神经网络-MNIST数据集训练
文章目录
- 一、MNIST数据集
- 1.数据集概述
- 2.数据集组成
- 3.文件结构
- 4.数据特点
- 二、代码实现
- 1.数据加载与预处理
- 2. 模型定义
- 3. 训练和测试函数
- 4.训练和测试结果
- 三、总结
一、MNIST数据集
MNIST数据集是深度学习和计算机视觉领域非常经典且基础的数据集,它包含了大量的手写数字图片,通常用于训练各种图像处理系统,也被广泛用于机器学习领域的训练和测试。
1.数据集概述
- 来源:MNIST数据集由Yann LeCun等人于1994年创建,它是NIST(美国国家标准与技术研究所)数据集的一个子集。
- 内容:数据集主要包含手写数字(0~9)的图片及其对应的标签。
- 用途:作为深度学习和计算机视觉领域的入门级数据集,它适合初学者练习建立模型、训练和预测。
2.数据集组成
MNIST数据集总共包含两个子数据集:训练数据集和测试数据集。
训练数据集:
- 包含了60,000张28x28像素的灰度图像。
- 对应的标签文件包含了60,000个标签,每个标签对应一张图像中的手写数字。
测试数据集:
- 包含了10,000张28x28像素的灰度图像。
- 对应的标签文件包含了10,000个标签。
3.文件结构
MNIST数据集包含四个文件,分别是训练集图像、训练集标签、测试集图像和测试集标签。这些文件以gzip格式压缩,并且不是标准的图像格式,需要通过专门的编程方式读取。
- 训练集图像:train-images-idx3-ubyte.gz
- 训练集标签:train-labels-idx1-ubyte.gz)
- 测试集图像:t10k-images-idx3-ubyte.gz
- 测试集标签:t10k-labels-idx1-ubyte.gz
4.数据特点
- 图像大小:每张图像的大小为28x28像素,是一个灰度图像,位深度为8(灰度值范围为0~255)。
- 数据来源:手写数字来自250个不同的人。
- 数据格式:图像数据以字节的形式存储在二进制文件中,标签文件则存储了每张图像对应的数字标签。
二、代码实现
1.数据加载与预处理
import torch
from torch import nn # 导入神经网络模块
from torch.utils.data import DataLoader # 数据包管理工具,打包数据
from torchvision import datasets # 封装了很多与图像相关的模型,数据集
from torchvision.transforms import ToTensor"""下载训练集数据(包含训练图片和标签)"""
training_data = datasets.MNIST(root="data",train=True,download=True,transform=ToTensor(), # 张量,图片是不能直接传入神经网络模型
)"""下载测试集数据(包括训练图片和标签)"""
test_data = datasets.MNIST(root="data",train=False,download=True,transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=64) # 64张图片为一个包
test_dataloader = DataLoader(test_data, batch_size=64)
- 下载数据集:使用torchvision.datasets.MNIST下载并加载MNIST数据集。数据集分为训练集和测试集,train=True为训练集数据,train=False为测试集数据。
- 数据转换:数据通过transform=ToTensor()进行预处理,将图片转换为PyTorch张量(Tensor),并自动将像素值归一化到[0,1]区间。
- 数据封装:使用DataLoader将数据集封装成批次(batch)形式,便于后续的训练和测试过程。
2. 模型定义
class NeuralNetwork(nn.Module): # 通过调用类的形式来使用神经网络,神经网络的模型,nn.moduledef __init__(self): # python基础关于类,self类自己本身super().__init__() # 继承的父类初始化self.flatten = nn.Flatten() # 展开,创建一个展开对象flattenself.hidden1 = nn.Linear(28 * 28, 128) # 第1个参数:有多少个神经元传入进来,第2个参数:有多少个数据传出去前一层神经元的个数,当前本层神经元个数self.hidden2 = nn.Linear(128, 256)self.hidden3 = nn.Linear(256, 128)self.out = nn.Linear(128, 10)def forward(self, x): # 前向传播,告诉它,数据的流向。x = self.flatten(x) # 图像进行展开x = self.hidden1(x)x = torch.sigmoid(x) x = self.hidden2(x)x = torch.sigmoid(x)x = self.hidden3(x)x = torch.sigmoid(x)x = self.out(x)return xmodel = NeuralNetwork().to(device) # 把刚刚创建的模型传入到gpu
print(model)定义类:定义了一个名为NeuralNetwork的类,该类继承自nn.Module,用于构建神经网络模型。
模型结构:模型包含输入层,输出层,隐藏层,其中隐藏层使用了Sigmoid激活函数,最后输出10个类别的得分(对应0-9的数字)
打印模型结构:打印了模型的结构,有助于理解模型的架构。

3. 训练和测试函数
def train(dataloader, model, loss_fn, optimizer):model.train()batch_size_num = 1for X, y in dataloader: # 其中batch为每一个数据的编号X, y = X.to(device), y.to(device) # 把训练数据集和标签传入cpu或GPUpred = model.forward(X) # .forward可以被省略,父类中已经对次功能进行了设置。自动初始化w权值loss = loss_fn(pred, y) # 通过交叉熵损失函数计算损失值loss# Backpropaqation 进来-个bqtch的数据,计算一次梯度,更新一次网络optimizer.zero_grad() # 梯度值清零loss.backward() # 反向传播计算得到每个参数的梯度值woptimizer.step() # 根据梯度更新网络w参数loss_value = loss.item() # 从tensor数据中提取数据出来,tensor获取损失值if batch_size_num % 100 == 0:print(f"loss:{loss_value:>7f} [number:{batch_size_num}]")batch_size_num += 1def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval() # 测试,w就不能再更新。test_loss, correct = 0, 0with torch.no_grad(): # 一个上下文管理器,关闭梯度计算。for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model.forward(X)test_loss += loss_fn(pred, y).item() # test loss是会自动累加每一个批次的损失值correct += (pred.argmax(1) == y).type(torch.float).sum().item()a = (pred.argmax(1) == y) # dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号b = (pred.argmax(1) == y).type(torch.float) # 把预测值Ture、False 转换为01test_loss /= num_batches # 评判模型的好坏correct /= size # 平均的准确率print(f"Test result:\n Accuracy:{(100 * correct)}%,Avg loss:{test_loss}")
- train函数负责训练模型。它遍历训练数据集的每个批次,计算模型的预测、损失,并执行反向传播和参数更新。
- test函数用于评估模型在测试集上的性能。它遍历测试数据集的每个批次,计算模型的预测和损失,但不进行反向传播或参数更新。
- 在训练和测试过程中,都使用了torch.no_grad()上下文管理器来关闭梯度计算,这可以节省内存和计算资源。
4.训练和测试结果
loss_fn = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 创建一个优化器,S6D为随机梯度下降算法epochs = 10
for t in range(epochs):print(f"Epoch {t + 1}\n-------------------------")train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
test(test_dataloader, model, loss_fn)- 使用torch.optim.Adam优化器来优化模型的参数,这里的学习率设置为0.01。
- 定义了训练轮次(epochs),并在每个epoch中调用train函数来训练模型。
- 最后,使用test函数来评估模型在测试集上的性能,并打印出准确率和平均损失。

三、总结
本文为大家介绍了MNIST数据集的组成、文件结构与数据集特点,然后为大家提供了MNIST数据集训练的相关代码,通过对数据集进行处理,训练来得出准确率与损失率,为大家更好的展示。总之,MNIST数据集是深度学习和计算机视觉领域不可或缺的基础数据集之一,对于初学者来说是一个非常好的练手项目,同时也为相关领域的研究和实验提供了宝贵的数据资源。
相关文章:
神经网络-MNIST数据集训练
文章目录 一、MNIST数据集1.数据集概述2.数据集组成3.文件结构4.数据特点 二、代码实现1.数据加载与预处理2. 模型定义3. 训练和测试函数4.训练和测试结果 三、总结 一、MNIST数据集 MNIST数据集是深度学习和计算机视觉领域非常经典且基础的数据集,它包含了大量的手…...

数据结构二
求 sizeof(name1)?(晟安信息) struct name1{ char str; short x; int num; }; sizeof name1内存对齐 8个字节 char分配8个字节 然后 short节省空间在4个字节中 而这个int独自分配分配内存 4个字节所以共8个字节 (电工时代) typedef struct _a { char c1; long i…...
)
Python|基于Kimi大模型,删除已上传的“指定文档”或“全部文档”(6)
前言 本文是该专栏的第6篇,后面会持续分享AI大模型干货知识,记得关注。 在本专栏上一篇《Python|基于Kimi大模型,实现上传文档并进行对话(5)》中,笔者有详细介绍“基于kimi大模型,上传指定文档并结合prompt,获取目标文本数据”。对此感兴趣的同学,可以直接点击翻阅查…...

CenterPoint-KITTI:环境配置、模型训练、效果展示;KITTI 3D 目标检测数据集下载
目录 前言 Python虚拟环境创建以及使用 KITTI3D目标检测数据集 CenterPoint-KITTI编译遇到问题合集 ImportError: cannot import name VoxelGenerator from spconv.utils 失败案例 最终解决方案 对于可选参数,road plane的处理 E: Unable to locate packag…...

【Android】ViewPager
1.ViewPager的简介和作用 ViewPager是android扩展包v4包中的类,这个类可以让用户左右切换当前的view,用于允许用户在几个页面(或称为碎片)之间左右滑动切换。它通常用于创建像画廊或轮播图那样的用户体验。 ViewPager类直接继承了…...

[go] 命令模式
命令模式 将“请求”封装成对象,以便使用不同的请求、队列或者日志来参数化其他对象。命令模式也支持可撤销的操作。 模型说明 触发者类负责对请求进行初始化,其中必须包含一个成员变量来存储对于命令对象的引用。触发命令,而不同接受者直接…...

代码随想录冲冲冲 Day48 单调栈Part2
42. 接雨水 关键点有以下几个 首先是怎么去理解接雨水 其实就是找每一个段的左边第一个最大值和右边第一个最大值 既然是最大值 那么单调栈就是递增的 左边第一个最大值其实就是pop掉中间的之后st.top 由于是出现大于等于情况时候进行操作 所以右边最大值就是i 接下来就…...

企业内训|Nvidia智算中心深度技术研修-某智算厂商研发中心
课程概述 此企业内训课程“Nvidia智算中心的深度技术研修”专为某智算厂商研发中心设计,内容涵盖了从基础设施构建到高性能计算优化的全方位技术要点。课程为期七天,分模块详细讲解了NV算力资源的网络架构、存储优化、智算集群的建设与自动化管理、NCCL…...
2021-03-03)
《算法笔记》例题解析 第3章入门模拟--3图形输出(9题)2021-03-03
例题 旋转方阵 题目描述 Time Limit: 1000 ms Memory Limit: 256 mb 打印出一个旋转方阵,见样例输出。 输入描述: 输入一个整数n(1 < n < 20), n为方阵的行数。 输出描述: 输出一个大小为n*n的距阵 输入 5 输出 1 16 15 14 13 2 17 24 23 12 3 18 25 22 11 4 1…...
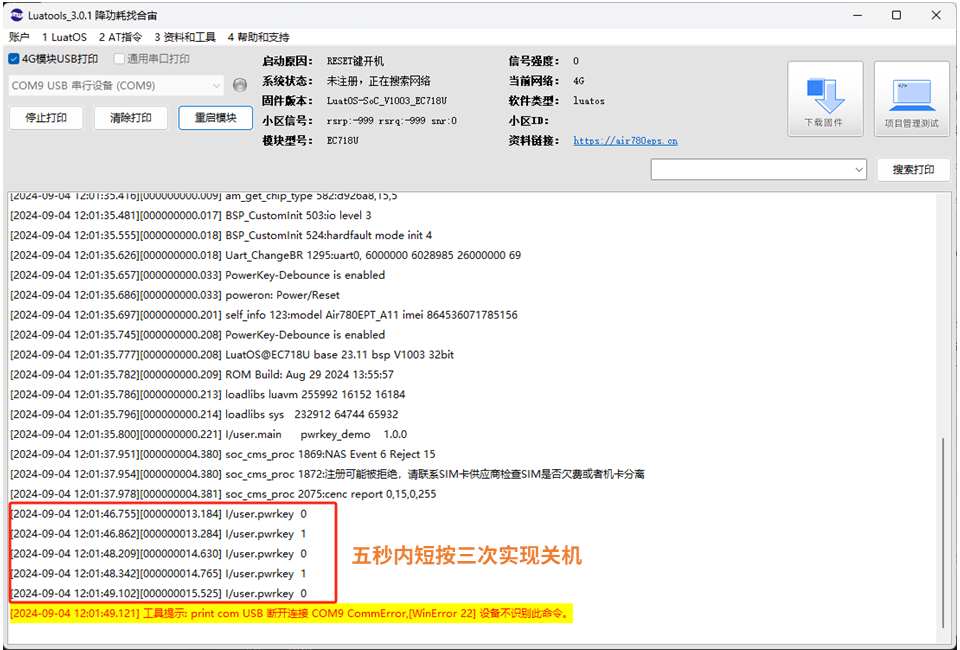
合宙Air201模组LuatOS:PWRKEY控制,一键解决解决关机难问题
不知不觉间,我们已经发布拉期课程:hello world初体验,点灯、远程控制、定位和扩展功能,你学的怎么样?很多伙伴表示已经有点上瘾啦!合宙Air201,如同我们一路升级打怪的得力法器,让开发…...

Kafka 命令详解及使用示例
文章目录 Kafka 命令详解及使用示例Kafka 命令详解kafka-topics.sh:主题管理创建主题创建带副本的主题修改主题分区数了解分区分布列出主题查看主题详情删除主题 kafka-console-producer.sh:消息生产者发送消息到主题带键值对的消息消息生产性能优化带分…...

重生归来之挖掘stm32底层知识(1)——寄存器
概念理解 要使用stm32首先要知道什么是引脚和寄存器。 如下图所示,芯片通过这些金属丝与电路板连接,这些金属丝叫做引脚。一般做软件开发是不需要了解芯片是怎么焊的,只要会使用就行。我们平常通过编程来控制这些引脚的输入和输出,…...

Qt构建JSON及解析JSON
目录 一.JSON简介 JSON对象 JSON数组 二.Qt中JSON介绍 QJsonvalue Qt中JSON对象 Qt中JSON数组 QJsonDocument 三.Qt构建JSON数组 四.解析JSON数组 一.JSON简介 一般来讲C类和对象在java中是无法直接直接使用的,因为压根就不是一个规则。但是他们在内存中…...

合宙Air201模组LuatOS扩展功能:温湿度传感器篇!
通过前面几期的学习,同学们的学习热情越来越高。 合宙Air201模组除了支持3种定位方式外,还具有丰富的扩展功能,比如:通过外扩BTB链接方案,最多可支持21个IO接口:SPI、I2C、UART等多种接口全部支持。 本期…...

主流敏捷工具scrum工具
在当今的快速变化和高需求的业务环境中,敏捷开发已经成为许多企业实现快速迭代和响应市场需求的重要方法。而在众多敏捷工具中,选择适合自己团队的工具尤为重要。 今天,我们将对比几款主流的敏捷工具,供参考 1. Leangoo领歌&…...

探索微服务架构:从理论到实践,深度剖析其优缺点
微服务架构(Microservice Architecture)是一种软件开发架构形式,它的核心 思想是将大型应用程序拆分成一组小的服务,每个服务都运行在其独立的进程中,并且 服务与服务之间通过轻量级的通信机制(如HTTP REST…...
2024 年最佳 Chrome 验证码扩展,解决 reCAPTCHA 问题
验证码,特别是 reCAPTCHA,已成为在线安全的不可或缺的一部分。虽然它们在区分人类和机器人方面起着至关重要的作用,但它们也可能成为合法用户和从事网络自动化的企业的主要障碍。无论您是试图简化在线体验的个人,还是依赖自动化工…...

Go语言现代web开发defer 延迟执行
The defer statement will delay the execution of a function until the surrounding function is completed. Although execution is postponed, funciton arguments will be evaluated immediately. defer语句将延迟函数的执行,直到周围的函数完成。虽然执行被延…...

Vue路由二(嵌套多级路由、路由query传参、路由命名、路由params传参、props配置、<router-link>的replace属性)
目录 1. 嵌套(多级)路由2. 路由query传参3. 路由命名4. 路由params传参5. props配置6. <router-link>的replace属性 1. 嵌套(多级)路由 pages/Car.vue <template><ul><li>car1</li><li>car2</li><li>car3</li></ul…...

【RabbitMQ】可靠性传输
概述 作为消息中间件来说,最重要的任务就是收发消息。因此我们在收发消息的过程中,就要考虑消息是否会丢失的问题。结果是必然的,假设我们没有采取任何措施,那么消息一定会丢失。对于一些不那么重要的业务来说,消息丢失…...

AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度
AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度 【免费下载链接】alphafold3 AlphaFold 3 inference pipeline. 项目地址: https://gitcode.com/gh_mirrors/alp/alphafold3 你是否在蛋白质结构预测项目中遇到MSA生成效率低下的瓶颈&#x…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...

03 - 变量与数据类型
03 - 变量与数据类型 变量是编程里最基础的概念,相当于你往电脑里存东西的"容器"。这章我们把变量的命名规则、Python 的几种基本数据类型都过一遍。 变量是什么 说白了,变量就是一个有名字的盒子。你往里面放个东西,以后想用这个…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...