Pandas的入门操作-Series对象
Pandas的数据结构

Series对象
class pandas.Series(data=None, index=None)
data参数
含义:
data是Series构造函数中最主要的参数,它用来指定要存储在Series中的数据。数据类型:
data可以是多种数据类型,例如:
Python 列表(list)或元组(tuple),如pd.Series([1, 2, 3])或pd.Series((4, 5, 6))。
NumPy 数组,例如pd.Series(np.array([7, 8, 9]))。
标量值(单个数值、字符串等),如pd.Series(5, index=[0, 1, 2]),这将创建一个包含相同标量值的Series。
字典(dictionary),字典的键将作为Series的索引(如果未另外指定索引),字典的值作为Series的数据,例如pd.Series({'a': 10, 'b': 20})。
index参数
含义:index参数用于指定Series的索引,它定义了数据的标签。
数据类型:
可以是一个Index对象(这是pandas中专门用于表示索引的数据结构),例如pd.Index(['x', 'y', 'z'])可以作为索引传递给Series。
也可以是其他类似序列的数据类型,如列表、元组等,例如pd.Series([100, 200, 300], index=['m', 'n', 'o'])。
索引长度要求:index的长度必须与data的长度相同(当data是列表、数组等有序数据结构时)。如果data是标量,index的长度决定了Series的长度。例如,data为标量值5,index为[0, 1, 2],则会生成一个包含三个元素值都为5的Series。
通过numpy.ndarray数组来创建
# 0 创建 numpy.ndarray数组
import numpy as nparr = np.array([3, 6, 9])
arr ![]()
# 1 通过 numpy.ndarray数组 来创建 Series对象(默认 索引)
import pandas as pds1 = pd.Series(arr)
s1
# 2 通过 numpy.ndarray数组 来创建 Series对象(指定 索引 类型)
s2 = pd.Series(arr, index=['x', 'y', 'z'])
s2
通过list列表来创建
# 导包 pandas
import pandas as pd
# 创建含字符串和整数的 Series 对象,,自动生成索引
s1 = pd.Series(['张三', 13])
print(s1)
print("-" * 50)
print(type(s1))
# 创建含两个字符串的 Series,自动生成索引
s2 = pd.Series(['李四', '北京'])
print(s2)
print("-" * 50)
print(type(s2))
# 创建含两个整数的 Series,自动生成索引
s3 = pd.Series([18, 15000])
print(s3)
print("-" * 50)
print(type(s3))
# 创建含有姓名和城市的 Series,自定义索引
s4 = pd.Series(["王五", "郑州"], index=['姓名', '城市'])
print(s4)
print("-" * 50)
print(type(s4))
通过元组或字典创建 Series 对象
# 1 使用元组 创建 Series 对象
import pandas as pds1 = pd.Series(('张三', '李四', '王五'), index=['a', 'b', 'c'])
print(s1)
print("-" * 50)
print(type(s1))
# 2 使用字典 创建 Series 对象
dict1 = {"name" : "悟空","age" : 23,"skill" : "火眼金睛"
}s2 = pd.Series(dict1, index=['name', 'age'])
print(s2)
print("-" * 50)
print(type(s2))
Series对象常用属性和方法
常见属性
| 属性 | 说明 |
| loc | 使用索引值取子集 |
| iloc | 使用索引位置取子集 |
| dtype或dtypes | Series内容的类型 |
| T | Series的转置矩阵 |
| shape | 数据的维数 |
| size | Series中元素的数量 |
| values | Series的值 |
常见方法
| 方法 | 说明 |
| append | 连接两个或多个Series |
| corr | 计算与另一个Series的相关系数 |
| cov | 计算与另一个Series的协方差 |
| describe | 计算常见统计量 |
| drop_duplicates | 返回去重之后的Series |
| equals | 判断两个Series是否相同 |
| get_values | 获取Series的值,作用与values属性相同 |
| hist | 绘制直方图 |
| isin | Series中是否包含某些值 |
| min | 返回最小值 |
| max | 返回最大值 |
| mean | 返回算术平均值 |
| median | 返回中位数 |
| mode | 返回众数 |
| quantile | 返回指定位置的分位数 |
| replace | 用指定值代替Series中的值 |
| sample | 返回Series的随机采样值 |
| sort_values | 对值进行排序 |
| to_frame | 把Series转换为DataFrame |
| unique | 去重返回数组 |
| value_counts | 统计不同值数量 |
| keys | 获取索引值 |
| head | 查看前5个值 |
| tail | 查看后5个值 |
import pandas as pd# 创建s对象
s1 = pd.Series(data=[1, 2, 3, 4, 2, 3], index=['E', 'F', 'A', 'B', 'C', 'D'])
print(s1)
print('=================== 常用属性 ===================')
# 查看s对象值数量
print("size: ", s1.size)# 查看s对象维度, 返回一个单个元素的元组, 元素个数代表维度数, 元素值代表值数量
print("shape: ", s1.shape)# 查看s对象数据类型
print("dtype: ", s1.dtype)# 获取s对象的数据值, 返回numpy的ndarray数组类型
print('values: ', s1.values)# 获取s对象的索引
print('index: ', s1.index)

print('=================== 常用方法 ===================')
# 查看s对象值数量
print(s1.value_counts())# 查看s对象前5个值, n默认等于5
print(s1.head(3))# 查看s对象后5个值, n默认等于5
s1.tail(3)# 获取s对象的索引
print(s1.keys())# s对象转换成python列表
print(list(s1))# s对象转换成df对象
print(s1.to_frame())
print(type(s1.to_frame()))# s对象中数据的基础统计信息
print(s1.describe())
# print('------------------------------')
# s对象最大值、最小值、平均值、求和值...
print(s1.max())
print(s1.min())
print(s1.mean())
print(s1.sum())# s对象数据值去重, 返回s对象
print(s1.drop_duplicates())
print(type(s1.drop_duplicates()))
print('------------------')
# s对象数据值去重, 返回数组
print(s1.unique())
print(type(s1.unique()))# s对象数据值排序, 默认升序
print(s1.sort_values())
# print('----------------------------------')
print(s1.sort_values(ascending=False))# s对象索引值排序, 默认升序
print(s1.sort_index())
# print('----------------------------------')
print(s1.sort_index(ascending=False))# s对象不同值的数量, 类似于分组计数操作
s1.value_counts()
实例
import pandas as pd
# 1 加载并观察数据集df = pd.read_csv('../data/a_scientists.csv')
df
# 2 获取年龄列
ages = df['Age']
ages# 3 求平均年龄
ages.mean()#%%
# 4 求高于平均年龄 组成 布尔结果
print(ages > ages.mean())
print('--------------------------------')
print(type(ages > ages.mean()))
print('--------------------------------')
print(list(ages > ages.mean()))# 5 求高于平均年龄 组成 年龄列
print(ages[ages > ages.mean()])
print('------------------------')
print(ages[list(ages > ages.mean())])求年龄大于平均值
ages > ages.mean()
df[ages > ages.mean()]
相关文章:
Pandas的入门操作-Series对象
Pandas的数据结构 Series对象 class pandas.Series(dataNone, indexNone) data参数 含义:data是Series构造函数中最主要的参数,它用来指定要存储在Series中的数据。 数据类型:data可以是多种数据类型,例如: Python 列…...

自然语言处理系列六十八》搜索引擎项目实战》搜索引擎系统架构设计
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 自然语言处理系列六十八搜索引擎项目实战》搜索引擎系统架构设计…...

H5依赖安装
依赖安装 git和sourceTree编辑器使用vscode下载nvm 和nodejs git和sourceTree 使用 ssh-keygen -t rsa 进行密钥获取 git下载地址:https://git-scm.com/ sourceTree下载地址:https://www.sourcetreeapp.com/ 编辑器使用vscode 最新版网址:…...

MatchRFG:引领MemeCoin潮流,探索无限增长潜力
Meme币无疑是本轮牛市最热闹的赛道,而围绕Meme币的讨论话题基本都集中在价格炒作上。似乎人们习惯性地认为,Meme币的创造和成长往往与真正的价值无关。热炒过后,价格能否通过共识转化为价值,也正是许多Meme币在热潮冷却后的主要成…...

2024/9/18 模型的存储与读取
一、模型的存储与读取 主要涉及到torch.save和torch.load函数 新建两个python文件: 1.在model_save文件中保存模型(方式一)和模型参数(方式二) 2.在model_load文件中读取模型(方式一)和模型参数并装载模型(方式二)...

在 fnOS上安装 KVM 虚拟化,并使用 Cockpit 网页管理虚拟机
在fnOS系统上安装 KVM 虚拟化,并使用 Cockpit 进行网页管理,可以按照以下步骤进行: 1. 安装 KVM虚拟化组件 首先,更新软件列表和系统包: sudo apt update && sudo apt upgrade -y 安装 KVM 及相关工具软件&…...

VUE实现刻度尺进度条
一、如下图所示效果: 运行后入下图所示效果: 实现原理是用div画图并动态改变进度, 二、div源码 <div style"width: 100%;"><div class"sdg_title" style"height: 35px;"><!--对话组[{{ dialo…...

ZYNQ FPGA自学笔记~点亮LED
一 ZYNQ FPGA简介 ZYNQ FPGA主要特点是包含了完整的ARM处理系统,内部包含了内存控制器和大量的外设,且可独立于可编程逻辑单元,下图中的ARM内核为 ARM Cortex™-A9,ZYNQ FPGA包含两大功能块,处理系统Processing System…...

攻击者如何在日常网络资源中隐藏恶意软件
近二十年来,安全 Web 网关 (SWG) 一直在监控网络流量,以检测恶意软件、阻止恶意网站并保护企业免受基于 Web 的威胁。 然而,攻击者已经找到了许多绕过这些防御措施的方法,SquareX的安全研究人员对此进行了记录。 最危险的策略之…...

《深度学习》深度学习 框架、流程解析、动态展示及推导
目录 一、深度学习 1、什么是深度学习 2、特点 3、神经网络构造 1)单层神经元 • 推导 • 示例 2)多层神经网络 3)小结 4、感知器 神经网络的本质 5、多层感知器 6、动态图像示例 1)一个神经元 相当于下列状态&…...

“中秋快乐”文字横幅的MATLAB代码生成
中秋快乐呀朋友们!!! 给大家带来一个好玩的代码,能够生成“中秋快乐”的横幅文字,比较简单,当然你也可以根据自己的需求去更改文字和背景,废话不多说,直接展示。 文字会一直闪烁&…...

【Node.js】RabbitMQ 延时消息
概述 在 RabbitMQ 中实现延迟消息通常需要借助插件(如 RabbitMQ 延迟队列插件),因为 RabbitMQ 本身不原生支持延迟消息。 延迟消息的一个典型场景是,当消息发布到队列后,等待一段时间再由消费者消费。这可以通过配置…...

前后端分离Vue美容店会员信息管理系统o7grs
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取 技术栈介绍 本课题的研究方法和研究步骤基本合理,难度适中,本选题是学生所学专业知识的延续,符合…...
初学Linux(学习笔记)
初学Linux(学习笔记) 前言 本文跳过了Linux前期的环境准备,直接从知识点和指令开始。 知识点: 1.目录文件夹(Windows) 2.文件内容属性 3.在Windows当中区分文件类型是通过后缀,而Linux是通过…...

新增的标准流程
同样的新增的话我们也是分成两种, 共同点: 返回值都是只需要一个Result.success就可以了 接受前端的格式都是json格式,所以需要requestbody 1.不需要连接其他表的 传统方法,在service层把各种数据拼接给new出来的employee从…...
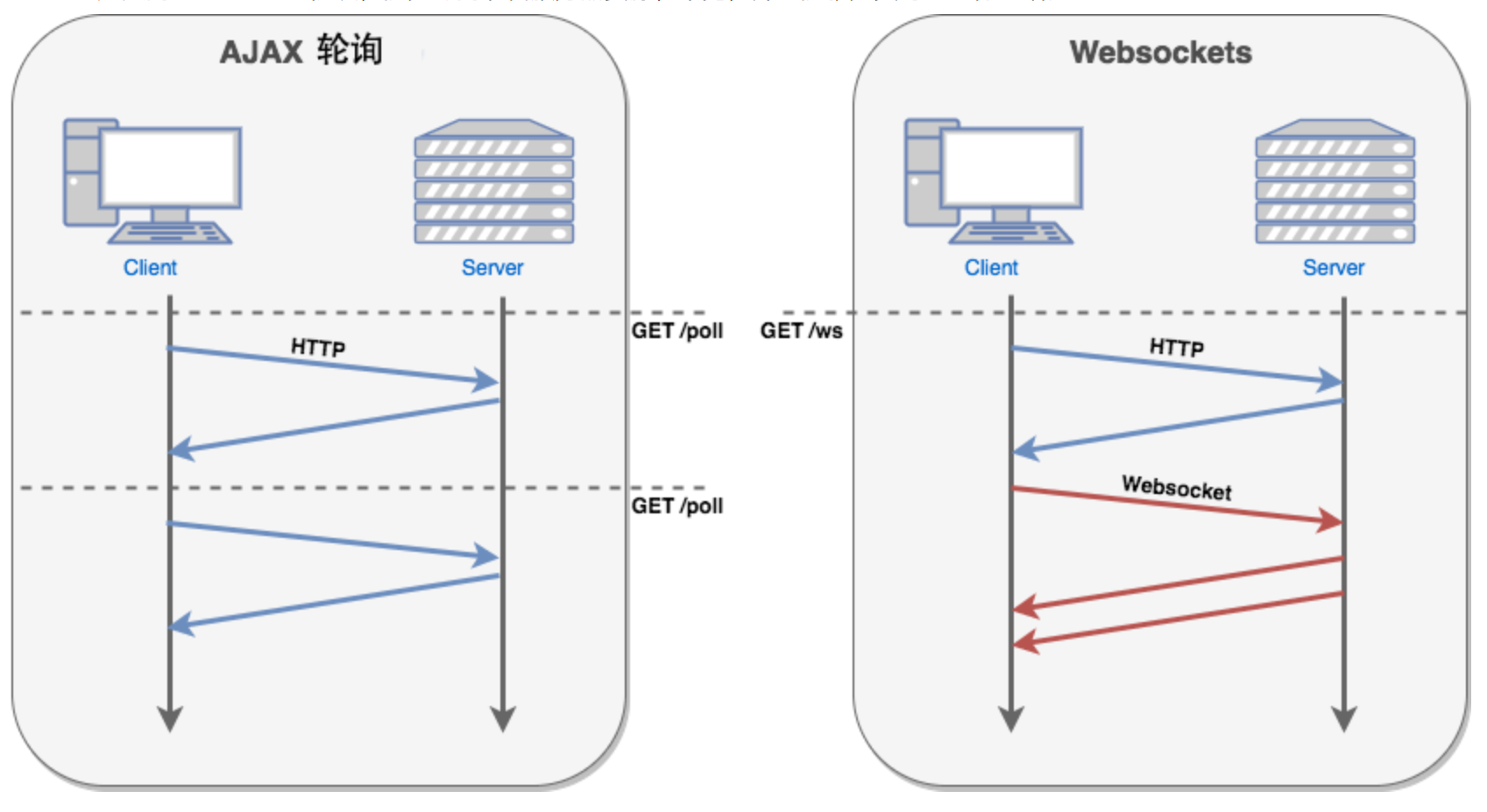
WebSocket 协议
原文地址:xupengboo WebSocket WebSocket 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议。 在 WebSocket API 中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。…...

[mysql]mysql排序和分页
#排序和分页本身是两块内容,因为都比较简单,我们就把它分到通一个内容里. #1排序: SELECT * FROM employees #我们会发现,我们没有做排序操作,但是最后出来的107条结果还是会按顺序发出,而且是每次都一样.这我们就有一个疑惑了,现在我们的数据库是根据什么来排序的,在我们没有进…...

开源 AI 智能名片 S2B2C 商城小程序中的全渠道供应策略
摘要:本文深入探讨在开源 AI 智能名片 S2B2C 商城小程序的情境下,全渠道供应的运行机制。阐述各环节企业相互配合的重要性,重点分析零售企业在其中的关键作用,包括协调工作、信息传递、需求把握等方面,旨在实现高效的全…...

一次渲染十万条数据:前端技术优化(上)
今天看了一篇文章,写的是一次性渲染十万条数据的方法,本文内容是对这篇文章的学习总结,以及知识点补充。 在现代Web应用中,前端经常需要处理大量的数据展示,例如用户评论、商品列表等。直接渲染大量数据会导致浏览器性…...

springboot实训学习笔记(5)(用户登录接口的主逻辑)
接着上篇博客学习。上篇博客是已经基本完成用户模块的注册接口的开发以及注册时的参数合法性校验。具体往回看了解的链接如下。 springboot实训学习笔记(4)(Spring Validation参数校验框架、全局异常处理器)-CSDN博客文章浏览阅读576次,点赞7…...
手写数字识别Demo)
用PyTorch和snnTorch库5分钟搞定一个脉冲神经网络(SNN)手写数字识别Demo
用PyTorch和snnTorch库5分钟搞定一个脉冲神经网络(SNN)手写数字识别Demo 脉冲神经网络(SNN)作为第三代神经网络模型,正逐渐从学术研究走向工业应用。与传统人工神经网络不同,SNN通过模拟生物神经元的脉冲发…...

FreeRTOS定时器防抖实战:用STM32 HAL库+按键中断,告别按键连击烦恼
FreeRTOS定时器防抖实战:用STM32 HAL库按键中断,告别按键连击烦恼 在嵌入式开发中,按键处理看似简单却暗藏玄机。我曾在一个智能家居项目中遇到这样的尴尬场景:用户按下墙壁开关时,本该只触发一次的动作,由…...

网盘直链下载助手完整教程:如何轻松获取百度、阿里云盘等八大平台真实下载地址
网盘直链下载助手完整教程:如何轻松获取百度、阿里云盘等八大平台真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 可以获取网盘文件真实下载地址。基于【网盘直链下载助手】修改(改自6.1.4版本) ,自用…...

Qt6 QML自定义控件实战:手把手教你做一个Material Design风格的Switch开关
Qt6 QML实战:打造Material Design风格Switch开关的完整指南 在移动端和桌面端应用开发中,开关控件(Switch)是最常用的交互元素之一。一个精致的开关不仅能提升用户体验,还能体现应用的整体设计水准。本文将带你从零开始,用Qt6 QML…...

MAD与标准差:鲁棒统计中的抗噪利器
1. 为什么我们需要抗噪统计量? 在日常数据分析中,我们经常会遇到一些"不听话"的数据点。比如分析员工薪资时突然冒出几个高管的天价年薪,或者测量温度时混入几个明显错误的极端值。这时候如果直接用传统的标准差来计算离散程度&…...

YimMenu终极指南:5大核心功能打造安全的GTA5增强体验
YimMenu终极指南:5大核心功能打造安全的GTA5增强体验 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMe…...

为什么92%的Polars新手在join时OOM?揭秘2.0新版streaming引擎的5个关键启用条件
第一章:Polars 2.0 大规模数据清洗技巧 面试题汇总Polars 2.0 引入了更严格的惰性执行模型、增强的字符串/时间解析能力,以及对空值传播行为的统一语义,使其在高频面试场景中成为考察候选人工程化数据处理能力的关键工具。以下为高频面试题及…...

个人时间管理神器:OpenClaw+百川2-13B自动分析日历与待办
个人时间管理神器:OpenClaw百川2-13B自动分析日历与待办 1. 为什么需要AI助手管理时间? 作为一个长期被多线程工作困扰的技术从业者,我一直在寻找能够真正理解时间管理需求的智能工具。传统的日历应用只能被动记录日程,而待办清…...

多模态大模型目标检测——从VOC到微调数据集的实战转换
1. 从VOC到多模态大模型的数据转换实战 第一次用Qwen2-VL做道路病害检测时,我对着VOC格式的RDD2022数据集发愁——XML文件和图片怎么变成大模型能"吃"的格式?这就像让习惯吃西餐的人突然用筷子,得先把食物切成合适的形状。下面我就…...
)
告别云端排队!用你的RTX 3060笔记本,15分钟搞定本地图生视频(FramePack保姆级配置)
用RTX 3060笔记本玩转AI视频创作:FramePack本地化实战指南 当在线AI视频生成服务需要排队等待时,拥有6GB显存的RTX 3060笔记本用户其实可以解锁更高效的创作方式。本文将带你探索如何利用FramePack这一创新工具,在消费级硬件上实现高质量的图…...