C++ STL全面解析:六大核心组件之一----序列式容器(vector和List)(STL进阶学习)
目录
序列式容器
Vector
vector概述
vector的迭代器
vector的数据结构
vector的构造和内存管理
vector的元素操作
List
List概述
List的设计结构
List的迭代器
List的数据结构
List的内存构造
List的元素操作
C++标准模板库(STL)是一组高效的数据结构和算法的集合,广泛应用于C++程序设计中。STL由六大核心组件组成,分别是:
- 容器(Containers):各种数据结构,如vector,list,deque等等。
- 迭代器(Iterators):扮演容器域算法之间的胶合剂,是所谓的”泛型指针“
- 算法(Algorithms):各种常用算法,例如sort,search,copy,erase等等。
- 函数对象(Function Objects):又名为仿函数,行为类似函数,可作为算法的某种策略。
- 适配器(Adapters):一种用来修饰容器或者仿函数或迭代器接口的东西,例如:stack和queue。
- 分配器(Allocators):负责空间配置域管理,从实现角度来看他是一个管理空间的模板类。
STL六大组件的交互关系,容器通过分配器获取数据存储空间,算法则通过迭代器去存取容器的内容,(这也是为什么说迭代器是类似于一种胶合剂的角色),仿函数则可以协助算法完成不同的策略变化,适配器可以修饰或者套接仿函数。

在 C++ 中,STL(Standard Template Library,标准模板库)提供了一系列容器来帮助程序员组织和管理数据。常用的数据结构有:aray(数组)、list(链表)、tee(树)stack(堆栈)、queue(队列)、hashtable(散列表)、set(集合)、map(映射表)…等等。当提到STL时,许多人的第一印象便是容器,这也证明了容器的可靠性以及受欢迎程度。
STL 容器大致可以分为两类:序列式容器(Sequence Containers)和关联式容器(Associative Containers)。如其各自的名字一般,序列式就是按照顺序排列的容器。而关联式容器就是通过键值和键值对进行查找的。
常见的序列式容器包括:
- vector(向量):动态数组,支持随机访问,内部连续存储。
- list(链表):双向链表,不支持随机访问,插入和删除操作非常快。
- deque(双端队列):支持两端快速插入和删除的容器,支持随机访问。
- forward_list(单向链表):C++11 引入的新容器,单向链表,不支持随机访问。
常见的关联式容器包括:
- set(集合):存储唯一的键值,不允许重复,通常按照键的字典序排序。
- multiset(多重集合):类似 set,但允许键值重复。
- map(映射):存储键值对,键唯一,通常按照键的字典序排序。
- multimap(多重映射):类似 map,但允许键值重复。
序列式容器
Vector
vector概述
vector的数据结构跟array是非常相似的,只不过他们有一点不同,那就是array在定义时会被限制住大小,是静态的容量。而vector则是动态的容量,可以根据插入数据的数量去自动扩容容量。我们不必再去担心初始化数组的时候去定义一个大块头,使用vector时这个顾虑将烟消云散。
vector的实现技术关键在于对其大小的控制以及重新分配时数据迁移的效率,一旦vector的空间满载,如果客户端每新增一个元素,vector随之去增加一个元素这种效率肯定是很慢的。所以vector是采用的未雨绸缪机制。
vector的迭代器
vector维护的是一个连续线性空间,所以无论是什么类型的元素,普通指针都可以作为vector的迭代器而满足所有的必要条件。因为vector迭代器的操作指针都可以完成,无非就是加减乘除,加加,减减等操作。所以vector迭代器的定义正是普通指针。

vector的数据结构
vector的数据结构也是非常简单:线性连续空间。它以两个迭代器start和finish分别指向所分配空间的目前已使用范围的头和尾,其中end_of_storage则是用来指向分配空间的尾。

为了提高数据迁移时的效率,vector引入未雨绸缪的机制。这个机制就是vector实际配置的大小要比客户端需求的大小更大,以备将来的扩充,降低分配空间的次数。这个不难理解。
通过start,finish,end_of_storage三个迭代器,便可轻易的提供首位标示,大小,容量,空容器判断等。
下方是vector的整体示意图:

vector的构造和内存管理
我们围绕这个小测试程序说起。
// filename : vector-test.cpp
#include <vector>
#include <iostream>
#include <algorithm>using namespace std;int main() {int i;vector<int> iv(2, 9);cout << "size=" << iv.size() << endl; // size=2cout << "capacity=" << iv.capacity() << endl; // capacity=2iv.push_back(1);cout << "size=" << iv.size() << endl; // size=3cout << "capacity=" << iv.capacity() << endl; // capacity=4iv.push_back(2);cout << "size=" << iv.size() << endl; // size=4cout << "capacity=" << iv.capacity() << endl; // capacity=4iv.push_back(3); cout << "size=" << iv.size() << endl; // size=5cout << "capacity=" << iv.capacity() << endl; // capacity=8iv.push_back(4);cout << "size=" << iv.size() << endl; // size=6cout << "capacity=" << iv.capacity() << endl; // capacity=8for (i = 0; i < iv.size(); ++i)cout << iv[i] << ' '; // 9 9 1 2 3 4cout << endl;iv.push_back(5);cout << "size=" << iv.size() << endl; // size=7cout << "capacity=" << iv.capacity() << endl; // capacity=8for (i = 0; i < iv.size(); ++i)cout << iv[i] << ' '; // 9 9 1 2 3 4 5cout << endl;iv.pop_back();iv.pop_back();cout << "size=" << iv.size() << endl; // size=5cout << "capacity=" << iv.capacity() << endl; // capacity=8cout << endl;iv.pop_back();cout << "size=" << iv.size() << endl; // size=4cout << "capacity=" << iv.capacity() << endl; // capacity=8vector<int>::iterator ite = find(iv.begin(), iv.end(), 1);if (ite != iv.end())iv.erase(ite);cout << "size=" << iv.size() << endl; // size=3cout << "capacity=" << iv.capacity() << endl; // capacity=8for (i = 0; i < iv.size(); ++i)cout << iv[i] << ' '; // 9 9 2cout << endl;ite = find(iv.begin(), iv.end(), 2);if (ite != iv.end())iv.insert(ite, 3, 7);cout << "size=" << iv.size() << endl; // size=6cout << "capacity=" << iv.capacity() << endl; // capacity=8for (int i = 0; i < iv.size(); ++i)cout << iv[i] << ' '; // 9 9 7 7 7 2cout << endl;iv.clear();cout << "size=" << iv.size() << endl; // size=0cout << "capacity=" << iv.capacity() << endl; // capacity=8return 0;
}从这段小的测试例子来看我们不难发现vector的分配空间的机制正如我们所了解的一样,它在扩容时会进行更大量级的扩容,又是双倍扩容。vector缺省使用alloc作为空间配置器,并据此定义了一个data_allocator,为的是方便以元素大小为配置单位。
 当我们使用push_back将新元素插入尾部时,该函数首先会去检测是否还有备用空间,如果有就不扩容,在备用空间上进行构造,并调整finish,如果没有就回去调用insert_aux扩容空间,重新配置,移动数据,释放空间。
当我们使用push_back将新元素插入尾部时,该函数首先会去检测是否还有备用空间,如果有就不扩容,在备用空间上进行构造,并调整finish,如果没有就回去调用insert_aux扩容空间,重新配置,移动数据,释放空间。

template <class T, class Alloc>
void vector<T, Alloc>::insert_aux(iterator position, const T& x) {if (finish != end_of_storage) { // 还有备用空间// 在备用空间起始处构造一个元素,并以vector最后一个元素值为其初值construct(&*finish, *finish-1);++finish;// 复制待插入的元素值T x_copy = x;// 将 [position, finish-1) 区间的元素向后移动一位copy_backward(position, finish-1, finish);*position = x_copy;} else { // 已无备用空间const size_type old_size = size(); // 记录旧的大小const size_type len = (old_size != 0 ? 2 * old_size : 1); // 新大小:如果原大小为0,则配置1;否则配置原大小的两倍// 分配新的内存空间iterator new_start = data_allocator::allocate(len);iterator new_finish = new_start;try {// 将原 vector 的内容拷贝到新 vectornew_finish = uninitialized_copy(start, position, new_start);// 为新元素设定初值 xconstruct(&*new_finish, x);++new_finish;// 将原 vector 的备用空间中的内容也忠实复制过来new_finish = uninitialized_copy(position, finish, new_finish);} catch (...) {// 如果出现异常,销毁新分配的内存并释放destroy(new_start, new_finish);data_allocator::deallocate(new_start, len);throw;}// 析构并释放原 vectordestroy(begin(), end());deallocate();// 调整迭代器,指向新 vectorstart = new_start;finish = new_finish;end_of_storage = new_start + len;}
}这里还需提一嘴,所谓的动态增加大小并非是像链表一般直接在后方增加新的扩容空间,因为vector的本质还是数组,所以它增加大小的方式和数组是相同的,大家不要误解。因此,一旦引起空间重新配置,那么原来vector的迭代器都将失效,切记。
vector的元素操作
这里我不再多说,大家可以参考我之前学习vector操作时的一篇文章。
C++基础知识(八:STL标准库(Vectors和list))_c++ stl标准库-CSDN博客![]() https://blog.csdn.net/LKHzzzzz/article/details/136316825
https://blog.csdn.net/LKHzzzzz/article/details/136316825
List
List概述
相对于vector,list则显得更为复杂一下。但是list本身的优势也是vector没有的。例如插入一个元素就会配置一个元素空间,这就做到了对空间运用的绝对精准,同时这也是许多大型项目中经常用到的一种数据结构,例有Linux内核,其中对list的运用更是出神入化,不得不感叹大神的智慧。但是vector和list各有各的优势,还需要取决于在什么场景下用那个数据结构。
List的设计结构
list的本身和list的节点是不同的结构,需要分开进行设计,以下是一个双向链表的节点机构。

List的迭代器
List的迭代器不能再像vector一般用一个普通指针作为迭代器,因为list的节点不是连续存在的,所以list迭代器必须要有能力指向list的节点,并可以进行++,--,等操作。这里我们可以看出来list是一个双向列表,那么我们的迭代器也就必须具备前移和后退的能力。
注:list的迭代器在析构这个list之前都是有效的!与vector并不相同!

以下是list的迭代器结构
template <typename T, typename Ref, typename Ptr>
struct list_iterator {typedef list_iterator<T, T&, T*> Self; // 自定义类型别名typedef bidirectional_iterator_tag iterator_category; // 迭代器类别typedef T value_type; // 值类型typedef Ptr pointer; // 指针类型typedef Ref reference; // 引用类型typedef std::list<T>::node* link_type; // 节点类型typedef std::size_t size_type; // 大小类型typedef std::ptrdiff_t difference_type; // 差值类型private:link_type node; // 迭代器内部的指针,指向 list 的节点public:// 构造函数list_iterator(link_type x) : node(x) {}list_iterator() : node(nullptr) {} // 默认构造函数list_iterator(const Self& x) : node(x.node) {} // 拷贝构造函数// 比较运算符bool operator==(const Self& x) const { return node == x.node; }bool operator!=(const Self& x) const { return node != x.node; }// 解引用运算符reference operator*() const { return (*node).data; }// 成员访问运算符pointer operator->() const { return &(*this->operator*()); }// 前缀递增运算符Self& operator++() {node = link_type((*node).next);return *this;}// 后缀递增运算符Self operator++(int) {Self tmp = *this;++(*this);return tmp;}// 前缀递减运算符Self& operator--() {node = link_type((*node).prev);return *this;}// 后缀递减运算符Self operator--(int) {Self tmp = *this;--(*this);return tmp;}
};List的数据结构
List不仅仅是一个双向链表,而且还是一个环状双向链表。所以它只需要一个指针便可以完整表现整个链表。


List的内存构造
让我们先从一段小的测试例子看起
#include <list>
#include <iostream>
#include <algorithm>using namespace std;int main() {int i;list<int> ilist;cout << "size=" << ilist.size() << endl; // size=0ilist.push_back(0);ilist.push_back(1);ilist.push_back(2);ilist.push_back(3);ilist.push_back(4);cout << "size=" << ilist.size() << endl; // size=5list<int>::iterator ite;for (ite = ilist.begin(); ite != ilist.end(); ++ite) {cout << *ite << " ";}cout << endl; // 输出 0 1 2 3 4cout << endl;ite = find(ilist.begin(), ilist.end(), 3);if (ite != ilist.end()) {ilist.insert(ite, 99);}cout << "size=" << ilist.size() << endl; // size=6cout << *ite << endl; // 输出 99for (ite = ilist.begin(); ite != ilist.end(); ++ite) {cout << *ite << " ";}cout << endl; // 输出 0 1 2 99 3 4cout << endl;ite = find(ilist.begin(), ilist.end(), 1);if (ite != ilist.end()) {cout << *(ilist.erase(ite)) << endl; // 输出 2}for (ite = ilist.begin(); ite != ilist.end(); ++ite) {cout << *ite << " ";}cout << endl; // 输出 0 2 99 3 4cout << endl;return 0;
}当我们以push_back()插入元素的时候他的底层调用的其实是Insert函数,
void push_back(const T& x){insert(end(),x);insert()是一个重载函数,有多种形式,但是在list中用的就是最简单一步操作,也就是单纯的去插入一个元素:首先构造一个元素空间,然后在尾部进行一系列的操作,把新元素插入进去。
list_node<T> *insert(list_node<T> *position, const T &x)
{list_node<T> *tmp = create_node(x); // 产生一个节点,内容为 x// 调整双向指针,使 tmp 插入进去tmp->next = position;tmp->prev = position->prev;// 更新前后节点的指针(static_cast<list_node<T> *>(position->prev))->next = tmp;position->prev = tmp;return tmp;
}插入之后的list状态也就如下图一般。由于list不像vector一般会在扩容时重新分配空间,然后转移过去,然后析构,因此list的迭代器是一直有效的。

List的元素操作
这里大家可以去看一下我之前写的一篇基本操作文章关于List的,这里就不多说了。
C++基础知识(八:STL标准库(Vectors和list))_c++ stl标准库-CSDN博客![]() https://blog.csdn.net/LKHzzzzz/article/details/136316825
https://blog.csdn.net/LKHzzzzz/article/details/136316825
相关文章:
C++ STL全面解析:六大核心组件之一----序列式容器(vector和List)(STL进阶学习)
目录 序列式容器 Vector vector概述 vector的迭代器 vector的数据结构 vector的构造和内存管理 vector的元素操作 List List概述 List的设计结构 List的迭代器 List的数据结构 List的内存构造 List的元素操作 C标准模板库(STL)是一组高效的…...

【c数据结构】OJ练习篇 帮你更深层次理解链表!(相交链表、相交链表、环形链表、环形链表之寻找环形入口点、判断链表是否是回文结构、 随机链表的复制)
目录 一. 相交链表 二. 环形链表 三. 环形链表之寻找环形入口点 四. 判断链表是否是回文结构 五. 随机链表的复制 一. 相交链表 最简单粗暴的思路,遍历两个链表,分别寻找是否有相同的对应的结点。 我们对两个链表的每个对应的节点进行判断比较&…...
)
微软开源GraphRAG的使用教程(最全,非常详细)
GraphRAG的介绍 目前微软已经开源了GraphRAG的完整项目代码。对于某一些LLM的下游任务则可以使用GraphRAG去增强自己业务的RAG的表现。项目给出了两种使用方式: 在打包好的项目状态下运行,可进行尝试使用。在源码基础上运行,适合为了下游任…...
初始化项目)
使用Refine构建项目(1)初始化项目
要初始化一个空的Refine项目,你可以使用Refine提供的CLI工具create-refine-app。以下是初始化步骤: 使用npx命令: 在命令行中运行以下命令来创建一个新的Refine项目: npx create-refine-applatest my-refine-project这将引导你通过…...

【Docker】安装及使用
1. 安装Docker Desktop Docker Desktop是官方提供的桌面版Docker客户端,在Mac上使用Docker需要安装这个工具。 访问 Docker官方页面 并下载Docker Desktop for Mac。打开下载的.dmg文件,并拖动Docker图标到应用程序文件夹。安装完成后,打开…...

[大语言模型-论文精读] 以《黑神话:悟空》为研究案例探讨VLMs能否玩动作角色扮演游戏?
1. 论文简介 论文《Can VLMs Play Action Role-Playing Games? Take Black Myth Wukong as a Study Case》是阿里巴巴集团的Peng Chen、Pi Bu、Jun Song和Yuan Gao,在2024.09.19提交到arXiv上的研究论文。 论文: https://arxiv.org/abs/2409.12889代码和数据: h…...

提升动态数据查询效率:应对数据库成为性能瓶颈的优化方案
引言 在现代软件系统中,数据库性能是决定整个系统响应速度和处理能力的关键因素之一。然而,当系统负载增加,特别是在高并发、大数据量场景下,数据库性能往往会成为瓶颈,导致查询响应时间延长,影响用户体验…...

Prometheus+grafana+kafka_exporter监控kafka运行情况
使用Prometheus、Grafana和kafka_exporter来监控Kafka的运行情况是一种常见且有效的方案。以下是详细的步骤和说明: 1. 部署kafka_exporter 步骤: 从GitHub下载kafka_exporter的最新版本:kafka_exporter项目地址(注意ÿ…...

在vue中:style 的几种使用方式
在日常开发中:style的使用也是比较常见的: 亲测有效 1.最通用的写法 <p :style"{fontFamily:arr.conFontFamily,color:arr.conFontColor,backgroundColor:arr.conBgColor}">{{con.title}}</p> 2.三元表达式 <a :style"{height:…...

商城小程序后端开发实践中出现的问题及其解决方法
前言 商城小程序后端开发中,开发者可能会面临多种问题。以下是一些常见的问题及其解决方法: 一、性能优化 问题:随着用户量的增加和功能的扩展,商城小程序可能会出现响应速度慢、处理效率低的问题。 解决方法: 对数…...

阿里Arthas-Java诊断工具,基本操作和命令使用
Arthas 是阿里巴巴开源的一款Java诊断工具,深受开发者喜爱。它可以帮助开发者在不需要修改代码的情况下,对运行中的Java程序进行问题诊断和性能分析。 软件具体使用方法 1 启动 Arthas,此时可能会出现好几个jvm的进程号,输入序号…...

Go 1.19.4 路径和目录-Day 15
1. 路径介绍 存储设备保存着数据,但是得有一种方便的模式让用户可以定位资源位置,操作系统采用一种路径字符 串的表达方式,这是一棵倒置的层级目录树,从根开始。 相对路径:不是以根目录开始的路径,例如 a/b…...

jEasyUI 创建标签页
jEasyUI 创建标签页 jEasyUI(jQuery EasyUI)是一个基于jQuery的框架,它为Web应用程序提供了丰富的用户界面组件。标签页(Tabs)是jEasyUI中的一个常用组件,用于在一个页面内组织多个面板,用户可…...

鸿蒙HarmonyOS开发:一次开发,多端部署(界面级)天气应用案例
文章目录 一、布局简介二、典型布局场景三、侧边栏 SideBarContainer1、子组件2、属性3、事件 四、案例 天气应用1、UX设计2、实现分析3、主页整体实现4、具体代码 五、运行效果 一、布局简介 布局可以分为自适应布局和响应式布局,二者的介绍如下表所示。 名称简介…...

使用 Python 模拟光的折射,反射,和全反射
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

大厂太卷了!又一款国产AI视频工具上线了,免费无限使用!(附提示词宝典)
大家好,我是程序员X小鹿,前互联网大厂程序员,自由职业2年,也一名 AIGC 爱好者,持续分享更多前沿的「AI 工具」和「AI副业玩法」,欢迎一起交流~ 记得去年刚开始分享 AI 视频工具的时候,介绍的大多…...

vue3扩展echart封装为组件库-快速复用
ECharts ECharts,全称Enterprise Charts,是一款由百度团队开发并开源,后捐赠给Apache基金会的纯JavaScript图表库。它提供了直观、生动、可交互、可个性化定制的数据可视化图表,广泛应用于数据分析、商业智能、网页开发等领域。以…...

随机掉落的项目足迹:Vue3 + wangEditor5富文本编辑器——toolbar.getConfig() 查看工具栏的默认配置
问题引入 小提示:问题引入是一个讲故事的废话环节,各位小伙伴可以直接跳到第二大点:问题解决 我的项目不需要在富文本编辑器中引入添加代码块的功能,于是我寻思在工具栏上把操作代码的菜单删一删 于是我来到官网文档工具栏配置 …...

更新 Git 软件
更新 Git 软件本身是指将你当前安装的 Git 版本升级到最新版本。不同的操作系统有不同的更新方法。以下是针对 Windows、macOS 和 Linux 的 Git 更新步骤: Windows 检查当前版本: git --version访问官网下载最新版本: 访问 Git 官方网站 (ht…...
Keil根据map文件确定单片机代码存储占用flash情况
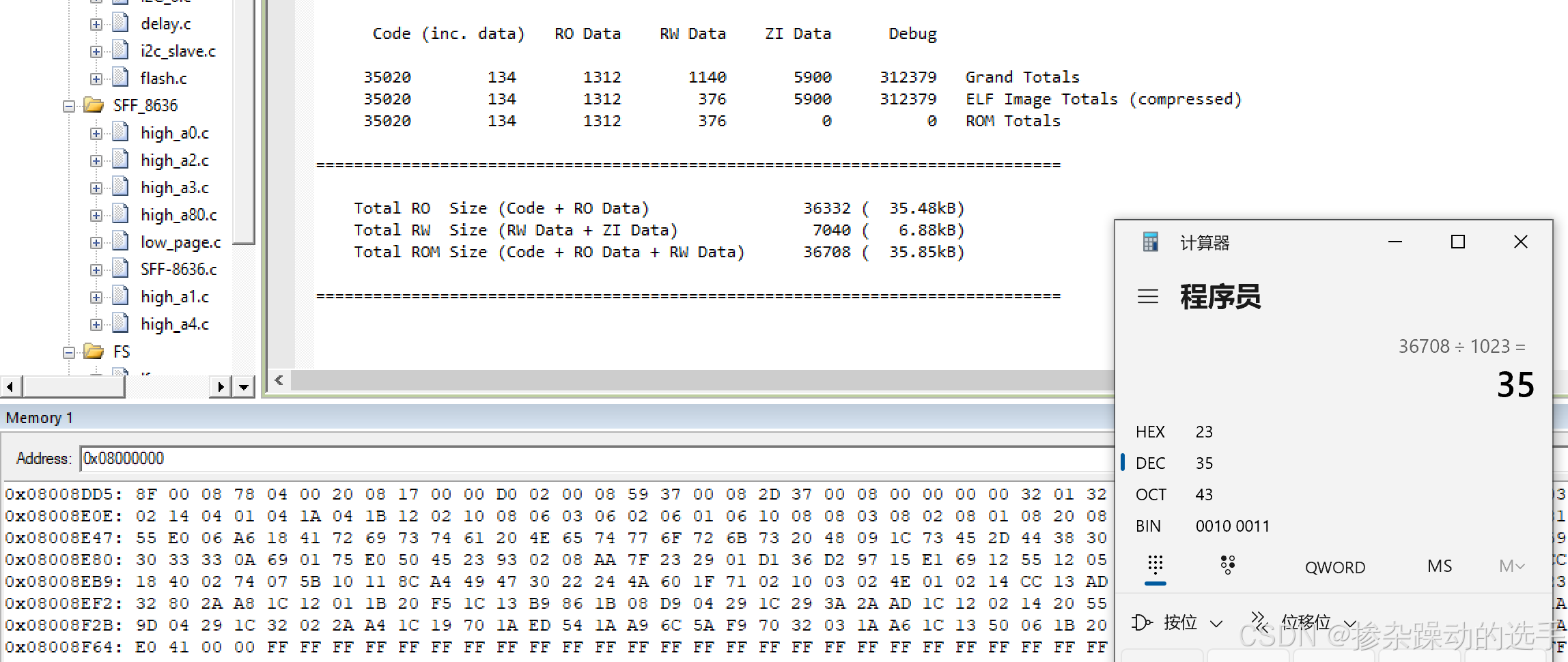
可以从map文件中查看得知,代码占用内存情况大概为35KB,而在在线仿真时,可以看到在flash的0x8008F64地址前均有数据,是代码数据,8F64(HEX)36708(DEC),36708/102335,刚好35。因此,要想操作读写flash,必须在不…...

从AT24C02 EEPROM的I2C时序出发,手把手调试你的蓝桥杯单片机存储模块
从AT24C02 EEPROM的I2C时序出发,手把手调试你的蓝桥杯单片机存储模块 在蓝桥杯单片机竞赛中,AT24C02 EEPROM存储模块的稳定读写是基本功,但真正的高手往往能在底层通信协议层面发现问题、解决问题。本文将带你从I2C时序的微观视角,…...

CANN/asc-devkit float2到half2向上取整转换函数
__float22half2_ru 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitc…...

Tunasync调度器工作原理:智能任务分配与并发控制完全指南
Tunasync调度器工作原理:智能任务分配与并发控制完全指南 【免费下载链接】tunasync Mirror job management tool. 项目地址: https://gitcode.com/gh_mirrors/tu/tunasync Tunasync调度器是开源镜像同步工具的核心组件,负责智能任务分配与并发控…...

杰理微蓝牙芯片AC696系列入门
1.文章背景 此篇文章以ac696n_soundbox_sdk_v1.7.0版本进行入门讲解: 写这篇文章的目的是因为自己在尝试入门杰理微的时候遇到了好多的问题点,想尝试用买到的开发板来驱动一颗LED闪烁却一直没有按自己想象的逻辑成功跑出效果,在网上到处翻找手…...

一条 SQL 干掉 8 秒卡顿,只因改了一个索引
一条 SQL 干掉 8 秒卡顿,只因改了一个索引 上周五晚上十一点,线上告警突然炸了,用户反馈下单接口卡成 PPT。打开慢查询日志一看,一条最普通的订单查询 SQL 居然跑了 8 秒多。当时我脑子里只有一个念头:这条 SQL 我上周才写的,测试环境明明只要 200 毫秒啊。排查了一整晚,…...

你的RAR5密码有多安全?我用hashcat掩码攻击实测了一下
RAR5密码安全实测:从暴力破解到防御策略 当你在深夜赶工,把重要文件打包成加密压缩包发送给同事时,是否想过这个密码能撑多久?上周我给自己设置了一个看似安全的8位数字密码,结果在咖啡还没凉透前就被破解了。这不是危…...
)
用Field II和MATLAB搞定超声波声场仿真:从理论推导到代码实战(附源码)
用Field II和MATLAB搞定超声波声场仿真:从理论推导到代码实战(附源码) 在医学超声成像和无损检测领域,精确模拟声场分布是优化成像质量的关键环节。Field II作为业界公认的超声波仿真工具,其强大的计算能力背后隐藏着大…...

Android Studio中文插件终极指南:3分钟实现完整汉化体验
Android Studio中文插件终极指南:3分钟实现完整汉化体验 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Androi…...

CSP认证202305-1题保姆级攻略:用C++的map轻松搞定国际象棋局面去重
CSP认证202305-1题深度解析:从字符串处理到STL高效去重 国际象棋对局中的局面重复判定是一个经典的字符串处理问题,也是CSP认证考试中常见的题型。这道题看似简单,却蕴含了算法选择与数据结构应用的核心思想。本文将带您从题目分析、解法对比…...

如何用AI语音修复工具VoiceFixer拯救你的受损录音:终极指南
如何用AI语音修复工具VoiceFixer拯救你的受损录音:终极指南 【免费下载链接】voicefixer General Speech Restoration 项目地址: https://gitcode.com/gh_mirrors/vo/voicefixer 还在为那些珍贵的录音因为各种原因变得模糊不清而烦恼吗?VoiceFixe…...