手写数字识别案例分析(torch,深度学习入门)
在人工智能和机器学习的广阔领域中,手写数字识别是一个经典的入门级问题,它不仅能够帮助我们理解深度学习的基本原理,还能作为实践编程和模型训练的良好起点。本文将带您踏上手写数字识别的深度学习之旅,从数据集介绍、模型构建到训练与评估,一步步深入探索。
一、引言
手写数字识别(Handwritten Digit Recognition)是指通过计算机程序自动识别手写数字的过程。最著名的手写数字数据集之一是MNIST(Modified National Institute of Standards and Technology database),它包含了大量的手写数字图片,每张图片都被标记了对应的数字(0-9)。这个数据集成为了初学者学习深度学习,尤其是卷积神经网络(CNN)的首选。
二、MNIST数据集简介
MNIST数据集由60,000个训练样本和10,000个测试样本组成,每个样本都是一张28x28像素的灰度图像,代表了一个手写数字。这些图像已经被归一化并居中在图像中心,使得数字不会受到位置变化的影响。
PyTorch 和 torchvision 库来下载并准备 MNIST 数据集,包括训练集和测试集
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor'''下载训练数据集(图片+标签)'''
training_data = datasets.MNIST(root="data",train=True,download=True,transform=ToTensor()
)
test_data = datasets.MNIST(root="data",train=False,download=True,transform=ToTensor()
)
-
打印设备信息:您的代码已经很好地检查了CUDA和MPS(针对Apple M系列芯片)的可用性,并设置了相应的设备。但是,在打印设备信息时,有一个小错误在字符串格式化上。您需要确保在字符串中正确地包含变量名。
-
打印数据形状:您已经正确地设置了
DataLoader并打印了测试数据集中的一个批次的数据和标签的形状。这是一个很好的实践,可以帮助您了解数据的维度。
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) # 通常训练时会打乱数据
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=False) # 测试时不需要打乱数据 # 打印测试数据集的一个批次的数据和标签的形状
for x, y in test_dataloader: print(f"Shape of x [N,C,H,W]: {x.shape}") # 注意这里的x是图像,但MNIST是灰度图,所以C=1 print(f"Shape of y: {y.shape}, {y.dtype}") # y是标签,通常是一维的,且为long类型 break # 判断当前设备是否支持GPU,其中mps是苹果m系列芯片的GPU
device = "cuda" if torch.cuda.is_available() else ('mps' if torch.backends.mps.is_available() else "cpu")
print(f"Using {device} device") # 确保在字符串中正确地包含了变量名 三、训练模型选择
一、创建一个具有多个隐藏层的神经网络,这些层都使用了nn.Linear来定义全连接层,并使用torch.sigmoid作为激活函数。
import torch
import torch.nn as nn class NeuralNetwork(nn.Module): def __init__(self): super().__init__() self.flatten = nn.Flatten() self.hidden1 = nn.Linear(28 * 28, 256) self.relu1 = nn.ReLU() self.hidden2 = nn.Linear(256, 128) self.relu2 = nn.ReLU() self.hidden3 = nn.Linear(128, 64) self.relu3 = nn.ReLU() self.hidden4 = nn.Linear(64, 32) self.relu4 = nn.ReLU() self.out = nn.Linear(32, 10) # 输出层对应于10个类别的得分 def forward(self, x):x = self.flatten(x)x = self.hidden1(x)x = torch.sigmoid(x)x = self.hidden2(x)x = torch.sigmoid(x)x = self.hidden3(x)x = torch.sigmoid(x)x = self.hidden4(x)x = torch.sigmoid(x)x = self.out(x)return x model = NeuralNetwork().to(device)
print(model) 二、定义了一个具有三个卷积层的CNN,每个卷积层后面都跟着ReLU激活函数,前两个卷积层后面还跟着最大池化层。最后,通过一个全连接层将卷积层的输出转换为10个类别的得分。
import torch
import torch.nn as nn class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.conv1 = nn.Sequential( nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=2), ) self.conv2 = nn.Sequential( nn.Conv2d(16, 32, 5, 1, 2), nn.ReLU(), nn.Conv2d(32, 32, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(2), ) self.conv3 = nn.Sequential( nn.Conv2d(32, 64, 5, 1, 2), nn.ReLU(), ) self.out = nn.Linear(64 * 7 * 7, 10) # 确保这里的输入特征数与卷积层输出后的特征数相匹配 def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = self.conv3(x) # 输出应为(batch_size, 64, 7, 7) x = x.view(x.size(0), -1) # 展平操作,输出为(batch_size, 64*7*7) output = self.out(x) return output model = CNN().to(device)
print(model)-
in_channels=1:这指定了输入图像的通道数。 -
out_channels=16:这指定了卷积操作后输出的通道数,也就是卷积核(或称为滤波器)的数量。 -
kernel_size=5:这定义了卷积核的大小。 -
stride=1:这指定了卷积核在输入数据上滑动的步长。 -
padding=2:这定义了要在输入数据周围添加的零填充(zero-padding)的数量。
四、处理数据集和测试集
训练集处理:
def train(dataloader, model, loss_fn, optimizer): model.train() # 将模型设置为训练模式 batch_size_num = 1 # 这不是标准的用法,但在这里用作计数已处理批次的数量 for x, y in dataloader: # 遍历数据加载器中的每个批次 x, y = x.to(device), y.to(device) # 将数据和标签移动到指定的设备(如GPU) pred = model(x) # 通过模型进行前向传播 loss = loss_fn(pred, y) # 计算预测和真实标签之间的损失 optimizer.zero_grad() # 清除之前的梯度 loss.backward() # 反向传播,计算当前梯度 optimizer.step() # 更新模型的权重 loss_value = loss.item()if batch_size_num % 200 == 0:print(f"{loss_value:>7f}[number:{batch_size_num}]")#打印结果batch_size_num += 1 # 增加已处理批次的数量测试集处理:
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for x, y in dataloader:x, y = x.to(device), y.to(device)pred = model(x)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()a = (pred.argmax(1) == y)b = (pred.argmax(1) == y).type(torch.float)test_loss /= num_batchescorrect /= sizeprint(f'Test result: \n Accuracy: {(100 * correct)}%, Avg loss: {test_loss}')
模型训练:
loss_fn = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)epochs = 10
for t in range(epochs):print(f"-----------------------------------------------\nepcho{t+1}")train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
test(test_dataloader, model, loss_fn)train(train_dataloader,model,loss_fn,optimizer)
test(test_dataloader,model, loss_fn)
结果:
神经网络:

cnn:

相关文章:
手写数字识别案例分析(torch,深度学习入门)
在人工智能和机器学习的广阔领域中,手写数字识别是一个经典的入门级问题,它不仅能够帮助我们理解深度学习的基本原理,还能作为实践编程和模型训练的良好起点。本文将带您踏上手写数字识别的深度学习之旅,从数据集介绍、模型构建到…...

应用密码学第一次作业(9.23)
一、Please briefly describe the objectives of information and network security,such as confidentiality, integrity, availability , authenticity , and accountability The objectives of information and network security include: Confidentiality: Protecting se…...

JSON合并工具
JSON合并工具 1. 项目概述 本项目旨在开发一个强大而灵活的JSON合并工具,能够合并多个JSON文件,处理复杂的嵌套结构,提供详细的合并报告,并实现全面的验证和错误处理机制。 2. 功能需求 2.1 基本合并功能 支持合并两个或多个…...

【网络编程】网页的显示过程
文章目录 1.URL 解析2.DNS 解析3.TCP三次握手4.服务器接收请求5.客户端接收响应 首先我们知道网页经过网络总共有应用层,传输层,网络层,数据链路层,物理层 1.URL 解析 将获得的网址解析出协议,主机名,域名…...

用nginx-rtmp-win32-master及ffmpeg模拟rtmp视频流
效果 使用nginx-rtmp-win32-master搭建RTMP服务 双击exe就可以了。切记整个目录不能有中文 README.md ,启用后本地的RTM路径: rtmp://192.168.1.186/live/xxx ffmpeg将地本地视频推RMTP F:\rtsp\ffmpeg-7.0.2-essentials_build\bin>ffmpeg -re -i F:\rtsp\123.mp4 -c c…...

使用python-pptx将PPT转换为图片:将每张幻灯片保存为单独的图片文件
哈喽,大家好,我是木头左! 本文将详细介绍如何使用python-pptx将PPT的每一张幻灯片保存为单独的图片文件。 安装python-pptx库 需要确保已经安装了python-pptx库。可以通过以下命令使用pip进行安装: pip install python-pptx导入所需库 接下来,需要导入一些必要的库,包…...

聊聊企业的低代码实践背景与成效
数字化转型的道路充满挑战是大家的普遍共识,许多企业仍未完全步入数字化的行列,它们面临的是系统的碎片化和操作的复杂性。在数字优先的今天,企业要想维持竞争力,比任何时期都更需要实施某种程度的数字化升级。如果一个组织难以提…...

zookeeper面试题
1. 什么是zookeeper zookeeper是一个开源的 分布式协调服务。他是一个为分布式应用提供一致性服务的软件,分布式应用程序可以基于Zookeeper实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能。 Zooke…...

Linux学习笔记13---GPIO 中断实验
中断系统是一个处理器重要的组成部分,中断系统极大的提高了 CPU 的执行效率,本章会将 I.MX6U 的一个 IO 作为输入中断,借此来讲解如何对 I.MX6U 的中断系统进行编程。 GIC 控制器简介 1、GIC 控制器总览 I.MX6U(Cortex-A)的中断控制器…...

[Redis][Hash]详细讲解
目录 0.前言1.常见命令1.HSET2.HGET3.HEXISTS4.HDEL5.HKEYS6.HVALS7.HGETALL8.HMGET9.HLEN10.HSETNX11.HINCRBY12.HINCRBYFLOAT 2.内部编码1.ziplist(压缩链表)2.hashtable(哈希表) 3.使用场景4.缓存方式对比1.原⽣字符串类型2.序列化字符串类型3.哈希类型 0.前言 在Redis中&am…...
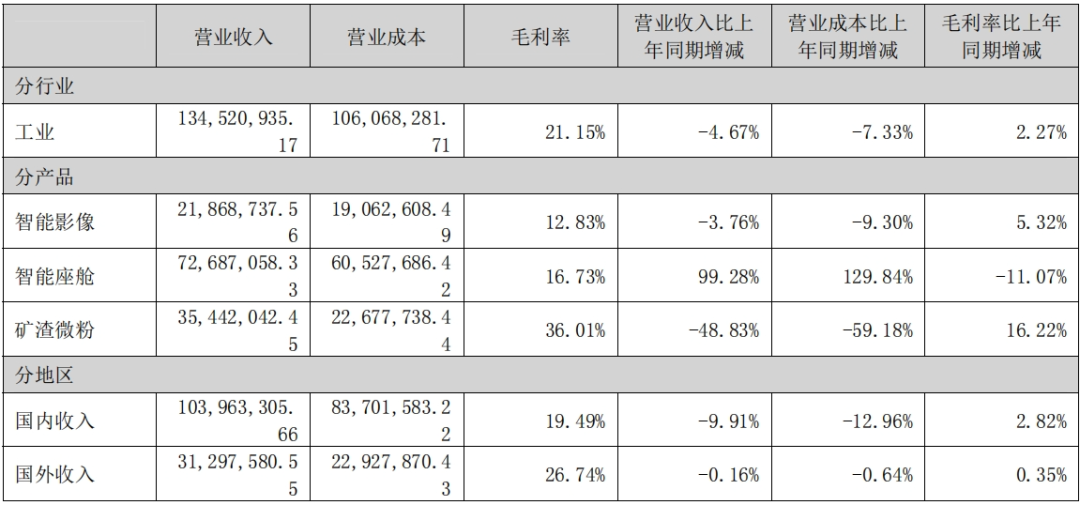
上半年亏损扩大/百亿资产重组终止,路畅科技如何“脱困”?
在智能网联汽车市场形势一片大好的前提下,路畅科技上半年的营收却出现了下滑,并且亏损也进一步扩大。 2024年半年度报告显示,路畅科技营业收入1.35亿元,同比下滑7.83%;实现归属上市公司股东的净利润为亏损2491.99万元…...

协议IP规定,576字节和1500字节的区别
576字节和1500字节的区别主要在于它们是IP数据报在数据链路层中的最大传输单元(MTU)的不同限制。 576字节:这个数值通常与IP层(网络层)的数据报有关,它指的是在不进行分片的情况下,IP数据…...

对抗攻击的详细解析:原理、方法与挑战
对抗攻击的详细解析:原理、方法与挑战 对抗攻击(Adversarial Attack)是现代机器学习模型,尤其是深度学习模型中的一个关键安全问题。其本质在于,通过对输入数据添加精微的扰动,人类难以察觉这些扰动&#…...

Python办公自动化教程(003):PDF的加密
【1】代码 from PyPDF2 import PdfReader, PdfWriter# 读取PDF文件 pdf_reader PdfReader(./file/Python教程_1.pdf) pdf_writer PdfWriter()# 对第1页进行加密 page pdf_reader.pages[0]pdf_writer.add_page(page) # 设置密码 pdf_writer.encrypt(3535)with open(./file/P…...

python全栈学习记录(十七)logging、json与pickle、time与datatime、random
logging、json与pickle、time与datatime、random 文章目录 logging、json与pickle、time与datatime、random一、logging二.json与pickle三.time与datatime四.random 一、logging logging模块用来记录日志信息。 import logging # 进行基本的日志配置 logging.basicConfig( fi…...

【艾思科蓝】JavaScript在数据可视化领域的探索与实践
【ACM出版 | EI快检索 | 高录用】2024年智能医疗与可穿戴智能设备国际学术会议(SHWID 2024)_艾思科蓝_学术一站式服务平台 更多学术会议请看 学术会议-学术交流征稿-学术会议在线-艾思科蓝 目录 引言 JavaScript可视化库概览 D3.js基础入门 1. 引入…...

【标准库的典型内容】std::declval
一、 d e c l v a l declval declval的基本概念和常规范例 s t d : : d e c l v a l std::declval std::declval 是 C 11 C11 C11标准中出现的一个函数模板。这个函数模板设计的比较奇怪(没有实现,只有声明),因此无法被调用&…...

深入了解package.json文件
在前端项目开发中,我们经常会遇到package.json文件。这个文件不仅是一个简单的配置文件,它还承担了项目管理的重任。下面,我们将深入探讨package.json文件的各个字段和作用,并通过实例来帮助你更好地理解和使用它。 package.json…...

【基础知识】网络套接字编程
套接字 IP地址 port(端口号) socket(套接字) socket常见API //创建套接字 int socket(int domain, int type, int protocol); //绑定端口 int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen); //监听套接字…...

小程序地图展示poi帖子点击可跳转
小程序地图展示poi帖子点击可跳转 是类似于小红书地图功能的需求 缺点 一个帖子只能有一个点击事件,不适合太复杂的功能,因为一个markers只有一个回调回调中只有markerId可以使用。 需求介绍 页面有地图入口,点开可打开地图界面地图上展…...

如何在VSCode中实现高效Mermaid图表实时预览:一站式解决方案
如何在VSCode中实现高效Mermaid图表实时预览:一站式解决方案 【免费下载链接】vscode-mermaid-preview Previews Mermaid diagrams 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-mermaid-preview 还在为技术文档中的图表制作而头疼吗?你是…...

OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具
OpCore Simplify:告别繁琐配置,轻松构建黑苹果OpenCore EFI的智能工具 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为黑…...

淘宝淘金币自动化脚本:5分钟完成每日任务,解放双手的时间管理方案
淘宝淘金币自动化脚本:5分钟完成每日任务,解放双手的时间管理方案 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors…...

Qt C++ 集成 SQLite 实现本地数据持久化:从原理到宠物投喂器实战
1. 项目概述与核心需求解析最近在做一个宠物智能投喂器的数据管理后台,核心需求是把设备上传的各种运行数据持久化存储起来,方便后续分析和查看。设备会上传投喂间隔时间、水温、剩余重量这几个关键参数,我需要一个轻量、可靠且易于集成的本地…...

阿里云Ubuntu22..04安装jdk21、MySQL8、nginx
推荐直接: Ubuntu 22.04下面全部基于: root 用户 Ubuntu 22.04展开。一、先更新系统 apt update && apt upgrade -y安装基础工具: apt install -y wget curl vim unzip net-tools二、安装 JDK21(推荐 Temurin)…...

LabVIEW开发者峰会:破解信息孤岛,构建实战技术生态
1. 为什么我们需要一场专属的LabVIEW开发者峰会?如果你是一名长期使用LabVIEW进行测控系统开发的工程师,可能经历过这样的场景:面对一个复杂的同步采集需求,你翻遍了官方帮助文档和范例,却总觉得方案不够优雅ÿ…...
)
不只是模拟器:用Android-x86把你的旧笔记本变成安卓平板(附VirtWifi联网指南)
旧笔记本重生计划:用Android-x86打造高性能安卓工作站 你是否有一台闲置多年的旧笔记本,性能早已跟不上现代操作系统的需求,却又舍不得丢弃?别急着让它沦为电子垃圾,通过Android-x86项目,这些老设备完全可以…...

正交张量、正定张量与材料稳定性:在有限元分析ABAQUS中的实际应用与参数设置
正交张量、正定张量与材料稳定性:在有限元分析ABAQUS中的实际应用与参数设置 当工程师在ABAQUS中遇到材料刚度矩阵非正定警告时,往往意味着仿真结果可能失去物理意义。这种警告背后隐藏着深刻的张量数学原理——正定张量的性质直接决定了材料本构模型的稳…...
)
告别WPF默认丑界面:用MahApps.Metro快速打造现代化桌面应用(Visual Studio 2022实战)
用MahApps.Metro重塑WPF应用:从传统到现代的视觉革命 当用户第一次打开一个默认样式的WPF应用时,那种扑面而来的Windows XP时代感往往让人失望。作为开发者,我们花费大量时间在功能实现上,却常常因为UI的陈旧感而让整个应用显得廉…...
)
TVA视觉新范式:工业视觉的百年未有之大变局(4)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...