Docker torchserve 部署模型流程
1.拉取官方镜像
地址: https://hub.docker.com/r/pytorch/torchserve/tags
docker pull pytorch/torchserve:0.7.1-gpu
2. docker启动指令
CPU
docker run --rm -it -d -p 8380:8080 -p 8381:8081 --name torch-server -v /path/model-server/extra-files:/home/model-server/extra-files -v /path/model-server/model-store:/home/model-server/model-store pytorch/torchserve:0.7.1-gpu
GPU
docker run --rm -it -d --gpus all -p 8380:8080 -p 8381:8081 --name torch-server -v /path/model-server/extra-files:/home/model-server/extra-files -v /path/model-server/model-store:/home/model-server/model-store pytorch/torchserve:0.7.1-gpu
/home/model-server/model-store 是docker映射地址,不能更改
进入容器,可以发现各个端口的意义,8080是通信访问接口,8081是管理服务配置接口,8082是服务监控接口

3. 打包模型文件
3.1 使用框架中脚本或者自己写脚本将模型转为torchscript(.pt)
3.2 torchscript转.mar文件
(1) run_hander.py
from xx_model_handler import KnowHandler_service = KnowHandler()def handle(data, context):try:if not _service.initialized:print('ENTERING INITIALIZATION')_service.initialize(context)if data is None:return Nonedata = _service.preprocess(data)data = _service.inference(data)data = _service.postprocess(data)return dataexcept Exception as e:raise Exception("Unable to process input data. " + str(e))
(2) xx_model_handler.py
"""
ModelHandler defines a custom model handler.
"""
import torch
import os
import json
import logging
from transformers import BertTokenizerclass KnowHandler(object):"""A custom model handler implementation."""def __init__(self):super(KnowHandler, self).__init__()self.initialized = Falsedef initialize(self, ctx):"""Initialize model. This will be called during model loading time:param context: Initial context contains model server system properties.:return:"""self.manifest = ctx.manifestproperties = ctx.system_propertiesmodel_dir = properties.get("model_dir")serialized_file = self.manifest["model"]["serializedFile"]model_pt_path = os.path.join(model_dir, serialized_file)self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")config_path = os.path.join(model_dir, "config.json")with open(config_path,"r") as fr:setup_config = json.load(fr)self.model = torch.jit.load(model_pt_path, map_location=self.device)self.tokenizer = BertTokenizer(setup_config["vocab_path"])self.max_length = setup_config["max_length"]self.initialized = True# load the model, refer 'custom handler class' above for detailsdef preprocess(self, data):"""Transform raw input into model input data.:param batch: list of raw requests, should match batch size:return: list of preprocessed model input data"""# Take the input data and make it inference readypreprocessed_data = data[0].get("data")if preprocessed_data is None:preprocessed_data = data[0].get("body")inputs = preprocessed_data.decode('utf-8')inputs = json.loads(inputs) # {"text": []}return inputsdef inference(self, model_input):"""Internal inference methods:param model_input: transformed model input data:return: list of inference output in NDArray"""# Do some inference call to engine here and return outputtext = model_input["text"]inputs = self.tokenizer(text,max_length=self.max_length,truncation=True,padding='max_length',return_tensors='pt')#inputs = {k: torch.as_tensor(v, dtype=torch.int64) for k, v in inputs.items()}for key, value in inputs.items():if isinstance(value, torch.Tensor):inputs[key] = value.to(self.device)input_ids = inputs['input_ids']token_type_ids = inputs['token_type_ids']attention_mask = inputs['attention_mask']logits = self.model(input_ids,attention_mask,token_type_ids)return logitsdef postprocess(self, inference_output):"""Return inference result.:param inference_output: list of inference output:return: list of predict results"""# Take output from network and post-process to desired formatpostprocess_output = [inference_output.tolist()]return postprocess_output(3) config.json
{"threshold": 0.8,"max_length": 40
}
torch-model-archiver --model-name {name of model} --version {模型版本} --serialized-file {torchscript文件地址} --export-path {.mar文件存放地址} --handler run_handler.py --extra-files {其它文件如配置文件等} --runtime python3 -f
torch-model-archiver --model-name my_model --version 1.0 --serialized-file /path/mymodel.pt --export-path /home/model-server/model-store --handler run_handler.py --extra-files "xx_model_handler,utils.py,config.json,vocab.txt" --runtime python -f
–model-name: 模型的名称,后来的接口名称和管理的模型名称都是这个
–serialized-file: 模型环境及代码及参数的打包文件
–export-path: 本次打包文件存放位置
–extra-files: handle.py中需要使用到的其他文件
–handler: 指定handler函数。(模型名:函数名)
-f 覆盖之前导出的同名打包文件
4. torchserver配置接口
(1)查询已注册的模型
curl "http://localhost:8381/models"
(2)注册模型并为模型分配资源
将.mar模型文件注册,注意:.mar文件必须放在model-store文件夹下,即/path/model-server/model-store
curl -X POST "{ip:port}/models?url={.mar文件名}&model_name={model_name}&batch_size=8&max_batch_delay=10&initial_workers=1"curl -X POST "localhost:8381/models?url=my_model.mar&model_name=my_model&batch_size=8&max_batch_delay=10&initial_workers=1"
(3)查看模型状态
curl http://localhost:8381/models/{model_name}
(4)删除注册模型
curl -X DELETE http://localhost:8381/models/{model_name}/{version}
5. 模型推理
response = requests.post('http://localhost:8380/predictions/{model_name}/{version}',data = data)
# -*- coding: utf-8 -*-
import requests
import json
text = ['xxxxx']
data = {'data':json.dumps({'text':text})}
print(data)
response = requests.post('http://localhost:8380/predictions/my_model',data = data)
print(response)
if response.status_code==200:vectors = response.json()print(vectors)
参考:
https://blog.51cto.com/u_16213661/8750698
https://blog.csdn.net/wangzitaotao/article/details/131101852
https://pytorch.org/serve/index.html
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/deploy-models-frameworks-torchserve.html
相关文章:
Docker torchserve 部署模型流程
1.拉取官方镜像 地址: https://hub.docker.com/r/pytorch/torchserve/tags docker pull pytorch/torchserve:0.7.1-gpu2. docker启动指令 CPU docker run --rm -it -d -p 8380:8080 -p 8381:8081 --name torch-server -v /path/model-server/extra-files:/home/model-serve…...

mybatis开启日志
步骤很详细,直接上教程 配置文件的文件格式可能有所不同,这里列举两种 配置方法 一. application.properties(默认 # 配置mybatis的日志信息 mybatis.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl二. application.y…...

MobaXterm : Network error: Connection refused(连接被拒绝)
具体报错如下如所示: 首先进行问题排查 ① 检查SSH服务是否运行 sudo service ssh status ② 检查SSH服务是否已启动(启用返回 enable) sudo systemctl is-enabled ssh ③ 查看所有的端口 sudo netstat -tulnp ④ 查看SSH使用的22号端口有…...

电脑的主板,内存条插多少合适?
首先,不是插满4条内存就是最好的。 内存条插得多,确实可以扩充容量,提升性能。但是有些低端的主板配低端CPU,插满4条内存,稳定性下降。这里的稳定性包括供电,单独的内存供电容量等。此时CPU会通过降低内存…...

C++:初始化列表
构造函数在上一篇帖子我们提到了对成员变量初始化的功能,出了在构造函数的函数体中队成员变量一个一个赋值以外,我们还可以采用初始化列表。 #include<iostream> using namespace std;class AA { private:int a;const int b; public:AA():b(200),…...

[000-01-008].第05节:OpenFeign特性-重试机制
我的后端学习大纲 SpringCloud学习大纲 1.1.重试机制的默认值: 1.重试机制默认是关闭的,给了默认值 1.2.测试重试机制的默认值: 1.3.开启Retryer功能: 1.修改配置文件YML的配置: 2.新增配置类: packa…...
及以上版本中,将Bitmap保存到设备上)
Android 11(API 级别 30)及以上版本中,将Bitmap保存到设备上
调用 saveBitmapToMediaStore(getContentResolver(),bitmap,“图片名”,mimeType); 参数解析: Bitmap myBitmap ...; // 这里应该是你获取或创建Bitmap的代码 private String mimeType "image/jpeg"; // 或者"image/png",取决于…...

django orm增删改查操作
1. 基本操作 1.1 创建对象 可以通过 Django ORM 来创建数据库中的记录。 示例: # 方法1:先创建对象,再保存 person Person(nameAlice, age30, emailaliceexample.com) person.save()# 方法2:直接创建 person Person.objects…...

禁忌搜索算法(TS算法)求解实例---旅行商问题 (TSP)
目录 一、采用TS求解 TSP二、 旅行商问题2.1 实际例子:求解 6 个城市的 TSP2.2 **求解该问题的代码**2.3 代码运行过程截屏2.4 代码运行结果截屏(后续和其他算法进行对比) 三、 如何修改代码?3.1 减少城市坐标,如下&am…...

Rust 所有权 简介
文章目录 发现宝藏1. 所有权基本概念2. 所有权规则3. 变量作用域4. 栈与堆4.1 栈(Stack)4.2 堆(Heap) 5. String类型5.1 String 类型5.2 String 的内存分配5.3 所有权与内存管理5.4 String 与切片 6. 变量与数据交互方式6.1 移动&…...

linux-网络管理-防火墙配置
Linux 网络管理:防火墙配置 1. 防火墙概述 防火墙是保护计算机系统和网络免受未经授权访问和网络攻击的安全机制。Linux 系统中,防火墙通过控制进入和离开网络的数据包,实现网络流量的过滤和管理。 Linux 上的防火墙配置工具有多种&#x…...

【springboot】实现文件上传和下载
目录 1. 新建一个springboot项目2. 配置文件application.propertiesapplication.yml 3. 控制类实现文件上传和下载4. 测试 1. 新建一个springboot项目 新建一个springboot项目,选择web,默认即可. 主要pom配置文件如下: <parent><gr…...

【RabbitMQ】RabbitMQ如何保证数据的可靠性,RabbitMQ如何保证数据不丢失,数据存储
【RabbitMQ】RabbitMQ如何保证数据的可靠性,RabbitMQ如何保证数据不丢失,数据存储 RabbitMQ通过一系列机制来确保数据(即消息)在传输和处理过程中不丢失。这些机制主要包括以下几个方面: 1. 消息持久化 持久化消息&a…...

Redis 篇-初步了解 Redis 持久化、Redis 主从集群、Redis 哨兵集群、Redis 分片集群
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 分布式缓存概述 2.0 Redis 持久化 2.1 RDB 持久化 2.1.1 RDB 的 fork 原理 2.2 AOF 持久化 2.3 RDB 与 AOF 之间的区别 3.0 Redis 主从集群 3.1 搭建主从集群 3.2…...

算法基础-二分查找
左闭右闭 [ left,right ] [1,1]可以 while( left < right ) if( a[mid] > target ) right mid - 1 else if( a[mid] < target ) left mid 1 左闭右开 [ left,right ) …...
)
LeetCode:1184. 公交站间的距离 一次遍历数组,复杂度O(n)
1184. 公交站间的距离 today 1184 公交站间的距离 题目描述 环形公交路线上有 n 个站,按次序从 0 到 n - 1 进行编号。我们已知每一对相邻公交站之间的距离,distance[i] 表示编号为 i 的车站和编号为 (i 1) % n 的车站之间的距离。 环线上的公交车都…...
)
牛客周赛 Round 60(A,B,C,D,E,F)
比赛链接 官方题解 这场基本都是数学题,官方题解讲的还不错,F能听懂的话其实不难。E是一个球盒模型的组合问题,F是化简递推式,成环时的解决方法很不错。 A 困难数学题 思路: 一个数异或两次结果为 0 0 0ÿ…...
以及记录使用方法)
vueCropper裁剪图片(不模糊)以及记录使用方法
需求:上传限定比例的图片。前端框架是vue3 element plus。 问题:使用vueCropper后比例固定。但是上传后的图片很模糊 vueCropper官网 解决办法 vueCropper中有一个full和high两个参数,记得开启 const options: any reactive({img: , // 原…...
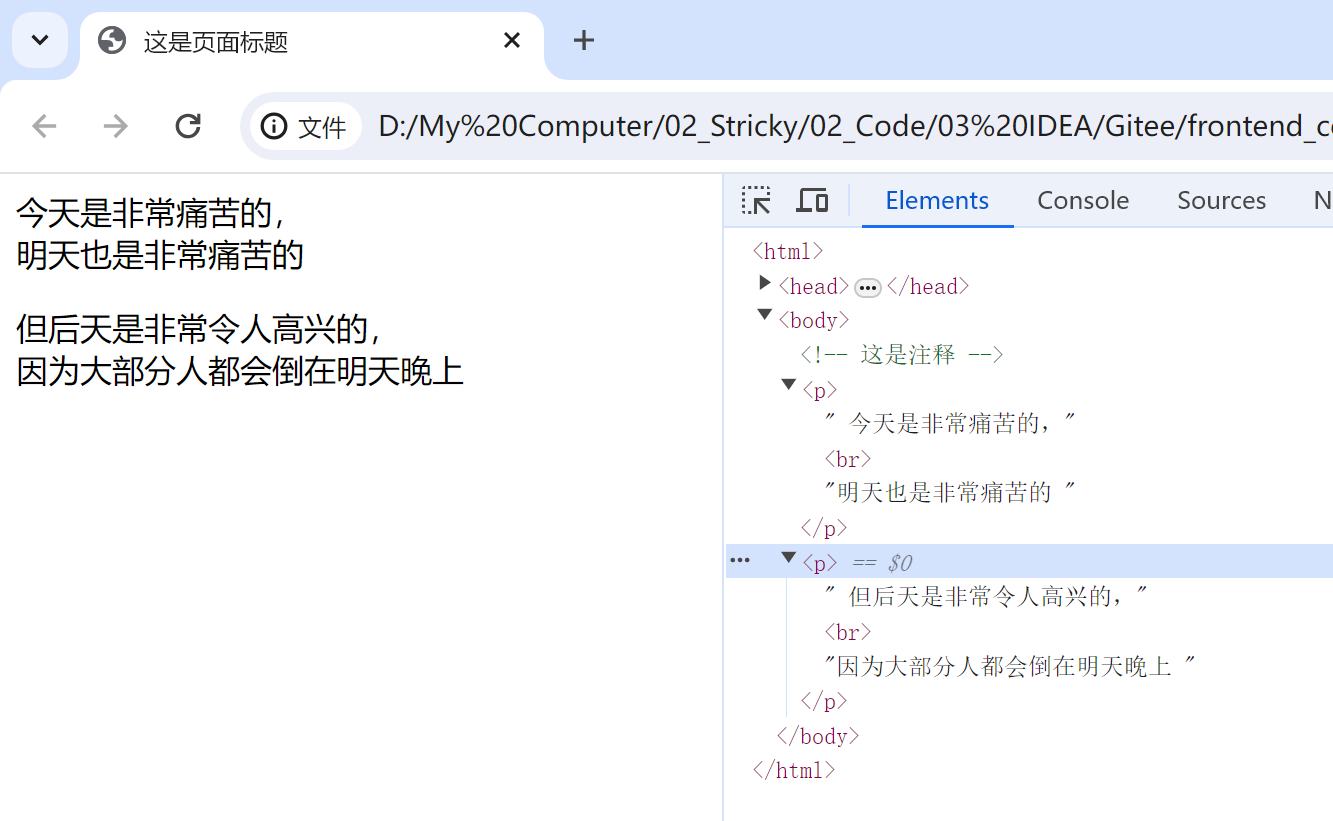
【HTML】HTML页面和常见标签
文章目录 什么是前端HTML 页面编写如何快速生成代码框架常见标签注释标签标题标签段落标签换行标签格式化标签 什么是前端 Web 前端,用来直接给以用户呈现的一个一个的网页。一个软件通常是由 后端前端 完成的 后端:通过 Java/C等语言,完成相…...

鸿蒙 ArkUI组件二
ArkUI组件(续) 文本组件 在HarmonyOS中,Text/Span组件是文本控件中的一个关键部分。Text控件可以用来显示文本内容,而Span只能作为Text组件的子组件显示文本内容。 Text/Span组件的用法非常简单和直观。我们可以通过Text组件来显…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

Windows文件夹共享
目标:同一局域网实现在一台计算机上共享文件夹,在另一台电脑访问一、电脑A 1.点击要共享的文件夹 -> 属性 -> 共享2.添加Everyone用户组3.控制面板中网络共享关闭密码保存,在访问时不用输入账号密码。二、电脑B 1.在文件资源管理器路径…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...
的原理、演进与未来)
车载诊断系统(OBD)的原理、演进与未来
本文约8,167字,建议收藏阅读 作者 | 北湾南巷 出品 | 汽车电子与软件 引 言 在现代汽车中,越来越多的故障不再表现为明显的机械损坏,而是以“亮灯”“报码”“性能异常”等电子信号的形式出现。发动机为什么亮起故障灯?排放是否达…...