Scrapy爬虫框架 Pipeline 数据传输管道
在网络数据采集领域,Scrapy 是一个非常强大的框架,而 Pipeline 是其中不可或缺的一部分。它允许我们在数据处理的最后阶段对抓取的数据进行进一步的处理,如清洗、存储等操作。
本教程将详细介绍如何在 Scrapy 中使用 Pipeline,帮助你理解和掌握如何配置、自定义以及管理和调试 Pipeline。通过本教程的学习,你将能够更加高效地处理和存储你抓取到的数据。
文章目录
- Pipeline
- 配置 Pipeline
- 自定义 Pipeline
- 管理和调试 Pipeline
- 总结
Pipeline
Pipeline 是 Scrapy 框架中的一项核心功能,用于处理 Spider 抓取到的数据。在 Pipeline 中,你可以对数据进行清洗、验证,甚至将其存储到数据库中。Pipeline 通过一系列的处理方法,使得数据可以逐步传递和处理,最终输出符合要求的数据。
| 方法 | 作用 |
|---|---|
| init(self) | 可选的初始化方法,用于进行对象的初始化和参数设置。 |
| process_item(self, item, spider) | 必须实现的方法,用于处理爬取的数据项。接收 item 和 spider 两个参数,返回一个处理后的 Item 对象。如果不需要处理数据项,可直接返回原始的 item 对象。 |
| open_spider(self, spider) | 可选的方法,在爬虫被开启时被调用。接收一个参数 spider,可用于执行一些初始化操作或其他在爬虫启动时需要完成的任务。 |
| close_spider(self, spider) | 可选的方法,在爬虫被关闭时被调用。接收一个参数 spider,可用于执行一些清理操作或其他在爬虫关闭时需要完成的任务。 |
是一个可选的初始化方法,用于在对象创建时进行初始化操作和参数设置。process_item(self, item, spider) 是这个类中必须实现的方法,它负责处理爬取到的数据项。这个方法接受两个参数:item 和 spider,并返回一个处理后的 Item 对象;如果无需处理数据,方法可以直接返回原始的 item。此外,还有两个可选的方法:open_spider(self, spider) 和 close_spider(self, spider),分别在爬虫启动和关闭时调用。open_spider 用于在爬虫开始时执行一些初始化任务,而 close_spider 则在爬虫结束时执行清理操作或其他必要的收尾工作。
在 Scrapy 中,Pipeline 是一种数据传输管道,用于对 item 对象进行逐步处理。每一个 Pipeline 类都会有一系列方法,这些方法会被 Scrapy 调用以处理抓取到的 item。通常,一个 Scrapy 项目会有多个 Pipeline,item 会依次通过这些 Pipeline 进行处理。
基本操作
在 Scrapy 中,使用 Pipeline 的基本步骤包括:
定义 Pipeline 类
每个 Pipeline 都是一个 Python 类,并且至少需要实现一个 process_item 方法。这个方法接收两个参数:item 和 spider,分别表示要处理的数据和当前使用的 Spider。
下面展示了一个简单的 Pipeline 类。process_item 方法接收一个 item,对其进行处理后返回。这里的处理可以是数据清洗、格式转换等操作。
class MyPipeline:def process_item(self, item, spider):# 处理数据return item
激活 Pipeline
在 Scrapy 项目的 settings.py 文件中,需要激活你定义的 Pipeline。通过向 ITEM_PIPELINES 字典添加你的 Pipeline 类的路径和优先级来实现。这里,ITEM_PIPELINES 是一个字典,键为 Pipeline 类的路径,值为一个整数表示优先级。优先级数值越小,Pipeline 的优先级越高,越早执行。
ITEM_PIPELINES = {'myproject.pipelines.MyPipeline': 300,
}
应用示例
Pipeline 还可以实现更多的功能,比如过滤数据、保存数据到数据库、或是对数据进行异步处理。你可以定义多个 Pipeline,并通过设置不同的优先级来控制它们的执行顺序。例如,你可以先使用一个 Pipeline 对数据进行清洗,再使用另一个 Pipeline 将清洗后的数据保存到数据库中。
这里展示了两个 Pipeline 类:CleanDataPipeline 和 SaveToDatabasePipeline。CleanDataPipeline 用于清洗数据,将价格字符串转换为浮点数;SaveToDatabasePipeline 则将清洗后的数据保存到数据库中。
class CleanDataPipeline:def process_item(self, item, spider):# 对数据进行清洗item['price'] = float(item['price'].replace('$', ''))return itemclass SaveToDatabasePipeline:def process_item(self, item, spider):# 将数据保存到数据库self.db.save(item)return item
配置 Pipeline
在 Scrapy 中,配置 Pipeline 是数据处理过程中的重要环节,它决定了数据在抓取后如何被处理和存储。通过正确配置 Pipeline,你可以将抓取到的数据传递给多个 Pipeline 类,以实现对数据的清洗、验证、存储等功能。每个 Pipeline 类负责不同的数据处理任务,而通过设置优先级,Scrapy 可以按顺序依次执行这些任务,确保数据按照预期的方式处理。
Pipeline 的配置类似于管理多个任务,每个任务都有不同的优先级。通过指定优先级,Scrapy 可以先执行重要的任务,再执行次要的任务,确保数据处理的正确性和效率。
| 步骤 | 说明 |
|---|---|
| 创建 Pipeline 类 | 编写自定义 Pipeline 类,用于处理、清洗或存储抓取到的数据。 |
| 注册 Pipeline | 在 Scrapy 项目的 settings.py 文件中,将自定义的 Pipeline 类注册到 ITEM_PIPELINES 配置项中。 |
| 设置 Pipeline 优先级 | 通过为 ITEM_PIPELINES 配置项中的每个 Pipeline 设置一个整数优先级,数字越小,优先级越高。 |
| 控制多个 Pipeline 的执行顺序 | 根据业务逻辑和需求,调整各个 Pipeline 的优先级,以控制数据处理的顺序。例如,清洗数据的 Pipeline 通常需要在存储数据的 Pipeline 之前执行。 |
配置 Pipeline 是确保数据处理顺畅且符合预期的关键步骤,通过合理的优先级设置,你可以灵活调整数据处理的流程和顺序。
基本操作
要配置 Pipeline,你需要在 Scrapy 项目的 settings.py 文件中进行相关设置。
激活 Pipeline
在 settings.py 文件中,将 Pipeline 类添加到 ITEM_PIPELINES 字典中,并为其分配一个优先级。CleanDataPipeline 的优先级为 300,而 SaveToDatabasePipeline 的优先级为 800。这意味着 CleanDataPipeline 会在 SaveToDatabasePipeline 之前执行。优先级值越小,Pipeline 执行得越早。
ITEM_PIPELINES = {'myproject.pipelines.CleanDataPipeline': 300,'myproject.pipelines.SaveToDatabasePipeline': 800,
}
配置参数
有些 Pipeline 可能需要在 settings.py 文件中配置一些参数。例如,如果你有一个 Pipeline 需要连接数据库,你可能需要在 settings.py 中提供数据库连接的配置信息。定义了一个数据库连接的 URI 和一个表名,这些参数将被用于 SaveToDatabasePipeline 中,以确保数据能够正确存储到数据库中。
DATABASE_URI = 'sqlite:///mydatabase.db'
DATABASE_TABLE = 'items'
应用示例
在实际应用中,你可能会遇到需要配置多个 Pipeline 的情况。除了设置优先级之外,你还可以根据条件选择性地启用或禁用某些 Pipeline。例如,你可能只希望在生产环境中启用某些 Pipeline,而在开发环境中禁用它们。你可以通过使用条件语句或环境变量来实现这一点。
环境变量 SCRAPY_ENV 的值来决定启用哪些 Pipeline。如果环境是生产环境 (production),则会启用所有的 Pipeline;否则,只启用 CleanDataPipeline。
import osif os.environ.get('SCRAPY_ENV') == 'production':ITEM_PIPELINES = {'myproject.pipelines.CleanDataPipeline': 300,'myproject.pipelines.SaveToDatabasePipeline': 800,}
else:ITEM_PIPELINES = {'myproject.pipelines.CleanDataPipeline': 300,}
自定义 Pipeline
自定义 Pipeline 是 Scrapy 中用于处理抓取数据的关键模块。虽然 Scrapy 提供了一些内置的 Pipeline 功能,但为了满足特定业务需求,开发者通常会根据项目需求创建自定义 Pipeline。通过自定义 Pipeline,你可以处理抓取到的数据,例如进行数据清洗、过滤、存储或者执行其他复杂操作。
就像在厨房中根据自己的口味调整食谱一样,自定义 Pipeline 使你能够灵活地控制数据处理流程。它是一个处理 item 对象的 Python 类,通过实现特定的方法,开发者可以定义数据处理的逻辑,从而保证抓取到的数据满足预期的标准。
| 步骤 | 说明 |
|---|---|
| 创建 Pipeline 类 | 编写一个继承自 object 或 BaseItem 的类,作为自定义 Pipeline。 |
实现 process_item 方法 | 在 process_item(self, item, spider) 方法中,编写自定义的处理逻辑。 |
| 调整处理流程 | 根据需求,在方法中执行数据清洗、过滤、存储等操作,返回处理后的 item。 |
| 设置 Pipeline 顺序 | 在 Scrapy 的 settings.py 文件中,定义 Pipelines 的优先级。 |
| 激活 Pipeline | 在 settings.py 中启用自定义 Pipeline,以使其参与到数据处理流程中。 |
自定义 Pipeline 赋予了开发者极大的灵活性,使其可以针对不同项目需求来调整数据的处理步骤,确保每个数据都能按照特定规则进行处理与存储。
基本操作
创建自定义 Pipeline 类
在 Scrapy 项目的 pipelines.py 文件中定义一个新的 Pipeline 类,并实现 process_item 方法。
这里定义了一个名为 CustomPipeline 的类。process_item 方法根据 item 的 price 字段判断物品是否昂贵,并在 item 中添加一个新的字段 expensive。这个字段可以用于后续的处理或存储。
class CustomPipeline:def process_item(self, item, spider):# 自定义的数据处理逻辑if item['price'] > 100:item['expensive'] = Trueelse:item['expensive'] = Falsereturn item
实现其他辅助方法(可选)
你可以选择实现 open_spider 和 close_spider 方法,用于在 Spider 启动和结束时执行一些初始化或清理工作。open_spider 方法在 Spider 启动时打开一个文件,close_spider 方法在 Spider 结束时关闭文件。而 process_item 方法则将每个 item 转换为 JSON 格式并写入文件。
class CustomPipeline:def open_spider(self, spider):self.file = open('items.jl', 'w')def close_spider(self, spider):self.file.close()def process_item(self, item, spider):line = json.dumps(dict(item)) + "\n"self.file.write(line)return item
在 settings.py 中激活自定义 Pipeline 和之前提到的激活 Pipeline 一样,你需要在 settings.py 文件中将自定义 Pipeline 注册到 ITEM_PIPELINES 中。将 CustomPipeline 添加到 ITEM_PIPELINES 中,并设置其优先级为 500,表示它将在其他 Pipeline 之后或之前运行,具体取决于其他 Pipeline 的优先级设置。
ITEM_PIPELINES = {'myproject.pipelines.CustomPipeline': 500,
}
应用示例
自定义 Pipeline 的功能可以进一步扩展。比如,你可以通过配置 Scrapy 设置来控制自定义 Pipeline 的行为,或者将不同的自定义 Pipeline 组合在一起,以实现复杂的数据处理流程。
这个 ConditionalPipeline 根据当前 Spider 的名称对 item 进行不同的处理。如果 Spider 的名称是 special_spider,那么 item 中的 special 字段将被设置为 True。
class ConditionalPipeline:def process_item(self, item, spider):# 根据条件进行不同的处理if spider.name == 'special_spider':item['special'] = Trueelse:item['special'] = Falsereturn item
管理和调试 Pipeline
管理和调试 Pipeline 是 Scrapy 项目中的关键步骤,确保数据处理流程能够高效且准确地运行。通过设置不同的 Pipeline 优先级,开发者可以灵活控制数据处理的顺序,保证各个环节的协调。此外,调试 Pipeline 则帮助发现并解决数据处理过程中出现的各种问题,确保抓取的数据能够按照预期的方式被处理和存储。就像生产线中的每一个环节都需要合理配置与监控,Pipeline 的管理和调试直接影响到最终数据处理的效果。
| 操作 | 说明 |
|---|---|
| 设置 Pipeline 优先级 | 在项目的 settings.py 中,通过配置 ITEM_PIPELINES 字典来设置不同 Pipeline 的执行顺序。 |
| 启用或禁用特定 Pipeline | 通过调整 ITEM_PIPELINES 中 Pipeline 类的启用状态,控制其在不同环境中的使用。 |
| 调试 Pipeline | 使用 Scrapy 提供的日志工具 logger 来捕捉 Pipeline 中的异常或错误信息,以便及时修复。 |
| 修改 Pipeline 行为 | 在运行时动态调整 Pipeline 的处理逻辑,适应不同的数据处理需求。 |
| 监控数据处理效率 | 通过分析 Pipeline 处理数据的时间和性能指标,优化数据处理流程。 |
基本操作
调整 Pipeline 的优先级
在 Scrapy 中,通过 settings.py 文件中的 ITEM_PIPELINES 配置,调整 Pipeline 的优先级。优先级越高的 Pipeline 越早执行。通过调整优先级,可以灵活地控制数据处理的顺序,确保重要的处理步骤优先完成。在这个示例中,CleanDataPipeline 和 ValidateDataPipeline 将分别在 SaveToDatabasePipeline 之前运行,确保数据在存储到数据库之前已经被清洗和验证。
ITEM_PIPELINES = {'myproject.pipelines.CleanDataPipeline': 300,'myproject.pipelines.ValidateDataPipeline': 400,'myproject.pipelines.SaveToDatabasePipeline': 800,
}
在不同环境中管理 Pipeline
你可以根据项目的不同阶段(如开发、测试、生产),动态地管理和调整 Pipeline 的配置。例如,你可以在开发环境中禁用某些性能开销较大的 Pipeline,只在生产环境中启用它们。这个配置根据环境变量 SCRAPY_ENV 的值决定启用哪些 Pipeline。在生产环境中,SaveToDatabasePipeline 会被激活,而在开发环境中,它将被禁用,从而节省资源并加快开发速度。
import osif os.environ.get('SCRAPY_ENV') == 'production':ITEM_PIPELINES = {'myproject.pipelines.CleanDataPipeline': 300,'myproject.pipelines.SaveToDatabasePipeline': 800,}
else:ITEM_PIPELINES = {'myproject.pipelines.CleanDataPipeline': 300,}
记录日志与调试
在 Pipeline 中,使用 Python 的 logging 模块记录调试信息是非常有效的调试手段。通过在 process_item 方法中添加日志记录,你可以实时监控数据处理的过程,并在出现异常时快速定位问题。这个 CustomPipeline 中的 process_item 方法包含了对 item 的验证逻辑和日志记录。如果 item 缺少 price 字段,它将被丢弃,并且会在日志中记录一条警告信息。如果处理成功,日志中会记录 item 已被处理的信息。
import loggingclass CustomPipeline:def process_item(self, item, spider):try:# 假设某个字段是必须的if 'price' not in item:raise DropItem(f"Missing price in {item}")item['processed'] = Truelogging.info(f"Processed item: {item}")return itemexcept DropItem as e:logging.warning(f"Item dropped: {e}")return None
应用示例
在实际项目中,你可能需要对 Pipeline 进行更复杂的管理和调试。例如,使用 Scrapy 的 signals 机制,你可以在特定的事件(如 Spider 开始或结束时)触发自定义的处理逻辑。另外,对于涉及多步骤处理的复杂 Pipeline,你可以通过设置断点或使用调试器(如 pdb)来逐步检查数据的处理流程。
这个 SignalPipeline 通过 Scrapy 的 signals 机制,在 Spider 开始时记录日志信息。这种方式可以帮助你在项目启动阶段捕获和处理特殊事件。
from scrapy import signalsclass SignalPipeline:@classmethoddef from_crawler(cls, crawler):pipeline = cls()crawler.signals.connect(pipeline.spider_opened, signal=signals.spider_opened)return pipelinedef spider_opened(self, spider):logging.info(f"Spider {spider.name} opened: ready to process items")def process_item(self, item, spider):# 正常的处理流程return item
总结
通过本教程的学习,你已经掌握了如何在 Scrapy 中使用 Pipeline 处理和管理抓取到的数据。我们从 Pipeline 的基本概念开始,逐步深入探讨了如何配置、自定义 Pipeline 以及如何有效地管理和调试它们。
这些知识和技能将使你能够更加高效和准确地处理从网络中抓取到的数据,并使你的 Scrapy 项目更加健壮和灵活。通过合理地使用和配置 Pipeline,你不仅能够确保数据质量,还能提高数据处理的自动化程度,从而节省宝贵的时间和资源。
相关文章:

Scrapy爬虫框架 Pipeline 数据传输管道
在网络数据采集领域,Scrapy 是一个非常强大的框架,而 Pipeline 是其中不可或缺的一部分。它允许我们在数据处理的最后阶段对抓取的数据进行进一步的处理,如清洗、存储等操作。 本教程将详细介绍如何在 Scrapy 中使用 Pipeline,帮…...

vim的 配置文件
vim 的配置文件名是vimrc,共有两个,一个是公共的、所有用户的vimrc,一个是私有的、个人的.vimrc。个人的配置文件是隐藏的,不进行配置的话一般是没有这个文件的,需要自己创建.vimrc 公共配置文件位于 :/etc/vim/vimrc…...

Golang | Leetcode Golang题解之第403题青蛙过河
题目: 题解: func canCross(stones []int) bool {n : len(stones)dp : make([][]bool, n)for i : range dp {dp[i] make([]bool, n)}dp[0][0] truefor i : 1; i < n; i {if stones[i]-stones[i-1] > i {return false}}for i : 1; i < n; i {…...

前端项目使用js将dom生成图片、PDF
在进行下方操作前,请你先安装 html2canvas 和 jspdf 包。 1、使用html2canvas将dom元素生成图片 // 获取要转换的dom const ele document.getElementById("dom"); // 生成canvas对象 let canvas await html2canvas(ele); 2、生成PDF对象,将…...

在 Red Hat 上安装 SQL Server 2022 并创建数据库
适用于: SQL Server - Linux 本快速入门介绍如何在 Red Hat Enterprise Linux (RHEL) 8.x 或 9.x 上安装 SQL Server 2022 (16.x)。然后可以使用 sqlcmd 进行连接,创建第一个数据库并运行查询。 注意:本教程需要用户输入和 Internet 连接。 …...

游戏如何应对云手机刷量问题
云手机的实现原理是依托公有云和 ARM 虚拟化技术,为用户在云端提供一个安卓实例,用户可以将手机上的应用上传至云端,再通过视频流的方式,远程实时控制云手机。 市面上常见的几款云手机 原本需要手机提供的计算、存储等能力都改由…...

QTableView使用QSortFilterProxyModel后行号错乱
在Qt中,当你使用QSortFilterProxyModel对QTableView进行排序或过滤后,点击事件可能会返回一个不正确的行号,因为代理模型可能会改变数据的显示顺序。为了获取点击数据的真实行号和内容,你可以使用mapToSource()函数,它…...

【Python】 报错Can‘t find model ‘en_core_web_md‘
出现这种错误表明Python环境中找不到名为en_core_web_md的模型。这通常发生在使用spaCy库进行自然语言处理时,因为spaCy依赖于预先训练好的模型来进行词性标注、依赖分析、命名实体识别等任务。如果没有安装该模型,尝试加载它时会导致错误。 解决办法&a…...

每天五分钟深度学习框架pytorch:pytorch中已经定义好的损失函数
本文重点 前面我们学习了pytorch中两种模式的损失函数,一种是nn,另外一种是functional,本文将讲解pytorch中已经封装好的损失函数。其实nn的方式就是类,而functional的方式就是方法。nn中使用的也是functional。 损失函数中的参数 无论是nn还是functional,大多数的损失函…...

dedecms(四种webshell姿势)、aspcms webshell漏洞复现
一、aspcms webshell 1、登陆后台,在扩展功能的幻灯片设置模块,点击保存进行抓包查看 2、在slideTextStatus写入asp一句话木马 1%25><%25Eval(Request(chr(65)))%25><%25 密码是a,放行,修改成功 3、使用菜刀工具连…...
——文末资料下载)
【STM32系统】基于STM32设计的智能垃圾桶(语音、颜色识别、称重、光强、烟雾、人体识别、步进电机、水泵)——文末资料下载
基于STM32设计的智能垃圾桶 演示视频: 基于STM32设计的智能垃圾桶 功能简介: 四个按键可分别打开四个垃圾桶(可回收垃圾、厨余垃圾、有害垃圾、其他垃圾) oled显示屏显示四个垃圾桶的打开/关闭状态、烟雾浓度、光照强度、称重的重量和识别到的颜色(白色、红色、绿色、蓝…...

GPT代码记录
#include <iostream>// 基类模板 template<typename T> class Base { public:void func() {std::cout << "Base function" << std::endl;} };// 特化的子类 template<typename T> class Derived : public Base<T> { public:void…...

powerbi
一. CALCULATE 和 FILTER FILTER 返回的数据必须是表, 所以 可以 用在 新建表中, 不能直接用在度量值中其实 filter 相当于 用 外表字段 去进行筛选 不使用 filter, 只能使用本表字段 进行筛选,如下1, 只能使用 门店信…...

【Unity】检测鼠标点击位置是否有2D对象
在这里提供两种方案,一种是射线检测,另一种是非射线检测。 初始准备步骤: 创建2D对象(比如2D精灵)给要被检测的2D对象添加2D碰撞体(必须是2D碰撞体)创建一个空对象,再创建一个检测…...
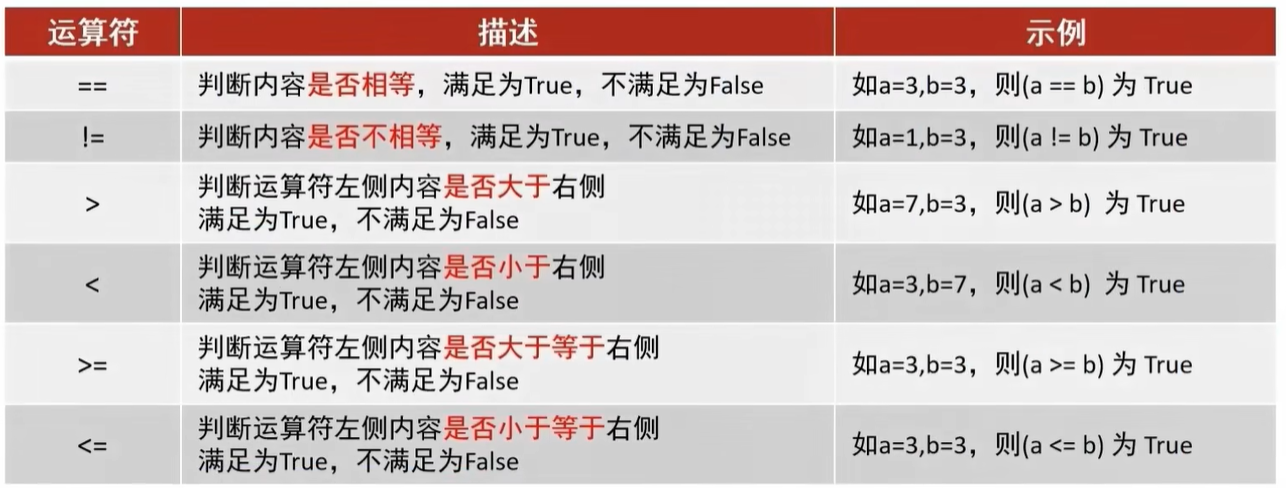
Python学习——【2.1】if语句相关语法
文章目录 【2.1】if语句相关一、布尔类型和比较运算符(一)布尔类型(二)比较运算符 二、if语句的基本格式※、练习 三、if-else组合判断语句※、练习 四、if-elif-else多条件判断语句※、练习 五、判断语句的嵌套※、实战案例 【2.…...

机器学习--K-Means
K均值聚类 算法过程 K − m e a n s K-means K−means 是 聚类 c l u s t e r i n g clustering clustering 算法的一种,就是给你一坨东西,让你给他们分类: 我们的 K − m e a n s K-means K−means 大概是这样一个流程: 第一…...

模型训练时CPU和GPU大幅度波动——可能是数据的读入拖后腿
模型训练时CPU和GPU大幅度波动——可能是数据的加载拖后腿 问题 在进行猫狗大战分类任务时,发现模型训练时CPU和GPU大幅度波动,且模型训练速度很慢。 原因 初步分析可能是数据加载(包括数据的transform,我用了Resize&#…...

keep-alive的应用场景
...

【C++ Primer Plus习题】16.9
大家好,这里是国中之林! ❥前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。有兴趣的可以点点进去看看← 问题: 解答: #include <iostream> #include <ctime> #include <v…...

Java入门:09.Java中三大特性(封装、继承、多态)02
2 继承 需要两个类才能实现继承的效果。 比如:类A 继承 类B A类 称为 子类 , 衍生类,派生类 B类 称为 父类,基类,超类 继承的作用 子类自动的拥有父类的所有属性和方法 (父类编写,子类不需要…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

基于声卡与电流互感器的安全交流功率测量系统设计与实践
1. 项目概述:用声卡安全测量交流功率我一直对各种测量技术抱有浓厚的兴趣,毕竟“测量即认知”这句老话在今天依然适用。对于电力消耗和产出,没有什么比直接测量更能说明问题了。交流功率的测量,核心在于同时获取电压和电流的瞬时值…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...

构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学
构建智能音乐档案:SoundCloud Downloader 的技术架构与实现哲学 【免费下载链接】scdl Soundcloud Music Downloader 项目地址: https://gitcode.com/gh_mirrors/sc/scdl 在流媒体音乐主导的时代,音乐爱好者面临着一种矛盾:我们享受着…...