SPSS26统计分析笔记——2 描述统计
1 统计量
1.1 集中量数
(1)平均值:最常用的集中趋势统计指标,包括算术平均值、几何平均值和调和平均值等。
①算术平均数:最常见的平均数,是所有数据的总和除以数据的个数。它能简单地反映数据的整体水平,但容易受到极端值的影响。
②几何平均数:用于乘法关系的数据,适合处理比例或百分比。例如,当我们希望求一组数据的平均增长率时,几何平均数比算术平均数更合适。
③调和平均数:用于处理速率或比率数据,尤其适合在计算平均速度或效率时使用。
(2)中位数(又称中点数、中数、中值)是集中趋势的一个度量,用来表示数据的中间位置。具体来说,当我们将数据从小到大排列时,位于中间位置的数就是中位数。中位数的特性是,在数据集中有一半的值小于它,另一半的值大于它。它适用于衡量不对称分布的数据,因为它不受极端值的影响。中位数可以是数据中的某个值,也可能是两个数的平均值(当数据量为偶数时)。
(3)众数是指一组数据中出现频率最高的数值,即在数据集中出现次数最多的那个(或那些)数。与平均数和中位数不同,众数更适用于描述类别或离散数据。众数的特点是它可以是唯一的,也可以有多个(即数据集有两个或更多众数时称为多众数)。众数不受极端值的影响,因此在分析分布较不均匀或分类数据时,众数是一个有用的统计量。
1.2 差异量数
全距:全距是指数据集中最大值与最小值之间的差异,计算方法是用最大值减去最小值。全距能够快速反映数据的分布范围,帮助了解数据的离散程度或数据值的广度。然而,由于全距只依赖于极端值,它容易受到异常值或极端数据的影响,无法充分反映数据的整体分布情况。因此,在分析数据的离散程度时,虽然全距提供了一个初步的参考,但通常还需要结合其他指标(如标准差或四分位距)来更全面地了解数据的变异性。
方差:方差是衡量一组数据与其平均值之间偏离程度的指标,反映了数据的波动性和离散程度。计算方差的过程是:先计算每个数据与平均值的差,再将这些差值平方,然后求这些平方值的平均。总体方差是将平方和除以总体样本数得到的结果。方差值越大,说明数据点之间的差异越明显,数据分布更为分散;方差值越小,则表示数据更集中在平均值附近。方差的平方处理使得正负差异不相互抵消,从而更准确地反映数据的变异程度。不过,方差的单位是原始数据单位的平方,因此它通常会与标准差一起使用,便于解释,公式如下所示:
但对于样本数据而言,方差是所有数据离均差的平方和除以自由度n-1,公示如下:
标准差:总体标准差+样本标准差;
总体标准差:
样本标准差:
百分位数:百分等级是指在一个分数分布中低于这个分数的人数百分比,用字母P表示。百分位数是指与某个百分等级P对应的那个分数点。百分位数可以分成很多种类,常用的百分位数有四分位数和十分位数,四分位数是将数据划分为四等份,每一等份包含25%的数据,处在各分位点的数值就是四分位数。四分位数就有三个,第一个四分位数称为下四分位数,第二个四分位数就是中位数,第三个四分位数称为上四分位数,分别用Q1,Q2,Q3表示。统计上利用四分位差来判断数据的离散情况,四分位差是将第三个四分位数减去第一个四分位数的一半,即QR=(Q3-Q1)/2,显然,其值越大说明数据离散程度越大,相反,其值越小离散程度距比起来,其优势是可以剔除两端的极值对离散程度的影响。
2 数据分布
2.1 正态分布
如果一组数据服从正态分布,其形状呈左右对称的钟形曲线。这意味着数据集中在平均值附近,远离平均值的数据点逐渐减少。
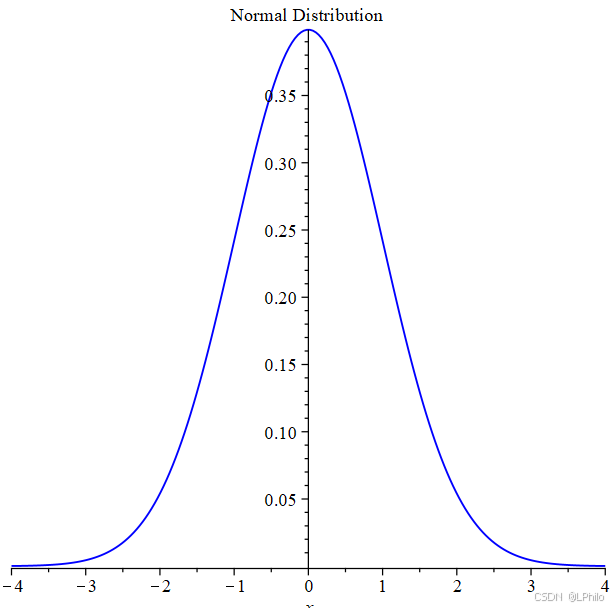
根据正态分布的特性:
①在距离平均值一个标准差范围内的数据约占总数的68%;
②在距离平均值两个标准差范围内的数据约占95%;
③ 在距离平均值三个标准差范围内的数据约占99%。
此外,所有的正态分布都可以通过标准化转化为标准正态分布。标准正态分布是一种特殊形式的正态分布,其均值为0、标准差为1,使得不同的正态分布可以进行比较和分析。标准化的过程主要是将原始数据减去其均值,再除以标准差,从而获得无量纲化的数值,便于分析和应用。
2.2 偏态分布
偏态分布是相对于正态分布的一种分布形式,特点是其分布曲线不对称。偏态分布在统计学中常见,通常是对连续随机变量的概率分布的一种描述,根据偏斜方向,偏态分布分为:
正偏态:分布曲线右侧较长,左侧较短。数据主要集中在较低的数值区间,但有少量较高的值向右延伸。
负偏态:分布曲线左侧较长,右侧较短。数据集中在较高的数值区间,少量较低的值向左延伸。
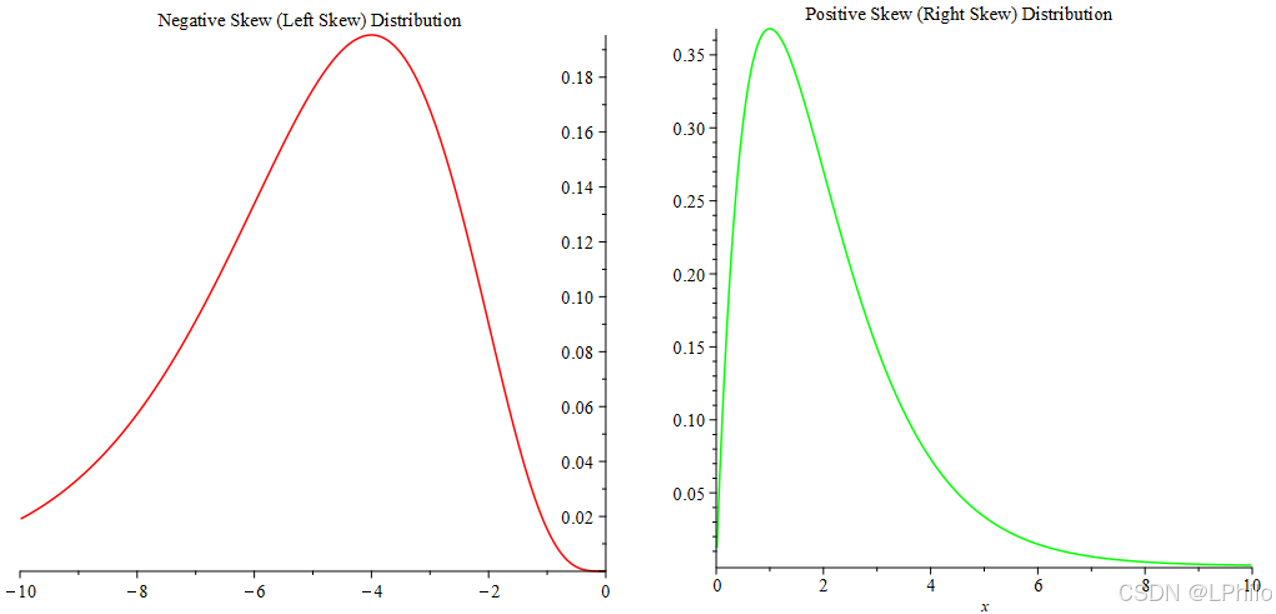
通过偏度和峰度的计算可以定量衡量偏态分布的程度。偏度表示分布的对称性,偏度为正时表示正偏态,为负时表示负偏态;而峰度则描述分布的“尖峭”或“平坦”程度,反映数据的集中或离散情况。
3 频率分析
在SPSS中,频率分析属于描述统计的一部分,它用于统计和显示每个类别或变量值出现的次数和比例。频率分析可以帮助我们快速了解数据的分布情况。描述统计的功能主要集中在“分析”菜单下的“描述统计”子菜单中,该子菜单提供了多种分析工具:
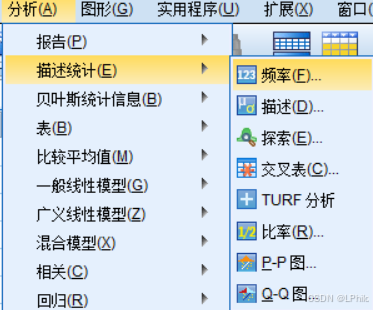
①频率:用于计算数据集中每个值或类别的出现频率和百分比。
②描述:用于生成一组变量的基本统计量,如均值、标准差等。
③探索:帮助深入了解数据分布情况,提供箱线图、均值比较等多种分析工具。
④交叉表:用于显示两个分类变量的分布及其交互关系。
⑤比率:用于计算和分析不同变量之间的比率。
⑥P-P图和Q-Q图:用于评估数据是否符合某种分布,通常用于正态性检验。
4 描述分析
描述命令用于对连续变量进行详细的统计分析,主要包括计算均值、标准差、方差、偏度、峰度等统计量。与频率命令相比,描述命令侧重于提供关于变量的详细统计描述,而不涉及类别数据的频数分布。具体来说:
①均值(Mean):数据的算术平均值。
②标准差(Standard Deviation):数据点相对于均值的离散程度。
③方差(Variance):标准差的平方,反映数据的总体离散程度。
④偏度(Skewness):数据分布的对称性,反映分布的偏斜程度。
⑤偏度(Skewness):数据分布的对称性,反映分布的偏斜程度。
⑥峰度(Kurtosis):数据分布的峰度,反映数据分布的尖峭程度。
⑦标准分(Z-scores):将原始数据转换为标准正态分布中的分数,以便于比较不同数据集的分布。
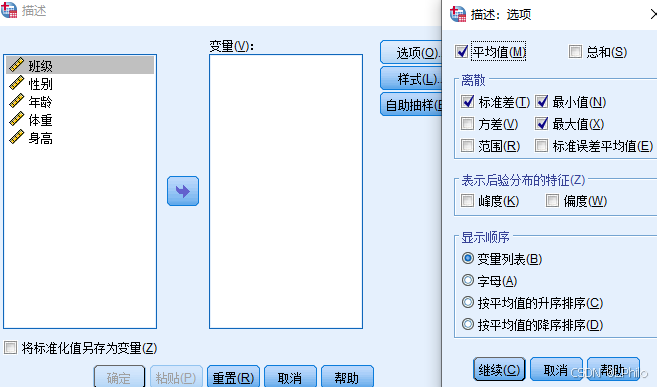
描述命令主要用于分析连续变量的集中趋势和离散程度,并提供转换成标准分的功能,这在频率命令中则不包含。使用描述命令时,您可以获取详细的统计信息和数据的分布特征,但它不包括图表功能,这一点与频率命令的图表功能有所不同。
4.1 标准化(Standardization)
单纯从一组数据的原始数值我们并不能了解这一数值在整个群体中的高低位置。为了反映某数值在一列变量数值中的相对位置,我们通常会将数据转换成标准分数,即Z分数。标准分是将个案的原始数值减去样本的平均值后除以样本的标准差所得到的数值,即它以平均数为参照点,以标准差为单位,其公式如下:
标准分代表个案的数值偏离样本平均值的标准差个数。
利用原始数据我们难以准确判断数据的高低好坏,但是如果把数据都转成标准分,我们就可以对分数做直观的判断了。
标准分取值在[-3,3]之间的面积占99%以上的数据,意味着凡是超出这个取值范围的数据是少见的,被称为极端值。数据中的极端值应该引起我们的重视。前面提到,有一些统计量,如算术平均数,容易受到两端极值的影响,如果我们利用![]() 分数将一些极端值做出筛选,那么分析的结果就会更稳定,也更可靠一些。
分数将一些极端值做出筛选,那么分析的结果就会更稳定,也更可靠一些。
4.2 归一化(Normalization)
归一化是将数据压缩到一个特定的范围(通常是[0,1]或[-1,1])。归一化后,数据的范围一致,但原本的分布信息可能会丢失。归一化的目的是将不同尺度的特征映射到同一范围,归一化的公式为:
5 数据探索
探索模块在SPSS中整合了频率分析和描述性统计功能,目的是在正式进行数据分析之前,帮助用户快速了解数据的基本分布情况,包括集中趋势、离散趋势、分布形态以及极端值的存在。通过探索模块,用户可以输出常见的统计量如平均值、标准差、中位数等,同时还会得到特有的分析结果,如95%的修整均值、极端值、正态性检验以及茎叶图和箱图等图形化展示。
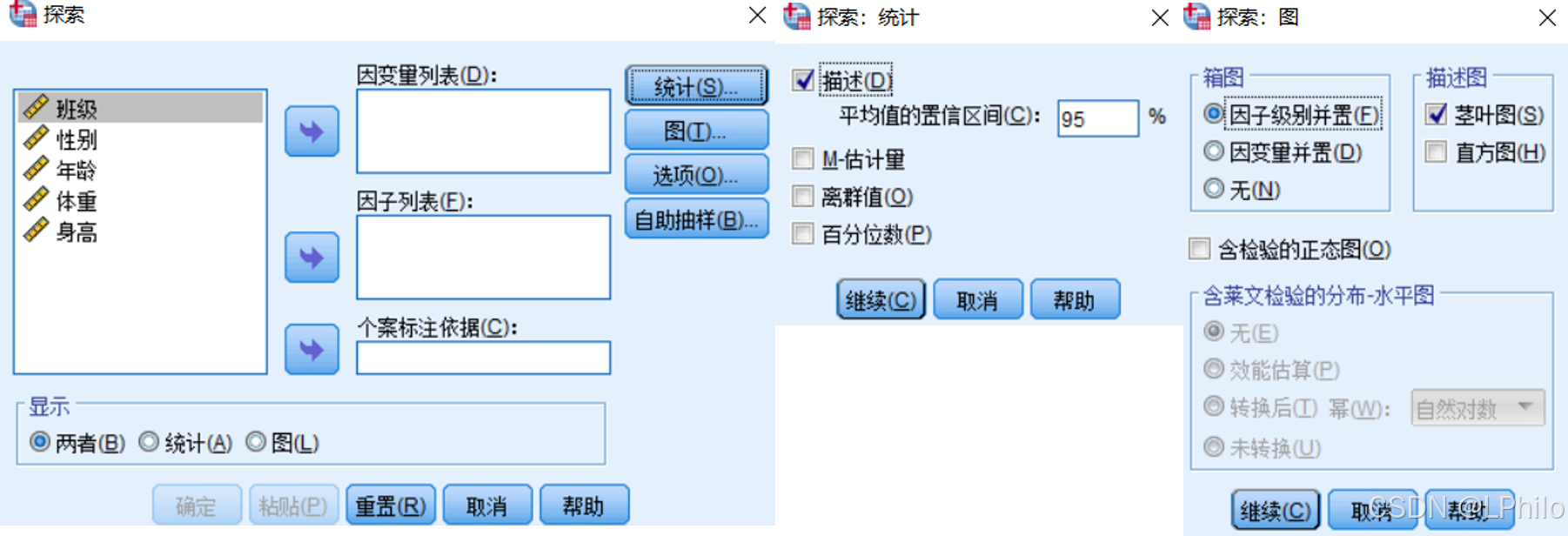
数据探索模块的几个重要功能:
①修整均值:95%的修整均值是将最高和最低各5%的数据剔除后计算的均值,目的是减少极端值对算术平均数的影响,使结果更加稳健。
②正态性检验:探索模块提供了“柯尔莫戈洛夫-斯米诺夫检验”和“夏皮洛-威尔克检验”两种正态性检验方式。如果显著性小于0.05,则表明该变量的数据不服从正态分布。
③极端值分析:通过探索模块,可以识别数据中的极端值,这对于判断数据的离群点非常重要。
④图形展示:茎叶图和箱图能够直观地展示数据的分布形态和离群点,有助于理解数据的整体分布情况。
茎叶图:一种将数据按位数拆分,直观呈现数据分布的统计图表。它通过将数据分为“茎”和“叶”两部分,分别表示数据的主干和尾数,既能显示数据的分布情况,又能保留原始数据的具体取值信息。
茎叶图的优势:
①保留原始数据:与直方图不同,茎叶图不仅展示了数据的分布情况,还完整保留了数据的具体值。
②显示数据频数:每一“茎”上的“叶”数量反映了该范围内数据的频数,因此可以直接从图中读出数据的分布密度。
③转换为直方图:将茎叶图逆时针旋转90度,能够得到类似于直方图的形态,这样可以同时直观理解数据的频数和分布形态。
箱图:一种用于可视化数据分布及检测离群点的统计图表。通过简单的图形表示,箱图能够展示数据的集中趋势、离散程度和对称性,帮助分析数据中的异常值。
箱图的关键元素包括:
①箱体:箱体的上下边分别代表上四分位数(Q3,75百分位数)和下四分位数(Q1,25百分位数),这表明数据分布的中间50%。
②中位数:箱体内部的横线表示数据的中位数(50百分位数),即数据的中心位置。
③四分位距(IQR):上四分位数与下四分位数之差称为四分位距(IQR = Q3 - Q1),用于衡量数据的离散程度。
④内限:箱体上下延伸的“须”表示数据的正常范围,通常为1.5倍IQR范围内的数据。超出此范围的数值称为异常值。
⑤异常值:超过1.5倍IQR之外的点称为异常值,用“○”表示。
⑥极端值:超过3倍IQR之外的点称为极端值,用“*”表示。
箱图的作用:
①展示数据的集中趋势和离散程度。
②检测数据中的异常值和极端值,便于进一步分析。
③可视化数据分布是否对称,帮助发现偏态分布。
6 交叉表分析
交叉表分析用于深入了解多个分类变量之间的关系,通过展示这些变量的交叉频数和百分比,帮助揭示变量之间的相关性或独立性。在实际应用中,交叉表分析不仅提供了单个分类变量的频数,还能够对多个分类变量进行综合分析。例如,如果我们想了解某地区不同民族在不同行业中的分布情况,交叉表分析能够展示每个民族在各行业中的频数及其百分比,这超出了单纯频率分析的范围。
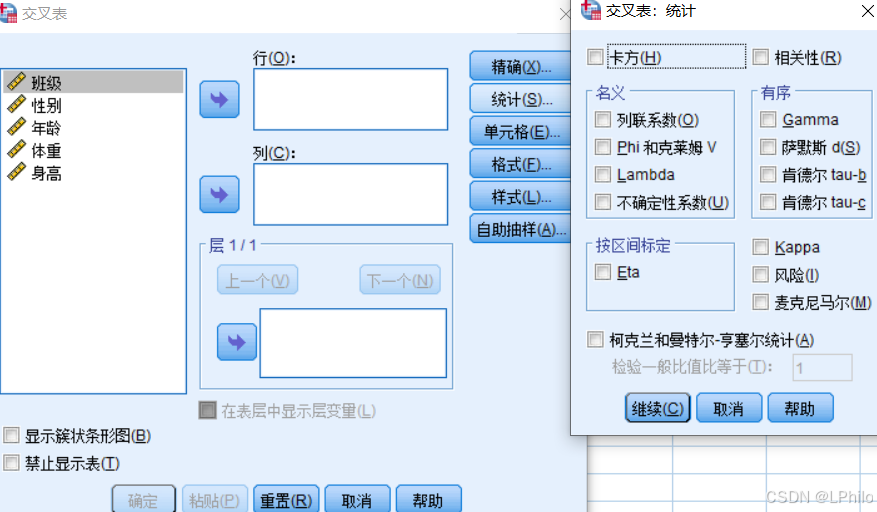
交叉表分析的主要用途包括:
①描述变量间的关系:揭示一个分类变量在不同水平上的分布情况,例如某地区的民族分布在各个行业中的情况。
②分析变量之间的关联性:评估两个或多个离散变量之间的相关性,检测它们是否独立或存在统计上的显著关系。
③检验独立性:利用卡方检验等方法,分析变量之间是否存在依赖关系,从而帮助理解变量之间的交互作用。
交叉表分析提供了一个结构化的方式来探索和理解分类数据之间的复杂关系,是数据分析中重要的一部分。
相关文章:
SPSS26统计分析笔记——2 描述统计
1 统计量 1.1 集中量数 (1)平均值:最常用的集中趋势统计指标,包括算术平均值、几何平均值和调和平均值等。 ①算术平均数:最常见的平均数,是所有数据的总和除以数据的个数。它能简单地反映数据的整体水平&…...

C++——输入一个字符串,把其中的字符按逆序输出。如输入LIGHT,输出THGIL。用string方法。
没注释的源代码 #include <iostream> #include <string.h> using namespace std; int main() { string a; cout<<"请输入字符串a:"; cin>>a; int k; ka.size(); for(int ik-1;i>0;i--) { cout<<a[i]; } return 0; }...

基于区块链的相亲交易系统源码解析
随着区块链技术的成熟与发展,其去中心化、不可篡改的特性逐渐被应用于各行各业。特别是在婚恋市场中,区块链技术的应用为相亲平台带来了新的可能性 。本文将探讨如何利用区块链技术构建一个透明、高效的相亲交易系统,并提供部分源码示例。 区…...

win11 wsl2安装ubuntu22最快捷方法
操作系统是win11,wsl版本是wsl2,wsl应该不用多介绍了,就是windows上的虚拟机,在wsl上可以很方便的运行Linux系统,性能棒棒的,而且wsl运行的系统和win11主机之间的文件移动是无缝的,就是两个系统…...

jekyll相关的技术点
jekyll相关的技术点 1. gem bundle jekyll 三者的关系gembundleJekyll 2. jekyll命令3. 注意事项 如果你用过github的Pages功能(现在在Action功能中),或者gitee中的Pages,那么对于jekyll你一定不陌生。今天研究部署了一下,供参考 1. gem bund…...

【Golang】Go语言中如何面向对象?
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

E2VPT: An Effective and Efficient Approach for Visual Prompt Tuning
论文汇总 存在的问题 1.以前的提示微调方法那样只关注修改输入,而应该明确地研究在微调过程中改进自注意机制的潜力,并探索参数效率的极限。 2.探索参数效率的极值来减少可调参数的数量? 解决办法 提示嵌入进行transformer中 提示剪枝 Token-wise …...

影刀RPA实战:网页爬虫之天猫商品数据
1.实战目标 1.1 实战目标 在电商行业,我们经常爬取各个平台的商品数据,通过收集和分析这些商品数据,企业可以了解市场趋势、消费者偏好和竞争对手的动态,从而制定更有效的市场策略。爬取商品数据对于企业在市场竞争中把握先机、…...

微信小程序注册流程及APPID获取(完整版图文教程)
文章目录 前言1. 注册微信小程序账号1.1微信小程序注册1.2 点击注册按钮,进入小程序注册步骤。1.3 填写邮箱、密码、验证码1.4 用户信息登记1.5 微信扫码认证后,回到微信公众平台点击确认提交1.6 进小程序后台,完成注册 2.完善小程序账号信息…...

分享课程:VUE数据可视化教程
在当今这个数据驱动的世界中,数据可视化已经成为了一种至关重要的工具,它帮助我们理解复杂的数据集,发现模式、趋势和异常。数据可视化不仅仅是将数字转换成图表,它是一种将数据转化为洞察力的艺术。 1.什么是数据可视化…...

Flink的反压机制:底层原理、产生原因、排查思路与解决方案
反压(Backpressure)是流处理框架(如 Apache Flink)中非常重要的概念。反压的产生和有效处理,直接影响整个流处理作业的稳定性和性能。本文将从 Flink 的底层原理、反压产生的原因、如何排查反压问题,以及如…...

Unity DOTS系列之Aspect核心机制分析
最近DOTS发布了正式的版本, 我们来分享一下DOTS里面Aspect机制,方便大家上手学习掌握Unity DOTS开发。 Aspect 机制概述 当我们使用ECS开发的时候,编写某个功能可能需要某个entity的一些组件,如果我们一个个组件的查询出来,可能…...

webpack 的打包target讲解 node环境打包下的文件存储造成不易察觉的坑点
背景 electron 主渲进程的打包,以及 preload 的打包,还有注入脚本的打包,这些东西 webpack 本身是自带的,这里主要讲一下 target: node 模式 代码 https://gitee.com/sen2020/webpack-demo/tree/feature%2Fnode-code-package/ n…...

JVM面试问题集
什么是运行时数据区? 什么是JVM? 了解过字节码文件的组成吗? 说一下运行时数据区 哪些区域会出现内存溢出,会有什么现象? JM在JDK6-8之间在内存区域上有什么不同 类的生命周期 常见的类加载器 什么是双亲委派机制 说明各个类加载器之间的关系 解释双亲委派机制 …...

Go weak包前瞻:弱指针为内存管理带来新选择
在介绍Go 1.23引入的unique包的《Go unique包:突破字符串局限的通用值Interning技术实现》一文中,我们知道了unique包底层是基于internal/weak包实现的,internal/weak是一个弱指针功能的Go实现。所谓弱指针(Weak Pointer,也称为弱…...

ZStack AIOS平台智塔入选2024世界计算大会专题展优秀成果
9月24日至25日,由湖南省人民政府主办,湖南省工业和信息化厅、长沙市人民政府、中国电子信息产业发展研究院承办的2024世界计算大会在湖南长沙举办。云轴科技ZStack AIOS平台智塔凭借在智算领域的卓越表现,入选2024世界计算大会专题展优秀成果…...

总结 自行解决问题经验
一、总结在使用Linux时遇到的各种坑 yum 源要替换为国内源wget 需要用yum先行下载在make的时候需要预先安装各种库端口无法访问时要记得去防火墙开启端口访问权限安装完各种程序的时候记得创建环境变量或者软链接… 二、遇到故障如何正确高效的去解决 在使用yum下载wget的时…...

软件设计模式——工厂模式
软件设计模式——工厂模式 文章目录 软件设计模式——工厂模式一、设计模式的认知1.1 什么是软件设计模式:1.2 为什么要学习设计模式:1.3 设计模式的分类: 二、工厂模式2.1 工厂模式实例: 一、设计模式的认知 1.1 什么是软件设计…...

Apache Druid命令执行(CVE-2021-25646)
漏洞详情: Apache Druid 是用Java编写的面向列的开源分布式数据存储系统,旨在快速获取大量事件数据,并在数据之上提供低延迟查询。 Apache Druid含有能够执行嵌入在各种类型请求中由用户提供的JavaScript代码功能。此功能适用于高度信任环境…...

新的 MathWorks 硬件支持包支持从 MATLAB 和 Simulink 模型到高通 Hexagon 神经处理单元架构的自动化代码生成
MathWorks 今天宣布,推出针对 Qualcomm Hexagon™ 神经处理单元(NPU)的硬件支持包。该处理单元嵌入在 Snapdragon 系列处理器中。MathWorks 硬件支持包,则专门针对 Qualcomm Technologies 的 Hexagon NPU 架构进行优化,…...

DDalkkak:逆向解析KakaoTalk数据库,实现聊天记录本地化备份与迁移
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫aristoapp/DDalkkak。乍一看这个仓库名,可能有点摸不着头脑,但如果你对韩国本土的即时通讯应用KakaoTalk有所了解,或者对数据迁移、备份工具有需求,那这个项…...

开源UI组件库深度解析:从设计系统到工程实践
1. 项目概述:一个开源UI组件库的诞生与价值如果你是一名前端开发者,或者正在负责一个需要快速搭建现代化界面的项目,那么你大概率听说过或者用过一些知名的UI组件库。今天我想深入聊聊一个在GitHub上拥有超过1.5万星标,被许多开发…...
基于GEMMA与NeoPixel制作智能可穿戴首饰:从硬件选型到代码实现
1. 项目概述:当微型控制器遇见珠宝设计几年前,当我第一次把一块微控制器塞进一个首饰盒里,看着它驱动一圈LED发出柔和的光晕时,我就知道,电子制作和个性化穿戴的结合,远不止于智能手表或健身手环。我们今天…...

046、PCIE桥设备与交换:当拓扑开始复杂起来
046、PCIE桥设备与交换:当拓扑开始复杂起来 最近在调一块自定义的PCIE扩展板,系统里突然出现了几个“神秘”的端点设备。在lspci列表里,它们出现在一个我从未配置过的总线号上,而且设备ID全对不上。折腾了两天才发现,原…...

企业信息采集神器:10分钟掌握天眼查企查查双平台爬虫
企业信息采集神器:10分钟掌握天眼查&企查查双平台爬虫 【免费下载链接】company-crawler 天眼查爬虫&企查查爬虫,指定关键字爬取公司信息 项目地址: https://gitcode.com/gh_mirrors/co/company-crawler 还在为获取企业信息而烦恼吗&…...
)
新手必看!CTFShow文件上传靶场通关保姆级教程(Web151-170全解析)
CTFShow文件上传靶场全解析:从入门到精通的实战指南 初识文件上传漏洞 文件上传功能几乎是每个Web应用都具备的基础模块,但恰恰是这个看似简单的功能,成为了无数安全漏洞的温床。在CTF竞赛中,文件上传类题目因其直观性和实战性&am…...
)
别再拍脑袋定样本量了!用Excel 5分钟搞定市场调研的样本容量计算(附置信区间模板)
别再拍脑袋定样本量了!用Excel 5分钟搞定市场调研的样本容量计算(附置信区间模板) 在快节奏的商业决策中,市场调研的可靠性往往取决于一个关键数字——样本量。产品经理小张最近就踩了坑:耗时两周完成的500份用户问卷&…...
)
Cesium实战:手把手教你用JavaScript实现5个酷炫的3D地图特效(雷达扫描/淹没分析/动态绘制)
Cesium实战:手把手教你用JavaScript实现5个酷炫的3D地图特效(雷达扫描/淹没分析/动态绘制) 在三维地理信息可视化领域,Cesium凭借其强大的WebGL渲染能力和灵活的JavaScript API,已成为开发者构建沉浸式空间应用的首选引…...

如何快速配置阅读APP书源:26个高质量小说资源一键导入指南
如何快速配置阅读APP书源:26个高质量小说资源一键导入指南 【免费下载链接】Yuedu 📚「阅读」自用书源分享 项目地址: https://gitcode.com/gh_mirrors/yu/Yuedu 阅读APP作为一款开源的小说阅读工具,本身不提供小说内容,而…...

科技与科学新闻摘要-2026年5月16日
科技与科学新闻摘要 日期: 2026年5月16日 科技领域重点新闻 1. 中国2025年度十大科学进展揭晓 核心要点: 中国科学技术部发布了2025年度十大科学进展,覆盖深空探测、人工智能、生命科学、能源技术等多个领域,集中展示了中国基础研究和应用研究的突破性…...