多表查询--实例
1
创建student和score表
CREATE TABLE student (
id INT(10) NOT NULL UNIQUE PRIMARY KEY ,
name VARCHAR(20) NOT NULL ,
sex VARCHAR(4) ,
birth YEAR,
department VARCHAR(20) ,
address VARCHAR(50)
);
创建score表。SQL代码如下:
CREATE TABLE score (
id INT(10) NOT NULL UNIQUE PRIMARY KEY AUTO_INCREMENT ,
stu_id INT(10) NOT NULL ,
c_name VARCHAR(20) ,
grade INT(10)
);2.
为student表和score表增加记录
向student表插入记录的INSERT语句如下:
INSERT INTO student VALUES( 901,'张老大', '男',1985,'计算机系', '北京市海淀区');
INSERT INTO student VALUES( 902,'张老二', '男',1986,'中文系', '北京市昌平区');
INSERT INTO student VALUES( 903,'张三', '女',1990,'中文系', '湖南省永州市');
INSERT INTO student VALUES( 904,'李四', '男',1990,'英语系', '辽宁省阜新市');
INSERT INTO student VALUES( 905,'王五', '女',1991,'英语系', '福建省厦门市');
INSERT INTO student VALUES( 906,'王六', '男',1988,'计算机系', '湖南省衡阳市');
向score表插入记录的INSERT语句如下:
INSERT INTO score VALUES(NULL,901, '计算机',98);
INSERT INTO score VALUES(NULL,901, '英语', 80);
INSERT INTO score VALUES(NULL,902, '计算机',65);
INSERT INTO score VALUES(NULL,902, '中文',88);
INSERT INTO score VALUES(NULL,903, '中文',95);
INSERT INTO score VALUES(NULL,904, '计算机',70);
INSERT INTO score VALUES(NULL,904, '英语',92);
INSERT INTO score VALUES(NULL,905, '英语',94);
INSERT INTO score VALUES(NULL,906, '计算机',90);
INSERT INTO score VALUES(NULL,906, '英语',85);>select * from student;
+-----+-----------+------+-------+--------------+--------------------+
| id | name | sex | birth | department | address |
+-----+-----------+------+-------+--------------+--------------------+
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 |
| 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 |
| 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 |
| 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 |
+-----+-----------+------+-------+--------------+--------------------+
6 rows in set (0.00 sec)
>select * from score limit 1,3;
+----+--------+-----------+-------+
| id | stu_id | c_name | grade |
+----+--------+-----------+-------+
| 2 | 901 | 英语 | 80 |
| 3 | 902 | 计算机 | 65 |
| 4 | 902 | 中文 | 88 |
+----+--------+-----------+-------+
3 rows in set (0.00 sec)
注意:limit 1,3 的意思是从1的下一行开始查找,往后找三行。也就是2,3,4行
>select id,name,department from student;
+-----+-----------+--------------+
| id | name | department |
+-----+-----------+--------------+
| 901 | 张老大 | 计算机系 |
| 902 | 张老二 | 中文系 |
| 903 | 张三 | 中文系 |
| 904 | 李四 | 英语系 |
| 905 | 王五 | 英语系 |
| 906 | 王六 | 计算机系 |
+-----+-----------+--------------+
6 rows in set (0.00 sec)
方法1
>select * from student where department='计算机系' or department='英语系';
+-----+-----------+------+-------+--------------+--------------------+
| id | name | sex | birth | department | address |
+-----+-----------+------+-------+--------------+--------------------+
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 |
| 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 |
+-----+-----------+------+-------+--------------+--------------------+
4 rows in set (0.01 sec)方法2
>select * from student where department in ('英语系','计算机系');
+-----+-----------+------+-------+--------------+--------------------+
| id | name | sex | birth | department | address |
+-----+-----------+------+-------+--------------+--------------------+
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 |
| 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 |
+-----+-----------+------+-------+--------------+--------------------+
4 rows in set (0.00 sec)
>select *from student where year(curdate())-birth between 18 and 22;
Empty set (0.00 sec)6.从student表中查询每个院系有多少人
利用数据分组(用department分组)
]>select department,count(department)from student group by department;
+--------------+-------------------+
| department | count(department) |
+--------------+-------------------+
| 计算机系 | 2 |
| 中文系 | 2 |
| 英语系 | 2 |
+--------------+-------------------+
3 rows in set (0.00 sec)
7.从score表中查询每个科目的最高分
利用科目进行分组查询
>select c_name,max(grade) from score group by c_name;
+-----------+------------+
| c_name | max(grade) |
+-----------+------------+
| 计算机 | 98 |
| 英语 | 94 |
| 中文 | 95 |
+-----------+------------+
3 rows in set (0.00 sec)
>select s.id,s.name,c.c_name,c.grade from student as s inner join score as c ON s.id=c.stu_id where name like '李四';+-----+--------+-----------+-------+
| id | name | c_name | grade |
+-----+--------+-----------+-------+
| 904 | 李四 | 计算机 | 70 |
| 904 | 李四 | 英语 | 92 |
+-----+--------+-----------+-------+
2 rows in set (0.01 sec)
]>select * from student as s join score as c ON s.id=c.stu_id ;
+-----+-----------+------+-------+--------------+--------------------+----+--------+-----------+-------+
| id | name | sex | birth | department | address | id | stu_id | c_name | grade |
+-----+-----------+------+-------+--------------+--------------------+----+--------+-----------+-------+
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | 1 | 901 | 计算机 | 98 |
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | 2 | 901 | 英语 | 80 |
| 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | 3 | 902 | 计算机 | 65 |
| 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | 4 | 902 | 中文 | 88 |
| 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 | 5 | 903 | 中文 | 95 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | 6 | 904 | 计算机 | 70 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | 7 | 904 | 英语 | 92 |
| 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 | 8 | 905 | 英语 | 94 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | 9 | 906 | 计算机 | 90 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | 10 | 906 | 英语 | 85 |
+-----+-----------+------+-------+--------------+--------------------+----+--------+-----------+-------+
10 rows in set (0.00 sec)>select s.name,sum(c.grade) from student as s inner join score as c on s.id=c.stu_id;
ERROR 1140 (42000): In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'chap01.s.name'; this is incompatible with sql_mode=only_full_group_by
#提示错误:在没有GROUP BY的聚合查询中
>select s.name,sum(c.grade) from
>student as s inner join score as c
>on s.id=c.stu_id group by s.name;
+-----------+--------------+
| name | sum(c.grade) |
+-----------+--------------+
| 张老大 | 178 |
| 张老二 | 153 |
| 张三 | 95 |
| 李四 | 162 |
| 王五 | 94 |
| 王六 | 175 |
+-----------+--------------+
6 rows in set (0.00 sec)>select c_name,avg(grade) from score group by c_name;
+-----------+------------+
| c_name | avg(grade) |
+-----------+------------+
| 计算机 | 80.7500 |
| 英语 | 87.7500 |
| 中文 | 91.5000 |
+-----------+------------+
3 rows in set (0.00 sec)
>select s.name,c.c_name,c.grade
>from student as s inner join score as c
>on s.id=c.stu_id
>where c.c_name='计算机' andc.grade>=95;
+-----------+-----------+-------+
| name | c_name | grade |
+-----------+-----------+-------+
| 张老大 | 计算机 | 98 |
+-----------+-----------+-------+
1 row in set (0.00 sec)
]>select c_name,grade from score where c_name='计算机' order by grade desc;
+-----------+-------+
| c_name | grade |
+-----------+-------+
| 计算机 | 98 |
| 计算机 | 90 |
| 计算机 | 70 |
| 计算机 | 65 |
+-----------+-------+
4 rows in set (0.00 sec)
>select s.id from student as s inner join score as c on s.id=c.stu_id;
+-----+
| id |
+-----+
| 901 |
| 901 |
| 902 |
| 902 |
| 903 |
| 904 |
| 904 |
| 905 |
| 906 |
| 906 |
+-----+
10 rows in set (0.00 sec)>select s.name,group_concat(c.c_name),s.department,group_concat(c.grade)
>from student as s inner join score as c on s..id=c.stu_id
>where s.name like '王%' or s.name like '张%' group by s.id;
+-----------+------------------------+--------------+-----------------------+
| name | group_concat(c.c_name) | department | group_concat(c.grade) |
+-----------+------------------------+--------------+-----------------------+
| 张老大 | 计算机,英语 | 计算机系 | 98,80 |
| 张老二 | 计算机,中文 | 中文系 | 65,88 |
| 张三 | 中文 | 中文系 | 95 |
| 王五 | 英语 | 英语系 | 94 |
| 王六 | 计算机,英语 | 计算机系 | 90,85 |
+-----------+------------------------+--------------+-----------------------+
5 rows in set (0.00 sec)
>select s.name,year(curdate())-s.birth as age,s.department,group_concat(c.c_name) ,group_concat(c.grade)from studentas s inne
+--------+------+--------------+------------------------+-----------------------+
| name | age | department | group_concat(c.c_name) | group_concat(c.grade) |
+--------+------+--------------+------------------------+-----------------------+
| 张三 | 33 | 中文系 | 中文 | 95 |
| 王六 | 35 | 计算机系 | 计算机,英语 | 90,85 |
+--------+------+--------------+------------------------+-----------------------+
2 rows in set (0.00 sec)>select *,year(curdate())-birth as age from student;
+-----+-----------+------+-------+--------------+--------------------+------+
| id | name | sex | birth | department | address | age |
+-----+-----------+------+-------+--------------+--------------------+------+
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 | 38 |
| 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 | 37 |
| 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 | 33 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 | 33 |
| 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 | 32 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 | 35 |
+-----+-----------+------+-------+--------------+--------------------+------+
6 rows in set (0.00 sec)
相关文章:

多表查询--实例
1 创建student和score表 CREATE TABLE student ( id INT(10) NOT NULL UNIQUE PRIMARY KEY , name VARCHAR(20) NOT NULL , sex VARCHAR(4) , birth YEAR, department VARCHAR(20) , address VARCHAR(50) ); 创建score表。SQL代码如下: CREATE TABLE score ( id INT…...

Differentially Private Grids for Geospatial Data
文章目录abstractintroabstract 在本文中,我们解决了为二维数据集(如地理空间数据集)构建差异私有概要的问题。目前最先进的方法通过执行数据域的递归二进制分区和构造分区的层次结构来工作。我们表明,基于分区的概要方法的关键挑战在于选择正确的分区粒…...

Java学习记录day8
类与对象 继承例题 https://www.bilibili.com/video/BV1PU4y1E7nX?p55&vd_source8f80327daa664c039f5c342a25bcbbae(B站千峰马剑威Java基础入门视频第P55,记录的重要学习内容之一) final关键字 作用: 声明一个常量&…...

Solon2 开发之容器,三、注入或手动获取 Bean
1、如何注入Bean? 先了解一下Bean生命周期的简化版: 运行构建函数尝试字段注入(有时同步注入,没时订阅注入。不会有相互依赖而卡住的问题)Init 函数(是在容器初始化完成后才执行)…释放&#…...

微信小程序_调用openAi搭建虚拟伙伴聊天
微信小程序_调用openAi搭建虚拟伙伴聊天背景效果关于账号注册接口实现8行python搞定小程序实现页面结构数据逻辑结速背景 从2022年的年底,网上都是chagpt的传说,个人理解这个chatgpt是模型优化训练,我们在用chatgpt的时候就在优化这个模型&a…...
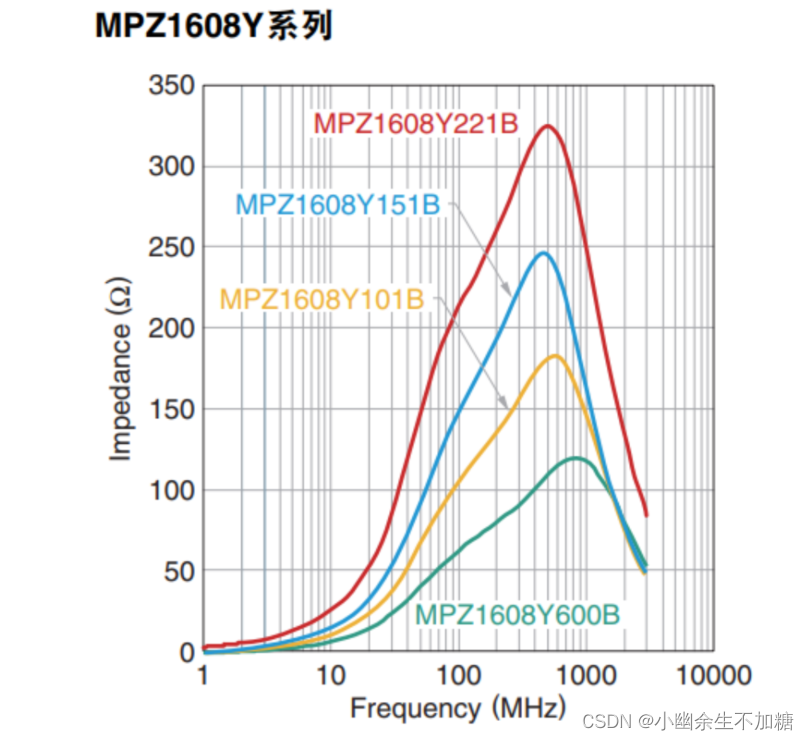
硬件工程师入门基础知识(一)基础元器件认识(一)
硬件工程师入门基础知识 (一)基础元器件认识(一) 今天水一篇hhh。介绍点基础但是实用的东西。 tips:学习资料和数据来自《硬件工程师炼成之路》、百度百科、网上资料。 1.贴片电阻 2.电容 3.电感 4.磁珠 1.贴片电…...
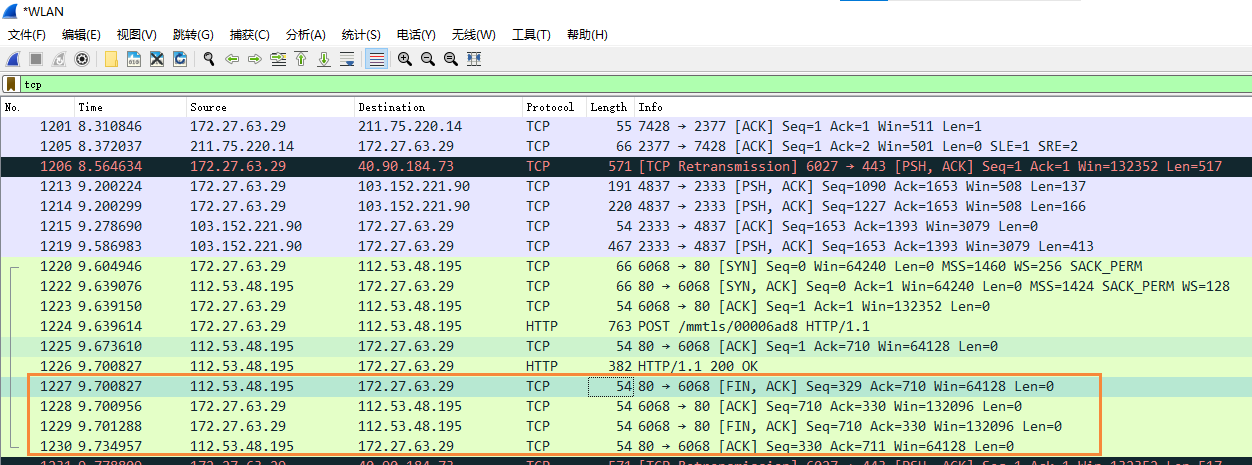
TCP的运输连接管理
TCP的运输连接管理 文章目录TCP的运输连接管理TCP报文格式简介首部各个字段的含义控制位(flags)TCP的连接建立抓包验证一些细节及解答TCP连接释放抓包验证一些细节及解答参考TCP是面向连接的协议。运输连接是用来传送TCP报文的。TCP运输连接的建立和释放时每一次面向连接的通信…...

地级市用电、用水、用气数据指标
用电用水量和煤气及液化石油气供应及利用情况可以反映出城市基础设施的建设情况!之前我们基于历年的《中国城市统计年鉴》整理了1999—2020年的人口数量数据指标、人口变动数据指标、用地相关数据指标、污染物排放和环境治理相关数据指标、地区生产总值及一二三产构…...

安装deepinlinuxV20.8配置docker和vscode开发c语言
# 重装的原因 某个开发任务时,发现需要glibc2.25,本机版本比较低,就下载源码configure make makeinstall,结果失败了, 看来与系统用的glibc有冲突,造成部分库版本不一致,打开终端出现段错误&#x…...
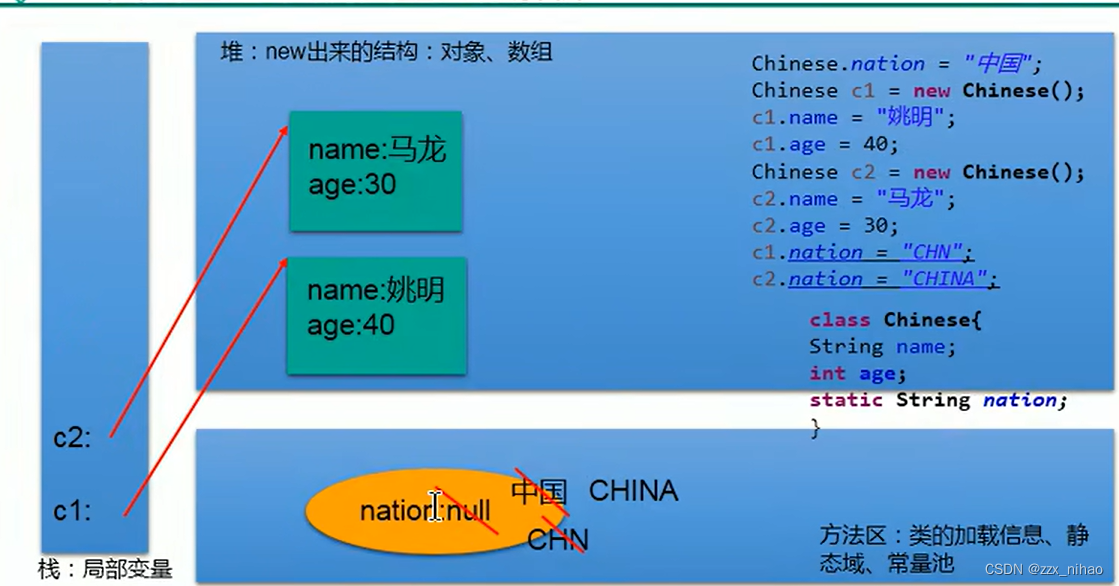
java08-面向对象3
一:static 关键字:静态的 1.可以用来修饰的结构:主要用来修饰类的内部结构 属性、方法、代码块、内部类 2. static 修饰属性:静态变量(或类变量) 2.1 属性,是否使用static修饰,又分为静态属…...
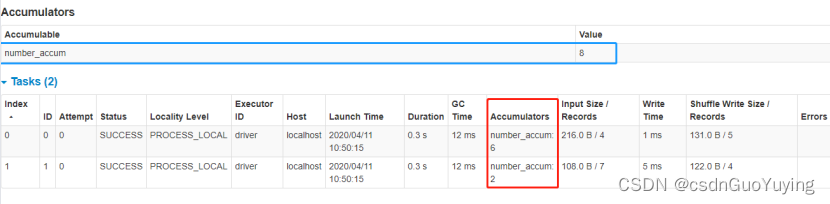
【Spark分布式内存计算框架——Spark Core】8. 共享变量
第七章 共享变量 在默认情况下,当Spark在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和…...

C++多态常见面试题
1.什么是多态 简单点说,就是多种形态,具体就是完成某个行为,当不同的对象去完成时产生的不同形态。多态分为静态多态和动态多态,静态多态一般指的是函数重载,在编译阶段通过函数名修饰规则,不同类型调用不同…...
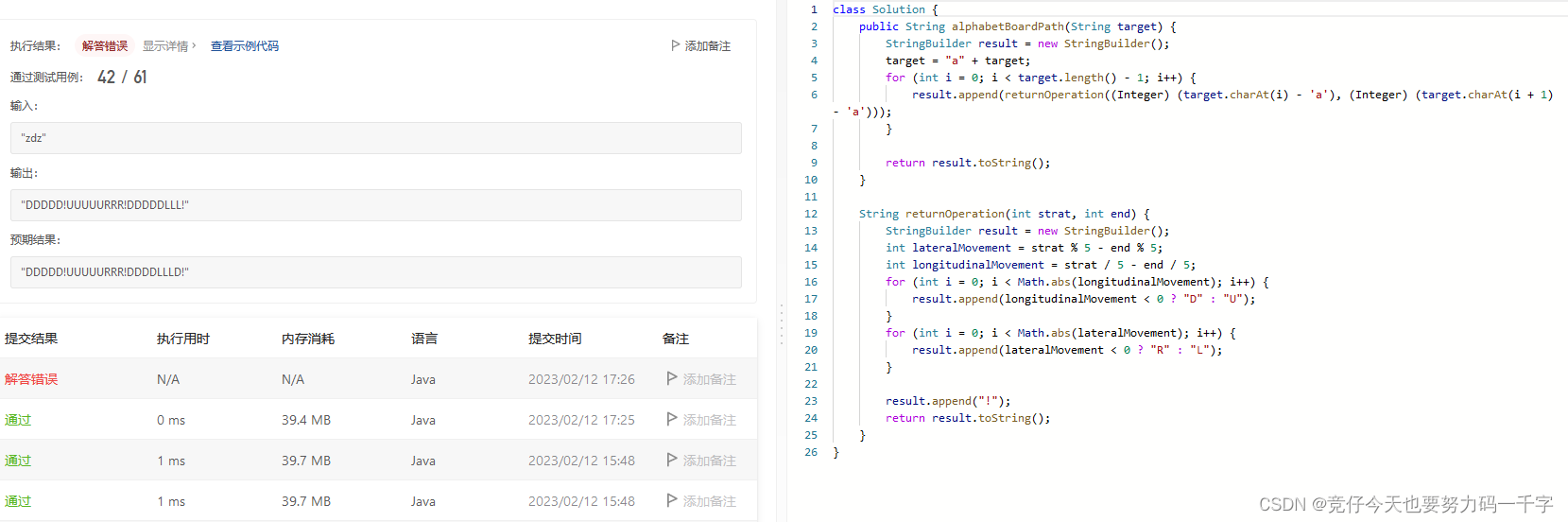
字母板上的路径 题解,力扣官方出来挨打(小声)
字母板上的路径 我们从一块字母板上的位置 (0, 0) 出发,该坐标对应的字符为 board[0][0]。 在本题里,字母板为board [“abcde”, “fghij”, “klmno”, “pqrst”, “uvwxy”, “z”],如下所示。 我们可以按下面的指令规则行动:…...
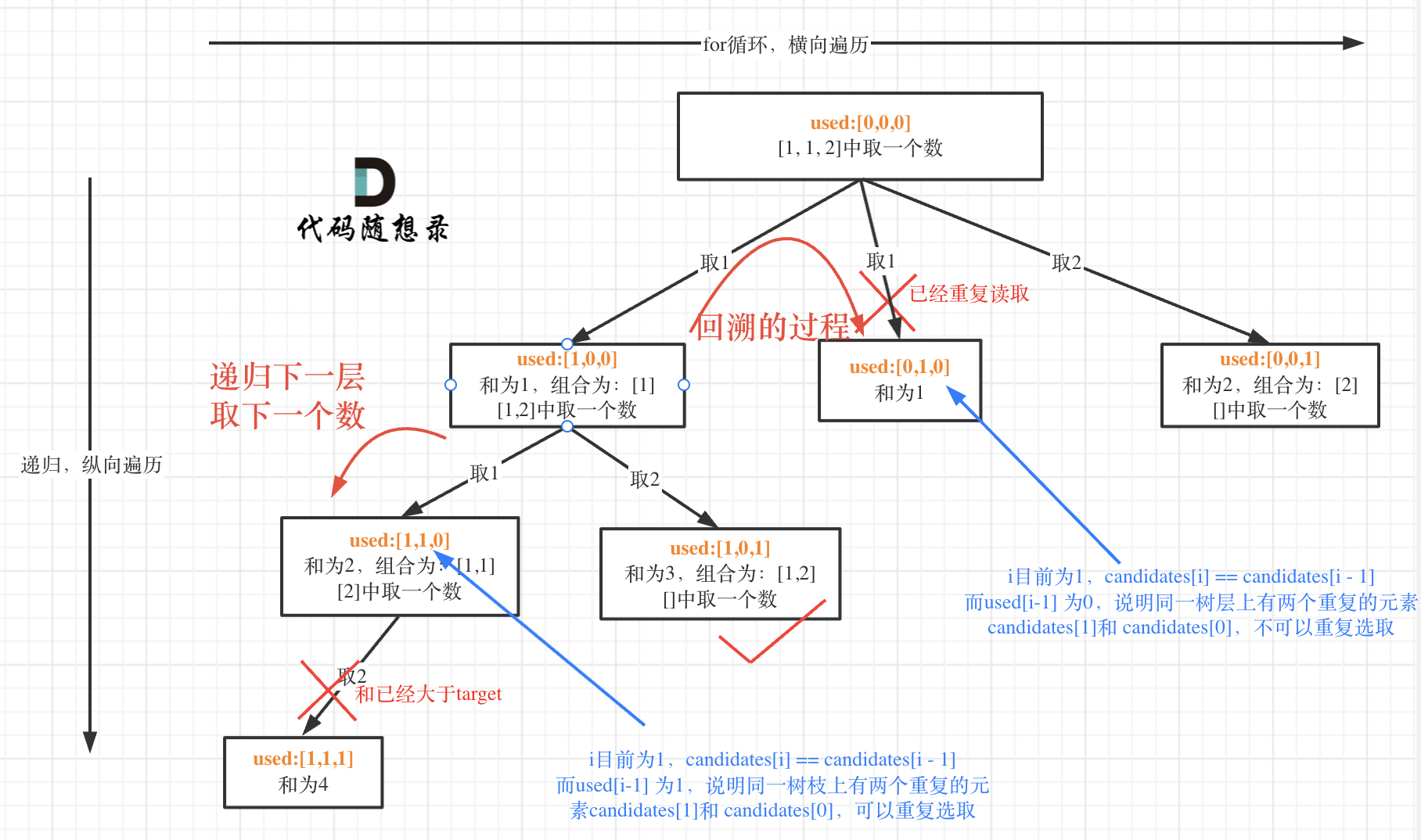
代码随想录算法训练营第二十六天 | 39. 组合总和,40.组合总和II,131.分割回文串
一、参考资料组合总和题目链接/文章讲解:https://programmercarl.com/0039.%E7%BB%84%E5%90%88%E6%80%BB%E5%92%8C.html 视频讲解:https://www.bilibili.com/video/BV1KT4y1M7HJ 组合总和II题目链接/文章讲解:https://programmercarl.com/004…...

vueday01-脚手架安装详细
一、vue脚手架安装命令npm i -g vue/cli 或 yarn global add vue/cli安装上面的工具,安装后运行 vue --version ,如果看到版本号,说明安装成功或 vue -V工具安装好之后,就可以安装带有webpack配置的vue项目了。创建项目之前&#…...
)
初识cesium3d(一)
使用ViteVue3.2Cesium。Vite需要Node.js版本14.18及以上版本。Vite命令创建的工程会自动生成vite.config.js文件,来配置一些相关的参数。 1、使用Vite创建vue3项目 # npm npm init vitelatest cesium-app -- --template vue # yarn yarn create vite cesium-app…...

点云转3D网格【Python】
推荐:使用 NSDT场景设计器 快速搭建 3D场景。 在本文中,我将介绍我的 3D 表面重建过程,以便使用 Python 从点云快速创建网格。 你将能够导出、可视化结果并将结果集成到您最喜欢的 3D 软件中,而无需任何编码经验。 此外࿰…...
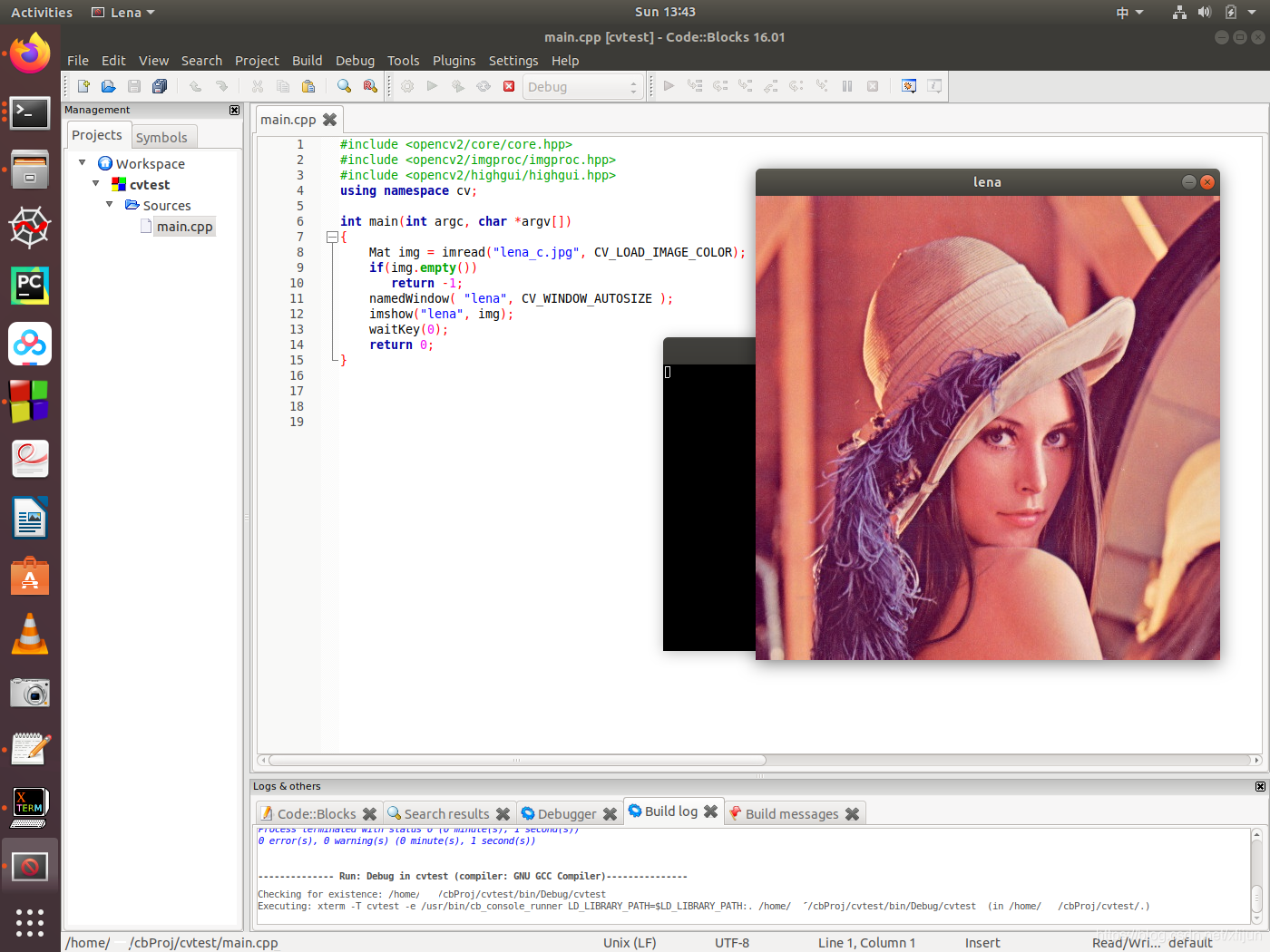
【OpenCV图像处理系列一】OpenCV开发环境的安装与搭建(Ubuntu + Window都适用)
🔗 运行环境:OpenCV,Ubuntu,Windows 🚩 撰写作者:左手の明天 🥇 精选专栏:《python》 🔥 推荐专栏:《算法研究》 #### 防伪水印——左手の明天 #### &#x…...

【代码随想录】-动态规划专题
文章目录理论基础斐波拉契数列爬楼梯使用最小花费爬楼梯不同路径不同路径 II整数拆分不同的二叉搜索树背包问题——理论基础01背包二维dp数组01背包一维数组(滚动数组)装满背包分割等和子集最后一块石头的重量 II目标和一和零完全背包零钱兑换 II组合总和…...

c++数据类型 输入输出
C++语法 //常用包: iostream:cin cout endl cstdio:scanf printf algorithm:max min reverse swap cstring:memset memcpymemset(a,-1,sizeof a) 填充数组memcpy(b,a,sizeof a) 将a数组复制到b数组,长度是a数组字节长度 cmath:sin sqrt pow abs fabs编程是一种控制计…...

AI技能树:构建系统化学习路径,从理论到工程实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“HieuNghi-AI-Skills”。光看这个名字,可能有点摸不着头脑,但点进去之后,我发现这其实是一个关于AI技能学习的资源集合库。简单来说,它就是一个由社区驱…...

3分钟拯救你的B站缓存视频:m4s-converter让珍贵回忆永不消失
3分钟拯救你的B站缓存视频:m4s-converter让珍贵回忆永不消失 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否遇到过这样的困扰…...

为什么你的Gemini写作总像“AI腔”?资深技术文档架构师揭秘3层语义校准法
更多请点击: https://intelliparadigm.com 第一章:为什么你的Gemini写作总像“AI腔”?资深技术文档架构师揭秘3层语义校准法 Gemini 生成的技术文档常被诟病为“语法正确但语义失焦”——术语堆砌、逻辑断层、人机语感割裂。根本原因在于模…...

Windows系统mfc140.dll文件丢失无法启动程序解决
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

基于MCP协议实现AI助手个性化:Terminal Buddies项目实战解析
1. 项目概述:当你的终端伙伴遇见AI助手 如果你和我一样,每天有大量时间泡在终端和代码编辑器里,那么一个能带来些许乐趣和陪伴感的“数字伙伴”或许能点亮枯燥的编码时光。Terminal Buddies 正是这样一个巧妙结合了复古 ASCII 艺术、轻量级游…...

ces sdfsdfdsf
https://github.com/wgpsec/redc https://github.com/wgpsec/benchmark-platform...

5G技术授权商业化的七大挑战与市场可行性深度解析
1. 项目概述:一次关于5G技术授权商业可行性的深度探讨最近在整理行业资料时,翻到一篇2019年EE Times上的旧文,标题挺抓人眼球,叫《授权华为5G技术可能是个坏主意的30个理由》。文章的核心是讨论当时华为创始人提出的一项设想&…...

【波导仿真】基于矢量有限元法分析均匀波导附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &#x…...

Spring Boot + JWT 实现无状态认证
1. JWT JWT(JSON Web Token)是一种开放标准(RFC 7519),用于在网络应用环境间安全地将信息作为 JSON 对象传输。JWT 是目前最流行的跨域认证解决方案,特别适合前后端分离的架构。 1.1 JWT 的结构 JWT 由三…...

从零到一:联想小新Air14 2020锐龙版Windows 10重装实战指南
1. 为什么需要重装系统? 最近有不少朋友跟我吐槽,说用了两年的联想小新Air14 2020锐龙版越来越卡,开机要等半天,打开个文档都要转圈圈。这种情况我太熟悉了,作为一个帮朋友修过不下20台同款机型的老司机,我…...