NLP基础1
NLP基础1
深度学习中的NLP的特征输入
1.稠密编码(特征嵌入)
稠密编码(Dense Encoding):指将离散或者高纬的稀疏数据转化为低纬度的连续、密集向量表示
特征嵌入(Feature Embedding)
也称为词嵌入,是稠密编码的一种表现形式,单词映射到一个低维的连续向量空间来表示单词,这些向量通常具有较低的维度,并且每个维度上的值是连续的浮点数。这种表示方法能够捕捉单词之间的语义和句法关系,并且在计算上更高效。
稠密编码的主要特点:
- 低维表示:
- 稠密编码将高维的稀疏向量(如 one-hot 编码)映射到低维的密集向量。这样可以减少计算复杂度,并且更好地捕捉词与词之间的关系。
- 语义信息:
- 稠密编码能够捕捉单词之间的语义关系。例如,“king” 和 “queen” 在向量空间中可能会非常接近(欧氏距离或余弦相似度),因为它们有相似的语义角色。
- 上下文依赖:
- 稠密编码通常是基于上下文生成的。不同的上下文可能会导致同一个单词有不同的向量表示。例如,“bank” 在金融上下文中和在河流上下文中会有不同的向量表示。
- 可微学习:
- 嵌入表示通常通过神经网络进行学习,并且通过反向传播算法进行优化。
2.词嵌入算法
2.1 Embedding Layer
嵌入层(Embedding Layer)是深度学习中用于将离散的、高维的稀疏表示(如 one-hot 编码)转换为低维的密集向量表示的一种神经网络层。这种转换能够捕捉到输入数据中的语义信息,并且在计算上更加高效。嵌入层通常用于处理文本数据,例如单词或字符。
嵌入层的主要特点
- 低维表示:
- 将高维的稀疏向量(如 one-hot 编码)映射到低维的密集向量空间。例如,一个词汇表大小为 10,000 的 one-hot 编码可以被映射到 100 维的密集向量。
- 参数学习:
- 嵌入层的权重是通过训练过程自动学习的。这些权重矩阵存储了每个输入项(如单词)的向量表示。
- 语义信息:
- 通过训练,嵌入层能够捕捉到输入项之间的语义关系。例如,在词嵌入中,相似的单词在向量空间中会非常接近。
- 灵活性:
- 嵌入层可以应用于多种类型的输入,包括单词、字符、用户 ID 等。
词嵌入层的使用:
nn.Embedding(num_embeddings=10, embedding_dim=4)
参数:
- num_embeddings 表示词的数量
- embedding_dim 表示用多少维的向量来表示每个词
尝试搭建NNLM语言模型
import torch
import torch.nn as nn
import torch.optim as optim
import jieba
import recorpus = ["床前明月光,疑是地上霜。举头望明月,低头思故乡。","春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。","千山鸟飞绝,万径人踪灭。孤舟蓑笠翁,独钓寒江雪。","白日依山尽,黄河入海流。欲穷千里目,更上一层楼。","茫茫烟水上,日暮阴云飞。孤坐正愁绪,湖南谁捣衣。","国破山河在,城春草木深。感时花溅泪,恨别鸟惊心。","烽火连三月,家书抵万金。白头搔更短,浑欲不胜簪。","人闲桂花落,夜静春山空。月出惊山鸟,时鸣春涧中。"
]def remove_punctuation(tokens):return [token for token in tokens if not re.match(r'[,。!?、;:“”‘’()《》〈〉【】〔〕…—~·]', token)]sentences = [jieba.lcut(sen) for sen in corpus]
# print(sentences)sentences = [remove_punctuation(sentence) for sentence in sentences]# 创建词表和对应的映射关系
word_list = [word for sentence in sentences for word in sentence]
# 去重
word_list = list(set(word_list))
# print(word_list)
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
# 词表大小
n_class = len(word_dict)
# print(n_class)# 设置超参数
m_dim = 2 # 嵌入向量的维度
n_hidden = 10 # 神经元数量
n_step = 1 # 输入步长数
max_lens = 1 # 最大长度# 创建输入的样本和目标值
def make_batch(sentences, max_lens, word_dict):input_batch = []target_batch = []for sentence in sentences:if len(sentence) < n_step + 1:continuefor i in range(len(sentence) - n_step):input = [word_dict[word] for word in sentence[i:i+n_step]]target = word_dict[sentence[i+n_step]]# 填充或者裁剪确保长度等于max_lensinput += [0] * (max_lens - len(input))input = input[:max_lens]input_batch.append(input)target_batch.append(target)return torch.LongTensor(input_batch), torch.LongTensor(target_batch)class NNLM(nn.Module):def __init__(self, n_step, n_class, m_dim, n_hidden):super(NNLM, self).__init__()# 定义嵌入层,单词索引映射为嵌入向量self.embed = nn.Embedding(n_class, m_dim) # 产出为每一个词的向量,为1 x m_dim的# 隐藏层,输入为两个词,所以采用m_dim*n_stepself.linear1 = nn.Linear(m_dim*n_step, n_hidden)# 分类类别就是词表大小self.linear2 = nn.Linear(n_hidden, n_class)def forward(self, x):x = self.embed(x) # 通过嵌入层得到的形状(batch_size, n_step, m_dim)->(batch_size, n_step*m_dim)x = x.view(-1, x.size(1) * x.size(2))x = self.linear1(x)x = torch.tanh(x)output = self.linear2(x)return outputmodel = NNLM(n_step, n_class, m_dim, n_hidden)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)input_batch, target_batch = make_batch(sentences, max_lens, word_dict)for epoch in range(10000):optimizer.zero_grad()output = model(input_batch)loss = criterion(output, target_batch)loss.backward()optimizer.step()if (epoch + 1) % 1000 == 0:print(f"Epoch:{epoch+1}, Loss:{loss:.4f}")# 预测
with torch.no_grad():predict = model(input_batch).max(1, keepdim=True)[1]predictions = [number_dict[n.item()] for n in predict.squeeze()]# print([sen.split()[:2] for sentence in sentences for sen in sentence], '->', [number_dict[n.item()] for n in predict.squeeze()])
print("输入序列 -> 预测结果")
new_sentences = "床前"
count = 5
flog = True
for i in range(0, len(input_batch)):input_seq = []x = i + 1if x < len(input_batch):input_seq = [number_dict[idx.item()] for idx in input_batch[x]]input_seq1 = [ number_dict[ idx.item() ] for idx in input_batch[ i ] ]# 按词预测下一个词,并组装诗歌new_sentences += predictions[i]# 判断诗歌后是否接符号if len(new_sentences) % count == 0 and flog:new_sentences += ","count += 6flog = Falseif len(new_sentences) % count == 0 and not flog:new_sentences += "。"count += 6flog = Trueif len(new_sentences) % 24 == 0:new_sentences += input_seq[0]print(f"{input_seq1} -> {predictions[i]}")
print(new_sentences)# 计算准确率
correct = (predict.squeeze() == target_batch).sum().item()
accuracy = correct / len(target_batch) * 100
print(f"Accuracy: {accuracy:.2f}%")2.2 word2vec
Word2Vec 是一种用于生成词嵌入(word embeddings)的流行算法,由 Google 在 2013 年提出。它通过在大规模文本数据上训练神经网络模型来学习单词的向量表示。这些向量能够捕捉到单词之间的语义和句法关系,使得相似的单词在向量空间中具有相近的表示。
Word2Vec 的主要特点
- 低维表示:
- 将高维的稀疏向量(如 one-hot 编码)映射到低维的密集向量空间。例如,一个词汇表大小为 10,000 的 one-hot 编码可以被映射到 100 维的密集向量。
- 语义信息:
- 通过训练,Word2Vec 能够捕捉到输入项之间的语义关系。例如,“king” 和 “queen” 在向量空间中会非常接近,因为它们有相似的语义角色。
- 上下文依赖:
- Word2Vec 通常是基于上下文生成的。不同的上下文可能会导致同一个单词有不同的向量表示。例如,“bank” 在金融上下文中和在河流上下文中会有不同的向量表示。
Word2Vec 包含两种主要的模型:CBOW (Continuous Bag of Words) 和 Skip-gram。
CBOW (Continuous Bag of Words)
- 目标:给定一个单词的上下文,预测该单词。
- 结构:输入是上下文单词的平均向量,输出是中心单词的概率分布。
- 优点:计算效率较高,适合处理小规模的数据集。
- 缺点:对于罕见词的处理不如 Skip-gram 好。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt# 定义数据类型
dtype = torch.FloatTensor# 语料库,包含训练模型的句子
sentences = ["i like dog", "i like cat", "i like animal","dog cat animal", "apple cat dog like", "cat like fish","dog like meat", "i like apple", "i hate apple","i like movie book music apple", "dog like bark", "dog friend cat"]# 构建词表
word_sentences = " ".join(sentences).split()
# 去重
word_list = list(set(word_sentences))
word_dict = {w: i for i, w in enumerate(word_list)}# 创建CBOW训练数据
cbow_data = []
for i in range(1, len(word_sentences) - 1):context = [word_dict[word_sentences[i-1]], word_dict[word_sentences[i+1]]]target = word_dict[word_sentences[i]]cbow_data.append([context, target])# 模型参数
voc_size = len(word_dict)
# 词向量维度
embedding_size = 2
# 批次
batch_size = 2# 定义CBOW模型
class CBOW(nn.Module):def __init__(self):super().__init__()# 映射维度self.embed = nn.Embedding(voc_size, embedding_size)# 输出矩阵self.linear = nn.Linear(embedding_size, voc_size)def forward(self, x):embeds = self.embed(x) # 映射矩阵, 通过嵌入层得到的形状是(batch_size, n_step, m_dim)avg_embeds = torch.mean(embeds, dim=1) # 在n_step维度上平均output = self.linear(avg_embeds)return outputmodel = CBOW()criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)def random_batch(data, size):random_labels = []random_inputs = []# 从数据中随机选择size个索引random_index = np.random.choice(range(len(data)), size, replace=False)# 根据随机索引生成输入和标签批次for i in random_index:# 目标词one-hot编码random_inputs.append(data[i][0])# 上下文的词的索引作为标签random_labels.append(data[i][1])return random_inputs, random_labelsfor epoch in range(10000):inputs, labels = random_batch(cbow_data, batch_size)inputs = np.array(inputs)input_batch = torch.LongTensor(inputs)label_batch = torch.LongTensor(labels)optimizer.zero_grad()output = model(input_batch)loss = criterion(output, label_batch)if (epoch + 1) % 1000 == 0:print(f"Epoch:{epoch+1}, Loss:{loss:.4f}")loss.backward()optimizer.step()# 可视化词嵌入
for i, label in enumerate(word_list):# 获取模型参数W = model.embed.weight.data.numpy()x, y = float(W[i][0]), float(W[i][1])# 绘制散点图plt.scatter(x, y)plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords="offset points", ha="right", va="bottom")
plt.show()Skip-gram
- 目标:给定一个中心单词,预测其上下文中的单词。
- 结构:输入是中心单词的向量,输出是上下文单词的概率分布。
- 优点:能够更好地处理罕见词,生成的词向量质量较高。
- 缺点:计算成本较高,特别是在大规模数据集上。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt# 定义数据类型
dtype = torch.FloatTensor# 语料库,包含训练模型的句子
sentences = ["i like dog", "i like cat", "i like animal","dog cat animal", "apple cat dog like", "cat like fish","dog like meat", "i like apple", "i hate apple","i like movie book music apple", "dog like bark", "dog friend cat"]# 构建词表
word_sentences = " ".join(sentences).split()
word_list = list(set(word_sentences))
word_index = {w: i for i, w in enumerate(word_list)}
index_word = {i: w for i, w in enumerate(word_list)}
vocab_size = len(word_list)# 创建skip的训练数据集
skip_grams = []
for i in range(1, len(word_sentences) - 1):# 当前词对应的idcenter = word_index[word_sentences[i]]# 获取当前词的前后两个上下文对应的词的idcontext = [word_index[word_sentences[i-1]], word_index[word_sentences[i+1]]]# 将当前词和上下文词组合成skip-gram数据集for w in context:skip_grams.append([center, w])# 定义超参数
# 词汇表维度
embed_dim = 2
# 训练批次
batch_size = 5# 定义skip模型
class Word2Vec(nn.Module):def __init__(self, dtype):super(Word2Vec, self).__init__()# 定义词嵌入矩阵,随机初始化,大小为(词汇表大小,词嵌入维度)self.W = nn.Parameter(torch.rand(vocab_size, embed_dim)).type(dtype)print(self.W.type())# 定义输出层矩阵W2, 随机初始化, 大小为(词嵌入维度, 词汇表大小)self.W2 = nn.Parameter(torch.rand(embed_dim, vocab_size)).type(dtype)self.log_softmax = nn.LogSoftmax(dim=1)def forward(self, x):# 映射层weights = torch.matmul(x, self.W)# 输出层out_put = torch.matmul(weights, self.W2)return out_putmodel = Word2Vec(dtype)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)def random_batch(data, size):random_labels = []random_inputs = []# 从数据中随机选择size个索引random_index = np.random.choice(range(len(data)), size, replace=False)# 根据随机索引生成输入和标签批次for i in random_index:# 目标词one-hot编码random_inputs.append(np.eye(vocab_size)[data[i][0]])# 上下文的词的索引作为标签random_labels.append(data[i][1])return random_inputs, random_labelsfor epoch in range(10000):inputs, labels = random_batch(skip_grams, batch_size)inputs = np.array(inputs)input_batch = torch.from_numpy(inputs).float()label_batch = torch.LongTensor(labels)optimizer.zero_grad()output = model(input_batch)loss = criterion(output, label_batch)if (epoch + 1) % 1000 == 0:print(f"Epoch:{epoch+1}, Loss:{loss:.4f}")loss.backward()optimizer.step()# 可视化词嵌入
for i, label in enumerate(word_list):# 获取模型参数W, W2 = model.parameters()x, y = float(W[i][0]), float(W[i][1])# 绘制散点图plt.scatter(x, y)plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords="offset points", ha="right", va="bottom")
plt.show()gensim API调用
| 参数 | 说明 |
|---|---|
| sentences | 可以是一个list,对于大语料集,建议使用BrownCorpus,Text8Corpus或lineSentence构建。 |
| vector_size | word向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好。推荐值为几十到几百。 |
| alpha | 学习率 |
| window | 表示当前词与预测词在一个句子中的最大距离是多少。 |
| min_count | 可以对字典做截断。词频少于min_count次数的单词会被丢弃掉,默认值为5。 |
| max_vocab_size | 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。 |
| sample | 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5) |
| seed | 用于随机数发生器。与初始化词向量有关。 |
| workers | 参数控制训练的并行数。 |
| sg | 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。 |
| hs | 如果为1则会采用hierarchica·softmax技巧。如果设置为0(default),则negative sampling会被使用。 |
| negative | 如果>0,则会采用negative samping,用于设置多少个noise words。 |
| cbow_mean | 如果为0,则采用上下文词向量的和,如果为1(default)则采用均值。只有使用CBOW的时候才起作用。 |
| hashfxn | hash函数来初始化权重。默认使用python的hash函数。 |
| epochs | 迭代次数,默认为5。 |
| trim_rule | 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RULE_DISCARD,utils。RULE_KEEP或者utils。RULE_DEFAULT的函数。 |
| sorted_vocab | 如果为1(default),则在分配word index 的时候会先对单词基于频率降序排序。 |
| batch_words | 每一批的传递给线程的单词的数量,默认为10000 |
| min_alpha | 随着训练的进行,学习率线性下降到min_alpha |
import numpy as np
from gensim.models import Word2Vec
import matplotlib.pyplot as plt# 语料库,包含训练模型的句子
sentences = ["i like dog", "i like cat", "i like animal","dog cat animal", "apple cat dog like", "cat like fish","dog like meat", "i like apple", "i hate apple","i like movie book music apple", "dog like bark", "dog friend cat"]# 每个句子分成单词表(word2vec api要求输入格式为二维列表: 每一个句子是一个单词列表
token_list = [sentence.split() for sentence in sentences]# 定义word2vec模型
model = Word2Vec(token_list, vector_size=2, window=1, min_count=0, sg=1)# 获取词汇表
word_list = list(model.wv.index_to_key)# 可视化词嵌入
for i, word in enumerate(word_list):# 获取模型参数W = model.wv[word]x, y = float(W[0]), float(W[1])# 绘制散点图plt.scatter(x, y)plt.annotate(word, xy=(x, y), xytext=(5, 2), textcoords="offset points", ha="right", va="bottom")
plt.show()print(model.wv.most_similar("dog"))
# 打印两个词的相似度
print(model.wv.similarity("dog", "cat"))相关文章:

NLP基础1
NLP基础1 深度学习中的NLP的特征输入 1.稠密编码(特征嵌入) 稠密编码(Dense Encoding):指将离散或者高纬的稀疏数据转化为低纬度的连续、密集向量表示 特征嵌入(Feature Embedding) 也称…...

001.docker30分钟速通版
docker简介 docker就是一个用于构建(build),运行(run),传送(share)应用程序的平台做一个不恰当的类比,就是外卖平台,如果你自己做华莱士不一定好吃࿰…...

Kafka 在 Linux 下的集群配置和安装
Kafka 在 Linux 下的集群配置和安装 Apache Kafka 是一个流行的分布式流处理平台,广泛用于实时数据管道和流处理应用。本文将详细讲解如何在 Linux 环境中配置和安装 Kafka 集群,并包括通过 Docker 安装和配置 Kafka 的步骤。每个步骤都将提供详细的解释…...

Python--操作列表
1.for循环 1.1 for循环的基本语法 for variable in iterable: # 执行循环体 # 这里可以是任何有效的Python代码块这里的variable是一个变量名,用于在每次循环迭代时临时存储iterable中的下一个元素。 iterable是一个可迭代对象,比如列表(…...
)
JMeter(需要补充请在留言区发给我,谢谢)
一、学习工具 1、CinfigElement(HTTP Request Defaults、HTTP Header Manager、HTTP Authorization、CSV Data Set Config、User Defined Variables、JDBC Connection Configuration、HTTP Cookie Manager、Random Variable) 二、协议 1、HTTP协议(消息体数据&am…...

线程池的执行流程和配置参数总结
一、线程池的执行流程总结 提交线程任务;如果线程池中存在空闲线程,则分配一个空闲线程给任务,执行线程任务;线程池中不存在空闲线程,则线程池会判断当前线程数是否超过核心线程数(corePoolSize)…...

node-red-L3-重启指定端口的 node-red
重启指定端口 目的步骤查找正在运行的Node.js服务的进程ID(PID):停止Node.js服务:启动Node.js服务: 目的 重启指定端口的 node-red 步骤 在Linux系统中,如果你想要重启一个正在运行的Node.js服务&#x…...

(done) 使用泰勒展开证明欧拉公式
问问神奇的 GPT,how to prove euler formula? 一个答案如下:...
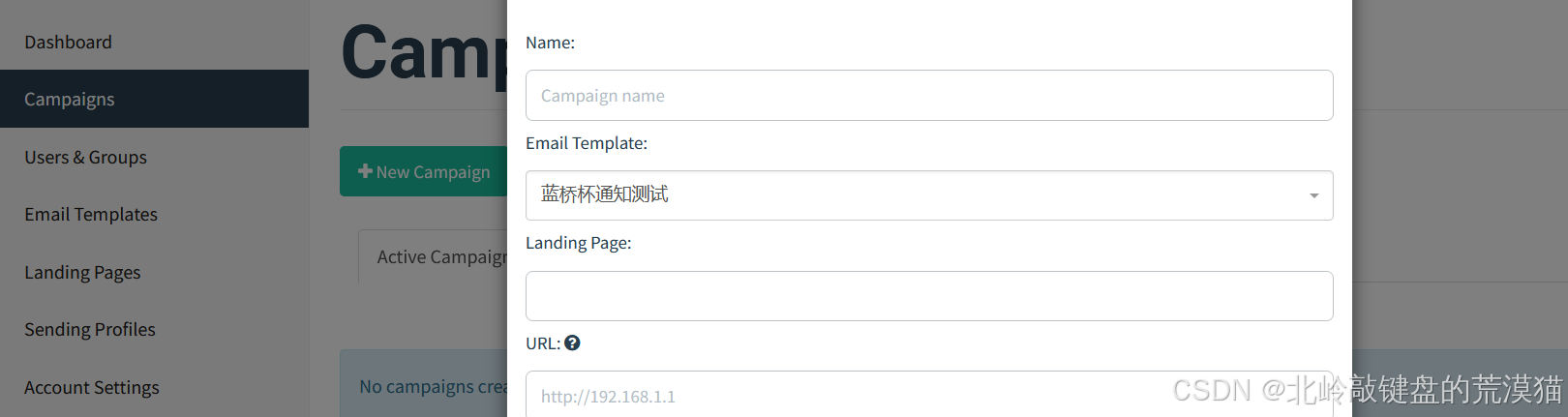
红队apt--邮件钓鱼
前言 欢迎来到我的博客 个人主页:北岭敲键盘的荒漠猫-CSDN博客 免责声明: 本文仅供了解攻击方手法使用,切勿用于非授权情节 初步了解邮件基础 用途方面 这个我们应该比较熟悉,最常用于验证码接收,也有一些厂商会用这个来打广告,…...

十七,Spring Boot 整合 MyBatis 的详细步骤(两种方式)
十七,Spring Boot 整合 MyBatis 的详细步骤(两种方式) 文章目录 十七,Spring Boot 整合 MyBatis 的详细步骤(两种方式)1. Spring Boot 配置 MyBatis 的详细步骤2. 最后: MyBatis 的官方文档:https://mybatis.p2hp.com/ 关于 MyBa…...

DNS协议解析
DNS协议解析 什么是DNS协议 IP地址:一长串唯一标识网络上的计算机的数字 域名:一串由点分割的字符串名字 网址包含了域名 DNS:域名解析协议 IP>域名 --反向解析 域名>IP --正向解析 域名 由ICANN管理,有级别…...

每日一题——第一百零八题
题目: 写几个函数, ①输入10个职工的姓名和职工号 ②按照职工号由小到大排列, 姓名顺序也随之调整 ③要求输入一个职工号, 用折半查找找出该职工的姓名 #include<stdio.h> #include<string.h> #define MAX_EMPOLYEES…...

使用Python免费将pdf转为docx
刚刚想将pdf转换为docx文档时,居然要收费 还好我学过编程,这不得露两手 将pdf 转换为 docx 文档 的操作步骤 我这里使用的是Python语言 (1)在终端上安装 pdf2docx 是一个 Python 库,它可以将 PDF 文件转换为 Word (…...

树莓派4B+UBUNTU20.04+静态ip+ssh配置
树莓派4B+UBUNTU20.04+静态ip+ssh配置 1.烧录Ubuntu镜像1.1选择pi 4b1.2选择ubuntu server (服务器版,无桌面)20.041.3选择sd卡1.4 点击右下角 NEXT ,编辑设置,输入密码,wifi选CN, 开启ssh1.5 烧录,依次点击“是”,等待完成2 烧录完成后装入树莓派,上电,等待系统完成配…...

C#实现指南:将文件夹与exe合并为一个exe
在软件开发过程中,有时需要将多个文件(如资源文件、配置文件等)与可执行文件(exe)打包在一起,以便于分发和部署。在C#中,我们可以利用ILMerge或Costura.Fody等工具来实现这一目标。本文将介绍如…...

linux信号 | 学习信号三步走 | 全解析信号的产生方式
前言:本节内容是信号, 主要讲解的是信号的产生。信号的产生是我们学习信号的第二个阶段。 我们已经学习过第一个阶段——信号的概念与预备知识(没有学过的友友可以查看我的前一篇文章)。 以及我们还没有学习信号的第三个阶段——信…...

C++ 刷题 使用到的一些有用的容器和函数
优先队列 c优先队列priority_queue(自定义比较函数)_c优先队列自定义比较-CSDN博客 373. 查找和最小的 K 对数字 - 力扣(LeetCode) 官方题解: class Solution { public:vector<vector<int>> kSmallestP…...
)
【Kubernetes】常见面试题汇总(三十四)
目录 86. K8s 每个 Pod 中有一个特殊的 Pause 容器能否去除,简述原因。 特别说明: 题目 1-68 属于【Kubernetes】的常规概念题,即 “ 汇总(一)~(二十二)” 。 题目 69-113 属于【Kuberne…...

C++标准库双向链表 list 中的insert函数实现。
CPrimer中文版(第五版): //运行时错误:迭代器表示要拷贝的范围,不能指向与目的位置相同的容器 slist.insert(slist.begin(),slist.begin(),slist.end()); 如果我们传递给insert一对迭代器,它们不能…...
)
华为机考练习(golang)
输入 第一行输入一个正整数N,表示整数个数。(0<N<100000) 第二行输入N个整数,整数的取值范围为[-100,100]。 第三行输入一个正整数M,M代表窗口的大小,M<100000,且M<N。 输出 窗口…...

Kubernetes部署Valheim游戏服务器:云原生架构实践指南
1. 项目概述:当维京英灵殿遇上Kubernetes如果你和我一样,既沉迷于《英灵神殿》(Valheim)里那种与三五好友一起伐木、采矿、建造长屋,然后被巨魔追得满地图跑的原始乐趣,又恰好是一名整天和容器、编排系统打…...
)
用Python复现FAST天眼数学建模:从坐标变换到促动器伸缩量计算(附完整代码)
用Python复现FAST天眼数学建模:从坐标变换到促动器伸缩量计算(附完整代码) 中国天眼FAST作为全球最大单口径射电望远镜,其主动反射面调节系统堪称现代工程奇迹。当观测不同方位天体时,需要通过促动器精确控制4450块反射…...

Excel MCP Server终极指南:让AI成为你的Excel自动化助手
Excel MCP Server终极指南:让AI成为你的Excel自动化助手 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了重复的Excel操作&…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...

【低功耗蓝牙】④ 蓝牙MIDI协议:从ESP32 MicroPython代码到智能乐器DIY
1. 蓝牙MIDI协议入门:从音乐小白到智能乐器开发者 第一次听说蓝牙MIDI协议时,我正盯着桌上的ESP32开发板发呆。作为一个只会弹几个和弦的编程爱好者,完全没想到自己能用代码"演奏"音乐。蓝牙MIDI就像音乐世界的通用语言,…...

地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书
地下态势智能研判,拔高硐室深部安全透明管控等级技术白皮书 副标题:全要素三维动态重建井下场景,融合井下无感坐标解算、跨断面跨镜轨迹串联、身体指纹人员轨迹存档,井下风险前置感知、动态全程透明追溯 前言 矿山井下深部硐室与纵…...

Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南
Seraphine:英雄联盟智能BP助手与战绩查询工具完整指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟的对局中,BP(禁选英雄)阶段往往是决定胜负的关…...

Forge模组开发效率提升:Gradle插件自动化构建与热部署实践
1. 项目概述:一个为Forge模组开发者准备的“瑞士军刀”如果你是一名Minecraft Forge模组的开发者,或者你正打算踏入这个充满创造力的领域,那么你大概率经历过这样的场景:为了测试一个简单的功能改动,你需要反复地执行g…...

Gitclaw:封装复杂Git操作,提升开发效率的命令行工具
1. 项目概述:一个为Git操作注入“爪牙”的命令行工具如果你和我一样,日常开发工作重度依赖Git,那你肯定也经历过这样的时刻:面对一个需要多步操作才能完成的复杂Git任务,比如清理多个已合并的分支、批量重写提交历史中…...

Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案
Gopeed下载器深度解析:从零开始构建你的全平台高速下载解决方案 【免费下载链接】gopeed A fast, modern download manager for HTTP, BitTorrent, Magnet, and ed2k. Cross-platform, built with Golang and Flutter. 项目地址: https://gitcode.com/GitHub_Tre…...