Apache Iceberg 试用
启动 spark-sql
因为 iceberg 相关的 jars 已经在 ${SPARK_HOME}/jars 目录,所以不用 --jars 或者 --package 参数。
spark-sql --master local[1] \--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \--conf spark.sql.catalog.spark_catalog.type=hive
创建普通表
create table t1(c1 string) stored as textfile;
load data local inpath '/etc/profile' into table t1;
创建 iceberg 表
create table ti(c1 string) using iceberg;
show create table ti;
CREATE TABLE spark_catalog.test.ti (c1 STRING)
USING iceberg
LOCATION 'hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti'
TBLPROPERTIES ('current-snapshot-id' = 'none','format' = 'iceberg/parquet','format-version' = '2','write.parquet.compression-codec' = 'zstd');
这时表目录下仅有一个 metadata 目录,metadata 目录下有一个 metadata.json 文件。
[hive@master-aa9bafd-2 ~]$ hadoop fs -ls hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti;
Found 1 items
drwxr-xr-x - hive hadoop 0 2024-09-18 16:44 hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata
[hive@master-aa9bafd-2 ~]$ hadoop fs -ls hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata
Found 1 items
-rw-r--r-- 3 hive hadoop 907 2024-09-18 16:44 hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata/00000-831f9491-0ebf-45e6-9ead-902bc62ba658.metadata.json
- metadata.json 文件内容:
{"format-version" : 2,"table-uuid" : "851c7d16-3dde-407b-848b-f4c07522532f","location" : "hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti","last-sequence-number" : 0,"last-updated-ms" : 1726649083494,"last-column-id" : 1,"current-schema-id" : 0,"schemas" : [ {"type" : "struct","schema-id" : 0,"fields" : [ {"id" : 1,"name" : "c1","required" : false,"type" : "string"} ]} ],"default-spec-id" : 0,"partition-specs" : [ {"spec-id" : 0,"fields" : [ ]} ],"last-partition-id" : 999,"default-sort-order-id" : 0,"sort-orders" : [ {"order-id" : 0,"fields" : [ ]} ],"properties" : {"owner" : "hive","write.parquet.compression-codec" : "zstd"},"current-snapshot-id" : -1,"refs" : { },"snapshots" : [ ],"statistics" : [ ],"snapshot-log" : [ ],"metadata-log" : [ ]
}
insert
insert into ti select * from t1;
插入记录后,表目录下有data 目录。
[hive@master-aa9bafd-2 ~]$hadoop fs -ls hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti
Found 2 items
drwxr-xr-x - hive hadoop 0 2024-09-18 16:50 hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/data
drwxr-xr-x - hive hadoop 0 2024-09-18 16:50 hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata
再次执行 show create table,可以看到 current-snapshot-id 发生了变化。
spark-sql (test)> show create table ti;
CREATE TABLE spark_catalog.test.ti (c1 STRING)
USING iceberg
LOCATION 'hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti'
TBLPROPERTIES ('current-snapshot-id' = '5859224922072073702','format' = 'iceberg/parquet','format-version' = '2','write.parquet.compression-codec' = 'zstd')Time taken: 0.034 seconds, Fetched 1 row(s)
metadata
metadata 下有4个文件,去掉创建时生成的 00000-831f9491-0ebf-45e6-9ead-902bc62ba658.metadata.json,现在解释以下 3 个文件。
[hive@master-aa9bafd-2 ~]$ hadoop fs -ls hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata
Found 4 items
-rw-r--r-- 3 hive hadoop 907 2024-09-18 16:44 hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata/00000-831f9491-0ebf-45e6-9ead-902bc62ba658.metadata.json
-rw-r--r-- 3 hive hadoop 2006 2024-09-18 16:50 hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata/00001-c38f8b27-0e16-41f1-b8d2-410ba46fa276.metadata.json
-rw-r--r-- 3 hive hadoop 6618 2024-09-18 16:50 hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata/c7bf675a-ef11-4dd3-a9a2-4dd9cd7c300c-m0.avro
-rw-r--r-- 3 hive hadoop 4269 2024-09-18 16:50 hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata/snap-5859224922072073702-1-c7bf675a-ef11-4dd3-a9a2-4dd9cd7c300c.avro
- 第1个文件 00001-c38f8b27-0e16-41f1-b8d2-410ba46fa276.metadata.json
当前的 metadata 文件,包含
{"format-version" : 2,"table-uuid" : "851c7d16-3dde-407b-848b-f4c07522532f","location" : "hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti","last-sequence-number" : 1,"last-updated-ms" : 1726649449201,"last-column-id" : 1,"current-schema-id" : 0,"schemas" : [ {"type" : "struct","schema-id" : 0,"fields" : [ {"id" : 1,"name" : "c1","required" : false,"type" : "string"} ]} ],"default-spec-id" : 0,"partition-specs" : [ {"spec-id" : 0,"fields" : [ ]} ],"last-partition-id" : 999,"default-sort-order-id" : 0,"sort-orders" : [ {"order-id" : 0,"fields" : [ ]} ],"properties" : {"owner" : "hive","write.parquet.compression-codec" : "zstd"},"current-snapshot-id" : 5859224922072073702,"refs" : {"main" : {"snapshot-id" : 5859224922072073702,"type" : "branch"}},"snapshots" : [ {"sequence-number" : 1,"snapshot-id" : 5859224922072073702,"timestamp-ms" : 1726649449201,"summary" : {"operation" : "append","spark.app.id" : "local-1726648289519","added-data-files" : "1","added-records" : "88","added-files-size" : "1735","changed-partition-count" : "1","total-records" : "88","total-files-size" : "1735","total-data-files" : "1","total-delete-files" : "0","total-position-deletes" : "0","total-equality-deletes" : "0"},"manifest-list" : "hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata/snap-5859224922072073702-1-c7bf675a-ef11-4dd3-a9a2-4dd9cd7c300c.avro","schema-id" : 0} ],"statistics" : [ ],"snapshot-log" : [ {"timestamp-ms" : 1726649449201,"snapshot-id" : 5859224922072073702} ],"metadata-log" : [ {"timestamp-ms" : 1726649083494,"metadata-file" : "hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata/00000-831f9491-0ebf-45e6-9ead-902bc62ba658.metadata.json"} ]
}
snapshots 表明当前快照信息。
- 第2个文件 snap-5859224922072073702-1-c7bf675a-ef11-4dd3-a9a2-4dd9cd7c300c.avro 是 metafest list 文件。
包含 manifest 文件 c7bf675a-ef11-4dd3-a9a2-4dd9cd7c300c-m0.avro。
hadoop fs -text hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata/snap-5859224922072073702-1-c7bf675a-ef11-4dd3-a9a2-4dd9cd7c300c.avro
{"manifest_path":"hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata/c7bf675a-ef11-4dd3-a9a2-4dd9cd7c300c-m0.avro","manifest_length":6618,"partition_spec_id":0,"content":0,"sequence_number":1,"min_sequence_number":1,"added_snapshot_id":5859224922072073702,"added_data_files_count":1,"existing_data_files_count":0,"deleted_data_files_count":0,"added_rows_count":88,"existing_rows_count":0,"deleted_rows_count":0,"partitions":{"array":[]}}
- 第3个文件 c7bf675a-ef11-4dd3-a9a2-4dd9cd7c300c-m0.avro 是 manifest 文件。
[hive@master-aa9bafd-2 ~]$ hadoop fs -text hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/metadata/c7bf675a-ef11-4dd3-a9a2-4dd9cd7c300c-m0.avro
输出结果 中说明 data_file:
{"status":1,"snapshot_id":{"long":5859224922072073702},"sequence_number":null,"file_sequence_number":null,"data_file":{"content":0,"file_path":"hdfs://bmr-cluster/apps/spark/warehouse/test.db/ti/data/00000-3-9038b786-1a74-4a42-ac4e-45a3db21e4b5-00001.parquet","file_format":"PARQUET","partition":{},"record_count":88,"file_size_in_bytes":1735,"column_sizes":{"array":[{"key":1,"value":1375}]},"value_counts":{"array":[{"key":1,"value":88}]},"null_value_counts":{"array":[{"key":1,"value":0}]},"nan_value_counts":{"array":[]},"lower_bounds":{"array":[{"key":1,"value":""}]},"upper_bounds":{"array":[{"key":1,"value":"}"}]},"key_metadata":null,"split_offsets":{"array":[4]},"equality_ids":null,"sort_order_id":{"int":0}}}每次 insert , metadata 目录增加3 个文件
再次执行
insert into ti select * from t1;
可以看到 metadata 文件增加了 3 个文件。
相关文章:

Apache Iceberg 试用
启动 spark-sql 因为 iceberg 相关的 jars 已经在 ${SPARK_HOME}/jars 目录,所以不用 --jars 或者 --package 参数。 spark-sql --master local[1] \--conf spark.sql.extensionsorg.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \--conf spar…...
速通汇编(六)认识栈,SS、SP寄存器,push和pop指令的作用
一,栈 (一)栈的特点 栈是一种具有特殊访问方式的存储空间,特殊在于,进出这块存储空间的数据,“先进后出,后进先出” 由于栈的这个“先进后出”的特点,我们可以利用其来很好的操作内…...

【Python机器学习】NLP信息提取——值得提取的信息
目录 提取GPS信息 提取日期 如下一些关键的定量信息值得“手写”正则表达式: GPS位置;日期;价格;数字。 和上述可以通过正则表达式轻松捕获的信息相比,其他一些重要的自然语言信息需要更复杂的模式: 问…...
代理IP批理检测工具,支持socks5,socks4,http和https代理批量检测是否可用
代理IP批理检测工具,支持socks5,socks4,http和https代理批量检测是否可用 工具使用c编写: 支持ipv4及ipv6代理服务器。 支持http https socks4及socks5代理的批量检测。 支持所有windows版本运行! 导入方式支持手工选择文件及拖放文件。 导入格式支持三…...

AI视觉算法盒是什么?如何智能化升级网络摄像机,守护全方位安全
在智能化浪潮席卷全球的今天,以其创新技术引领行业变革,推出的集高效、智能、灵活于一体的AI视觉算法盒。这款革命性的产品,旨在通过智能化升级传统网络摄像机,为各行各业提供前所未有的安全监控与智能分析能力,让安全…...

【Vue】VueRouter路由
系列文章目录 第七章 VueRouter路由 文章目录 系列文章目录第一节:VueRouter基础一、安装:二、基本使用:1. 创建路由代码:Single Page Application:SPA2. 使用路由3. 展示路由: 二、嵌套路由三、路由传参1…...
idea多模块启动
文章目录 idea多模块启动2018版本的idea2019版本的idea idea多模块启动 2018版本的idea 1.首先看一下view> Tool Windows下有没有Run Dashboard 如果有,点击一下底部的窗口就会出现 如果不存在,执行下一步 2.查看自己项目的工作空间位置 点击 File&…...

23:SPI二:W25Q64存储器模块的使用
W25Q64存储器模块的使用 1、W25Q64的简介2、模块内部结构2.1:引脚结构2.2:内部存储结构2.3:此模块的注意事项 3、程序模拟SPI读写W25Q644、片上外设SPI读写W25Q64 1、W25Q64的简介 其中最主要的特点就是掉电不丢失。 由上图所示:…...

论文解读《COMMA: Co-articulated Multi-Modal Learning》
系列文章目录 文章目录 系列文章目录论文细节理解1. 研究背景2. 论文贡献3. 方法框架4. 研究思路5. 实验6. 限制结论 论文细节理解 这段话中,the vision branch is uni-directionally influenced by the text branch only 什么意思?具体举例一下 以下是…...
10款电脑加密软件超好用推荐|2024年常用电脑加密软件排行榜
随着数据隐私和信息安全意识的增强,电脑加密软件已成为日常工作和个人生活中不可或缺的工具之一。无论是保护公司机密文件,还是保障个人数据的安全,合适的加密软件都能提供强有力的保护。本文将推荐2024年超好用的10款电脑加密软件࿰…...
用户态缓存:环形缓冲区(Ring Buffer)
目录 环形缓冲区(Ring Buffer)简介 为什么选择环形缓冲区? 代码解析 1. 头文件与类型定义 1.1 头文件保护符 1.2 包含必要的标准库 1.3 类型定义 2. 环形缓冲区结构体 2.1 结构体成员解释 3. 辅助宏与内联函数 3.1 min 宏 3.2 is…...

Harmony应用 ArkTs AES 加密方法之GCM对称加密
加解密介绍 在数据存储或传输场景中,可以使用加解密操作用于保证数据的机密性,防止敏感数据泄露。 使用加解密操作中,典型的场景有: 使用对称密钥的加解密操作。 使用非对称密钥的加解密操作。 使用RSA(PKCS1_OAEP…...

热成像在战场上的具体作用!!!
1. 探测和跟踪敌人 原理:人体和许多类型的军事设备都会发热,热成像技术通过探测这些红外辐射,能够在远距离探测和跟踪敌人的位置。 应用场景:这一功能在夜间或有覆盖物(如草丛、树林)的情况下尤为有效&am…...

2024年09月20日《每日一练》
1、 根据我国“十三五”规划纲要,()不属于新一代信息技术产业创新发展的重点。 A 人工智能 B 移动智能终端 C 先进传感器 D 4G D P13 此题考察的是新一代信息技术,必须掌握,高频考点 国在“十三五“规划纲要中&#x…...
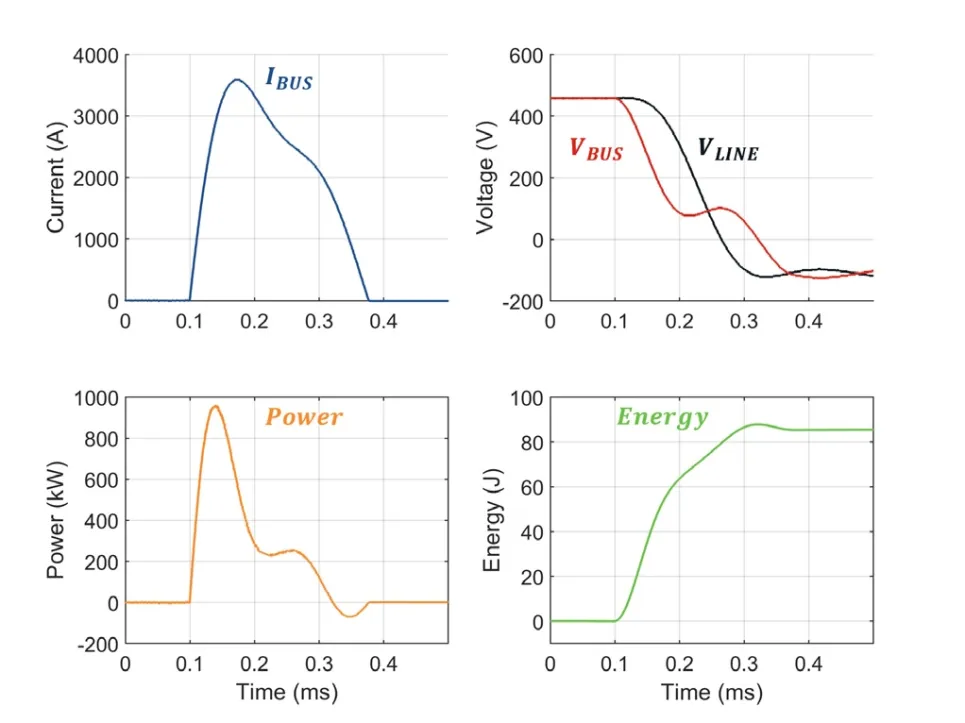
使用 SSCB 保护现代高压直流系统的优势
在各种应用中,系统效率和功率密度不断提高,这导致了更高的直流系统电压。然而,传统的电路保护解决方案不足以在保持高可靠性和安全性的同时有效保护这些高压配电系统。 固态断路器 (SSCB) 和电熔断器具有众多优点&…...

Linux基础命令——文件系统的日常管理
目录 一.如何查看当前工作目录?(你现在所处的位置路径) 二.命令touch的用途是什么?还有别的方法新建文件吗? (1)创建空文件 (2)如果已经存在这个文件,就会更新创建时间。 (3…...
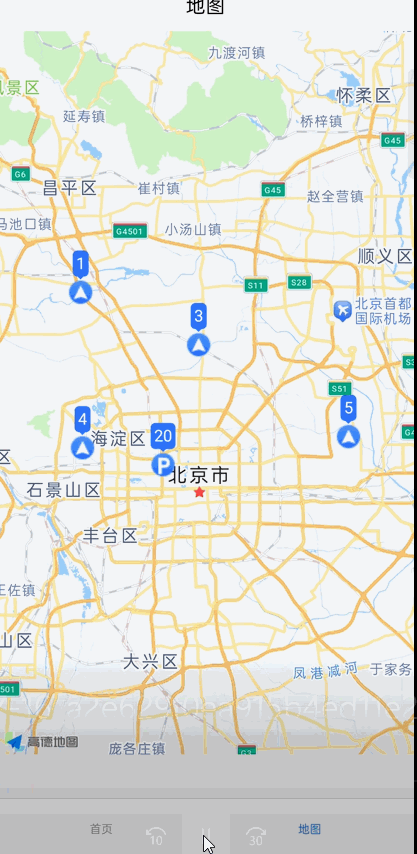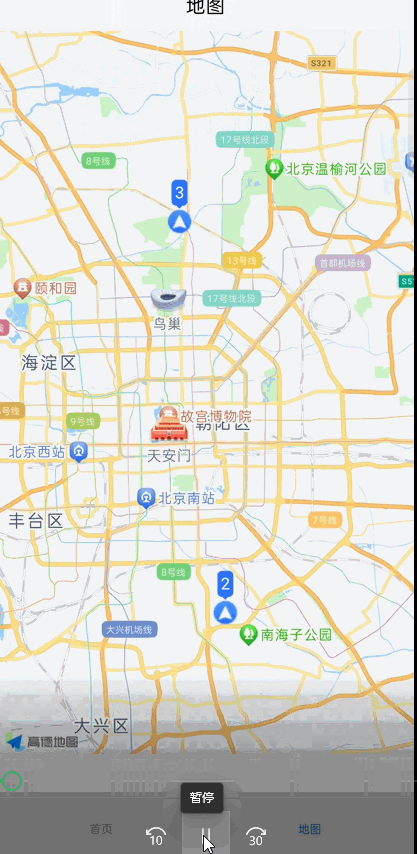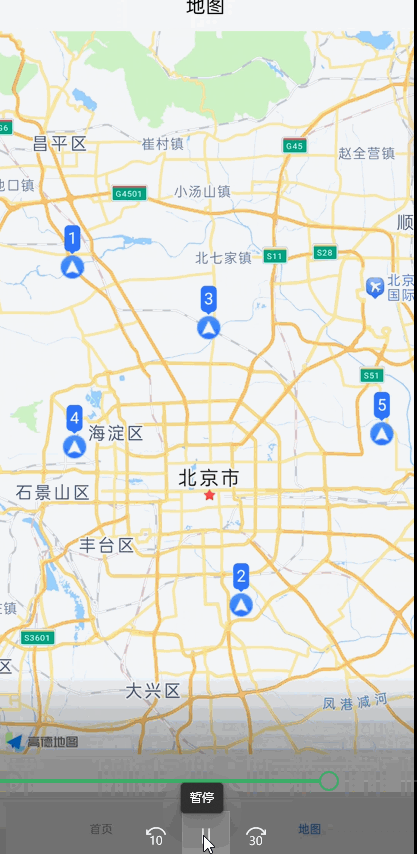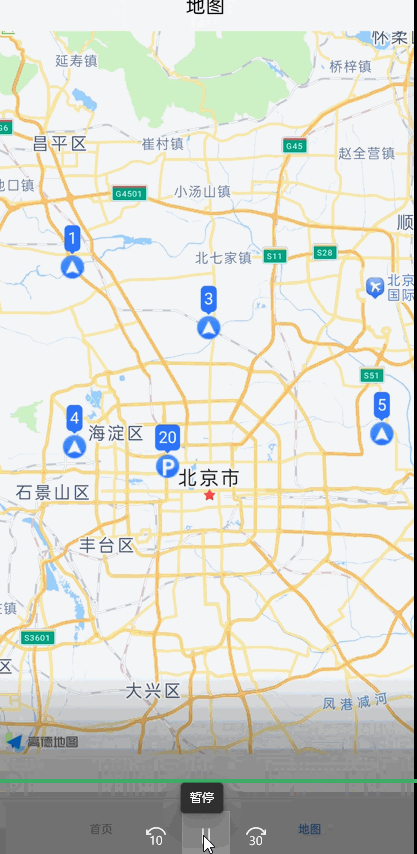
uniapp使用高德地图设置marker标记点,后续根据接口数据改变某个marker标记点,动态更新
最近写的一个功能属实把我难倒了,刚开始我请求一次数据获取所有标记点,然后设置到地图上,然后后面根据socket传来的数据对这些标记点实时更新,改变标记点的图片或者文字, 1:第一个想法是直接全量替换,事实证明这样不行,会很卡顿,有明显闪烁感,如果标记点比较少,就十几个可以用…...

坦白了,因为这个我直接爱上了 FreeBuds 6i
上个月,华为发布的 FreeBuds 6i 联名了泡泡玛特真的超级惊艳,不少宝子被这款耳机的颜值所吸引,而它的实力更是不容小觑的。FreeBuds 6i 是一款性能强大的降噪耳机,它一直在强调平均降噪深度,但是应该很多人对这个概念很…...
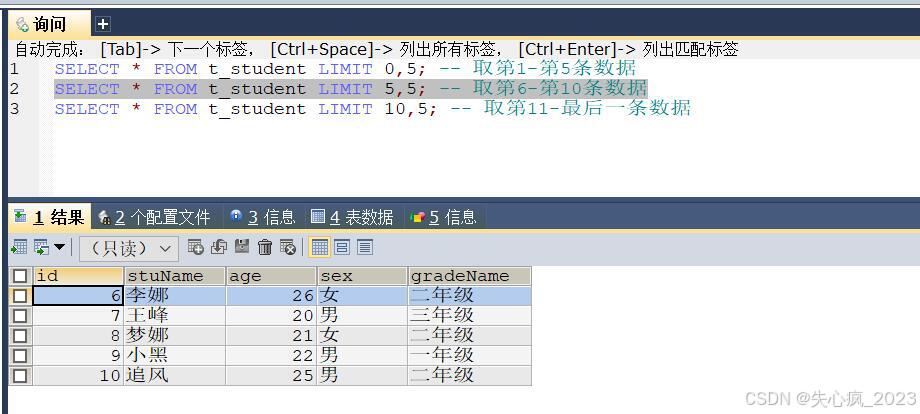
006.MySQL_查询数据
课 程 推 荐我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈虚 拟 环 境 搭 建 :…...

【C#生态园】从图像到视觉:Emgu.CV、AForge.NET、OpenCvSharp 全面解析
C#图像处理库大比拼:功能对比、安装配置、API概览 前言 图像处理和计算机视觉在现代软件开发中扮演着重要角色,而C#作为一种流行的编程语言,拥有许多优秀的图像处理库。本文将介绍几个用于C#的图像处理和计算机视觉库,包括Image…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

智能检索新范式,让AIAgent自主决策,提升RAG效率100%!
市面上的 RAG 系统,不管叫什么名字,本质上只有两种做法: 第一种,一次性检索。把用户的 query 向量化,从语料库里捞出 Top-K 个文档片段,拼成一个大 prompt 塞给模型。GraphRAG、HippoRAG、LightRAG 都属于…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

我们公司全员把 Cursor 换成了自研的 全开源AtomCode
【引子】这是一篇实录——一位 CTO 用 28 天,用 Claude GLM 双模型调度,造出了一个让全公司放弃 Cursor 的工具。然后我意识到我们正在经历的事情,比"换工具"大得多。【读者承诺】接下来 15 分钟,你会拿到三件东西:一个真实案例(28 天 1,146 commits 是怎么做出来的…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

Keil µVision反汇编窗口内容导出方案与调试技巧
1. 问题背景与需求解析在嵌入式开发过程中,调试环节往往占据大量时间。Keil Vision作为业界广泛使用的集成开发环境(IDE),其调试器功能强大但某些细节功能仍有提升空间。最近我在使用C251架构开发汽车电子控制单元时,就遇到了一个看似简单却影…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...