LLM - 使用 XTuner 指令微调 多模态大语言模型(InternVL2) 教程
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/142528967
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。

XTuner 是高效、灵活且功能齐全的大语言模型和多模态模型微调工具,支持简单配置和轻量级运行,通过配置文件,封装大部分微调场景,降低微调的门槛,同时,支持多种预训练模型,如 InternVL 等,支持多种数据集格式,包括文本、图像或视频等。
相关GitHub:
- InternVL:https://github.com/OpenGVLab/InternVL
- XTuner:https://github.com/InternLM/xtuner
1. 准备模型
以 InternVL2-2B 为例,下载 HuggingFace 的 InternVL2-2B 模型:
export HF_ENDPOINT="https://hf-mirror.com"
pip install -U huggingface_hub hf-transfer
huggingface-cli download --token [your hf token] --resume-download OpenGVLab/InternVL2-2B --local-dir InternVL2-2B
或 下载 ModelScope 的 InternVL2-2B 模型,推荐:
pip install modelscope
modelscope --token [your ms token] download --model OpenGVLab/InternVL2-2B --local_dir InternVL2-2B
ModelScope 的 Token 是 SDK Token,在网站注册之后获取。
使用 Docker 构建环境:
docker run -it \
--privileged \
--network host \
--shm-size 32G \
--gpus all \
--ipc host \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--name xtuner \
-v [your disk]:[your disk] \
nvcr.io/nvidia/pytorch:23.03-py3 \
/bin/bash
注意:需要继续配置 pip 与 conda 环境
2. 配置 XTuner 环境
配置 XTuner 的 conda 环境,参考 GitHub - xtuner,即:
lmdeploy:用于部署 VL 大模型streamlit:用于处理数据
即:
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-envpip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install lmdeploy==0.5.3 -i https://pypi.tuna.tsinghua.edu.cn/simpleapt install libaio-dev
pip show transformers # 4.39.3
pip show streamlit # 1.36.0
pip show lmdeploy # 0.5.3
测试 PyTorch 可用,即:
pythonimport torch
print(torch.__version__)
print(torch.cuda.is_available())
exit()
配置 XTuner 库,建议使用源码安装:
git clone https://github.com/InternLM/xtuner.git
git checkout v0.1.23
pip install -e '.[deepspeed]'xtuner version
xtuner help
3. 准备 VL 数据集
测试使用的 HuggingFace 数据集: zhongshsh/CLoT-Oogiri-GO,冷笑话数据集
export HF_ENDPOINT="https://hf-mirror.com"
pip install -U huggingface_hub hf-transfer
huggingface-cli download --token [hf token] --repo-type dataset --resume-download zhongshsh/CLoT-Oogiri-GO --local-dir CLoT-Oogiri-GO
使用 I2T (Image to Text) 的数据集进行训练,只选择图像到中文的数据。
核心数据内容 cn.jsonl 是中文注释,images 是图像内容:
├── [8.8M] cn.jsonl
├── [3.5M] en.jsonl
├── [1.5M] images
├── [1.3G] images.zip
数据样本如下:
{"text": "『住手!现在的你还不是那家伙的对手!先撤吧!!", "question": null, "star": null, "type": "I2T", "image": "007aPnLRgy1hb39z0im50j30ci0el0wm"}
在构建数据集时,如果 question 是空,替换默认提示文字:请你根据这张图片,讲一个脑洞大开的梗。
安装图像处理的 Python 包,即:
pip install datasets matplotlib Pillow timm -i https://pypi.tuna.tsinghua.edu.cn/simple
处理 CLoT-Oogiri-GO 数据集,转换成 XTuner 的格式,参考:
{"id": 0,"image": "images/00000000.jpg","width": 897,"height": 1152,"conversations": [{"from": "human","value": "<image>\nCan you extract any readable text from the image?"},{"from": "gpt","value": "Dares Wins Vol. 5 Tommy's Heroes Vol. 6: For Tomorrow Vol. 7: Closing Time miniseries. Clark Kent is being interviewed about Superman's connection to notorious killer Tommy Monaghan. Taking the conversation..."}]
}
参考 InternVL - Chat Data Format 的
Single-Image Data格式。
处理之后的数据集样本数量是 39736,文件是 Json 格式,即ex_cn.json,格式如下:
[
# ...{"id": 2,"image": "images/007aPnLRgy1hb39z0im50j30ci0el0wm.jpg","width": 450,"height": 404,"conversations": [{"from": "human","value": "<image>\n请你根据这张图片,讲一个脑洞大开的梗。"},{"from": "gpt","value": "『住手!现在的你还不是那家伙的对手!先撤吧!!"}]},
#...
]
4. 指令微调(Finetune)
修改训练配置 xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_qlora_finetune_my.py,即:
data_root:数据集 的位置data_path:处理之后,符合 xtuner 格式的 json 数据集image_folder:图像路径,注意,不包括images,默认会查找image_folder/images文件夹max_length:最大 Token 长度prompt_template:提示词模版,参考xtuner/utils/templates.pybatch_size:batch size 影响显存占用accumulative_counts:梯度累计,影响显存占用dataloader_num_workers:数据加载,影响速度max_epochs:运行的最大 epoch
即:
# Model
# path = 'OpenGVLab/InternVL2-2B'
path = "llm/InternVL2-2B"# Data
# data_root = './data/llava_data/'
# data_path = data_root + 'LLaVA-Instruct-150K/llava_v1_5_mix665k.json'
# image_folder = data_root + 'llava_images'
data_root = 'llm/CLoT-Oogiri-GO/'
data_path = data_root + 'ex_cn.json'
image_folder = data_root
prompt_template = PROMPT_TEMPLATE.internlm2_chat
max_length = 8192# Scheduler & Optimizer
batch_size = 8 # per_device
accumulative_counts = 2
dataloader_num_workers = 4
max_epochs = 1
其中 PROMPT_TEMPLATE.internlm2_chat 如下:
internlm2_chat=dict(SYSTEM='<|im_start|>system\n{system}<|im_end|>\n',INSTRUCTION=('<|im_start|>user\n{input}<|im_end|>\n''<|im_start|>assistant\n'),SUFFIX='<|im_end|>',SUFFIX_AS_EOS=True,SEP='\n',STOP_WORDS=['<|im_end|>']),
运行训练脚本:
CUDA_VISIBLE_DEVICES=2,3,4,5 NPROC_PER_NODE=4 xtuner train xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_qlora_finetune_my.py --work-dir xtuner/outputs/internvl_v2_internlm2_2b_qlora_finetune_my --deepspeed deepspeed_zero1
CUDA_VISIBLE_DEVICES的卡数,需要与NPROC_PER_NODE的数量一致。
运行日志,包括:
lr学习率eta预估的训练时间time单步运行时间data_time数据处理时间memory现存占用loss损失函数
即:
dynamic ViT batch size: 56, images per sample: 7.0, dynamic token length: 3409
09/25 15:07:26 - mmengine - INFO - Iter(train) [ 10/1242] lr: 5.0002e-06 eta: 3:58:14 time: 11.6030 data_time: 0.0238 memory: 37911 loss: 5.6273
09/25 15:08:52 - mmengine - INFO - Iter(train) [ 20/1242] lr: 1.0556e-05 eta: 3:25:19 time: 8.5596 data_time: 0.0286 memory: 37906 loss: 5.7473
09/25 15:10:20 - mmengine - INFO - Iter(train) [ 30/1242] lr: 1.6111e-05 eta: 3:14:46 time: 8.7649 data_time: 0.0290 memory: 37850 loss: 5.1485
09/25 15:11:49 - mmengine - INFO - Iter(train) [ 40/1242] lr: 2.0000e-05 eta: 3:09:50 time: 8.9780 data_time: 0.0293 memory: 37850 loss: 5.0301
09/25 15:13:18 - mmengine - INFO - Iter(train) [ 50/1242] lr: 1.9995e-05 eta: 3:05:54 time: 8.8847 data_time: 0.0283 memory: 37803 loss: 5.0017
09/25 15:14:42 - mmengine - INFO - Iter(train) [ 60/1242] lr: 1.9984e-05 eta: 3:01:05 time: 8.3671 data_time: 0.0271 memory: 37691 loss: 4.7469
09/25 15:17:02 - mmengine - INFO - Iter(train) [ 70/1242] lr: 1.9965e-05 eta: 3:13:06 time: 14.0434 data_time: 0.0302 memory: 37892 loss: 4.9295
09/25 15:18:25 - mmengine - INFO - Iter(train) [ 80/1242] lr: 1.9940e-05 eta: 3:07:30 time: 8.2537 data_time: 0.0324 memory: 37757 loss: 4.8976
09/25 15:19:43 - mmengine - INFO - Iter(train) [ 90/1242] lr: 1.9908e-05 eta: 3:01:51 time: 7.7941 data_time: 0.0348 memory: 37891 loss: 4.7055
09/25 15:20:55 - mmengine - INFO - Iter(train) [ 100/1242] lr: 1.9870e-05 eta: 2:56:03 time: 7.2490 data_time: 0.0288 memory: 37729 loss: 4.8404
dynamic ViT batch size: 40, images per sample: 5.0, dynamic token length: 3405
09/25 15:22:13 - mmengine - INFO - Iter(train) [ 110/1242] lr: 1.9824e-05 eta: 2:51:54 time: 7.7299 data_time: 0.0280 memory: 37869 loss: 5.1263
09/25 15:23:29 - mmengine - INFO - Iter(train) [ 120/1242] lr: 1.9772e-05 eta: 2:48:05 time: 7.6363 data_time: 0.0345 memory: 37937 loss: 4.8139
09/25 15:24:46 - mmengine - INFO - Iter(train) [ 130/1242] lr: 1.9714e-05 eta: 2:44:44 time: 7.6952 data_time: 0.0355 memory: 37875 loss: 5.0916
输出目录 xtuner/outputs/internvl_v2_internlm2_2b_qlora_finetune_my/20240925_150518:
20240925_150518.log:日志缓存scalars.json:运行 loss 相关的日志config.py:配置缓存
即:
├── [ 58K] 20240925_150518.log
└── [4.0K] vis_data├── [ 15K] 20240925_150518.json├── [4.6K] config.py└── [ 15K] scalars.json
5. LMDeploy 部署模型
LMDeploy 工具用于部署 VL 模型,注意,如果需要 ModelScope:
pip install modelscope
export LMDEPLOY_USE_MODELSCOPE=True
安装环境:
pip install lmdeploy==0.5.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install datasets matplotlib Pillow timm -i https://pypi.tuna.tsinghua.edu.cn/simple
模型评估代码:
from lmdeploy import pipeline
from lmdeploy.vl import load_imageimport os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"pipe = pipeline('llm/InternVL2-2B/')image = load_image('llm/CLoT-Oogiri-GO/007aPnLRgy1hb39z0im50j30ci0el0wm.jpg')
response = pipe(('请你根据这张图片,讲一个脑洞大开的梗。', image))
print(response.text)
注意:如果是 Jupyter 运行,注意清空输出,避免重复加载模型,报错。
测试 InternVL2 的图像效果:
Warning: Flash attention is not available, using eager attention instead.
[WARNING] gemm_config.in is not found; using default GEMM algo这张图片中的猫咪看起来非常可爱,甚至有点滑稽。让我们来脑洞大开一下,看看这个梗会如何发展:**梗名:“猫咪的愤怒表情”****梗描述:**
1. **场景设定**:猫咪站在一个高处,看起来像是在观察周围的环境。
2. **猫咪的表情**:猫咪张大嘴巴,眼睛瞪得大大的,似乎在发出愤怒的吼声。
3. **背景细节**:背景中有一个楼梯,猫咪似乎在楼梯上,可能是在观察楼上的人或物。**梗发展**:
- **猫咪的愤怒**:猫咪的愤怒表情非常夸张,仿佛它真的在生气,甚至可能在向人发出警告。
- **猫咪的愤怒原因**:猫咪的愤怒可能与它所处的环境有关,比如楼上的人或物让它感到不安,或者它觉得自己的领地受到了侵犯。
- **猫咪的愤怒反应**:猫咪可能会通过大声吼叫、挠痒痒、甚至跳起来来表达它的愤怒。**梗应用**:
- **搞笑图片**:这张图片可以用来制作搞笑的社交媒体帖子,猫咪的愤怒表情非常生动,能够引起大家的共鸣和笑声。
- **猫咪行为研究**:通过观察猫咪的愤怒表情,研究者可以更好地了解猫咪的情感表达方式,从而更好地照顾和训练它们。**总结**:
这张图片通过夸张的猫咪愤怒表情,引发了人们对猫咪行为的思考和讨论。它不仅展示了猫咪的可爱,还通过幽默的方式引发了更多关于猫咪行为和情感的有趣话题。
6. 合并模型
将已训练的 LoRA 模型,合并成完整的模型,即:
- LoRA 模型是 288M
- InternVL2-2B 模型是 4.2G
- 合并之后模型也是 4.2G
即:
cd XTuner
# transfer weights
python xtuner/xtuner/configs/internvl/v1_5/convert_to_official.py \
xtuner/xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_qlora_finetune_my.py \
xtuner/outputs/internvl_v2_internlm2_2b_qlora_finetune_my/iter_1242.pth \
llm/convert_model/# 重命名
mv llm/convert_model/ llm/InternVL2-2B-my/
注意:需要修改模型
convert_model名称,确保 LMDeploy 可以识别 PromptTemplate, 参考 XTuner - Load failure with the converted finetune InternVL2-2B model
使用 LMDeploy 测试新模型 InternVL2-2B-my 的输出,明显更加简洁,即:
小猫咪,你的猫爪好臭啊
7. 其他
CLoT-Oogiri-GO 数据集转换成 XTuner 格式的脚本:
import json
import osimport PIL.Image as Image
from tqdm import tqdmfrom root_dir import DATA_DIRclass OogirlGoProcessor(object):"""将 oogirl_go 数据集转换为 xtuner 格式"""def __init__(self):pass@staticmethoddef process(json_path, output_path):print(f"[Info] json_path: {json_path}")print(f"[Info] output_path: {output_path}")with open(json_path, "r", encoding="utf-8") as f:lines = f.readlines()r_id = 0dataset_dir = os.path.dirname(json_path)sample_list = []for line in tqdm(lines):data = json.loads(line)# print(data)img_name = data["image"]r_image = f"images/{img_name}.jpg"img_path = os.path.join(dataset_dir, r_image)if not os.path.exists(img_path):continueimg = Image.open(img_path)r_width, r_height = img.size# print(f"[Info] w: {r_width}, h: {r_height}")r_human = data["question"]if not r_human:r_human = "请你根据这张图片,讲一个脑洞大开的梗。"r_gpt = data["text"]if not r_gpt:continuesample_dict = {"id": r_id,"image": r_image,"width": r_width,"height": r_height,"conversations": [{"from": "human","value": f"<image>\n{r_human}"},{"from": "gpt","value": r_gpt}]}sample_list.append(sample_dict)r_id += 1print(f"[Info] 全部样本数量: {r_id}")with open(output_path, "w", encoding="utf-8") as f:json.dump(sample_list, f, ensure_ascii=False, indent=4)def main():json_path = os.path.join(DATA_DIR, "CLoT-Oogiri-GO", "cn.jsonl")output_path = os.path.join(DATA_DIR, "CLoT-Oogiri-GO", "ex_cn.json")ogp = OogirlGoProcessor()ogp.process(json_path, output_path)if __name__ == '__main__':main()
BugFix1:ImportError: libGL.so.1: cannot open shared object file: No such file or directory
解决方案:
apt-get update && apt-get install ffmpeg libsm6 libxext6 -y
参考:
- InternVL - 垂直领域场景微调实践
- xTuner - Quickstart
- StackOverflow - ImportError: libGL.so.1: cannot open shared object file: No such file or directory
相关文章:
LLM - 使用 XTuner 指令微调 多模态大语言模型(InternVL2) 教程
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/142528967 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 XTuner…...

【Python】数据可视化之热力图
热力图(Heatmap)是一种通过颜色深浅来展示数据分布、密度和强度等信息的可视化图表。它通过对色块着色来反映数据特征,使用户能够直观地理解数据模式,发现规律,并作出决策。 目录 基本原理 sns.heatmap 代码实现 基…...
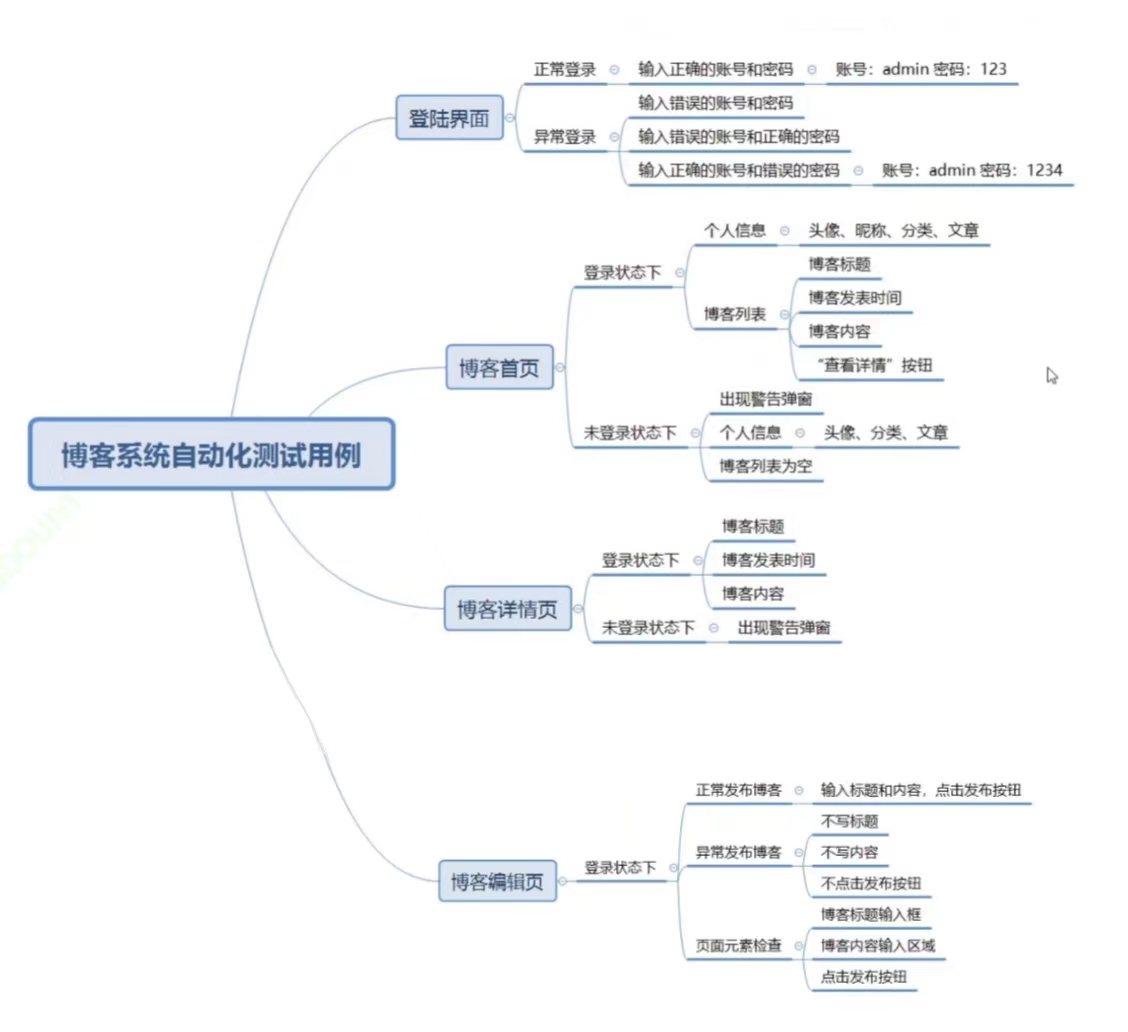
个人博客系统测试(selenium)
P. S.:以下代码均在VS2019环境下测试,不代表所有编译器均可通过。 P. S.:测试代码均未展示头文件stdio.h的声明,使用时请自行添加。 博主主页:Yan. yan. …...

【速成Redis】01 Redis简介及windows上如何安装redis
前言: 适用于:需要快速掌握redis技能的人(比如我),在b站,找了个课看。 01.课程简介_哔哩哔哩_bilibili01.课程简介是【GeekHour】一小时Redis教程的第1集视频,该合集共计19集,视频…...
和入侵预防系统(IPS))
入侵检测系统(IDS)和入侵预防系统(IPS)
入侵检测系统(IDS)和入侵预防系统(IPS)是网络安全领域中用来检测和防止潜在的恶意活动或政策违规行为的系统。它们的主要目的是保护网络和主机不受未授权访问和各种形式的攻击。以下是它们的主要区别和功能: 一&#…...

pytorch 加载模型参数后 如何测试数据,应用模型预测数据,然后连续变量转换成 list 或者numpy.array padans并保存到csv文件中
在PyTorch中,加载模型参数后测试数据通常涉及以下几个步骤: 1. **加载模型**:首先,你需要定义模型的结构,然后加载预训练的参数。 2. **加载数据**:准备你的测试数据集。确保数据集已经正确地预处理&…...
)
uni-app开发流程(开发、预览、构建和发布过程)
uni-app 是一个使用 Vue.js 开发所有前端应用的框架,支持编写一次代码,生成可以在多个平台(如微信小程序、H5、App等)运行的应用。下面是 uni-app 的开发流程,包括从创建项目到部署的各个阶段。 1. 创建项目 通过 HB…...

Linux Shell: 使用 Expect 自动化 SCP 和 SSH 连接的 Shell 脚本详解
文章目录 0. 引言2. 解决方案3. 脚本详解脚本1:使用 SSH 和 Expect 自动化登录远端机器脚本说明 脚本2:使用 SCP 和 Expect 自动化文件上传脚本说明 脚本3:使用 SCP 和 Expect 自动化文件下载脚本说明 4. 脚本的使用方法5. 关键技术点5.1. Ex…...
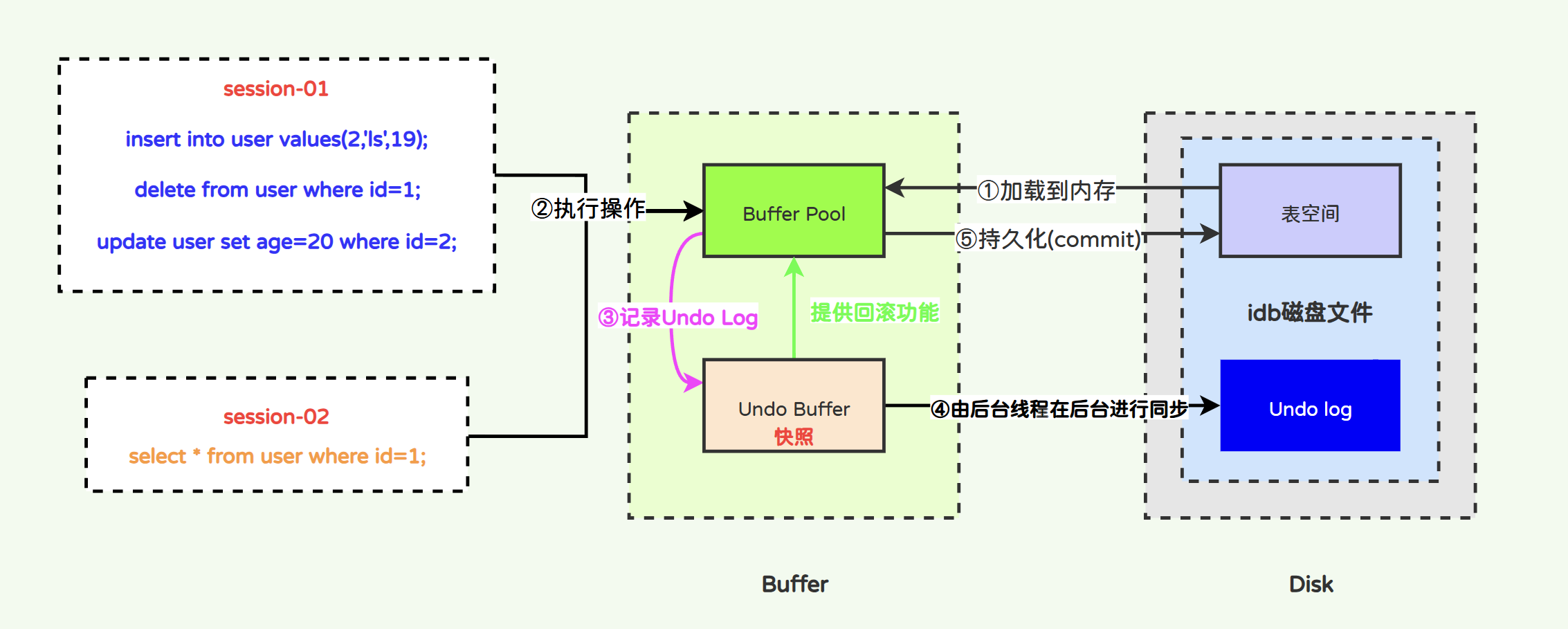
深入分析MySQL事务日志-Undo Log日志
文章目录 InnoDB事务日志-Undo Log日志2.1 Undo Log2.1.1 Undo Log与原子性2.1.2 Undo的存储格式1)insert类型Undo Log2)delete类型Undo Log3)update类型Undo Log 2.1.3 Undo Log的工作原理2.1.4 Undo Log的系统参数2.1.5 Undo Log与Purge线程…...
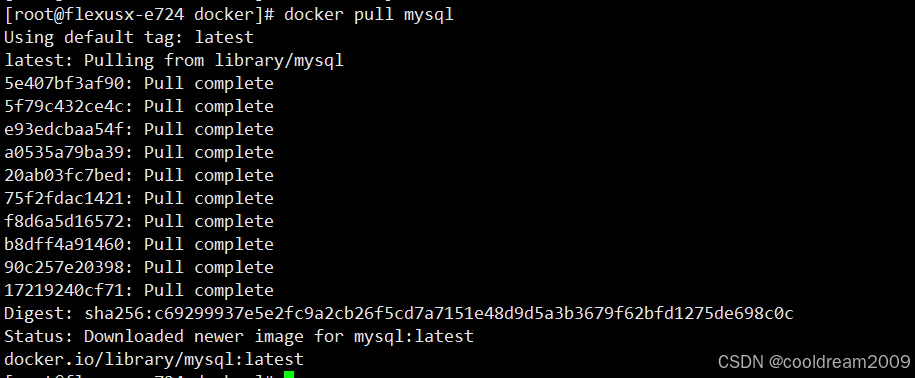
828华为云征文 | 在Huawei Cloud EulerOS系统中安装Docker的详细步骤与常见问题解决
前言 Docker是一种轻量级的容器技术,广泛用于应用程序的开发、部署和运维。在华为云的欧拉(Huawei Cloud EulerOS)系统上安装和运行Docker,虽然与CentOS有相似之处,但在具体实现过程中,可能会遇到一些系统…...
什么是数据增强中的插值法?
一、插值法的概念 在数据增强中,插值法是一种重要的技术,它通过数学模型在已知数据点之间估计未知数据点的值。这种方法可以帮助我们在不增加实际数据的情况下,通过生成新的数据点来扩展数据集。插值法基于这样的假设:如果已知的数…...

springboot实战学习(9)(配置mybatis“驼峰命名“和“下划线命名“自动转换)(postman接口测试统一添加请求头)(获取用户详细信息接口)
接着学习。之前的博客的进度:完成用户模块的注册接口的开发以及注册时的参数合法性校验、也基本完成用户模块的登录接口的主逻辑的基础上、JWT令牌"的组成与使用以及完成了"登录认证"(生成与验证JWT令牌)具体往回看了解的链接…...

之前做了抵押贷款,现在房市不景气,马上贷款要到期了该怎么办?
面对房贷的重压,特别是对于那些正承受高息贷款之苦的现有房产业主而言,探索有效的减负策略显得尤为重要。今天,我们共同探讨几种智慧策略,旨在帮助您巧妙减轻房贷的经济负担。 一、优化贷款结构:低息置换的魔力 当前&a…...

poi生成的ppt,powerPoint打开提示内容错误解决方案
poi生成的ppt,powerPoint打开提示内容错误解决方案 最近做了ppt的生成,使用poi制作ppt,出现一个问题。微软的powerPoint打不开,提示错误信息 通过xml对比工具发现只需要删除幻灯片的某些标签即可解决。 用的是XML Notepand 分…...

基于stm32物联网身体健康检测系统
在当今社会,由于经济的发展带来了人们生活水平不断提高,但是人们的健康问题却越来越突出了,各种各样的亚健康随处可在,失眠、抑郁、焦虑症,高血压、高血糖等等侵袭着人们的健康,人们对健康的关注达到了一个…...

BeautifulSoup4在爬虫中的使用
一、Beautiful Soup4简介 Beautiful Soup 提供一些简单的python函数来处理导航、搜索等功能。 它是一个工具箱,是python的一个库,最主要的功能是从网页获取数据。 二、Beautiful Soup4安装 在cmd下安装 pip install beautifulsoup4三、BeautifulSou…...

Laya2.x出包alipay小游戏
小游戏开发者工具,支付宝官方已经出了,不说了。 1.LAYA2.X打出得小游戏包中my-adapter.js这个文件需要替换,或者自行修改,替换3.x得; 2.unity导包出得模型文件命名需要注意,避免太长,路径也不…...

Vue极简入门
1.注册路由,如果是子路由,就加一个children import Vue from vue import Router from vue-router import Main from ../views/Main.vue import Login from ../views/Login.vueimport UserProfile from "../views/user/Profile.vue" import Us…...

系统敏感信息搜索工具(支持Windows、Linux)
目录 工具介绍 使用说明 search模块 browser模块 下载地址 工具介绍 可以快速搜索服务器中的有关username,passsword,账号,口令的敏感信息还有浏览器的账户密码。 使用说明 search模块 searchall64.exe search -p 指定路径 searchall64.exe search -p 指定路径 -s &q…...
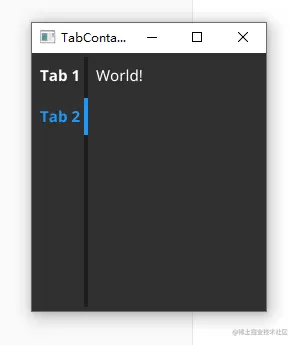
Fyne ( go跨平台GUI )中文文档-容器和布局 (四)
本文档注意参考官网(developer.fyne.io/) 编写, 只保留基本用法 go代码展示为Go 1.16 及更高版本, ide为goland2021.2 这是一个系列文章: Fyne ( go跨平台GUI )中文文档-入门(一)-CSDN博客 Fyne ( go跨平台GUI )中文文档-Fyne总览(二)-CSDN博客 Fyne ( go跨平台GUI…...

基于SpringBoot的公司固定资产盘点系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot框架的公司固定资产盘点系统以解决传统资产管理方式中存在的效率低下问题。当前企业固定资产管理工作普遍面临数据采集繁琐、…...

VTube Studio API完全指南:5个核心场景教你打造个性化虚拟主播互动
VTube Studio API完全指南:5个核心场景教你打造个性化虚拟主播互动 【免费下载链接】VTubeStudio VTube Studio API Development Page 项目地址: https://gitcode.com/gh_mirrors/vt/VTubeStudio 想要为你的虚拟主播形象添加更多互动功能,却不知道…...

Adafruit Bluefruit模块DFU模式恢复与固件更新全攻略
1. 项目概述如果你正在玩Adafruit的Bluefruit系列蓝牙模块,比如UART Friend或者SPI Friend,并且某天它突然“变砖”了——连接不上、没反应,或者Arduino IDE里怎么也刷不进新程序,先别急着把它扔进抽屉吃灰。这种情况我遇到过不止…...

G-Helper终极教程:华硕笔记本轻量级性能控制神器
G-Helper终极教程:华硕笔记本轻量级性能控制神器 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertb…...

等保2.0合规实战:Redis安全配置核查与加固指南
1. Redis安全配置入门:为什么等保2.0要求这么严格? 我第一次接触Redis安全配置是在一次等保2.0合规检查中。当时客户系统因为Redis默认配置导致数据泄露,整个项目组连夜加班整改。从那以后,我就养成了每次部署Redis必做安全检查的…...

【Midjourney Tea印相全链路解析】:从提示词工程到胶片质感渲染的7大隐性参数控制法则
更多请点击: https://intelliparadigm.com 第一章:Midjourney Tea印相的技术起源与美学范式 Midjourney Tea印相并非传统摄影工艺的简单复刻,而是融合生成式AI语义理解、茶渍拓印物理建模与东亚留白美学的一次跨媒介实验。其技术雏形可追溯至…...

MAA明日方舟小助手:让游戏回归乐趣的智能伙伴
MAA明日方舟小助手:让游戏回归乐趣的智能伙伴 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcode.com…...

小红书内容采集神器:XHS-Downloader免费开源工具完全指南
小红书内容采集神器:XHS-Downloader免费开源工具完全指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&…...
)
用STM32定时器中断做个呼吸灯吧:CubeMX+HAL库驱动LED渐变效果(正点原子F103)
STM32呼吸灯实战:用CubeMXHAL库实现PWM渐变效果 呼吸灯作为嵌入式开发的经典项目,不仅能直观展示PWM技术的魅力,更是理解定时器中断机制的绝佳案例。本文将带您从零开始,在正点原子STM32F103开发板上实现LED的平滑呼吸效果&#x…...

QQ截图独立版:免费获取专业级屏幕工具集的完整指南
QQ截图独立版:免费获取专业级屏幕工具集的完整指南 【免费下载链接】QQScreenShot 电脑QQ截图工具提取版,支持文字提取、图片识别、截长图、qq录屏。默认截图文件名为ScreenShot日期 项目地址: https://gitcode.com/gh_mirrors/qq/QQScreenShot 还在为寻找功…...