infoNCE损失和互信息的关系
文章目录
- InfoNCE 损失与互信息的关系推导
- 将相似度 sim ( q , x ) \text{sim}(q, x) sim(q,x) 看作是负的能量函数
- infoNCE和互信息的分母不同
InfoNCE 损失与互信息的关系推导
为了理解 InfoNCE 损失与互信息的关系,首先我们回顾两个公式的基本形式:
-
互信息 I ( X ; Y ) I(X; Y) I(X;Y):
互信息 I ( X ; Y ) I(X; Y) I(X;Y) 用来衡量两个变量 X X X 和 Y Y Y 之间共享的信息量,定义为:I ( X ; Y ) = E p ( x , y ) [ log p ( x , y ) p ( x ) p ( y ) ] I(X; Y) = \mathbb{E}_{p(x, y)} \left[ \log \frac{p(x, y)}{p(x) p(y)} \right] I(X;Y)=Ep(x,y)[logp(x)p(y)p(x,y)]
互信息背景知识看这篇
-
InfoNCE 损失公式:
InfoNCE 损失用于对比学习,通过最大化正样本之间的相似性、最小化负样本之间的相似性,定义为:L InfoNCE = − log exp ( sim ( q , x + ) ) ∑ i = 0 N exp ( sim ( q , x i ) ) \mathcal{L}_{\text{InfoNCE}} = - \log \frac{\exp(\text{sim}(q, x^+))}{\sum_{i=0}^{N} \exp(\text{sim}(q, x_i))} LInfoNCE=−log∑i=0Nexp(sim(q,xi))exp(sim(q,x+))
其中 x + x^+ x+ 是正样本, x i x_i xi 是负样本, sim ( q , x ) \text{sim}(q, x) sim(q,x) 表示查询样本 q q q 与样本 x x x 之间的相似度(通常使用内积或余弦相似度)。
我们现在要推导出 InfoNCE 损失和互信息的关系,步骤如下:
- InfoNCE 损失的解释
首先,我们把 InfoNCE 损失用概率的形式进行改写。可以将相似度 sim ( q , x ) \text{sim}(q, x) sim(q,x) 看作是负的能量函数,用来估计联合概率 p ( x , q ) p(x, q) p(x,q) 的对数:
sim ( q , x ) = log p ( x , q ) \text{sim}(q, x) = \log p(x, q) sim(q,x)=logp(x,q)
因此,InfoNCE 损失的形式可以被解释为对正样本联合概率和负样本对的联合概率的对比:
L InfoNCE = − log exp ( sim ( q , x + ) ) ∑ i = 0 N exp ( sim ( q , x i ) ) = − log exp ( log p ( x + , q ) ) ∑ i = 0 N exp ( log p ( x i , q ) ) = − log p ( x + , q ) ∑ i = 0 N p ( x i , q ) \mathcal{L}_{\text{InfoNCE}} = - \log \frac{\exp(\text{sim}(q, x^+))}{\sum_{i=0}^{N} \exp(\text{sim}(q, x_i))}= - \log \frac{\exp(\log p(x^+, q))}{\sum_{i=0}^{N} \exp(\log p(x_i, q))}= - \log \frac{p(x^+, q)}{\sum_{i=0}^{N} p(x_i, q)} LInfoNCE=−log∑i=0Nexp(sim(q,xi))exp(sim(q,x+))=−log∑i=0Nexp(logp(xi,q))exp(logp(x+,q))=−log∑i=0Np(xi,q)p(x+,q)
- 联合概率与边缘概率
为了与互信息的形式建立联系,接下来我们对比联合概率 p ( x , q ) p(x, q) p(x,q) 和边缘概率 p ( x ) p(x) p(x) 与 p ( q ) p(q) p(q)。InfoNCE 损失通过将正样本与负样本对比来最大化正样本的联合概率。
我们将 InfoNCE 的分母部分拆解为:
∑ i = 0 N p ( x i , q ) = p ( x + , q ) + ∑ i = 1 N p ( x i − , q ) \sum_{i=0}^{N} p(x_i, q) = p(x^+, q) + \sum_{i=1}^{N} p(x_i^{-}, q) i=0∑Np(xi,q)=p(x+,q)+i=1∑Np(xi−,q)
假设负样本 x i − x_i^- xi− 来自于 p ( x ) p(x) p(x) 的边缘分布,而正样本 x + x^+ x+ 是从联合分布 p ( x , q ) p(x, q) p(x,q) 中采样的。因此,负样本的联合概率可以看作是 p ( x i − , q ) = p ( x i − ) p ( q ) p(x_i^- , q) = p(x_i^-) p(q) p(xi−,q)=p(xi−)p(q),即将边缘概率 p ( x i − ) p(x_i^-) p(xi−) 乘以查询样本的边缘概率 p ( q ) p(q) p(q)。
这意味着分母部分可以写成:
∑ i = 0 N p ( x i , q ) ≈ p ( x + , q ) + N ⋅ p ( x − ) p ( q ) \sum_{i=0}^{N} p(x_i, q) \approx p(x^+, q) + N \cdot p(x^-) p(q) i=0∑Np(xi,q)≈p(x+,q)+N⋅p(x−)p(q)
这个公式表明正样本 p ( x + , q ) p(x^+, q) p(x+,q) 来自联合分布,而负样本是基于边缘分布 p ( x − ) p(x^-) p(x−) 和 p ( q ) p(q) p(q) 的独立抽样。
- 将 InfoNCE 损失形式与互信息公式对比
我们将 InfoNCE 损失公式代入上面的分解:
L InfoNCE = − log p ( x + , q ) p ( x + , q ) + N ⋅ p ( x − ) p ( q ) \mathcal{L}_{\text{InfoNCE}} = - \log \frac{p(x^+, q)}{p(x^+, q) + N \cdot p(x^-) p(q)} LInfoNCE=−logp(x+,q)+N⋅p(x−)p(q)p(x+,q)
为了理解这一点,我们可以考虑当 N N N 很大时,负样本对占主导地位,因此该公式可以近似为:
L InfoNCE ≈ − log p ( x + , q ) N ⋅ p ( x − ) p ( q ) \mathcal{L}_{\text{InfoNCE}} \approx - \log \frac{p(x^+, q)}{N \cdot p(x^-) p(q)} LInfoNCE≈−logN⋅p(x−)p(q)p(x+,q)
此时, N N N 仍然在对数函数的内部。为了让这个表达式更接近互信息的形式,我们需要将 N N N 从对数内部移到外部。
我们可以将这个表达式进一步简化:
L InfoNCE ≈ − log p ( x + , q ) p ( x ) p ( q ) + log N \mathcal{L}_{\text{InfoNCE}} \approx - \log \frac{p(x^+, q)}{p(x) p(q)} + \log N LInfoNCE≈−logp(x)p(q)p(x+,q)+logN
现在这个公式的第一项 − log p ( x + , q ) p ( x ) p ( q ) - \log \frac{p(x^+, q)}{p(x) p(q)} −logp(x)p(q)p(x+,q) 正是互信息的形式。第二项 log N \log N logN 是一个常数项,它与数据集中负样本的数量 N N N 相关。
因此,经过重新推导,InfoNCE 损失在 N N N 很大时近似为互信息的下界,并且可以写成如下形式:
L InfoNCE ≈ − E [ log p ( x + , q ) p ( x ) p ( q ) ] + log N \mathcal{L}_{\text{InfoNCE}} \approx - \mathbb{E} \left[ \log \frac{p(x^+, q)}{p(x)p(q)} \right] + \log N LInfoNCE≈−E[logp(x)p(q)p(x+,q)]+logN
这表明 InfoNCE 损失包含了互信息 I ( X ; Y ) I(X; Y) I(X;Y) 的一个近似项,另外加上一个与 N N N 相关的对数常数项 log N \log N logN。
为什么可以引入期望 E \mathbb{E} E ,以及期望是从哪里来的。
- 引入期望的原因
在 InfoNCE 损失函数中,正样本对 ( x + , q ) (x^+, q) (x+,q) 和负样本对 ( x i − , q ) (x_i^-, q) (xi−,q) 都是从数据中采样得到的。这意味着 InfoNCE 是对一组样本对的损失值进行计算的。但在推导互信息时,我们通常计算的是所有可能的样本对上的平均值,而不仅仅是单一的样本对。因此,为了从单个样本对的 InfoNCE 损失推广到整个数据集的平均损失,我们可以引入一个期望 E \mathbb{E} E,表示对整个数据分布进行平均。
互信息的公式本质上是对所有可能的 ( x , q ) (x, q) (x,q) 对的联合分布 p ( x , q ) p(x, q) p(x,q) 和边缘分布 p ( x ) p ( q ) p(x)p(q) p(x)p(q) 计算的期望值:
I ( X ; Y ) = E p ( x , q ) [ log p ( x , q ) p ( x ) p ( q ) ] I(X; Y) = \mathbb{E}_{p(x, q)} \left[ \log \frac{p(x, q)}{p(x)p(q)} \right] I(X;Y)=Ep(x,q)[logp(x)p(q)p(x,q)]在这种情况下,我们可以理解为在整个数据分布上计算 InfoNCE 损失的期望。也就是说, L InfoNCE \mathcal{L}_{\text{InfoNCE}} LInfoNCE 不仅仅是针对一个正样本 ( x + , q ) (x^+, q) (x+,q) 进行计算,而是针对所有正样本对 ( x , q ) (x, q) (x,q) 的平均损失。为了将 InfoNCE 损失与互信息的定义对齐,我们引入了期望 E \mathbb{E} E 来表示这个平均过程。
- 期望的具体来源
在推导 InfoNCE 与互信息的关系时,我们处理的是某一对正样本 ( x + , q ) (x^+, q) (x+,q) 的损失值。但我们要计算的是整个数据集上所有正样本对的平均损失,也就是期望值。因此,为了推广到整个数据集,我们需要在公式中引入期望。
因此,基于上述的解释,我们可以将 InfoNCE 的近似公式写成期望的形式:
L InfoNCE ≈ − E p ( x , q ) [ log p ( x , q ) p ( x ) p ( q ) ] + log N \mathcal{L}_{\text{InfoNCE}} \approx - \mathbb{E}_{p(x, q)} \left[ \log \frac{p(x, q)}{p(x)p(q)} \right] + \log N LInfoNCE≈−Ep(x,q)[logp(x)p(q)p(x,q)]+logN这个期望 E p ( x , q ) \mathbb{E}_{p(x, q)} Ep(x,q) 表示对所有可能的正样本对 ( x , q ) (x, q) (x,q) 进行计算,而不是只计算某一个特定样本对。
- 互信息的期望形式
互信息的定义:
I ( X ; Y ) = E p ( x , y ) [ log p ( x , y ) p ( x ) p ( y ) ] I(X; Y) = \mathbb{E}_{p(x, y)} \left[ \log \frac{p(x, y)}{p(x)p(y)} \right] I(X;Y)=Ep(x,y)[logp(x)p(y)p(x,y)]
也是一个关于所有可能的 ( x , y ) (x, y) (x,y) 对的期望。通过 InfoNCE 损失对正样本对进行优化,本质上就是在最大化这些正样本对的互信息,因此引入期望是为了与互信息的定义保持一致。
- 总结
引入期望 E \mathbb{E} E 是为了表明我们不仅仅是在一个正样本对上计算 InfoNCE 损失,而是在整个数据分布上对所有正样本对计算其平均损失。这样可以推广单个 InfoNCE 损失到全局,体现它与互信息最大化的关系。
这就接近于互信息的公式形式:
I ( X ; Y ) = E p ( x , y ) [ log p ( x , y ) p ( x ) p ( y ) ] I(X; Y) = \mathbb{E}_{p(x, y)} \left[ \log \frac{p(x, y)}{p(x) p(y)} \right] I(X;Y)=Ep(x,y)[logp(x)p(y)p(x,y)]
问题:但是互信息 I ( X ; Y ) = E p ( x , y ) [ log p ( x , y ) p ( x ) p ( y ) ] I(X; Y) = \mathbb{E}_{p(x, y)} \left[ \log \frac{p(x, y)}{p(x) p(y)} \right] I(X;Y)=Ep(x,y)[logp(x)p(y)p(x,y)]里面的log分子分母都是 x x x,而 L InfoNCE \mathcal{L}_{\text{InfoNCE}} LInfoNCE里面的分子是正样本 x + x^{+} x+,而分母是负样本 x x x。参看下面的“infoNCE和互信息的分母不同”
因此,InfoNCE 损失通过最大化正样本对的联合概率和最小化负样本对的边缘概率,从而实现对正样本和负样本之间互信息的优化。
- 数学上的关系:InfoNCE 是互信息的下界
通过上述推导,InfoNCE 损失可以被视为互信息的一个下界。根据 Mutual Information Neural Estimation (MINE) 的理论,InfoNCE 损失在一定条件下逼近于互信息的一个对比下界。MINE 使用的是一种基于对比学习的策略,通过优化 p ( x + , q ) p(x^+, q) p(x+,q) 和 p ( x ) p ( q ) p(x) p(q) p(x)p(q) 之间的比率来逼近互信息。
- 总结
通过推导,InfoNCE 损失通过对正负样本的对比,隐式地在最大化正样本对之间的联合概率 p ( x + , q ) p(x^+, q) p(x+,q) 和负样本对之间的边缘概率 p ( x ) p ( q ) p(x) p(q) p(x)p(q) 之间的比率,从而实现了对互信息的近似最大化。因此,InfoNCE 损失实际上是互信息的一个下界,它通过对比学习的方式来实现这一点。
将相似度 sim ( q , x ) \text{sim}(q, x) sim(q,x) 看作是负的能量函数
这个角度有点像基于能量的扩散模型的角度
将相似度函数 sim ( q , x ) \text{sim}(q, x) sim(q,x) 视为负的能量函数并用来估计联合概率 p ( x , q ) p(x, q) p(x,q) 的对数是从**能量基模型(Energy-Based Models, EBM)**的思想得来的。在这种模型中,能量函数定义了一种状态的“能量”,而状态的概率分布可以通过将能量转换为概率来表示。这个过程通常用指数函数来完成,因此能量越低,概率越高。
- 能量基模型背景
能量基模型的核心思想是给定一对输入 ( q , x ) (q, x) (q,x),通过一个能量函数 E ( q , x ) E(q, x) E(q,x) 来衡量这对输入的匹配程度。能量值 E ( q , x ) E(q, x) E(q,x) 越低,说明 q q q 和 x x x 越匹配,概率 p ( x , q ) p(x, q) p(x,q) 越高。
这里用熵的概念去理解,熵越小,说明越规律,复杂度越低,里面的元素越相近。
通常,联合概率 p ( x , q ) p(x, q) p(x,q) 可以通过能量函数的指数化来表示:
p ( x , q ) ∝ exp ( − E ( q , x ) ) p(x, q) \propto \exp(-E(q, x)) p(x,q)∝exp(−E(q,x))
这表示能量越小,概率越大。
- 相似度与能量函数的关系
在 InfoNCE 损失中, sim ( q , x ) \text{sim}(q, x) sim(q,x) 用来度量样本 q q q 和 x x x 的相似性。为了将这个相似性解释为一种概率,我们可以将相似度视为能量函数的负数。假设相似度函数 sim ( q , x ) \text{sim}(q, x) sim(q,x) 与能量函数成反比,即:
sim ( q , x ) = − E ( q , x ) \text{sim}(q, x) = -E(q, x) sim(q,x)=−E(q,x)
因此,联合概率 p ( x , q ) p(x, q) p(x,q) 可以表示为:
p ( x , q ) ∝ exp ( sim ( q , x ) ) p(x, q) \propto \exp(\text{sim}(q, x)) p(x,q)∝exp(sim(q,x))
这就是将相似度视为负能量函数的原因——高相似度(即低能量)对应于高的联合概率,低相似度(即高能量)对应于低的联合概率。
- 从相似度到联合概率的推导
我们进一步推导联合概率 p ( x , q ) p(x, q) p(x,q) 的形式。由于联合概率需要归一化,我们可以将它写成如下形式:
p ( x , q ) = exp ( sim ( q , x ) ) Z p(x, q) = \frac{\exp(\text{sim}(q, x))}{Z} p(x,q)=Zexp(sim(q,x))
其中 Z Z Z 是归一化项,确保 p ( x , q ) p(x, q) p(x,q) 是一个有效的概率分布,通常称为配分函数或分区函数:
Z = ∑ x ′ exp ( sim ( q , x ′ ) ) Z = \sum_{x'} \exp(\text{sim}(q, x')) Z=x′∑exp(sim(q,x′))
这样,通过将相似度转化为概率,便可以从模型的相似度分数得到联合概率分布 p ( x , q ) p(x, q) p(x,q)。
- 相似度作为联合概率对数的推导
现在,我们希望将相似度 sim ( q , x ) \text{sim}(q, x) sim(q,x) 直接看作联合概率 p ( x , q ) p(x, q) p(x,q) 的对数。根据上述公式,联合概率 p ( x , q ) p(x, q) p(x,q) 是相似度的指数化,因此可以直接写出:
sim ( q , x ) = log p ( x , q ) + log Z \text{sim}(q, x) = \log p(x, q)+\log Z sim(q,x)=logp(x,q)+logZ
这个公式的意义在于,相似度反映了 q q q 和 x x x 之间的匹配程度,因此与它们的联合概率成正比。
- InfoNCE 的解读
在 InfoNCE 损失中,我们希望最大化正样本 q q q 和 x + x^+ x+ 的相似度,同时最小化负样本 q q q 和 x − x^- x− 的相似度。通过将相似度看作联合概率的对数,我们可以直接使用相似度来表示 p ( x , q ) p(x, q) p(x,q),并构建概率模型进行优化。
因此,将相似度函数视为联合概率对数的依据源于能量基模型的思想,即通过能量(或相似度)函数衡量样本间的匹配程度,然后使用指数函数将其转换为概率分布。
- 总结
将相似度视为负能量函数并用来估计联合概率 p ( x , q ) p(x, q) p(x,q) 的对数可以通过以下公式推导得到:
p ( x , q ) ∝ exp ( sim ( q , x ) ) p(x, q) \propto \exp(\text{sim}(q, x)) p(x,q)∝exp(sim(q,x))
从而得到:
sim ( q , x ) = log p ( x , q ) + log Z \text{sim}(q, x) = \log p(x, q)+\log Z sim(q,x)=logp(x,q)+logZ
这个思想基于能量基模型的框架,能量函数的负数代表相似度,高相似度对应高概率,低相似度对应低概率。这种表示法使得我们能够自然地将相似度解释为联合概率的对数。
infoNCE和互信息的分母不同
这是一个很关键的问题,涉及到 InfoNCE 和互信息的本质关系。InfoNCE 损失中确实是通过对正样本对 ( q , x + ) (q, x^+) (q,x+) 和负样本对 ( q , x − ) (q, x^-) (q,x−) 进行对比学习,而互信息公式中则是计算随机变量 X X X 和 Y Y Y 的联合分布和边缘分布之间的差异。
- 互信息公式解释
互信息 I ( X ; Y ) I(X; Y) I(X;Y) 公式中的 p ( x , q ) p ( x ) p ( q ) \frac{p(x, q)}{p(x)p(q)} p(x)p(q)p(x,q) 表示 X X X 和 Y Y Y 之间共享的信息量。它衡量的是 X X X 和 Y Y Y 的联合概率分布 p ( x , q ) p(x, q) p(x,q) 与边缘概率分布 p ( x ) p ( q ) p(x)p(q) p(x)p(q) 的差异。在这个公式中, log p ( x , q ) p ( x ) p ( q ) \log \frac{p(x, q)}{p(x)p(q)} logp(x)p(q)p(x,q) 计算的是对于每个 ( x , q ) (x, q) (x,q) 对,联合分布和边缘分布的对数比值。
- 分子 p ( x , q ) p(x, q) p(x,q):表示 x x x 和 q q q 同时出现的联合概率。
- 分母 p ( x ) p ( q ) p(x)p(q) p(x)p(q):表示 x x x 和 q q q 独立出现的概率乘积,即边缘概率。
互信息通过最大化这个比值,来找到那些强相关的 x x x 和 q q q 对。
- InfoNCE 的形式和互信息的区别
在 InfoNCE 损失中,形式上有类似的结构,但是它实际上通过对比学习来优化样本对之间的关系。
InfoNCE 损失公式:
L InfoNCE = − log p ( x + , q ) p ( x + , q ) + N ⋅ p ( x ) p ( q ) \mathcal{L}_{\text{InfoNCE}} = - \log \frac{p(x^+, q)}{p(x^+, q) + N \cdot p(x) p(q)} LInfoNCE=−logp(x+,q)+N⋅p(x)p(q)p(x+,q)
可以近似为:
L InfoNCE ≈ − log p ( x + , q ) N ⋅ p ( x ) p ( q ) \mathcal{L}_{\text{InfoNCE}} \approx - \log \frac{p(x^+, q)}{N \cdot p(x) p(q)} LInfoNCE≈−logN⋅p(x)p(q)p(x+,q)
注意:
- 分子 p ( x + , q ) p(x^+, q) p(x+,q) 代表正样本 x + x^+ x+ 和查询样本 q q q 的联合概率。
- 分母 N ⋅ p ( x ) p ( q ) N \cdot p(x) p(q) N⋅p(x)p(q) 包含了 N N N 个负样本 x x x,即从数据中抽取的其他样本与 q q q 的边缘概率乘积。
为什么分子和分母不同?
- 分子 p ( x + , q ) p(x^+, q) p(x+,q):正样本 x + x^+ x+ 和 q q q 是从相同分布中采样的,因此我们希望这个联合概率尽可能大。这对应了互信息中的 p ( x , q ) p(x, q) p(x,q)。
- 分母 N ⋅ p ( x ) p ( q ) N \cdot p(x)p(q) N⋅p(x)p(q):包含了负样本的边缘概率。负样本 x − x^- x− 并不与查询样本 q q q 相关,因此我们期望这个值尽可能小。这在对比学习中通过将负样本视为噪声来实现。分母的结构是为了保证与负样本的对比,即降低负样本的相似度,从而强化正样本对的关联。
因此,虽然在形式上看起来 InfoNCE 中的分子和分母不完全对称(正样本在分子,负样本在分母),但这正是对比学习的核心思想——我们通过对正样本和负样本的对比来强化正样本间的关系(对应于 p ( x + , q ) p(x^+, q) p(x+,q)),并弱化负样本的影响(对应于 N ⋅ p ( x ) p ( q ) N \cdot p(x)p(q) N⋅p(x)p(q))。
- 解释互信息优化的视角
InfoNCE 近似于互信息的优化过程是通过以下方式实现的:
- 正样本对的联合概率最大化:这相当于互信息公式中的 p ( x , q ) p(x, q) p(x,q),我们希望提高 x + x^+ x+ 和 q q q 的匹配度,这也意味着希望它们共享更多的信息。
- 负样本对的边缘概率最小化:通过对比大量负样本,我们希望 x − x^- x− 和 q q q 的联合概率接近它们各自的独立概率,即 p ( x ) p ( q ) p(x)p(q) p(x)p(q),表示它们是无关的。通过这种方式,我们有效地在最大化互信息。
尽管分子和分母中的 x x x 和 x + x^+ x+ 不完全相同,但 InfoNCE 通过对比负样本来强调正样本的关联性,从而间接最大化了互信息。
- 总结
- 互信息公式中 log p ( x , q ) p ( x ) p ( q ) \log \frac{p(x, q)}{p(x)p(q)} logp(x)p(q)p(x,q) 是在计算 X X X 和 Y Y Y 的联合概率与独立概率之间的比值。
- 在 InfoNCE 中,分子和分母包含正样本 x + x^+ x+ 和负样本 x − x^- x−,这是为了通过对比学习来强化正样本的联合概率和弱化负样本的影响。
- InfoNCE 虽然在形式上与互信息不同,但它通过对正样本对最大化联合概率,对负样本对最小化边缘概率,从而间接地在优化正样本对之间的互信息。
相关文章:

infoNCE损失和互信息的关系
文章目录 InfoNCE 损失与互信息的关系推导将相似度 sim ( q , x ) \text{sim}(q, x) sim(q,x) 看作是负的能量函数infoNCE和互信息的分母不同 InfoNCE 损失与互信息的关系推导 为了理解 InfoNCE 损失与互信息的关系,首先我们回顾两个公式的基本形式: 互…...

Java学习路线指南
目录 前言1. Java基础知识1.1 面向对象编程思想1.2 Java平台与JVM1.3 Java语言的核心概念 2. Java语法与基础实践2.1 数据类型与变量2.2 控制结构2.3 方法与函数2.4 数据结构与集合框架 3. Java进阶知识3.1 异步编程与多线程3.2 JVM调优与垃圾回收机制3.3 设计模式 4. 实践与项…...

在SpringCloud中实现服务间链路追踪
在微服务架构中,由于系统的复杂性和多样性,往往会涉及到多个服务之间的调用。当一个请求经过多个服务时,如果出现问题,我们希望能够快速定位问题所在。这就需要引入链路追踪机制,帮助我们定位问题。 Spring Cloud为我们…...
[数据集][目标检测]红外微小目标无人机直升机飞机飞鸟检测数据集VOC+YOLO格式7559张4类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):7559 标注数量(xml文件个数):7559 标注数量(txt文件个数):7559 标注…...
TS Vue项目中使用TypeScript
模块系统与命名空间 概念 模块化开发是目前最流行的组织代码方式,可以有效的解决代码之间的冲突与代码之间的依赖关系,模块系统一般视为“外部模块”,而命名空间一般视为“内部模块” 模块系统 TS中的模块化开发跟ES6中的模块化开发并没有…...
打工人、设计师必备的AI抠图工具
前言 你是否厌倦了繁琐的PS操作?是否在寻找一种快速、简便的抠图方法?别担心,AI技术已经为你准备好了解决方案。以下是9个令人惊叹的AI抠图工具,让你无需PS也能轻松获得专业级别的抠图效果。 1. 千鹿设计助手:EmGaur…...
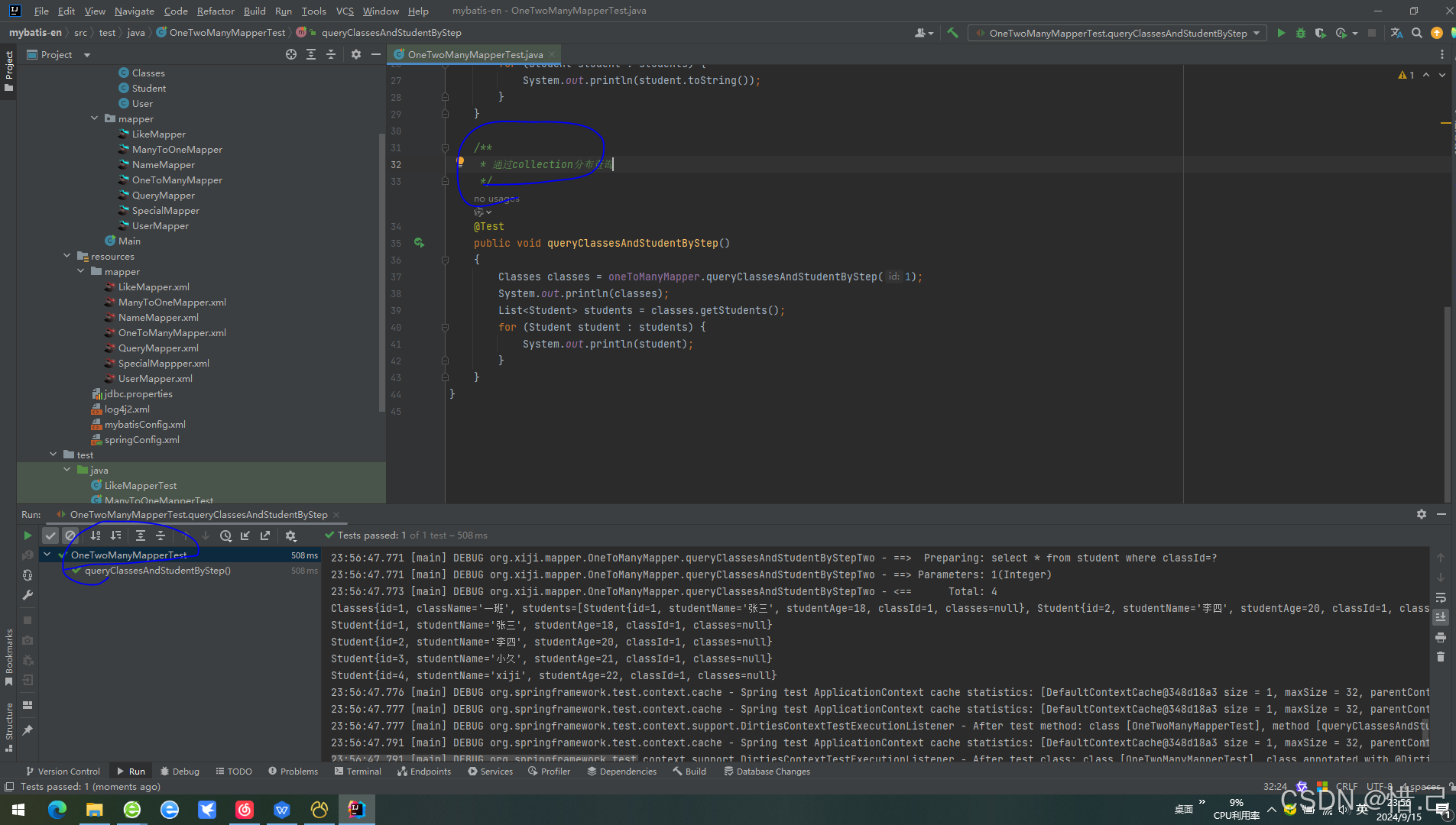
MyBatis中一对多关系的两种处理方法
目录 1.多表联查(通过collection标签的ofType属性) 1)mapper 2)mapper.xml 3)测试代码 4)测试结果 2.分布查询(通过collection标签的select属性) 1)mapper 2)mapper.xml 3࿰…...

视频美颜SDK与直播美颜工具的实现原理与优化方案
本篇文章,小编将为大家详细讲解视频美颜SDK的实现原理,并提出优化方案。 一、视频美颜SDK的实现原理 1.图像采集与处理 2.人脸识别与关键点检测 3.美颜滤镜与特效处理 4.实时性与低延迟 二、直播美颜工具的实现原理 直播美颜工具与视频美颜SDK的…...

Linux 安装JDK8和卸载
目录 一、下载JDK8的rpm包 二、安装JDK 三、设置环境变量 Linux环境下安装JDK的方式有多种,可以通过rpm包、yum安装或者tar.gz压缩包。本章节会教大家通过前两者方式来安装JDK,压缩包的形式因为下载压缩包后上传到服务器环境下,将压缩包解…...

javascript 浏览器打印不同页面设置方向,横向纵向打印
// 在JavaScript中添加打印样式 const printStyle document.createElement(style); printStyle.innerHTML media print { page { size: landscape; }body { margin: 10mm; } }; document.head.appendChild(printStyle);// 触发打印 function printPage() {window.print(); }/…...

Maven 的多种打jar包方式详细介绍、区别及使用教程——附使用命令
文章目录 1. **标准 JAR 打包****打包方式****配置示例****使用方式****优点****缺点** 2. **可执行 JAR(Executable JAR)****打包方式****配置示例****使用方式****优点****缺点** 3. **Uber JAR(Fat JAR / Shadow JAR)****打包方…...

计算机毕业设计 基于协同过滤算法的个性化音乐推荐系统 Java+SpringBoot+Vue 前后端分离 文档报告 代码讲解 安装调试
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...

Arthas 全攻略:让调试变得简单
文章目录 一、简介二、命令列表 一、简介 注意 : 我安装的版本是:Arthas V3.7.2 官网:https://arthas.aliyun.com/doc/ 相关错误解决方案请看GitHub:https://github.com/alibaba/arthas/issues Alibaba开源的Java诊断工具。 从…...
)
icpc江西:L. campus(dij最短路)
题目 在樱花盛开的季节,西湖大学吸引了大量游客,这让胥胥非常烦恼。于是,他发明了一个神奇的按钮,按下按钮后,校园里所有的游客都会以光速从最近的大门离开学校。现在,胥胥非常好奇,游客们以光…...

日志收集工具 Fluentd vs Fluent Bit 的区别
参考链接: FluentdFluentd BitFluentd & Fluent Bit | Fluent Bit: Official Manual Fluentd 与 Fluent Bit 两者都是生产级遥测生态系统! 遥测数据处理可能很复杂,尤其是在大规模处理时。这就是创建 Fluentd 的原因。 Fluentd 不仅仅是…...

PostgreSQL技术内幕11:PostgreSQL事务原理解析-MVCC
文章目录 0.简介1.MVCC介绍2.MVCC常见的实现方式3.PG的MVCC实现3.1 可见性判断3.2 提交/取消 0.简介 本文主要介绍在事务模块中MVCC(多版本并发控制)常见的实现方式,优缺点以及PG事务模块中MVCC(多版本并发控制)的实现。 1.MVCC…...

Java-面向对象编程(基础部分)
类和对象的区别和联系 类:类是封装对象的属性和行为的载体,在Java语言中对象的属性以成员变量的形式存在,而对象的方法以成员方法的形式存在。 对象:Java是面向对象的程序设计语言,对象是由类抽象出来的,…...

SMS over IP原理
目录 1. 短消息业务的实现方式 2. 传统 CS 短消息业务中的发送与送达报告 3. MAP/CAP 信令常见消息 4. SMS over IP 特点概述 5. SMS over IP 中的主要流程 5.1 短消息注册流程(NR 或 LTE 接入) 5.2 短消息发送(MO)流程(NR 或 LTE 接入) 5.3 短消息接收(MT)流程(NR 或…...

Linux中使用Docker容器构建Tomcat容器完整教程
🏡作者主页:点击! 🐧Linux基础知识(初学):点击! 🐧Linux高级管理防护和群集专栏:点击! 🔐Linux中firewalld防火墙:点击! ⏰️创作…...

【机器学习】7 ——k近邻算法
机器学习7——k近邻 输入:实例的特征向量 输出:类别 懒惰学习(lazy learning)的代表算法 文章目录 机器学习7——k近邻1.k近邻2.模型——距离,k,分类规则2.1距离——相似程度的反映2.2 k值分类规则 算法实…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...
)
第二周(第12周)
1.单电源供电的二阶低通滤波器2.功率放大电路...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南
3分钟搞定专业短视频!Pixelle-Video终极AI创作指南 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 还在为视频制作发愁吗&am…...

Metabase:零代码 BI 数据可视化工具,自建数据看板
Metabase:零代码 BI 数据可视化工具,自建数据看板 在数据驱动决策的时代,能快速看到业务数据的变化趋势至关重要。然而,专业 BI 工具(如 Tableau、Power BI)价格昂贵,而让每个业务同学都学 SQL …...

10.刷机变砖、IMEI 丢失、基带未知、触控失灵?一站式终极修复方案
摘要 本文面向具备基础计算机操作能力的维修从业者与高级用户,系统讲解当前主流品牌手机(华为、小米、OPPO、vivo、一加、苹果)的刷机与维修核心流程。内容涵盖底层引导架构差异、Fastboot/Recovery/DFU模式操作规范、分区表保护策略、驱动兼容性处理以及常见硬件故障的软件…...

如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练
如何快速上手SoundMind:10分钟完成音频逻辑推理模型训练 【免费下载链接】SoundMind We introduce the Audio Logical Reasoning (ALR) dataset, consisting of 6,446 text-audio annotated samples specifically designed for complex reasoning tasks. Building o…...

Balena Etcher:跨平台系统镜像安全写入的技术实现
Balena Etcher:跨平台系统镜像安全写入的技术实现 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 当你需要在不同操作系统之间部署系统镜像时&#x…...

COM3D2.MaidFiddler:实时内存编辑器与游戏模组开发的技术深度解析
COM3D2.MaidFiddler:实时内存编辑器与游戏模组开发的技术深度解析 【免费下载链接】COM3D2.MaidFiddler Maid Fiddler for COM3D2 -- a real-time value editor for COM3D2 项目地址: https://gitcode.com/gh_mirrors/co/COM3D2.MaidFiddler COM3D2.MaidFidd…...