Pandas 数据分析入门详解
今日内容大纲介绍
-
DataFrame读写文件
-
DataFrame加载部分数据
-
DataFrame分组聚合计算
-
DataFrame常用排序方式
1.DataFrame-保存数据到文件
-
格式
df对象.to_数据格式(路径) # 例如: df.to_csv('data/abc.csv') -
代码演示
如要保存的对象是计算的中间结果,或者以后会在Python中复用,推荐保存成pickle文件
如果保存成pickle文件,只能在python中使用, 文件的扩展名可以是
.p,.pkl,.pickl# output文件夹必须存在 df.to_pickle('output/scientists.pickle') # 保存为 pickle文件 df.to_csv('output/scientists.csv') # 保存为 csv文件 df.to_excel('output/scientists.xlsx') # 保存为 Excel文件 df.to_excel('output/scientists_noindex.xlsx', index=False) # 保存为 Excel文件 df.to_csv('output/scientists_noindex.csv', index=False) # 保存为 Excel文件 df.to_csv('output/scientists_noindex.tsv', index=False, sep='\t') print('保存成功') -
注意, pandas读写excel需要额外安装如下三个包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlwt pip install -i https://pypi.tuna.tsinghua.edu.cn/simple openpyxl pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlrd
2.DataFrame-读取文件数据
-
格式
pd对象.read_数据格式(路径) # 例如: pd.read_csv('data/movie.csv') -
代码演示
# pd.read_pickle('output/scientists.pickle') # 读取Pickle文件中的内容 # pd.read_excel('output/scientists.xlsx') # 多1个索引列 # pd.read_csv('output/scientists.csv') # 多1个索引列 pd.read_csv('output/scientists_noindex.csv') # 正常数据
3.DataFrame-数据分析入门
-
回顾
DataFrame和Series概念-
Pandas是用于数据分析的开源Python库,可以实现数据加载,清洗,转换,统计处理,可视化等功能
-
DataFrame和Series是Pandas最基本的两种数据结构
-
DataFrame用来处理结构化数据(SQL数据表,Excel表格)
-
Series用来处理单列数据,也可以把DataFrame看作由Series对象组成的字典或集合
-
-
按列加载数据
做数据分析首先要加载数据,并查看其结构和内容,对数据有初步的了解 查看行,列数据分布情况 查看每一列中存储信息的类型
import pandas as pd # 1. 加载数据 df = pd.read_csv('data/gapminder.tsv', sep='\t') # 指定切割符为\t df.head() # 2. # 查看df类型 type(df) df.shape # (1704, 6) df.columns # Index(['country', 'continent', 'year', 'lifeExp', 'pop', 'gdpPercap'], dtype='object') df.index # RangeIndex(start=0, stop=1704, step=1) df.dtypes # 查看df对象 每列的数据类型 df.info() # 查看df对象 详细信息 # 3. 加载一列数据 # country_series = df['country'] country_series = df.country # 效果同上 country_series.head() # 查看前5条数据 # 细节: 如果写 df['country'] 则是Series对象, 如果写 df[['country']]则是df对象 # 4. 加载多列数据 subset = df[['country', 'continent', 'year']] # df对象 print(subset.tail()) -
按行加载数据
# 1. 按行加载数据 df.head() # 获取前5条, 最左侧是一列行号, 也是 df的行索引, 即: Pandas默认使用行号作为 行索引. # 2. 使用 tail()方法, 获取最后一行数据 df.tail(n=1) # 3. 演示 iloc属性 和 loc属性的区别, loc属性写的是: 行索引值. iloc写的是行号. df.tail(n=1).loc[1703] df.tail(n=1).iloc[0] # 效果同上. # 4. loc属性 传入行索引, 来获取df的部分数据(一行, 或多行) df.loc[0] # 获取 行索引为 0的行 df.loc[99] # 获取 行索引为 99的行 df.loc[[0, 99, 999]] # loc属性, 根据行索引值, 获取多条数据. # 5. 获取最后一条数据 # df.loc[-1] # 报错 df.iloc[-1] # 正确 -
获取指定行/列数据
# 1. 获取指定 行|列 数据 df.loc[[0, 1, 2], ['country', 'year', 'lifeExp']] # 行索引, 列名 df.iloc[[0, 1, 2], [0, 2, 3]] # 行索引, 列的编号 # 2. 使用loc 获取所有行的, 某些列 df.loc[:, ['year', 'pop']] # 获取所有行的 year 和 pop列数据 # 3. 使用 iloc 获取所有行的, 某些列 df.iloc[:, [2, 3, -1]] # 获取所有行的, 索引为: 2, 3 以及 最后1列数据 # 4. loc只接收 行列名, iloc只接收行列序号, 搞反了, 会报错. # df.loc[:, [2, 3, -1]] # 报错 # df.iloc[:, ['country', 'continent']] # 报错 # 5. 也可以通过 range()生成序号, 结合 iloc 获取连续多列数据. df.iloc[:, range(1, 5, 2)] df.iloc[:, list(range(1, 5, 2))] # 把range()转成列表, 再传入, 也可以. # 6. 在iloc中, 使用切片语法 获取 n列数据. df.iloc[:, 3:5] # 获取列编号为 3 ~ 5 区间的数据, 包左不包右, 即: 只获取索引为3, 4列的数据. df.iloc[:, 0:6:2] # 获取列编号为 0 ~ 6 区间, 步长为2的数据, 即: 只获取索引为0, 2, 4列的数据. # 7. 使用loc 和 iloc 获取指定行, 指定列的数据. df.loc[42, 'country'] # 行索引为42, 列名为:country 的数据 df.iloc[42, 0] # 行号为42, 列编号为: 0 的数据 # 8. 获取多行多列 df.iloc[[0, 1, 2], [0, 2, 3]] # 行号, 列的编号 df.loc[2:6, ['country', 'lifeExp', 'gdpPercap']] # 行索引, 列名 推荐用法.
4.DataFrame-分组聚合计算
-
概述
-
在我们使用Excel或者SQL进行数据处理时,Excel和SQL都提供了基本的统计计算功能
-
当我们再次查看gapminder数据的时候,可以根据数据提出几个问题
-
每一年的平均预期寿命是多少?
-
每一年的平均人口和平均GDP是多少?
-
如果我们按照大洲来计算,每年个大洲的平均预期寿命,平均人口,平均GDP情况又如何?
-
在数据中,每个大洲列出了多少个国家和地区?
-
-
-
分组方式
-
对于上面提出的问题,需要进行分组-聚合计算
-
先将数据分组(每一年的平均预期寿命问题 按照年份将相同年份的数据分成一组)
-
对每组的数据再去进行统计计算如,求平均,求每组数据条目数(频数)等
-
再将每一组计算的结果合并起来
-
可以使用DataFrame的groupby方法完成分组/聚合计算
-
-
语法格式
df.groupby('分组字段')['要聚合的字段'].聚合函数() df.groupby(['分组字段','分组字段2'])[['要聚合的字段','要聚合的字段2']].聚合函数()分组后默认会把分组字段作为结果的行索引(index)
如果是多字段分组, 得到的是MultiIndex(复合索引), 此时可以通过reset_index() 把复合索引变成普通的列
例如: df.groupby(['year', 'continent'])[['lifeExp', 'gdpPercap']].mean().reset_index()
基本代码调用的过程
-
通过df.groupby('year')先创一个分组对象
-
从分组之后的数据DataFrameGroupBy中,传入列名进行进一步计算返回结果为一个 SeriesGroupBy ,其内容是分组后的数据
-
对分组后的数据计算平均值
-
-
代码演示
# 1. 统计每年, 平均预期寿命 # SQL写法: select year, avg(lifeExp) from 表名 group by year; df.groupby('year')['lifeExp'].mean() # 2. 上述代码, 拆解介绍. df.groupby('year') # 它是1个 DataFrameGroupBy df分组对象. df.groupby('year')['lifeExp'] # 从df分组对象中提取的 SeriesGroupBy Series分组对象(即: 分组后的数据) df.groupby('year')['lifeExp'].mean() # 对 Series分组对象(即: 分组后的数据), 具体求平均值的动作. # 3. 对多列值, 进行分组聚合操作. # 需求: 按照年, 大洲分组, 统计每年, 每个大洲的 平均预期寿命, 平均gdp df.groupby(['year', 'continent'])[['lifeExp', 'gdpPercap']].mean() # 4. 统计每个大洲, 列出了多少个国家和地区. df.groupby('continent')['country'].value_counts() # 频数计算, 即: 每个洲, 每个国家和地区 出现了多少次. df.groupby('continent')['country'].nunique() # 唯一值计数, 即: 每个大洲, 共有多少个国家和地区 参与统计.
5.Pandas-基本绘图
-
概述
-
可视化在数据分析的每个步骤中都非常重要
-
在理解或清理数据时,可视化有助于识别数据中的趋势
-
-
参考代码
data = df.groupby('year')['lifeExp'].mean() # Series对象 data.plot() # 默认绘制的是: 折线图. 更复杂的绘图, 后续详解.
6.Pandas-常用排序方法
-
第1步: 加载并查看数据
import pandas as pd # 1. 加载数据. movie = pd.read_csv('data/movie.csv') movie.head() # 2. 查看数据字段说明. movie.columns # 3. 查看数据行列数 movie.shape # (4916, 28) # 4. 统计数值列, 并进行转置. movie.describe() movie.describe().T # T表示转置操作, 即: 行列转换. # 5. 统计对象 和 类型列 movie.describe(include='all') # 统计所有的列, 包括: 数值列, 类别类型, 字符串类型 movie.describe(include=object) # 类别类型, 字符串类型 # 6. 通过info() 方法了解不同字段的条目数量,数据类型,是否缺失及内存占用情况 movie.info() -
第2步: 完整具体的需求
# 需求1: 找到小成本, 高口碑电影. # 即: 从最大的N个值中, 选取最小值. # 1. 加载数据. movie2 = movie[['movie_title', 'imdb_score', 'budget']] # 电影名, 电影评分, 成本(预算) # nlargest(): 获取某个字段取值最大的前n条数据. # nsmallest(): 获取某个字段取值最大的前n条数据. # 2. 用 nlargest()方法, 选出 imdb_score 分数最高的100个数据. movie2.nlargest(100, 'imdb_score') # 3. 用 smallest()方法, 从上述数据中, 挑出预算最小的 5步电影. movie2.nlargest(100, 'imdb_score').nsmallest(5, 'budget') # 需求2: 找到每年imdb评分最高的电影 # 1. 获取数据. movie3 = movie[['movie_title', 'title_year', 'imdb_score']] # 电影名, 上映年份, 电影评分 # 2. sort_values() 按照年排序. movie3.sort_values('title_year', ascending=False).head() # 按年降序排列, 查看数据. # 3. 同时对 title_year, imdb_score 两列进行排序. # movie4 = movie3.sort_values(['title_year', 'imdb_score'], ascending=[False, False]) movie4 = movie3.sort_values(['title_year', 'imdb_score'], ascending=False) # 效果同上 movie4.head() # 4. 用 drop_duplicates()去重, 只保留每年的第一条数据 # subset: 指定要考虑重复的列。 # keep: first/last/False 去重的时候, 保留第一条/保留最后一条/删除所有 movie4.drop_duplicates(subset='title_year').head()
相关文章:

Pandas 数据分析入门详解
今日内容大纲介绍 DataFrame读写文件 DataFrame加载部分数据 DataFrame分组聚合计算 DataFrame常用排序方式 1.DataFrame-保存数据到文件 格式 df对象.to_数据格式(路径) # 例如: df.to_csv(data/abc.csv) 代码演示 如要保存的对象是计算的中间结果,或者以…...

【网络】高级IO——epoll版本TCP服务器初阶
目录 前言 一,epoll的三个系统调用接口 1.1.epoll_create函数 1.1.1.epoll_create函数干了什么 1.2. epoll_ctl函数 1.2.1.epoll_ctl函数函数干了什么 1.3.epoll_wait函数 1.3.1.epoll_wait到底干了什么 1.4.epoll的工作过程中内核在干什么 二,…...

xml中的转义字符
文章目录 xml中的转义字符 xml中的转义字符 &对应的字符是& <对应的字符是< >对应的字符是> "对应的字符是" '对应的字符是转义的实体引用虽然简单易用,但是需要记忆,而且如果字符串中包含大量的特殊字…...

Webpack:现代前端项目的强大打包工具
在现代前端开发中,随着应用的复杂性不断提高,我们需要一种工具来管理项目的依赖、优化代码结构并打包资源文件。Webpack 就是这样一个强大的打包工具,它为前端开发者提供了灵活、强大且可扩展的功能。本文将介绍 Webpack 的基本概念、安装与使…...

以root用户登陆ubuntu的桌面环境
去我的个人博客观看,观感更佳哦,😙😙 前言 在学习Linux的时候,经常都需要使用sudo权限来对配置文件进行修改,常用的方法就是用vim编辑器在命令行界面进行修改,比如sudo vim /etc/profile&#…...

《系统架构设计师教程(第2版)》第17章-通信系统架构设计理论与实践-04-其他网络架构(存储网络架构、软件定义网络架构)
文章目录 1. 存储网络架构1.1 网络连接存储 (NAS)1.2 存储区域网络(SAN) 2. 软件定义网络架构2.1 软件定义网络(SDN)2.2 SDN架构2.3 相关技术2.3.1 控制平面技术2.3.2 数据平面技术1) 硬件处理方式4) 软件处…...
)
大话Python|基础语法(上)
一、单行注释 以下代码输出一个Hello World!字符串 在Python代码中,注释会自动被Python解析器忽略 print(Hello World) 二、多行注释 在Python代码中,注释一共有两种形式; 1、单行注释:注释的内容只有一行 2、多行…...

crosscrossover24支持的游戏有那些
CrossOver刚刚更新了24版本,支持《地平线零之曙光》、《以撒的结合:重生》等游戏。一起来看看它有哪些更新吧!之前买过23版的用户可以在1年之内免费升级哦,点击这里查看升级教程。 一、功能优化 - 更新 Wine 至最新的稳定版 Wine …...

如何免费调用GPT API进行自然语言处理
在当今这个信息爆炸的时代,自然语言处理(NLP)技术正逐步渗透到我们生活的各个方面,从智能客服到内容创作,无一不彰显着其强大的应用价值。而GPT(Generative Pre-trained Transformer)作为NLP领域…...

vue无感刷新Token并重新请求
vue 拦截器拦截401重新请求Token 无感刷新Token 之后重新请求报401的接口 instance.interceptors.response.use(async (response) > {let { data } response;if (data.code 401 || data.code 403) {return await handleExpiredToken(response.config);}if (data.code ! …...

C++和OpenGL实现3D游戏编程【连载10】——纹理的半透明显示
1、本节实现的内容 上一节课我们讲到了图片的镂空显示,它能在显示图片时去除指定颜色的背景,那么这节课我们来说一下图片的半透明显示效果,半透明效果能给画面带来更高质量的提升,使图片显示的更自然,产生更真实的效果。下面是一个气泡向上漂浮的效果。 气泡效果 2、非纹…...
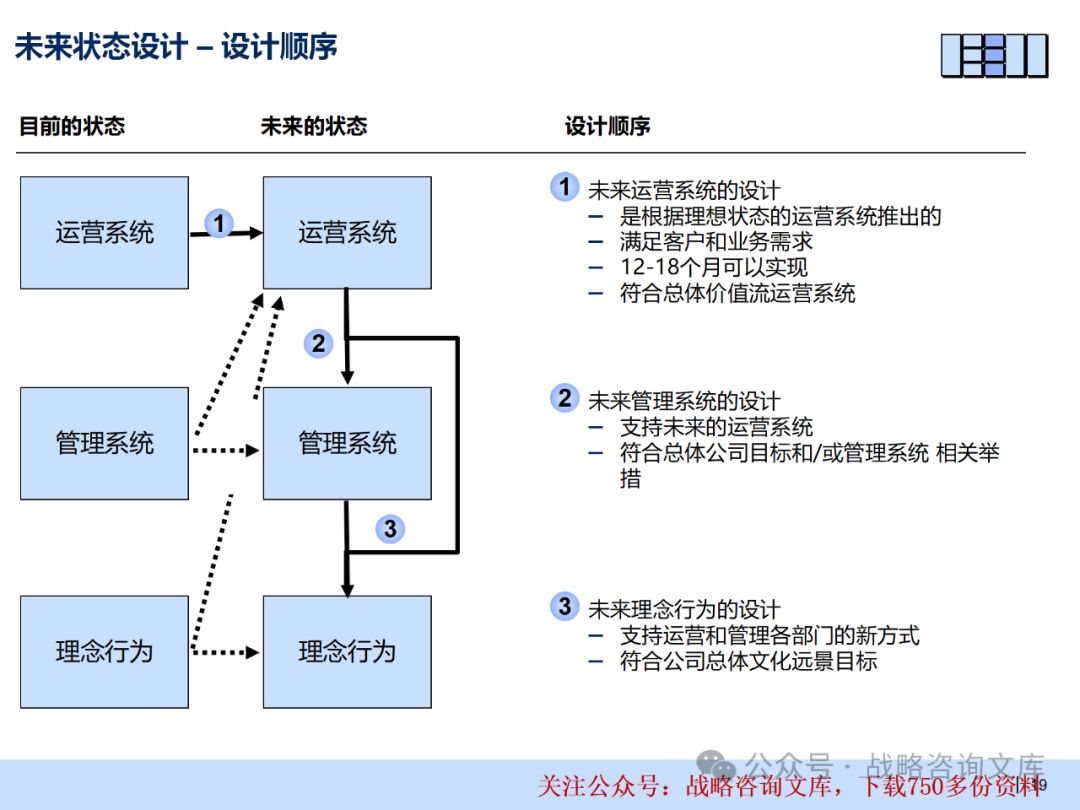
50页PPT麦肯锡精益运营转型五步法
读者朋友大家好,最近有会员朋友咨询晓雯,需要《 50页PPT麦肯锡精益运营转型五步法》资料,欢迎大家下载学习。 知识星球已上传的资料链接: 企业架构 企业架构 (EA) 设计咨询项目-企业架构治理(EAM)现状诊断 105页PPTHW企业架构设…...
Fyne ( go跨平台GUI )中文文档-小部件 (五)
本文档注意参考官网(developer.fyne.io/) 编写, 只保留基本用法 go代码展示为Go 1.16 及更高版本, ide为goland2021.2 这是一个系列文章: Fyne ( go跨平台GUI )中文文档-入门(一)-CSDN博客 Fyne ( go跨平台GUI )中文文档-Fyne总览(二)-CSDN博客 Fyne ( go跨平台GUI…...

GUI编程19:贪吃蛇小游戏及GUI总结
视频链接:21、贪吃蛇之界面绘制_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1DJ411B75F?p21&vd_sourceb5775c3a4ea16a5306db9c7c1c1486b5 1.游戏中用的的图片素材 1.贪吃蛇游戏的主启动类StartGame; package com.yundait.snake;import j…...

linux StarRocks 安装
一、检查服务器是否支持avx2,如果执行命令显示空,则不支持,那么安装后无法启动BE cat /proc/cpuinfo |grep avx2我的支持显示如下: 二、安装 docker run -p 9030:9030 -p 8030:8030 -p 8040:8040 -p 9001:9000 --privilegedtrue…...

解决RabbitMQ设置x-max-length队列最大长度后不进入死信队列
解决RabbitMQ设置x-max-length队列最大长度后不进入死信队列 问题发现问题解决方法一:只监听死信队列,在死信队列里面处理业务逻辑方法二:修改预取值 问题发现 最近再学习RabbitMQ过程中,看到关于死信队列内容: 来自队…...

【解决】chrome 谷歌浏览器,鼠标点击任何区域都是 Input 输入框的状态,能看到输入的光标
chrome 谷歌浏览器,鼠标点击任何区域都是 Input 输入框的状态,能看到输入的光标 今天打开电脑的时候,网页中任何文本的地方,只要鼠标点击,就会出现一个输入的光标,无论在哪个站点哪个页面都是如此。 我知道…...

使用python操作数据库
文章目录 一、问题背景二、安装python三、代码示例四、总结 一、问题背景 在日常开发过程中,随着项目进展和业务功能的迭代,我们需要对数据库的表结构进行修改,向部分表中追加字段,并对追加后的字段进行数据填充。但是如果需要追加…...

[Redis] 渐进式遍历+使用jedis操作Redis+使用Spring操作Redis
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

排序----数据结构
Comparable Integer Double 默认情况下都是按照升序排列的 string 按照字母再ASCII码表中对应的数字升序进行排列 冒泡排序 时间复杂度O(x^2) 选择排序 时间复杂度O(x^2) 插入排序 时间复杂度O(x^2) 希尔排序 时间复杂度O(x) 归并排序 时间复杂度O(nlogn) 快速排序...
)
Linux 文件隐藏属性 chattr、lsattr 详解——锁住文件防误删(运维必备)
前言很多人只知道 chmod、chown 改权限,却不知道 Linux 还有隐藏文件属性。普通权限能被 root 绕过,而 chattr 隐藏属性可以 锁住文件,root 也无法删除、修改,是服务器防护、防误删、保护配置文件的核心命令。一、命令简介lsattr&…...

如何用 polyfill-iconv 处理中文编码?GBK、BIG5、UTF-8 转换终极指南
如何用 polyfill-iconv 处理中文编码?GBK、BIG5、UTF-8 转换终极指南 【免费下载链接】polyfill-iconv This component provides a native PHP implementation of the php.net/iconv functions. 项目地址: https://gitcode.com/gh_mirrors/po/polyfill-iconv …...
Windows一键部署包v2.7.5|零代码+可视化操作)
OpenClaw(小龙虾AI)Windows一键部署包v2.7.5|零代码+可视化操作
适配系统:Windows10 64 位(纯小白友好版) 核心优势:免命令行、免环境配置、解压即装,内置所有运行依赖,全程可视化操作,新手也能一次成功部署 2026 爆火的开源 AI 智能体! 本文专属…...

【上篇】SenseNova-U1:基于NEO-unify架构统一多模态理解与生成
📣 更新动态 [2026.05.15] 发布 SenseNova-U1-8B-MoT-信息图表 📊,优化信息图表生成功能。详情请参阅 U1信息图表模型,并查看 ✨ 信息图表展示 获取100个生成示例。 ✨ 点击展开历史动态 [2026.05.10] 发布🔥SenseNo…...
](https://towardsdatascience.com/the-ultimate-guide-to-finding-outliers-in-yo)
[寻找时间序列数据中异常值终极指南(第三部分)](https://towardsdatascience.com/the-ultimate-guide-to-finding-outliers-in-yo
原文:towardsdatascience.com/the-ultimate-guide-to-finding-outliers-in-your-time-series-data-part-3-0ff73ce28ca3...

第11章:故障诊断与处理
第11章:故障诊断与处理 11.1 常见故障类型与原因 集群级故障 故障类型 症状 常见原因 集群Red 存在未分配的主分片 节点故障、磁盘满、分片损坏 集群Yellow 存在未分配的副本分片 节点不足、磁盘满、副本数过多 集群脑裂 多个Master节点 网络分区、Master配置错误 集群无响应…...

从零搭建 Geo 开源项目源码开发环境——以 GeoServer 为例
在地理信息(GIS)与空间数据服务开发中,Geo 系开源项目(如 GeoServer、GeoPandas、GeoDjango 等)非常常见。很多团队后期都会走到“读源码 / 改源码 / 二次开发”这一步,而第一步往往是:把源码跑…...

TV Bro:解锁智能电视上网的终极遥控器浏览器方案
TV Bro:解锁智能电视上网的终极遥控器浏览器方案 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 想象一下,坐在舒适的沙发上,手握电视…...

5步掌握DSEFix:Windows驱动签名的终极解决方案
5步掌握DSEFix:Windows驱动签名的终极解决方案 【免费下载链接】DSEFix Windows x64 Driver Signature Enforcement Overrider 项目地址: https://gitcode.com/gh_mirrors/ds/DSEFix DSEFix是一个专为Windows x64系统设计的驱动签名强制执行覆盖工具…...

微信单向好友检测:3分钟找出谁悄悄删了你
微信单向好友检测:3分钟找出谁悄悄删了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends 你是否曾经…...