欺诈文本分类检测(十四):GPTQ量化模型
1. 引言
量化的本质:通过将模型参数从高精度(例如32位)降低到低精度(例如8位),来缩小模型体积。
本文将采用一种训练后量化方法GPTQ,对前文已经训练并合并过的模型文件进行量化,通过比较模型量化前后的评测指标,来测试量化对模型性能的影响。
GPTQ的核心思想在于:将所有权重压缩到8位或4位量化中,通过最小化与原始权重的均方误差来实现。在推理过程中,它将动态地将权重解量化为float16,以提高性能,同时保持较低的内存占用率。
注:均方误差是评估两个数值数据集之间差异的一种常用方法,它通过计算量化后权重与原始权重之间的均方误差,并使之最小化,来减少量化过程中引入的误差,以保持模型在推理时的性能。
2. 量化过程
2.1 加载量化模型
首先引入必要的包,其中:
- auto_gptq: 一个用于模型量化的库,通常用于减少模型的内存占用和计算消耗。
- AutoGPTQForCausalLM: 用于加载和使用经过量化的因果语言模型。
- BaseQuantizeConfig: 定义量化模型时所需的参数,例如量化精度。
- AutoTokenizer:transformers库提供的分词器,用于处理文本分词。
import os
import json
import torch
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from transformers import AutoTokenizer
定义量化任务要使用的设备,并指定模型的原始路径model_path。
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
device = 'cuda'
model_path = "/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud_1__0"
配置量化参数。
quantize_config = BaseQuantizeConfig(bits=8, group_size=128, # 分组量化damp_percent=0.01,desc_act=False, static_groups=False,sym=True,true_sequential=True,model_name_or_path=None,model_file_base_name="model"
)
参数释义如下:
- bits: 指定量化的位数为8位。
- group_size:量化时的分组大小,分组量化可以提高计算效率,通常设置为 128 是一个合理的选择,适合大多数模型。
- damp_percent:控制量化过程中对权重的平滑处理,防止过度量化导致的性能下降。默认值 0.01 通常是一个良好的起点,如果量化不佳,可以增加此值。
- desc_act:控制是否使用描述性激活,设置为 False 可以加速推理,如果模型的精度更重要,可以设置为 True。
- static_groups: 是否使用静态分组。静态分组可以提高推理效率, 如果模型结构固定且不需要动态调整,可以设置为 True。否则,保持为 False 以支持动态分组。
- sym: 指定是否使用对称量化。对称量化可以简化计算,如果模型对称性较好,可以设置为 True。
- true_sequential: 控制是否使用真实的顺序量化。真实顺序量化可以提高模型的表现,但可能会增加计算复杂性。如果模型对顺序敏感,可以设置为 True。
- model_file_base_name:指定生成的量化模型文件名称,最终体现在输出文件的命名上。
加载分词器,并根据配置quantize_config指定的量化位数来加载模型。
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoGPTQForCausalLM.from_pretrained(model_path, quantize_config)
2.2 准备校准数据集
GPTQ采用权重分组量化(如上面的配置中128列为一组),一个分组内的参数采用逐个进行量化(如下图所示),在每个参数被量化后,需要适当调整这个 block 内其他未量化的参数,以弥补量化造成的精度损失。

因此,GPTQ 量化需要准备校准数据集,我们这里采用一个以前生成的测试数据集作为校准数据。
def load_jsonl(path):conversations = []with open(path, 'r') as file:data = [json.loads(line) for line in file]conversations = [dialog['messages'] for dialog in data]return conversationseval_data_path = '/data2/anti_fraud/dataset/test_chatml_0815.jsonl'
conversations = load_jsonl(eval_data_path)
conversations[0]
校验数据集的数据格式是一个标准的聊天模板,示例如下:
[{'role': 'system', 'content': 'You are a helpful assistant.'},{'role': 'user','content': '\n下面是一段对话文本, 请分析对话内容是否有诈骗风险,以json格式输出你的判断结果(is_fraud: true/false)。\n\n\n发言人3: 那就是说看上半年我们的三四月份会不会有一些这个相关的一些这个缓解,就是说这方面的一些矛盾的一些缓解,债务的一个情况的一些缓解,那我们还要继续观察。\n发言人2: 好的,蒋总,那我们看一下那个其他投资者有没有什么其他问题。\n发言人1: 大家好,通过网络端接入的投资者可点击举手连麦等候提问,或在文字交流区提交您的问题,通过电话端接入的投资者请按星一键提问。先按星号键,再按一键,谢谢。大家好,通过网络端接入的投资者可点击举手连麦,然后提问,或在文字交流区提交您的问题。通过电话端接入的投资者请按星一键提问。\n发言人1: 先按星号键,再按数字一键,谢谢。'},{'role': 'assistant', 'content': '{"is_fraud": false}'}]
定义一个预处理函数,将文本数据预处理为张量数据。
def preprocess(dataset, max_len=1024):data = []for msg in dataset:text = tokenizer.apply_chat_template(msg, tokenize=False, add_generation_prompt=False)model_inputs = tokenizer([text])input_ids = torch.tensor(model_inputs.input_ids[:max_len], dtype=torch.int)data.append(dict(input_ids=input_ids, attention_mask=input_ids.ne(tokenizer.pad_token_id)))return datadataset = preprocess(conversations)
- tokenizer.apply_chat_template:负责将消息格式转化为Qwen模型需要的提示词格式。
- tokenizer([text]):使用tokenizer对文本进行分词,并将token转换为ID值。
- torch.tensor:将token_id转换为tensor张量。
配置日志显示格式:
import logginglogging.basicConfig(format="%(asctime)s %(levelname)s [%(name)s] %(message)s", level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S"
)
2.3 开始量化
使用校准数据集来动态调整量化参数,使模型在量化时学习并适应数据分布。
%%time
model.quantize(dataset, cache_examples_on_gpu=False)
INFO - Start quantizing layer 1/28
INFO - Quantizing self_attn.k_proj in layer 1/28...
INFO - Quantizing self_attn.v_proj in layer 1/28...
INFO - Quantizing self_attn.q_proj in layer 1/28...
INFO - Quantizing self_attn.o_proj in layer 1/28...
INFO - Quantizing mlp.up_proj in layer 1/28...
INFO - Quantizing mlp.gate_proj in layer 1/28...
INFO - Quantizing mlp.down_proj in layer 1/28...
INFO - Start quantizing layer 2/28
……
INFO - Start quantizing layer 28/28
INFO - Quantizing self_attn.k_proj in layer 28/28...
INFO - Quantizing self_attn.v_proj in layer 28/28...
INFO - Quantizing self_attn.q_proj in layer 28/28...
INFO - Quantizing self_attn.o_proj in layer 28/28...
INFO - Quantizing mlp.up_proj in layer 28/28...
INFO - Quantizing mlp.gate_proj in layer 28/28...
INFO - Quantizing mlp.down_proj in layer 28/28...CPU times: user 30min 52s, sys: 3min 40s, total: 34min 32s
Wall time: 27min 23s
由于内容太长,中间作了省略,不过仍然可以看出,量化是一层一层逐个对每个矩阵分别进行量化的,一个1.5B的模型量化过程耗时达27分钟。
保存量化后的模型和分词器状态。
- quant_path指定了量化模型的保存路径
- use_safetensors=True 参数表示使用安全张量格式(SafeTensors)进行保存,具有更好的安全性和性能。
- tokenizer.save_pretrained为量化后的模型保存一份分词器配置。
quant_path = "/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int8"
model.save_quantized(quant_path, use_safetensors=True)
tokenizer.save_pretrained(quant_path)
输出保存的分词器配置。
('/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int8/tokenizer_config.json','/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int8/special_tokens_map.json','/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int8/vocab.json','/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int8/merges.txt','/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int8/added_tokens.json','/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int8/tokenizer.json')
2.4 4位量化
上面是采用8位量化,作为对比,我们也量化一个4位模型,与8位量化的区别只在于量化配置时的参数bits改成了4,其它都不作改变.
quantize_config_int4 = BaseQuantizeConfig(bits=4, # 4位量化group_size=128, # 分组量化damp_percent=0.01,desc_act=False, static_groups=False,sym=True,true_sequential=True,model_name_or_path=None,model_file_base_name="model"
)
采用4位量化配置来加载模型。
model_int4 = AutoGPTQForCausalLM.from_pretrained(model_path, quantize_config_int4)
对4位参数进行量化校验,校准数据集复用前面8位量化时生成的数据。
%%time
model_int4.quantize(dataset, cache_examples_on_gpu=False)
INFO - Start quantizing layer 1/28
INFO - Quantizing self_attn.k_proj in layer 1/28...
INFO - Quantizing self_attn.v_proj in layer 1/28...
INFO - Quantizing self_attn.q_proj in layer 1/28...
INFO - Quantizing self_attn.o_proj in layer 1/28...
INFO - Quantizing mlp.up_proj in layer 1/28...
INFO - Quantizing mlp.gate_proj in layer 1/28...
INFO - Quantizing mlp.down_proj in layer 1/28...
INFO - Start quantizing layer 2/28
……
INFO - Start quantizing layer 28/28
INFO - Quantizing self_attn.k_proj in layer 28/28...
INFO - Quantizing self_attn.v_proj in layer 28/28...
INFO - Quantizing self_attn.q_proj in layer 28/28...
INFO - Quantizing self_attn.o_proj in layer 28/28...
INFO - Quantizing mlp.up_proj in layer 28/28...
INFO - Quantizing mlp.gate_proj in layer 28/28...
INFO - Quantizing mlp.down_proj in layer 28/28...CPU times: user 37min 11s, sys: 3min 2s, total: 40min 13s
Wall time: 31min 56s
保存量化后的模型和分词器配置。
quant_int4_path = "/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int4"
model_int4.save_quantized(quant_int4_path, use_safetensors=True)
tokenizer.save_pretrained(quant_int4_path)
('/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int4/tokenizer_config.json','/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int4/special_tokens_map.json','/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int4/vocab.json','/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int4/merges.txt','/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int4/added_tokens.json','/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int4/tokenizer.json')
3. 评测
与前文不同,这里统一采用测试数据集进行评测,以评估模型的最终性能。
原始模型评测(16位)
%run evaluate.py
testdata_path = '/data2/anti_fraud/dataset/test0819.jsonl'
evaluate(model_path, '', testdata_path, device, batch=True, debug=True)
progress: 100%|██████████| 2349/2349 [01:52<00:00, 20.87it/s]tn:1136, fp:31, fn:162, tp:1020
precision: 0.9705042816365367, recall: 0.8629441624365483
这时的召回率recall
0.8629和前文的测评结果0.9129有差异,前文用的验证集,这里用的是测试集,可能是这两个数据集的数据分布不均匀,导致两者结果有较大差异。
量化8位模型评测
%run evaluate.py
testdata_path = '/data2/anti_fraud/dataset/test0819.jsonl'
model_int8_path = '/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int8'
evaluate(model_gptq_path, '', testdata_path, device, batch=True, debug=True)
tn:1134, fp:33, fn:158, tp:1024
precision: 0.9687795648060549, recall: 0.8663282571912013
8位量化模型的评测结果与原始模型基本一致,说明8位量化依然保持了原始模型的推理表现。
量化4位模型评测
%run evaluate.py
testdata_path = '/data2/anti_fraud/dataset/test0819.jsonl'
model_int4_path = '/data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int4'
tokenizer = AutoTokenizer.from_pretrained(model_int4_path)
model_int4_reload = AutoModelForCausalLM.from_pretrained(model_int4_path, device_map=device)
evaluate_with_model(model_int4_reload, tokenizer, testdata_path, device, batch=True, debug=True)
注:4位量化模型这里之所以要单独加载model,是因为GPTQ量化的4位模型有个限制——只能在GPU上运行,我们原先的加载方式会报错,详情可以参看本文最后的
附:4位量化模型加载错误。
tn:1081, fp:86, fn:50, tp:1132
precision: 0.9293924466338259, recall: 0.9576988155668359
从这个结果来看,4位量化模型与原始模型的性能差别较大,具体体现在:
- 精确率下降明显,表明模型在检测欺诈文本时,误报(false positives)数量增加,模型可能会将更多的非欺诈文本错误地分类为欺诈文本。
- 召回率上升,模型在检测欺诈时漏报(false negatives)的数量减少,这意味着模型在检测欺诈文本时更加激进,尽可能减少漏报,哪怕误报增加。
4位量化比8位量化引入更多的信息丢失和噪声,模型权重和激活值的精度显著下降,最终导致分类效果的明显差异。
4. 模型文件差异
原始模型文件列表信息:
!ls -l /data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud_1__0
total 3026376-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 80 Aug 29 11:30 added_tokens.json-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 748 Aug 29 11:30 config.json-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 242 Aug 29 11:30 generation_config.json-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 1671853 Aug 29 11:30 merges.txt-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 1975314632 Aug 29 11:30 model-00001-of-00002.safetensors-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 1112152304 Aug 29 11:30 model-00002-of-00002.safetensors-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 27693 Aug 29 11:30 model.safetensors.index.json-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 367 Aug 29 11:30 special_tokens_map.json-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 1532 Aug 29 11:30 tokenizer_config.json-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 7028043 Aug 29 11:30 tokenizer.json-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 2776833 Aug 29 11:30 vocab.json
8位量化模型的文件列表信息:
!ls -l /data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int8
total 2235860
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 80 Sep 10 11:53 added_tokens.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 1062 Sep 10 11:53 config.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 1671853 Sep 10 11:53 merges.txt
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 2278014312 Sep 10 11:53 model.safetensors
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 269 Sep 10 11:53 quantize_config.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 367 Sep 10 11:53 special_tokens_map.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 1532 Sep 10 11:53 tokenizer_config.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 7028043 Sep 10 11:53 tokenizer.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 2776833 Sep 10 11:53 vocab.json
4位量化模型的文件列表信息:
!ls -l /data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int4
total 1591120
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 80 Sep 10 12:50 added_tokens.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 1088 Sep 10 18:12 config.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 1671853 Sep 10 12:50 merges.txt
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 1617798120 Sep 10 12:50 model.safetensors
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 269 Sep 10 12:50 quantize_config.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 367 Sep 10 12:50 special_tokens_map.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 1532 Sep 10 12:50 tokenizer_config.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 7028043 Sep 10 12:50 tokenizer.json
-rw-rw-r-- 1 xiaoguanghua xiaoguanghua 2776833 Sep 10 12:50 vocab.json
可以看到,原始模型、8位量化、4位量化三者的模型文件大小分别3.08GB、2.27GB、1.61GB,量化位数越小,模型文件相应也越小。
另外还可以看到,模型文件大小与量化位宽的比例并不完全是线性关系。因为除了模型参数本身之外,还有模型架构、框架开销(pytorch)、优化器的动量和梯度信息等,这些都会影响着模型文件的总大小。
小结:本文通过gptq方法分别对微调后的模型进行了8位量化和4位量化,并对比了量化前后模型的性能指标差异,8位量化模型的性能指标变化小,而4位量化模型的性能指标变异较大。就我们这个场景来说,更适合采用8位量化模型。
附1:4位量化模型加载错误
使用如下代码进行先CPU加载再移到目标GPU时会报Found modules on cpu/disk错误:
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16).eval().to(device)
错误详情:
ValueError: Found modules on cpu/disk. Using Exllama or Exllamav2 backend requires all the modules to be on GPU.You can deactivate exllama backend by setting `disable_exllama=True` in the quantization config object
原因:使用GPTQ方式量化int4模型时使用了exllama,这是一种高效的kernel实现,但需要所有模型参数在GPU上,因此对于GPTQ的4位量化模型,先使用CPU加载再移到GPU这种做法行不通。
解法:
- 在模型目录下的config.json文件中,在quantization_config配置块中设置
disable_exllama=true或者use_exllama=false,来禁用exllama,不过可能会影响推理速度。 - 在加载模型时直接加载到GPU上,类似
from_disk = AutoModelForCausalLM.from_pretrained(path, device_map="cuda:0")
附2:偏置参数未使用警告
在加载4位量化模型时会报此警告,详细信息如下:
Some weights of the model checkpoint at /data2/anti_fraud/models/Qwen2-1__5B-Instruct-anti_fraud-gptq-int4 were not used when initializing Qwen2ForCausalLM: ['model.layers.0.mlp.down_proj.bias', 'model.layers.0.mlp.gate_proj.bias', 'model.layers.0.mlp.up_proj.bias',
……
'model.layers.9.self_attn.o_proj.bias']
此问题的原因暂时未找到,哪位小伙伴知道原因有劳告知。
这个网页上有人报类似问题,但未说明原因:https://github.com/QwenLM/Qwen2/issues/239
参考资料
- 欺诈文本分类检测(十一):LLamaFactory多卡微调
- 欺诈文本分类检测(十二):模型导出与部署
- 大模型量化技术原理
- Found modules on cpu/disk错误讨论
相关文章:
欺诈文本分类检测(十四):GPTQ量化模型
1. 引言 量化的本质:通过将模型参数从高精度(例如32位)降低到低精度(例如8位),来缩小模型体积。 本文将采用一种训练后量化方法GPTQ,对前文已经训练并合并过的模型文件进行量化,通…...

2024.9.14(RC和RS)
一、replicationcontroller (RC) 1、更改镜像站 [rootk8s-master ~]# vim /etc/docker/daemon.json {"registry-mirrors": ["https://do.nark.eu.org","https://dc.j8.work","https://docker.m.daocloud.io",&…...

【算法随想录04】KMP 字符串匹配算法
这是字符串模式匹配经典算法。 给定一个文本 t 和一个字符串 s,我们尝试找到并展示 s 在 t 中的所有出现(occurrence)。 #include<bits/stdc.h>using namespace std;vector<int> KMP(string s) {int n s.size();vector<int&g…...

TCP和MQTT通信协议
协议分层 网络分层 协议应用层 Co AP MQTT HTTP传输层 UDP TCP网络层 IP链路层 Enternet 网络分层中最…...

Python Pickle 与 JSON 序列化详解:存储、反序列化与对比
Python Pickle 与 JSON 序列化详解:存储、反序列化与对比 文章目录 Python Pickle 与 JSON 序列化详解:存储、反序列化与对比一 功能总览二 Pickle1 应用2 序列化3 反序列化4 系统资源对象1)不能被序列化的系统资源对象2)强行序列…...

第二百三十二节 JPA教程 - JPA教程 - JPA ID自动生成器示例、JPA ID生成策略示例
JPA教程 - JPA ID自动生成器示例 我们可以将id字段标记为自动生成的主键列。 数据库将在插入时自动为id字段生成一个值数据到表。 例子 下面的代码来自Person.java。 package cn.w3cschool.common;import javax.persistence.Entity; import javax.persistence.GeneratedValu…...

计算机网络 ---- 计算机网络的体系结构【计算机网络的分层结构】
一、以快递网络来引入分层思想 1.1 “分层” 的设计思想【将庞大而复杂的问题,转化为若干较小的局部问题】 从我们最熟悉的快递网络出发,在你家附近会有一个快递终点站A,在其他的城市,也会有这种快递终点站,比如说快递…...

Vite + Electron 时,Electron 渲染空白,静态资源加载错误等问题解决
问题 如果在 electron 里直接引入 vite 打包后的东西,那么有些资源是请求不到的 这是我的引入方式 根据报错,我们来到 vite 打包后的路径看一看 ,修改一下 dist 里的文件路径试了一试 修改后的样子,发现是可以的了 原因分析 …...
)
ZAB协议(算法)
一、ZAB(ZooKeeper Atomic Broadcast)介绍 ZAB 即 ZooKeeper Atomic Broadcast,是 ZooKeeper 实现分布式数据一致性的核心算法。它是一种原子广播协议,用于确保在分布式环境中,多个 ZooKeeper 服务器之间的数据一致性。…...
多个音频怎么合并?把多个音频合并在一起的方法推荐
多个音频怎么合并?无论是制作连贯的播客节目还是将音乐片段整合成专辑,音频合并已成为许多创作者的常见需求。通过有效合并音频,可以显著提升项目的整体质量,确保内容的连续性和一致性。然而,合并后的文件通常比原始单…...
 与 DRF APIView 的区别解析)
【Django】Django Class-Based Views (CBV) 与 DRF APIView 的区别解析
Django Class-Based Views (CBV) 与 DRF APIView 的区别解析 在 Django 开发中,基于类的视图(Class-Based Views, CBV)是实现可重用性和代码结构化的利器。而 Django REST Framework (DRF) 提供的 APIView 是针对 API 开发的扩展。 一、CBV …...

如何增加Google收录量?
想增加Google收录量,首先自然是你的页面数量就要多,但这些页面的内容也绝对不能敷衍,你的网站都没多少页面,谷歌哪怕想收录都没办法,当然,这是一个过程,持续缓慢的增加页面,增加网站…...

leetcode练习 格雷编码
n 位格雷码序列 是一个由 2n 个整数组成的序列,其中: 每个整数都在范围 [0, 2n - 1] 内(含 0 和 2n - 1)第一个整数是 0一个整数在序列中出现 不超过一次每对 相邻 整数的二进制表示 恰好一位不同 ,且第一个 和 最后一…...

【LLM:Gemini】文本摘要、信息提取、验证和纠错、重新排列图表、视频理解、图像理解、模态组合
开始使用Gemini 目录 开始使用Gemini Gemini简介 Gemini实验结果 Gemini的多模态推理能力 文本摘要 信息提取 验证和纠错 重新排列图表 视频理解 图像理解 模态组合 Gemini多面手编程助理 库的使用 引用 本文概述了Gemini模型和如何有效地提示和使用这些模型。本…...

CMS之Wordpress建设
下载 https://cn.wordpress.org/ 宝塔安装Wordpress 创建网站 上传文件、并解压、剪切文件到项目根目录 安装 -> 数据库信息 -> 标题信息 http://wordpress.xxxxx.com 登录 http://wordpress.xxxxxxxxx.com/wp-admin/ 1. 主题(模板) wordpress-基本使用-02-在主题…...

使用Neo4j存储聊天记录的简单教程
引言 在当今的数据驱动世界中,关系型数据库有时难以处理复杂的、相互关联的数据集。Neo4j作为一款开源图数据库,以其高效管理高连接数据的能力而广受欢迎。本篇文章将详细介绍如何使用Neo4j来存储聊天信息历史,引导您在实际项目中利用其强大…...

前端面试常考算法
快速排序 #include<iostream> #include<cstdio> using namespace std; const int N 100005; int a[N];void quick_sort(int a[], int l, int r) {if (l > r) return;int x a[l r >> 1];int i l - 1, j r 1;while (i < j) {while (a[i] < x);…...

【机试准备】常用容器与函数
Vector详解 原文链接:【超详细】C vector 详解 例题,这一篇就够了-CSDN博客 向量(Vector)是一个封装了动态大小数组的顺序容器(Sequence Container)。跟任意其它类型容器一样,它能够存放各种…...
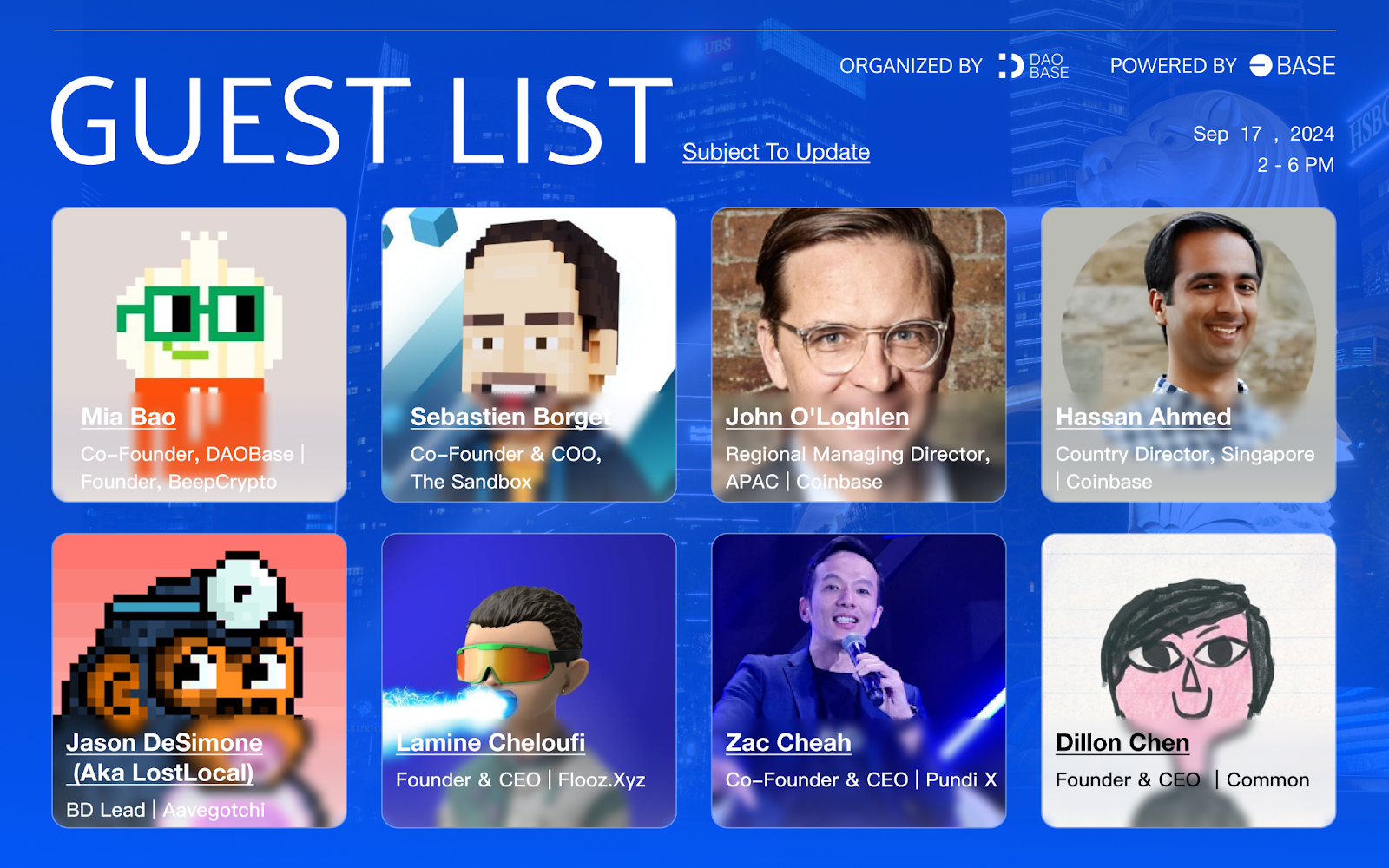
Base 社区见面会 | 新加坡站
活动信息 备受期待的 Base 社区见面会将于 Token2049 期间在新加坡举行,为 Base 爱好者和生态系统建设者提供一个独特的交流机会。本次活动由 DAOBase 组织,Base 和 Coinbase 提供支持,并得到了以下合作伙伴的大力支持: The Sand…...

麒麟操作系统搭建Nacos集群
Nacos 集群搭建 2.4.2 环境介绍 操作系统Kylin Linux Advanced Server V10 (Lance)Kylin Linux Advanced Server V10 (Lance)Kylin Linux Advanced Server V10 (Lance)内核版本Linux 4.19.90-52.22.v2207.ky10.aarch64Linux 4.19.90-52.22.v2207.ky10.aarch64Linux 4.19.90-52…...

华为设备静态路由与BFD联动实战:从配置到故障切换全解析
1. 为什么需要BFD与静态路由联动? 静态路由就像一张纸质地图,一旦画好就不会自动更新。当某条道路(网络链路)突然塌方时,纸质地图不会自动标注"此路不通",司机(数据包)还是…...
——基于阿里云的远程监控与交互控制)
【STM32实战】机械臂快递分拣系统(三)——基于阿里云的远程监控与交互控制
1. 阿里云物联网平台接入实战 第一次接触阿里云物联网平台时,我被它强大的设备管理能力震撼到了。这个平台就像个智能管家,不仅能实时监控设备状态,还能远程下发控制指令。对于我们的机械臂快递分拣系统来说,简直是量身定做的解决…...

VideoAgentTrek-ScreenFilter艺术化过滤效果:将敏感区域替换为创意图案而非简单模糊
VideoAgentTrek-ScreenFilter艺术化过滤效果:将敏感区域替换为创意图案而非简单模糊 最近在折腾视频内容处理时,我发现了一个挺有意思的新玩法。传统的视频敏感信息处理,比如给人脸打码、给车牌模糊,总是显得有点生硬,…...

OpenClaw配置优化:Kimi-VL-A3B-Thinking的vllm参数调校指南
OpenClaw配置优化:Kimi-VL-A3B-Thinking的vllm参数调校指南 1. 为什么需要关注vllm参数调校 去年第一次接触Kimi-VL-A3B-Thinking多模态模型时,我天真地以为只要把模型跑起来就能获得理想性能。结果在OpenClaw上部署后,处理简单的图文问答任…...

RMBG-2.0部署避坑指南:常见问题解决方案
RMBG-2.0部署避坑指南:常见问题解决方案 1. 引言 最近RMBG-2.0这个开源背景去除模型确实火得不行,效果确实惊艳,精确到发丝级别的抠图能力让很多开发者跃跃欲试。但在实际部署过程中,不少朋友都遇到了各种坑:环境配置…...

大模型应用开发零基础教程:30分钟上手
大模型应用开发零基础教程:30分钟上手 标签:#人工智能、#大模型、#自然语言处理、#大模型开发、#智能体开发、#agent开发、#AI 系统封装学习规划(从玩具到产品) 用streamlit run xxx.py --server.port 8501本地测试免费部署&#…...

东莞故意伤害罪律师在线咨询
在东莞遇到故意伤害罪相关法律问题,别慌!广东秦仪律师团队为您提供专业且贴心的在线咨询服务。我们拥有经验丰富的律师,他们不仅是广东省律师协会会员,还在法律领域深耕多年,有着扎实的法律知识和丰富的实战经验。曾在…...

别再只跑Demo了!手把手教你用YOLOv5/v8训练自己的钢材缺陷数据集并部署成Web服务
从零构建工业级钢材缺陷检测系统:YOLOv5/v8实战全流程指南 在工业质检领域,深度学习技术正在掀起一场革命。想象一下,当传统质检员需要花费数小时仔细检查钢材表面的每一寸区域时,一个训练有素的AI系统可以在几毫秒内完成同样的工…...

都是微软亲儿子,WPF凭啥干不掉WinForm?这3个场景说明白了
大家好,我是码农刚子。 前两天有个刚入行的兄弟问我:“现在学桌面开发,是学WinForm还是WPF?我看网上也有人问都是基于.NET平台,WPF能取代Winform吗?” 我听完笑了笑。这个问题吧,就跟“C#能不能取代Java”一…...
)
用libhv从零搭建一个能跑7万QPS的微型HTTP服务器(附完整源码解析)
用libhv构建7万QPS的微型HTTP服务器:工业级性能优化实战 在当今快速迭代的互联网服务开发中,开发者经常面临一个核心矛盾:如何在不牺牲性能的前提下,快速构建可投入生产环境的高并发服务?传统方案往往需要在开发效率与…...