大数据处理技术:分布式文件系统HDFS
目录
1 实验名称:
2 实验目的
3 实验内容
4 实验原理
5 实验过程或源代码
5.1 HDFS的基本操作
5.2 HDFS-JAVA接口之读取文件
5.3 HDFS-JAVA接口之上传文件
5.4 HDFS-JAVA接口之删除文件
6 实验结果
6.1 HDFS的基本操作
6.2 HDFS-JAVA接口之读取文件
6.3 HDFS-JAVA接口之上传文件
6.4 HDFS-JAVA接口之删除文件
1 实验名称:
分布式文件系统HDFS
2 实验目的
1.理解HDFS存在的优势,理解HDFS体系架构,学会在环境中部署HDFS学会HDFS基本命令。
2.理解HDFS的读写操作原理,掌握HDFS的一些常用命令,理解实际操作HDFS读写时的流程。
3 实验内容
(1)HDFS的基本操作
(2)HDFS-JAVA接口之读取文件
(3)HDFS-JAVA接口之上传文件
(4)HDFS-JAVA接口之删除文件
4 实验原理
HDFS(Hadoop Distributed File System)是一个分布式文件系统,是谷歌的GFS山寨版本。它具有高容错性并提供了高吞吐量的数据访问,非常适合大规模数据集上的应用,它提供了一个高度容错性和高吞吐量的海量数据存储解决方案。
HDFS文件系统的角色分为三种(Master和Slave的结构,主从节点结构),分为NameNode、Secondary NameNode和DataNode三种角色。
HDFS为分布式计算存储提供了底层支持,采用Java语言开发,可以部署在多种普通的廉价机器上,以集群处理数量积达到大型主机处理性能。HDFS 架构原理HDFS采用master/slave架构。一个HDFS集群包含一个单独的NameNode和多个DataNode。Namenode管理文件系统的元数据,而Datanode存储了实际的数据。
5 实验过程或源代码
5.1 HDFS的基本操作
1.启动Hadoop,在HDFS中创建/usr/output/文件夹:
start-dfs.sh
hadoop fs -mkdir /usr
hadoop fs -mkdir /usr/output2.在本地创建hello.txt文件并添加内容:“HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。”:vim hello.txt
3.将hello.txt上传至HDFS的/usr/output/目录下:hadoop fs -put hello.txt /usr/output
4.删除HDFS的/user/hadoop目录:hadoop fs -rm -r /user/hadoop
5.将Hadoop上的文件hello.txt从HDFS复制到本地/usr/local目录:hadoop fs -copyToLocal /usr/output/hello.txt /usr/local
5.2 HDFS-JAVA接口之读取文件
1.使用FSDataInputStream获取HDFS的/user/hadoop/目录下的task.txt的文件内容,并输出。代码实现如下:
URI uri = URI.create("hdfs://localhost:9000/user/hadoop/task.txt");Configuration config = new Configuration();FileSystem fs = FileSystem.get(uri,config);InputStream in = null;try{in = fs.open(new Path(uri));IOUtils.copyBytes(in, System.out,2048,false);}catch (Exception e){IOUtils.closeStream(in);}5.3 HDFS-JAVA接口之上传文件
1.在/develop/input/目录下创建hello.txt文件,并输入如下数据:迢迢牵牛星,皎皎河汉女。纤纤擢素手,札札弄机杼。终日不成章,泣涕零如雨。河汉清且浅,相去复几许?盈盈一水间,脉脉不得语。《迢迢牵牛星》。命令行:
mkdir /develop
mkdir /develop/input
cd /develop/input
vim hello.txt
start-dfs.sh2.使用FSDataOutputStream对象将文件上传至HDFS的/user/tmp/目录下,并打印进度。代码实现如下:
File localPath = new File("/develop/input/hello.txt");String hdfsPath = "hdfs://localhost:9000/user/tmp/hello.txt";InputStream in = new BufferedInputStream(new FileInputStream(localPath));Configuration config = new Configuration();FileSystem fs = FileSystem.get(URI.create(hdfsPath), config);long fileSize = localPath.length() > 65536 ? localPath.length() / 65536 : 1; FSDataOutputStream out = fs.create(new Path(hdfsPath), new Progressable() {long fileCount = 0;public void progress() {System.out.println("总进度" + (fileCount / fileSize) * 100 + "%");fileCount++;}});IOUtils.copyBytes(in, out, 2048, true);5.4 HDFS-JAVA接口之删除文件
1.启动hadoop:start-dfs.sh
2.实现如下功能:删除HDFS的/user/hadoop/目录(空目录);删除HDFS的/tmp/test/目录(非空目录);列出HDFS根目录下所有的文件和文件夹;列出HDFS下/tmp/的所有文件和文件夹。代码实现如下:
String root = "hdfs://localhost:9000/";String path = "hdfs://localhost:9000/tmp";String del1 = "hdfs://localhost:9000/user/hadoop";String del2 = "hdfs://localhost:9000/tmp/test";Configuration config = new Configuration();FileSystem fs = FileSystem.get(URI.create(root),config);fs.delete(new Path(del1),true);fs.delete(new Path(del2),true);Path[] paths = {new Path(root),new Path(path)};FileStatus[] status = fs.listStatus(paths);Path[] listPaths = FileUtil.stat2Paths(status);for (Path path1 : listPaths){
System.out.println(path1);
}6 实验结果
6.1 HDFS的基本操作
1.文件输出结果

6.2 HDFS-JAVA接口之读取文件
1.获取HDFS的/user/hadoop/目录下的task.txt的文件内容

6.3 HDFS-JAVA接口之上传文件
1.文件上传并打印进度

6.4 HDFS-JAVA接口之删除文件
1.删除文件输出结果

相关文章:
大数据处理技术:分布式文件系统HDFS
目录 1 实验名称: 2 实验目的 3 实验内容 4 实验原理 5 实验过程或源代码 5.1 HDFS的基本操作 5.2 HDFS-JAVA接口之读取文件 5.3 HDFS-JAVA接口之上传文件 5.4 HDFS-JAVA接口之删除文件 6 实验结果 6.1 HDFS的基本操作 6.2 HDFS-JAVA接口之读取文件 6.…...
组合数(模板)
1.杨辉三角求组合数,最高只能求几千内的组合数。 #include<bits/stdc.h> using namespace std; #define int long long int C[1005][1005]; signed main() {//求 1000 以内的组合数 for(int i0;i<1000;i){C[i][0]C[i][i]1;for(int j1;j<i;j){C[i][j]C[…...
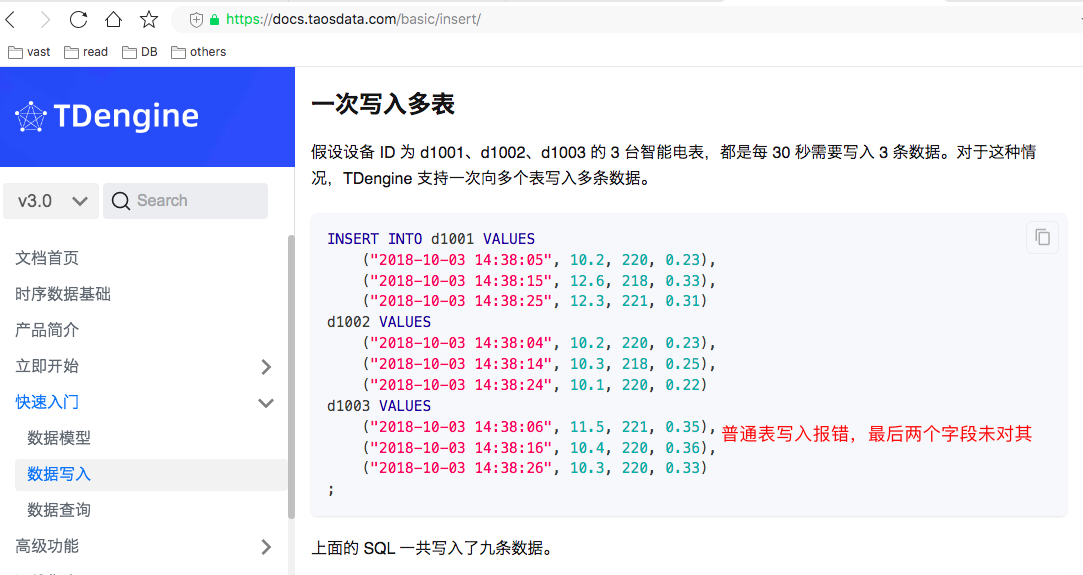
时序数据库 TDengine 的入门体验和操作记录
时序数据库 TDengine 的学习和使用经验 什么是 TDengine ?什么是时序数据 ?使用RPM安装包部署默认的网络端口 TDengine 使用TDengine 命令行(CLI)taosBenchmark服务器内存需求删库跑路测试 使用体验文档纠错 什么是 TDengine &…...

Qt-QPushButton按钮类控件(22)
目录 描述 使用 给按钮添加图片 给按钮添加快捷键 添加槽函数 添加快捷键 添加组合键 开启鼠标的连发功能 描述 经过上面的一些介绍,我们也尝试的使用过了这个控件,接下来我们就要详细介绍这些比较重要的控件了 使用 给按钮添加图片 我们创建…...

镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态
当今企业数据管理日益规范化,数据应用系统随着数据类型与数量的增长不断细分,为了提升市场竞争力与技术实力,数据领域软件服务商与上下游伙伴的紧密对接与合作显得尤为重要。通过构建完善的生态系统,生态内企业间能够整合资源、共…...

蒸!--数据在内存中的存储
一.整数在内存中的存储 对于整形来说:数据存放内存中其实存放的是补码。 为什么? 在计算机系统中,数值⼀律⽤补码来表⽰和存储。 原因在于,使⽤补码,可以将符号位和数值域统⼀处理; 同时,加法和…...

利用AI增强现实开发:基于CoreML的深度学习图像场景识别实战教程
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...

每个企业都需要 (但未使用) 的 BYOD 安全解决方案
远程办公模式的转变彻底改变了组织管理员工设备的方式。如今,员工希望能够灵活地在任何地方使用任何设备工作,这导致自带设备 (BYOD) 政策被广泛采用。 但随着越来越多的企业采用BYOD,一个问题依然摆在眼前:如何在不侵犯个人隐私…...

【多系统萎缩患者必看】科学锻炼秘籍,让生命之树常青
亲爱的小红书朋友们,👋 今天我们要聊一个温暖而坚韧的话题——关于多系统萎缩(MSA)患者的锻炼指南。在这个充满挑战的旅程中,锻炼不仅是身体的锻炼,更是心灵的滋养,是对抗病魔的勇敢姿态&#x…...

【Android】Room—数据库的基本操作
引言 在Android开发中,数据持久化是一个不可或缺的部分。随着应用的复杂度增加,选择合适的数据存储方式变得尤为重要。Room数据库作为Android Jetpack架构组件之一,提供了一种抽象层,使得开发者能够以更简洁、更安全的方式操作SQ…...

「数组」堆排序 / 大根堆优化(C++)
目录 概述 核心概念:堆 堆结构 数组存堆 思路 算法过程 up() down() Code 优化方案 大根堆优化 Code(pro) 复杂度 总结 概述 在「数组」快速排序 / 随机值优化|小区间插入优化(C)中,我们介绍了三种基本排序中的冒泡…...

Edegex Foundry docker和源码安装
edgex文档下载 https://github.com/edgexfoundry/edgex-docs/branches/all 在线文档查看 首先要安装python3环境 然后后安装 打开超级终端 #pip3 install mkdocs #mkdocs serve 在浏览器中输入 http://127.0.0.1:8000/edgex-docs/2.3/ 即可打开在线文档 edgex入门可以参考…...

阿里P8和P9级别有何要求
阿里巴巴的P8和P9级别,代表着公司的资深技术专家或管理者岗位,要求候选人具有丰富的职业经历、深厚的技术能力以及出色的领导力。以下是对P8和P9级别的要求、考察点以及准备建议的详细分析。 P8 级别要求 1. 职业经历: 8年以上的工作经验&a…...
【目标检测数据集】锯子数据集1107张VOC+YOLO格式
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1107 标注数量(xml文件个数):1107 标注数量(txt文件个数):1107 标注…...
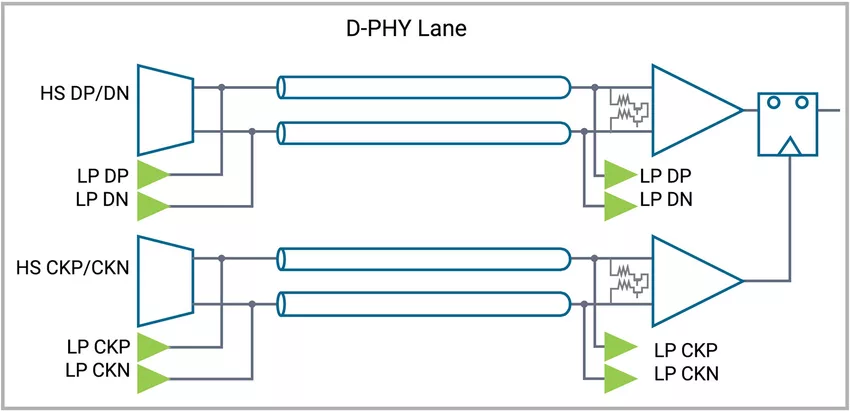
移动产业处理器接口(MIPI)协议是什么?
未来汽车的宏伟愿景备受瞩目,特别是驱动这些汽车的技术更是成为焦点。如今,传感器对于汽车视觉和安全技术的下一阶段至关重要,因为驾驶员和乘客都依赖于它们。这些传感器能够支持众多应用,这些应用往往基于人工智能(AI…...
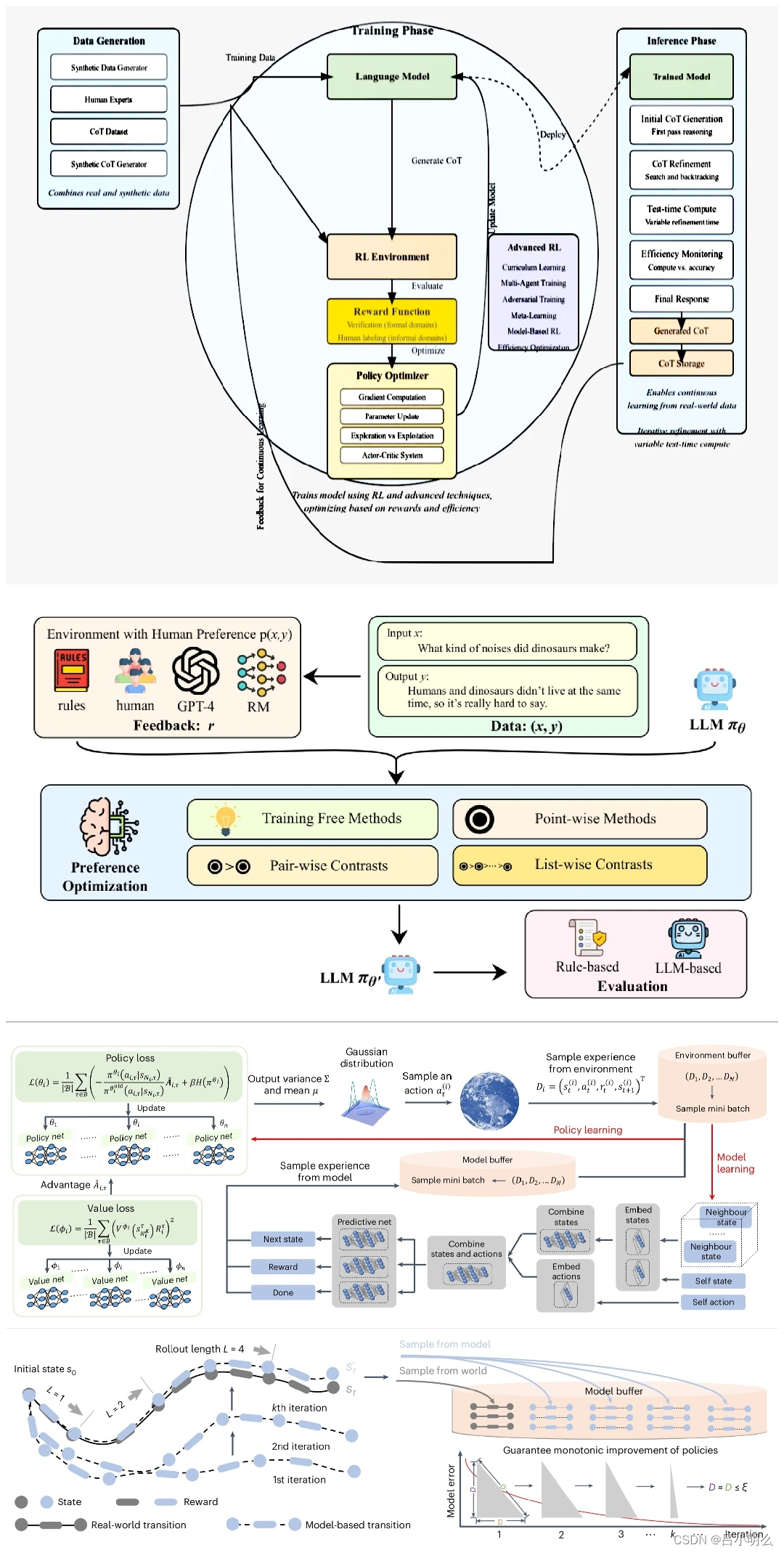
OpenAI o1:隐含在训练与推理间的动态泛化与流形分布
随着OpenAI o1发布,进一步激发了产业与学术各界对AGI的期待以及new scaling law下的探索热情,也看到来自社区和专业机构对o1的阐释,但总感觉还差点什么,因此决定以自己的角度分篇幅梳理下,并分享给大伙: O…...

沉浸式体验和评测Meta最新超级大语言模型405B
2024年7月23日, 亚马逊云科技的AI模型托管平台Amazon Bedrock正式上线了Meta推出的超级参数量大语言模型 - Llama 3.1模型,小李哥也迫不及待去体验和试用了该模型,那这么多参数量的AI模型究竟强在哪里呢?Llama 3.1模型是Meta&…...

Python 课程10-单元测试
前言 在现代软件开发中,单元测试 已成为一种必不可少的实践。通过测试,我们可以确保每个功能模块在开发和修改过程中按预期工作,从而减少软件缺陷,提高代码质量。而测试驱动开发(TDD) 则进一步将测试作为开…...

【嵌入式硬件开发基础】Arduino板常用外设及应用:MPU6050空间运动传感器(简介,类库函数,卡尔曼滤波),继电器(原理介绍,含应用实例/代码)
当一个人不能拥有的时候,他唯一能做的便是不要忘记。 🎯作者主页: 追光者♂🔥 🌸个人简介: 📝[1] CSDN 博客专家📝 🏆[2] 人工智能领域优质创作者🏆 🌟[3] 2022年度博客之星人工智能领域TOP4🌟 🌿[4] 2023年城市之星领跑者TOP1(哈尔滨…...

Pandas Series对象创建,属性,索引及运算详解
目录 Series对象创建 实例化参数 index参数 选用array-like创建Series对象 list ndarray 显示索引与隐式索引 选用dict创建Series对象 不指定索引 指定索引 选用标量创建Series对象 使用标量创建的广播机制 Series属性 name size shape index values Series索…...

OpenClaw自动化周报:Qwen3.5-9B-AWQ-4bit整合Git与日历数据
OpenClaw自动化周报:Qwen3.5-9B-AWQ-4bit整合Git与日历数据 1. 为什么需要自动化周报 每周五下午,我的日历总会准时弹出"写周报"的提醒。这个看似简单的任务却总让我头疼——需要翻遍Git提交记录、查日历会议纪要、整理零散的笔记࿰…...

从零到一:STM32 SPWM逆变器设计全流程解析
从零到一:STM32 SPWM逆变器设计全流程解析 在新能源和电力电子领域,逆变器作为直流转交流的关键设备,其设计能力已成为工程师的核心竞争力之一。而基于STM32的SPWM逆变器设计,因其高性价比和灵活可控的特点,正成为工业…...

OpenClaw 实战:让AI 页面“秒开即用”,实现 Vibecoding 真正闭环
我为什么会发出这个疑问呢?是因为我研究Web开发中的一个问题时,HTTP请求体在 Filter(过滤器)处被读取了之后,在 Controller(控制层)就读不到值了,使用 RequestBody 的时候。 无论是字…...

tmux和screen对比
tmux和screen都是优秀的终端复用器,核心功能相似:在单个终端窗口中创建多个持久化的虚拟终端会话,实现会话保持、窗口分割和多任务管理。 核心对比概括: tmux:设计更现代,功能更强大灵活,配置…...

OpenClaw学术写作助手:Kimi-VL-A3B-Thinking自动生成论文图表说明
OpenClaw学术写作助手:Kimi-VL-A3B-Thinking自动生成论文图表说明 1. 为什么需要自动化论文图表说明 写论文最痛苦的时刻之一,就是整理完数据图表后,还要绞尽脑汁写出专业又准确的说明文字。去年我完成硕士论文时,光是图表说明就…...

晶振负载电容与谐振电容的快速计算与选型指南
1. 晶振负载电容的基础概念 第一次接触晶振电路设计时,我也被"负载电容"这个概念绕晕了。简单来说,负载电容就是晶振要正常工作所需要的"外部助力"。想象一下荡秋千,负载电容就像是推秋千的力度——太小了荡不起来&#…...

nli-distilroberta-base保姆级部署教程:开源DistilRoBERTa NLI服务一键启动
nli-distilroberta-base保姆级部署教程:开源DistilRoBERTa NLI服务一键启动 1. 项目介绍 nli-distilroberta-base是一个基于DistilRoBERTa模型的自然语言推理(NLI)Web服务。它能帮你快速判断两个句子之间的关系,特别适合需要分析文本逻辑关系的场景。 …...
》--32.最长的斐波那契子序列的长度,33.最长等差数列,34.等差数列划分II-子序列)
《算法题讲解指南:动态规划算法--子序列问题(附总结)》--32.最长的斐波那契子序列的长度,33.最长等差数列,34.等差数列划分II-子序列
🔥小叶-duck:个人主页 ❄️个人专栏:《Data-Structure-Learning》《C入门到进阶&自我学习过程记录》 《算法题讲解指南》--优选算法 《算法题讲解指南》--递归、搜索与回溯算法 《算法题讲解指南》--动态规划算法 ✨未择之路࿰…...

Ubuntu 20.04下Python调用海康SDK,解决FastAPI与libssl.so.1.1冲突的完整避坑指南
Ubuntu 20.04下Python调用海康SDK与FastAPI的SSL冲突深度解析与工程实践 在物联网和安防系统开发领域,将海康威视设备接入Python后端服务已成为常见需求。但当开发者尝试在Ubuntu 20.04上使用FastAPI框架集成海康SDK时,往往会遭遇一个令人困惑的陷阱——…...

深入剖析watchdog机制:从soft lockup到Hard LOCKUP的检测与应对
1. 什么是watchdog机制? 想象一下你养了一只忠诚的狗狗,它的任务就是定时检查你是否还活着。如果你长时间不动,它就会叫醒你或者采取其他措施。Linux内核中的watchdog机制就是这样一个"看门狗",它的职责是监控系统是否正…...