LLMs之OCR:llm_aided_ocr(基于LLM辅助的OCR项目)的简介、安装和使用方法、案例应用之详细攻略
LLMs之OCR:llm_aided_ocr(基于LLM辅助的OCR项目)的简介、安装和使用方法、案例应用之详细攻略
目录
llm_aided_ocr的简介
1、特性
2、详细技术概览
PDF处理和OCR
PDF到图像转换
OCR处理
文本处理流程
分块创建
错误校正与格式化
重复内容移除
标题和页码抑制(可选)
LLM集成
灵活的LLM支持
本地LLM处理
基于API的LLM处理
异步处理
令牌管理
令牌估计
动态令牌调整
质量评估
日志记录与错误处理
3、配置与定制
4、输出与文件处理
llm_aided_ocr的安装和使用方法
1、安装
环境需求
安装
安装Pyenv和Python 3.12(如果需要):
设置项目:
安装Tesseract OCR引擎(如果尚未安装):
在.env文件中设置您的环境变量:
2、使用
3、工作原理
4、代码优化
5、配置
6、输出文件
7、限制与未来改进
llm_aided_ocr的案例应用
1、示例输出
llm_aided_ocr的简介
2024年8月,LLM辅助OCR项目是一个先进的系统,旨在显著提高光学字符识别(OCR)输出的质量。通过利用尖端的自然语言处理技术和大型语言模型(LLMs),该项目将原始OCR文本转换为高度准确、格式良好且可读性强的文档。
GitHub地址:GitHub - Dicklesworthstone/llm_aided_ocr: Enhance Tesseract OCR output for scanned PDFs by applying Large Language Model (LLM) corrections.
1、特性
>> PDF到图像的转换
>> 使用Tesseract进行OCR
>> 使用LLM(本地或基于API)进行高级错误校正
>> 智能文本分块以提高处理效率
>> 可选的Markdown格式化选项
>> 标题和页码抑制(可选)
>> 最终输出的质量评估
>> 支持本地LLM和基于云的API提供商(OpenAI, Anthropic)
>> 异步处理以提高性能
>> 详细的日志记录用于过程跟踪和调试
>> GPU加速本地LLM推理
2、详细技术概览
PDF处理和OCR
PDF到图像转换
功能:convert_pdf_to_images()
使用pdf2image库将PDF页面转换为图像
支持使用max_pages和skip_first_n_pages参数处理页面子集
OCR处理
功能:ocr_image()
利用pytesseract进行文本提取
包含预处理图像的preprocess_image()函数:
将图像转换为灰度
使用Otsu方法应用二值阈值
执行膨胀以增强文本清晰度
文本处理流程
分块创建
process_document()函数将全文拆分为可管理的块
使用句子边界进行自然分割
实现块之间的重叠以保持上下文
错误校正与格式化
核心功能:process_chunk()
两步骤过程:a. OCR校正:
使用LLM修复由OCR引起的错误
维护原始结构和内容 b. Markdown格式化(可选):
将文本转换为适当的Markdown格式
处理标题、列表、强调等
重复内容移除
在Markdown格式化步骤中实现
识别并移除完全相同或近乎相同的重复段落
保留独特内容并确保文本流畅
标题和页码抑制(可选)
可配置以移除或以不同格式显示标题、页脚和页码
LLM集成
灵活的LLM支持
支持本地LLM和基于云的API提供商(OpenAI, Anthropic)
通过环境变量配置
本地LLM处理
功能:generate_completion_from_local_llm()
使用llama_cpp库进行本地LLM推理
支持自定义语法以获得结构化输出
基于API的LLM处理
功能:generate_completion_from_claude() 和 generate_completion_from_openai()
实现了适当的错误处理和重试逻辑
管理令牌限制并动态调整请求大小
异步处理
使用asyncio并发处理基于API的LLM时的块
保持处理块的顺序以保证最终输出的一致性
令牌管理
令牌估计
功能:estimate_tokens()
在可用时使用特定于模型的分词器
回退到approximate_tokens()进行快速估计
动态令牌调整
根据提示长度和模型限制调整max_tokens参数
实现TOKEN_BUFFER和TOKEN_CUSHION以安全地管理令牌
质量评估
输出质量评估
功能:assess_output_quality()
比较原始OCR文本与处理后的输出
使用LLM提供质量评分和解释
日志记录与错误处理
代码库中的全面日志记录
详细的错误消息和堆栈跟踪用于调试
抑制HTTP请求日志以减少噪音
3、配置与定制
项目使用.env文件进行轻松配置。关键设置包括:
LLM选择(本地或基于API)
API提供商选择
不同提供商的模型选择
令牌限制和缓冲区大小
Markdown格式化选项
4、输出与文件处理
原始OCR输出:保存为{base_name}__raw_ocr_output.txt
LLM校正后的输出:保存为{base_name}_llm_corrected.md 或 .txt
脚本生成整个过程的详细日志,包括时间信息和质量评估。
llm_aided_ocr的安装和使用方法
1、安装
环境需求
Python 3.12+
Tesseract OCR引擎
PDF2Image库
PyTesseract
OpenAI API(可选)
Anthropic API(可选)
本地LLM支持(可选,需要兼容的GGUF模型)
安装
安装Pyenv和Python 3.12(如果需要):
如果需要安装Pyenv和python 3.12,并使用它来创建虚拟环境
设置项目:
使用pyenv创建虚拟环境:
安装Tesseract OCR引擎(如果尚未安装):
对于Ubuntu: sudo apt-get install tesseract-ocr
对于macOS: brew install tesseract
对于Windows: 从GitHub下载并安装
在.env文件中设置您的环境变量:
2、使用
将您的PDF文件放置在项目目录中。
更新main()函数中的input_pdf_file_path变量,使用您的PDF文件名。
运行脚本:
python llm_aided_ocr.py
脚本将生成多个输出文件,包括最终后处理的文本。
3、工作原理
LLM辅助OCR项目采用多步骤过程将原始OCR输出转换为高质量、易读的文本:
PDF转换:使用pdf2image将输入PDF转换为图像。
OCR:应用Tesseract OCR从图像中提取文本。
文本分块:将原始OCR输出拆分为可管理的块以便处理。
错误校正:每个块都经过LLM处理,以纠正OCR错误并提高可读性。
Markdown格式化(可选):将校正后的文本重新格式化为干净一致的Markdown。
质量评估:基于LLM的评估比较最终输出质量与原始OCR文本。
4、代码优化
并发处理:当使用基于API的模型时,块被并发处理以提高速度。
上下文保留:每个块都包含与前一个块的小部分重叠以维持上下文。
自适应令牌管理:系统根据输入大小和模型约束动态调整LLM请求使用的令牌数量。
5、配置
项目使用.env文件进行配置。关键设置包括:
USE_LOCAL_LLM:设为True以使用本地LLM,False则使用基于API的LLM。
API_PROVIDER:在“OPENAI”或“CLAUDE”之间选择。
OPENAI_API_KEY, ANTHROPIC_API_KEY:各自服务的API密钥。
CLAUDE_MODEL_STRING, OPENAI_COMPLETION_MODEL:指定每个提供商使用的模型。
LOCAL_LLM_CONTEXT_SIZE_IN_TOKENS:设置本地LLM的上下文大小。
6、输出文件
脚本生成多个输出文件:
{base_name}__raw_ocr_output.txt:来自Tesseract的原始OCR输出。
{base_name}_llm_corrected.md:最终LLM校正并格式化的文本。
7、限制与未来改进
系统性能严重依赖所使用的LLM的质量。
处理非常大的文档可能耗时较长,可能需要大量的计算资源。
llm_aided_ocr的案例应用
1、示例输出
要查看LLM辅助OCR项目可以做什么,请参阅这些示例输出:
- Original PDF
- Raw OCR Output
- LLM-Corrected Markdown Output
相关文章:
的简介、安装和使用方法、案例应用之详细攻略)
LLMs之OCR:llm_aided_ocr(基于LLM辅助的OCR项目)的简介、安装和使用方法、案例应用之详细攻略
LLMs之OCR:llm_aided_ocr(基于LLM辅助的OCR项目)的简介、安装和使用方法、案例应用之详细攻略 目录 llm_aided_ocr的简介 1、特性 2、详细技术概览 PDF处理和OCR PDF到图像转换 OCR处理 文本处理流程 分块创建 错误校正与格式化 重复内容移除 标题和页码…...

低代码平台后端搭建-阶段完结
前言 最近又要开始为跳槽做准备了,发现还是写博客学的效率高点,在总结其他技术栈之前准备先把这个专题小完结一波。在这一篇中我又试着添加了一些实际项目中可能会用到的功能点,用来验证这个平台的扩展性,以及总结一些学过的知识。…...

暑假考研集训营游记
文章目录 摘要:1.对各大辅导机构考研封闭集训营的一些个人看法:2.对于考研原因一些感想:结语 摘要: Ashy在暑假的时候参加了所在辅导班的为期一个月的考研封闭集训营,有了一些全新的感悟,略作记录。 1.对…...
)
C#中的报文(Message)
在C#中,报文(Message)通常是指在网络通信中交换的数据单元。报文可以由多种不同的组成部分构成,具体取决于通信协议和应用场景。 以下是一些常见的报文组成部分: 头部(Header):包含…...
)
Python知识点:如何使用Python与Java进行互操作(Jython)
开篇,先说一个好消息,截止到2025年1月1日前,翻到文末找到我,赠送定制版的开题报告和任务书,先到先得!过期不候! Jython 是一种完全兼容 Java 的 Python 实现,它将 Python 代码编译成…...

ffmpeg解封装解码
文章目录 封装和解封装封装解封装 相关接口解封装的流程图关于AVPacket的解释如何区分不同的码流,视频流,音频流?第一种方式av_find_best_stream第二种方式 通过遍历流 代码 封装和解封装 封装 是把音频流 ,视频流,字…...

golang学习笔记10-循环结构
注:本人已有C,C,Python基础,只写本人认为的重点。 go的循环只有for循环,但有多个语法,可以实现C/C中的while和do while。当然,for循环也有break和continue,这点和C/C相同。 语法1: f…...
)
Java高级编程——泛型(泛型类、泛型接口、泛型方法,完成详解,并附有案例+代码)
文章目录 泛型21.1 概述21.2 泛型类21.3 泛型方法21.4 泛型接口 泛型 21.1 概述 JDK5中引入的特性,在编译阶段约束操作的数据类型,并进行检查 泛型格式:<数据类型> 泛型只能支持引用数据类型,如果写基本数据类型需要写对…...

GPU硬件如何实现光栅化?
版权声明 本文为“优梦创客”原创文章,您可以自由转载,但必须加入完整的版权声明文章内容不得删减、修改、演绎本文视频版本:见文末 引言 大家好,我是老雷,今天我想从GPU硬件原理出发,给大家分享在图形渲…...

Python写入文件内容:从入门到精通
在日常编程工作中,我们常常会遇到需要将数据保存至磁盘的需求。无论是日志记录、配置文件管理还是数据持久化,掌握如何有效地使用Python来写入文件内容都是必不可少的一项技能。本文将从基础语法开始,逐步深入探讨Python中写入文件内容的各种…...

相亲交易系统源码详解与开发指南
随着互联网技术的发展,越来越多的传统行业开始寻求线上转型,其中就包括婚恋服务。传统的相亲方式已经不能满足现代人快节奏的生活需求,因此,开发一款基于Web的相亲交易系统显得尤为重要开发者h17711347205。本文将详细介绍如何使用…...

Golang | Leetcode Golang题解之第413题等差数列划分
题目: 题解: func numberOfArithmeticSlices(nums []int) (ans int) {n : len(nums)if n 1 {return}d, t : nums[0]-nums[1], 0// 因为等差数列的长度至少为 3,所以可以从 i2 开始枚举for i : 2; i < n; i {if nums[i-1]-nums[i] d {t}…...

汽车总线之----FlexRay总线
Introduction 随着汽车智能化发展,车辆开发的ECU数量不断增加,人们对汽车系统的各个性能方面提出了更高的需求,比如更多的数据交互,更高的传输带宽等。现如今人们广泛接受电子功能来提高驾驶安全性,像ABS防抱死系统&a…...

前端代替后端做分页操作
如果后端没有分页api,前端如何做分页一、使用computed 这个变量应该是计算之后的值,是一个状态管理变量,跟onMounted类似import {computed} from vue // 定义ref储存rolelist,这里是原始数据 const roleList ref([])// 定义页码…...

L3 逻辑回归
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 在周将使用 LogisticRegression 函数对经典的鸢尾花 (Iris) 数据集进行分类。将详细介绍逻辑回归的数学原理。 1. 逻辑回归的数学原理 逻辑回归是一种线性分…...

Flink系列知识之:Checkpoint原理
Flink系列知识之:Checkpoint原理 在介绍checkpoint的执行流程之前,需要先明白Flink中状态的存储机制,因为状态对于检查点的持续备份至关重要。 State Backends分类 下图显示了Flink中三个内置的状态存储种类。MemoryStateBackend和FsState…...
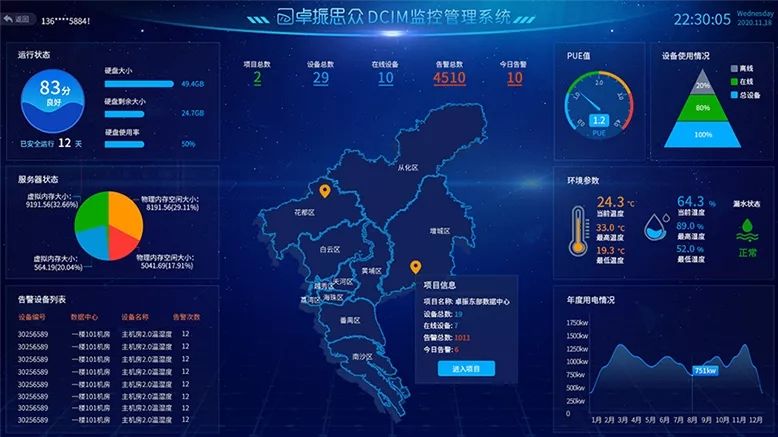
智算中心动环监控:构建高效、安全的数字基础设施@卓振思众
在当今快速发展的数字经济时代,智算中心作为人工智能和大数据技术的核心支撑设施,正日益成为各行业实现智能化转型的重要基石。为了确保这些高性能计算环境的安全与稳定,卓振思众动环监控应运而生,成为智算中心管理的重要组成部分…...

PyTorch VGG16手写数字识别教程
手写数字识别教程:使用PyTorch和VGG16 1. 环境准备 确保你已安装以下库: pip install torch torchvision2. 导入必要的库 import torch import torch.nn as nn import torch.optim as optim import torchvision.transforms as transforms import tor…...

安卓13删除下拉栏中的设置按钮 android13删除设置按钮
总纲 android13 rom 开发总纲说明 文章目录 1.前言2.问题分析3.代码分析4.代码修改5.编译6.彩蛋1.前言 顶部导航栏下拉可以看到,底部这里有个设置按钮,点击可以进入设备的设置页面,这里我们将更改为删除,不同用户通过这个地方进入设置。也就是下面这个按钮。 2.问题分析…...

FDA辅料数据库在线免费查询-药用辅料
在药物制剂的研制过程中,需要确定这些药用辅料的安全用量。而美国食品药品监督管理局(FDA)的辅料数据库(IID)提供了其制剂研发中的关键参考资源,使得更多的医药研发相关人员及企业单位节省试验环节及时间成…...

【Autosar】MCAL - 从零到一的工程配置实战
1. 工程创建:从零搭建MCAL开发环境 第一次打开Autosar配置工具时,面对满屏的选项确实容易发懵。记得我刚接触MCAL配置时,光是工程创建就反复折腾了好几次。下面我就把踩过的坑和验证过的正确姿势分享给大家。 创建新工程时,工程名…...
)
为什么你的Perplexity查不到正确代码?——基于127个失败Query的日志审计报告(附修复清单)
更多请点击: https://codechina.net 第一章:为什么你的Perplexity查不到正确代码?——基于127个失败Query的日志审计报告(附修复清单) 我们对127条在Perplexity平台中返回空结果、过时答案或完全偏离编程意图的用户Qu…...

Agent 一接数据大屏就开始配错指标:从维度意图识别到口径一致性校验的工程实战
一、🎯 生产痛点:大促当夜的指标错位 去年双 11 零点,某电商团队的 Agent 接到"生成实时 GMV 监控大屏"指令后产出了一套仪表盘。运营同学却发现 GMV 曲线在凌晨 1 点下跌 40%。问题在于 Agent 把"下单金额"和"退款…...

开发同城短途散步治愈路线生成程序,根据定位生成小众风景散步路线,适配日常解压。
基于创新思维与创业实验方法的「同城短途散步治愈路线生成程序,保持中立、去营销化、无引流。 一、实际应用场景描述 城市上班族常见状态: - 工作日长期处于高压、久坐状态 - 周末不想远行,但市内缺乏“新鲜感” - 热门公园人多、吵闹&…...
:助你轻松掌握办公自动化利器)
Excel VBA编程实例(150例):助你轻松掌握办公自动化利器
Excel VBA编程实例(150例):助你轻松掌握办公自动化利器 【下载地址】ExcelVBA编程实例150例资源下载 本仓库提供了一个名为“Excel VBA编程实例(150例)”的资源文件下载。该资源文件包含了150个Excel VBA编程实例,旨在帮助用户通过实际案例学习和掌握Exc…...
)
告别ICMP被墙!用TCP Traceroute精准探测服务器网络路径(附Win/Mac/Linux三平台保姆级教程)
告别传统路径探测:TCP Traceroute的跨平台实战指南 当服务器访问异常时,传统ICMP traceroute往往在第一个防火墙处就戛然而止。想象一下,你正面临生产环境突发性网络延迟,而常规工具返回的只有一串令人沮丧的"***"——此…...
)
从数学常数到编程实战:用C++三种方法手把手教你计算自然常数e(附OpenJudge NOI 1.5 35题解)
从数学常数到编程实战:用C三种方法手把手教你计算自然常数e 自然常数e是数学中最重要的常数之一,广泛应用于微积分、概率统计和复利计算等领域。对于编程学习者来说,理解e的计算原理并实现其算法,不仅能加深对数学概念的理解&…...

SpringBoot开发秘籍【个人八股】
介绍一下 SpringBoot? Spring Boot极大地简化了 Spring 应用的开发和部署过程。 以前我们用 Spring 开发项目的时候,需要配置一大堆 XML 文件,包括 Bean 的定义、数据源配置、事务配置等等,非常繁琐。而且还要手动管理各种 jar 包…...

移动端部署实战:用PyTorch实现的MobileNetV2模型,教你如何压缩并部署到安卓设备
移动端AI模型部署实战:从PyTorch到安卓的MobileNetV2全流程指南 在移动设备上部署深度学习模型已成为AI落地的关键环节。想象一下,当你用手机拍照时实时识别人物和场景,或是通过智能家居摄像头检测异常行为——这些场景背后都离不开高效、轻量…...
的三大优势)
EMD过时了?从故障诊断实战看经验小波变换(EWT)的三大优势
EMD过时了?从故障诊断实战看经验小波变换(EWT)的三大优势 在工业设备状态监测领域,振动信号分析一直是故障诊断的黄金标准。传统方法如经验模态分解(EMD)曾因其自适应特性广受推崇,但工程师们逐渐发现它在处理轴承点蚀、齿轮断齿等典型故障时…...