数学建模——熵权+TOPSIS+肘部法则+系统聚类
文章目录
- 一、起因
- 二、代码展示
一、起因
我本科的数学建模队长找上我,让我帮她写下matlab代码,当然用的模型还是曾经打比赛的模型,所以虽然代码量多,但是写的很快,也是正逢中秋,有点时间。
当然我也没想到,研一刚开学这论文就这么水灵灵的要发出来了,队长的实力还是遥遥领先啊,在这里,祝她们的论文一次见刊!
二、代码展示
差不多有460行代码这样
%% 获取数据
[num,txt,raw] = xlsread('C:\Users\19468\Desktop\zhibiao1.xlsx',1);%% 标准化MIN = min(num); %各指标的最大值
MAX = max(num); %各指标的最小值
NUM_B = []; %保存标准化后的数据
for i = 1:size(num,1) % 运行31个省份for j = 1:size(num,2) % 1个省份的23个数据NUM_B(i,j) = (num(i,j)-MIN(j))/(MAX(j) - MIN(j));end
end%% 对个别指标正向化
% 对指标在第5,10,11,13,14、22列进行正向化
Z = [5,10,11,13,14,22]; % 保存正向化列数
NUM_B_Z = NUM_B; % 存放标准化正向化后的数据
for i = 1:size(num,1) % 运行31个省份for j=1:size(Z,2) % 5列数据NUM_B_Z(i,Z(j)) = 1 - NUM_B(i,Z(j));end
end%% 对二级指标进行熵权+TOPSIS,保留各省份各一级指标的数据
TOP_one = [1,2,3,4,5]; % 第一个一级指标
TOP_two = [6,7,8]; % 第二个一级指标
TOP_three = [9,10,11,12,13]; % 第三个一级指标
TOP_four = [14,15]; % 第四个一级指标
TOP_five = [16,17,18,19]; % 第五个一级指标
TOP_six = [20,21,22,23]; % 第六个一级指标TOP_one_data = NUM_B_Z(:,1:5); % 第一个一级指标的数据
TOP_two_data = NUM_B_Z(:,6:8); % 第二个一级指标的数据
TOP_three_data = NUM_B_Z(:,9:13); % 第三个一级指标的数据
TOP_four_data = NUM_B_Z(:,14:15); % 第四个一级指标的数据
TOP_five_data = NUM_B_Z(:,16:19); % 第五个一级指标的数据
TOP_six_data = NUM_B_Z(:,20:23); % 第六个一级指标的数据% NUM_B_Z_W(:,:,1) = TOP_one_data;
% NUM_B_Z_W(:,:,2) = TOP_two_data;
% NUM_B_Z_W(:,:,3) = TOP_three_data;
% NUM_B_Z_W(:,:,4) = TOP_four_data;
% NUM_B_Z_W(:,:,5) = TOP_five_data;% 熵权法+TOPSIS
% 指标一
Z = TOP_one_data;
[n,m] = size(Z);
D = zeros(1,m); % 初始化保存信息效用值的行向量
for i = 1:mx = Z(:,i); % 取出第i列的指标p = x / sum(x);% 注意,p有可能为0,此时计算ln(p)*p时,Matlab会返回NaN,所以要判断n = length(p); % 向量的长度lnp = zeros(n,1); % 初始化最后的结果for j = 1:n % 开始循环if p(j) == 0 % 如果第i个元素为0lnp(j) = 0; % 那么返回的第i个结果也为0elselnp(j) = log(p(j));endend%到这里结束e = -sum(p .* lnp) / log(n); % 计算信息熵D(i) = 1- e; % 计算信息效用值
end
W = D ./ sum(D); % 将信息效用值归一化,得到权重
WD_min = min(TOP_one_data);
D_max = max(TOP_one_data);zonghedefen_one = 1:31; %生成记录点
for i = 1:31%利用(C = D-/((D-)+(D+)))topsis模型与熵权进行结合D_jia = sqrt(W(1)*(TOP_one_data(i,1)-D_max(1))^2 + W(2)*(TOP_one_data(i,2)-D_max(2))^2 + ...W(3)*(TOP_one_data(i,3)-D_max(3))^2 + W(4)*(TOP_one_data(i,4)-D_max(4))^2 + ...W(5)*(TOP_one_data(i,5)-D_max(5))^2);D_jian = sqrt(W(1)*(TOP_one_data(i,1)-D_min(1))^2 + W(2)*(TOP_one_data(i,2)-D_min(2))^2 + ...W(3)*(TOP_one_data(i,3)-D_min(1))^2 + W(4)*(TOP_one_data(i,4)-D_min(2))^2 + ...W(5)*(TOP_one_data(i,5)-D_min(1))^2);zonghedefen_one(i) = D_jian/(D_jia+D_jian); % 一次就是产生31个数据
endzonghedefen_one = zonghedefen_one'; % 指标二
Z = TOP_two_data;
[n,m] = size(Z);
D = zeros(1,m); % 初始化保存信息效用值的行向量
for i = 1:mx = Z(:,i); % 取出第i列的指标p = x / sum(x);% 注意,p有可能为0,此时计算ln(p)*p时,Matlab会返回NaN,所以要判断n = length(p); % 向量的长度lnp = zeros(n,1); % 初始化最后的结果for j = 1:n % 开始循环if p(j) == 0 % 如果第i个元素为0lnp(j) = 0; % 那么返回的第i个结果也为0elselnp(j) = log(p(j));endend%到这里结束e = -sum(p .* lnp) / log(n); % 计算信息熵D(i) = 1- e; % 计算信息效用值
end
W = D ./ sum(D); % 将信息效用值归一化,得到权重
WD_min = min(TOP_two_data);
D_max = max(TOP_two_data);zonghedefen_two = 1:31; %生成记录点
for i = 1:31%利用(C = D-/((D-)+(D+)))topsis模型与熵权进行结合D_jia = sqrt(W(1)*(TOP_two_data(i,1)-D_max(1))^2 + W(2)*(TOP_two_data(i,2)-D_max(2))^2 + ...W(3)*(TOP_two_data(i,3)-D_max(3))^2);D_jian = sqrt(W(1)*(TOP_two_data(i,1)-D_min(1))^2 + W(2)*(TOP_two_data(i,2)-D_min(2))^2 + ...W(3)*(TOP_two_data(i,3)-D_min(1))^2);zonghedefen_two(i) = D_jian/(D_jia+D_jian); % 一次就是产生31个数据
endzonghedefen_two = zonghedefen_two'; % 指标三
Z = TOP_three_data;
[n,m] = size(Z);
D = zeros(1,m); % 初始化保存信息效用值的行向量
for i = 1:mx = Z(:,i); % 取出第i列的指标p = x / sum(x);% 注意,p有可能为0,此时计算ln(p)*p时,Matlab会返回NaN,所以要判断n = length(p); % 向量的长度lnp = zeros(n,1); % 初始化最后的结果for j = 1:n % 开始循环if p(j) == 0 % 如果第i个元素为0lnp(j) = 0; % 那么返回的第i个结果也为0elselnp(j) = log(p(j));endend%到这里结束e = -sum(p .* lnp) / log(n); % 计算信息熵D(i) = 1- e; % 计算信息效用值
end
W = D ./ sum(D); % 将信息效用值归一化,得到权重
WD_min = min(TOP_three_data);
D_max = max(TOP_three_data);zonghedefen_three = 1:31; %生成记录点
for i = 1:31%利用(C = D-/((D-)+(D+)))topsis模型与熵权进行结合D_jia = sqrt(W(1)*(TOP_three_data(i,1)-D_max(1))^2 + W(2)*(TOP_three_data(i,2)-D_max(2))^2 + ...W(3)*(TOP_three_data(i,3)-D_max(3))^2 + W(4)*(TOP_three_data(i,4)-D_max(4))^2 + ...W(5)*(TOP_three_data(i,5)-D_max(5))^2);D_jian = sqrt(W(1)*(TOP_three_data(i,1)-D_min(1))^2 + W(2)*(TOP_three_data(i,2)-D_min(2))^2 + ...W(3)*(TOP_three_data(i,3)-D_min(3))^2 + W(4)*(TOP_three_data(i,4)-D_min(4))^2 + ...W(5)*(TOP_three_data(i,5)-D_min(5))^2);zonghedefen_three(i) = D_jian/(D_jia+D_jian); % 一次就是产生31个数据
endzonghedefen_three = zonghedefen_three';% 指标四
Z = TOP_four_data;
[n,m] = size(Z);
D = zeros(1,m); % 初始化保存信息效用值的行向量
for i = 1:mx = Z(:,i); % 取出第i列的指标p = x / sum(x);% 注意,p有可能为0,此时计算ln(p)*p时,Matlab会返回NaN,所以要判断n = length(p); % 向量的长度lnp = zeros(n,1); % 初始化最后的结果for j = 1:n % 开始循环if p(j) == 0 % 如果第i个元素为0lnp(j) = 0; % 那么返回的第i个结果也为0elselnp(j) = log(p(j));endend%到这里结束e = -sum(p .* lnp) / log(n); % 计算信息熵D(i) = 1- e; % 计算信息效用值
end
W = D ./ sum(D); % 将信息效用值归一化,得到权重
WD_min = min(TOP_four_data);
D_max = max(TOP_four_data);zonghedefen_four = 1:31; %生成记录点
for i = 1:31%利用(C = D-/((D-)+(D+)))topsis模型与熵权进行结合D_jia = sqrt(W(1)*(TOP_four_data(i,1)-D_max(1))^2 + W(2)*(TOP_four_data(i,2)-D_max(2))^2);D_jian = sqrt(W(1)*(TOP_four_data(i,1)-D_min(1))^2 + W(2)*(TOP_four_data(i,2)-D_min(2))^2);zonghedefen_four(i) = D_jian/(D_jia+D_jian); % 一次就是产生31个数据
endzonghedefen_four = zonghedefen_four'; % 指标五
Z = TOP_five_data;
[n,m] = size(Z);
D = zeros(1,m); % 初始化保存信息效用值的行向量
for i = 1:mx = Z(:,i); % 取出第i列的指标p = x / sum(x);% 注意,p有可能为0,此时计算ln(p)*p时,Matlab会返回NaN,所以要判断n = length(p); % 向量的长度lnp = zeros(n,1); % 初始化最后的结果for j = 1:n % 开始循环if p(j) == 0 % 如果第i个元素为0lnp(j) = 0; % 那么返回的第i个结果也为0elselnp(j) = log(p(j));endend%到这里结束e = -sum(p .* lnp) / log(n); % 计算信息熵D(i) = 1- e; % 计算信息效用值
end
W = D ./ sum(D); % 将信息效用值归一化,得到权重
WD_min = min(TOP_five_data);
D_max = max(TOP_five_data);zonghedefen_five = 1:31; %生成记录点
for i = 1:31%利用(C = D-/((D-)+(D+)))topsis模型与熵权进行结合D_jia = sqrt(W(1)*(TOP_five_data(i,1)-D_max(1))^2 + W(2)*(TOP_five_data(i,2)-D_max(2))^2 + ...W(3)*(TOP_five_data(i,3)-D_max(3))^2 + W(4)*(TOP_five_data(i,4)-D_max(4))^2);D_jian = sqrt(W(1)*(TOP_five_data(i,1)-D_min(1))^2 + W(2)*(TOP_five_data(i,2)-D_min(2))^2 + ...W(3)*(TOP_five_data(i,3)-D_min(3))^2 + W(4)*(TOP_five_data(i,4)-D_min(4))^2);zonghedefen_five(i) = D_jian/(D_jia+D_jian); % 一次就是产生31个数据
endzonghedefen_five = zonghedefen_five'; % 指标六
Z = TOP_six_data;
[n,m] = size(Z);
D = zeros(1,m); % 初始化保存信息效用值的行向量
for i = 1:mx = Z(:,i); % 取出第i列的指标p = x / sum(x);% 注意,p有可能为0,此时计算ln(p)*p时,Matlab会返回NaN,所以要判断n = length(p); % 向量的长度lnp = zeros(n,1); % 初始化最后的结果for j = 1:n % 开始循环if p(j) == 0 % 如果第i个元素为0lnp(j) = 0; % 那么返回的第i个结果也为0elselnp(j) = log(p(j));endend%到这里结束e = -sum(p .* lnp) / log(n); % 计算信息熵D(i) = 1- e; % 计算信息效用值
end
W = D ./ sum(D); % 将信息效用值归一化,得到权重
WD_min = min(TOP_six_data);
D_max = max(TOP_six_data);zonghedefen_six = 1:31; %生成记录点
for i = 1:31%利用(C = D-/((D-)+(D+)))topsis模型与熵权进行结合D_jia = sqrt(W(1)*(TOP_six_data(i,1)-D_max(1))^2 + W(2)*(TOP_six_data(i,2)-D_max(2))^2 + ...W(3)*(TOP_six_data(i,3)-D_max(3))^2 + W(4)*(TOP_six_data(i,4)-D_max(4))^2);D_jian = sqrt(W(1)*(TOP_six_data(i,1)-D_min(1))^2 + W(2)*(TOP_six_data(i,2)-D_min(2))^2 + ...W(3)*(TOP_six_data(i,3)-D_min(3))^2 + W(4)*(TOP_six_data(i,4)-D_min(4))^2);zonghedefen_six(i) = D_jian/(D_jia+D_jian); % 一次就是产生31个数据
endzonghedefen_six = zonghedefen_six';%% 数据整合
zonghedefen = [zonghedefen_one,zonghedefen_two,zonghedefen_three,zonghedefen_four,zonghedefen_five,zonghedefen_six];
% xlswrite('C:\Users\19468\Desktop\writing_two.xlsx',zonghedefen);%% 对一级指标熵权+TOPSIS,保留各一级指标的熵值,信息效用值以及权重,以及最终得分
Z = zonghedefen;
[n,m] = size(Z);
D = zeros(1,m); % 初始化保存信息效用值的行向量
for i = 1:mx = Z(:,i); % 取出第i列的指标p = x / sum(x);% 注意,p有可能为0,此时计算ln(p)*p时,Matlab会返回NaN,所以要判断n = length(p); % 向量的长度lnp = zeros(n,1); % 初始化最后的结果for j = 1:n % 开始循环if p(j) == 0 % 如果第i个元素为0lnp(j) = 0; % 那么返回的第i个结果也为0elselnp(j) = log(p(j));endend%到这里结束e(i) = -sum(p .* lnp) / log(n); % 计算信息熵D(i) = 1- e(i); % 计算信息效用值
end
W = D ./ sum(D); % 将信息效用值归一化,得到权重
WD_min = min(zonghedefen);
D_max = max(zonghedefen);zonghedefen_last = 1:31; %生成记录点
for i = 1:31%利用(C = D-/((D-)+(D+)))topsis模型与熵权进行结合D_jia = sqrt(W(1)*(zonghedefen(i,1)-D_max(1))^2 + W(2)*(zonghedefen(i,2)-D_max(2))^2 + ...W(3)*(zonghedefen(i,3)-D_max(3))^2 + W(4)*(zonghedefen(i,4)-D_max(4))^2 + ...W(5)*(zonghedefen(i,5)-D_max(5))^2 + W(6)*(zonghedefen(i,6)-D_max(6))^2);D_jian = sqrt(W(1)*(zonghedefen(i,1)-D_min(1))^2 + W(2)*(zonghedefen(i,2)-D_min(2))^2 + ...W(3)*(zonghedefen(i,3)-D_min(3))^2 + W(4)*(zonghedefen(i,4)-D_min(4))^2 + ...W(5)*(zonghedefen(i,5)-D_min(5))^2 + W(6)*(zonghedefen(i,6)-D_min(6))^2);zonghedefen_last(i) = D_jian/(D_jia+D_jian); % 一次就是产生31个数据
endzonghedefen_last = zonghedefen_last';
e = e';
D = D';
W = W';%% 肘部法制聚类(一级)
[n, p] = size(zonghedefen_last);
K = 8;
D = zeros(K, 2);
for k = 2:K[label, c, sumd, d] = kmeans(zonghedefen_last, k, 'dist', 'sqeuclidean');% data,n×p原始数据向量% label,n×1向量,聚类结果标签;% c,k×p向量,k个聚类质心的位置% sumd,k×1向量,类间所有点与该类质心点距离之和% d,n×k向量,每个点与聚类质心的距离sse1 = sum(sumd.^2);D(k, 1) = k;D(k, 2) = sse1;
end
% 绘制聚类偏差图
plot(D(2:end, 1), D(2:end, 2), 'o-');
title('不同K值聚类偏差图')
xlabel('分类数(K值)')
ylabel('簇内误差平方和')%% 肘部法制聚类(二级)
[n, p] = size(zonghedefen);
K = 8;
D = zeros(K, 2);
for k = 2:K[label, c, sumd, d] = kmeans(zonghedefen, k, 'dist', 'sqeuclidean');% data,n×p原始数据向量% label,n×1向量,聚类结果标签;% c,k×p向量,k个聚类质心的位置% sumd,k×1向量,类间所有点与该类质心点距离之和% d,n×k向量,每个点与聚类质心的距离sse1 = sum(sumd.^2);D(k, 1) = k;D(k, 2) = sse1;
end
% 绘制聚类偏差图
plot(D(2:end, 1), D(2:end, 2), 'o-');
title('不同K值聚类偏差图')
xlabel('分类数(K值)')
ylabel('簇内误差平方和')%% 系统聚类(一级)
% 执行系统聚类
Z = linkage(zonghedefen_last, 'ward');% 绘制树状图
figure;
dendrogram(Z);
title('Hierarchical Clustering Dendrogram');% 如果你想要裁剪树状图以显示特定数量的聚类,可以使用以下代码
% 例如,我们想要将数据聚类为4个类别
k = 4;
figure;
dendrogram(Z, k);
title(['Hierarchical Clustering Dendrogram with ', num2str(k), ' clusters']);% 裁剪树状图并获取聚类索引
idx = cluster(Z, 'maxclust', k);% 绘制裁剪后的聚类结果
figure;
gscatter(zonghedefen_last(:,1), idx);
title(['Hierarchical Clustering with ', num2str(k), ' clusters']);
xlabel('Feature 1');
ylabel('Feature 2');
legend('Location', 'best');%% 系统聚类(二级)% % 执行系统聚类
% Z = linkage(zonghedefen, 'ward');
%
% % 绘制树状图
% figure;
% dendrogram(Z);
% title('Hierarchical Clustering Dendrogram');
%
% % 如果你想要裁剪树状图以显示特定数量的聚类,可以使用以下代码
% % 例如,我们想要将数据聚类为4个类别
% k = 4;
% figure;
% dendrogram(Z, k);
% title(['Hierarchical Clustering Dendrogram with ', num2str(k), ' clusters']);
%
% % 裁剪树状图并获取聚类索引
% idx = cluster(Z, 'maxclust', k);
%
% % 绘制裁剪后的聚类结果
% figure;
% gscatter(zonghedefen(:,1),zonghedefen(:,2),zonghedefen(:,3),zonghedefen(:,4),zonghedefen(:,5),zonghedefen(:,6), idx);
% title(['Hierarchical Clustering with ', num2str(k), ' clusters']);
% xlabel('Feature 1');
% ylabel('Feature 2');
% legend('Location', 'best');相关文章:

数学建模——熵权+TOPSIS+肘部法则+系统聚类
文章目录 一、起因二、代码展示 一、起因 我本科的数学建模队长找上我,让我帮她写下matlab代码,当然用的模型还是曾经打比赛的模型,所以虽然代码量多,但是写的很快,也是正逢中秋,有点时间。 当然我也没想到…...

Java | Leetcode Java题解之第403题青蛙过河
题目: 题解: class Solution {public boolean canCross(int[] stones) {int n stones.length;boolean[][] dp new boolean[n][n];dp[0][0] true;for (int i 1; i < n; i) {if (stones[i] - stones[i - 1] > i) {return false;}}for (int i 1…...

828华为云征文|华为Flexus云服务器搭建OnlyOffice私有化在线办公套件
一、引言 在当今数字化办公的时代,在线办公套件的需求日益增长。华为Flexus云服务器凭借其强大的性能和稳定性,为搭建OnlyOffice私有化在线办公套件提供了理想的平台。在2024年9月14日这个充满探索精神的日子里,我们开启利用华为Flexus云服务…...
[Java]maven从入门到进阶
介绍 apache旗下的开源项目,用于管理和构建java项目的工具 官网: Welcome to The Apache Software Foundation! 1.依赖管理 通过简单的配置, 就可以方便的管理项目依赖的资源(jar包), 避免版本冲突问题 优势: 基于项目对象模型(POM),通过一小段描述信息来管理项目的构建 2…...

Leetcode面试经典150题-130.被围绕的区域
给你一个 m x n 的矩阵 board ,由若干字符 X 和 O 组成,捕获 所有 被围绕的区域: 连接:一个单元格与水平或垂直方向上相邻的单元格连接。区域:连接所有 O 的单元格来形成一个区域。围绕:如果您可以用 X 单…...

Ruffle 继续在开源软件中支持 Adobe Flash Player
大多数人已经无需考虑对早已寿终正寝的 Adobe Flash 的支持,但对于那些仍有一些 Adobe Flash/SWF 格式的旧资产,或想重温一些基于 Flash 的旧游戏/娱乐项目的人来说,开源 Ruffle 项目仍是 2024 年及以后处理 Flash 的主要竞争者之一。 Ruffl…...

【postgres】笔记
数据库相关笔记 1.分区表创建时间戳设置问题2.查询语句2.1查询数据库某表有多少行2.2 表中某列值类型是 1.分区表创建时间戳设置问题 今天早上发现postgres数据库表中总会隔4天丢失一天的数据,后来查了一下,发现是分区表创建的有问题。 如图所示 可以看…...

#if等命令的学习
预处理命令 #include(文件包含命令) #define(宏定义命令) #undef #if(条件编译) #ifdef #ifndef #elif #endif defined函数(与if等结合使用) 下面将解释上述各自的用法、使用…...

【有啥问啥】深入浅出马尔可夫链蒙特卡罗(Markov Chain Monte Carlo, MCMC)算法
深入浅出马尔可夫链蒙特卡罗(Markov Chain Monte Carlo, MCMC)算法 0. 引言 Markov Chain Monte Carlo(MCMC)是一类用于从复杂分布中采样的强大算法,特别是在难以直接计算分布的情况下。它广泛应用于统计学、机器学习…...

java企业办公自动化OA
技术架构: sshjbpm 功能描述: 用户管理,岗位管理,部门管理,权限管理,网上交流,贴吧,审批流转。权限管理是树状结构人性化操作,也可以用作论坛。 效果图:...

【leetcode】树形结构习题
二叉树的前序遍历 返回结果:[‘1’, ‘2’, ‘4’, ‘5’, ‘3’, ‘6’, ‘7’] 144.二叉树的前序遍历 - 迭代算法 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。 示例 1: 输入:root [1,null,2,3] 输出:[1,…...

在ros2中安装gazebo遇到报错
安装命令: sudo apt-get install ros-${ROS_DISTRO}-ros-gz 报错如下: E: Unable to locate package ros-galactic-ros-gz 解决方法: 用如下安装命令: sudo apt install ros-galactic-ros-ign 问题解决!...
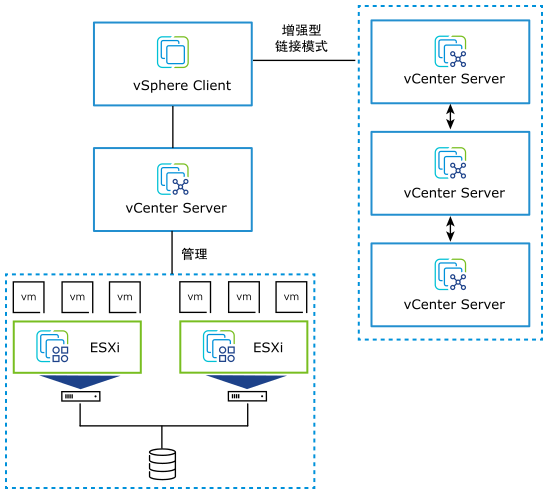
VMware vSphere 8.0 Update 3b 发布下载,新增功能概览
VMware vSphere 8.0 Update 3b 发布下载,新增功能概览 vSphere 8.0U3 | ESXi 8.0U3 & vCenter Server 8.0U3 请访问原文链接:https://sysin.org/blog/vmware-vsphere-8-u3/,查看最新版。原创作品,转载请保留出处。 作者主页…...

在设计开发中,如何提高网站的用户体验?
在网站设计开发中,提高用户体验是至关重要的。良好的用户体验不仅能提升用户的满意度和忠诚度,还能增加转化率和用户留存率。以下是一些有效的方法和策略: 优化页面加载速度 减少HTTP请求:合并CSS和JavaScript文件以减少HTTP请求…...

油耳拿什么清理比较好?好用的无线可视挖耳勺推荐
油耳的朋友通常都是用棉签来掏耳。这种方式是很不安全的。因为使用棉签戳破耳道和棉絮掉落在耳道中而引起感染的新闻不在少数。在使用过程中更加建议大家可视挖耳勺来清理会更好。不仅清晰度得干净而且安全会更高。但最近这几年我发现可视挖耳勺市面上不合格产品很多࿰…...

永久配置清华源,告别下载龟速
为了每次使用 pip 时自动使用清华源,可以通过以下步骤进行配置: 方法一:通过命令行配置 你可以在命令行中运行以下命令来自动设置清华源: pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple此命令会将…...

什么是数据库回表,又该如何避免
目录 一. 回表的概念二. 回表的影响三. 解决方案1. 使用覆盖索引2. 合理选择索引列3. 避免选择不必要的列4. 分析和优化查询5. 定期更新统计信息6. 避免使用SELECT DISTINCT或GROUP BY7. 使用适当的数据库设计 数据库中的“回表”是指在查询操作中,当数据库需要访问…...

UE5中使用UTexture2D进行纹理绘制
在UE中有时需要在CPU阶段操作像素,生成纹理贴图等,此时可以通过UTexture2D来进行处理,例子如下: 1.CPP部分 首先创建一个蓝图函数库,将UTexture2D的绘制逻辑封装成单个函数: .h: #include &…...

Matlab simulink建模与仿真 第十六章(用户定义函数库)
参考视频:simulink1.1simulink简介_哔哩哔哩_bilibili 一、用户定义函数库中的模块概览 注:MATLAB版本不同,可能有些模块也会有差异,但大体上区别是不大的。 二、Fcn/Matlab Fcn模块 1、Fcn模块 双击Fcn模块,在对话…...

每天练打字2:今日状况——完成击键5第1遍,赛文速度74.71
今日跟打:604字 总跟打:99883字 记录天数:2435天 (实际没有这么多天,这个是注册账号的天数) 平均每天:41字 练习常用单字中500,击键5,键准100%,两遍。&#x…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

2026智慧校园规划必读:如何在预算吃紧下选到高性价比方案
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

当B站字幕不再只是弹幕:你的个人学习宝库解锁指南
当B站字幕不再只是弹幕:你的个人学习宝库解锁指南 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还记得那个深夜吗?你正在B站追着某个技术…...

独立开发者如何利用Taotoken的TokenPlan在项目初期有效控制AI实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的TokenPlan在项目初期有效控制AI实验成本 对于独立开发者或学生而言,在构建AI应用原型时&…...

ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 [特殊字符]
ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 🚀 【免费下载链接】clojuredocs clojuredocs.org web app 项目地址: https://gitcode.com/gh_mirrors/cl/clojuredocs ClojureDocs作为社区驱动的Clojure文档网站,其性能优…...
的6个关键参数,选型不踩坑)
别光看手册!手把手教你读懂气体放电管(GDT)的6个关键参数,选型不踩坑
气体放电管实战选型指南:从参数表到电路设计的6个关键决策点 每次打开气体放电管(GDT)的英文数据手册,面对密密麻麻的参数表格和波形图,不少工程师都会陷入选择困难——这些数值到底如何影响实际电路保护效果…...

2026 最新版网络安全全岗位详解,入行择业一看就懂
全网最全!网络安全全岗位解析(2026版) 摘要:随着数字化转型加速,网络安全已成为企业、政务、互联网大厂的核心刚需,人才缺口持续扩大,2026年国内网络安全人才缺口已突破327万,全球缺…...
)
从酒店评论到情感分析:手把手教你用fastText做文本分类(Python实战避坑指南)
从酒店评论到情感分析:fastText文本分类实战全解析 当产品经理甩给你一份未经处理的酒店评论数据集,要求48小时内给出情感倾向分析报告时,作为工程师的你该如何应对?本文将带你用fastText这个轻量级工具,从原始数据到…...

对比直接使用官方API,Taotoken在计费透明性上的实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方API,Taotoken在计费透明性上的实际感受 1. 引言:从多模型调用到费用感知的转变 在同时接…...