【数据结构】排序算法系列——快速排序(附源码+图解)
快速排序
接下来我们将要介绍的是排序中最为重要的算法之一——快速排序。
快速排序(英语:Quicksort),又称分区交换排序(partition-exchange sort),最早由东尼·霍尔提出。快速排序通常明显比其他算法更快,因为它的内部循环可以在大部分的架构上很有效率地达成。我们直接来分析它的算法思想。
算法思想与图解
我们首先直接来看算法步骤,再分析其原理和目的
- 首先确定一个基准值,基准值一般选最左边或者最右边的
- 然后使用左右指针对数据和基准值进行大小比较
- 比基准值小的放左边,比基准值大的放右边,从而使得最终基准值的左边比其小,右边比其大
- 递归重复此步骤,注意基准值不能重复,直到完全有序
具体的动画分析可以看这:快速排序算法动画演示_哔哩哔哩_bilibili
我们首先来对基准值的选择进行分析:
通常我们都会选择最左边或者最右边的基准值,这是最不需要多想的选择方法;
但是往往我们需要考虑时间效率,这样选择的话,时间效率是怎样的呢?我们知道最左边和最右边的数有可能是整个数据组中最大或者最小的数,而一轮快速排序的最终目的就是使用基准值将数据分为比其大和比其小的两部分,那么如果记住基准值本身就是一个最值,排序完之后必定也只会在最前或者最后一个位置,这样就会进行浪费的比较,从而降低效率。

如果我们需要规避这种最坏的情况,我们可以使用随机基准值或者三数取中法。这样能够有效规避最坏情况的发生,但并非绝对事件。
//1.随机取基准值
//随机选基准值,从而可以有效减小最坏情况的概率
int randindex = rand() % (right - left + 1) + left;
Swap(&a[randindex], &a[left]);//2,三数取中
int GetMid(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] < a[mid])//左边和中间比较{if(a[mid]<a[right])return mid;else if (a[left] < a[right])return right;elsereturn left;}else//左边和中间比较{if (a[mid] > a[right])return mid;else if (a[left] > a[right])return right;elsereturn left;}
}
从基准值的选择我们其实也可以看出,实际上快速排序的核心思想就是使用基准值,将数据组分成两份。这也是它分区交换排序名字的由来。分析分区原理,只要一直不断地进行分区操作,那么最后每个数都可以成为一次基准值,也就可以达到每个数的左边都比其小,右边都比其大,那么整体来看就已经实现了完全有序。
C语言代码分析
- 霍尔快排
void QuickSort1(int* a, int left, int right)
{if (left >= right)return;//随机选基准值,从而可以有效减小最坏情况的概率 int randindex = rand() % (right - left + 1) + left;Swap(&a[randindex], &a[left]);int key = left;//选择最左边为基准值while (left < right){//右边找小的while (a[right] >= a[key])right--;//左边找大的while (a[left] <= a[key])left++;Swap(&a[left], &a[right]);}Swap(&a[key], &a[left]);//二叉树的递归方式QuickSort1(a, key, left - 1);//递归左边QuickSort1(a, left + 1, right);//递归右边
}
//霍尔单趟
int PartSort1(int* a, int left, int right)
{if (left >= right)return;//随机选基准值,从而可以有效减小最坏情况的概率 int randindex = rand() % (right - left + 1) + left;Swap(&a[randindex], &a[left]);int key = left;//选择最左边为基准值while (left < right){//右边找小的while (a[right] >= a[key])right--;//左边找大的while (a[left] <= a[key])left++;Swap(&a[left], &a[right]);}Swap(&a[key], &a[left]);return left;}
注意
二叉树思想
我们观察上述的代码,会发现我们的分区思想与[[二叉树]]的思想略有相似:将基准值看成根节点,那么它的左子树——也就是左边的部分绝对比其小;类似,右子树也绝对比其大(都反过来也可)——实际上霍尔当时就是根据[[二叉树]]的思想从而发明了这样一种排序的算法。
左右指针相遇的逻辑
-
初始化指针:
- 左指针从数组的起始位置开始向右移动,寻找一个大于基准值的元素。
- 右指针从数组的末尾开始向左移动,寻找一个小于基准值的元素。
-
移动指针:
- 左指针向右移动,直到找到一个大于等于基准值的元素。
- 右指针向左移动,直到找到一个小于等于基准值的元素。
-
指针相遇:
- 当左右指针相遇时,意味着左指针的位置是一个元素大于基准值的位置,而右指针已经通过其他元素找到了一个小于基准值的元素。此时可以认为,左指针的位置应该是大于或等于基准值的(可能因为左指针已经停止在一个比基准值小的元素上),而右指针的位置则是小于或等于基准值的。
为什么相遇节点永远小于基准值
在理想的情况下,通过上述移动,左右指针不会交叉的情况下,最终会在一个位置相遇,这个位置可能就是基准值的位置,也可能比基准值小。而这个位置的元素比基准值小的原因是基于以下几点:
-
分区约束:
-
根据右边先走,左边再走的顺序,左右指针最终需要相遇前会有以下两种情况:
1.右指针找到小的,左指针没有找到大的,那么此时继续移动二指针就会相遇。
2,右指针没有找到小的,继续移动直到遇到了左指针,鉴于左指针本身就比基准值要小或者相等(才会停下),所以此时的相遇位置就可以是比基准值要小。
无独有偶,当左边先走,右边再走时就有可能遇见比基准值大的相遇位置。
-
-
基准值的定义:
- 最终将会把基准值放在左右指针交会的位置的元素上。这个位置的特性就是:在其左边的都是小于基准值的元素,而在其右边的都是大于基准值的元素。
因此,尽管左右指针可能在不等于基准值的元素上相遇,实际上通过合并数据的方式能整理出期望的排序效果。因此,它并不意味着相遇位置的元素永远小于基准值,而是说在执行分区后,基准值应该放在那个位置以满足排序的条件。
算法优化
快速排序除了霍尔发明的最初的一种算法,实际上还有改进算法。
- 挖坑法
挖坑法的实质是不断变换坑位,这个坑位最终是用来存放基准值的位置。而在算法中我们将看到坑位始终是根据左右指针来进行定位的,因此当坑位要存放基准值也就是单趟结束的时候,左右指针会相遇在基准值的坑位。左右指针的移动也是根据同基准值的大小来决定的。
这个算法的好处是有助于我们更好地理解快排的本质,从而优化算法。
//挖坑法的实质就是不断变基准值的位置,直到找到基准值的位置
void QuickSort2(int* a, int left, int right)
{if (left >= right)return;int begin = left, end = right;//三数取中int mid = GetMid(a, left, right);if (left != mid)Swap(&a[left], &a[mid]);int key = a[left];int hole = left;//挖坑位置while (left < right){//右边找小的while (a[right] >= a[key])right--;a[hole] = a[right];//填坑hole = right;//左边找大的while (a[left] <= a[key])left++;a[hole] = a[left];//填坑hole = left;Swap(&a[left], &a[right]);}Swap(&a[key], &a[left]);//二叉树的递归方式QuickSort1(a, key, left - 1);//递归左边QuickSort1(a, left + 1, right);//递归右边
}//挖坑单趟
void PartSort2(int* a, int left, int right)
{//三数取中int mid = GetMid(a, left, right);if (left != mid)Swap(&a[left], &a[mid]);int key = a[left];int hole = left;//挖坑位置while (left < right){//右边找小的while (a[right] >= a[key])right--;a[hole] = a[right];//填坑hole = right;//左边找大的while (a[left] <= a[key])left++;a[hole] = a[left];//填坑hole = left;}a[hole] = key;return hole;
}
- 前后指针法
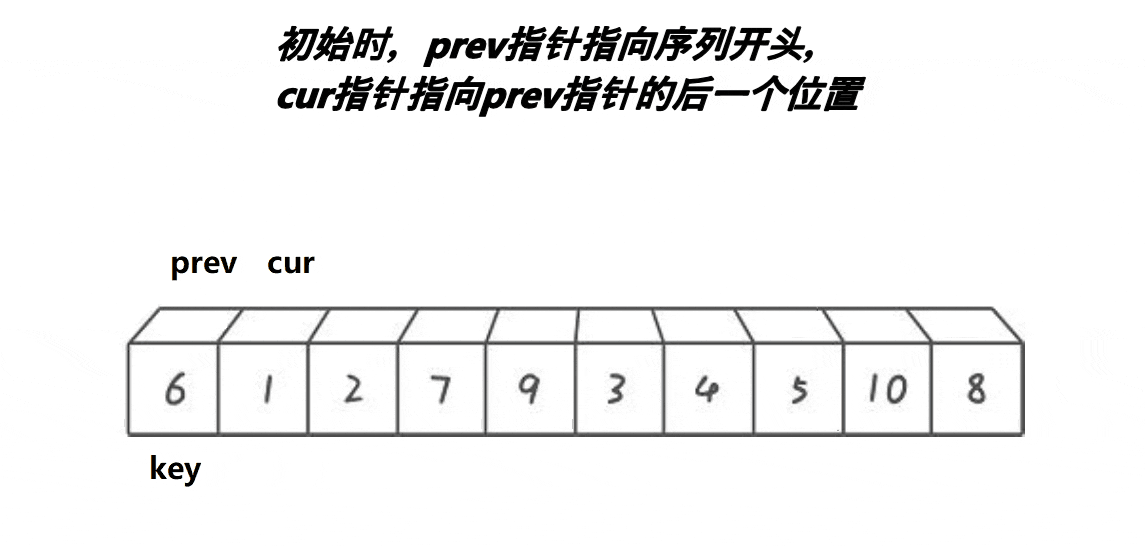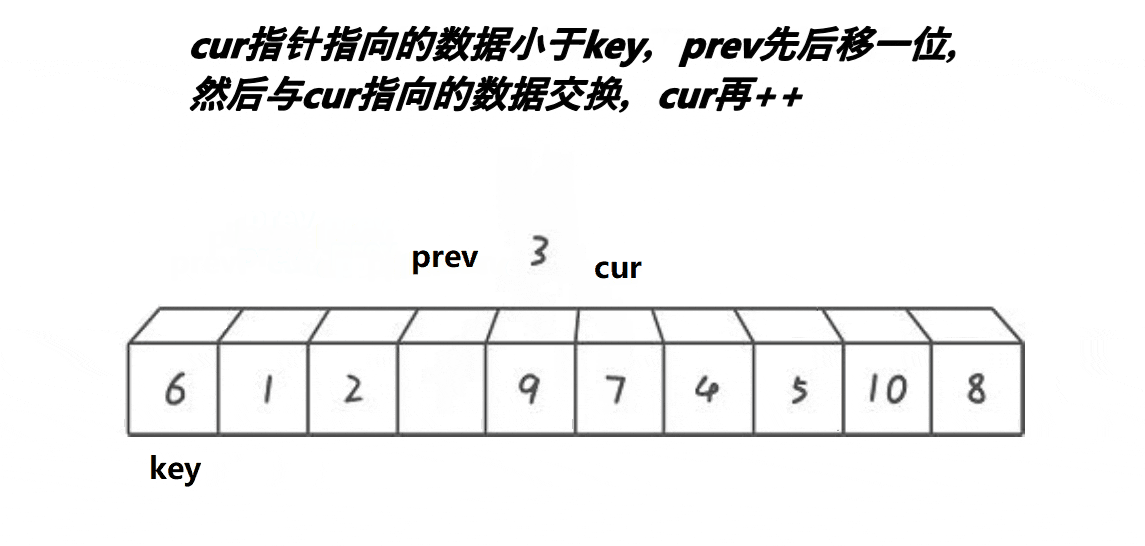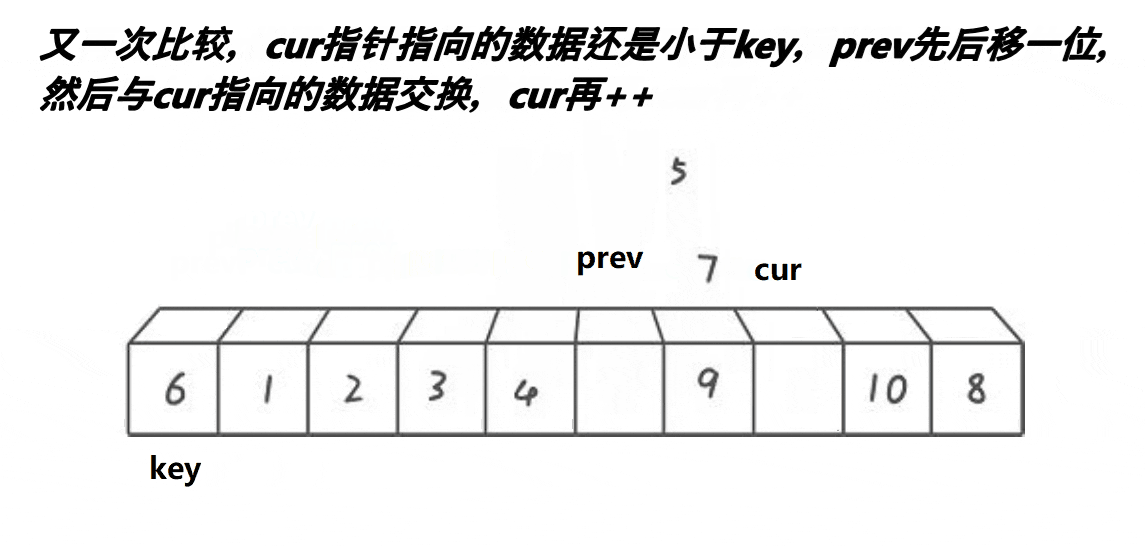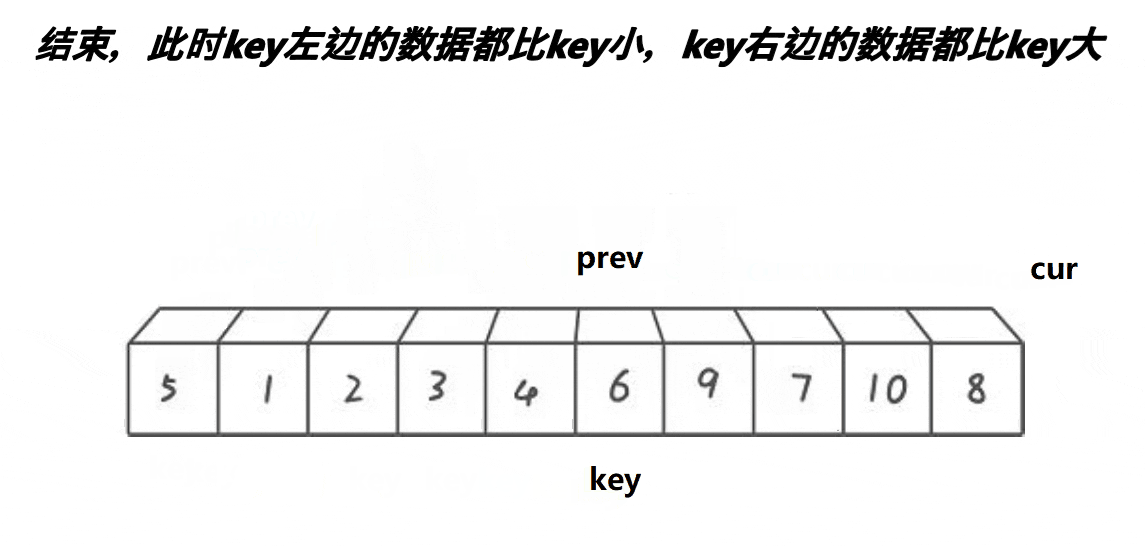
前后指针法使用cur和prev前后两个指针进行移动,规则如下:
- A.cur找到比基准值小的值,prev++,再将cur与prev位置的值交换,cur++
- B.cur找到比基准值大的值,cur++
- 当cur越界(识别完所有的数据)时,结束所有的移动,将基准值放入此时prev的位置。
我们分析,在这两种情况下,prev要么就是紧跟cur,两个指针一直依附着对方前进,要么就是中间间隔的数都比基准值要大;同时它也实现了快排的核心思想:比基准值大的放右边,比基准值小的放左边。
//第三种是前后指针法
//前后指针法的实质是通过比较后指针和基准值的大小,
//然后满足大小条件时进行前后指针交换
//交换的原则就是把小的放在前边,大的放在后边
void QuickSort3(int* a, int left, int right)
{int mid = GetMid(a, left, right);if (mid != left)Swap(&a[left], &a[mid]);int key = left;int prev = left;int cur = left + 1;while (cur <= right){if (a[cur] <a[key] && ++prev != cur){Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[prev], &a[key]);key = prev;return key;}//前后指针单趟
int PartSort3(int* a, int left, int right)
{int mid = GetMid(a, left, right);if (mid != left)Swap(&a[left], &a[mid]);int key = left;int prev = left;int cur = left + 1;while (cur <= right){if (a[cur] < a[key] && ++prev != cur){Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[prev], &a[key]);key = prev;return key;}- 非递归快排
非递归版本主要通过显式栈来模拟递归调用栈。
使用非递归的原因:当数据过多的时候,递归算法就会跑不起来——递归需要建立栈帧,当建立了过多的栈帧就会出现栈溢出的情况。
- 初始化栈:创建一个栈来保存需要处理的数组区间。
- 入栈:将整个数组的左右边界(即数组的起始和结束索引)入栈。
- 循环处理:
- 从栈顶弹出一对左右边界。
- 使用这些边界对数组进行分区,找到分区的中间点(即分区点)。
- 将分区点两侧的左右边界分别入栈,表示后续需要处理的子数组。
- 如果某个子数组的元素数量少于等于1,则不需要入栈处理。
- 结束:当栈为空时,所有区间都已经处理完毕,排序完成。
//非递归实现快排
void QuickSortNoR(int* a, int left, int right)
{ST s;STInit(&s);STPush(&s, left);//先将左右边界入栈STPush(&s, right);while (STEmpty(&s)){//取出左右边界int begin = STTop(&s);STPop(&s);int end = STTop(&s);STPop(&s);//使用一次单趟的快排得到第一次的基准值int key = PartSort3(a, begin, end);//将基准值的左右边界入栈if (key + 1 < end){STPush(&s, end);STPush(&s, key + 1);}if (begin < key-1){STPush(&s, key-1);STPush(&s, begin);}}STDestroy(&s);
}
代码解析
- S结构体:用来保存左右边界索引。
- PartSort3函数:选择数组的最右边元素为基准元素,通过交换使得基准元素的左侧都是小于等于它的元素,右侧都是大于它的元素。返回值是基准元素的最终位置。
这个算法是利用栈模拟递归过程,适用于不能使用递归的环境或递归深度较大的情况。
时间复杂度
关于快速排序为什么是最好的排序算法之一,肯定与它优秀的时间效率扯不开关系。这里我们直接看维基对于其平均时间复杂度的分析:

可以看到,快速排序从根本上就能够良好的减少遇见最坏情况的概率,而它的最坏情况实际上也坏不到哪去,如此优秀的排序机制也为它奠定了基础和不可动摇的地位。
最坏情况:O(n2)
最好情况:O(n logn)
稳定性
鉴于快速排序会改变前后元素的相对位置,所以:不稳定
相关文章:
【数据结构】排序算法系列——快速排序(附源码+图解)
快速排序 接下来我们将要介绍的是排序中最为重要的算法之一——快速排序。 快速排序(英语:Quicksort),又称分区交换排序(partition-exchange sort),最早由东尼霍尔提出。快速排序通常明显比其…...

Arthas thread(查看当前JVM的线程堆栈信息)
文章目录 二、命令列表2.1 jvm相关命令2.1.2 thread(查看当前JVM的线程堆栈信息)举例1:展示[数字]线程的运行堆栈,命令:thread 线程ID举例2:找出当前阻塞其他线程的线程 二、命令列表 2.1 jvm相关命令 2.…...

Tomcat_WebApp
Tomcat的目录的介绍 /bin: 这个目录包含启动和关闭 Tomcat 的脚本。 startup.bat / startup.sh:用于启动 Tomcat(.bat 文件是 Windows 系统用的,.sh 文件是 Linux/Unix 系统用的)。shutdown.bat / shutdown.sh…...

代码随想录算法训练营Day10
150. 逆波兰表达式求值 力扣题目链接;. - 力扣(LeetCode) Collection——Deque——LInkedList类 class Solution {public int evalRPN(String[] tokens) {Deque<Integer> myquenew LinkedList<>();for(String a:tokens){if(a.…...

十个服务器中毒的常见特征及其检测方法
服务器作为企业的核心资源,其安全性至关重要。一旦服务器被病毒入侵,不仅会影响系统的正常运行,还可能导致数据泄露等严重后果。以下是十种常见的服务器中毒特征及其检测方法。 1. 系统性能下降 病毒常常占用大量的CPU和内存资源࿰…...
LeetCode 每周算法 6(图论、回溯)
LeetCode 每周算法 6(图论、回溯) 图论算法: class Solution: def dfs(self, grid: List[List[str]], r: int, c: int) -> None: """ 深度优先搜索函数,用于遍历并标记与当前位置(r, c)相连的所有陆地&…...

Selenium元素定位:深入探索与实践
目录 一、引言 二、Selenium元素定位基础 1. WebDriver与元素定位 2. 定位策略概览 三、ID定位 1. 特点与优势 2. 示例代码 四、Class Name定位 1. 特点与限制 2. 示例代码 五、XPath定位 1. 特点与优势 2. 示例代码 3. XPath高级用法 六、CSS Selector定位 1.…...
使用vercel进行网页开发)
前端开发——(1)使用vercel进行网页开发
前端开发——(1)使用Vercel进行网页开发 在现代前端开发中,选择一个高效的部署平台至关重要。Vercel 提供了快速、简便的部署方式,特别适合静态网站和 Next.js 应用。本文将带你逐步了解如何使用 Vercel 部署并运行你的网页项目。…...
故障诊断│GWO-DBN灰狼算法优化深度置信网络故障诊断
1.引言 随着人工智能技术的快速发展,深度学习已经成为解决复杂问题的热门方法之一。深度置信网络(DBN)作为深度学习中应用比较广泛的一种算法,被广泛应用于分类和回归预测等问题中。然而,DBN的训练过程通常需要大量的…...

【工具】Windows|两款开源桌面窗口管理小工具Deskpins和WindowTop
总结 Deskpins 功能单一,拖到窗口上窗口就可以置顶并且标记钉子标签,大小 104 KB,开源位置:https://github.com/thewhitegrizzli/DeskPins/releases WindowTop 功能完善全面强大,包括透明度、置顶、选区置顶等一系列功…...

【Unity杂谈】iOS 18中文字体显示问题的调查
一、问题现象 最近苹果iOS 18系统正式版推送,周围升级系统的同事越来越多,有些同事发现,iOS 18上很多游戏(尤其是海外游戏)的中文版,显示的字很奇怪,就像一些字被“吞掉了”,无法显示…...

后端-navicat查找语句(单表与多表)
表格字段设置如图 语句: 1.输出 1.输出name和age列 SELECT name,age from student 1.2.全部输出 select * from student 2.where子语句 1.运算符: 等于 >大于 >大于等于 <小于 <小于等于 ! <>不等于 select * from stude…...

基于springboot的在线视频点播系统
文未可获取一份本项目的java源码和数据库参考。 国外研究现状: 与传统媒体不同的是,新媒体在理念和应用上都采用了新颖的媒介或媒体。新媒体是指应用在数字技术、在传统媒体基础上改造、或者更新换代而来的媒介或媒体。新兴媒体与传统媒体在理念和应用…...

笔记整理—内核!启动!—kernel部分(8)动态编译链接库与BSP文件
linux的C语言程序是用编译的,但是如果要在开发板上运行的话就不能使用默认的ubuntu提供的gcc编译器,而是使用arm-linux版本的一类的编译器。我们可以用file xx去查看一个程序的架构。 (arm架构) (intel的80386架构&…...

Cpp类和对象(中续)(5)
文章目录 前言一、赋值运算符重载运算符重载赋值运算符重载赋值运算符不可重载为全局函数前置和后置的重载 二、const修饰成员函数三、取地址及const取地址操作符重载四、日期类的实现构造函数日期 天数日期 天数日期 - 天数日期 - 天数日期类的大小比较日期类 > 日期类日…...

深度学习02-pytorch-01-张量的创建
深度学习 pytorch 框架 是目前最热门的。 深度学习 pytorch 框架相当于 机器学习阶段的 numpy sklearn 它将数据封装成张量(Tensor)来进行处理,其实就是数组。也就是numpy 里面的 ndarray . pip install torch1.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simp…...

pg入门9—pg中的extentions是什么
在 PostgreSQL(PG)中,Extension(扩展) 是一组预先打包的功能模块,可以轻松地添加到数据库中以扩展其功能。这些扩展通常包含新的数据类型、函数、索引方法、操作符以及其他数据库增强功能。通过扩展&#x…...
--(1))
JAVA:Nginx(轻量级的Web服务器、反向代理服务器)--(1)
一、Nginx:起因 nginx为什么为开发出来,起因是什么 总述:NGINX 的开发起因源于上世纪 90 年代末至 2000 年代初的互联网快速发展。当时,互联网流量急剧增长,特别是像 Apache 这样的传统 Web 服务器在高并发连接处理方面开始显现出瓶颈。 举例子:Apache 的 "每个连接…...

互斥锁和自旋锁
1、锁: 自旋锁与互斥锁的区别主要体现在以下几个方面: 1. 实现方式 互斥锁:属于sleep-waiting类型的锁。当一个线程尝试获取已被其他线程持有的互斥锁时,该线程会被阻塞(进入睡眠状态)ÿ…...

救生圈检测系统源码分享
救生圈检测检测系统源码分享 [一条龙教学YOLOV8标注好的数据集一键训练_70全套改进创新点发刊_Web前端展示] 1.研究背景与意义 项目参考AAAI Association for the Advancement of Artificial Intelligence 项目来源AACV Association for the Advancement of Computer Visio…...

BLE技术解析:物联网低功耗无线通信核心
1. BLE技术概述:物联网的无线连接基石蓝牙低功耗技术(Bluetooth Low Energy,简称BLE)自2010年作为蓝牙4.0核心规范的一部分推出以来,已成为物联网设备无线通信的事实标准。与经典蓝牙技术相比,BLE在保持相似…...

基于Ansible Playbook的Kubernetes集群自动化部署实践
1. 项目概述:一个为Kubernetes集群部署而生的自动化剧本如果你和我一样,长期在运维和DevOps一线摸爬滚打,那么对Kubernetes集群的初始化部署一定又爱又恨。爱的是它带来的强大编排能力,恨的是那套繁琐、易错、文档分散的kubeadm i…...

40_《智能体微服务架构企业级实战教程》智能助手主应用服务之工具类封装
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

终极指南:如何用WarcraftHelper彻底解决魔兽争霸3的现代系统兼容性问题
终极指南:如何用WarcraftHelper彻底解决魔兽争霸3的现代系统兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争…...

InjectFix实战:除了修Bug,如何在Unity里用它安全地‘新增’功能与属性?
InjectFix实战:突破Bug修复边界,安全扩展Unity功能 在Unity开发中,InjectFix作为热修复方案早已被开发者熟知,但大多数教程仅停留在修复Bug的基础用法上。当线上版本需要临时增加活动界面属性或工具函数时,重新打包发布…...
)
航模老鸟的‘省钱’秘籍:一块BB响如何守护你的多块锂电池(附设置误区避坑)
航模电池管理的低成本智慧:BB响的进阶使用策略 在航模和无人机领域,电池管理一直是玩家们关注的焦点。对于拥有多块电池的资深爱好者或小型工作室来说,如何在保证安全的前提下优化成本,是一个值得深入探讨的话题。传统做法是为每块…...

ArcGIS符号库“隐身”之谜:从DAO组件缺失到完整恢复的实战指南
1. 当符号选择器突然"罢工":一个GISer的崩溃瞬间 那天早上我正赶着完成客户的地图项目,准备给水系图层换个漂亮的蓝色符号。像往常一样双击图层打开属性窗口,点击Symbol Selector准备挑选样式时,整个人瞬间僵住了——本…...

MTCNN级联网络设计精讲:从P-Net到O-Net,看作者如何用‘奇数特征图’和‘重叠池化’提升召回率
MTCNN级联网络架构解密:奇数特征图与重叠池化的工程智慧 人脸检测领域的技术演进始终围绕着两个核心命题:如何在有限计算资源下实现实时检测,以及如何在小目标场景中保持高召回率。2016年问世的MTCNN(Multi-task Cascaded Convol…...

3步快速上手Thorium浏览器:新手也能掌握的完整性能优化指南
3步快速上手Thorium浏览器:新手也能掌握的完整性能优化指南 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards the top o…...

医疗电源设计:IEC 60601-1标准与EMC挑战解析
1. IEC 60601-1标准演进与医疗电源设计挑战医疗电气设备的安全性和可靠性直接关系到患者生命健康,这使得相关设计标准比普通电子设备严格得多。作为医疗设备领域的"圣经",IEC 60601-1标准自1977年首次发布以来,已经历四次重大修订&…...