提:信息冗余1.2 发现抄写错误的方法1.3 计算机的信息校验原理:奇偶校验1.4 有效的纠错编码II 案例2.1 例子1:自身DNA的编码2.2 例子2:海明码引言 预则立,不预则废:不确定性是我们这个世界自然的属性,在解决问题之前,要考虑到世界的不…...

MySQL执行计划(explain)
MySQL执行计划(explain) 1.什么是执行计划 2.如何分析执行计划 执行计划一共有12列,每一列都有着特殊的含义,接下来我们逐一分析 id select语句的查询顺序,包含一组数字,如果数字相同则从上到下,如果数字不同则从大到小。 select_type …...

思必驰回复第二轮审核问询,如何与科大讯飞、阿里巴巴“虎口夺食”?
数据智能产业创新服务媒体——聚焦数智 改变商业3月21日,思必驰科技股份有限公司(以下简称“思必驰”)更新上市申请审核动态,已回复上交所第二轮审核问询函,回复了涵盖关于实际控制人的认定、关于预计持续亏损及关于…...

基于Spring、SpringMVC、MyBatis的汽车租赁系统设计
文章目录 项目介绍主要功能截图:前台首页汽车信息列表汽车租赁留言反馈个人信息管理后台汽车类型管理汽车信息管理租赁信息管理用户管理续租信息管理归还信息管理保险信息管理违章登记管理部分代码展示设计总结项目获取方式🍅 作者主页:Java韩立 🍅 简介:Java领域优质创…...

读《刻意练习》后感,与原文好句摘抄
第一章,有目的的练习 所谓“天真的练习”,基本上只是反复的做某件事情,并指望只靠这种反复的练习,就能够提高表现和水平。 有目的练习的四个特点 有目的的练习具有定义明确的特定目标有目的的练习是专注的有目的的练习包含反馈…...

华为OD机试用java实现 -【选座位】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧本篇题解:选座位 题目 疫情期间需要大…...

国产蓝牙耳机怎么挑选?口碑最好的国产蓝牙耳机
蓝牙耳机已经成为现代人生活中必不可少的设备之一,因此市场上涌现出了众多的品牌和型号。但是,在这个竞争激烈的市场中,哪些品牌的蓝牙耳机更受欢迎呢?以下是几款口碑不错的蓝牙耳机品牌。 一、南卡小音舱蓝牙耳机 推荐系数&…...
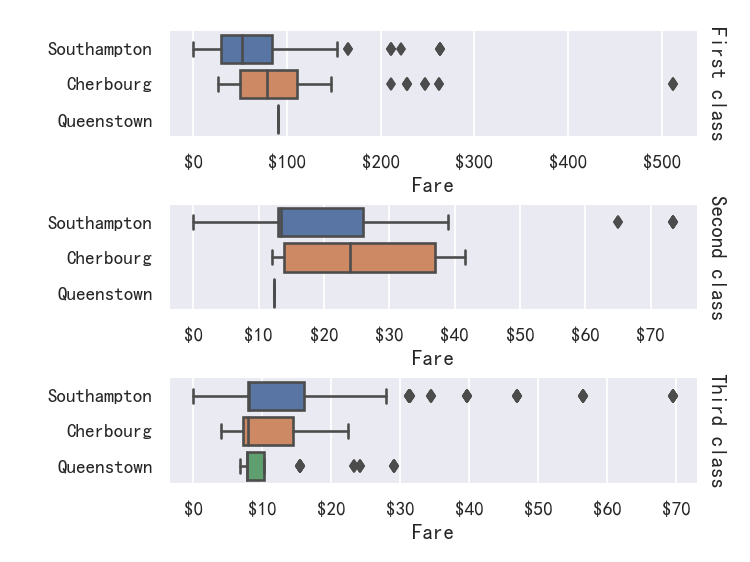
seaborn从入门到精通03-绘图功能实现02-分类绘图Categorical plots
seaborn从入门到精通03-绘图功能实现02-分类绘图Categorical plots总结参考关系-分布-分类分类绘图-Visualizing categorical data图形级接口catplot--figure-level interface导入库与查看tips和diamonds 数据分类散点图参考分布散点图stripplot分布密度散点图-swarmplot&#…...

❤️独特的算法❤️:一文解决编辑距离问题
编辑距离问题 题目关键点115. 不同的子序列 - 力扣(LeetCode)*dp数组定义,情况讨论583. 两个字符串的删除操作 - 力扣(LeetCode)两个字符串删除,情况讨论多加一种72. 编辑距离 - 力扣(LeetCode…...

三次样条样条:Bézier样条和Hermite样条
总结 What is the Difference Between Natural Cubic Spline, Hermite Spline, Bzier Spline and B-spline? 1.多项式拟合中的 Runge Phenomenon 找到一条通过N1个点的多项式曲线 ,需要N次曲线。通过两个点的多项式曲线为一次,三个点的多项式曲线为二…...
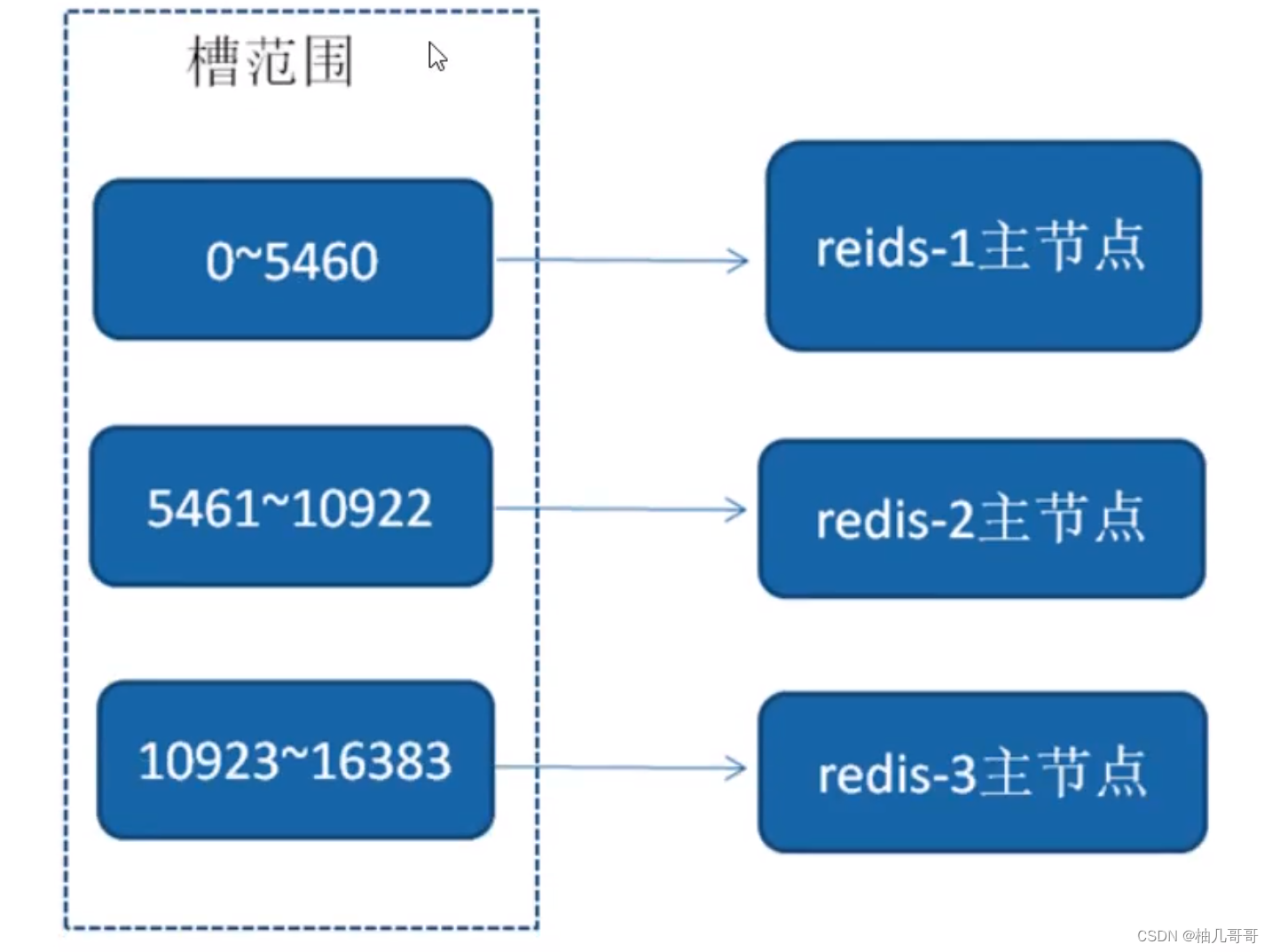
Redis面试题 (2023最新版)
文章目录一、Redis为什么快?1、纯内存访问2、单线程,避免上下文切换3、渐进式ReHash、缓存时间戳(1)渐进式ReHash:(2)缓存时间戳:二、Redis合适的应用场景常用基本数据类型ÿ…...

基于springboot实现家乡特色食品景点推荐系统【源码+论文】分享
基于springboot实现家乡特色推荐系统演示开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包&…...
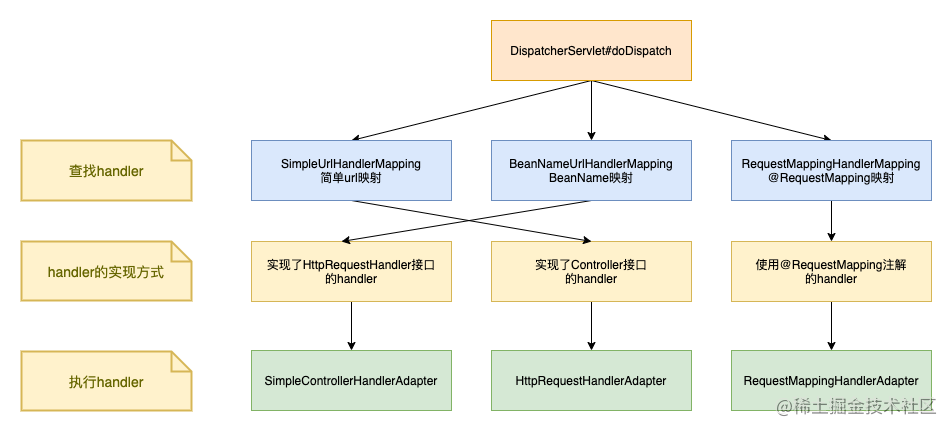
Spring MVC 启动之 HandlerMapping
在上一篇文章中,我们介绍了 Spring MVC 的启动流程,接下来我们将发分多个篇章详细介绍流程中的重点步骤 今天我们从 HandlerMapping 开始分析,HandlerMapping 是框架中的一个非常重要的组件。它的作用是将URL请求映射到合适的处理程序&#x…...

基于YOLOv5的停车位检测系统(清新UI+深度学习+训练数据集)
摘要:基于YOLOv5的停车位检测系统用于露天停车场车位检测,应用深度学习技术检测停车位是否占用,以辅助停车场对车位进行智能化管理。在介绍算法原理的同时,给出Python的实现代码、训练数据集以及PyQt的UI界面。博文提供了完整的Py…...

【Linux系统编程】5.vim基本操作命令
目录 跳转到指定行 命令模式 末行模式 跳转行首 跳转行尾 自动格式化代码 大括号、中括号、小括号对应 光标移至行首 光标移至行尾 删除单个字符 删除一个单词 删除光标至行尾 删除光标至行首 替换单个字符 删除指定区域 删除指定1行 删除指定多行 复制一行 …...
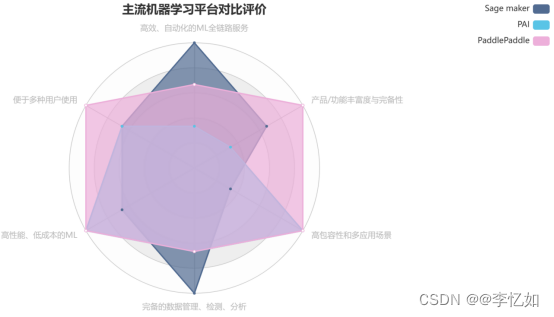
主流机器学习平台调研与对比分析
梗概 本报告主要调研目前主流的机器学习平台,包括但不限于Amazon的Sage maker,Alibaba的PAI,Baidu的PaddlePaddle。对产品的定位、功能、实践、定价四个方面进行详细解析,并通过标杆对比分析提出一套机器学习平台评价体系&#x…...

作业帮基于明道云开展的硬件业务数字化建设
今天由我代表作业帮来介绍公司在低代码平台应用的一些经验和心得。我今天分享的内容包含两部分,一个是作业帮硬件的介绍,另一个是基于明道云的系统能力建设,也是我们自己总结的经验,希望能给大家带来一些启发。 一、关于作业帮 …...

位图及布隆过滤器的模拟实现与面试题
位图 模拟实现 namespace yyq {template<size_t N>class bitset{public:bitset(){_bits.resize(N / 8 1, 0);//_bits.resize((N >> 3) 1, 0);}void set(size_t x)//将某位做标记{size_t i x / 8; //第几个char对象size_t j x % 8; //这个char对象的第几个比特…...

在 Python 中将天数添加到日期
使用 datetime 模块中的 timedelta() 方法将天数添加到日期中,例如 result_1 date_1 timedelta(days3)。 timedelta 方法可以传递天数参数并将指定的天数添加到日期。 from datetime import datetime, date, timedelta# ✅ 将天数添加到日期 my_str 09-24-2023 …...
)
ubuntu linux虚拟机安装部署hermes详细教程(安装、问题处理)
文章目录 前言 一、Hermes 介绍 1. 什么是 Hermes Agent? 2. 核心特性 3. 为什么选择 Hermes Agent? 4. 适用场景 二、安装Hermes 1.安装 2.配置 3.开始对话 4.接入多平台(可选) 5.保持更新 三、Hermes接入微信 四、常见错误解决 1.Failed to connect to github.com port 4…...

面试鸭:一站式面试题库解决方案,助你轻松备战技术面试
面试鸭:一站式面试题库解决方案,助你轻松备战技术面试 【免费下载链接】mianshiya-public 持续维护的企业面试题库网站,帮你拿到满意 offer!⭐️ 2026年最新Java面试题、前端面试题、AI大模型面试题、AI Agent面试题、RAG面试题、…...

3分钟从单图到3D模型:Wonder3D如何改变你的创作流程
3分钟从单图到3D模型:Wonder3D如何改变你的创作流程 【免费下载链接】Wonder3D Single Image to 3D using Cross-Domain Diffusion for 3D Generation 项目地址: https://gitcode.com/gh_mirrors/wo/Wonder3D 你是否曾为找不到合适的3D模型而烦恼?…...

Steam Deck Windows控制器驱动终极配置指南:5步实现完美游戏体验
Steam Deck Windows控制器驱动终极配置指南:5步实现完美游戏体验 【免费下载链接】steam-deck-windows-usermode-driver A windows usermode controller driver for the steam deck internal controller. 项目地址: https://gitcode.com/gh_mirrors/st/steam-deck…...

物联网技术如何重塑智能电网的底层架构
1. 物联网技术重塑智能电网的底层逻辑2003年美加大停电事故导致5000万人陷入黑暗,这场灾难直接催生了现代智能电网的诞生。如今,当我们谈论智能电网时,本质上是在讨论一个由物联网(IoT)技术重构的能源神经系统。这个系统通过海量智能终端实时…...

用STM32F103的USART1和PC串口助手玩“聊天室”:一个完整的数据收发项目实战
STM32F103串口聊天室:从零构建双向交互式终端 项目背景与核心价值 在嵌入式开发领域,串口通信如同"Hello World"般基础却又至关重要。传统教学往往止步于数据收发演示,而本项目将打破常规——用STM32F103的USART1构建一个具有完整交…...
)
不止于测温:用MAX31855和K型热电偶搭建一个低成本高精度温度监控系统(附STM32源码)
从热电偶到云端:基于MAX31855的高精度温度监测系统全栈开发指南 在工业自动化、实验室监测甚至家庭酿造等场景中,温度数据的精确采集与实时监控往往成为项目成败的关键。传统温度传感器虽然简单易用,但在高温、腐蚀性环境或需要极高精度的场合…...

WebToEpub:5分钟快速制作专业EPUB电子书的完整指南
WebToEpub:5分钟快速制作专业EPUB电子书的完整指南 【免费下载链接】WebToEpub A simple Chrome (and Firefox) Extension that converts Web Novels (and other web pages) into an EPUB. 项目地址: https://gitcode.com/gh_mirrors/we/WebToEpub 还在为在线…...

长期使用Taotoken的Token Plan套餐带来的月度成本变化观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken的Token Plan套餐带来的月度成本变化观察 对于需要持续调用大模型API的开发者或团队而言,成本的可预测…...

Paperless-ngx文档管理系统:5个关键技巧实现智能无纸化办公
Paperless-ngx文档管理系统:5个关键技巧实现智能无纸化办公 【免费下载链接】paperless-ngx A community-supported supercharged document management system: scan, index and archive all your documents 项目地址: https://gitcode.com/GitHub_Trending/pa/pa…...