时序数据库 TDengine 的入门体验和操作记录
时序数据库 TDengine 的学习和使用经验
- 什么是 TDengine ?
- 什么是时序数据 ?
- 使用RPM安装包部署
- 默认的网络端口
- TDengine 使用
- TDengine 命令行(CLI)
- taosBenchmark
- 服务器内存需求
- 删库跑路测试
- 使用体验
- 文档纠错
什么是 TDengine ?
TDengine 核心是一款高性能、集群开源、云原生的时序数据库(Time Series Database,TSDB),专为物联网IoT平台、工业互联网、电力、IT 运维等场景设计并优化,具有极强的弹性伸缩能力。同时它还带有内建的缓存、流式计算、数据订阅等系统功能,能大幅减少系统设计的复杂度,降低研发和运营成本,是一个高性能、分布式的物联网IoT、工业大数据平台。
官网:https://www.taosdata.com/
GitHub 社区:https://github.com/taosdata/TDengine
什么是时序数据 ?
时序数据,即时间序列数据(Time-Series Data),是一组按照时间发生先后顺序进行排列的序列数据。日常生活中,设备、传感器采集的数据,证券交易的记录都是时序数据。这些时序数据是周期、准周期产生的,或事件触发产生的,有的采集频率高,有的采集频率低。一般被发送至服务器中进行汇总并进行实时分析和处理,对系统的运行做出实时监测或预警,对股市行情进行预测。这些数据也可以被长期保存下来,用以进行离线数据分析。
时序数据的十大特征:
- 数据是时序的,一定带有时间戳
- 数据是结构化的
- 一个数据采集点就是一个数据流
- 数据较少有更新删除操作
- 数据不依赖于事务
- 相对互联网应用,写多读少
- 用户关注的是一段时间的趋势
- 数据是有保留期限的
- 需要实时分析计算操作
- 流量平稳、可预测
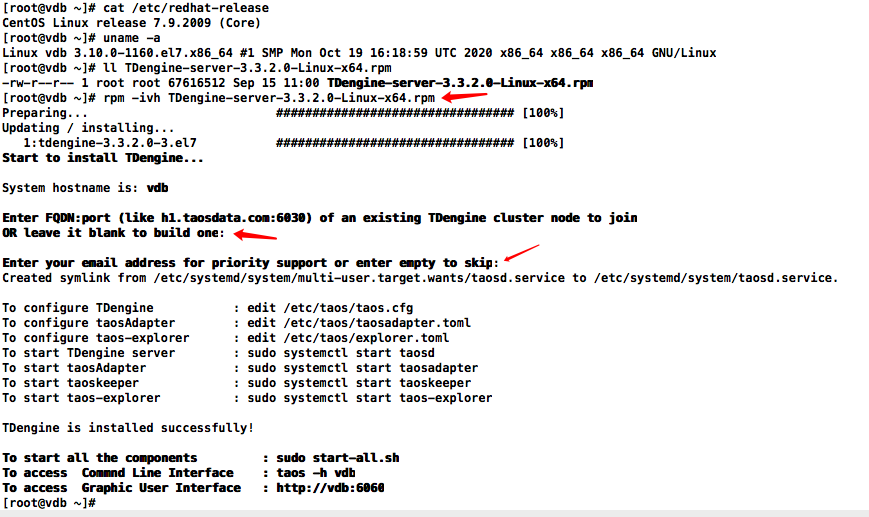
使用RPM安装包部署
硬件环境:
[root@vdb ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
[root@vdb ~]# uname -a
Linux vdb 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
[root@vdb ~]# ll TDengine-server-3.3.2.0-Linux-x64.rpm
-rw-r--r-- 1 root root 67616512 Sep 15 11:00 TDengine-server-3.3.2.0-Linux-x64.rpm
安装
[root@vdb ~]# rpm -ivh TDengine-server-3.3.2.0-Linux-x64.rpm
Preparing... ################################# [100%]
Updating / installing...1:tdengine-3.3.2.0-3.el7 ################################# [100%]
Start to install TDengine...System hostname is: vdbEnter FQDN:port (like h1.taosdata.com:6030) of an existing TDengine cluster node to join
OR leave it blank to build one:Enter your email address for priority support or enter empty to skip:
Created symlink from /etc/systemd/system/multi-user.target.wants/taosd.service to /etc/systemd/system/taosd.service.To configure TDengine : edit /etc/taos/taos.cfg
To configure taosAdapter : edit /etc/taos/taosadapter.toml
To configure taos-explorer : edit /etc/taos/explorer.toml
To start TDengine server : sudo systemctl start taosd
To start taosAdapter : sudo systemctl start taosadapter
To start taoskeeper : sudo systemctl start taoskeeper
To start taos-explorer : sudo systemctl start taos-explorerTDengine is installed successfully!To start all the components : sudo start-all.sh
To access Commnd Line Interface : taos -h vdb
To access Graphic User Interface : http://vdb:6060
启动 TDengine 的服务进程
systemctl start taosd
systemctl start taosadapter
systemctl start taoskeeper
systemctl start taos-explorer
备注:systemctl stop taosd 指令在执行后并不会马上停止 TDengine 服务,而是会等待系统中必要的落盘工作正常完成。在数据量很大的情况下,这可能会消耗较长时间。
默认的网络端口
TDengine 的一些接口或组件的常用端口,这些端口均可以通过配置文件中的参数进行修改。
| 接口或组件 | 端口 |
|---|---|
| 原生接口(taosc) | 6030 |
| RESTful 接口 | 6041 |
| WebSocket 接口 | 6041 |
| taosKeeper | 6043 |
| taosX | 6050, 6055 |
| taosExplorer | 6060 |
TDengine 使用
TDengine 命令行(CLI)
客户端命令taos,语法特性跟MySQL有点类似
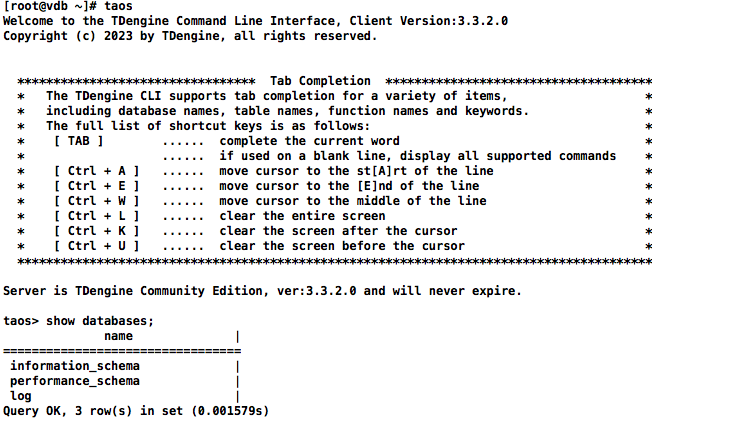
[root@vdb ~]# taos
Welcome to the TDengine Command Line Interface, Client Version:3.3.2.0
Copyright (c) 2023 by TDengine, all rights reserved.********************************* Tab Completion ************************************** The TDengine CLI supports tab completion for a variety of items, ** including database names, table names, function names and keywords. ** The full list of shortcut keys is as follows: ** [ TAB ] ...... complete the current word ** ...... if used on a blank line, display all supported commands ** [ Ctrl + A ] ...... move cursor to the st[A]rt of the line ** [ Ctrl + E ] ...... move cursor to the [E]nd of the line ** [ Ctrl + W ] ...... move cursor to the middle of the line ** [ Ctrl + L ] ...... clear the entire screen ** [ Ctrl + K ] ...... clear the screen after the cursor ** [ Ctrl + U ] ...... clear the screen before the cursor *****************************************************************************************Server is TDengine Community Edition, ver:3.3.2.0 and will never expire.taos> show databases;name |
=================================information_schema |performance_schema |log |
Query OK, 3 row(s) in set (0.001579s)taos> CREATE DATABASE demo;
Create OK, 0 row(s) affected (0.173739s)taos> use demo;
Database changed.taos> CREATE TABLE t (ts TIMESTAMP, speed INT);
Create OK, 0 row(s) affected (0.002680s)taos> INSERT INTO t VALUES ('2024-09-15 00:00:00', 10);
Insert OK, 1 row(s) affected (0.000937s)taos> INSERT INTO t VALUES ('2014-09-15 01:00:00', 20);DB error: Timestamp data out of range (0.000959s)
taos> INSERT INTO t VALUES ('2024-09-15 01:00:00', 20);
Insert OK, 1 row(s) affected (0.000789s)taos> INSERT INTO t VALUES ('2024-09-15 00:00:00', 30);
Insert OK, 1 row(s) affected (0.000893s)taos> INSERT INTO t VALUES ('2024-09-14 00:00:00', 40);
Insert OK, 1 row(s) affected (0.000929s)taos> SELECT * FROM t;ts | speed |
========================================2024-09-14 00:00:00.000 | 40 |2024-09-15 00:00:00.000 | 30 |2024-09-15 01:00:00.000 | 20 |
Query OK, 3 row(s) in set (0.001628s)
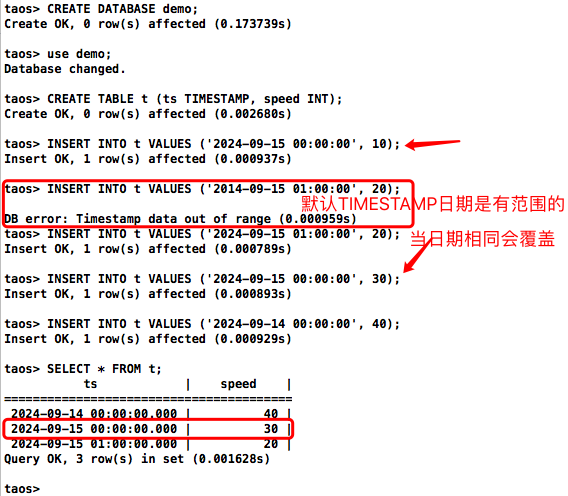
- 默认TIMESTAMP日期是有范围的
- 插入相同日期会直接做覆盖处理
taosBenchmark
taosBenchmark 是一个专为测试 TDengine 性能而设计的工具,它能够全面评估TDengine 在写入、查询和订阅等方面的功能表现。
taosBenchmark -y
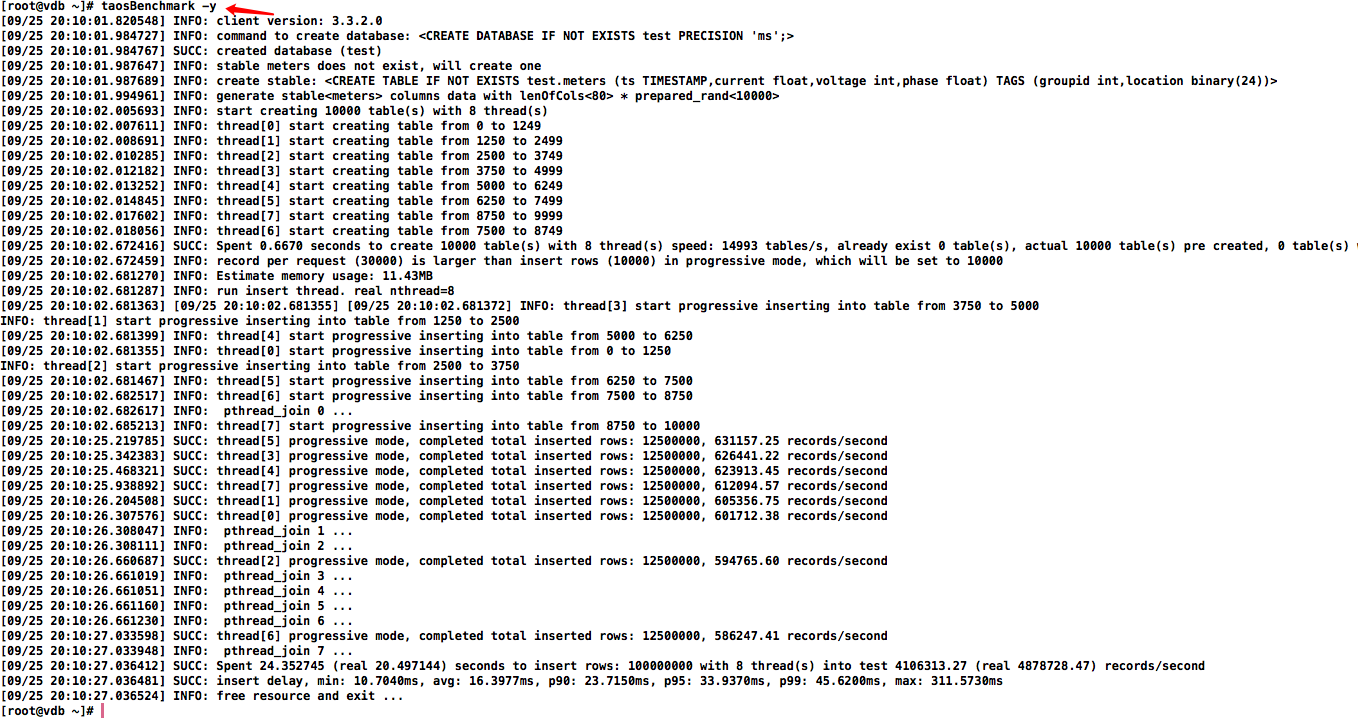
备注:非事务操作,中途中断(Cont+C)插入的数据不会回滚
系统将自动在数据库 test 下创建一张名为 meters的超级表。这张超级表将包含 10,000 张子表,表名从 d0 到 d9999,每张表包含 10,000条记录。每条记录包含 ts(时间戳)、current(电流)、voltage(电压)和 phase(相位)4个字段。时间戳范围从 “2017-07-14 10:40:00 000” 到 “2017-07-14 10:40:09 999”。每张表还带有 location 和 groupId 两个标签,其中,groupId 设置为 1 到 10,而 location 则设置为 California.Campbell、California.Cupertino 等城市信息。
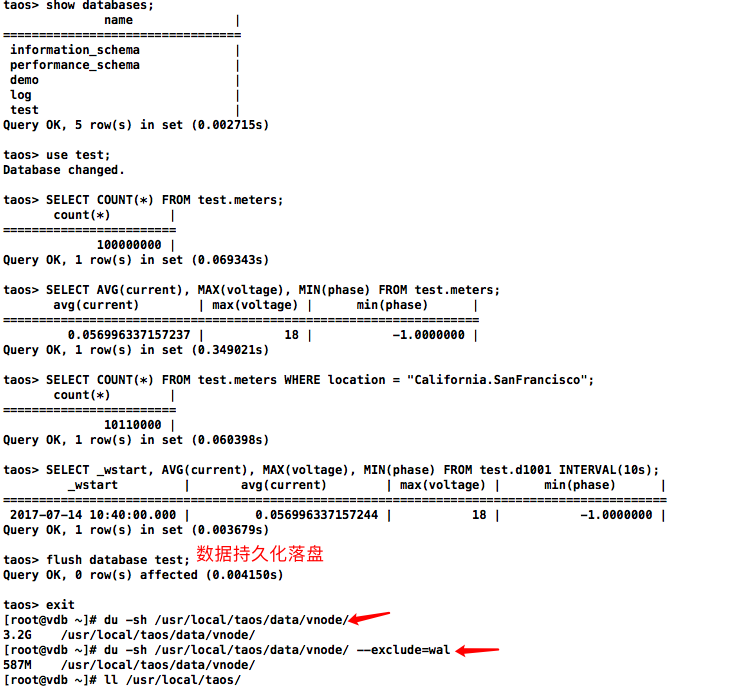
通过系统提供的伪列_wstart 来给出每个窗口的开始时间
备注:实际数据量占用不到590MB的磁盘空间
根据库vgroup_id查找对应数据目录下库对应的目录:
show vgroups;
show vnodes;
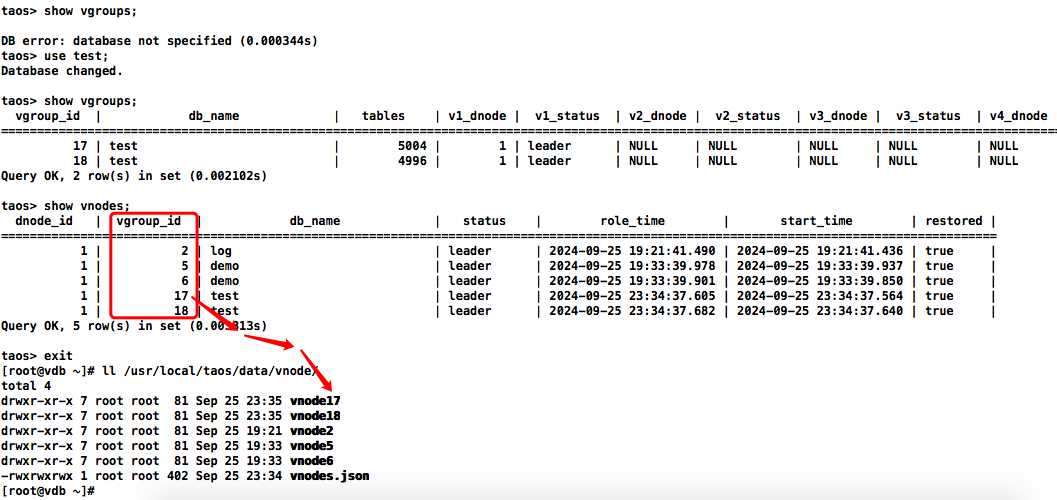
服务器内存需求
每个数据库能够创建固定数量的 vgroup,默认情况下为两个。在创建数据库时,可以通过 vgroups 参数指定 vgroup 的数量,而副本数则由 replica 参数确定。由于每个 vgroup 中的副本会对应一个 vnode,因此数据库所占用的内存计算方式:vgroups ×replica × (buffer + pages × pagesize + cachesize)
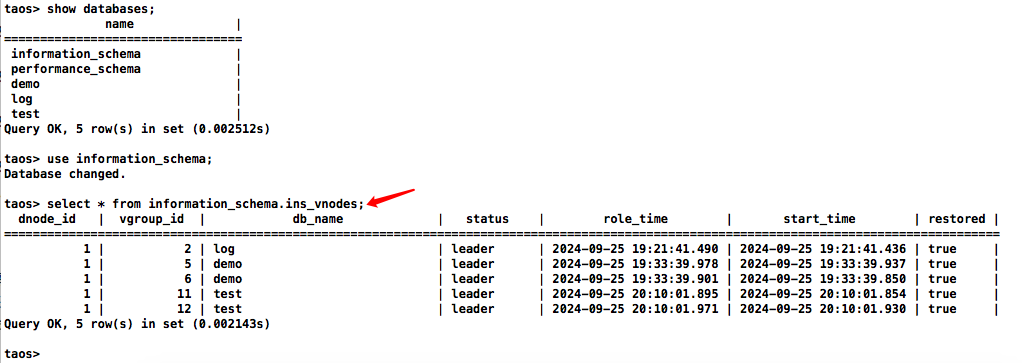
系统管理员可以通过如下 SQL 查看 information_schema 库中的 ins_vnodes 表来获得所有数据库所有 vnodes 在各个 dnode 上的分布。
taos> select * from information_schema.ins_vnodes;dnode_id | vgroup_id | db_name | status | role_time | start_time | restored |
==========================================================================================================================================1 | 2 | log | leader | 2024-09-25 19:21:41.490 | 2024-09-25 19:21:41.436 | true |1 | 5 | demo | leader | 2024-09-25 19:33:39.978 | 2024-09-25 19:33:39.937 | true |1 | 6 | demo | leader | 2024-09-25 19:33:39.901 | 2024-09-25 19:33:39.850 | true |1 | 11 | test | leader | 2024-09-25 20:10:01.895 | 2024-09-25 20:10:01.854 | true |1 | 12 | test | leader | 2024-09-25 20:10:01.971 | 2024-09-25 20:10:01.930 | true |
Query OK, 5 row(s) in set (0.002143s)
删库跑路测试
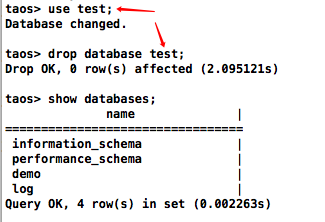
删库过程无需等待,即使有正在操作的会话也会被直接干掉
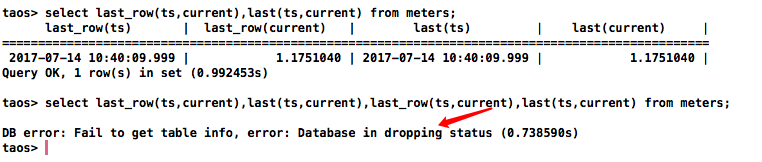
使用体验
- rpm安装体贴还是比较友好的,安装后会打印各个配置文件基本信息和操作命令
- 客户端命令taos,语法特性跟MySQL数据库有点像
- 可视化组件—taosExplorer注册需要连接互联网,对完全内网环境不是很友好,这块是否可以考虑分开单独特供一个网页注册平台,使用taosExplorer可视化管理工具就不要连网注册了
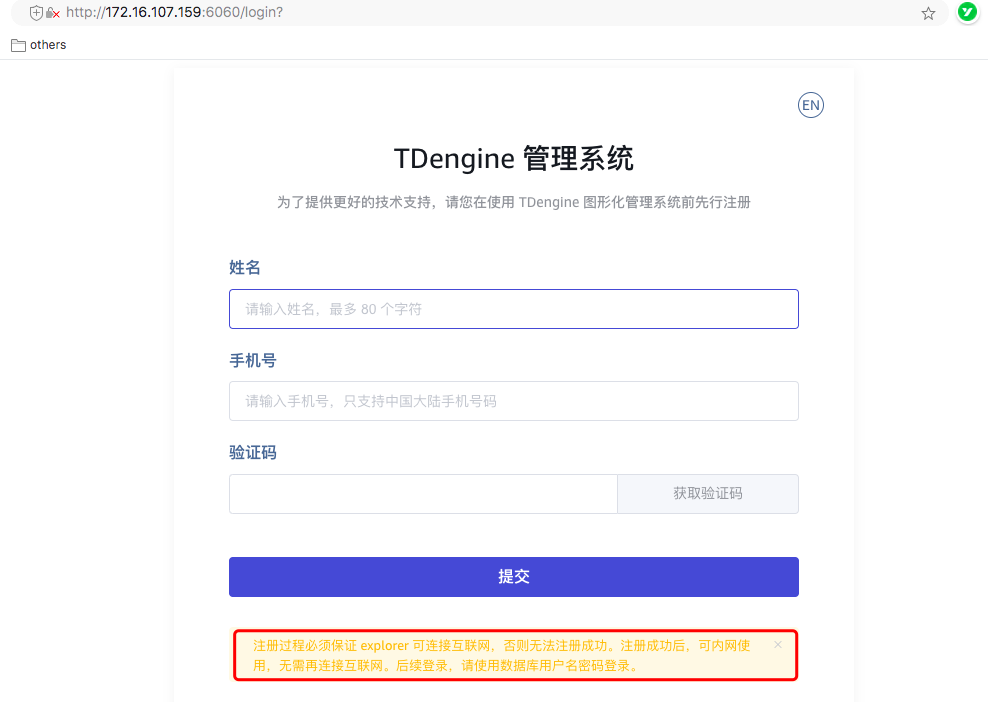
文档纠错
创建的d1003是普通表,且列未指定默认值,但后面插入数据时存在列缺少问题

d1003是普通表:
文档链接:https://docs.taosdata.com/basic/insert/
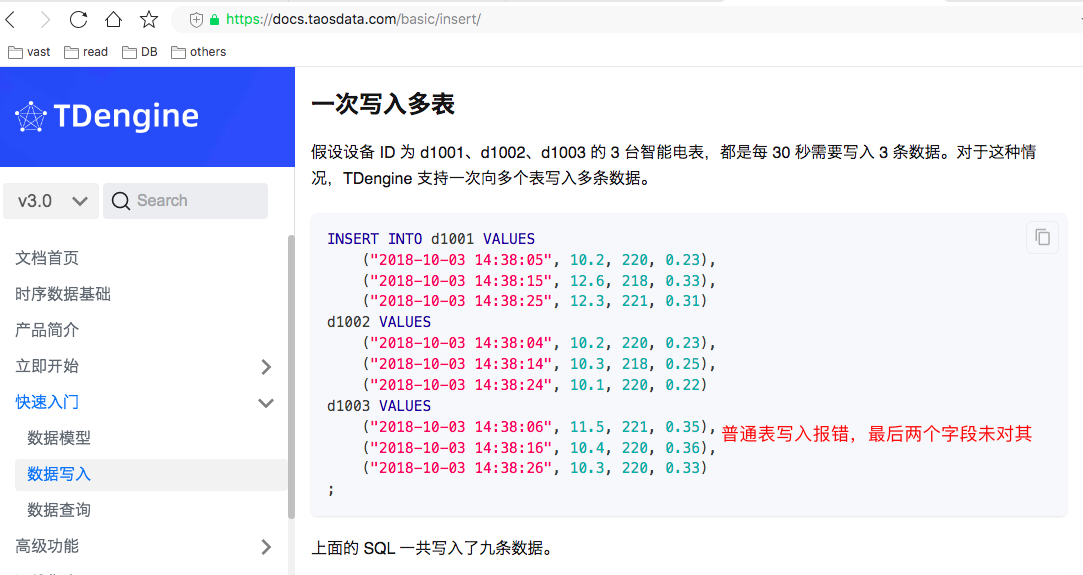
# 错误SQL
INSERT INTO d1001 VALUES ("2018-10-03 14:38:05", 10.2, 220, 0.23),("2018-10-03 14:38:15", 12.6, 218, 0.33),("2018-10-03 14:38:25", 12.3, 221, 0.31)
d1002 VALUES ("2018-10-03 14:38:04", 10.2, 220, 0.23),("2018-10-03 14:38:14", 10.3, 218, 0.25),("2018-10-03 14:38:24", 10.1, 220, 0.22)
d1003 VALUES("2018-10-03 14:38:06", 11.5, 221, 0.35),("2018-10-03 14:38:16", 10.4, 220, 0.36),("2018-10-03 14:38:26", 10.3, 220, 0.33)
;
# 更正写法一:补全d1003表插入所有列数据
INSERT INTO d1001 VALUES ("2018-10-03 14:38:05", 10.2, 220, 0.23),("2018-10-03 14:38:15", 12.6, 218, 0.33),("2018-10-03 14:38:25", 12.3, 221, 0.31)
d1002 VALUES ("2018-10-03 14:38:04", 10.2, 220, 0.23),("2018-10-03 14:38:14", 10.3, 218, 0.25),("2018-10-03 14:38:24", 10.1, 220, 0.22)
d1003 VALUES("2018-10-03 14:38:06", 11.5, 221, 0.35, "California.SanFrancisco", 2),("2018-10-03 14:38:16", 10.4, 220, 0.36, "California.SanFrancisco", 2),("2018-10-03 14:38:26", 10.3, 220, 0.33, "California.SanFrancisco", 2)
;
# 更正写法二:指定表d1003插入列
INSERT INTO d1001 VALUES ("2018-10-03 14:38:05", 10.2, 220, 0.23),("2018-10-03 14:38:15", 12.6, 218, 0.33),("2018-10-03 14:38:25", 12.3, 221, 0.31)
d1002 VALUES ("2018-10-03 14:38:04", 10.2, 220, 0.23),("2018-10-03 14:38:14", 10.3, 218, 0.25),("2018-10-03 14:38:24", 10.1, 220, 0.22)
d1003(ts, current, voltage, phase) VALUES("2018-10-03 14:38:06", 11.5, 221, 0.35),("2018-10-03 14:38:16", 10.4, 220, 0.36),("2018-10-03 14:38:26", 10.3, 220, 0.33)
;
相关文章:
时序数据库 TDengine 的入门体验和操作记录
时序数据库 TDengine 的学习和使用经验 什么是 TDengine ?什么是时序数据 ?使用RPM安装包部署默认的网络端口 TDengine 使用TDengine 命令行(CLI)taosBenchmark服务器内存需求删库跑路测试 使用体验文档纠错 什么是 TDengine &…...

Qt-QPushButton按钮类控件(22)
目录 描述 使用 给按钮添加图片 给按钮添加快捷键 添加槽函数 添加快捷键 添加组合键 开启鼠标的连发功能 描述 经过上面的一些介绍,我们也尝试的使用过了这个控件,接下来我们就要详细介绍这些比较重要的控件了 使用 给按钮添加图片 我们创建…...

镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态
当今企业数据管理日益规范化,数据应用系统随着数据类型与数量的增长不断细分,为了提升市场竞争力与技术实力,数据领域软件服务商与上下游伙伴的紧密对接与合作显得尤为重要。通过构建完善的生态系统,生态内企业间能够整合资源、共…...

蒸!--数据在内存中的存储
一.整数在内存中的存储 对于整形来说:数据存放内存中其实存放的是补码。 为什么? 在计算机系统中,数值⼀律⽤补码来表⽰和存储。 原因在于,使⽤补码,可以将符号位和数值域统⼀处理; 同时,加法和…...

利用AI增强现实开发:基于CoreML的深度学习图像场景识别实战教程
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...

每个企业都需要 (但未使用) 的 BYOD 安全解决方案
远程办公模式的转变彻底改变了组织管理员工设备的方式。如今,员工希望能够灵活地在任何地方使用任何设备工作,这导致自带设备 (BYOD) 政策被广泛采用。 但随着越来越多的企业采用BYOD,一个问题依然摆在眼前:如何在不侵犯个人隐私…...

【多系统萎缩患者必看】科学锻炼秘籍,让生命之树常青
亲爱的小红书朋友们,👋 今天我们要聊一个温暖而坚韧的话题——关于多系统萎缩(MSA)患者的锻炼指南。在这个充满挑战的旅程中,锻炼不仅是身体的锻炼,更是心灵的滋养,是对抗病魔的勇敢姿态&#x…...

【Android】Room—数据库的基本操作
引言 在Android开发中,数据持久化是一个不可或缺的部分。随着应用的复杂度增加,选择合适的数据存储方式变得尤为重要。Room数据库作为Android Jetpack架构组件之一,提供了一种抽象层,使得开发者能够以更简洁、更安全的方式操作SQ…...

「数组」堆排序 / 大根堆优化(C++)
目录 概述 核心概念:堆 堆结构 数组存堆 思路 算法过程 up() down() Code 优化方案 大根堆优化 Code(pro) 复杂度 总结 概述 在「数组」快速排序 / 随机值优化|小区间插入优化(C)中,我们介绍了三种基本排序中的冒泡…...

Edegex Foundry docker和源码安装
edgex文档下载 https://github.com/edgexfoundry/edgex-docs/branches/all 在线文档查看 首先要安装python3环境 然后后安装 打开超级终端 #pip3 install mkdocs #mkdocs serve 在浏览器中输入 http://127.0.0.1:8000/edgex-docs/2.3/ 即可打开在线文档 edgex入门可以参考…...

阿里P8和P9级别有何要求
阿里巴巴的P8和P9级别,代表着公司的资深技术专家或管理者岗位,要求候选人具有丰富的职业经历、深厚的技术能力以及出色的领导力。以下是对P8和P9级别的要求、考察点以及准备建议的详细分析。 P8 级别要求 1. 职业经历: 8年以上的工作经验&a…...
【目标检测数据集】锯子数据集1107张VOC+YOLO格式
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1107 标注数量(xml文件个数):1107 标注数量(txt文件个数):1107 标注…...
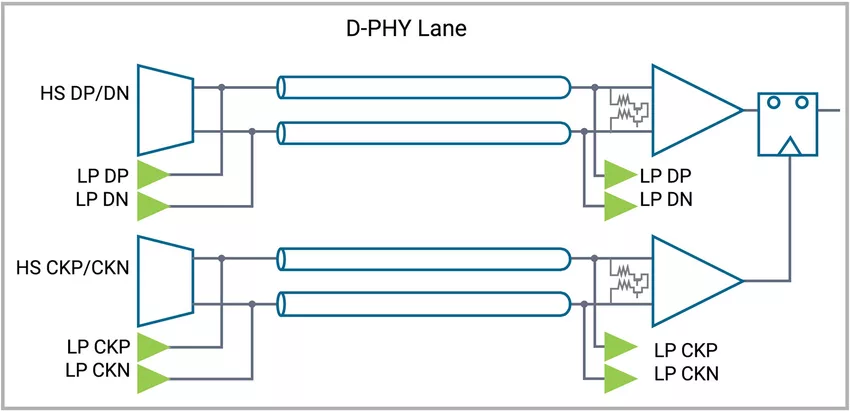
移动产业处理器接口(MIPI)协议是什么?
未来汽车的宏伟愿景备受瞩目,特别是驱动这些汽车的技术更是成为焦点。如今,传感器对于汽车视觉和安全技术的下一阶段至关重要,因为驾驶员和乘客都依赖于它们。这些传感器能够支持众多应用,这些应用往往基于人工智能(AI…...
OpenAI o1:隐含在训练与推理间的动态泛化与流形分布
随着OpenAI o1发布,进一步激发了产业与学术各界对AGI的期待以及new scaling law下的探索热情,也看到来自社区和专业机构对o1的阐释,但总感觉还差点什么,因此决定以自己的角度分篇幅梳理下,并分享给大伙: O…...

沉浸式体验和评测Meta最新超级大语言模型405B
2024年7月23日, 亚马逊云科技的AI模型托管平台Amazon Bedrock正式上线了Meta推出的超级参数量大语言模型 - Llama 3.1模型,小李哥也迫不及待去体验和试用了该模型,那这么多参数量的AI模型究竟强在哪里呢?Llama 3.1模型是Meta&…...

Python 课程10-单元测试
前言 在现代软件开发中,单元测试 已成为一种必不可少的实践。通过测试,我们可以确保每个功能模块在开发和修改过程中按预期工作,从而减少软件缺陷,提高代码质量。而测试驱动开发(TDD) 则进一步将测试作为开…...

【嵌入式硬件开发基础】Arduino板常用外设及应用:MPU6050空间运动传感器(简介,类库函数,卡尔曼滤波),继电器(原理介绍,含应用实例/代码)
当一个人不能拥有的时候,他唯一能做的便是不要忘记。 🎯作者主页: 追光者♂🔥 🌸个人简介: 📝[1] CSDN 博客专家📝 🏆[2] 人工智能领域优质创作者🏆 🌟[3] 2022年度博客之星人工智能领域TOP4🌟 🌿[4] 2023年城市之星领跑者TOP1(哈尔滨…...

Pandas Series对象创建,属性,索引及运算详解
目录 Series对象创建 实例化参数 index参数 选用array-like创建Series对象 list ndarray 显示索引与隐式索引 选用dict创建Series对象 不指定索引 指定索引 选用标量创建Series对象 使用标量创建的广播机制 Series属性 name size shape index values Series索…...
优化算法(一)—遗传算法(Genetic Algorithm)附MATLAB程序
遗传算法(Genetic Algorithm, GA)是一种启发式搜索算法,用于寻找复杂优化问题的近似解。它模拟了自然选择和遗传学中的进化过程,主要用于解决那些传统算法难以处理的问题。 遗传算法的基本步骤: 初始化种群࿰…...

高等数学 2.3 高阶导数
一般地,函数 y f ( x ) y f(x) yf(x) 的导数 y ′ f ′ ( x ) y\ f\ (x) y ′f ′(x) 仍然是 x x x 的函数。我们把 y ′ f ′ ( x ) y\ f\ (x) y ′f ′(x) 的导数叫做函数 y f ( x ) y f(x) yf(x) 的二阶导数,记作 y ′ ′ y\ y ′…...

双向链表的实现与优势
文章目录双向链表的实现与优势 ✨什么是双向链表? 🤔实现双向链表 💻双向链表的优势 🌟应用示例:浏览器历史记录 🌐总结 📚双向链表的实现与优势 ✨ 在计算机科学中,数据结构是组织…...

揭秘openGauss向量化执行引擎代价模型
揭秘openGauss向量化执行引擎代价模型openGauss的向量化执行引擎针对列存,生成执行计划后根据配置项是否开启直接决定是否将执行计划转换成向量化执行计划来执行。若向量化执行引擎在行存上执行就需要将数据转换成VectorBatch即列存的形式才可执行,这个转…...

智能开门柜自动售货机哪里生产
当你考虑引入一台智能开门柜自动售货机时,脑海中浮现的第一个问题往往是:“这东西,哪里生产的靠谱?”这背后,是对设备质量、技术稳定性和长期服务的深度关切。今天,我们就来深入剖析智能开门柜的生产格局&a…...

STM32外设驱动:内存映射与寄存器操作详解
1. STM32外设驱动基础:内存映射与寄存器操作在嵌入式开发领域,STM32系列单片机因其出色的性能和丰富的外设资源而广受欢迎。要真正掌握STM32的开发,理解其底层外设驱动机制至关重要。让我们从一个工程师的视角,深入剖析STM32外设驱…...

C#海康视觉VM4.1二次开发框架源码:多流程、运动控制卡、服务框架详解
C#基于海康视觉VM4.1的二次开发框架源码,有多流程框架 运动控制卡 服务框架 需要有海康VM的基础并且有海康威视VM开发狗GVM V2.7 代码功能说明引言本文旨在详细说明GVM V2.7版本软件的核心功能及其实现机制。GVM是一款基于海康威视VM4.1视觉平台进行二次开发的框架软…...

AI辅助开发新思路:让快马AI智能生成可配置的403 forbidden全局处理组件
今天在开发一个后台管理系统时,遇到了一个常见的权限控制问题:当用户访问没有权限的页面时,系统直接抛出了403错误。这种生硬的体验显然不够友好,于是我决定开发一个智能化的403 forbidden处理组件。经过在InsCode(快马)平台上的实…...
Matlab/simulink仿真,ip-iq检测,电压电流补偿)
统一电能质量变换器(UPQC)Matlab/simulink仿真,ip-iq检测,电压电流补偿
统一电能质量变换器(UPQC)Matlab/simulink仿真,ip-iq检测,电压电流补偿,软件版本matlab2016最近在实验室折腾统一电能质量变换器(UPQC)的仿真,发现Matlab2016的Simulink真是个好东西…...

Spring Boot 3.0升级实战:从2.x迁移到3.x的完整避坑指南
Spring Boot 3.0升级实战:从2.x迁移到3.x的完整避坑指南 Spring Boot 3.0的发布为Java开发者带来了诸多令人振奋的新特性,但同时也意味着从2.x版本升级并非简单的版本号变更。本文将深入剖析升级过程中的关键挑战,提供一套经过实战验证的迁移…...

5个步骤安全使用YimMenu:GTA5 DLL注入入门指南
5个步骤安全使用YimMenu:GTA5 DLL注入入门指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu …...

Math.js 使用教程
Math.js 是 JavaScript 生态里最强大、通用的数学计算库,核心解决原生 Math 功能弱、精度差、无表达式解析、不支持复数/矩阵/单位等痛点。一、核心定位与优势 兼容浏览器 & Node.js,无外部依赖支持:高精度数、复数、分数、单位、矩阵、符…...