多机部署,负载均衡-LoadBalance
文章目录
- 多机部署,负载均衡-LoadBalance
- 1. 开启多个服务
- 2. 什么是负载均衡
- 负载均衡的实现
- 客户端负载均衡
- 3. Spring Cloud LoadBalance
- 快速上手
- 使用Spring Cloud LoadBalance实现负载均衡
- 修改IP,端口号为服务名称
- 启动多个服务
- 负载均衡策略
- 自定义负载均衡策略
- LoadBalance原理
多机部署,负载均衡-LoadBalance
1. 开启多个服务

多复制两个服务,将服务全部启动起来
此时多次访问原来的接口,发现
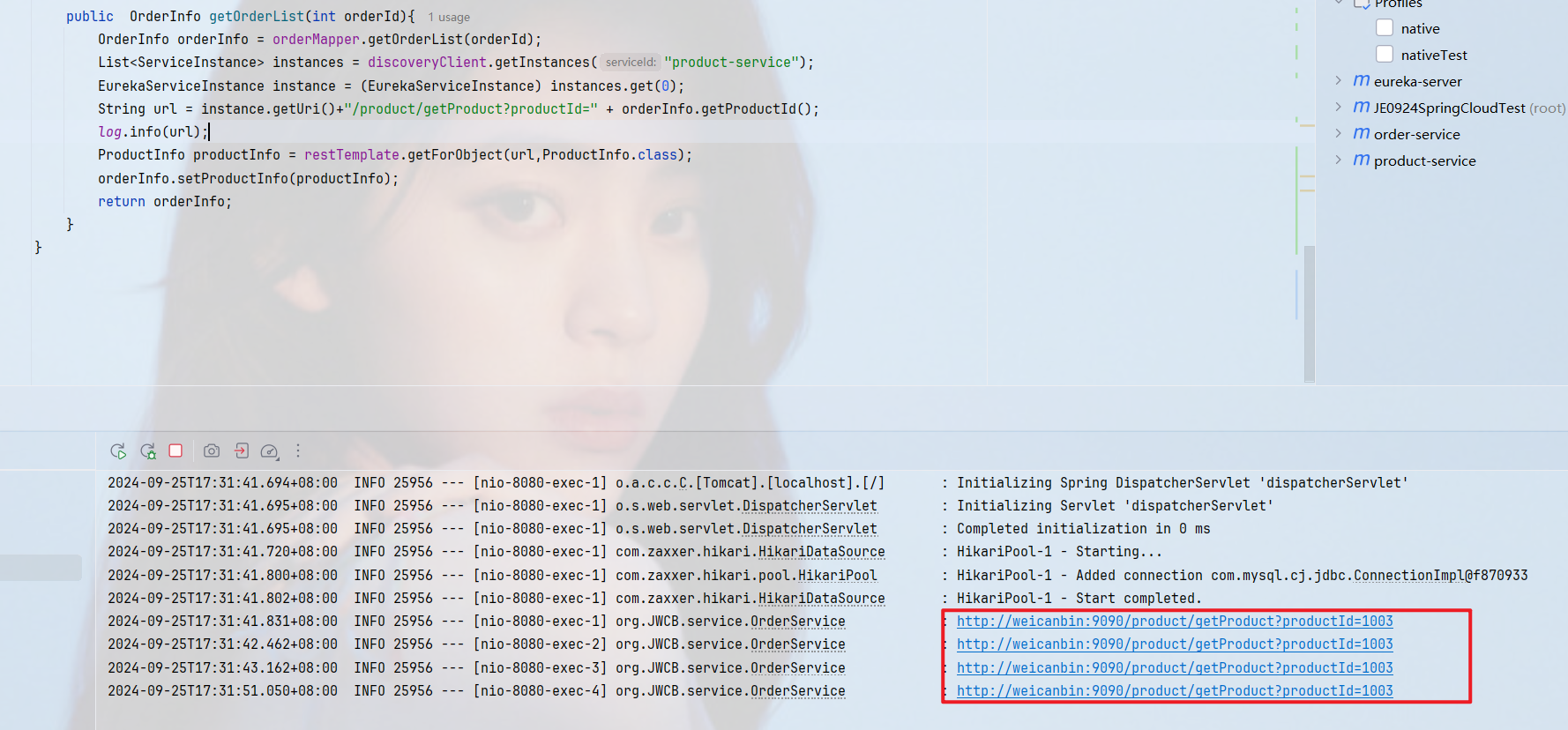
调用的还是同一个
我们对代码进行修改:
@Service
public class OrderService {private static final Logger log = LoggerFactory.getLogger(OrderService.class);@Autowiredprivate OrderMapper orderMapper;@Resourceprivate DiscoveryClient discoveryClient;@Autowiredprivate RestTemplate restTemplate;private static AtomicInteger atomicInteger = new AtomicInteger(1);private static List<ServiceInstance> instances;@PostConstructpublic void init() {instances = discoveryClient.getInstances("product-service");}public OrderInfo getOrderList(int orderId){OrderInfo orderInfo = orderMapper.getOrderList(orderId);int index = atomicInteger.getAndIncrement() % instances.size();EurekaServiceInstance instance = (EurekaServiceInstance) instances.get(index);String url = instance.getUri() + "/product/getProduct?productId=" + orderInfo.getProductId();log.info(url);ProductInfo productInfo = restTemplate.getForObject(url,ProductInfo.class);orderInfo.setProductInfo(productInfo);return orderInfo;}
}
通过轮询的方式去将请求均衡的分配到不同的实例上,这就是负载均衡

2. 什么是负载均衡
负载均衡是高并发,高可用系统必不可少的关键组件
当服务流量增大的时候,通常会采用增加机器的方式进行扩容,负载均衡就是用来在多个机器或者其他资源中,按照一定的规则合理分配负载,也就是负载均衡策略
负载均衡的实现
负载均衡分为服务端负载均衡和客户端负载均衡
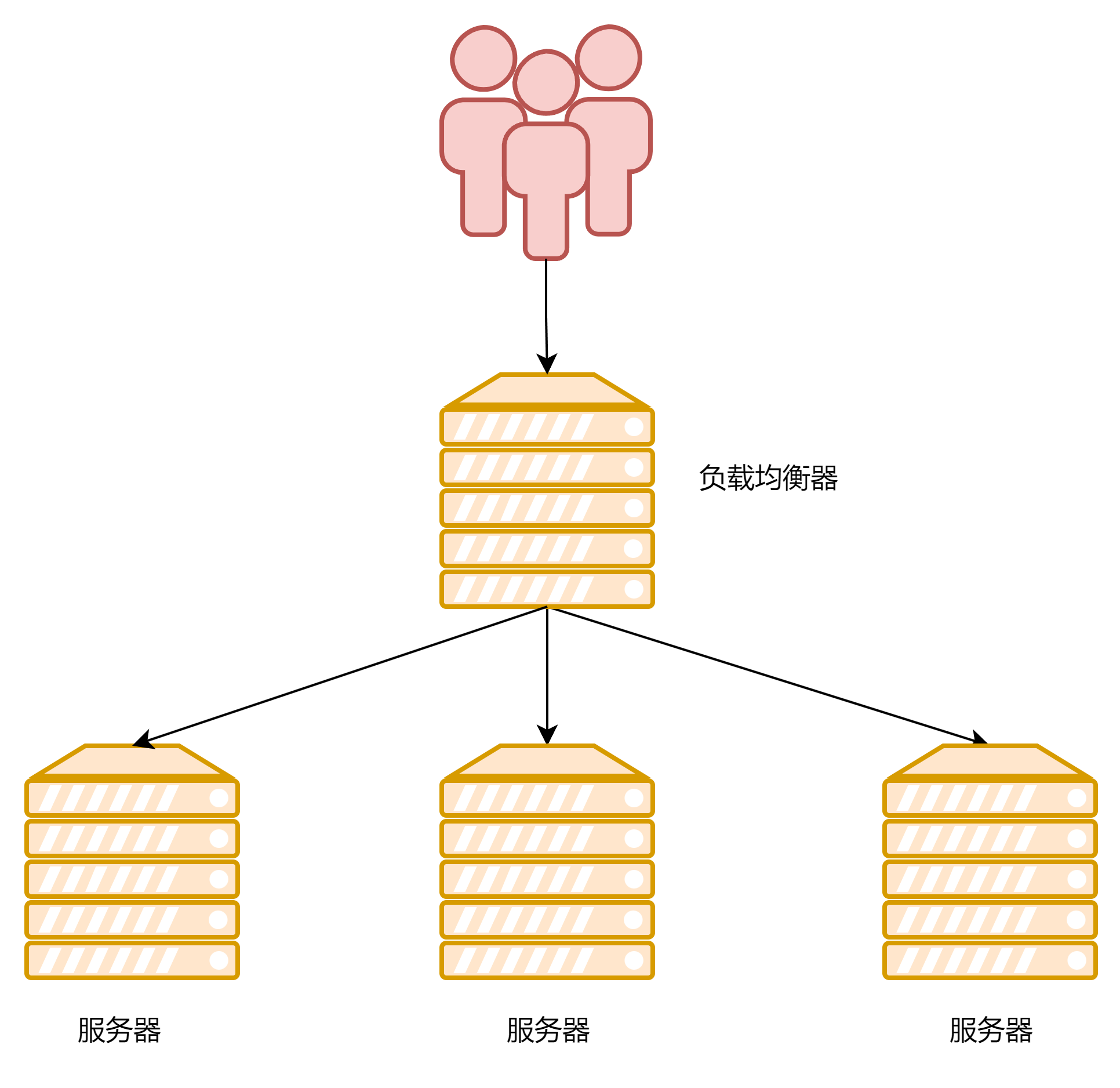
服务端负载均衡
指的是在服务端进行负载均衡的算法分配例如Nginx就是比较出名的服务端负载均衡器,请求会先到达Nginx负载均衡器,然后通过负载均衡算法,在多个服务器之间选择一个进行访问
客户端负载均衡
在客户端进行负载均衡的算法分配
就是将负载均衡的功能以库的方式集成到客户端,而不是由一台指定的负载均衡设备集中提供
比如Spring Cloud的Ribbon,请求发送到客户端,客户端从注册中心(比如Eureka)获取服务列表,在发送请求的时候通过负载均衡算法一个服务器,然后进行访问
但是Ribbon是Spring Cloud早期的默认实现,由于不维护了,现在最新版本的Spring Cloud 负载均衡集成的是Spring Cloud LoadBalance(Spring Cloud官方维护)

客户端负载均衡器和服务端负载均衡器的最大区别在于服务清单存储的位置
3. Spring Cloud LoadBalance
快速上手
使用Spring Cloud LoadBalance实现负载均衡
给RestTemplate这个Bean 添加 @LoadBalance注解
@Configuration
public class BeanConfig {@LoadBalanced@Beanpublic RestTemplate restTemplate() {return new RestTemplate();}
}
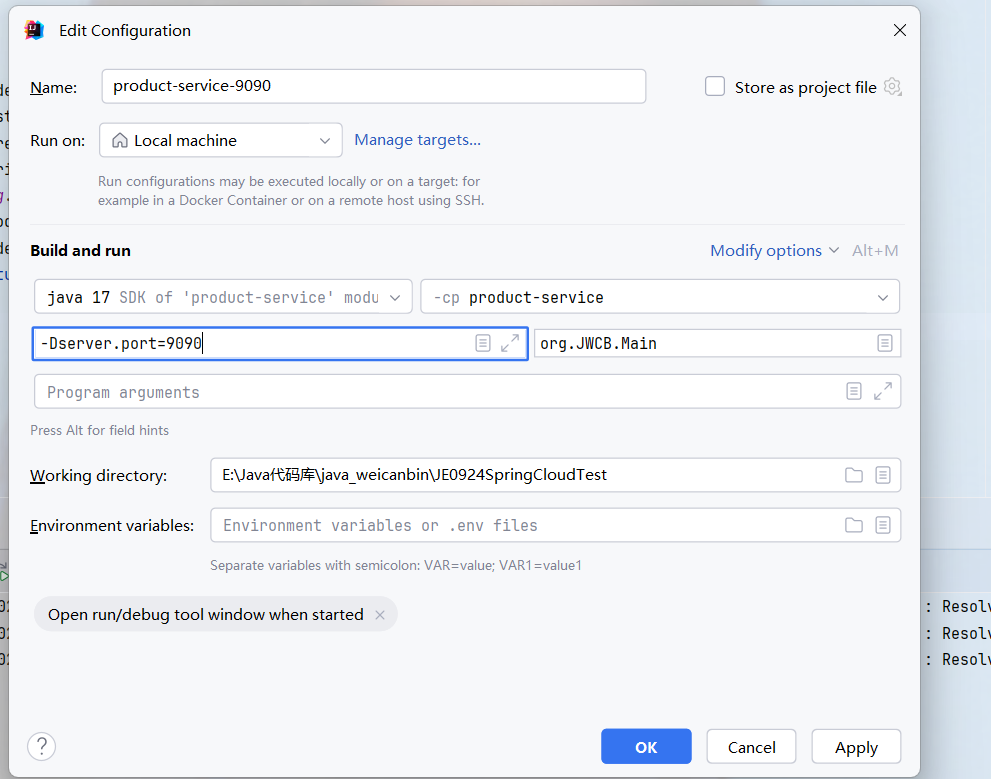
修改IP,端口号为服务名称
@Service
public class OrderService {private static final Logger log = LoggerFactory.getLogger(OrderService.class);@Autowiredprivate OrderMapper orderMapper;@Autowiredprivate RestTemplate restTemplate;public OrderInfo getOrderList(int orderId){OrderInfo orderInfo = orderMapper.getOrderList(orderId);String url = "http://product-service/product/getProduct?productId=" + orderInfo.getProductId();log.info(url);ProductInfo productInfo = restTemplate.getForObject(url,ProductInfo.class);orderInfo.setProductInfo(productInfo);return orderInfo;}
}
启动多个服务
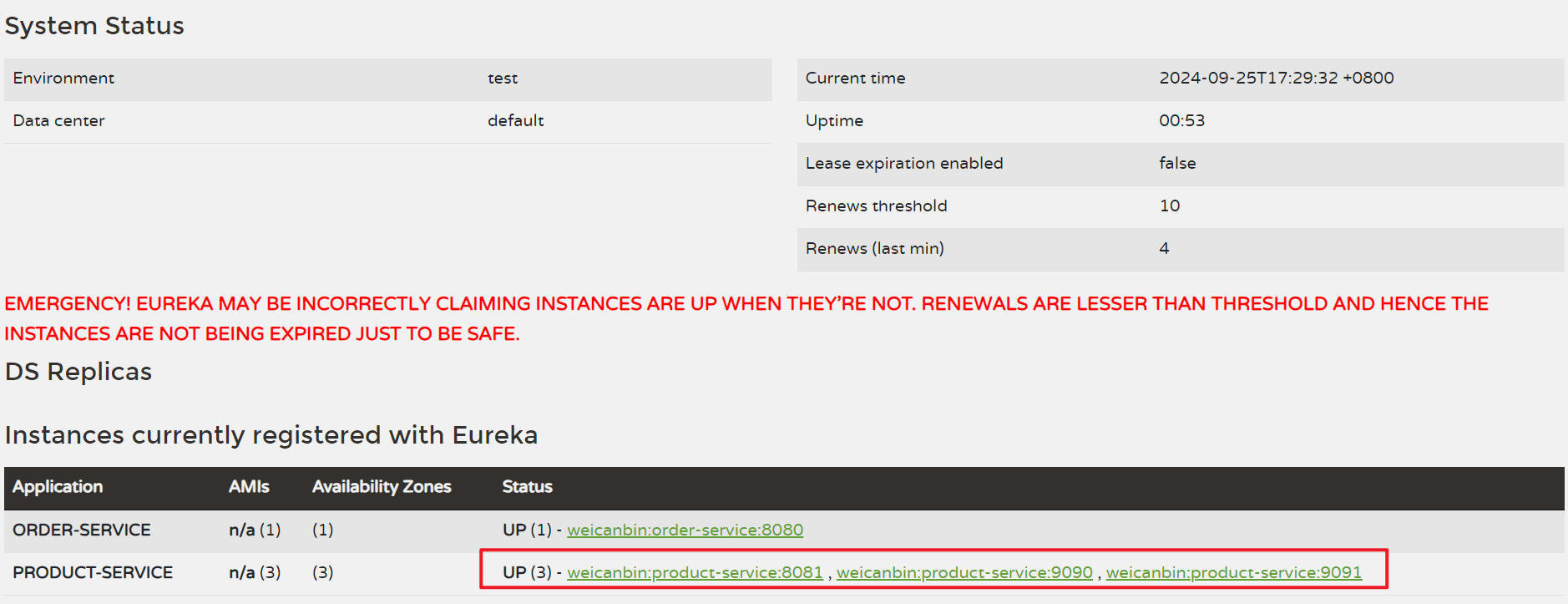
进行6次访问
为了方便观察,我们在product-service里面加上日志
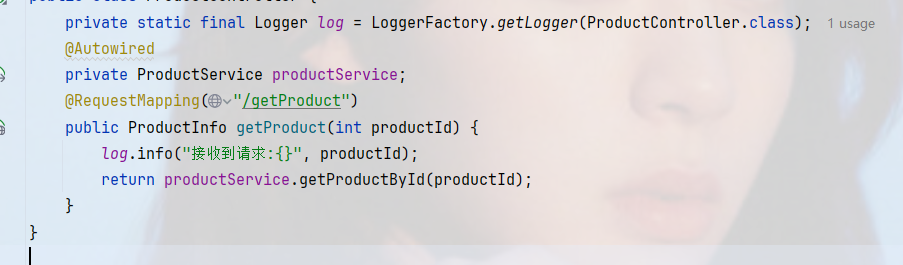
此时进行访问



可以看到请求被均匀的分布在3个实例上
负载均衡策略
负载均衡策略是一种思想,无论是哪种负载均衡,他们的负载均衡策略都是相似的.Spring Cloud LoadBalance仅支持两种负载均衡策略:轮询策略以及随机策略
- 轮询:轮询策略指的是服务器轮流处理用户的请求.这是一种实现最简单,也最常用的策略
- 随机选择:随机选择策略是指随机选择一个后端服务器来处理新的请求
自定义负载均衡策略
Spring Cloud LoadBalance默认的负载均衡策略是轮询策略.实现是RoundRobinLoadBalance
如果想使用随机的负载均衡策略:
- 定义随机算法对象,通过@Bean将其加载到Spring容器里面
这里我们使用Spring Cloud LoadBalancer提供的RandomLoadBalance
public class LoadBalanceConfig {@BeanReactorLoadBalancer<ServiceInstance> randomLoadBalance(Environment env, LoadBalancerClientFactory clientFactory) {String name = env.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);return new RandomLoadBalancer(clientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class),name);}
}
注意:不用@Configuration注释,要求这个类在组件扫描范围内
- 使用
@LoadBalancerClieent或者@LoadBalancerClients注解在RestTemplate配置类上方,就可以实现对不同的服务提供方配置不同的客户端负载均衡算法策略
@LoadBalancerClient(name = "product-service",configuration = LoadBalanceConfig.class)
@Configuration
public class BeanConfig {@LoadBalanced@Beanpublic RestTemplate restTemplate() {return new RestTemplate();}
}
其中,name表示该负载均衡策略对哪个服务生效(服务提供方),Configuration表示负载均衡策略
LoadBalance原理
LoadBalance的实现,主要是LoadBalanceInterceptor,这个类会对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表,然后利用负载均衡算法得到真实的服务地址信息,替换服务Id
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor {private LoadBalancerClient loadBalancer;private LoadBalancerRequestFactory requestFactory;public LoadBalancerInterceptor(LoadBalancerClient loadBalancer, LoadBalancerRequestFactory requestFactory) {this.loadBalancer = loadBalancer;this.requestFactory = requestFactory;}public LoadBalancerInterceptor(LoadBalancerClient loadBalancer) {this(loadBalancer, new LoadBalancerRequestFactory(loadBalancer));}public ClientHttpResponse intercept(final HttpRequest request, final byte[] body, final ClientHttpRequestExecution execution) throws IOException {URI originalUri = request.getURI();String serviceName = originalUri.getHost();Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);return (ClientHttpResponse)this.loadBalancer.execute(serviceName, this.requestFactory.createRequest(request, body, execution));}
}
主要就是看intercept方法,拦截了用户的请求后,做了以下几件事:
request.getURI()从请求中获取urioriginalUri.getHost()从uri中获取路径的主机名,也就是服务IdloadBalancer.execute根据服务Id,进行负载均衡,并处理请求
我们继续看execute方法
public <T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException {
String hint = this.getHint(serviceId);
LoadBalancerRequestAdapter<T, TimedRequestContext> lbRequest = new LoadBalancerRequestAdapter(request, this.buildRequestContext(request, hint));
Set<LoadBalancerLifecycle> supportedLifecycleProcessors = this.getSupportedLifecycleProcessors(serviceId);
supportedLifecycleProcessors.forEach((lifecycle) -> {lifecycle.onStart(lbRequest);
});
// 根据serviceId,和负载均衡策略,选择处理的服务
ServiceInstance serviceInstance = this.choose(serviceId, lbRequest);
if (serviceInstance == null) {supportedLifecycleProcessors.forEach((lifecycle) -> {lifecycle.onComplete(new CompletionContext(Status.DISCARD, lbRequest, new EmptyResponse()));});throw new IllegalStateException("No instances available for " + serviceId);
} else {return this.execute(serviceId, serviceInstance, lbRequest);
}
}
public <T> ServiceInstance choose(String serviceId, Request<T> request) {// 获取负载均衡器ReactiveLoadBalancer<ServiceInstance> loadBalancer = this.loadBalancerClientFactory.getInstance(serviceId);if (loadBalancer == null) {return null;} else {// 根据负载均衡算法,在列表中选择一个服务实例Response<ServiceInstance> loadBalancerResponse = (Response)Mono.from(loadBalancer.choose(request)).block();return loadBalancerResponse == null ? null : (ServiceInstance)loadBalancerResponse.getServer();}
}
相关文章:
多机部署,负载均衡-LoadBalance
文章目录 多机部署,负载均衡-LoadBalance1. 开启多个服务2. 什么是负载均衡负载均衡的实现客户端负载均衡 3. Spring Cloud LoadBalance快速上手使用Spring Cloud LoadBalance实现负载均衡修改IP,端口号为服务名称启动多个服务 负载均衡策略自定义负载均衡策略 LoadBalance原理…...

Hadoop安装与配置
一、Hadoop安装与配置 1、解压Hadoop安装包 找到hadoop-2.6.0.tar.gz,将其复到master0节点的”/home/csu”目录内,解压hadoop [csumaster0 ~]$ tar -zxvf ~/hadoop-2.6.0.tar.gz 解压成成功后自动在csu目录下创建hadoop-2.6.0子目录,可以用cd hadoo…...

一个自制的比较low的刷题软件
一个自制的比较low的刷题软件 一、背景 工作中往往涉及一些考试,比如阿里云ACP认证,华为GAUSS认证、软考等,应对这些考试的时候,我们往往是先看书后刷题(当然也有直接刷题的大神,毕竟考试,懂的…...
【Java 集合】List接口 —— ArrayList 与 LinkedList 详解
List接口继承自Collection接口,是单列集合的一个重要分支。 在List集合中允许出现重复的元素,所有的元素是以一种线性方式进行存储的,在程序中可以通过索引(类似于数组中的元素角标)来访问集合中的指定元素。另外&…...

通信工程学习:什么是PNF物理网络功能
PNF:物理网络功能 PNF(Physical Network Function)即物理网络功能,是指支持网络功能的物理设备。以下是关于PNF的详细解释: 一、定义与特点 定义: PNF是网络设备厂商(如Cisco、华为、H3C等)通过专用硬件实体提供软件功能的设备。这些设备直接在物理服务器上运…...

Unity的Text组件中实现输入内容的渐变色效果
要在Unity的Text组件中实现输入内容的渐变色效果,默认的Text组件不直接支持渐变色。但是,你可以通过以下几种方式实现: ### 1. **使用Shader**来实现渐变效果 通过自定义Shader为Text组件创建一个渐变效果。这是一个常用的做法࿰…...

network-scripts目录下没有ens33文件的问题
作者:程序那点事儿 日期:2023/11/09 06:52 systemctl start NetworkManager #开启网络管理器nmcli con show #查看ens33网卡对应的是ifcfg-Wired_connection_3这个文件(网络管理器要开启,不然报错),或者根据…...

OpenHarmony(鸿蒙南向)——平台驱动指南【DAC】
往期知识点记录: 鸿蒙(HarmonyOS)应用层开发(北向)知识点汇总 鸿蒙(OpenHarmony)南向开发保姆级知识点汇总~ 持续更新中…… 概述 功能简介 DAC(Digital to Analog Converter&…...

10.Lab Nine —— file system-下
Symbolic links 添加符号链接 1.添加有关symlink系统调用的定义声明,包括kernel/syscall.h, kernel/syscall.c, user/usys.pl 和 user/user.h. 2.添加新的文件类型T_SYMLINK到kernel/stat.h中,添加新的文件标识位O_NOFOLLOW到kernel/fcntl.h中 3.在ken…...

低代码中实现数据映射的必要性与方案
在数字化转型的浪潮中,低代码平台因其快速开发和灵活性而受到越来越多企业的青睐。然而,随着业务需求的复杂化,单纯依赖低代码工具往往难以满足企业在数据处理和业务逻辑上的要求。数据映射作为连接不同数据源和业务逻辑的桥梁,显…...

SpringBoot集成阿里easyexcel(一)基础导入导出
easyexcel主要用于excel文件的读写,可使用model实体类来定义文件读写的模板,对开发人员来说实现简单Excel文件的读写很便捷。可参考官方文档 https://github.com/alibaba/easyexcel 一、引入依赖 <!-- 阿里开源EXCEL --><dependency><gr…...
四元组问题
目录 问题描述 输入格式 输出格式 样例输入 样例输出 说明 评测数据规模 运行限制 原题链接 代码思路 问题描述 从小学开始,小明就是一个非常喜欢数学的孩子。他喜欢用数学的方式解决各种问题。在他的高中时期,他遇到了一个非常有趣的问题&…...

如何用Prometheus监控禁用了Actuator的SpringBoot?
需求来源 prometheus监控微服务一般都是使用micrometer结合actuator来做: 添加依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId> </dependency> <d…...

使用TensorFlow实现一个简单的神经网络:从入门到精通
使用TensorFlow实现一个简单的神经网络:从入门到精通 在现代数据科学和机器学习领域,神经网络是一个非常重要的工具。TensorFlow 是一个开源的深度学习框架,由 Google 开发和维护,它使得构建和训练神经网络变得更加容易。本文将详细介绍如何使用 TensorFlow 实现一个简单的…...

应用DFX能力介绍
一、HarmonyOS生态DFX能力范围 围绕开发者,构建三方应用和设备从开发到维护全生命周期所必需、有竞争力、有特色的调试调优、定位、维护能力。 二、HarmonyOS DFX能力全集 三、DFX设计主要范围 1、HiLog 日志分类 日志常用命令 日志级别 日志规则 2、HiAppEvent 完…...

第三篇 第20章工程计价数字化与智能化
第三篇 工程计价 第20章 工程计价数字化与智能化 20.1 BIM在工程计价中的应用 20.1.1 BIM概述 1.定义 在建设工程及设施全生命周期内,对其物理特征和功能特征信息进行数字化表达,依次设计、施工、运营的过程和结果的总称。应由核心层、共享层、专业领域层、资源层四个概念层…...
)
成语700词(46~65组)
目录 46.熟悉、了解、知晓相关(15 个)47.很常见不奇怪(6 个)48.看法一致与否(10 个)49.从细节看全貌(10 个)50.看事情透彻(11 个)51.对事情的态度与评价(7 个)52.数量多与少(11 个)53.建筑相关(6 个)54.相同与不同(17 个)55.技艺精湛(10 个)56.与观看欣赏相…...

linux如何配置静态IP
文章目录 使用ip命令(临时配置)Debian/Ubuntu系统(使用netplan)CentOS/RHEL系统(使用nmcli或nmtui)使用nmcli(命令行界面)使用nmtui(文本用户界面)通过图形界…...

Dependency Check:一款针对应用程序依赖组件的安全检测工具
关于Dependency Check Dependency-Check 是一款软件组合分析 (SCA) 工具,可尝试检测项目依赖项中包含的公开披露的漏洞。它通过确定给定依赖项是否存在通用平台枚举 (CPE) 标识符来实现此目的。如果找到,它…...

Python 从入门到实战28(文件的读操作)
我们的目标是:通过这一套资料学习下来,通过熟练掌握python基础,然后结合经典实例、实践相结合,使我们完全掌握python,并做到独立完成项目开发的能力。 上篇文章我们讨论了文件的打开、创建、关闭的相关知识。今天我们将…...

初创团队如何利用 Taotoken 以更低成本试用多种大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用 Taotoken 以更低成本试用多种大模型 对于初创团队和独立开发者而言,在产品原型验证阶段,…...

R3nzSkin国服换肤终极教程:5分钟免费解锁英雄联盟全皮肤
R3nzSkin国服换肤终极教程:5分钟免费解锁英雄联盟全皮肤 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 还在为英雄联盟国服的限定皮肤望而…...

如何一键下载推特上的所有媒体资源?X-Spider帮你轻松解决内容收集难题
如何一键下载推特上的所有媒体资源?X-Spider帮你轻松解决内容收集难题 【免费下载链接】x-spider A spider for X (Twitter) 项目地址: https://gitcode.com/gh_mirrors/xs/x-spider 你是否曾遇到过这种情况:在推特上看到了精美的图片、有趣的视频…...

DaVinci Developer与Configurator Pro联调指南:如何高效设计SWC并集成到ECU工程
DaVinci Developer与Configurator Pro联调实战:从SWC设计到ECU集成的全流程解析 在汽车电子控制单元(ECU)开发领域,工具链的协同效率直接决定了项目进度和质量。作为Vector公司AUTOSAR工具链的核心组件,DaVinci Develo…...

GARbro:跨平台视觉小说游戏资源解析与提取工具
GARbro:跨平台视觉小说游戏资源解析与提取工具 【免费下载链接】GARbro Visual Novels resource browser 项目地址: https://gitcode.com/gh_mirrors/ga/GARbro GARbro是一款专门用于解析和提取视觉小说游戏资源文件的跨平台开源工具,支持数百种游…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

使用mcp-maker快速构建AI工具调用服务器:从协议原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给大语言模型(LLM)装上更强大的“手脚”,让它能直接操作我电脑上的各种软件和工具。这听起来很酷,对吧?但实际操作起来,你会发现一个核心痛…...

Supabase AI Agent技能库:安全集成数据库操作与边缘函数调用
1. 项目概述:当Supabase遇上AI Agent,一个技能库的诞生最近在捣鼓AI Agent应用开发,发现一个挺有意思的现象:大家都能用LangChain、LlamaIndex这些框架快速搭出个Agent的架子,但真想让这个Agent去干点具体、有用的活儿…...

前端工程化实战:基于 Kelivo 模板的配置即代码与自动化工作流
1. 项目概述与核心价值最近在整理个人开发环境时,发现一个挺有意思的项目,叫Chevey339/kelivo。乍一看这个仓库名,可能有点摸不着头脑,但点进去之后,你会发现它是一个围绕特定开发工具或框架进行深度定制、优化和功能增…...

如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南
如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾在寻找百度网盘资源时,被一个小小的提取码卡住,不得不花费…...